 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Invariant Attribute Profiles: A Spatial-Frequency Joint Feature Extractor for Hyperspectral Image Classification
Dec 18, 2019
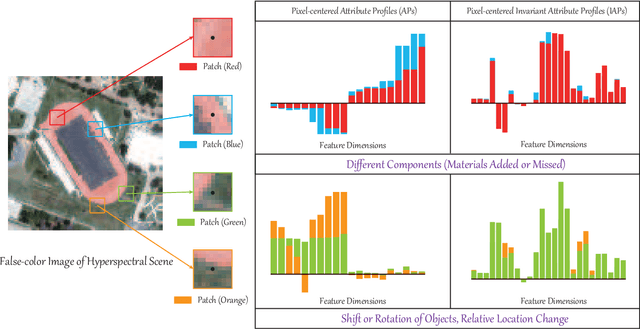

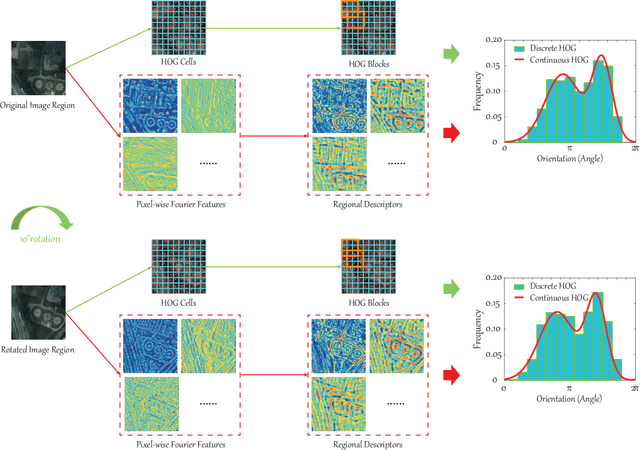
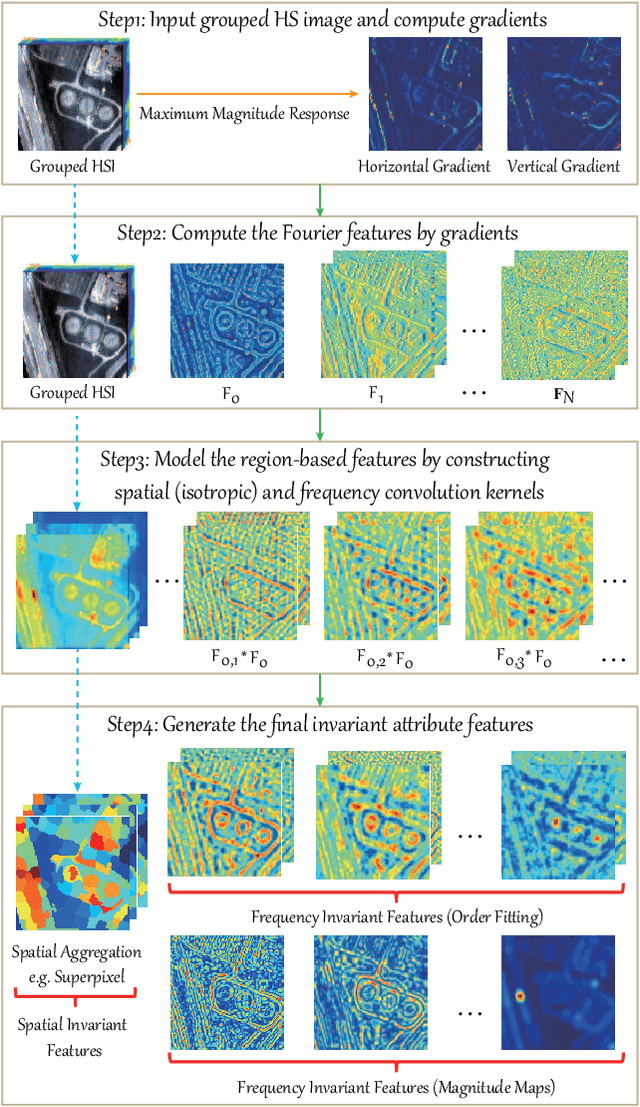
Up to the present, an enormous number of advanced techniques have been developed to enhance and extract the spatially semantic information in hyperspectral image processing and analysis. However, locally semantic change, such as scene composition, relative position between objects, spectral variability caused by illumination, atmospheric effects, and material mixture, has been less frequently investigated in modeling spatial information. As a consequence, identifying the same materials from spatially different scenes or positions can be difficult. In this paper, we propose a solution to address this issue by locally extracting invariant features from hyperspectral imagery (HSI) in both spatial and frequency domains, using a method called invariant attribute profiles (IAPs). IAPs extract the spatial invariant features by exploiting isotropic filter banks or convolutional kernels on HSI and spatial aggregation techniques (e.g., superpixel segmentation) in the Cartesian coordinate system. Furthermore, they model invariant behaviors (e.g., shift, rotation) by the means of a continuous histogram of oriented gradients constructed in a Fourier polar coordinate. This yields a combinatorial representation of spatial-frequency invariant features with application to HSI classification. Extensive experiments conducted on three promising hyperspectral datasets (Houston2013 and Houston2018) demonstrate the superiority and effectiveness of the proposed IAP method in comparison with several state-of-the-art profile-related techniques. The codes will be available from the website: https://sites.google.com/view/danfeng-hong/data-code.
Deep Parallel MRI Reconstruction Network Without Coil Sensitivities
Aug 04, 2020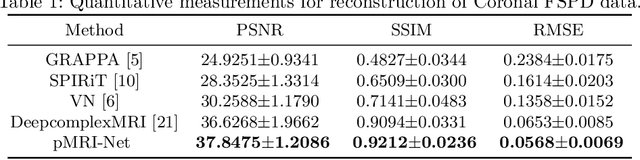
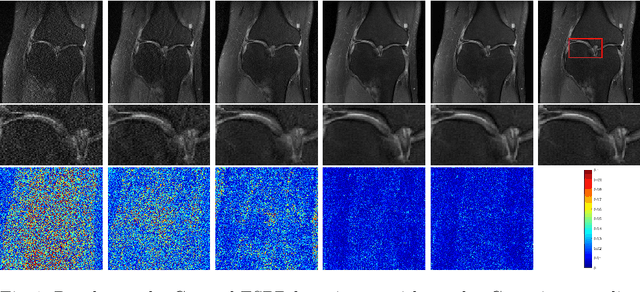
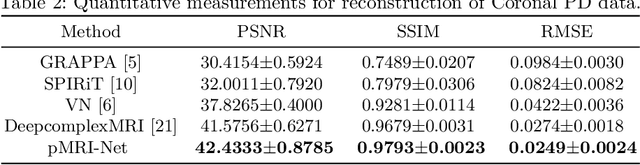
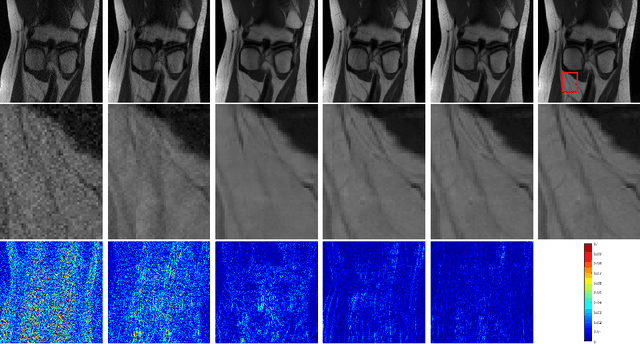
We propose a novel deep neural network architecture by mapping the robust proximal gradient scheme for fast image reconstruction in parallel MRI (pMRI) with regularization function trained from data. The proposed network learns to adaptively combine the multi-coil images from incomplete pMRI data into a single image with uniform contrast, which is then passed to a nonlinear encoder to efficiently extract sparse features of the image. Unlike most of existing deep image reconstruction networks, our network does not require knowledge of sensitivity maps, which are notoriously difficult to estimate and have been a major bottleneck of image reconstruction in real-world pMRI applications. The experimental results demonstrate the promising performance of our method on a variety of pMRI imaging data sets.
Geography-Aware Self-Supervised Learning
Dec 02, 2020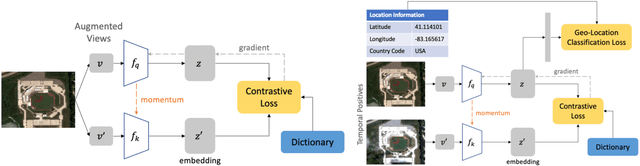
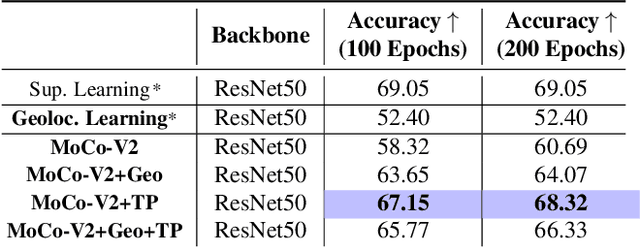

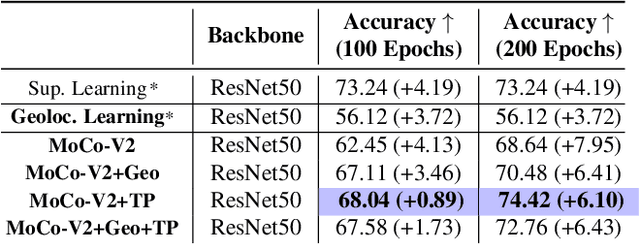
Contrastive learning methods have significantly narrowed the gap between supervised and unsupervised learning on computer vision tasks. In this paper, we explore their application to remote sensing, where unlabeled data is often abundant but labeled data is scarce. We first show that due to their different characteristics, a non-trivial gap persists between contrastive and supervised learning on standard benchmarks. To close the gap, we propose novel training methods that exploit the spatiotemporal structure of remote sensing data. We leverage spatially aligned images over time to construct temporal positive pairs in contrastive learning and geo-location to design pre-text tasks. Our experiments show that our proposed method closes the gap between contrastive and supervised learning on image classification, object detection and semantic segmentation for remote sensing and other geo-tagged image datasets.
Distribution Alignment: A Unified Framework for Long-tail Visual Recognition
Mar 30, 2021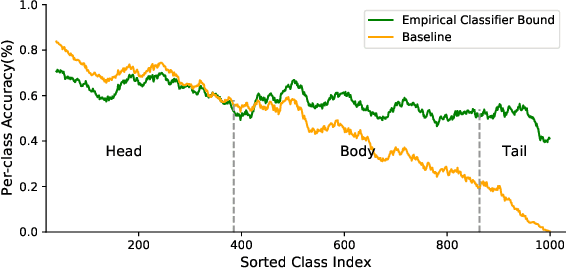
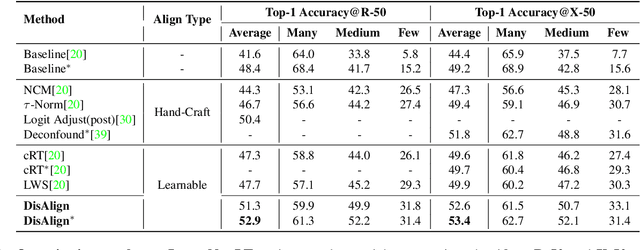
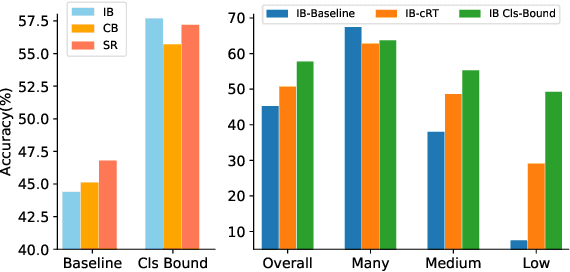
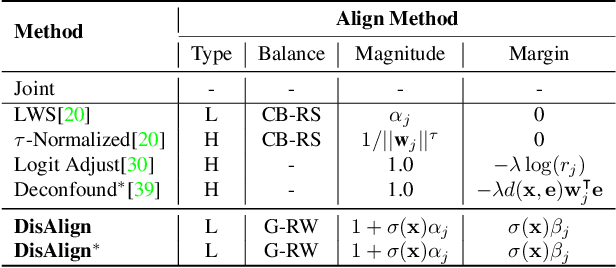
Despite the recent success of deep neural networks, it remains challenging to effectively model the long-tail class distribution in visual recognition tasks. To address this problem, we first investigate the performance bottleneck of the two-stage learning framework via ablative study. Motivated by our discovery, we propose a unified distribution alignment strategy for long-tail visual recognition. Specifically, we develop an adaptive calibration function that enables us to adjust the classification scores for each data point. We then introduce a generalized re-weight method in the two-stage learning to balance the class prior, which provides a flexible and unified solution to diverse scenarios in visual recognition tasks. We validate our method by extensive experiments on four tasks, including image classification, semantic segmentation, object detection, and instance segmentation. Our approach achieves the state-of-the-art results across all four recognition tasks with a simple and unified framework. The code and models will be made publicly available at: https://github.com/Megvii-BaseDetection/DisAlign
Using StyleGAN for Visual Interpretability of Deep Learning Models on Medical Images
Jan 19, 2021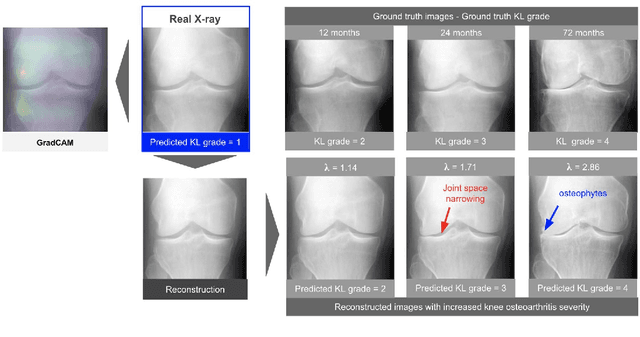
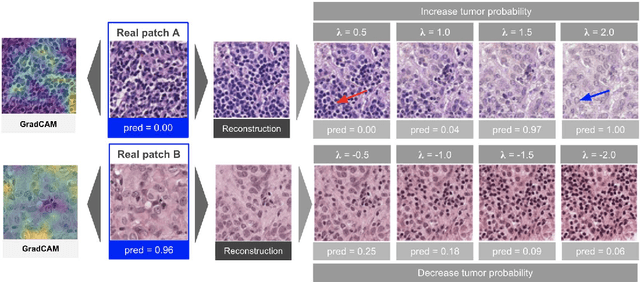
As AI-based medical devices are becoming more common in imaging fields like radiology and histology, interpretability of the underlying predictive models is crucial to expand their use in clinical practice. Existing heatmap-based interpretability methods such as GradCAM only highlight the location of predictive features but do not explain how they contribute to the prediction. In this paper, we propose a new interpretability method that can be used to understand the predictions of any black-box model on images, by showing how the input image would be modified in order to produce different predictions. A StyleGAN is trained on medical images to provide a mapping between latent vectors and images. Our method identifies the optimal direction in the latent space to create a change in the model prediction. By shifting the latent representation of an input image along this direction, we can produce a series of new synthetic images with changed predictions. We validate our approach on histology and radiology images, and demonstrate its ability to provide meaningful explanations that are more informative than GradCAM heatmaps. Our method reveals the patterns learned by the model, which allows clinicians to build trust in the model's predictions, discover new biomarkers and eventually reveal potential biases.
A Two-branch Neural Network for Non-homogeneous Dehazing via Ensemble Learning
Apr 18, 2021
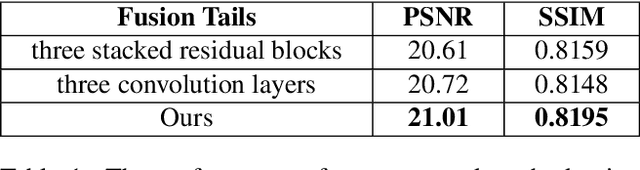
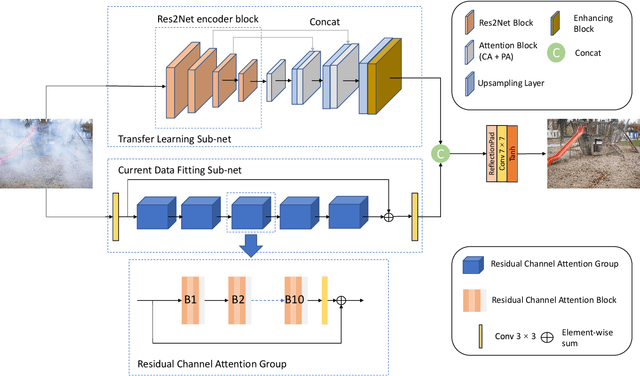
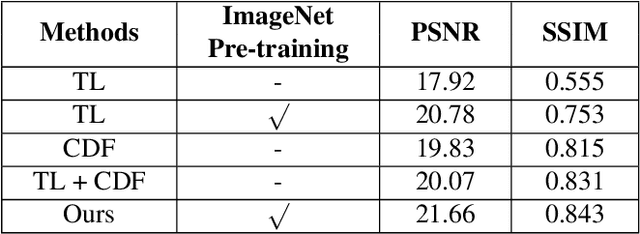
Recently, there has been rapid and significant progress on image dehazing. Many deep learning based methods have shown their superb performance in handling homogeneous dehazing problems. However, we observe that even if a carefully designed convolutional neural network (CNN) can perform well on large-scaled dehazing benchmarks, the network usually fails on the non-homogeneous dehazing datasets introduced by NTIRE challenges. The reasons are mainly in two folds. Firstly, due to its non-homogeneous nature, the non-uniformly distributed haze is harder to be removed than the homogeneous haze. Secondly, the research challenge only provides limited data (there are only 25 training pairs in NH-Haze 2021 dataset). Thus, learning the mapping from the domain of hazy images to that of clear ones based on very limited data is extremely hard. To this end, we propose a simple but effective approach for non-homogeneous dehazing via ensemble learning. To be specific, we introduce a two-branch neural network to separately deal with the aforementioned problems and then map their distinct features by a learnable fusion tail. We show extensive experimental results to illustrate the effectiveness of our proposed method.
Improving Description-based Person Re-identification by Multi-granularity Image-text Alignments
Jun 23, 2019

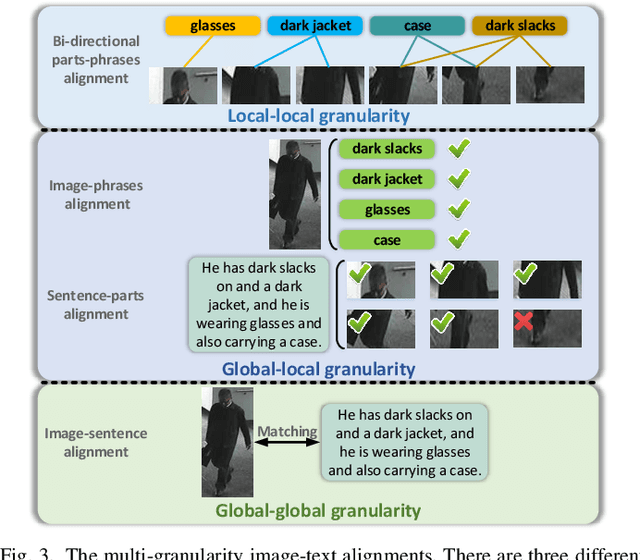
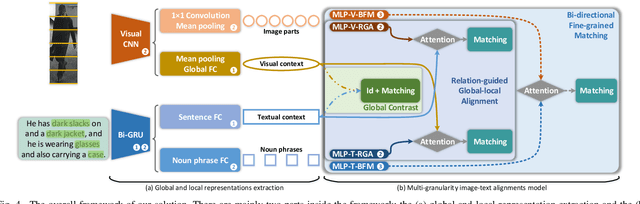
Description-based person re-identification (Re-id) is an important task in video surveillance that requires discriminative cross-modal representations to distinguish different people. It is difficult to directly measure the similarity between images and descriptions due to the modality heterogeneity (the cross-modal problem). And all samples belonging to a single category (the fine-grained problem) makes this task even harder than the conventional image-description matching task. In this paper, we propose a Multi-granularity Image-text Alignments (MIA) model to alleviate the cross-modal fine-grained problem for better similarity evaluation in description-based person Re-id. Specifically, three different granularities, i.e., global-global, global-local and local-local alignments are carried out hierarchically. Firstly, the global-global alignment in the Global Contrast (GC) module is for matching the global contexts of images and descriptions. Secondly, the global-local alignment employs the potential relations between local components and global contexts to highlight the distinguishable components while eliminating the uninvolved ones adaptively in the Relation-guided Global-local Alignment (RGA) module. Thirdly, as for the local-local alignment, we match visual human parts with noun phrases in the Bi-directional Fine-grained Matching (BFM) module. The whole network combining multiple granularities can be end-to-end trained without complex pre-processing. To address the difficulties in training the combination of multiple granularities, an effective step training strategy is proposed to train these granularities step-by-step. Extensive experiments and analysis have shown that our method obtains the state-of-the-art performance on the CUHK-PEDES dataset and outperforms the previous methods by a significant margin.
Let's See Clearly: Contaminant Artifact Removal for Moving Cameras
Apr 18, 2021
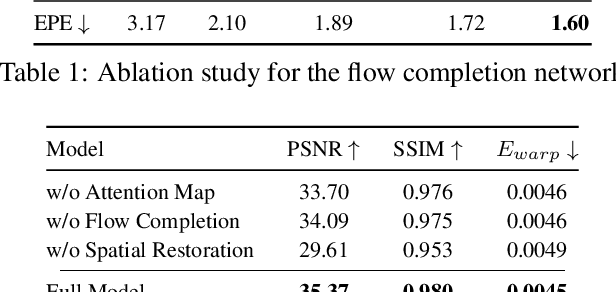
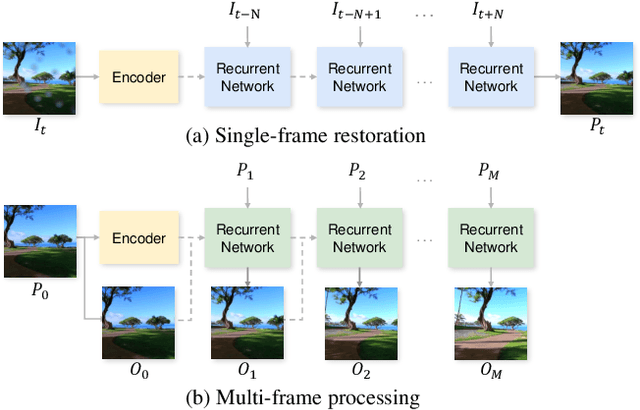

Contaminants such as dust, dirt and moisture adhering to the camera lens can greatly affect the quality and clarity of the resulting image or video. In this paper, we propose a video restoration method to automatically remove these contaminants and produce a clean video. Our approach first seeks to detect attention maps that indicate the regions that need to be restored. In order to leverage the corresponding clean pixels from adjacent frames, we propose a flow completion module to hallucinate the flow of the background scene to the attention regions degraded by the contaminants. Guided by the attention maps and completed flows, we propose a recurrent technique to restore the input frame by fetching clean pixels from adjacent frames. Finally, a multi-frame processing stage is used to further process the entire video sequence in order to enforce temporal consistency. The entire network is trained on a synthetic dataset that approximates the physical lighting properties of contaminant artifacts. This new dataset and our novel framework lead to our method that is able to address different contaminants and outperforms competitive restoration approaches both qualitatively and quantitatively.
Self-Supervised Pretraining Improves Self-Supervised Pretraining
Mar 25, 2021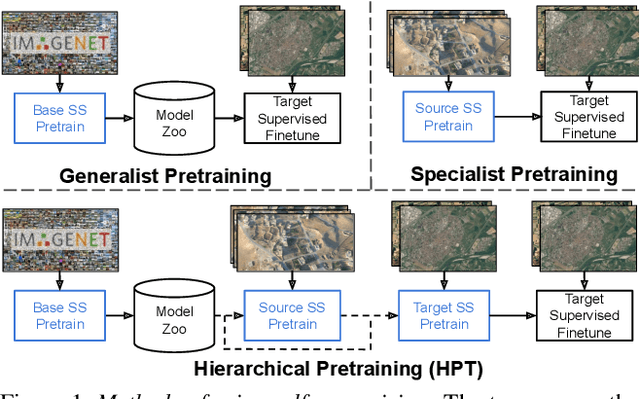
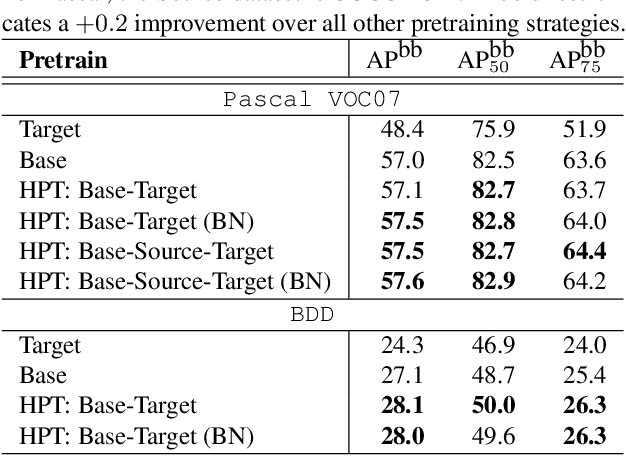
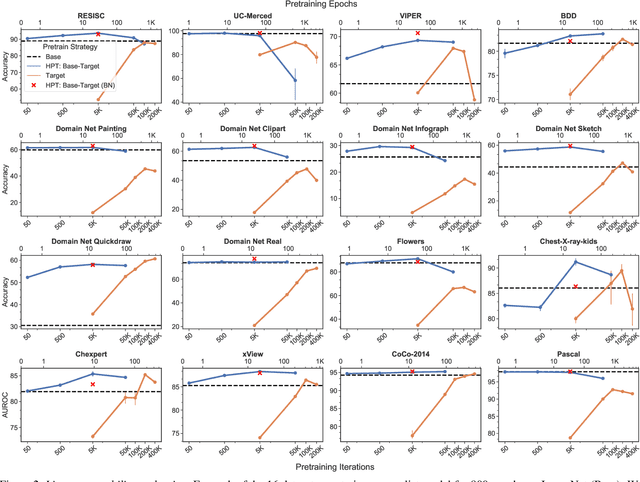
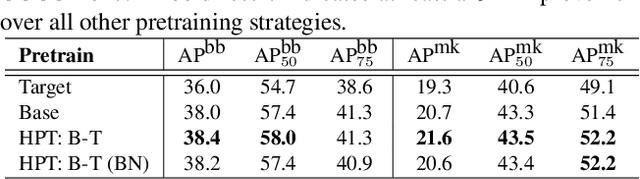
While self-supervised pretraining has proven beneficial for many computer vision tasks, it requires expensive and lengthy computation, large amounts of data, and is sensitive to data augmentation. Prior work demonstrates that models pretrained on datasets dissimilar to their target data, such as chest X-ray models trained on ImageNet, underperform models trained from scratch. Users that lack the resources to pretrain must use existing models with lower performance. This paper explores Hierarchical PreTraining (HPT), which decreases convergence time and improves accuracy by initializing the pretraining process with an existing pretrained model. Through experimentation on 16 diverse vision datasets, we show HPT converges up to 80x faster, improves accuracy across tasks, and improves the robustness of the self-supervised pretraining process to changes in the image augmentation policy or amount of pretraining data. Taken together, HPT provides a simple framework for obtaining better pretrained representations with less computational resources.
Generative Damage Learning for Concrete Aging Detection using Auto-flight Images
Jun 27, 2020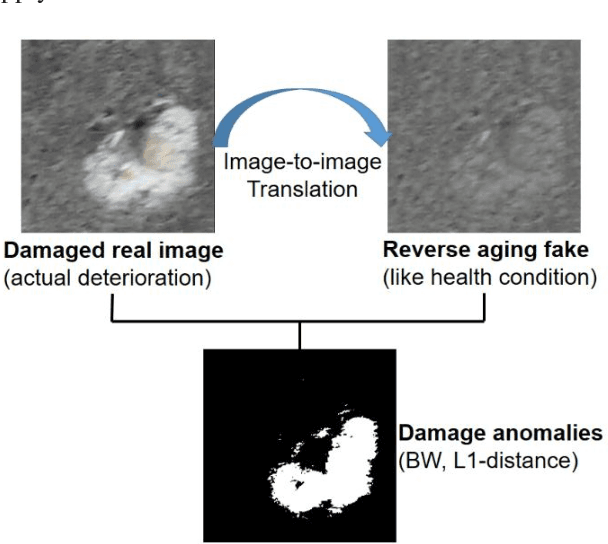

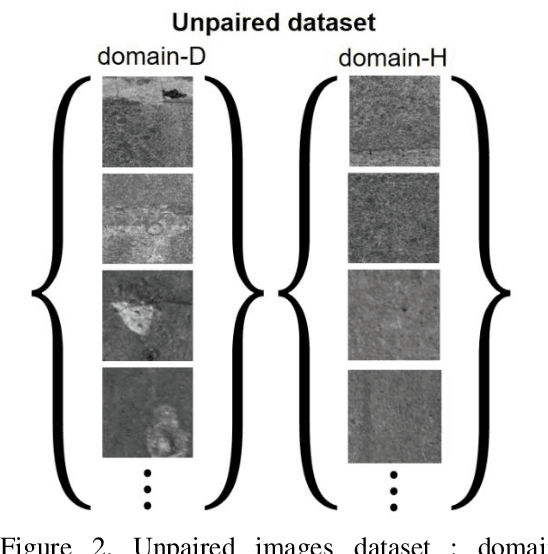
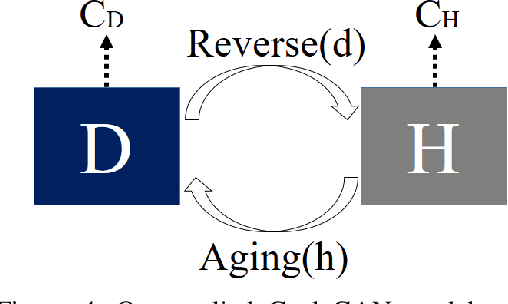
In order to health monitoring the state of large scale infrastructures, image acquisition by autonomous flight drone is efficient for stable angle and high quality image. Supervised learning requires a great deal of data set consisting images and annotation labels. It takes long time to accumulate images including damaged region of interest (ROI). In recent years, unsupervised deep learning approach such as generative adversarial network (GAN) for anomaly detection algorithms have progressed. When a damaged image is a generator input, it tends to reverse from the damaged state to the health-like state image. Using the distance of distribution between the real damaged image and the generated reverse aging health-like image, it is possible to detect the concrete damage automatically from unsupervised learning. This paper proposes an anomaly detection method using unpaired image-to-image translation mapping from damaged image to reverse aging fake like health condition. Actually, we apply our method to field studies, and we examine the usefulness for health monitoring concrete damages.