 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Addressing Training Bias via Automated Image Annotation
Oct 10, 2018
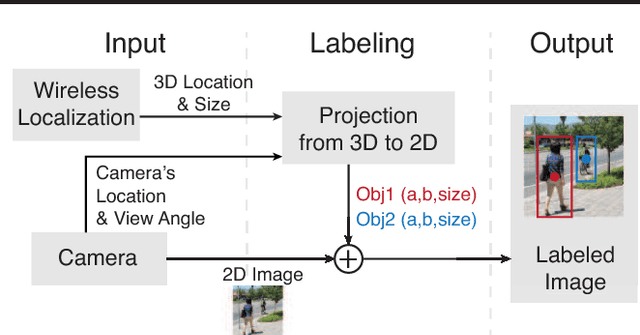



Build accurate DNN models requires training on large labeled, context specific datasets, especially those matching the target scenario. We believe advances in wireless localization, working in unison with cameras, can produce automated annotation of targets on images and videos captured in the wild. Using pedestrian and vehicle detection as examples, we demonstrate the feasibility, benefits, and challenges of an automatic image annotation system. Our work calls for new technical development on passive localization, mobile data analytics, and error-resilient ML models, as well as design issues in user privacy policies.
Real-Time Surface Fitting to RGBD Sensor Data
Mar 11, 2021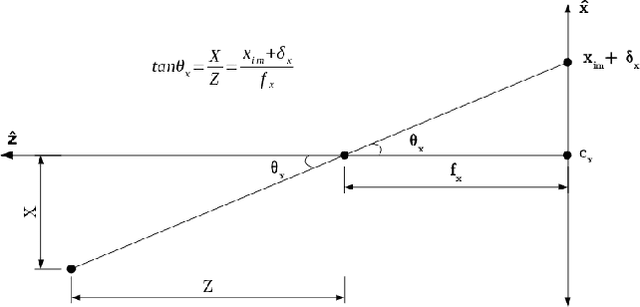
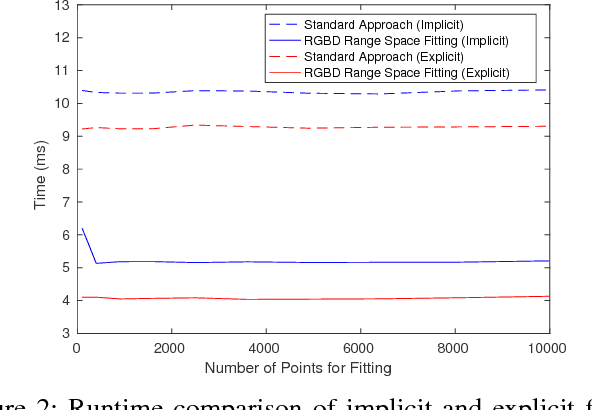
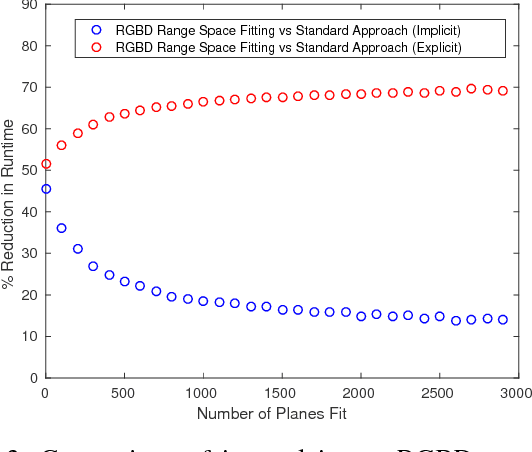

This article describes novel approaches to quickly estimate planar surfaces from RGBD sensor data. The approach manipulates the standard algebraic fitting equations into a form that allows many of the needed regression variables to be computed directly from the camera calibration information. As such, much of the computational burden required by a standard algebraic surface fit can be pre-computed. This provides a significant time and resource savings, especially when many surface fits are being performed which is often the case when RGBD point-cloud data is being analyzed for normal estimation, curvature estimation, polygonization or 3D segmentation applications. Using an integral image implementation, the proposed approaches show a significant increase in performance compared to the standard algebraic fitting approaches.
Is Pretraining Necessary for Hyperspectral Image Classification?
Jan 24, 2019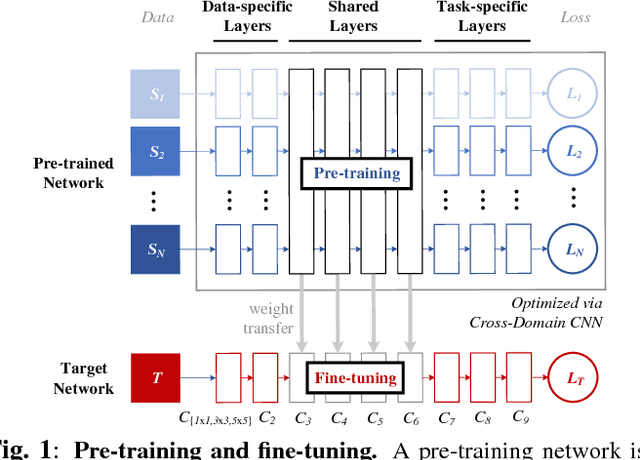
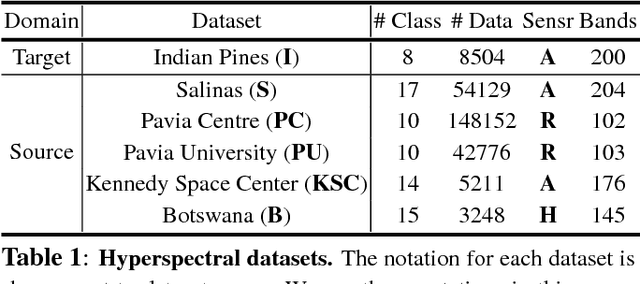

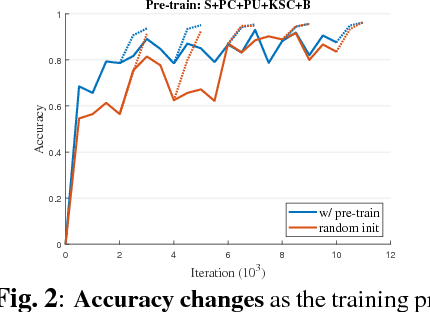
We address two questions for training a convolutional neural network (CNN) for hyperspectral image classification: i) is it possible to build a pre-trained network? and ii) is the pre-training effective in furthering the performance? To answer the first question, we have devised an approach that pre-trains a network on multiple source datasets that differ in their hyperspectral characteristics and fine-tunes on a target dataset. This approach effectively resolves the architectural issue that arises when transferring meaningful information between the source and the target networks. To answer the second question, we carried out several ablation experiments. Based on the experimental results, a network trained from scratch performs as good as a network fine-tuned from a pre-trained network. However, we observed that pre-training the network has its own advantage in achieving better performances when deeper networks are required.
Level Generation for Angry Birds with Sequential VAE and Latent Variable Evolution
Apr 13, 2021

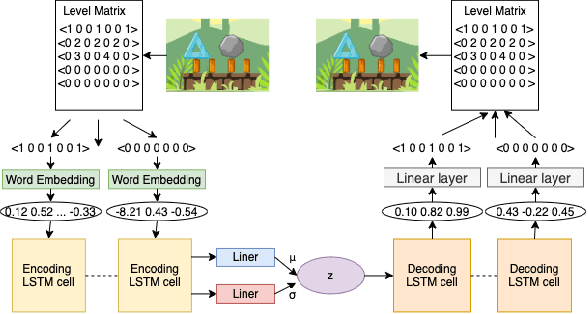

Video game level generation based on machine learning (ML), in particular, deep generative models, has attracted attention as a technique to automate level generation. However, applications of existing ML-based level generations are mostly limited to tile-based level representation. When ML techniques are applied to game domains with non-tile-based level representation, such as Angry Birds, where objects in a level are specified by real-valued parameters, ML often fails to generate playable levels. In this study, we develop a deep-generative-model-based level generation for the game domain of Angry Birds. To overcome these drawbacks, we propose a sequential encoding of a level and process it as text data, whereas existing approaches employ a tile-based encoding and process it as an image. Experiments show that the proposed level generator drastically improves the stability and diversity of generated levels compared with existing approaches. We apply latent variable evolution with the proposed generator to control the feature of a generated level computed through an AI agent's play, while keeping the level stable and natural.
Binary Constrained Deep Hashing Network for Image Retrieval without Manual Annotation
Aug 02, 2018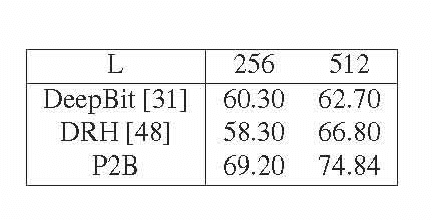
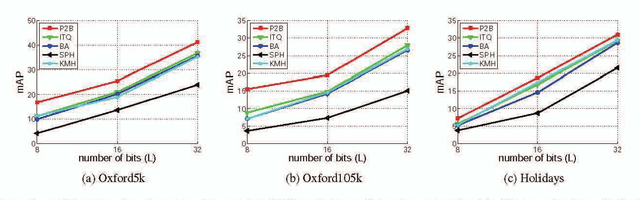
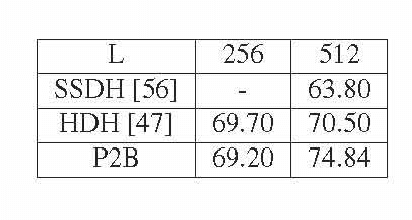
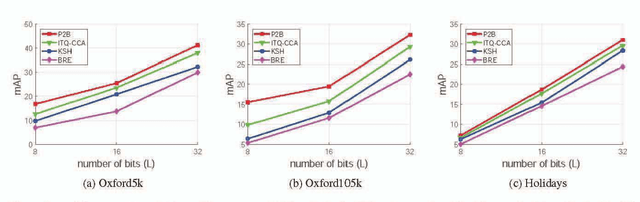
Learning compact binary codes for image retrieval problem using deep neural networks has attracted increasing attention recently. However, training deep hashing networks is challenging due to the binary constraints on the hash codes, the similarity preserving property, and the requirement for a vast amount of labelled images. To the best of our knowledge, none of the existing methods has tackled all of these challenges completely in a unified framework. In this work, we propose a novel end-to-end deep hashing approach, which is trained to produce binary codes directly from image pixels without the need of manual annotation. In particular, we propose a novel pairwise binary constrained loss function, which simultaneously encodes the distances between pairs of hash codes, and the binary quantization error. In order to train the network with the proposed loss function, we also propose an efficient parameter learning algorithm. In addition, to provide similar/dissimilar training images to train the network, we exploit 3D models reconstructed from unlabelled images for automatic generation of enormous similar/dissimilar pairs. Extensive experiments on three image retrieval benchmark datasets demonstrate the superior performance of the proposed method over the state-of-the-art hashing methods on the image retrieval problem.
Pulmonary embolism identification in computerized tomography pulmonary angiography scans with deep learning technologies in COVID-19 patients
May 28, 2021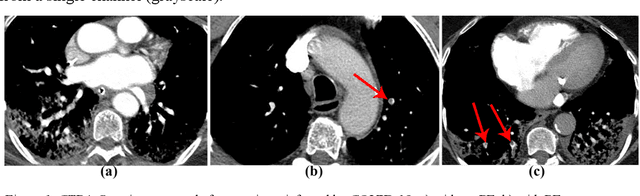
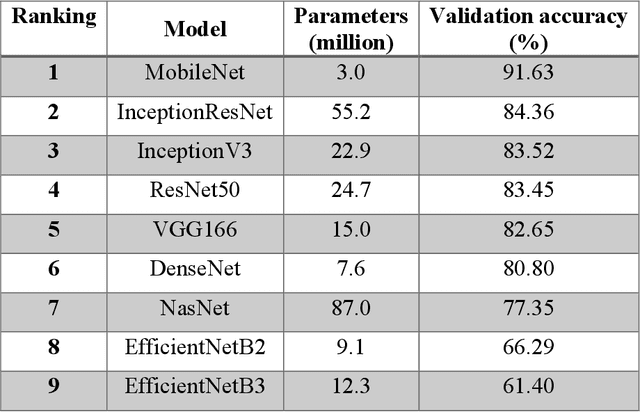
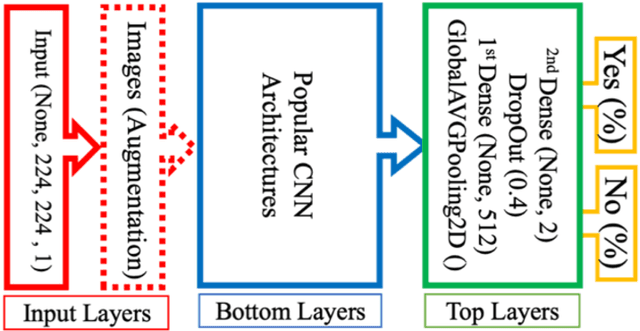
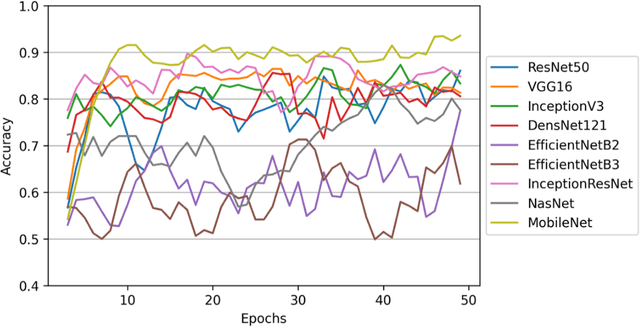
The main objective of this work is to utilize state-of-the-art deep learning approaches for the identification of pulmonary embolism in CTPA-Scans for COVID-19 patients, provide an initial assessment of their performance and, ultimately, provide a fast-track prototype solution (system). We adopted and assessed some of the most popular convolutional neural network architectures through transfer learning approaches, to strive to combine good model accuracy with fast training. Additionally, we exploited one of the most popular one-stage object detection models for the localization (through object detection) of the pulmonary embolism regions-of-interests. The models of both approaches are trained on an original CTPA-Scan dataset, where we annotated of 673 CTPA-Scan images with 1,465 bounding boxes in total, highlighting pulmonary embolism regions-of-interests. We provide a brief assessment of some state-of-the-art image classification models by achieving validation accuracies of 91% in pulmonary embolism classification. Additionally, we achieved a precision of about 68% on average in the object detection model for the pulmonary embolism localization under 50% IoU threshold. For both approaches, we provide the entire training pipelines for future studies (step by step processes through source code). In this study, we present some of the most accurate and fast deep learning models for pulmonary embolism identification in CTPA-Scans images, through classification and localization (object detection) approaches for patients infected by COVID-19. We provide a fast-track solution (system) for the research community of the area, which combines both classification and object detection models for improving the precision of identifying pulmonary embolisms.
Visibility Interpolation in Solar Hard X-ray Imaging: Application to RHESSI and STIX
Dec 27, 2020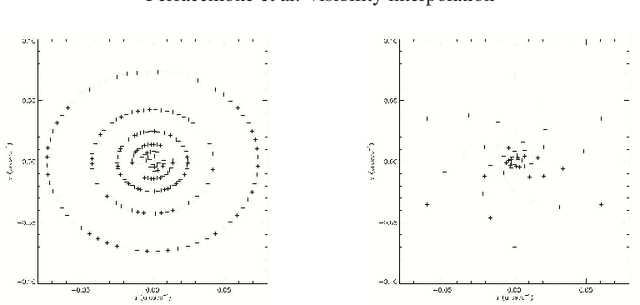
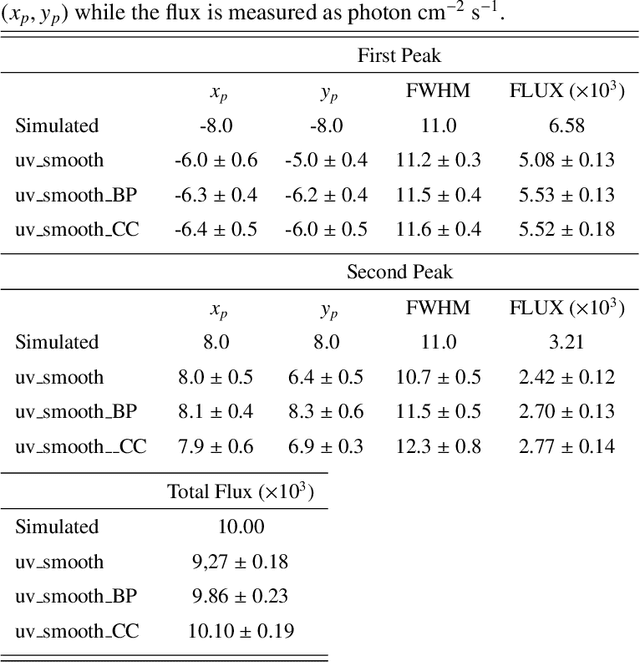
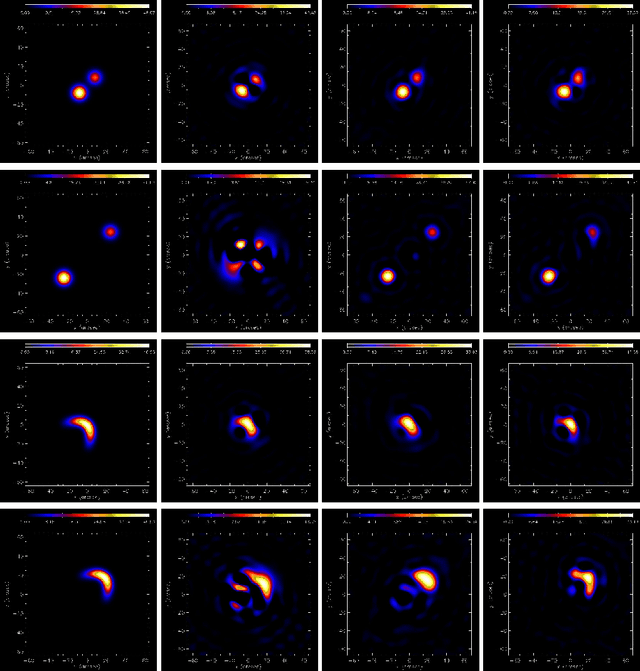
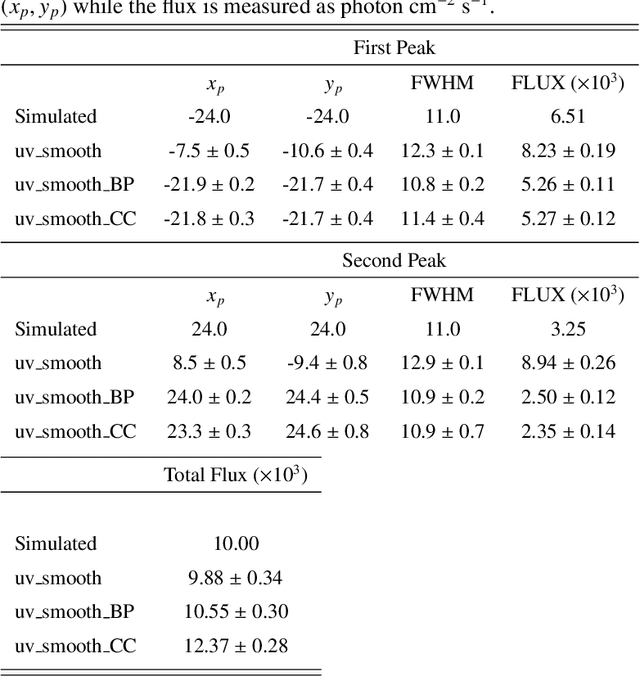
Space telescopes for solar hard X-ray imaging provide observations made of sampled Fourier components of the incoming photon flux. The aim of this study is to design an image reconstruction method relying on enhanced visibility interpolation in the Fourier domain. % methods heading (mandatory) The interpolation-based method is applied on synthetic visibilities generated by means of the simulation software implemented within the framework of the Spectrometer/Telescope for Imaging X-rays (STIX) mission on board Solar Orbiter. An application to experimental visibilities observed by the Reuven Ramaty High Energy Solar Spectroscopic Imager (RHESSI) is also considered. In order to interpolate these visibility data we have utilized an approach based on Variably Scaled Kernels (VSKs), which are able to realize feature augmentation by exploiting prior information on the flaring source and which are used here, for the first time, for image reconstruction purposes.} % results heading (mandatory) When compared to an interpolation-based reconstruction algorithm previously introduced for RHESSI, VSKs offer significantly better performances, particularly in the case of STIX imaging, which is characterized by a notably sparse sampling of the Fourier domain. In the case of RHESSI data, this novel approach is particularly reliable when either the flaring sources are characterized by narrow, ribbon-like shapes or high-resolution detectors are utilized for observations. % conclusions heading (optional), leave it empty if necessary The use of VSKs for interpolating hard X-ray visibilities allows a notable image reconstruction accuracy when the information on the flaring source is encoded by a small set of scattered Fourier data and when the visibility surface is affected by significant oscillations in the frequency domain.
Photoacoustic Reconstruction Using Sparsity in Curvelet Frame
Nov 26, 2020
We compare two approaches to photoacoustic image reconstruction from compressed/subsampled photoacoustic data based on assumption of sparsity in the Curvelet frame: DR, a two step approach based on the recovery of the complete volume of the photoacoustic data from the subsampled data followed by the acoustic inversion, and p0R, a one step approach where the photoacoustic image (the initial pressure, p0) is directly recovered from the subsampled data. For representation of the photoacoustic data, we propose a modification of the Curvelet transform corresponding to the restriction to the range of the photoacoustic forward operator. Both recovery problems are formulated in a variational framework. As the Curvelet frame is heavily overdetermined, we use reweighted l1 norm penalties to enhance the sparsity of the solution. The data reconstruction problem DR is a standard compressed sensing recovery problem, which we solve using an ADMM-type algorithm, SALSA. Subsequently, the initial pressure is recovered using time reversal as implemented in the k-Wave Toolbox. The p0 reconstruction problem, p0R, aims to recover the photoacoustic image directly via FISTA, or ADMM when in addition including a non-negativity constraint. We compare and discuss the relative merits of the two approaches and illustrate them on 2D simulated and 3D real data.
Unidentified Floating Object detection in maritime environment using dictionary learning
Jul 30, 2020

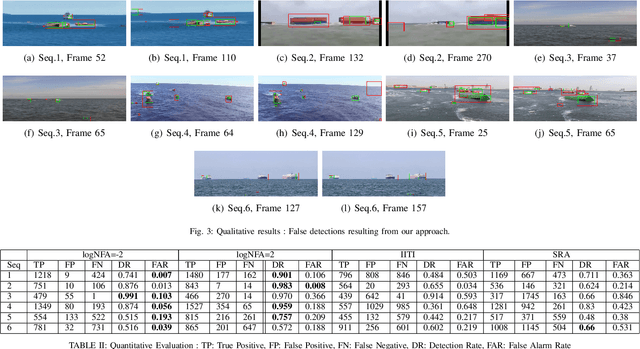

Maritime domain is one of the most challenging scenarios for object detection due to the complexity of the observed scene. In this article, we present a new approach to detect unidentified floating objects in the maritime environment. The proposed approach is capable of detecting floating objects without any prior knowledge of their visual appearance, shape or location. The input image from the video stream is denoised using a visual dictionary learned from a K-SVD algorithm. The denoised image is made of self-similar content. Later, we extract the residual image, which is the difference between the original image and the denoised (self-similar) image. Thus, the residual image contains noise and salient structures (objects). These salient structures can be extracted using an a contrario model. We demonstrate the capabilities of our algorithm by testing it on videos exhibiting varying maritime scenarios.
Continuous control of an underground loader using deep reinforcement learning
Mar 23, 2021
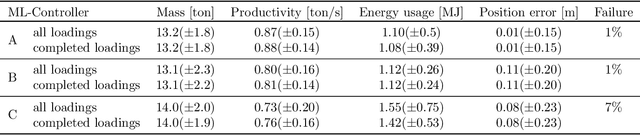

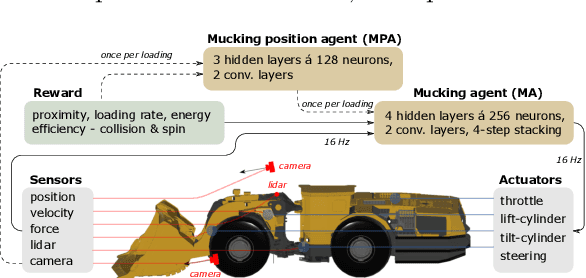
Reinforcement learning control of an underground loader is investigated in simulated environment, using a multi-agent deep neural network approach. At the start of each loading cycle, one agent selects the dig position from a depth camera image of the pile of fragmented rock. A second agent is responsible for continuous control of the vehicle, with the goal of filling the bucket at the selected loading point, while avoiding collisions, getting stuck, or losing ground traction. It relies on motion and force sensors, as well as on camera and lidar. Using a soft actor-critic algorithm the agents learn policies for efficient bucket filling over many subsequent loading cycles, with clear ability to adapt to the changing environment. The best results, on average 75% of the max capacity, are obtained when including a penalty for energy usage in the reward.