 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Multi-Stage Fusion for One-Click Segmentation
Oct 19, 2020

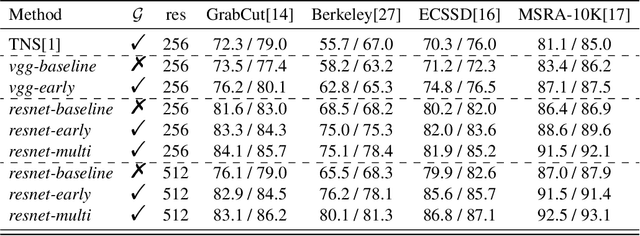
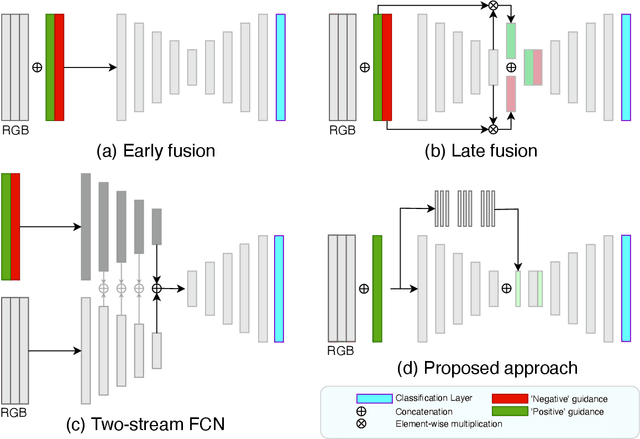
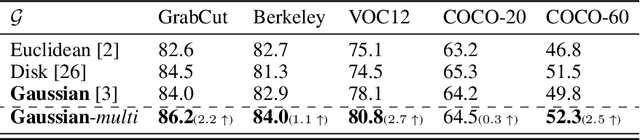
Segmenting objects of interest in an image is an essential building block of applications such as photo-editing and image analysis. Under interactive settings, one should achieve good segmentations while minimizing user input. Current deep learning-based interactive segmentation approaches use early fusion and incorporate user cues at the image input layer. Since segmentation CNNs have many layers, early fusion may weaken the influence of user interactions on the final prediction results. As such, we propose a new multi-stage guidance framework for interactive segmentation. By incorporating user cues at different stages of the network, we allow user interactions to impact the final segmentation output in a more direct way. Our proposed framework has a negligible increase in parameter count compared to early-fusion frameworks. We perform extensive experimentation on the standard interactive instance segmentation and one-click segmentation benchmarks and report state-of-the-art performance.
Shadow Neural Radiance Fields for Multi-view Satellite Photogrammetry
Apr 20, 2021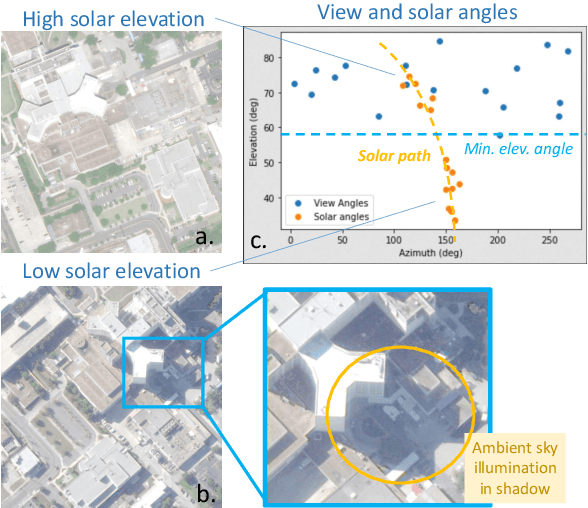
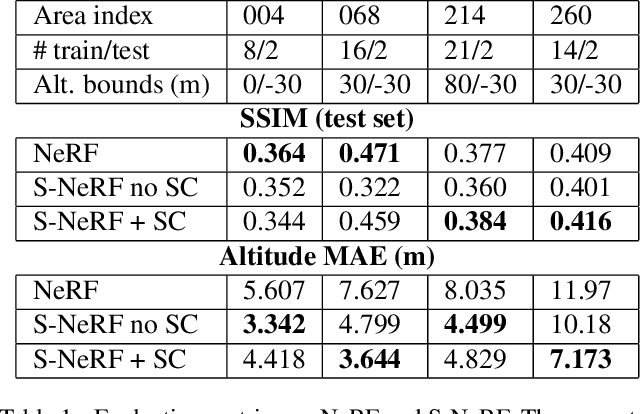
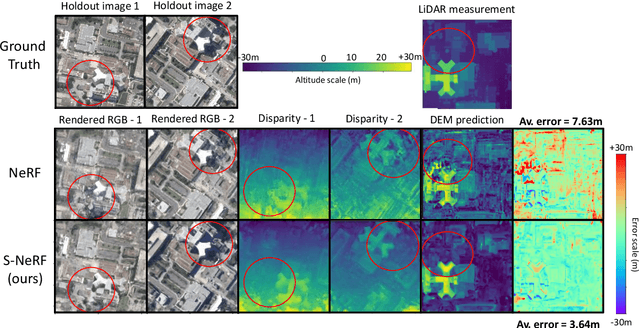

We present a new generic method for shadow-aware multi-view satellite photogrammetry of Earth Observation scenes. Our proposed method, the Shadow Neural Radiance Field (S-NeRF) follows recent advances in implicit volumetric representation learning. For each scene, we train S-NeRF using very high spatial resolution optical images taken from known viewing angles. The learning requires no labels or shape priors: it is self-supervised by an image reconstruction loss. To accommodate for changing light source conditions both from a directional light source (the Sun) and a diffuse light source (the sky), we extend the NeRF approach in two ways. First, direct illumination from the Sun is modeled via a local light source visibility field. Second, indirect illumination from a diffuse light source is learned as a non-local color field as a function of the position of the Sun. Quantitatively, the combination of these factors reduces the altitude and color errors in shaded areas, compared to NeRF. The S-NeRF methodology not only performs novel view synthesis and full 3D shape estimation, it also enables shadow detection, albedo synthesis, and transient object filtering, without any explicit shape supervision.
Are Deep Neural Architectures Losing Information? Invertibility Is Indispensable
Sep 07, 2020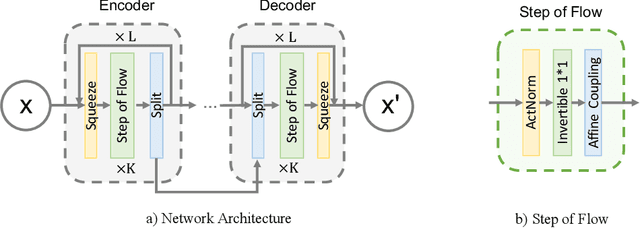
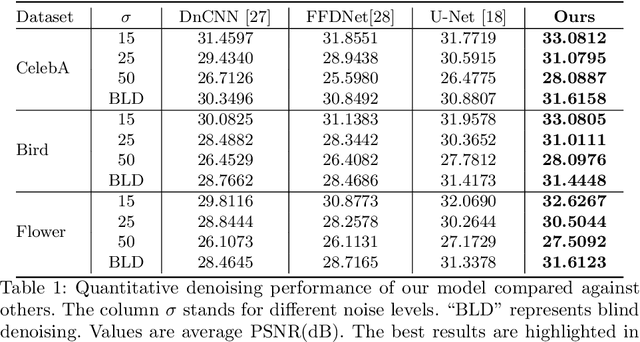

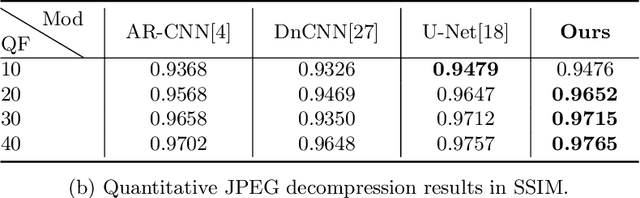
Ever since the advent of AlexNet, designing novel deep neural architectures for different tasks has consistently been a productive research direction. Despite the exceptional performance of various architectures in practice, we study a theoretical question: what is the condition for deep neural architectures to preserve all the information of the input data? Identifying the information lossless condition for deep neural architectures is important, because tasks such as image restoration require keep the detailed information of the input data as much as possible. Using the definition of mutual information, we show that: a deep neural architecture can preserve maximum details about the given data if and only if the architecture is invertible. We verify the advantages of our Invertible Restoring Autoencoder (IRAE) network by comparing it with competitive models on three perturbed image restoration tasks: image denoising, jpeg image decompression and image inpainting. Experimental results show that IRAE consistently outperforms non-invertible ones. Our model even contains far fewer parameters. Thus, it may be worthwhile to try replacing standard components of deep neural architectures, such as residual blocks and ReLU, with their invertible counterparts. We believe our work provides a unique perspective and direction for future deep learning research.
Synthesizing a 4D Spatio-Angular Consistent Light Field from a Single Image
Mar 29, 2019
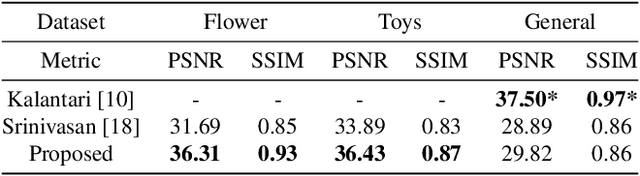
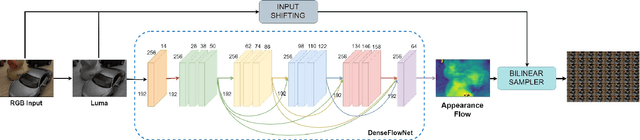
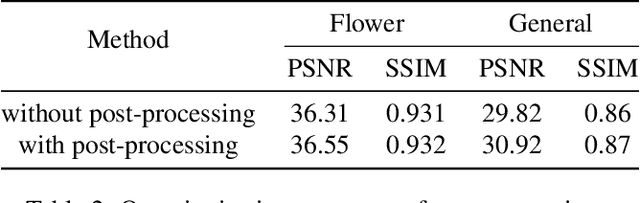
Synthesizing a densely sampled light field from a single image is highly beneficial for many applications. The conventional method reconstructs a depth map and relies on physical-based rendering and a secondary network to improve the synthesized novel views. Simple pixel-based loss also limits the network by making it rely on pixel intensity cue rather than geometric reasoning. In this study, we show that a different geometric representation, namely, appearance flow, can be used to synthesize a light field from a single image robustly and directly. A single end-to-end deep neural network that does not require a physical-based approach nor a post-processing subnetwork is proposed. Two novel loss functions based on known light field domain knowledge are presented to enable the network to preserve the spatio-angular consistency between sub-aperture images effectively. Experimental results show that the proposed model successfully synthesizes dense light fields and qualitatively and quantitatively outperforms the previous model . The method can be generalized to arbitrary scenes, rather than focusing on a particular class of object. The synthesized light field can be used for various applications, such as depth estimation and refocusing.
Coloring with Words: Guiding Image Colorization Through Text-based Palette Generation
Aug 07, 2018
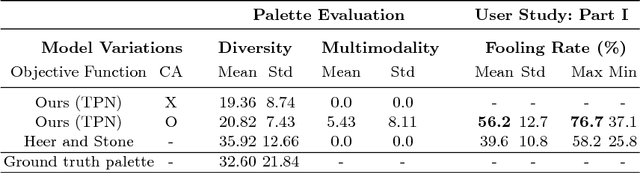


This paper proposes a novel approach to generate multiple color palettes that reflect the semantics of input text and then colorize a given grayscale image according to the generated color palette. In contrast to existing approaches, our model can understand rich text, whether it is a single word, a phrase, or a sentence, and generate multiple possible palettes from it. For this task, we introduce our manually curated dataset called Palette-and-Text (PAT). Our proposed model called Text2Colors consists of two conditional generative adversarial networks: the text-to-palette generation networks and the palette-based colorization networks. The former captures the semantics of the text input and produce relevant color palettes. The latter colorizes a grayscale image using the generated color palette. Our evaluation results show that people preferred our generated palettes over ground truth palettes and that our model can effectively reflect the given palette when colorizing an image.
* 25 pages, 22 figures
Deep Learning for Low-Field to High-Field MR: Image Quality Transfer with Probabilistic Decimation Simulator
Sep 15, 2019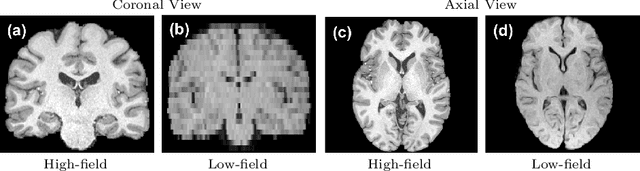
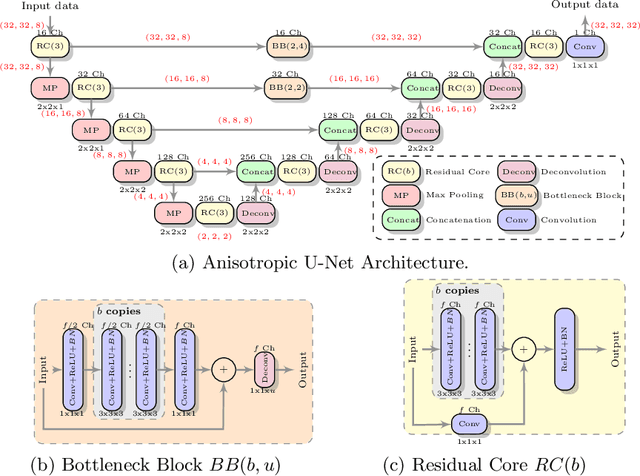
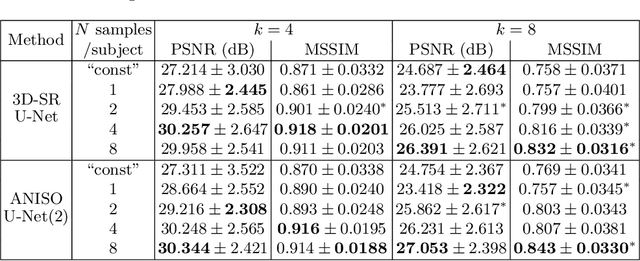
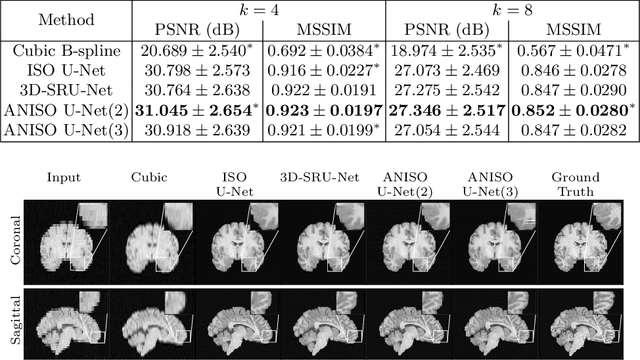
MR images scanned at low magnetic field ($<1$T) have lower resolution in the slice direction and lower contrast, due to a relatively small signal-to-noise ratio (SNR) than those from high field (typically 1.5T and 3T). We adapt the recent idea of Image Quality Transfer (IQT) to enhance very low-field structural images aiming to estimate the resolution, spatial coverage, and contrast of high-field images. Analogous to many learning-based image enhancement techniques, IQT generates training data from high-field scans alone by simulating low-field images through a pre-defined decimation model. However, the ground truth decimation model is not well-known in practice, and lack of its specification can bias the trained model, aggravating performance on the real low-field scans. In this paper we propose a probabilistic decimation simulator to improve robustness of model training. It is used to generate and augment various low-field images whose parameters are random variables and sampled from an empirical distribution related to tissue-specific SNR on a 0.36T scanner. The probabilistic decimation simulator is model-agnostic, that is, it can be used with any super-resolution networks. Furthermore we propose a variant of U-Net architecture to improve its learning performance. We show promising qualitative results from clinical low-field images confirming the strong efficacy of IQT in an important new application area: epilepsy diagnosis in sub-Saharan Africa where only low-field scanners are normally available.
Adversarial Learning for Image Forensics Deep Matching with Atrous Convolution
Sep 08, 2018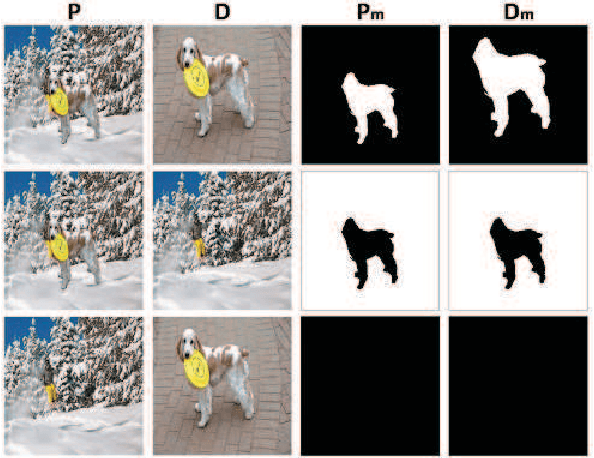
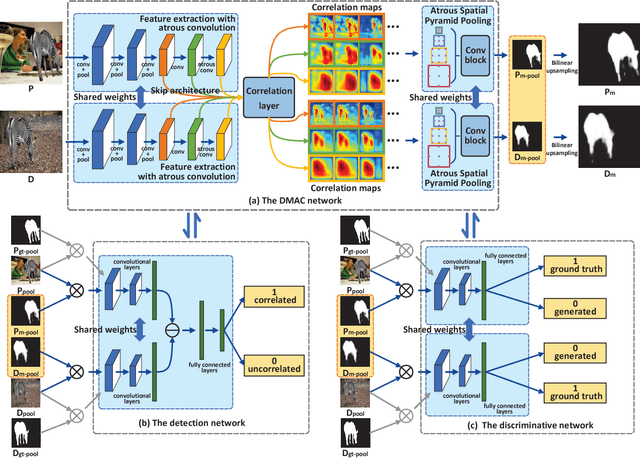
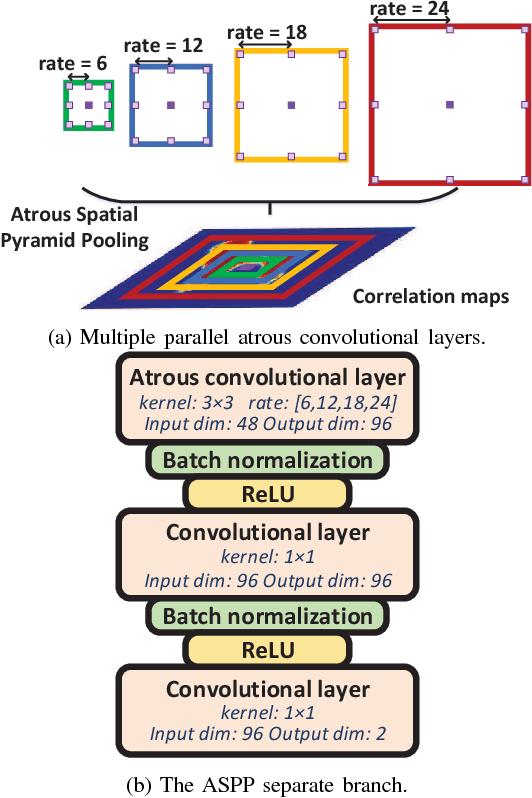
Constrained image splicing detection and localization (CISDL) is a newly proposed challenging task for image forensics, which investigates two input suspected images and identifies whether one image has suspected regions pasted from the other. In this paper, we propose a novel adversarial learning framework to train the deep matching network for CISDL. Our framework mainly consists of three building blocks: 1) the deep matching network based on atrous convolution (DMAC) aims to generate two high-quality candidate masks which indicate the suspected regions of the two input images, 2) the detection network is designed to rectify inconsistencies between the two corresponding candidate masks, 3) the discriminative network drives the DMAC network to produce masks that are hard to distinguish from ground-truth ones. In DMAC, atrous convolution is adopted to extract features with rich spatial information, the correlation layer based on the skip architecture is proposed to capture hierarchical features, and atrous spatial pyramid pooling is constructed to localize tampered regions at multiple scales. The detection network and the discriminative network act as the losses with auxiliary parameters to supervise the training of DMAC in an adversarial way. Extensive experiments, conducted on 21 generated testing sets and two public datasets, demonstrate the effectiveness of the proposed framework and the superior performance of DMAC.
Deep Learning-based Face Super-resolution: A Survey
Jan 11, 2021
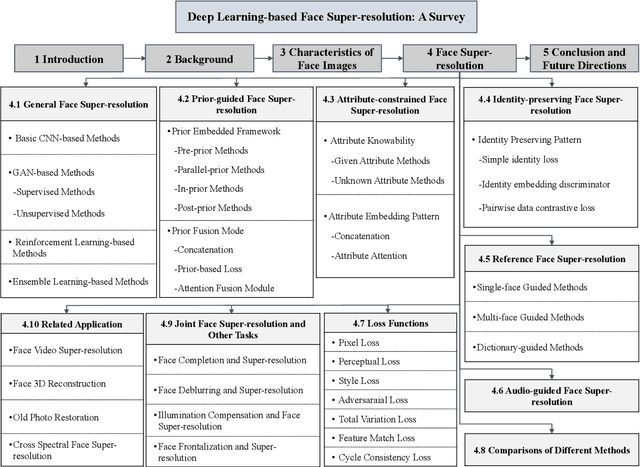

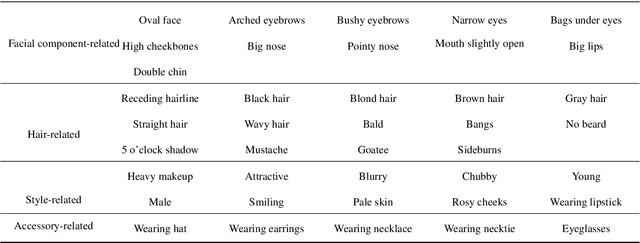
Face super-resolution, also known as face hallucination, which is aimed at enhancing the resolution of low-resolution (LR) one or a sequence of face images to generate the corresponding high-resolution (HR) face images, is a domain-specific image super-resolution problem. Recently, face super-resolution has received considerable attention, and witnessed dazzling advances with deep learning techniques. To date, few summaries of the studies on the deep learning-based face super-resolution are available. In this survey, we present a comprehensive review of deep learning techniques in face super-resolution in a systematic manner. First, we summarize the problem formulation of face super-resolution. Second, we compare the differences between generic image super-resolution and face super-resolution. Third, datasets and performance metrics commonly used in facial hallucination are presented. Fourth, we roughly categorize existing methods according to the utilization of face-specific information. In each category, we start with a general description of design principles, present an overview of representative approaches, and compare the similarities and differences among various methods. Finally, we envision prospects for further technical advancement in this field.
Unsupervised Person Re-identification via Simultaneous Clustering and Consistency Learning
Apr 01, 2021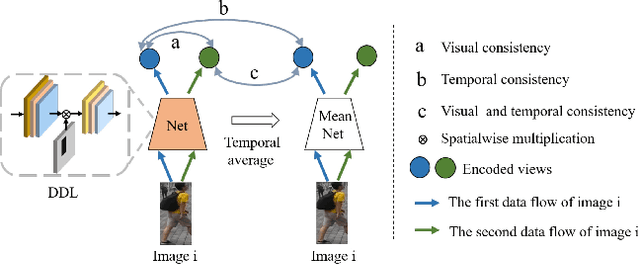
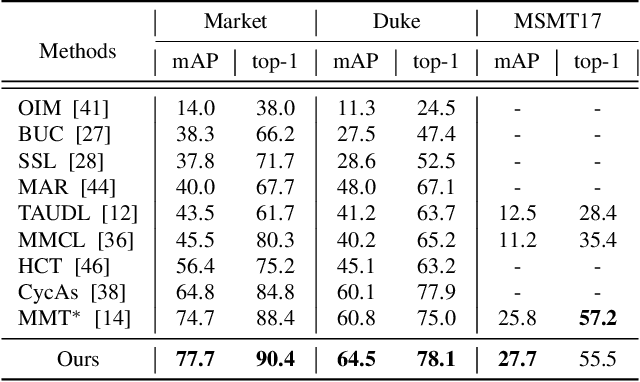
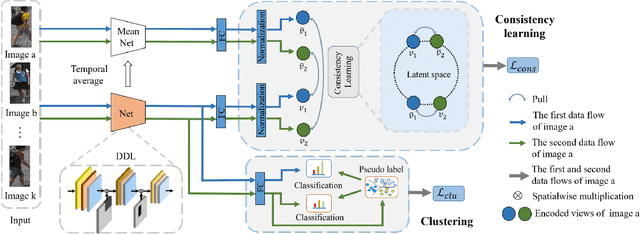
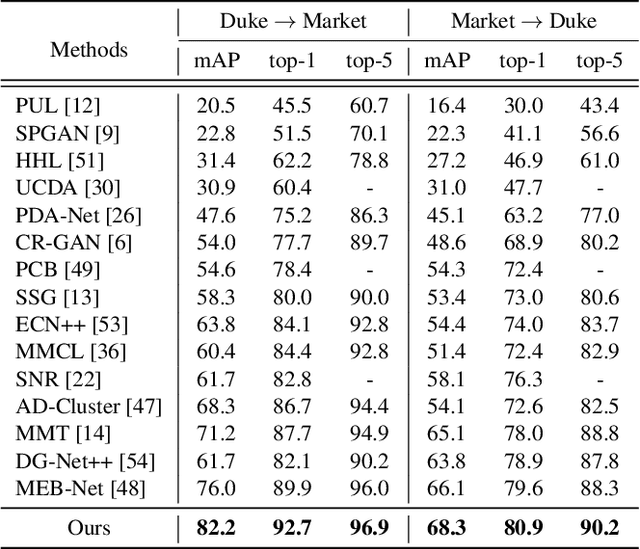
Unsupervised person re-identification (re-ID) has become an important topic due to its potential to resolve the scalability problem of supervised re-ID models. However, existing methods simply utilize pseudo labels from clustering for supervision and thus have not yet fully explored the semantic information in data itself, which limits representation capabilities of learned models. To address this problem, we design a pretext task for unsupervised re-ID by learning visual consistency from still images and temporal consistency during training process, such that the clustering network can separate the images into semantic clusters automatically. Specifically, the pretext task learns semantically meaningful representations by maximizing the agreement between two encoded views of the same image via a consistency loss in latent space. Meanwhile, we optimize the model by grouping the two encoded views into same cluster, thus enhancing the visual consistency between views. Experiments on Market-1501, DukeMTMC-reID and MSMT17 datasets demonstrate that our proposed approach outperforms the state-of-the-art methods by large margins.
Deep image representations using caption generators
May 25, 2017

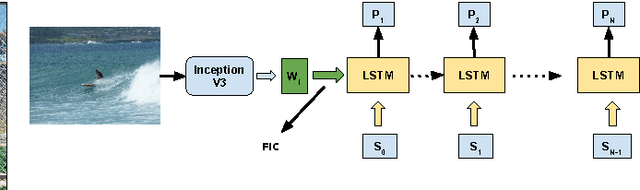
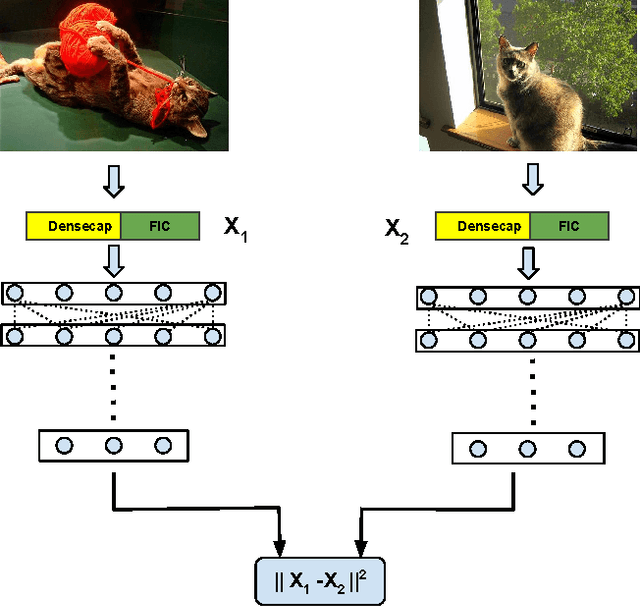
Deep learning exploits large volumes of labeled data to learn powerful models. When the target dataset is small, it is a common practice to perform transfer learning using pre-trained models to learn new task specific representations. However, pre-trained CNNs for image recognition are provided with limited information about the image during training, which is label alone. Tasks such as scene retrieval suffer from features learned from this weak supervision and require stronger supervision to better understand the contents of the image. In this paper, we exploit the features learned from caption generating models to learn novel task specific image representations. In particular, we consider the state-of-the art captioning system Show and Tell~\cite{SnT-pami-2016} and the dense region description model DenseCap~\cite{densecap-cvpr-2016}. We demonstrate that, owing to richer supervision provided during the process of training, the features learned by the captioning system perform better than those of CNNs. Further, we train a siamese network with a modified pair-wise loss to fuse the features learned by~\cite{SnT-pami-2016} and~\cite{densecap-cvpr-2016} and learn image representations suitable for retrieval. Experiments show that the proposed fusion exploits the complementary nature of the individual features and yields state-of-the art retrieval results on benchmark datasets.