 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Two-Stage Convolutional Neural Network for Breast Cancer Histology Image Classification
Apr 01, 2018
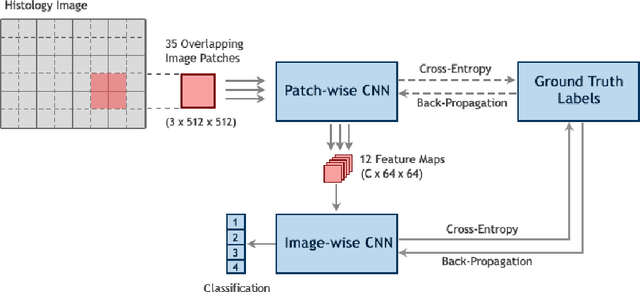

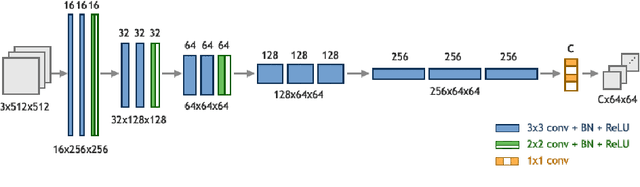
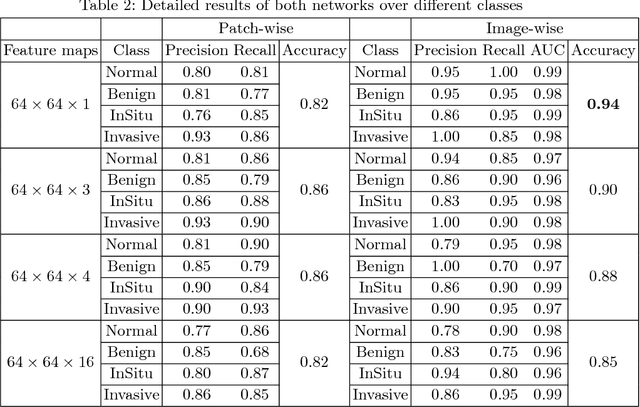
This paper explores the problem of breast tissue classification of microscopy images. Based on the predominant cancer type the goal is to classify images into four categories of normal, benign, in situ carcinoma, and invasive carcinoma. Given a suitable training dataset, we utilize deep learning techniques to address the classification problem. Due to the large size of each image in the training dataset, we propose a patch-based technique which consists of two consecutive convolutional neural networks. The first "patch-wise" network acts as an auto-encoder that extracts the most salient features of image patches while the second "image-wise" network performs classification of the whole image. The first network is pre-trained and aimed at extracting local information while the second network obtains global information of an input image. We trained the networks using the ICIAR 2018 grand challenge on BreAst Cancer Histology (BACH) dataset. The proposed method yields 95 % accuracy on the validation set compared to previously reported 77 % accuracy rates in the literature. Our code is publicly available at https://github.com/ImagingLab/ICIAR2018
* 10 pages, 5 figures, ICIAR 2018 conference
Multi-Stage Fusion for One-Click Segmentation
Oct 20, 2020
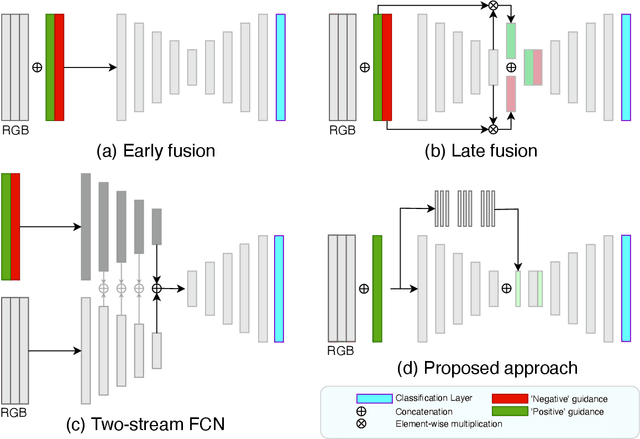
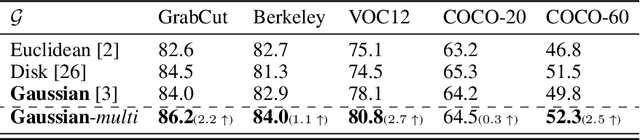
Segmenting objects of interest in an image is an essential building block of applications such as photo-editing and image analysis. Under interactive settings, one should achieve good segmentations while minimizing user input. Current deep learning-based interactive segmentation approaches use early fusion and incorporate user cues at the image input layer. Since segmentation CNNs have many layers, early fusion may weaken the influence of user interactions on the final prediction results. As such, we propose a new multi-stage guidance framework for interactive segmentation. By incorporating user cues at different stages of the network, we allow user interactions to impact the final segmentation output in a more direct way. Our proposed framework has a negligible increase in parameter count compared to early-fusion frameworks. We perform extensive experimentation on the standard interactive instance segmentation and one-click segmentation benchmarks and report state-of-the-art performance.
Trainable Activation Function in Image Classification
Jun 05, 2020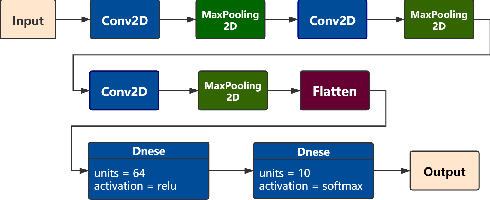
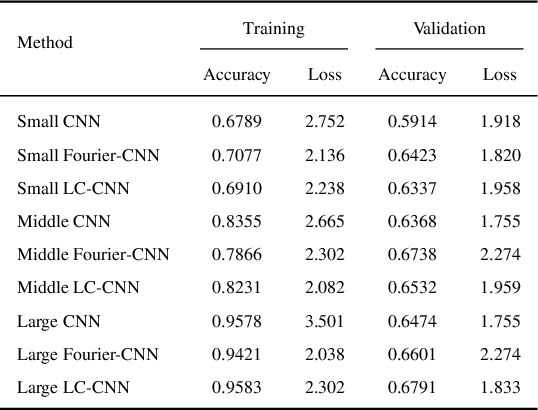
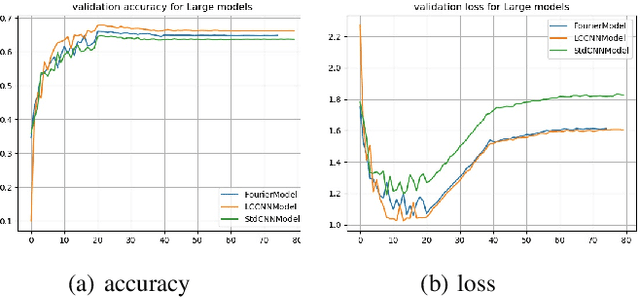
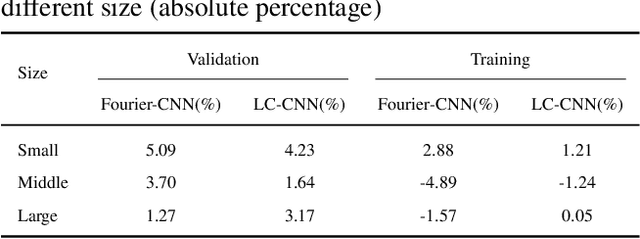
In the current research of neural networks, the activation function is manually specified by human and not able to change themselves during training. This paper focus on how to make the activation function trainable for deep neural networks. We use series and linear combination of different activation functions make activation functions continuously variable. Also, we test the performance of CNNs with Fourier series simulated activation(Fourier-CNN) and CNNs with linear combined activation function (LC-CNN) on Cifar-10 dataset. The result shows our trainable activation function reveals better performance than the most used ReLU activation function. Finally, we improves the performance of Fourier-CNN with Autoencoder, and test the performance of PSO algorithm in optimizing the parameters of networks
Frustratingly Simple Domain Generalization via Image Stylization
Jul 10, 2020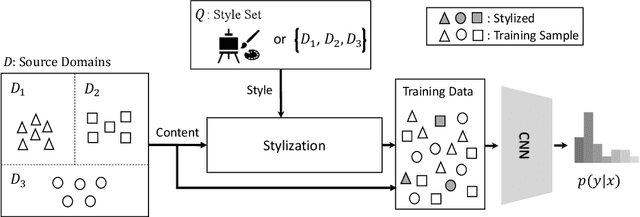
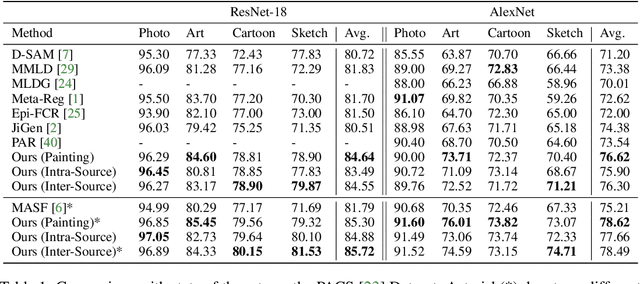
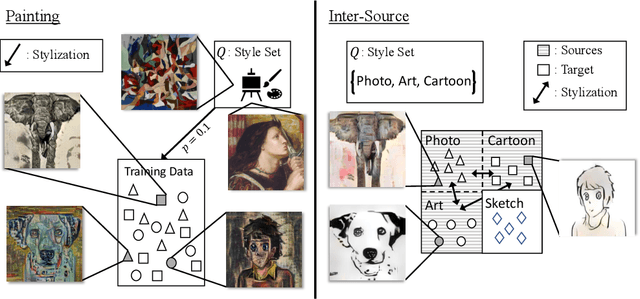
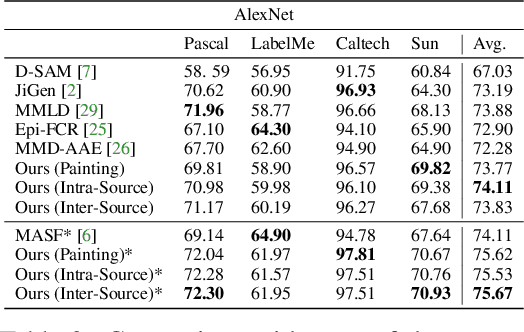
Convolutional Neural Networks (CNNs) show impressive performance in the standard classification setting where training and testing data are drawn i.i.d. from a given domain. However, CNNs do not readily generalize to new domains with different statistics, a setting that is simple for humans. In this work, we address the Domain Generalization problem, where the classifier must generalize to an unknown target domain. Inspired by recent works that have shown a difference in biases between CNNs and humans, we demonstrate an extremely simple yet effective method, namely correcting this bias by augmenting the dataset with stylized images. In contrast with existing stylization works, which use external data sources such as art, we further introduce a method that is entirely in-domain using no such extra sources of data. We provide a detailed analysis as to the mechanism by which the method works, verifying our claim that it changes the shape/texture bias, and demonstrate results surpassing or comparable to the state of the arts that utilize much more complex methods.
Understanding image motion with group representations
Feb 26, 2018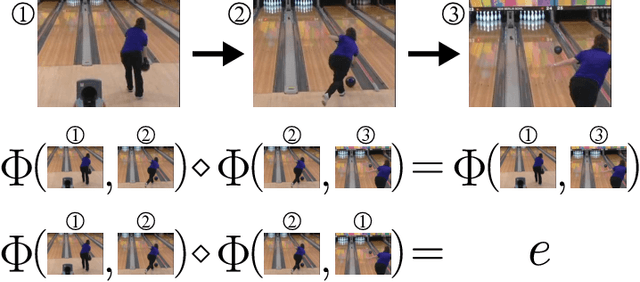
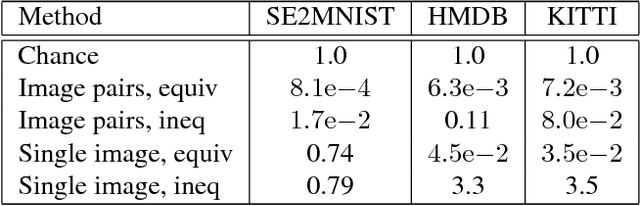

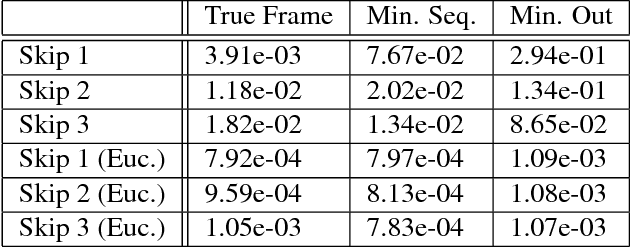
Motion is an important signal for agents in dynamic environments, but learning to represent motion from unlabeled video is a difficult and underconstrained problem. We propose a model of motion based on elementary group properties of transformations and use it to train a representation of image motion. While most methods of estimating motion are based on pixel-level constraints, we use these group properties to constrain the abstract representation of motion itself. We demonstrate that a deep neural network trained using this method captures motion in both synthetic 2D sequences and real-world sequences of vehicle motion, without requiring any labels. Networks trained to respect these constraints implicitly identify the image characteristic of motion in different sequence types. In the context of vehicle motion, this method extracts information useful for localization, tracking, and odometry. Our results demonstrate that this representation is useful for learning motion in the general setting where explicit labels are difficult to obtain.
Parallax Attention for Unsupervised Stereo Correspondence Learning
Sep 16, 2020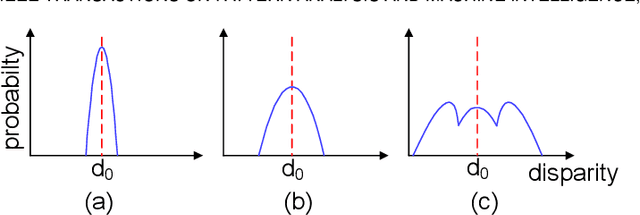
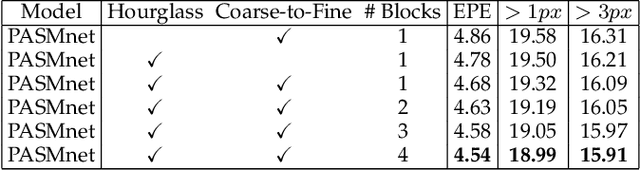
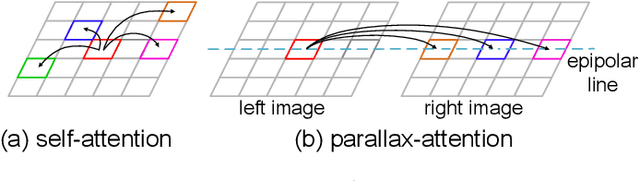

Stereo image pairs encode 3D scene cues into stereo correspondences between the left and right images. To exploit 3D cues within stereo images, recent CNN based methods commonly use cost volume techniques to capture stereo correspondence over large disparities. However, since disparities can vary significantly for stereo cameras with different baselines, focal lengths and resolutions, the fixed maximum disparity used in cost volume techniques hinders them to handle different stereo image pairs with large disparity variations. In this paper, we propose a generic parallax-attention mechanism (PAM) to capture stereo correspondence regardless of disparity variations. Our PAM integrates epipolar constraints with attention mechanism to calculate feature similarities along the epipolar line to capture stereo correspondence. Based on our PAM, we propose a parallax-attention stereo matching network (PASMnet) and a parallax-attention stereo image super-resolution network (PASSRnet) for stereo matching and stereo image super-resolution tasks. Moreover, we introduce a new and large-scale dataset named Flickr1024 for stereo image super-resolution. Experimental results show that our PAM is generic and can effectively learn stereo correspondence under large disparity variations in an unsupervised manner. Comparative results show that our PASMnet and PASSRnet achieve the state-of-the-art performance.
A Comparative Study of Quality and Content-Based Spatial Pooling Strategies in Image Quality Assessment
Nov 21, 2018

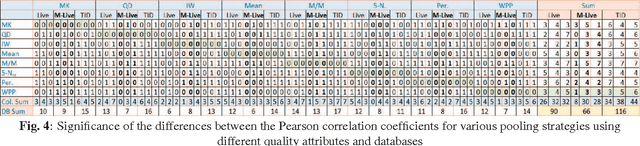
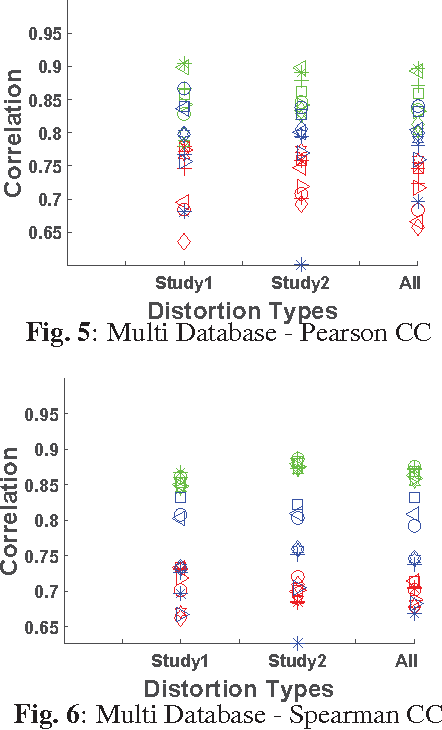
The process of quantifying image quality consists of engineering the quality features and pooling these features to obtain a value or a map. There has been a significant research interest in designing the quality features but pooling is usually overlooked compared to feature design. In this work, we compare the state of the art quality and content-based spatial pooling strategies and show that although features are the key in any image quality assessment, pooling also matters. We also propose a quality-based spatial pooling strategy that is based on linearly weighted percentile pooling (WPP). Pooling strategies are analyzed for squared error, SSIM and PerSIM in LIVE, multiply distorted LIVE and TID2013 image databases.
* Paper: 5 pages, 8 figures, Presentation: 21 slides [Ancillary files]
A Straightforward Framework For Video Retrieval Using CLIP
Feb 24, 2021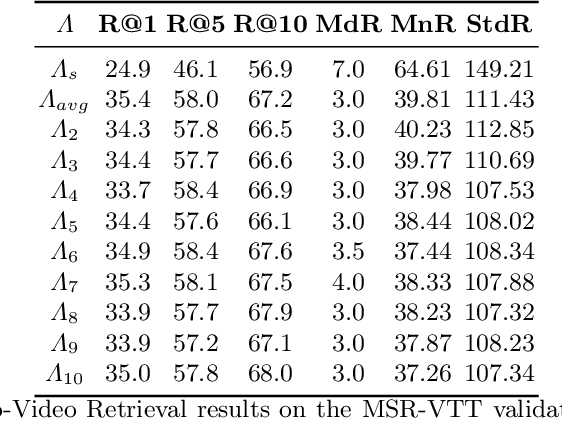
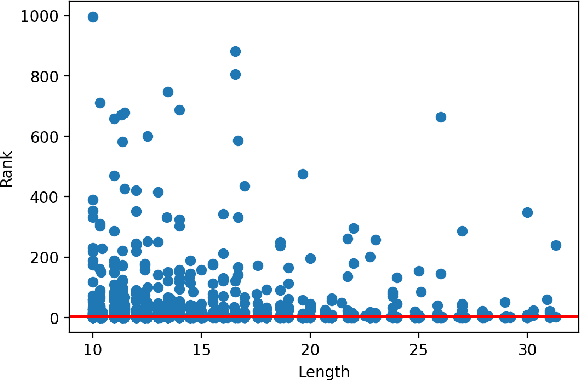
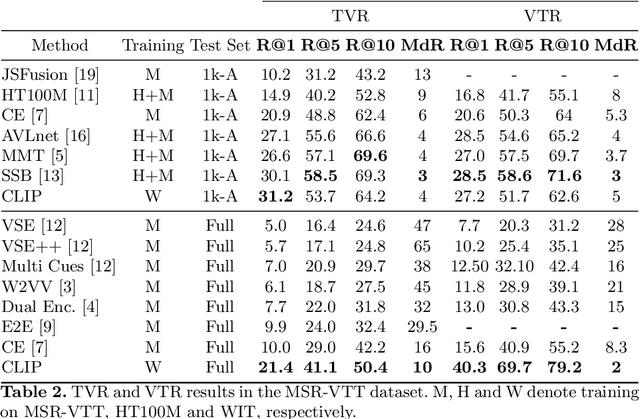
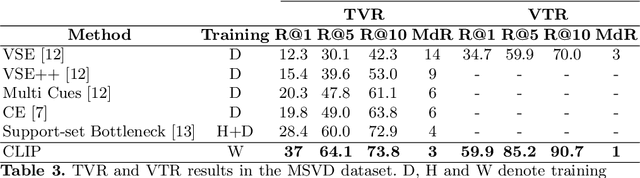
Video Retrieval is a challenging task where a text query is matched to a video or vice versa. Most of the existing approaches for addressing such a problem rely on annotations made by the users. Although simple, this approach is not always feasible in practice. In this work, we explore the application of the language-image model, CLIP, to obtain video representations without the need for said annotations. This model was explicitly trained to learn a common space where images and text can be compared. Using various techniques described in this document, we extended its application to videos, obtaining state-of-the-art results on the MSR-VTT and MSVD benchmarks.
Pulmonary embolism identification in computerized tomography pulmonary angiography scans with deep learning technologies in COVID-19 patients
May 28, 2021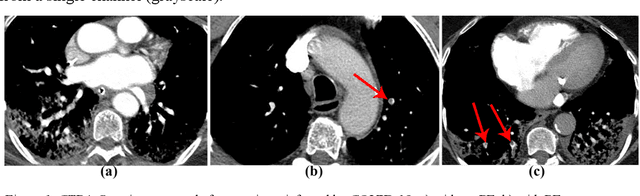
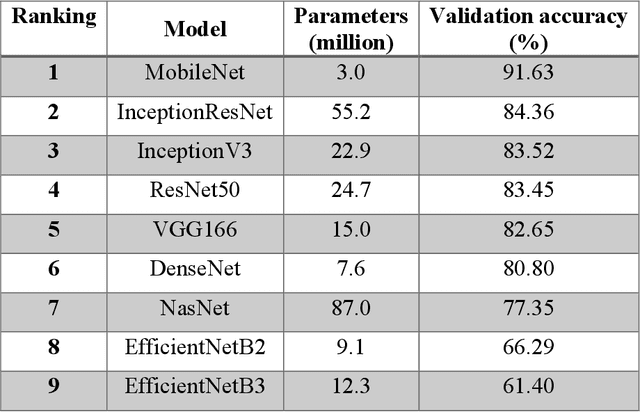
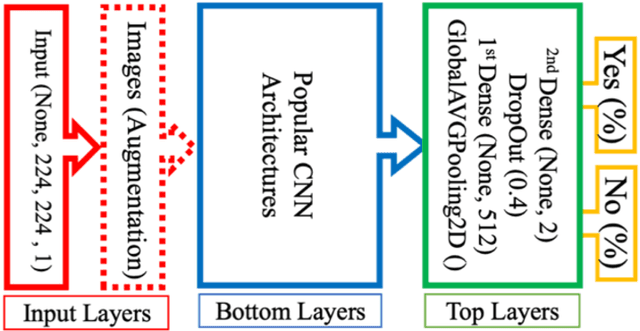
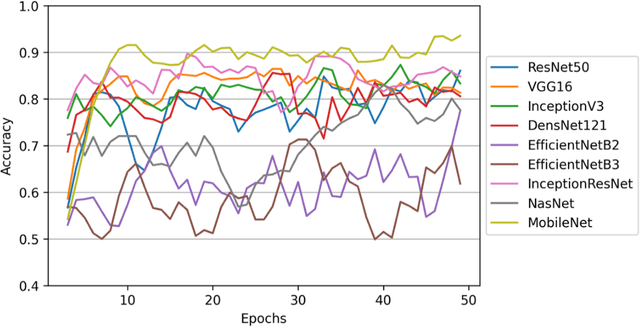
The main objective of this work is to utilize state-of-the-art deep learning approaches for the identification of pulmonary embolism in CTPA-Scans for COVID-19 patients, provide an initial assessment of their performance and, ultimately, provide a fast-track prototype solution (system). We adopted and assessed some of the most popular convolutional neural network architectures through transfer learning approaches, to strive to combine good model accuracy with fast training. Additionally, we exploited one of the most popular one-stage object detection models for the localization (through object detection) of the pulmonary embolism regions-of-interests. The models of both approaches are trained on an original CTPA-Scan dataset, where we annotated of 673 CTPA-Scan images with 1,465 bounding boxes in total, highlighting pulmonary embolism regions-of-interests. We provide a brief assessment of some state-of-the-art image classification models by achieving validation accuracies of 91% in pulmonary embolism classification. Additionally, we achieved a precision of about 68% on average in the object detection model for the pulmonary embolism localization under 50% IoU threshold. For both approaches, we provide the entire training pipelines for future studies (step by step processes through source code). In this study, we present some of the most accurate and fast deep learning models for pulmonary embolism identification in CTPA-Scans images, through classification and localization (object detection) approaches for patients infected by COVID-19. We provide a fast-track solution (system) for the research community of the area, which combines both classification and object detection models for improving the precision of identifying pulmonary embolisms.
End-to-end learning of keypoint detection and matching for relative pose estimation
Apr 02, 2021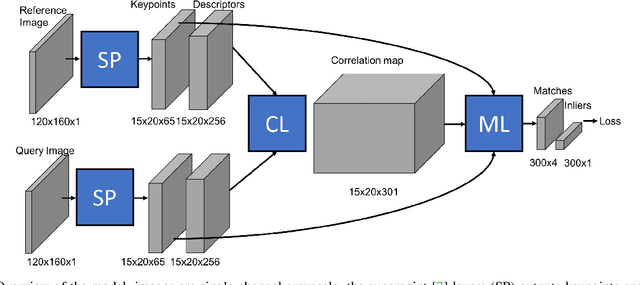
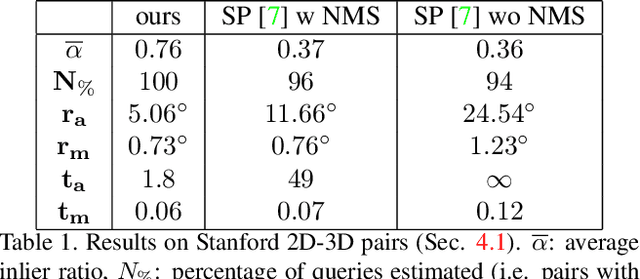
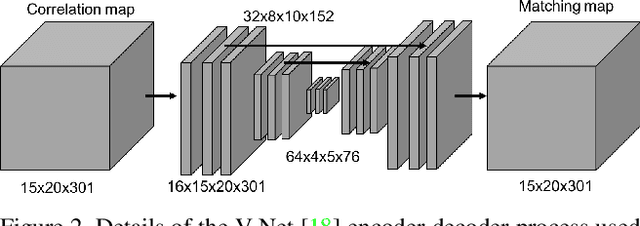

We propose a new method for estimating the relative pose between two images, where we jointly learn keypoint detection, description extraction, matching and robust pose estimation. While our architecture follows the traditional pipeline for pose estimation from geometric computer vision, all steps are learnt in an end-to-end fashion, including feature matching. We demonstrate our method for the task of visual localization of a query image within a database of images with known pose. Pairwise pose estimation has many practical applications for robotic mapping, navigation, and AR. For example, the display of persistent AR objects in the scene relies on a precise camera localization to make the digital models appear anchored to the physical environment. We train our pipeline end-to-end specifically for the problem of visual localization. We evaluate our proposed approach on localization accuracy, robustness and runtime speed. Our method achieves state of the art localization accuracy on the 7 Scenes dataset.