 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Single Image Reflection Removal Using Deep Encoder-Decoder Network
Jan 31, 2018

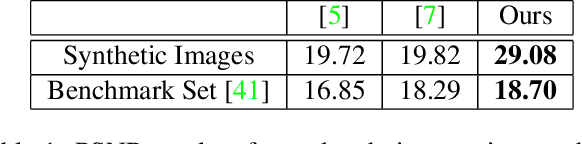
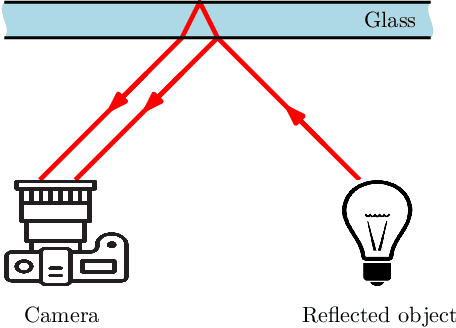

Image of a scene captured through a piece of transparent and reflective material, such as glass, is often spoiled by a superimposed layer of reflection image. While separating the reflection from a familiar object in an image is mentally not difficult for humans, it is a challenging, ill-posed problem in computer vision. In this paper, we propose a novel deep convolutional encoder-decoder method to remove the objectionable reflection by learning a map between image pairs with and without reflection. For training the neural network, we model the physical formation of reflections in images and synthesize a large number of photo-realistic reflection-tainted images from reflection-free images collected online. Extensive experimental results show that, although the neural network learns only from synthetic data, the proposed method is effective on real-world images, and it significantly outperforms the other tested state-of-the-art techniques.
Indonesian ID Card Extractor Using Optical Character Recognition and Natural Language Post-Processing
Dec 15, 2020
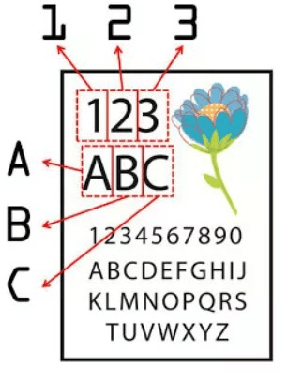
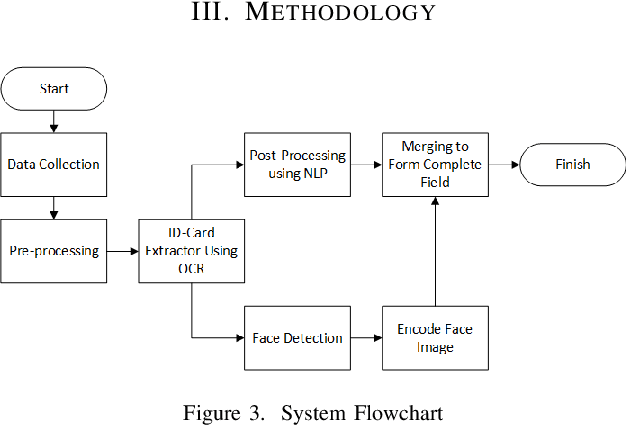

The development of Information Technology has been increasingly changing the means of information exchange leading to the need of digitizing print documents. In the present era, there is a lot of fraud that often occur. To avoid account fraud there was verification using ID card extraction using OCR and NLP. Optical Character Recognition (OCR) is technology that used to generate text from image. With OCR we can extract Indonesian ID card or kartu tanda penduduk (KTP) into text too. This is using to make easier service operator to do data entry. To improve the accuracy we made text correction using Natural language Processing (NLP) method to fixing the text. With 50 Indonesian ID card image we got 0.78 F-score, and we need 4510 milliseconds to extract per ID card.
A Fully Convolutional Two-Stream Fusion Network for Interactive Image Segmentation
Oct 02, 2018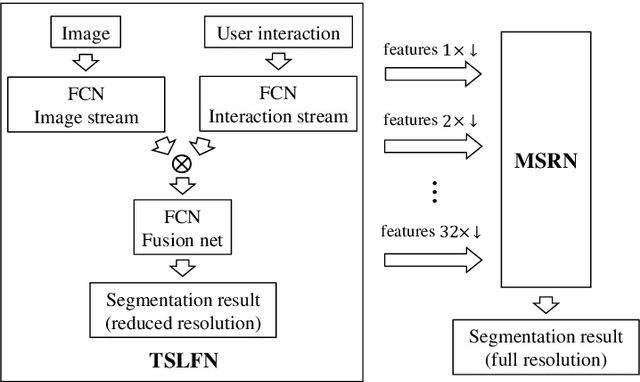
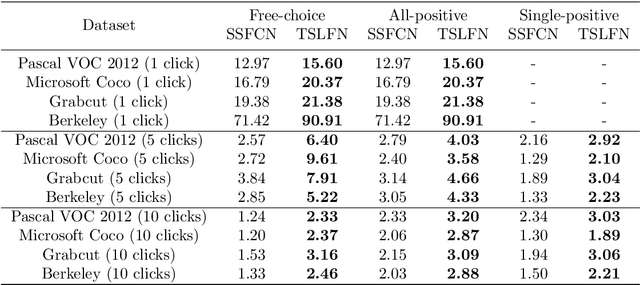
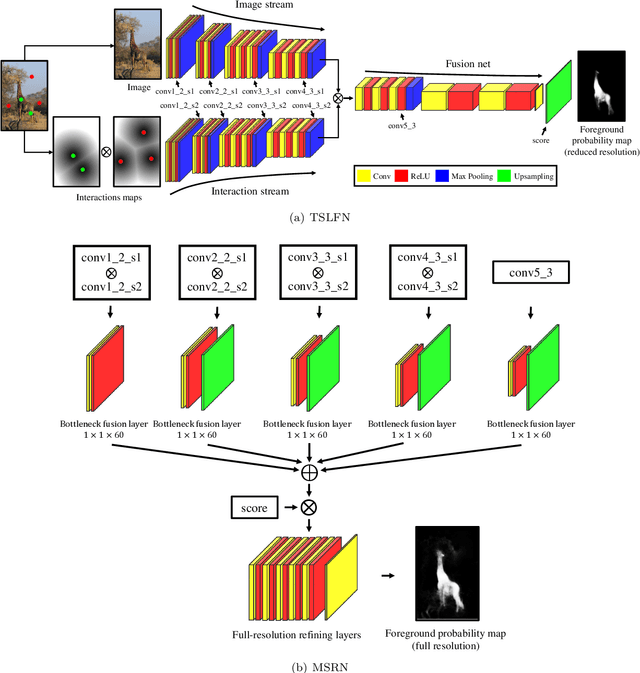
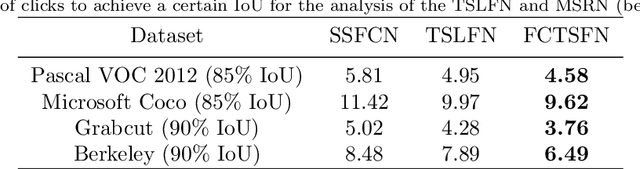
In this paper, we propose a novel fully convolutional two-stream fusion network (FCTSFN) for interactive image segmentation. The proposed network includes two sub-networks: a two-stream late fusion network (TSLFN) that predicts the foreground at a reduced resolution, and a multi-scale refining network (MSRN) that refines the foreground at full resolution. The TSLFN includes two distinct deep streams followed by a fusion network. The intuition is that, since user interactions are more direct information on foreground/background than the image itself, the two-stream structure of the TSLFN reduces the number of layers between the pure user interaction features and the network output, allowing the user interactions to have a more direct impact on the segmentation result. The MSRN fuses the features from different layers of TSLFN with different scales, in order to seek the local to global information on the foreground to refine the segmentation result at full resolution. We conduct comprehensive experiments on four benchmark datasets. The results show that the proposed network achieves competitive performance compared to current state-of-the-art interactive image segmentation methods
Cloud-based Image Classification Service Is Not Robust To Simple Transformations: A Forgotten Battlefield
Jun 19, 2019
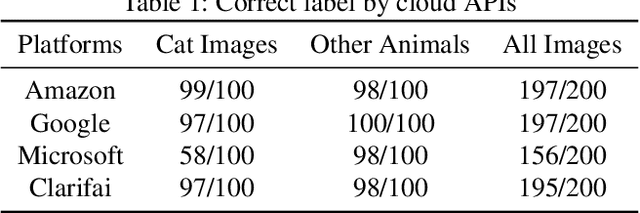

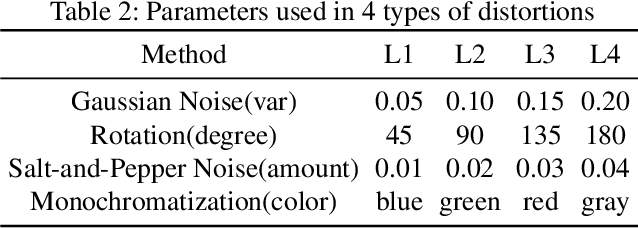
Many recent works demonstrated that Deep Learning models are vulnerable to adversarial examples.Fortunately, generating adversarial examples usually requires white-box access to the victim model, and the attacker can only access the APIs opened by cloud platforms. Thus, keeping models in the cloud can usually give a (false) sense of security.Unfortunately, cloud-based image classification service is not robust to simple transformations such as Gaussian Noise, Salt-and-Pepper Noise, Rotation and Monochromatization. In this paper,(1) we propose one novel attack method called Image Fusion(IF) attack, which achieve a high bypass rate,can be implemented only with OpenCV and is difficult to defend; and (2) we make the first attempt to conduct an extensive empirical study of Simple Transformation (ST) attacks against real-world cloud-based classification services. Through evaluations on four popular cloud platforms including Amazon, Google, Microsoft, Clarifai, we demonstrate that ST attack has a success rate of approximately 100% except Amazon approximately 50%, IF attack have a success rate over 98% among different classification services. (3) We discuss the possible defenses to address these security challenges.Experiments show that our defense technology can effectively defend known ST attacks.
Learning Discriminative Features using Multi-label Dual Space
Feb 25, 2021

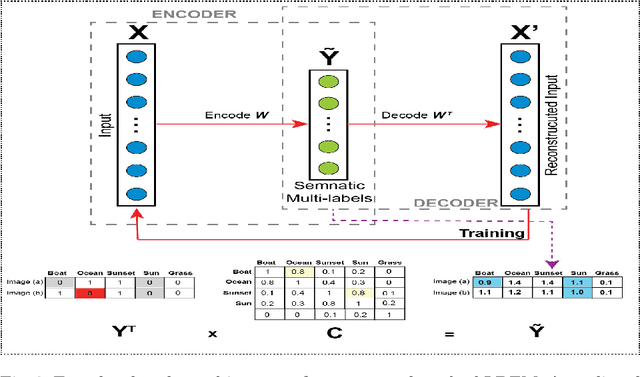
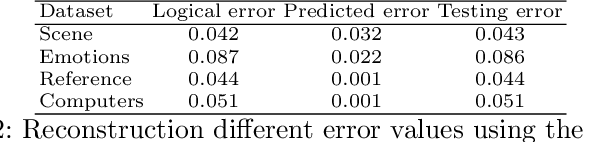
Multi-label learning handles instances associated with multiple class labels. The original label space is a logical matrix with entries from the Boolean domain $\in \left \{ 0,1 \right \}$. Logical labels are not able to show the relative importance of each semantic label to the instances. The vast majority of existing methods map the input features to the label space using linear projections with taking into consideration the label dependencies using logical label matrix. However, the discriminative features are learned using one-way projection from the feature representation of an instance into a logical label space. Given that there is no manifold in the learning space of logical labels, which limits the potential of learned models. In this work, inspired from a real-world example in image annotation to reconstruct an image from the label importance and feature weights. We propose a novel method in multi-label learning to learn the projection matrix from the feature space to semantic label space and projects it back to the original feature space using encoder-decoder deep learning architecture. The key intuition which guides our method is that the discriminative features are identified due to map the features back and forth using two linear projections. To the best of our knowledge, this is one of the first attempts to study the ability to reconstruct the original features from the label manifold in multi-label learning. We show that the learned projection matrix identifies a subset of discriminative features across multiple semantic labels. Extensive experiments on real-world datasets show the superiority of the proposed method.
* 12 pages
FAPIS: A Few-shot Anchor-free Part-based Instance Segmenter
Mar 31, 2021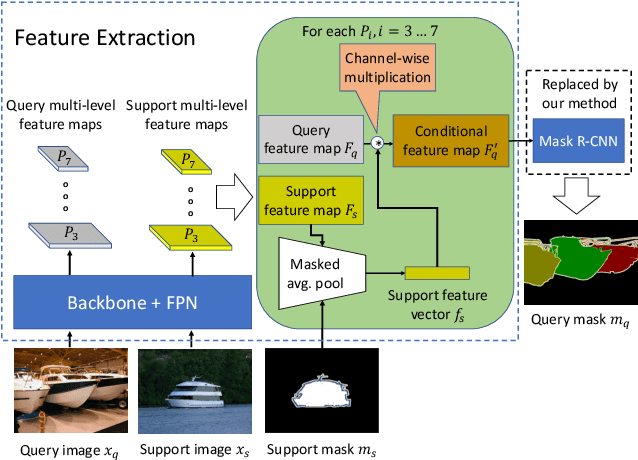

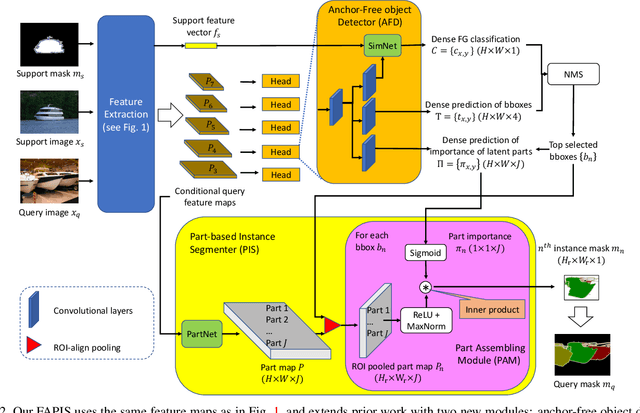

This paper is about few-shot instance segmentation, where training and test image sets do not share the same object classes. We specify and evaluate a new few-shot anchor-free part-based instance segmenter FAPIS. Our key novelty is in explicit modeling of latent object parts shared across training object classes, which is expected to facilitate our few-shot learning on new classes in testing. We specify a new anchor-free object detector aimed at scoring and regressing locations of foreground bounding boxes, as well as estimating relative importance of latent parts within each box. Also, we specify a new network for delineating and weighting latent parts for the final instance segmentation within every detected bounding box. Our evaluation on the benchmark COCO-20i dataset demonstrates that we significantly outperform the state of the art.
Resolution Dependant GAN Interpolation for Controllable Image Synthesis Between Domains
Oct 11, 2020
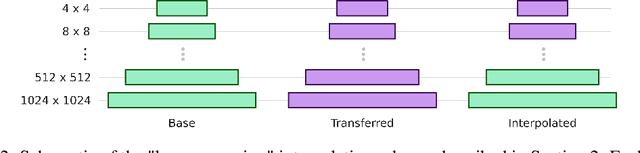


GANs can generate photo-realistic images from the domain of their training data. However, those wanting to use them for creative purposes often want to generate imagery from a truly novel domain, a task which GANs are inherently unable to do. It is also desirable to have a level of control so that there is a degree of artistic direction rather than purely curation of random results. Here we present a method for interpolating between generative models of the StyleGAN architecture in a resolution dependant manner. This allows us to generate images from an entirely novel domain and do this with a degree of control over the nature of the output.
GANchors: Realistic Image Perturbation Distributions for Anchors Using Generative Models
Jun 01, 2019
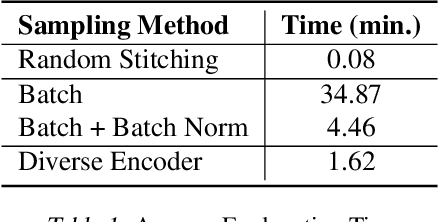

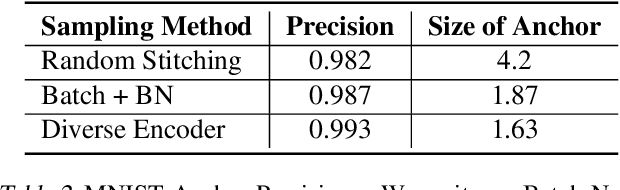
We extend and improve the work of Model Agnostic Anchors for explanations on image classification through the use of generative adversarial networks (GANs). Using GANs, we generate samples from a more realistic perturbation distribution, by optimizing under a lower dimensional latent space. This increases the trust in an explanation, as results now come from images that are more likely to be found in the original training set of a classifier, rather than an overlay of random images. A large drawback to our method is the computational complexity of sampling through optimization; to address this, we implement more efficient algorithms, including a diverse encoder. Lastly, we share results from the MNIST and CelebA datasets, and note that our explanations can lead to smaller and higher precision anchors.
Revisiting 2D Convolutional Neural Networks for Graph-based Applications
May 23, 2021
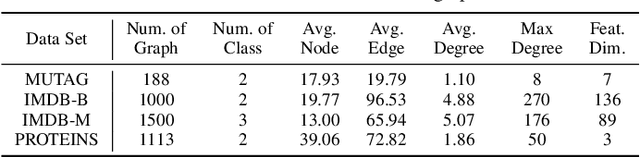
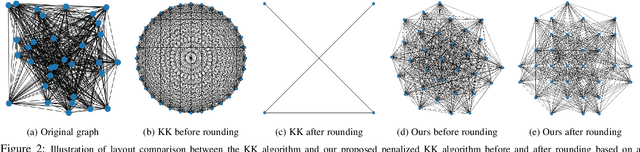
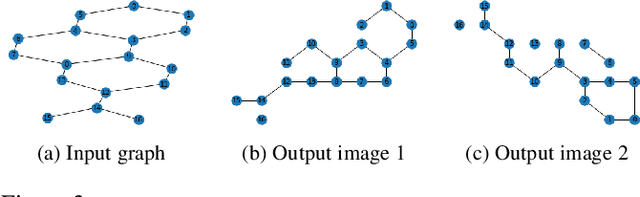
Graph convolutional networks (GCNs) are widely used in graph-based applications such as graph classification and segmentation. However, current GCNs have limitations on implementation such as network architectures due to their irregular inputs. In contrast, convolutional neural networks (CNNs) are capable of extracting rich features from large-scale input data, but they do not support general graph inputs. To bridge the gap between GCNs and CNNs, in this paper we study the problem of how to effectively and efficiently map general graphs to 2D grids that CNNs can be directly applied to, while preserving graph topology as much as possible. We therefore propose two novel graph-to-grid mapping schemes, namely, {\em graph-preserving grid layout (GPGL)} and its extension {\em Hierarchical GPGL (H-GPGL)} for computational efficiency. We formulate the GPGL problem as integer programming and further propose an approximate yet efficient solver based on a penalized Kamada-Kawai method, a well-known optimization algorithm in 2D graph drawing. We propose a novel vertex separation penalty that encourages graph vertices to lay on the grid without any overlap. Along with this image representation, even extra 2D maxpooling layers contribute to the PointNet, a widely applied point-based neural network. We demonstrate the empirical success of GPGL on general graph classification with small graphs and H-GPGL on 3D point cloud segmentation with large graphs, based on 2D CNNs including VGG16, ResNet50 and multi-scale maxout (MSM) CNN.
Classification of Hematoma: Joint Learning of Semantic Segmentation and Classification
Mar 31, 2021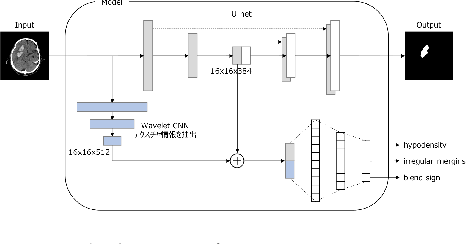
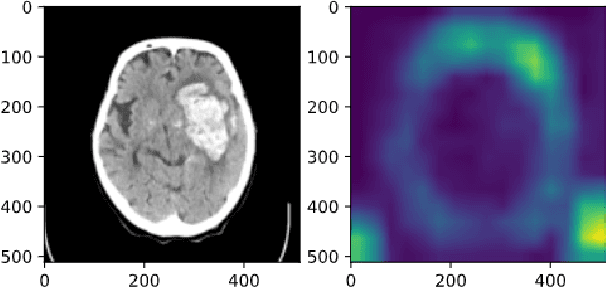
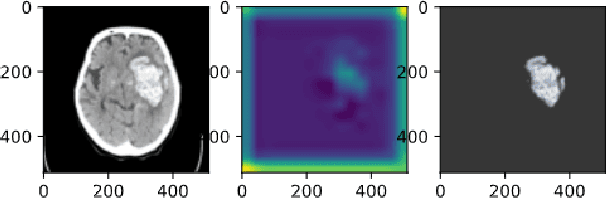
Cerebral hematoma grows rapidly in 6-24 hours and misprediction of the growth can be fatal if it is not operated by a brain surgeon. There are two types of cerebral hematomas: one that grows rapidly and the other that does not grow rapidly. We are developing the technique of artificial intelligence to determine whether the CT image includes the cerebral hematoma which leads to the rapid growth. This problem has various difficulties: the few positive cases in this classification problem of cerebral hematoma and the targeted hematoma has deformable object. Other difficulties include the imbalance classification, the covariate shift, the small data, and the spurious correlation problems. It is difficult with the plain CNN classification such as VGG. This paper proposes the joint learning of semantic segmentation and classification and evaluate the performance of this.