 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Visual Aware Hierarchy Based Food Recognition
Dec 06, 2020
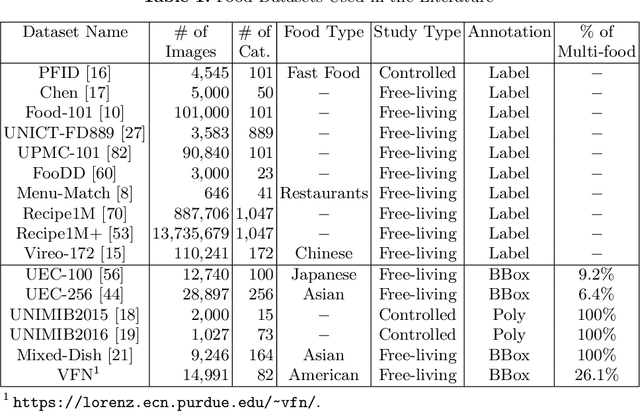
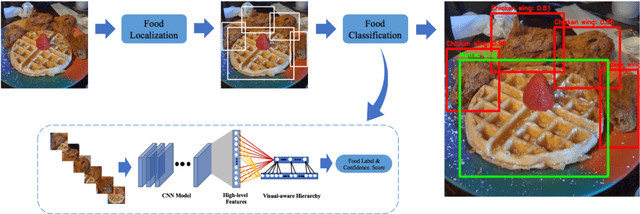

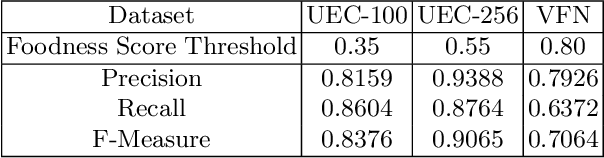
Food recognition is one of the most important components in image-based dietary assessment. However, due to the different complexity level of food images and inter-class similarity of food categories, it is challenging for an image-based food recognition system to achieve high accuracy for a variety of publicly available datasets. In this work, we propose a new two-step food recognition system that includes food localization and hierarchical food classification using Convolutional Neural Networks (CNNs) as the backbone architecture. The food localization step is based on an implementation of the Faster R-CNN method to identify food regions. In the food classification step, visually similar food categories can be clustered together automatically to generate a hierarchical structure that represents the semantic visual relations among food categories, then a multi-task CNN model is proposed to perform the classification task based on the visual aware hierarchical structure. Since the size and quality of dataset is a key component of data driven methods, we introduce a new food image dataset, VIPER-FoodNet (VFN) dataset, consists of 82 food categories with 15k images based on the most commonly consumed foods in the United States. A semi-automatic crowdsourcing tool is used to provide the ground-truth information for this dataset including food object bounding boxes and food object labels. Experimental results demonstrate that our system can significantly improve both classification and recognition performance on 4 publicly available datasets and the new VFN dataset.
Neural RGB-D Surface Reconstruction
Apr 09, 2021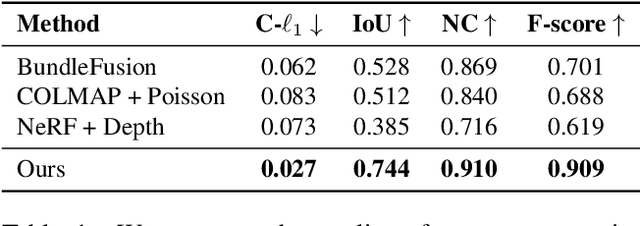
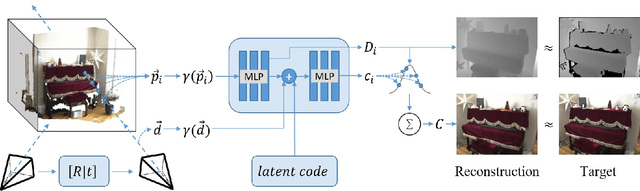
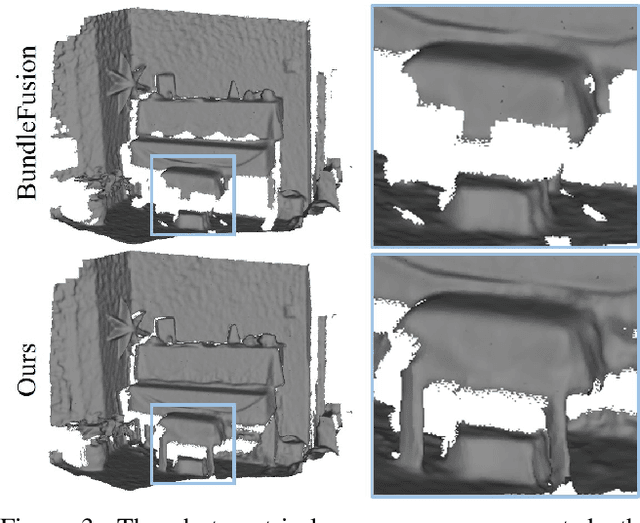
In this work, we explore how to leverage the success of implicit novel view synthesis methods for surface reconstruction. Methods which learn a neural radiance field have shown amazing image synthesis results, but the underlying geometry representation is only a coarse approximation of the real geometry. We demonstrate how depth measurements can be incorporated into the radiance field formulation to produce more detailed and complete reconstruction results than using methods based on either color or depth data alone. In contrast to a density field as the underlying geometry representation, we propose to learn a deep neural network which stores a truncated signed distance field. Using this representation, we show that one can still leverage differentiable volume rendering to estimate color values of the observed images during training to compute a reconstruction loss. This is beneficial for learning the signed distance field in regions with missing depth measurements. Furthermore, we correct misalignment errors of the camera, improving the overall reconstruction quality. In several experiments, we showcase our method and compare to existing works on classical RGB-D fusion and learned representations.
Distribution Alignment: A Unified Framework for Long-tail Visual Recognition
Mar 30, 2021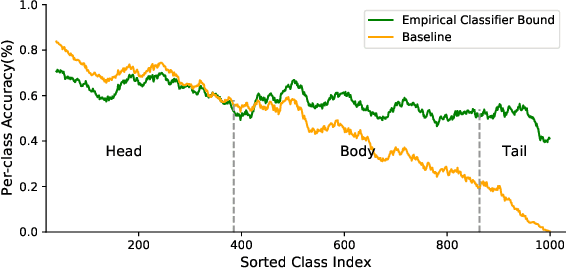
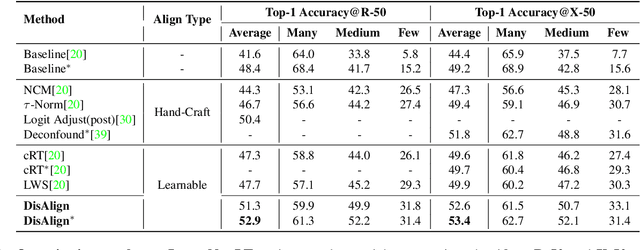
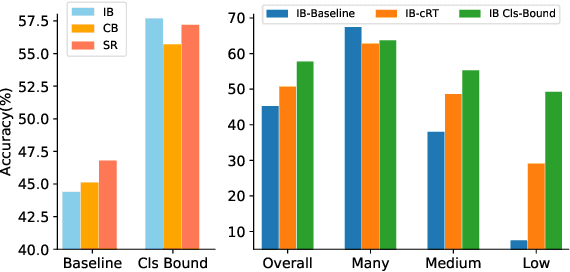
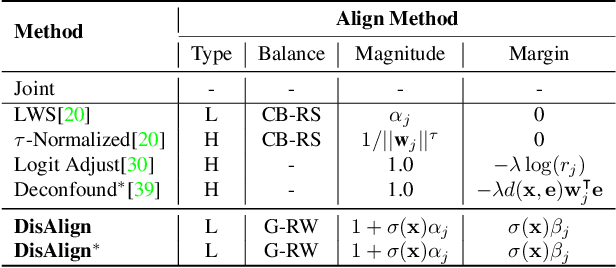
Despite the recent success of deep neural networks, it remains challenging to effectively model the long-tail class distribution in visual recognition tasks. To address this problem, we first investigate the performance bottleneck of the two-stage learning framework via ablative study. Motivated by our discovery, we propose a unified distribution alignment strategy for long-tail visual recognition. Specifically, we develop an adaptive calibration function that enables us to adjust the classification scores for each data point. We then introduce a generalized re-weight method in the two-stage learning to balance the class prior, which provides a flexible and unified solution to diverse scenarios in visual recognition tasks. We validate our method by extensive experiments on four tasks, including image classification, semantic segmentation, object detection, and instance segmentation. Our approach achieves the state-of-the-art results across all four recognition tasks with a simple and unified framework. The code and models will be made publicly available at: https://github.com/Megvii-BaseDetection/DisAlign
An Assessment of GANs for Identity-related Applications
Dec 18, 2020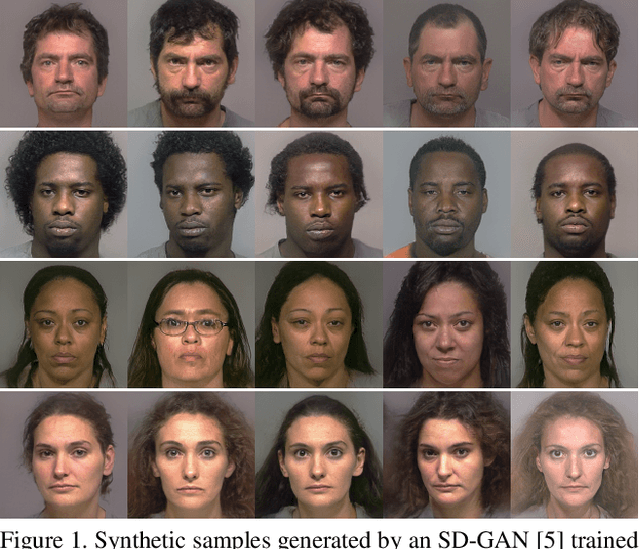

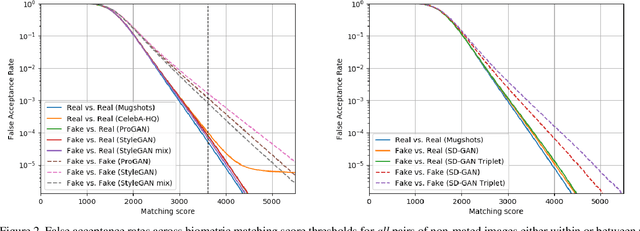

Generative Adversarial Networks (GANs) are now capable of producing synthetic face images of exceptionally high visual quality. In parallel to the development of GANs themselves, efforts have been made to develop metrics to objectively assess the characteristics of the synthetic images, mainly focusing on visual quality and the variety of images. Little work has been done, however, to assess overfitting of GANs and their ability to generate new identities. In this paper we apply a state of the art biometric network to various datasets of synthetic images and perform a thorough assessment of their identity-related characteristics. We conclude that GANs can indeed be used to generate new, imagined identities meaning that applications such as anonymisation of image sets and augmentation of training datasets with distractor images are viable applications. We also assess the ability of GANs to disentangle identity from other image characteristics and propose a novel GAN triplet loss that we show to improve this disentanglement.
Intelligent Frame Selection as a Privacy-Friendlier Alternative to Face Recognition
Jan 27, 2021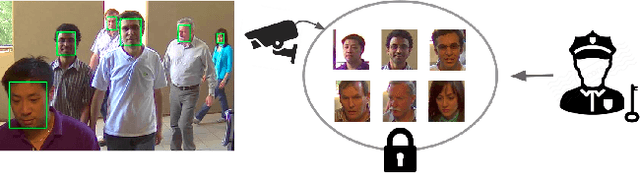

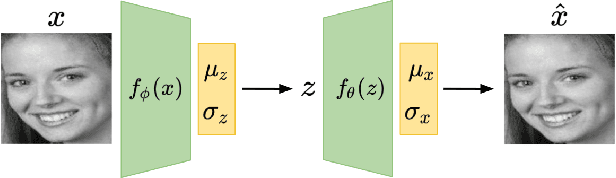

The widespread deployment of surveillance cameras for facial recognition gives rise to many privacy concerns. This study proposes a privacy-friendly alternative to large scale facial recognition. While there are multiple techniques to preserve privacy, our work is based on the minimization principle which implies minimizing the amount of collected personal data. Instead of running facial recognition software on all video data, we propose to automatically extract a high quality snapshot of each detected person without revealing his or her identity. This snapshot is then encrypted and access is only granted after legal authorization. We introduce a novel unsupervised face image quality assessment method which is used to select the high quality snapshots. For this, we train a variational autoencoder on high quality face images from a publicly available dataset and use the reconstruction probability as a metric to estimate the quality of each face crop. We experimentally confirm that the reconstruction probability can be used as biometric quality predictor. Unlike most previous studies, we do not rely on a manually defined face quality metric as everything is learned from data. Our face quality assessment method outperforms supervised, unsupervised and general image quality assessment methods on the task of improving face verification performance by rejecting low quality images. The effectiveness of the whole system is validated qualitatively on still images and videos.
Self-Supervised Pretraining Improves Self-Supervised Pretraining
Mar 25, 2021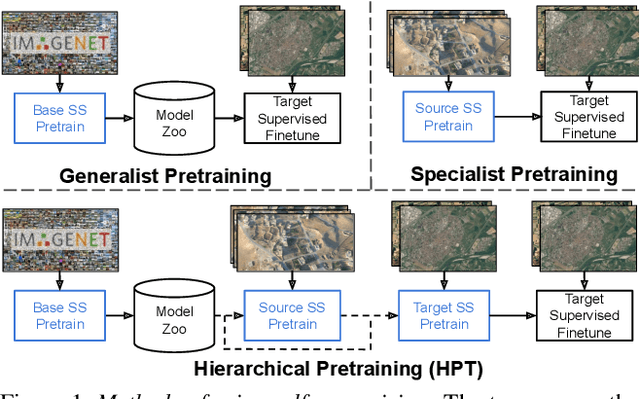
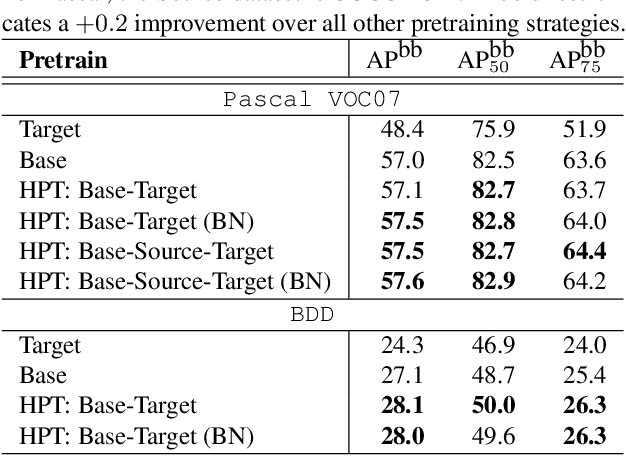
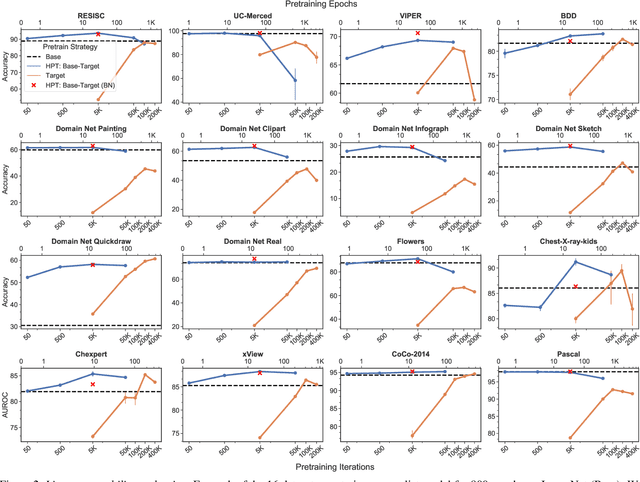
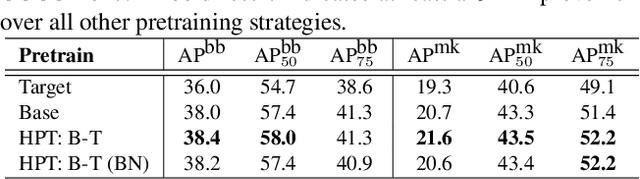
While self-supervised pretraining has proven beneficial for many computer vision tasks, it requires expensive and lengthy computation, large amounts of data, and is sensitive to data augmentation. Prior work demonstrates that models pretrained on datasets dissimilar to their target data, such as chest X-ray models trained on ImageNet, underperform models trained from scratch. Users that lack the resources to pretrain must use existing models with lower performance. This paper explores Hierarchical PreTraining (HPT), which decreases convergence time and improves accuracy by initializing the pretraining process with an existing pretrained model. Through experimentation on 16 diverse vision datasets, we show HPT converges up to 80x faster, improves accuracy across tasks, and improves the robustness of the self-supervised pretraining process to changes in the image augmentation policy or amount of pretraining data. Taken together, HPT provides a simple framework for obtaining better pretrained representations with less computational resources.
Learning to Guide Local Feature Matches
Oct 21, 2020
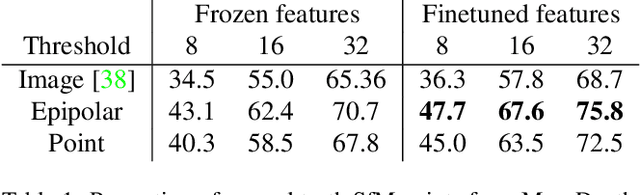
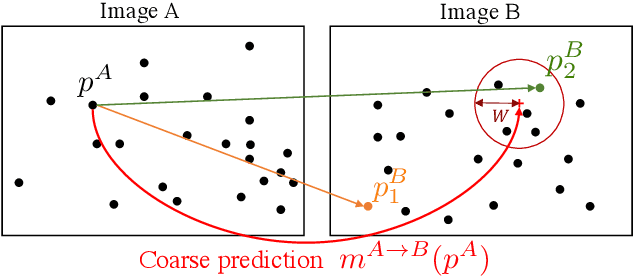
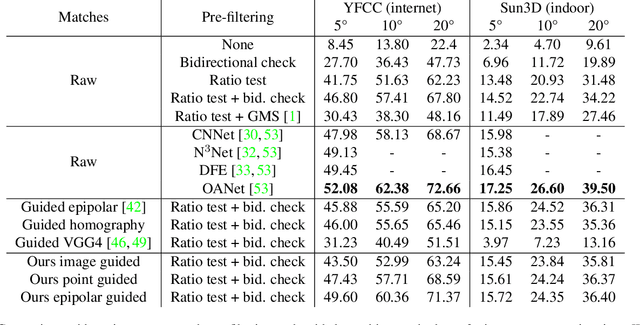
We tackle the problem of finding accurate and robust keypoint correspondences between images. We propose a learning-based approach to guide local feature matches via a learned approximate image matching. Our approach can boost the results of SIFT to a level similar to state-of-the-art deep descriptors, such as Superpoint, ContextDesc, or D2-Net and can improve performance for these descriptors. We introduce and study different levels of supervision to learn coarse correspondences. In particular, we show that weak supervision from epipolar geometry leads to performances higher than the stronger but more biased point level supervision and is a clear improvement over weak image level supervision. We demonstrate the benefits of our approach in a variety of conditions by evaluating our guided keypoint correspondences for localization of internet images on the YFCC100M dataset and indoor images on theSUN3D dataset, for robust localization on the Aachen day-night benchmark and for 3D reconstruction in challenging conditions using the LTLL historical image data.
Convolutional Neural Network for Blur Images Detection as an Alternative for Laplacian Method
Oct 15, 2020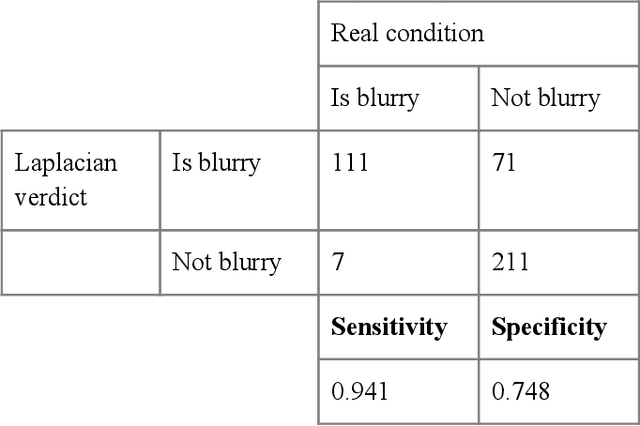
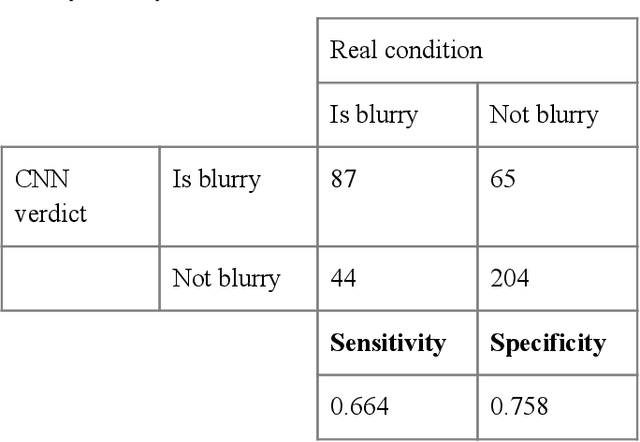

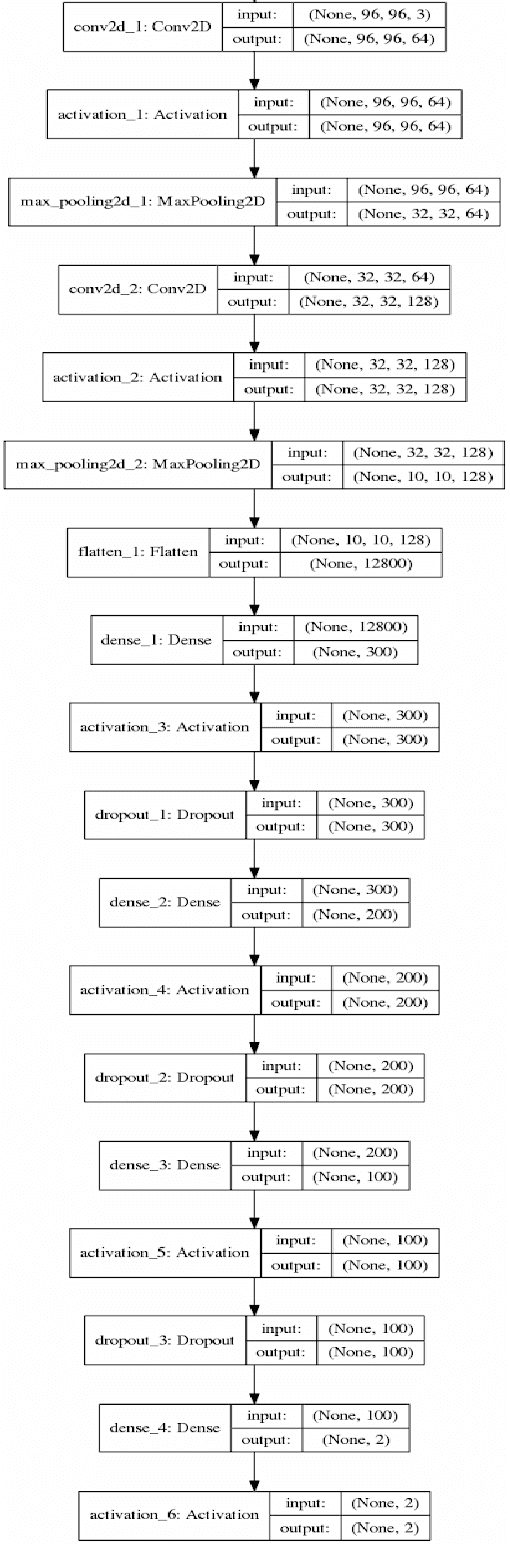
With the prevalence of digital cameras, the number of digital images increases quickly, which raises the demand for non-manual image quality assessment. While there are many methods considered useful for detecting blurriness, in this paper we propose and evaluate a new method that uses a deep convolutional neural network, which can determine whether an image is blurry or not. Experimental results demonstrate the effectiveness of the proposed scheme and are compared to deterministic methods using the confusion matrix.
Robust One Shot Audio to Video Generation
Dec 14, 2020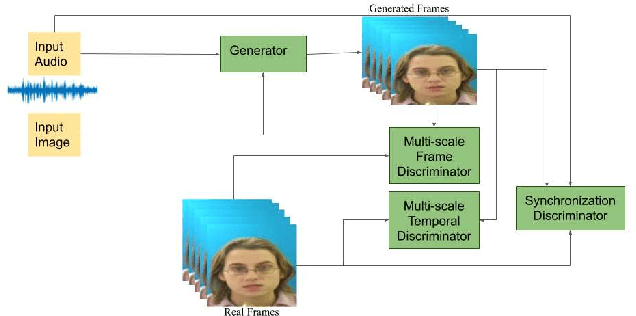
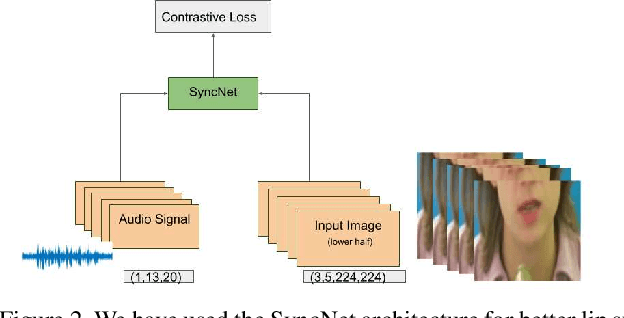

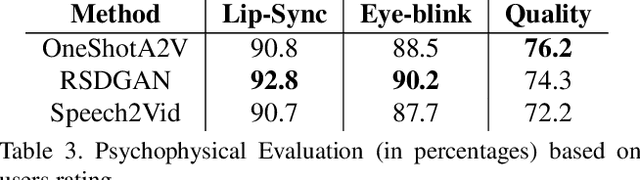
Audio to Video generation is an interesting problem that has numerous applications across industry verticals including film making, multi-media, marketing, education and others. High-quality video generation with expressive facial movements is a challenging problem that involves complex learning steps for generative adversarial networks. Further, enabling one-shot learning for an unseen single image increases the complexity of the problem while simultaneously making it more applicable to practical scenarios. In the paper, we propose a novel approach OneShotA2V to synthesize a talking person video of arbitrary length using as input: an audio signal and a single unseen image of a person. OneShotA2V leverages curriculum learning to learn movements of expressive facial components and hence generates a high-quality talking-head video of the given person. Further, it feeds the features generated from the audio input directly into a generative adversarial network and it adapts to any given unseen selfie by applying fewshot learning with only a few output updation epochs. OneShotA2V leverages spatially adaptive normalization based multi-level generator and multiple multi-level discriminators based architecture. The input audio clip is not restricted to any specific language, which gives the method multilingual applicability. Experimental evaluation demonstrates superior performance of OneShotA2V as compared to Realistic Speech-Driven Facial Animation with GANs(RSDGAN) [43], Speech2Vid [8], and other approaches, on multiple quantitative metrics including: SSIM (structural similarity index), PSNR (peak signal to noise ratio) and CPBD (image sharpness). Further, qualitative evaluation and Online Turing tests demonstrate the efficacy of our approach.
3D Reasoning for Unsupervised Anomaly Detection in Pediatric WbMRI
Mar 24, 2021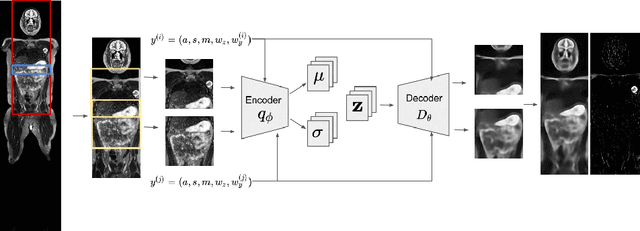
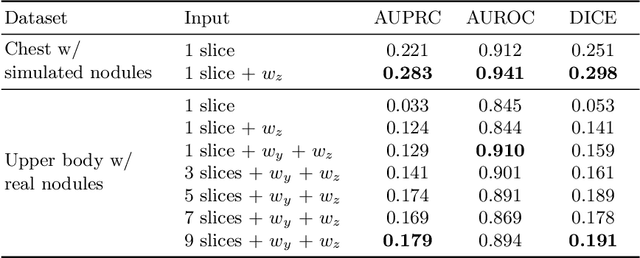

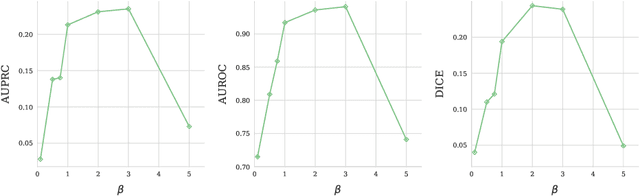
Modern deep unsupervised learning methods have shown great promise for detecting diseases across a variety of medical imaging modalities. While previous generative modeling approaches successfully perform anomaly detection by learning the distribution of healthy 2D image slices, they process such slices independently and ignore the fact that they are correlated, all being sampled from a 3D volume. We show that incorporating the 3D context and processing whole-body MRI volumes is beneficial to distinguishing anomalies from their benign counterparts. In our work, we introduce a multi-channel sliding window generative model to perform lesion detection in whole-body MRI (wbMRI). Our experiments demonstrate that our proposed method significantly outperforms processing individual images in isolation and our ablations clearly show the importance of 3D reasoning. Moreover, our work also shows that it is beneficial to include additional patient-specific features to further improve anomaly detection in pediatric scans.