 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Perceptual Robust Hashing for Color Images with Canonical Correlation Analysis
Dec 08, 2020

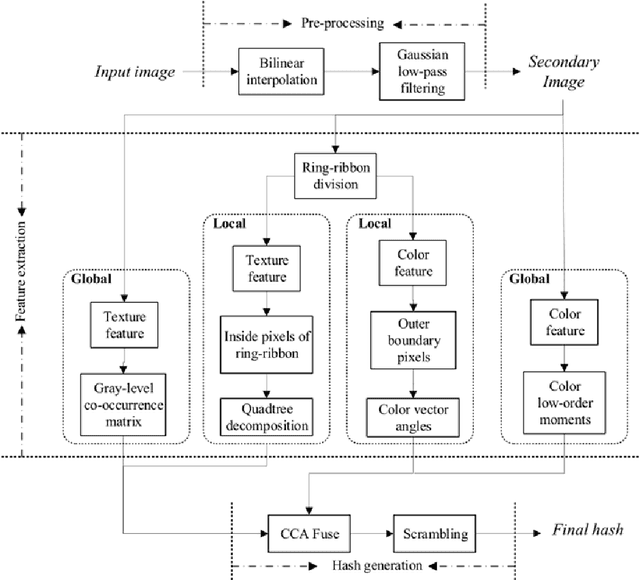
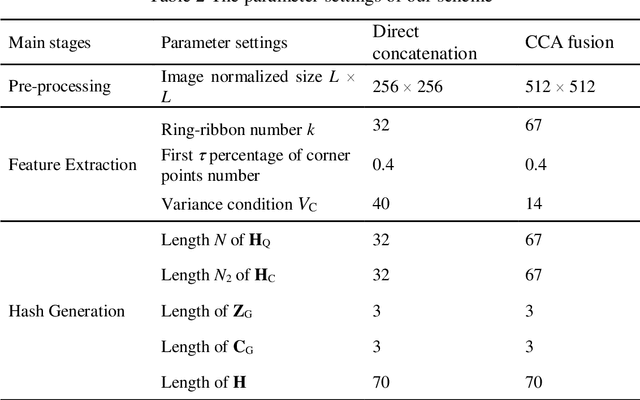

In this paper, a novel perceptual image hashing scheme for color images is proposed based on ring-ribbon quadtree and color vector angle. First, original image is subjected to normalization and Gaussian low-pass filtering to produce a secondary image, which is divided into a series of ring-ribbons with different radii and the same number of pixels. Then, both textural and color features are extracted locally and globally. Quadtree decomposition (QD) is applied on luminance values of the ring-ribbons to extract local textural features, and the gray level co-occurrence matrix (GLCM) is used to extract global textural features. Local color features of significant corner points on outer boundaries of ring-ribbons are extracted through color vector angles (CVA), and color low-order moments (CLMs) is utilized to extract global color features. Finally, two types of feature vectors are fused via canonical correlation analysis (CCA) to prodcue the final hash after scrambling. Compared with direct concatenation, the CCA feature fusion method improves classification performance, which better reflects overall correlation between two sets of feature vectors. Receiver operating characteristic (ROC) curve shows that our scheme has satisfactory performances with respect to robustness, discrimination and security, which can be effectively used in copy detection and content authentication.
Container: Context Aggregation Network
Jun 02, 2021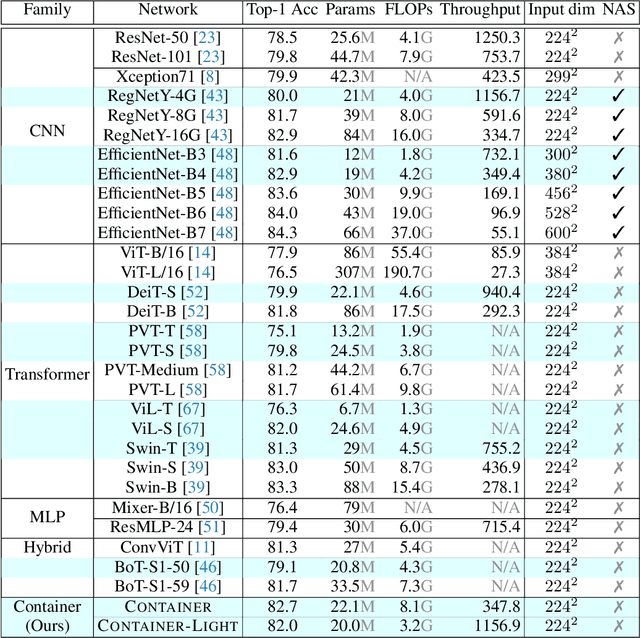
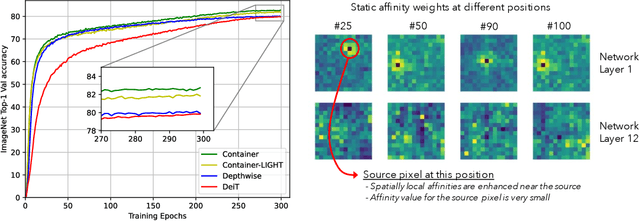
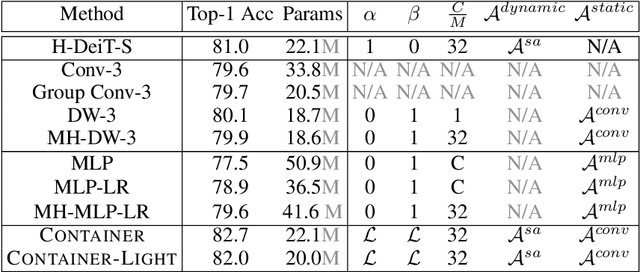
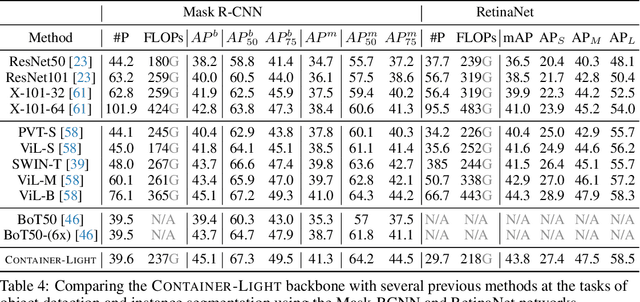
Convolutional neural networks (CNNs) are ubiquitous in computer vision, with a myriad of effective and efficient variations. Recently, Transformers -- originally introduced in natural language processing -- have been increasingly adopted in computer vision. While early adopters continue to employ CNN backbones, the latest networks are end-to-end CNN-free Transformer solutions. A recent surprising finding shows that a simple MLP based solution without any traditional convolutional or Transformer components can produce effective visual representations. While CNNs, Transformers and MLP-Mixers may be considered as completely disparate architectures, we provide a unified view showing that they are in fact special cases of a more general method to aggregate spatial context in a neural network stack. We present the \model (CONText AggregatIon NEtwoRk), a general-purpose building block for multi-head context aggregation that can exploit long-range interactions \emph{a la} Transformers while still exploiting the inductive bias of the local convolution operation leading to faster convergence speeds, often seen in CNNs. In contrast to Transformer-based methods that do not scale well to downstream tasks that rely on larger input image resolutions, our efficient network, named \modellight, can be employed in object detection and instance segmentation networks such as DETR, RetinaNet and Mask-RCNN to obtain an impressive detection mAP of 38.9, 43.8, 45.1 and mask mAP of 41.3, providing large improvements of 6.6, 7.3, 6.9 and 6.6 pts respectively, compared to a ResNet-50 backbone with a comparable compute and parameter size. Our method also achieves promising results on self-supervised learning compared to DeiT on the DINO framework.
Deep BCD-Net Using Identical Encoding-Decoding CNN Structures for Iterative Image Recovery
Apr 28, 2018
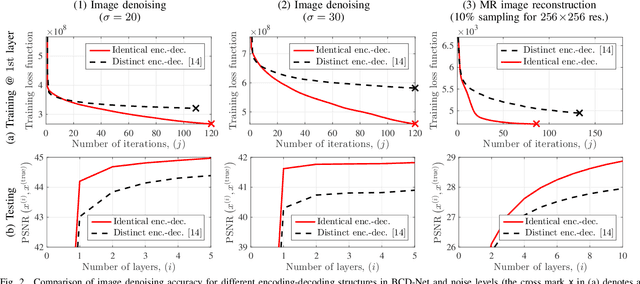
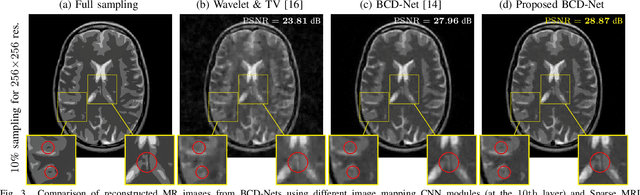
In "extreme" computational imaging that collects extremely undersampled or noisy measurements, obtaining an accurate image within a reasonable computing time is challenging. Incorporating image mapping convolutional neural networks (CNN) into iterative image recovery has great potential to resolve this issue. This paper 1) incorporates image mapping CNN using identical convolutional kernels in both encoders and decoders into a block coordinate descent (BCD) signal recovery method and 2) applies alternating direction method of multipliers to train the aforementioned image mapping CNN. We refer to the proposed recurrent network as BCD-Net using identical encoding-decoding CNN structures. Numerical experiments show that, for a) denoising low signal-to-noise-ratio images and b) extremely undersampled magnetic resonance imaging, the proposed BCD-Net achieves significantly more accurate image recovery, compared to BCD-Net using distinct encoding-decoding structures and/or the conventional image recovery model using both wavelets and total variation.
ISD: Self-Supervised Learning by Iterative Similarity Distillation
Dec 16, 2020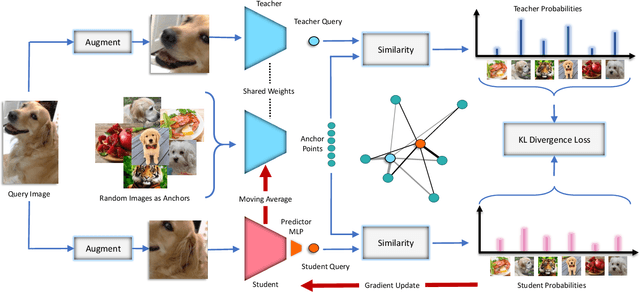
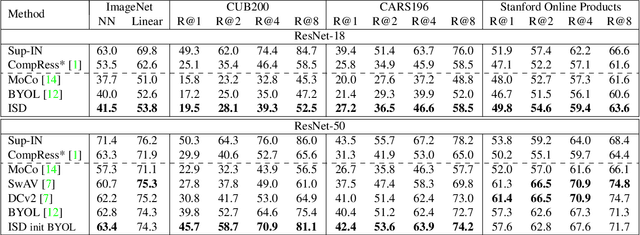

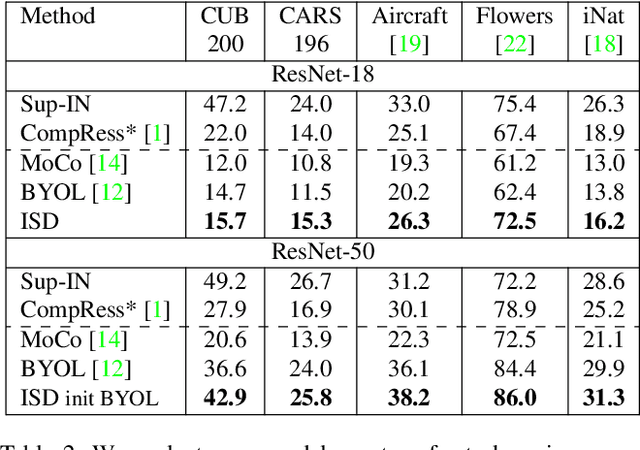
Recently, contrastive learning has achieved great results in self-supervised learning, where the main idea is to push two augmentations of an image (positive pairs) closer compared to other random images (negative pairs). We argue that not all random images are equal. Hence, we introduce a self supervised learning algorithm where we use a soft similarity for the negative images rather than a binary distinction between positive and negative pairs. We iteratively distill a slowly evolving teacher model to the student model by capturing the similarity of a query image to some random images and transferring that knowledge to the student. We argue that our method is less constrained compared to recent contrastive learning methods, so it can learn better features. Specifically, our method should handle unbalanced and unlabeled data better than existing contrastive learning methods, because the randomly chosen negative set might include many samples that are semantically similar to the query image. In this case, our method labels them as highly similar while standard contrastive methods label them as negative pairs. Our method achieves better results compared to state-of-the-art models like BYOL and MoCo on transfer learning settings. We also show that our method performs better in the settings where the unlabeled data is unbalanced. Our code is available here: https://github.com/UMBCvision/ISD.
Toward a Thinking Microscope: Deep Learning in Optical Microscopy and Image Reconstruction
May 23, 2018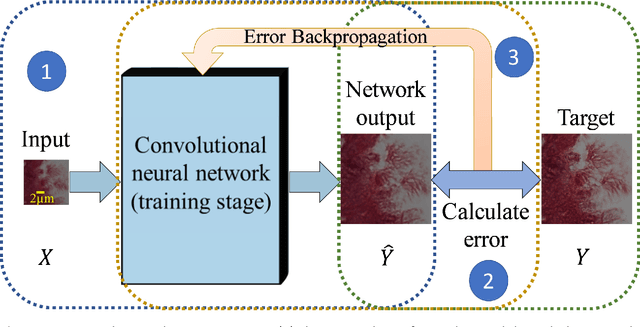
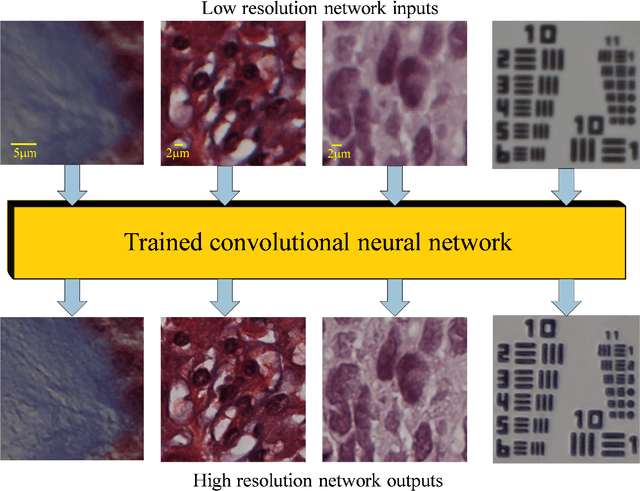
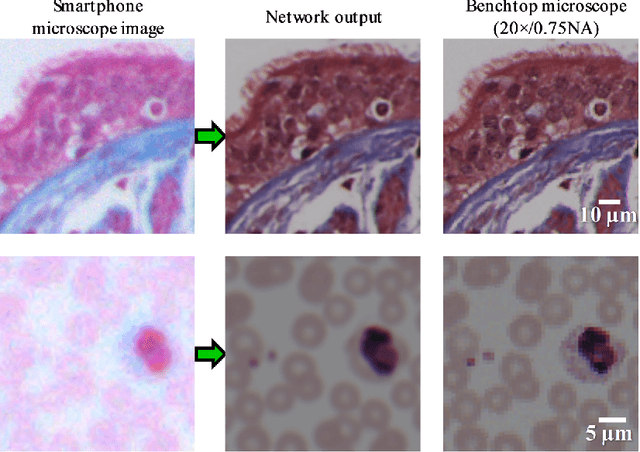

We discuss recently emerging applications of the state-of-art deep learning methods on optical microscopy and microscopic image reconstruction, which enable new transformations among different modes and modalities of microscopic imaging, driven entirely by image data. We believe that deep learning will fundamentally change both the hardware and image reconstruction methods used in optical microscopy in a holistic manner.
Performance analysis of facial recognition: A critical review through glass factor
Apr 04, 2021
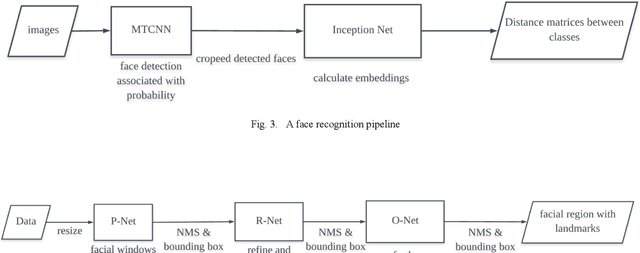
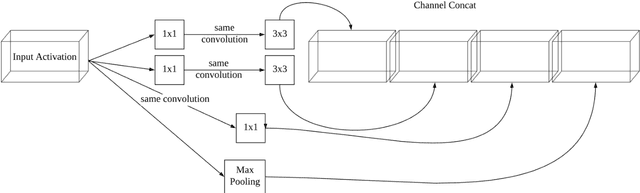

COVID-19 pandemic and social distancing urge a reliable human face recognition system in different abnormal situations. However, there is no research which studies the influence of glass factor in facial recognition system. This paper provides a comprehensive review of glass factor. The study contains two steps: data collection and accuracy test. Data collection includes collecting human face images through different situations, such as clear glasses, glass with water and glass with mist. Based on the collected data, an existing state-of-the-art face detection and recognition system built upon MTCNN and Inception V1 deep nets is tested for further analysis. Experimental data supports that 1) the system is robust for classification when comparing real-time images and 2) it fails at determining if two images are of same person by comparing real-time disturbed image with the frontal ones.
A Survey on Active Learning and Human-in-the-Loop Deep Learning for Medical Image Analysis
Oct 07, 2019


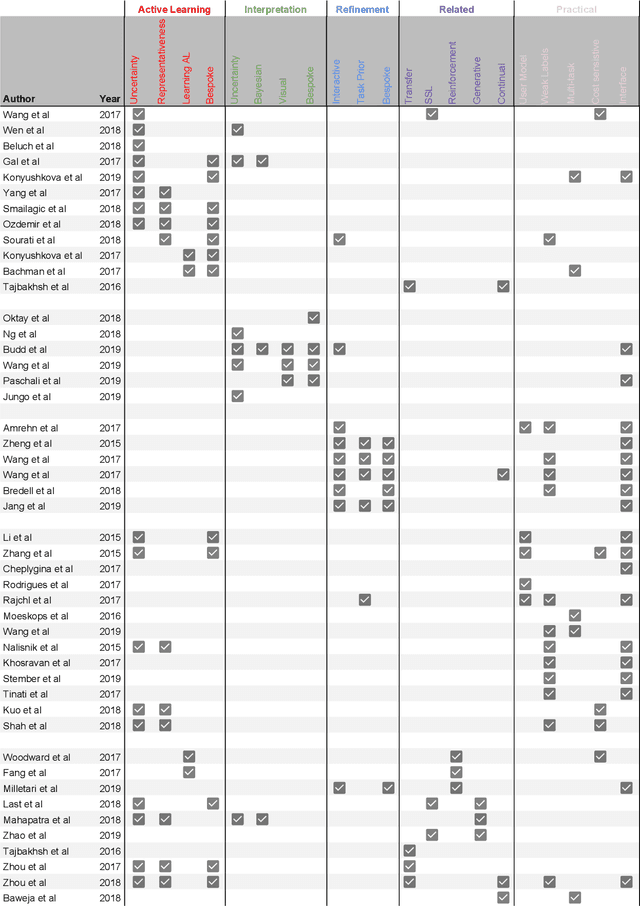
Fully automatic deep learning has become the state-of-the-art technique for many tasks including image acquisition, analysis and interpretation, and for the extraction of clinically useful information for computer-aided detection, diagnosis, treatment planning, intervention and therapy. However, the unique challenges posed by medical image analysis suggest that retaining a human end-user in any deep learning enabled system will be beneficial. In this review we investigate the role that humans might play in the development and deployment of deep learning enabled diagnostic applications and focus on techniques that will retain a significant input from a human end user. Human-in-the-Loop computing is an area that we see as increasingly important in future research due to the safety-critical nature of working in the medical domain. We evaluate four key areas that we consider vital for deep learning in the clinical practice: (1) Active Learning - to choose the best data to annotate for optimal model performance; (2) Interpretation and Refinement - using iterative feedback to steer models to optima for a given prediction and offering meaningful ways to interpret and respond to predictions; (3) Practical considerations - developing full scale applications and the key considerations that need to be made before deployment; (4) Related Areas - research fields that will benefit human-in-the-loop computing as they evolve. We offer our opinions on the most promising directions of research and how various aspects of each area might be unified towards common goals.
PGMAN: An Unsupervised Generative Multi-adversarial Network for Pan-sharpening
Dec 16, 2020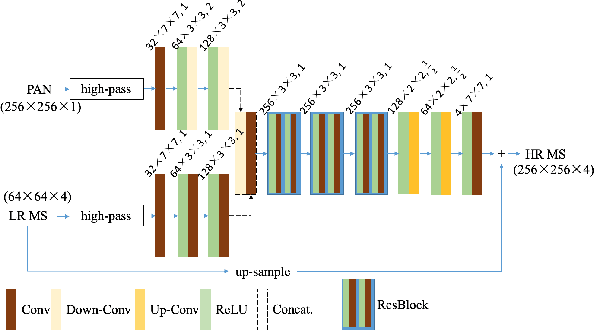
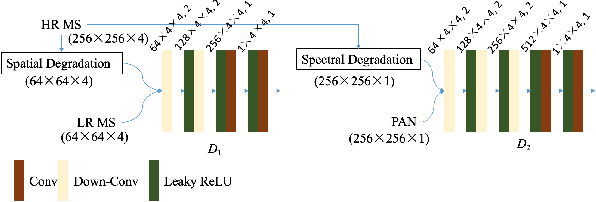


Pan-sharpening aims at fusing a low-resolution (LR) multi-spectral (MS) image and a high-resolution (HR) panchromatic (PAN) image acquired by a satellite to generate an HR MS image. Many deep learning based methods have been developed in the past few years. However, since there are no intended HR MS images as references for learning, almost all of the existing methods down-sample the MS and PAN images and regard the original MS images as targets to form a supervised setting for training. These methods may perform well on the down-scaled images, however, they generalize poorly to the full-resolution images. To conquer this problem, we design an unsupervised framework that is able to learn directly from the full-resolution images without any preprocessing. The model is built based on a novel generative multi-adversarial network. We use a two-stream generator to extract the modality-specific features from the PAN and MS images, respectively, and develop a dual-discriminator to preserve the spectral and spatial information of the inputs when performing fusion. Furthermore, a novel loss function is introduced to facilitate training under the unsupervised setting. Experiments and comparisons with other state-of-the-art methods on GaoFen-2 and QuickBird images demonstrate that the proposed method can obtain much better fusion results on the full-resolution images.
Style transfer-based image synthesis as an efficient regularization technique in deep learning
May 27, 2019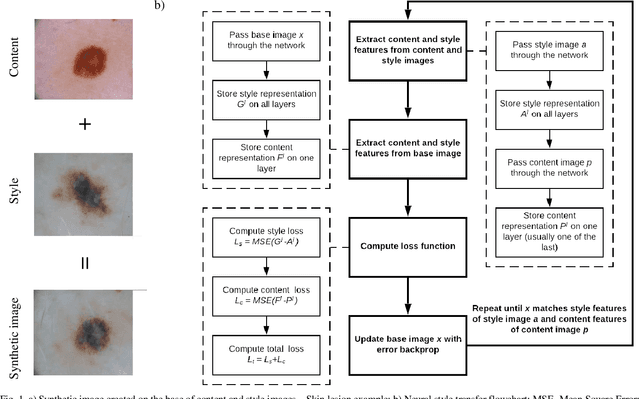
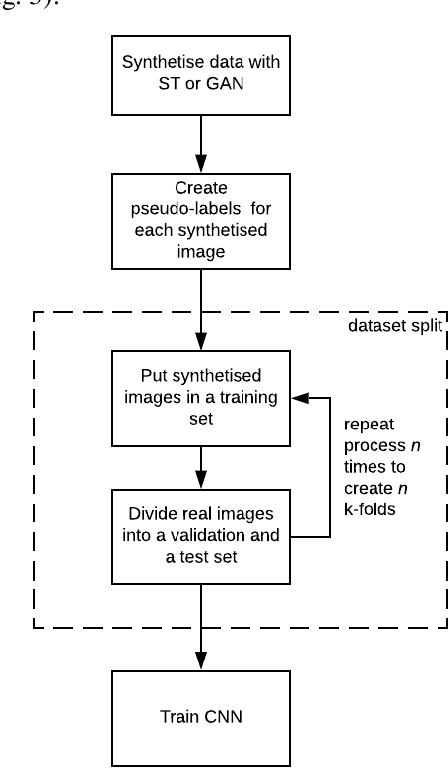
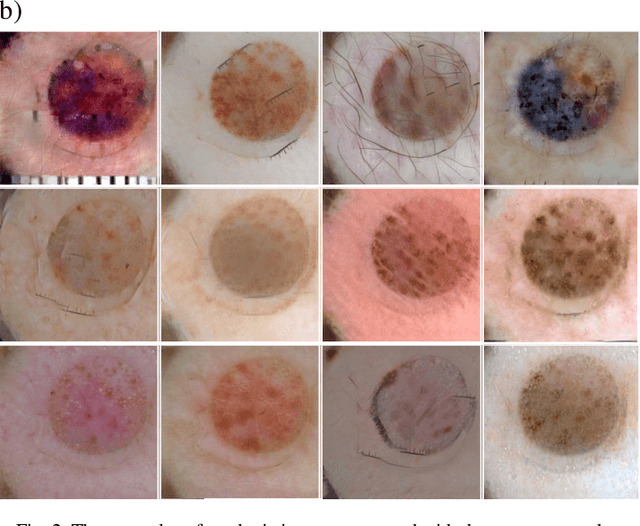
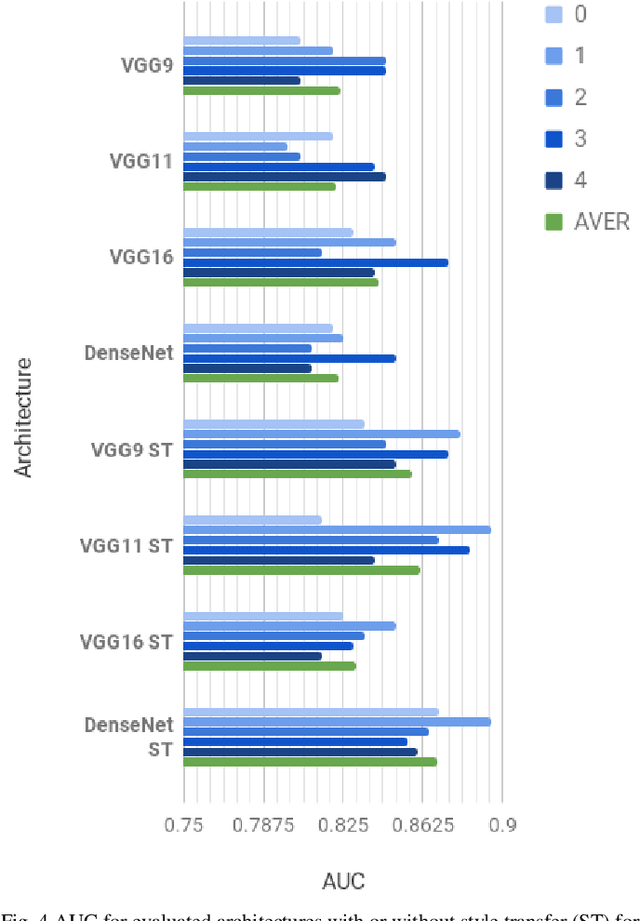
These days deep learning is the fastest-growing area in the field of Machine Learning. Convolutional Neural Networks are currently the main tool used for image analysis and classification purposes. Although great achievements and perspectives, deep neural networks and accompanying learning algorithms have some relevant challenges to tackle. In this paper, we have focused on the most frequently mentioned problem in the field of machine learning, that is relatively poor generalization abilities. Partial remedies for this are regularization techniques e.g. dropout, batch normalization, weight decay, transfer learning, early stopping and data augmentation. In this paper, we have focused on data augmentation. We propose to use a method based on a neural style transfer, which allows generating new unlabeled images of a high perceptual quality that combine the content of a base image with the appearance of another one. In a proposed approach, the newly created images are described with pseudo-labels, and then used as a training dataset. Real, labeled images are divided into the validation and test set. We validated the proposed method on a challenging skin lesion classification case study. Four representative neural architectures are examined. Obtained results show the strong potential of the proposed approach.
Weakly-Supervised Universal Lesion Segmentation with Regional Level Set Loss
May 03, 2021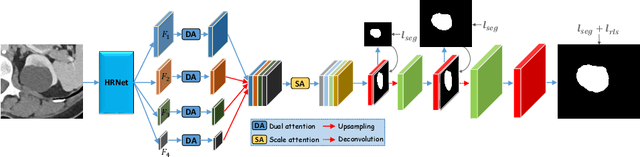
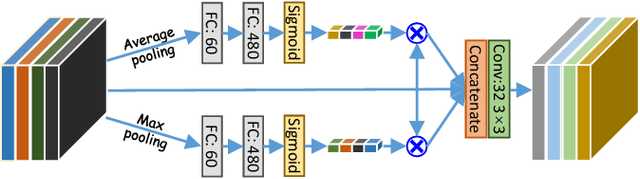
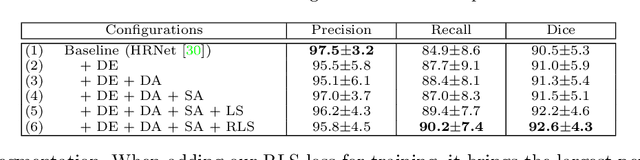
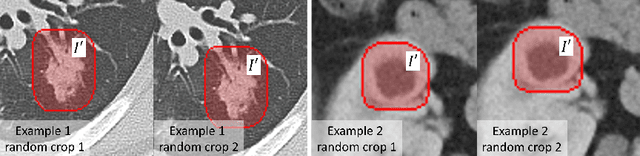
Accurately segmenting a variety of clinically significant lesions from whole body computed tomography (CT) scans is a critical task on precision oncology imaging, denoted as universal lesion segmentation (ULS). Manual annotation is the current clinical practice, being highly time-consuming and inconsistent on tumor's longitudinal assessment. Effectively training an automatic segmentation model is desirable but relies heavily on a large number of pixel-wise labelled data. Existing weakly-supervised segmentation approaches often struggle with regions nearby the lesion boundaries. In this paper, we present a novel weakly-supervised universal lesion segmentation method by building an attention enhanced model based on the High-Resolution Network (HRNet), named AHRNet, and propose a regional level set (RLS) loss for optimizing lesion boundary delineation. AHRNet provides advanced high-resolution deep image features by involving a decoder, dual-attention and scale attention mechanisms, which are crucial to performing accurate lesion segmentation. RLS can optimize the model reliably and effectively in a weakly-supervised fashion, forcing the segmentation close to lesion boundary. Extensive experimental results demonstrate that our method achieves the best performance on the publicly large-scale DeepLesion dataset and a hold-out test set.