 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Using StyleGAN for Visual Interpretability of Deep Learning Models on Medical Images
Jan 19, 2021
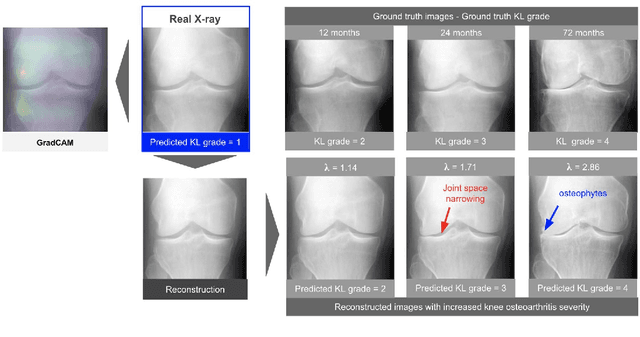
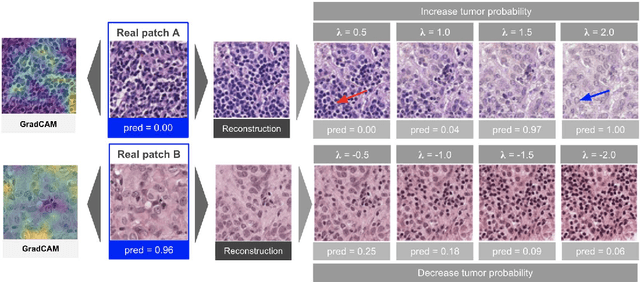
As AI-based medical devices are becoming more common in imaging fields like radiology and histology, interpretability of the underlying predictive models is crucial to expand their use in clinical practice. Existing heatmap-based interpretability methods such as GradCAM only highlight the location of predictive features but do not explain how they contribute to the prediction. In this paper, we propose a new interpretability method that can be used to understand the predictions of any black-box model on images, by showing how the input image would be modified in order to produce different predictions. A StyleGAN is trained on medical images to provide a mapping between latent vectors and images. Our method identifies the optimal direction in the latent space to create a change in the model prediction. By shifting the latent representation of an input image along this direction, we can produce a series of new synthetic images with changed predictions. We validate our approach on histology and radiology images, and demonstrate its ability to provide meaningful explanations that are more informative than GradCAM heatmaps. Our method reveals the patterns learned by the model, which allows clinicians to build trust in the model's predictions, discover new biomarkers and eventually reveal potential biases.
CIE XYZ Net: Unprocessing Images for Low-Level Computer Vision Tasks
Jun 23, 2020



Cameras currently allow access to two image states: (i) a minimally processed linear raw-RGB image state (i.e., raw sensor data) or (ii) a highly-processed nonlinear image state (e.g., sRGB). There are many computer vision tasks that work best with a linear image state, such as image deblurring and image dehazing. Unfortunately, the vast majority of images are saved in the nonlinear image state. Because of this, a number of methods have been proposed to "unprocess" nonlinear images back to a raw-RGB state. However, existing unprocessing methods have a drawback because raw-RGB images are sensor-specific. As a result, it is necessary to know which camera produced the sRGB output and use a method or network tailored for that sensor to properly unprocess it. This paper addresses this limitation by exploiting another camera image state that is not available as an output, but it is available inside the camera pipeline. In particular, cameras apply a colorimetric conversion step to convert the raw-RGB image to a device-independent space based on the CIE XYZ color space before they apply the nonlinear photo-finishing. Leveraging this canonical image state, we propose a deep learning framework, CIE XYZ Net, that can unprocess a nonlinear image back to the canonical CIE XYZ image. This image can then be processed by any low-level computer vision operator and re-rendered back to the nonlinear image. We demonstrate the usefulness of the CIE XYZ Net on several low-level vision tasks and show significant gains that can be obtained by this processing framework. Code and dataset are publicly available at https://github.com/mahmoudnafifi/CIE_XYZ_NET.
Continual learning in cross-modal retrieval
Apr 19, 2021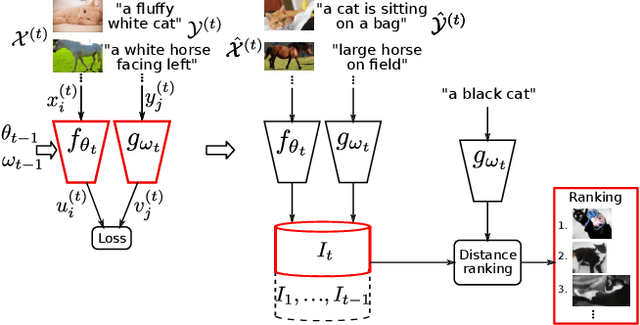
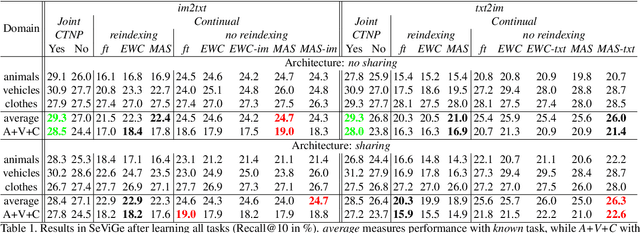
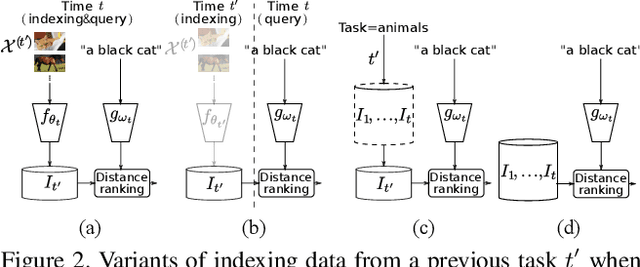
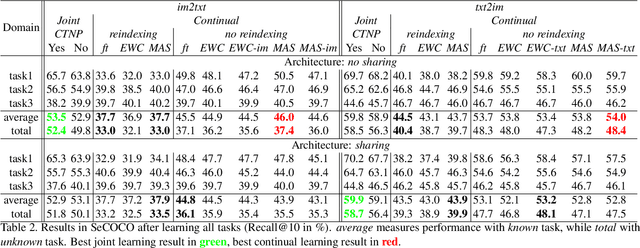
Multimodal representations and continual learning are two areas closely related to human intelligence. The former considers the learning of shared representation spaces where information from different modalities can be compared and integrated (we focus on cross-modal retrieval between language and visual representations). The latter studies how to prevent forgetting a previously learned task when learning a new one. While humans excel in these two aspects, deep neural networks are still quite limited. In this paper, we propose a combination of both problems into a continual cross-modal retrieval setting, where we study how the catastrophic interference caused by new tasks impacts the embedding spaces and their cross-modal alignment required for effective retrieval. We propose a general framework that decouples the training, indexing and querying stages. We also identify and study different factors that may lead to forgetting, and propose tools to alleviate it. We found that the indexing stage pays an important role and that simply avoiding reindexing the database with updated embedding networks can lead to significant gains. We evaluated our methods in two image-text retrieval datasets, obtaining significant gains with respect to the fine tuning baseline.
Preserve, Promote, or Attack? GNN Explanation via Topology Perturbation
Mar 25, 2021
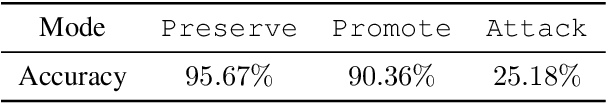

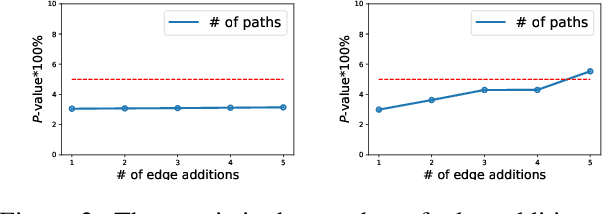
Prior works on formalizing explanations of a graph neural network (GNN) focus on a single use case - to preserve the prediction results through identifying important edges and nodes. In this paper, we develop a multi-purpose interpretation framework by acquiring a mask that indicates topology perturbations of the input graphs. We pack the framework into an interactive visualization system (GNNViz) which can fulfill multiple purposes: Preserve,Promote, or Attack GNN's predictions. We illustrate our approach's novelty and effectiveness with three case studies: First, GNNViz can assist non expert users to easily explore the relationship between graph topology and GNN's decision (Preserve), or to manipulate the prediction (Promote or Attack) for an image classification task on MS-COCO; Second, on the Pokec social network dataset, our framework can uncover unfairness and demographic biases; Lastly, it compares with state-of-the-art GNN explainer baseline on a synthetic dataset.
Regularization by Denoising Sub-sampled Newton Method for Spectral CT Multi-Material Decomposition
Mar 25, 2021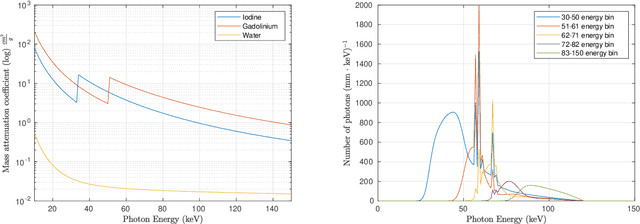
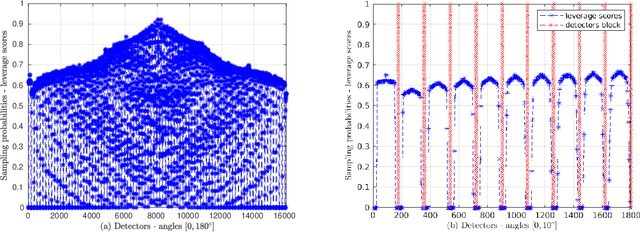

Spectral Computed Tomography (CT) is an emerging technology that enables to estimate the concentration of basis materials within a scanned object by exploiting different photon energy spectra. In this work, we aim at efficiently solving a model-based maximum-a-posterior problem to reconstruct multi-materials images with application to spectral CT. In particular, we propose to solve a regularized optimization problem based on a plug-in image-denoising function using a randomized second order method. By approximating the Newton step using a sketching of the Hessian of the likelihood function, it is possible to reduce the complexity while retaining the complex prior structure given by the data-driven regularizer. We exploit a non-uniform block sub-sampling of the Hessian with inexact but efficient Conjugate gradient updates that require only Jacobian-vector products for denoising term. Finally, we show numerical and experimental results for spectral CT materials decomposition.
Deep learning using Havrda-Charvat entropy for classification of pulmonary endomicroscopy
Apr 19, 2021
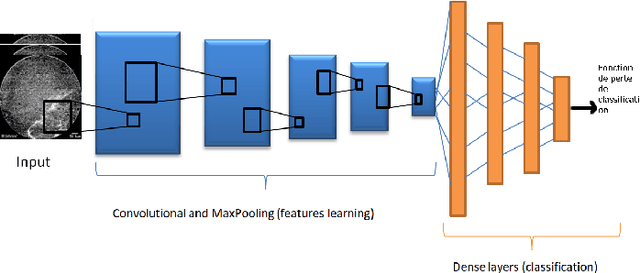
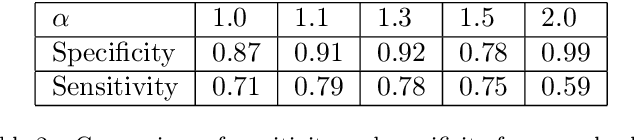
Pulmonary optical endomicroscopy (POE) is an imaging technology in real time. It allows to examine pulmonary alveoli at a microscopic level. Acquired in clinical settings, a POE image sequence can have as much as 25% of the sequence being uninformative frames (i.e. pure-noise and motion artefacts). For future data analysis, these uninformative frames must be first removed from the sequence. Therefore, the objective of our work is to develop an automatic detection method of uninformative images in endomicroscopy images. We propose to take the detection problem as a classification one. Considering advantages of deep learning methods, a classifier based on CNN (Convolutional Neural Network) is designed with a new loss function based on Havrda-Charvat entropy which is a parametrical generalization of the Shannon entropy. We propose to use this formula to get a better hold on all sorts of data since it provides a model more stable than the Shannon entropy. Our method is tested on one POE dataset including 2947 distinct images, is showing better results than using Shannon entropy and behaves better with regard to the problem of overfitting. Keywords: Deep Learning, CNN, Shannon entropy, Havrda-Charvat entropy, Pulmonary optical endomicroscopy.
A Simple Baseline for Semi-supervised Semantic Segmentation with Strong Data Augmentation
Apr 19, 2021

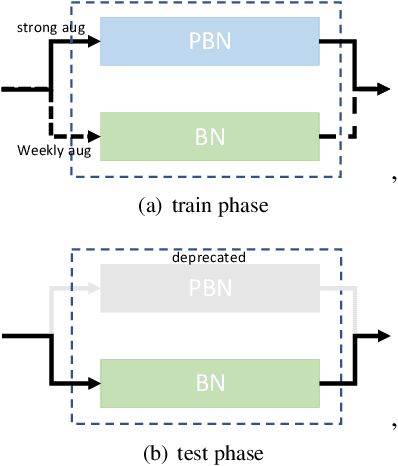

Recently, significant progress has been made on semantic segmentation. However, the success of supervised semantic segmentation typically relies on a large amount of labelled data, which is time-consuming and costly to obtain. Inspired by the success of semi-supervised learning methods in image classification, here we propose a simple yet effective semi-supervised learning framework for semantic segmentation. We demonstrate that the devil is in the details: a set of simple design and training techniques can collectively improve the performance of semi-supervised semantic segmentation significantly. Previous works [3, 27] fail to employ strong augmentation in pseudo label learning efficiently, as the large distribution change caused by strong augmentation harms the batch normalisation statistics. We design a new batch normalisation, namely distribution-specific batch normalisation (DSBN) to address this problem and demonstrate the importance of strong augmentation for semantic segmentation. Moreover, we design a self correction loss which is effective in noise resistance. We conduct a series of ablation studies to show the effectiveness of each component. Our method achieves state-of-the-art results in the semi-supervised settings on the Cityscapes and Pascal VOC datasets.
GAN based ball screw drive picture database enlargement for failure classification
Nov 20, 2020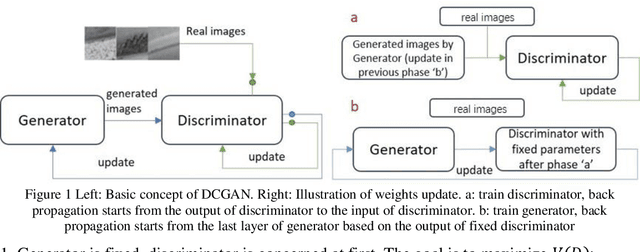
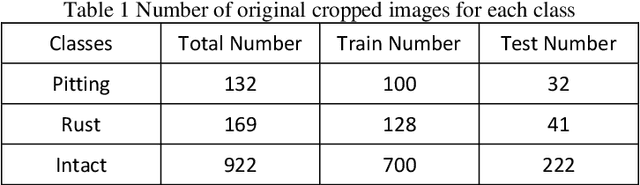
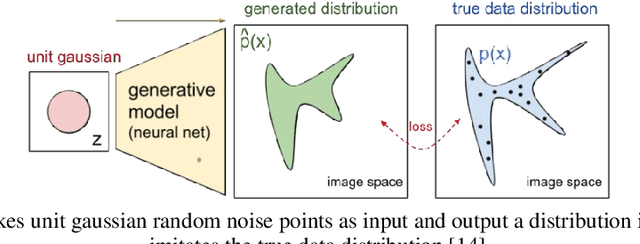
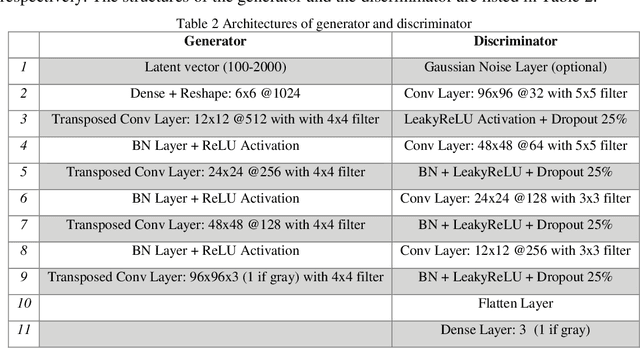
The lack of reliable large datasets is one of the biggest difficulties of using modern machine learning methods in the field of failure detection in the manufacturing industry. In order to develop the function of failure classification for ball screw surface, sufficient image data of surface failures is necessary. When training a neural network model based on a small dataset, the trained model may lack the generalization ability and may perform poorly in practice. The main goal of this paper is to generate synthetic images based on the generative adversarial network (GAN) to enlarge the image dataset of ball screw surface failures. Pitting failure and rust failure are two possible failure types on ball screw surface chosen in this paper to represent the surface failure classes. The quality and diversity of generated images are evaluated afterwards using qualitative methods including expert observation, t-SNE visualization and the quantitative method of FID score. To verify whether the GAN based generated images can increase failure classification performance, the real image dataset was augmented and replaced by GAN based generated images to do the classification task. The authors successfully created GAN based images of ball screw surface failures which showed positive effect on classification test performance.
Unveiling personnel movement in a larger indoor area with a non-overlapping multi-camera system
Apr 10, 2021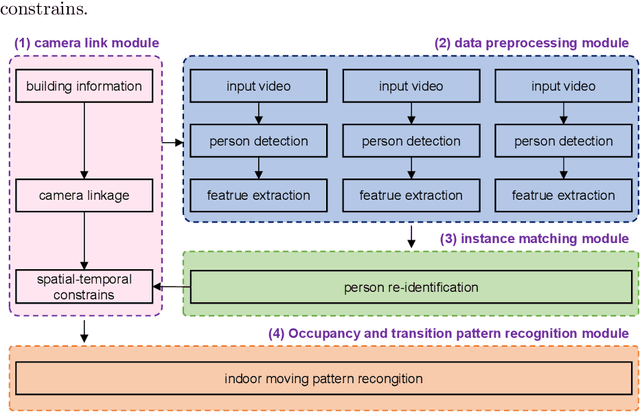
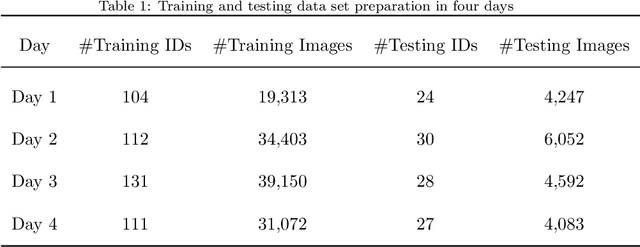
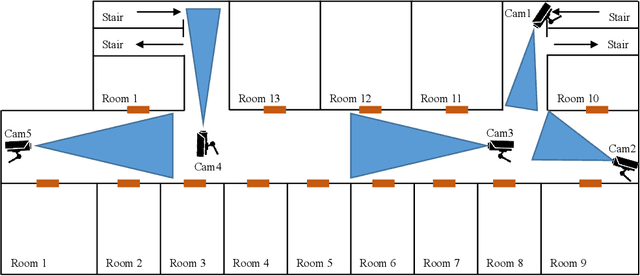

Surveillance cameras are widely applied for indoor occupancy measurement and human movement perception, which benefit for building energy management and social security. To address the challenges of limited view angle of single camera as well as lacking of inter-camera collaboration, this study presents a non-overlapping multi-camera system to enlarge the surveillance area and devotes to retrieve the same person appeared from different camera views. The system is deployed in an office building and four-day videos are collected. By training a deep convolutional neural network, the proposed system first extracts the appearance feature embeddings of each personal image, which detected from different cameras, for similarity comparison. Then, a stochastic inter-camera transition matrix is associated with appearance feature for further improving the person re-identification ranking results. Finally, a noise-suppression explanation is given for analyzing the matching improvements. This paper expands the scope of indoor movement perception based on non-overlapping multiple cameras and improves the accuracy of pedestrian re-identification without introducing additional types of sensors.
Shapes and Context: In-the-Wild Image Synthesis & Manipulation
Jun 11, 2019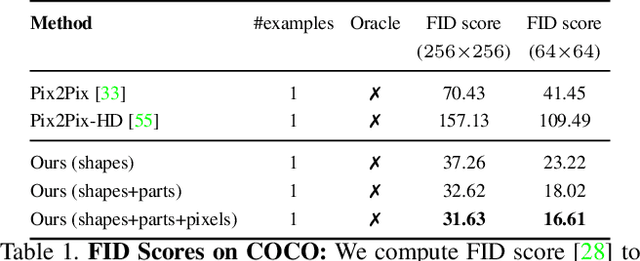

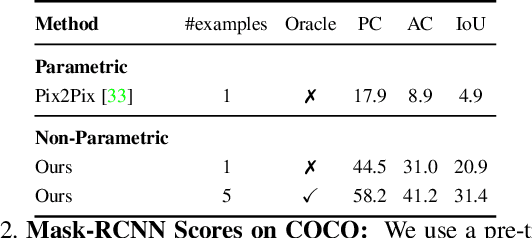
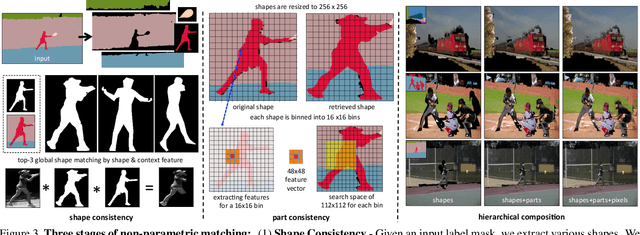
We introduce a data-driven approach for interactively synthesizing in-the-wild images from semantic label maps. Our approach is dramatically different from recent work in this space, in that we make use of no learning. Instead, our approach uses simple but classic tools for matching scene context, shapes, and parts to a stored library of exemplars. Though simple, this approach has several notable advantages over recent work: (1) because nothing is learned, it is not limited to specific training data distributions (such as cityscapes, facades, or faces); (2) it can synthesize arbitrarily high-resolution images, limited only by the resolution of the exemplar library; (3) by appropriately composing shapes and parts, it can generate an exponentially large set of viable candidate output images (that can say, be interactively searched by a user). We present results on the diverse COCO dataset, significantly outperforming learning-based approaches on standard image synthesis metrics. Finally, we explore user-interaction and user-controllability, demonstrating that our system can be used as a platform for user-driven content creation.
* Project Page: http://www.cs.cmu.edu/~aayushb/OpenShapes/