 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Frustratingly Simple Domain Generalization via Image Stylization
Jul 10, 2020
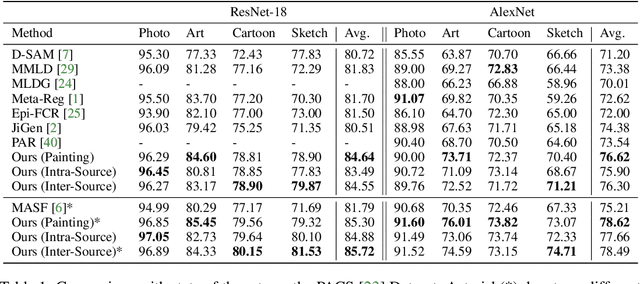
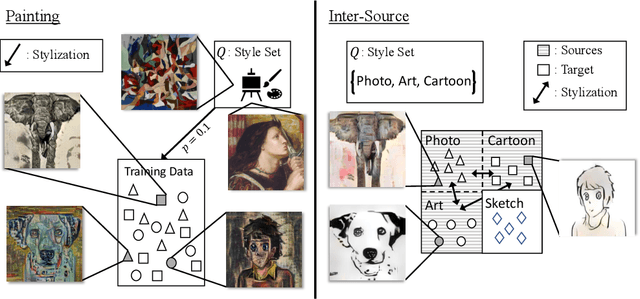
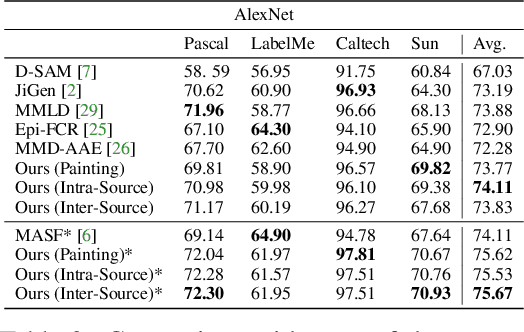
Convolutional Neural Networks (CNNs) show impressive performance in the standard classification setting where training and testing data are drawn i.i.d. from a given domain. However, CNNs do not readily generalize to new domains with different statistics, a setting that is simple for humans. In this work, we address the Domain Generalization problem, where the classifier must generalize to an unknown target domain. Inspired by recent works that have shown a difference in biases between CNNs and humans, we demonstrate an extremely simple yet effective method, namely correcting this bias by augmenting the dataset with stylized images. In contrast with existing stylization works, which use external data sources such as art, we further introduce a method that is entirely in-domain using no such extra sources of data. We provide a detailed analysis as to the mechanism by which the method works, verifying our claim that it changes the shape/texture bias, and demonstrate results surpassing or comparable to the state of the arts that utilize much more complex methods.
Path planning model of mobile robots in the context of crowds
Sep 10, 2020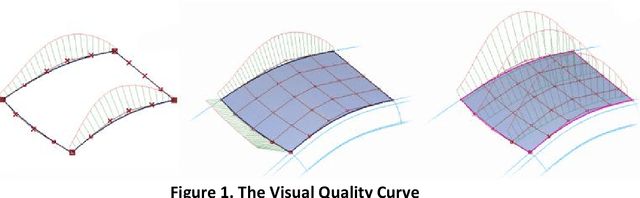
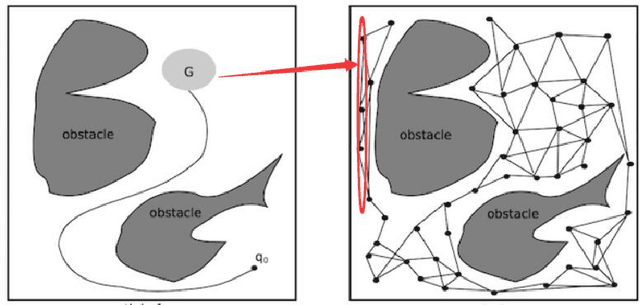
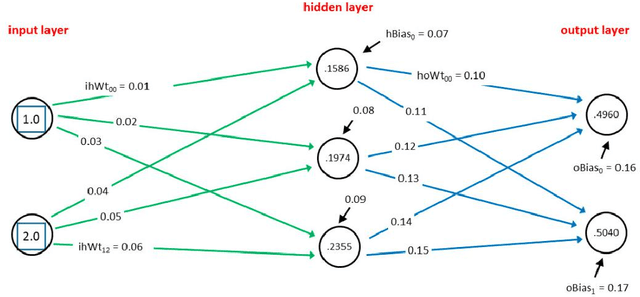
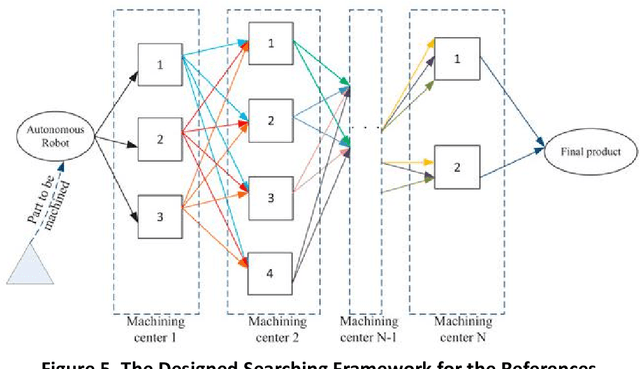
Robot path planning model based on RNN and visual quality evaluation in the context of crowds is analyzed in this paper. Mobile robot path planning is the key to robot navigation and an important field in robot research. Let the motion space of the robot be a two-dimensional plane, and the motion of the robot is regarded as a kind of motion under the virtual artificial potential field force when the artificial potential field method is used for the path planning. Compared to simple image acquisition, image acquisition in a complex crowd environment requires image pre-processing first. We mainly use OpenCV calibration tools to pre-process the acquired images. In themethodology design, the RNN-based visual quality evaluation to filter background noise is conducted. After calibration, Gaussian noise and some other redundant information affecting the subsequent operations still exist in the image. Based on RNN, a new image quality evaluation algorithm is developed, and denoising is performed on this basis. Furthermore, the novel path planning model is designed and simulated. The expeirment compared with the state-of-the-art models have shown the robustness of the model.
Analyzing and Quantifying Generalization in Convolutional Neural Networks
Apr 02, 2021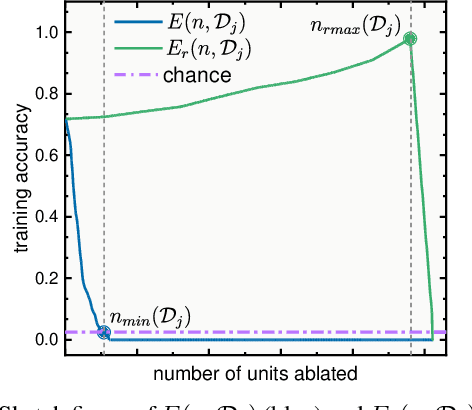
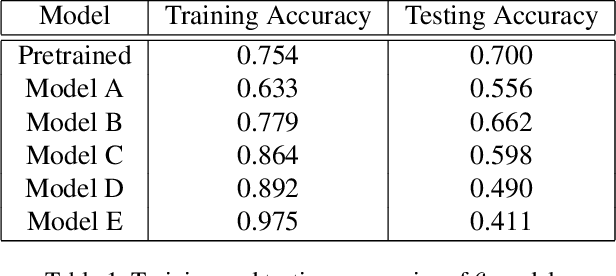
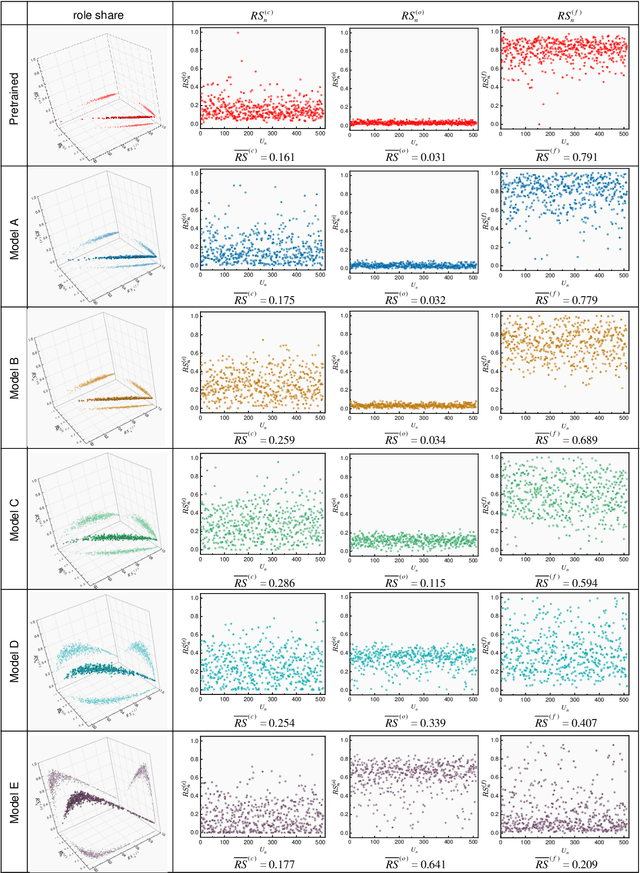
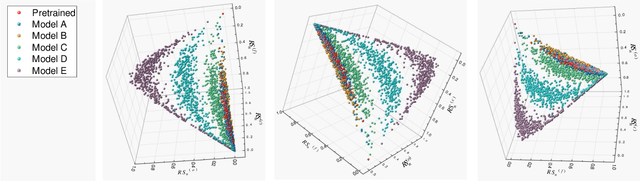
Generalization is the key capability of convolutional neural networks (CNNs). However, it is still quite elusive for differentiating the CNNs with good or poor generalization. It results in the barrier for providing reliable quantitative measure of generalization ability. To this end, this paper aims to clarify the generalization status of individual units in typical CNNs and quantify the generalization ability of networks using image classification task with multiple classes data. Firstly, we propose a feature quantity, role share, consisting of four discriminate statuses for a certain unit based on its contribution to generalization. The distribution of role shares across all units provides a straightforward visualization for the generalization of a network. Secondly, using only training sets, we propose a novel metric for quantifying the intrinsic generalization ability of networks. Lastly, a predictor of testing accuracy via only training accuracy of typical CNN is given. Empirical experiments using practical network model (VGG) and dataset (ImageNet) illustrate the rationality and effectiveness of our feature quantity, metric and predictor.
Trainable Activation Function in Image Classification
Jun 05, 2020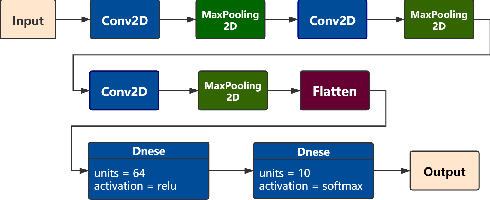
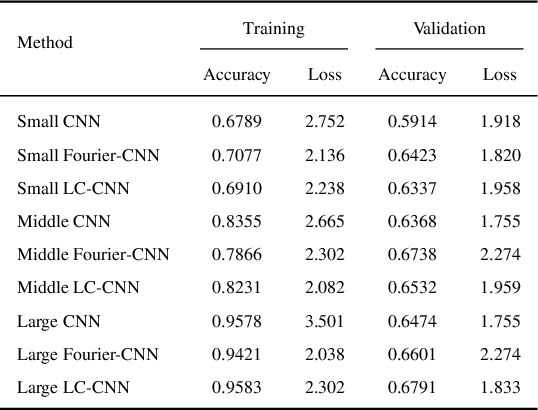
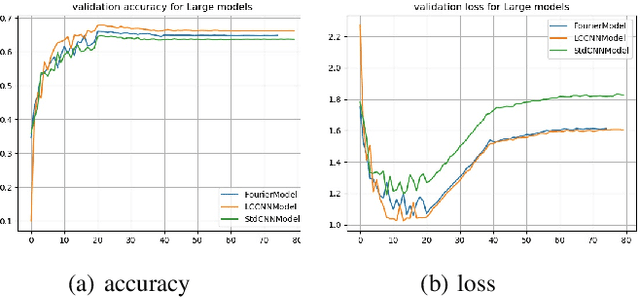
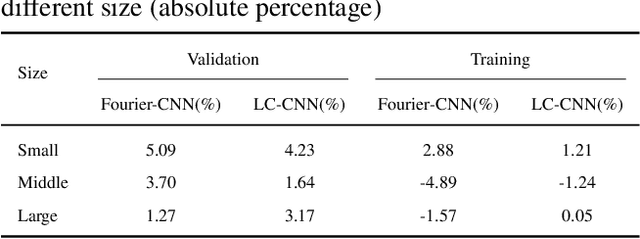
In the current research of neural networks, the activation function is manually specified by human and not able to change themselves during training. This paper focus on how to make the activation function trainable for deep neural networks. We use series and linear combination of different activation functions make activation functions continuously variable. Also, we test the performance of CNNs with Fourier series simulated activation(Fourier-CNN) and CNNs with linear combined activation function (LC-CNN) on Cifar-10 dataset. The result shows our trainable activation function reveals better performance than the most used ReLU activation function. Finally, we improves the performance of Fourier-CNN with Autoencoder, and test the performance of PSO algorithm in optimizing the parameters of networks
Improving Generation and Evaluation of Visual Stories via Semantic Consistency
May 20, 2021
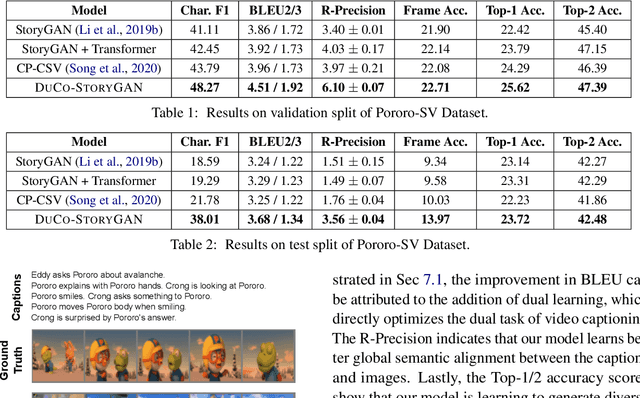
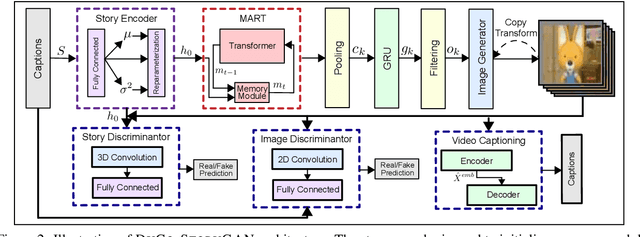
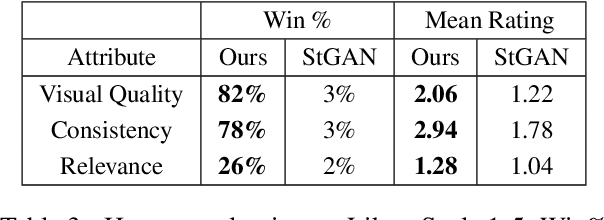
Story visualization is an under-explored task that falls at the intersection of many important research directions in both computer vision and natural language processing. In this task, given a series of natural language captions which compose a story, an agent must generate a sequence of images that correspond to the captions. Prior work has introduced recurrent generative models which outperform text-to-image synthesis models on this task. However, there is room for improvement of generated images in terms of visual quality, coherence and relevance. We present a number of improvements to prior modeling approaches, including (1) the addition of a dual learning framework that utilizes video captioning to reinforce the semantic alignment between the story and generated images, (2) a copy-transform mechanism for sequentially-consistent story visualization, and (3) MART-based transformers to model complex interactions between frames. We present ablation studies to demonstrate the effect of each of these techniques on the generative power of the model for both individual images as well as the entire narrative. Furthermore, due to the complexity and generative nature of the task, standard evaluation metrics do not accurately reflect performance. Therefore, we also provide an exploration of evaluation metrics for the model, focused on aspects of the generated frames such as the presence/quality of generated characters, the relevance to captions, and the diversity of the generated images. We also present correlation experiments of our proposed automated metrics with human evaluations. Code and data available at: https://github.com/adymaharana/StoryViz
Current Status and Performance Analysis of Table Recognition in Document Images with Deep Neural Networks
Apr 29, 2021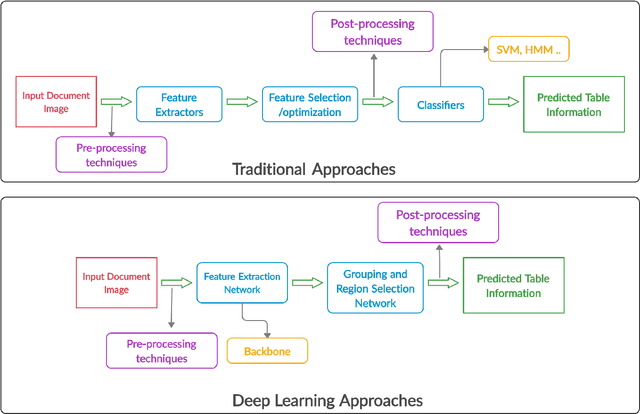
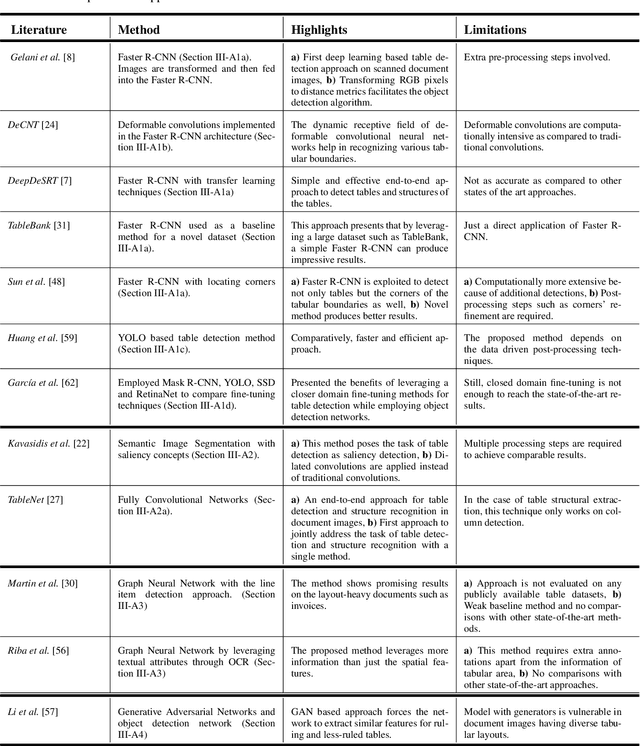
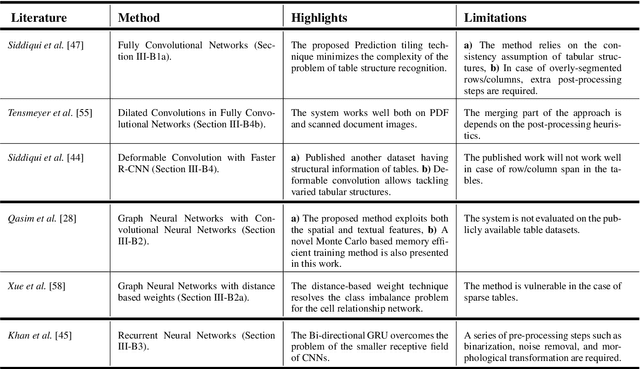
The first phase of table recognition is to detect the tabular area in a document. Subsequently, the tabular structures are recognized in the second phase in order to extract information from the respective cells. Table detection and structural recognition are pivotal problems in the domain of table understanding. However, table analysis is a perplexing task due to the colossal amount of diversity and asymmetry in tables. Therefore, it is an active area of research in document image analysis. Recent advances in the computing capabilities of graphical processing units have enabled deep neural networks to outperform traditional state-of-the-art machine learning methods. Table understanding has substantially benefited from the recent breakthroughs in deep neural networks. However, there has not been a consolidated description of the deep learning methods for table detection and table structure recognition. This review paper provides a thorough analysis of the modern methodologies that utilize deep neural networks. This work provided a thorough understanding of the current state-of-the-art and related challenges of table understanding in document images. Furthermore, the leading datasets and their intricacies have been elaborated along with the quantitative results. Moreover, a brief overview is given regarding the promising directions that can serve as a guide to further improve table analysis in document images.
Towards Histopathological Stain Invariance by Unsupervised Domain Augmentation using Generative Adversarial Networks
Dec 22, 2020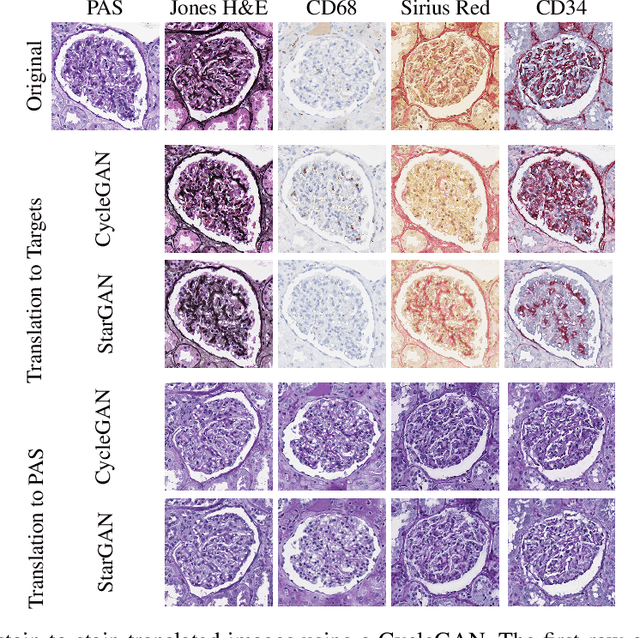
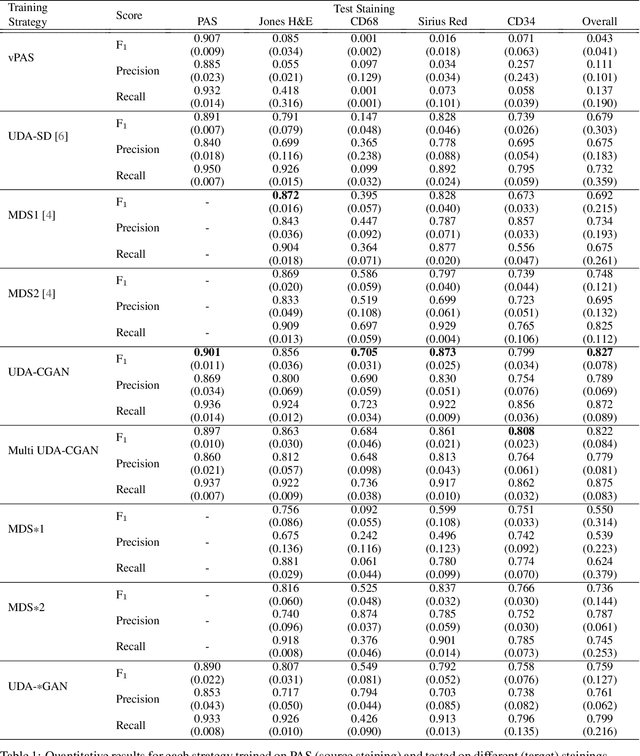
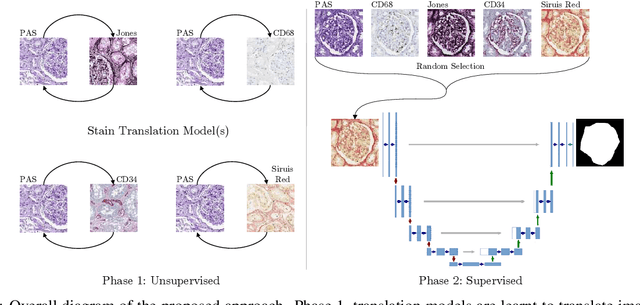
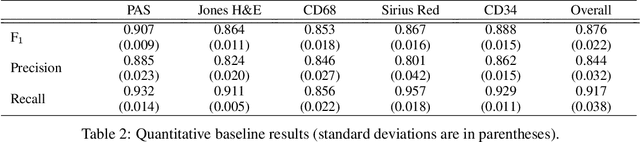
The application of supervised deep learning methods in digital pathology is limited due to their sensitivity to domain shift. Digital Pathology is an area prone to high variability due to many sources, including the common practice of evaluating several consecutive tissue sections stained with different staining protocols. Obtaining labels for each stain is very expensive and time consuming as it requires a high level of domain knowledge. In this article, we propose an unsupervised augmentation approach based on adversarial image-to-image translation, which facilitates the training of stain invariant supervised convolutional neural networks. By training the network on one commonly used staining modality and applying it to images that include corresponding, but differently stained, tissue structures, the presented method demonstrates significant improvements over other approaches. These benefits are illustrated in the problem of glomeruli segmentation in seven different staining modalities (PAS, Jones H&E, CD68, Sirius Red, CD34, H&E and CD3) and analysis of the learned representations demonstrate their stain invariance.
Super-resolution Guided Pore Detection for Fingerprint Recognition
Dec 10, 2020
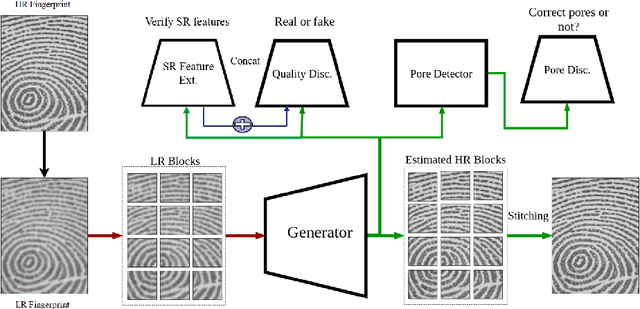

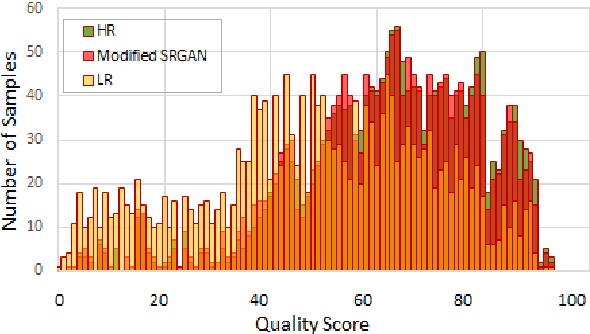
Performance of fingerprint recognition algorithms substantially rely on fine features extracted from fingerprints. Apart from minutiae and ridge patterns, pore features have proven to be usable for fingerprint recognition. Although features from minutiae and ridge patterns are quite attainable from low-resolution images, using pore features is practical only if the fingerprint image is of high resolution which necessitates a model that enhances the image quality of the conventional 500 ppi legacy fingerprints preserving the fine details. To find a solution for recovering pore information from low-resolution fingerprints, we adopt a joint learning-based approach that combines both super-resolution and pore detection networks. Our modified single image Super-Resolution Generative Adversarial Network (SRGAN) framework helps to reliably reconstruct high-resolution fingerprint samples from low-resolution ones assisting the pore detection network to identify pores with a high accuracy. The network jointly learns a distinctive feature representation from a real low-resolution fingerprint sample and successfully synthesizes a high-resolution sample from it. To add discriminative information and uniqueness for all the subjects, we have integrated features extracted from a deep fingerprint verifier with the SRGAN quality discriminator. We also add ridge reconstruction loss, utilizing ridge patterns to make the best use of extracted features. Our proposed method solves the recognition problem by improving the quality of fingerprint images. High recognition accuracy of the synthesized samples that is close to the accuracy achieved using the original high-resolution images validate the effectiveness of our proposed model.
A Framework and Dataset for Abstract Art Generation via CalligraphyGAN
Dec 02, 2020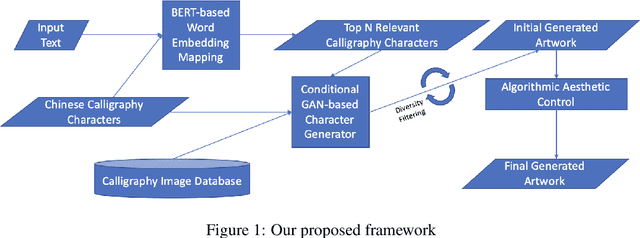

With the advancement of deep learning, artificial intelligence (AI) has made many breakthroughs in recent years and achieved superhuman performance in various tasks such as object detection, reading comprehension, and video games. Generative Modeling, such as various Generative Adversarial Networks (GAN) models, has been applied to generate paintings and music. Research in Natural Language Processing (NLP) also had a leap forward in 2018 since the release of the pre-trained contextual neural language models such as BERT and recently released GPT3. Despite the exciting AI applications aforementioned, AI is still significantly lagging behind humans in creativity, which is often considered the ultimate moonshot for AI. Our work is inspired by Chinese calligraphy, which is a unique form of visual art where the character itself is an aesthetic painting. We also draw inspirations from paintings of the Abstract Expressionist movement in the 1940s and 1950s, such as the work by American painter Franz Kline. In this paper, we present a creative framework based on Conditional Generative Adversarial Networks and Contextual Neural Language Model to generate abstract artworks that have intrinsic meaning and aesthetic value, which is different from the existing work, such as image captioning and text-to-image generation, where the texts are the descriptions of the images. In addition, we have publicly released a Chinese calligraphy image dataset and demonstrate our framework using a prototype system and a user study.
Spectral Image Visualization Using Generative Adversarial Networks
Feb 07, 2018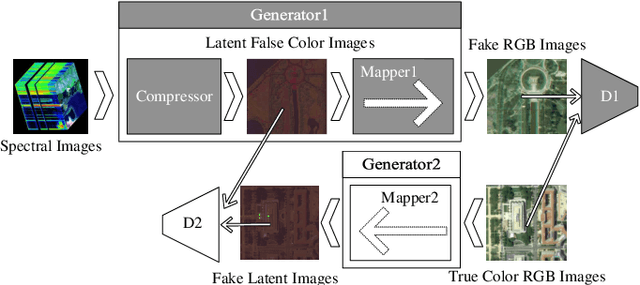

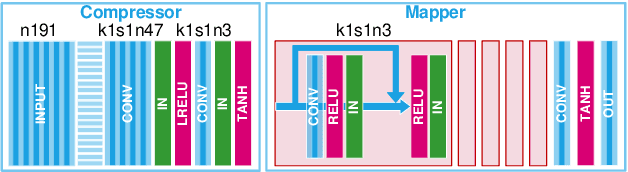

Spectral images captured by satellites and radio-telescopes are analyzed to obtain information about geological compositions distributions, distant asters as well as undersea terrain. Spectral images usually contain tens to hundreds of continuous narrow spectral bands and are widely used in various fields. But the vast majority of those image signals are beyond the visible range, which calls for special visualization technique. The visualizations of spectral images shall convey as much information as possible from the original signal and facilitate image interpretation. However, most of the existing visualizatio methods display spectral images in false colors, which contradict with human's experience and expectation. In this paper, we present a novel visualization generative adversarial network (GAN) to display spectral images in natural colors. To achieve our goal, we propose a loss function which consists of an adversarial loss and a structure loss. The adversarial loss pushes our solution to the natural image distribution using a discriminator network that is trained to differentiate between false-color images and natural-color images. We also use a cycle loss as the structure constraint to guarantee structure consistency. Experimental results show that our method is able to generate structure-preserved and natural-looking visualizations.