 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
An Automatic Cardiac Segmentation Framework based on Multi-sequence MR Image
Sep 12, 2019
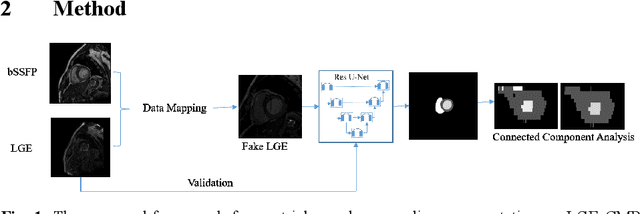
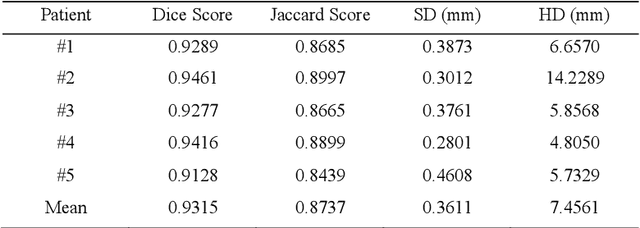
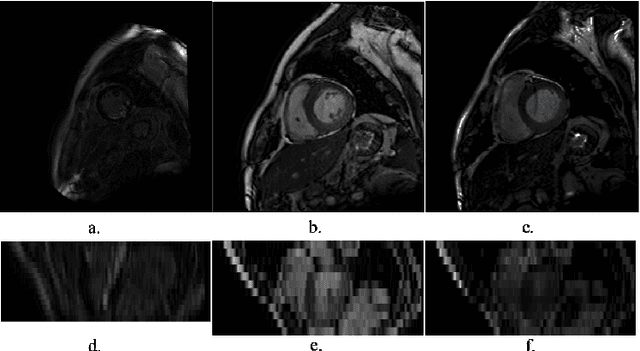
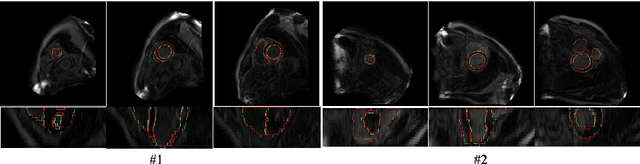
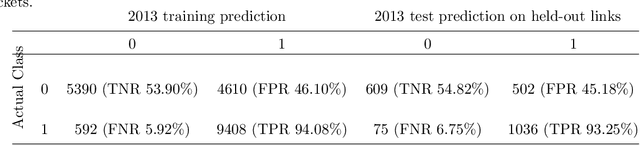
LGE CMR is an efficient technology for detecting infarcted myocardium. An efficient and objective ventricle segmentation method in LGE can benefit the location of the infarcted myocardium. In this paper, we proposed an automatic framework for LGE image segmentation. There are just 5 labeled LGE volumes with about 15 slices of each volume. We adopted histogram match, an invariant of rotation registration method, on the other labeled modalities to achieve effective augmentation of the training data. A CNN segmentation model was trained based on the augmented training data by leave-one-out strategy. The predicted result of the model followed a connected component analysis for each class to remain the largest connected component as the final segmentation result. Our model was evaluated by the 2019 Multi-sequence Cardiac MR Segmentation Challenge. The mean testing result of 40 testing volumes on Dice score, Jaccard score, Surface distance, and Hausdorff distance is 0.8087, 0.6976, 2.8727mm, and 15.6387mm, respectively. The experiment result shows a satisfying performance of the proposed framework. Code is available at https://github.com/Suiiyu/MS-CMR2019.
* accepted by STACOM 2019
Joint Autoregressive and Hierarchical Priors for Learned Image Compression
Sep 08, 2018

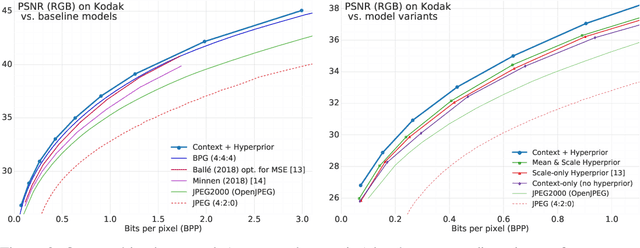
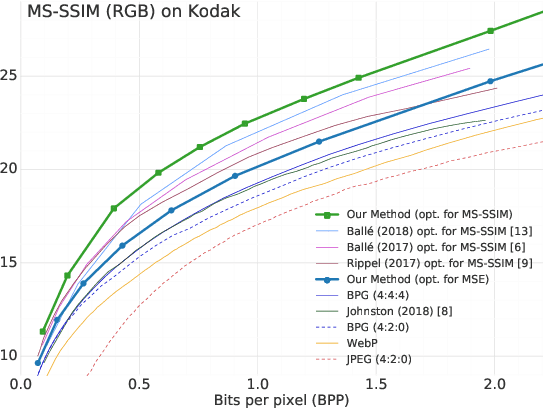
Recent models for learned image compression are based on autoencoders, learning approximately invertible mappings from pixels to a quantized latent representation. These are combined with an entropy model, a prior on the latent representation that can be used with standard arithmetic coding algorithms to yield a compressed bitstream. Recently, hierarchical entropy models have been introduced as a way to exploit more structure in the latents than simple fully factorized priors, improving compression performance while maintaining end-to-end optimization. Inspired by the success of autoregressive priors in probabilistic generative models, we examine autoregressive, hierarchical, as well as combined priors as alternatives, weighing their costs and benefits in the context of image compression. While it is well known that autoregressive models come with a significant computational penalty, we find that in terms of compression performance, autoregressive and hierarchical priors are complementary and, together, exploit the probabilistic structure in the latents better than all previous learned models. The combined model yields state-of-the-art rate--distortion performance, providing a 15.8% average reduction in file size over the previous state-of-the-art method based on deep learning, which corresponds to a 59.8% size reduction over JPEG, more than 35% reduction compared to WebP and JPEG2000, and bitstreams 8.4% smaller than BPG, the current state-of-the-art image codec. To the best of our knowledge, our model is the first learning-based method to outperform BPG on both PSNR and MS-SSIM distortion metrics.
Balancing Constraints and Submodularity in Data Subset Selection
Apr 26, 2021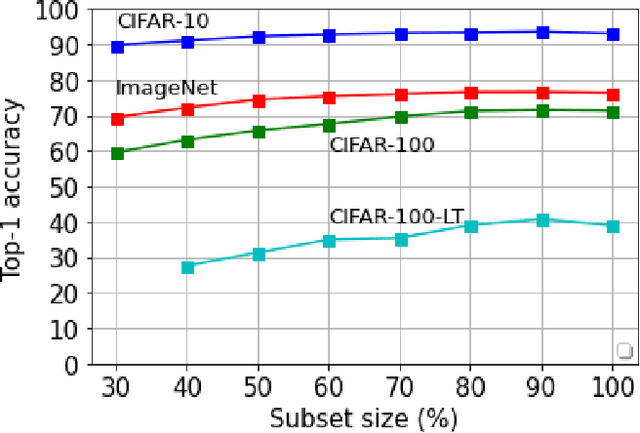
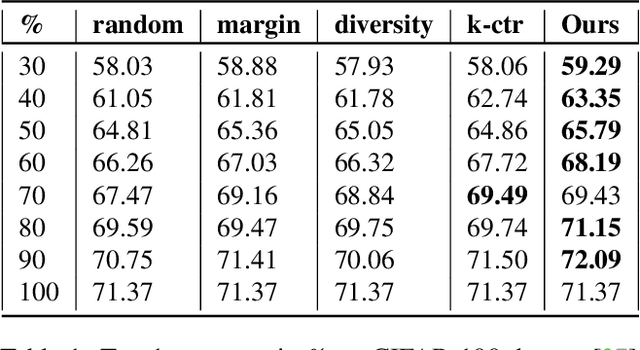
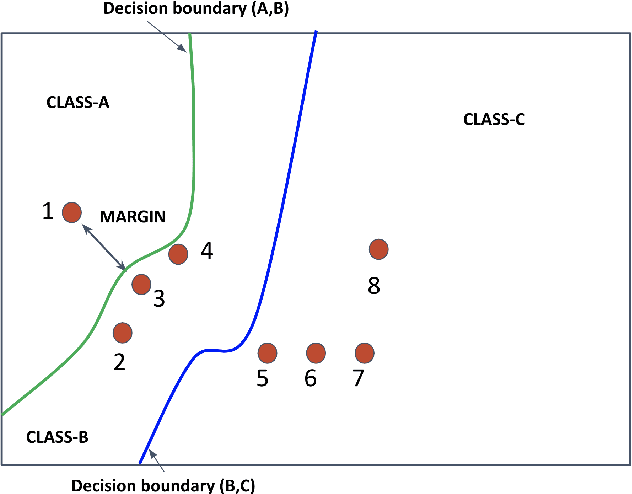
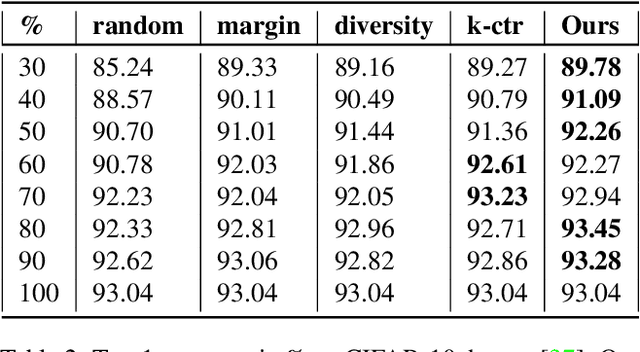
Deep learning has yielded extraordinary results in vision and natural language processing, but this achievement comes at a cost. Most deep learning models require enormous resources during training, both in terms of computation and in human labeling effort. In this paper, we show that one can achieve similar accuracy to traditional deep-learning models, while using less training data. Much of the previous work in this area relies on using uncertainty or some form of diversity to select subsets of a larger training set. Submodularity, a discrete analogue of convexity, has been exploited to model diversity in various settings including data subset selection. In contrast to prior methods, we propose a novel diversity driven objective function, and balancing constraints on class labels and decision boundaries using matroids. This allows us to use efficient greedy algorithms with approximation guarantees for subset selection. We outperform baselines on standard image classification datasets such as CIFAR-10, CIFAR-100, and ImageNet. In addition, we also show that the proposed balancing constraints can play a key role in boosting the performance in long-tailed datasets such as CIFAR-100-LT.
Detecting Adversarial Examples by Input Transformations, Defense Perturbations, and Voting
Jan 27, 2021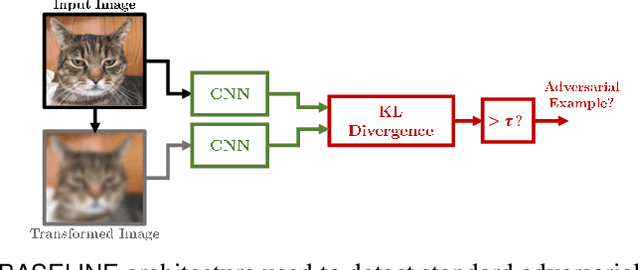

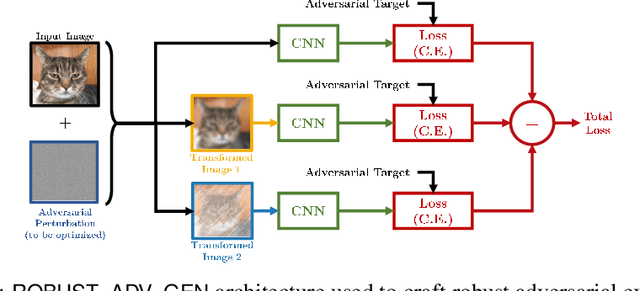
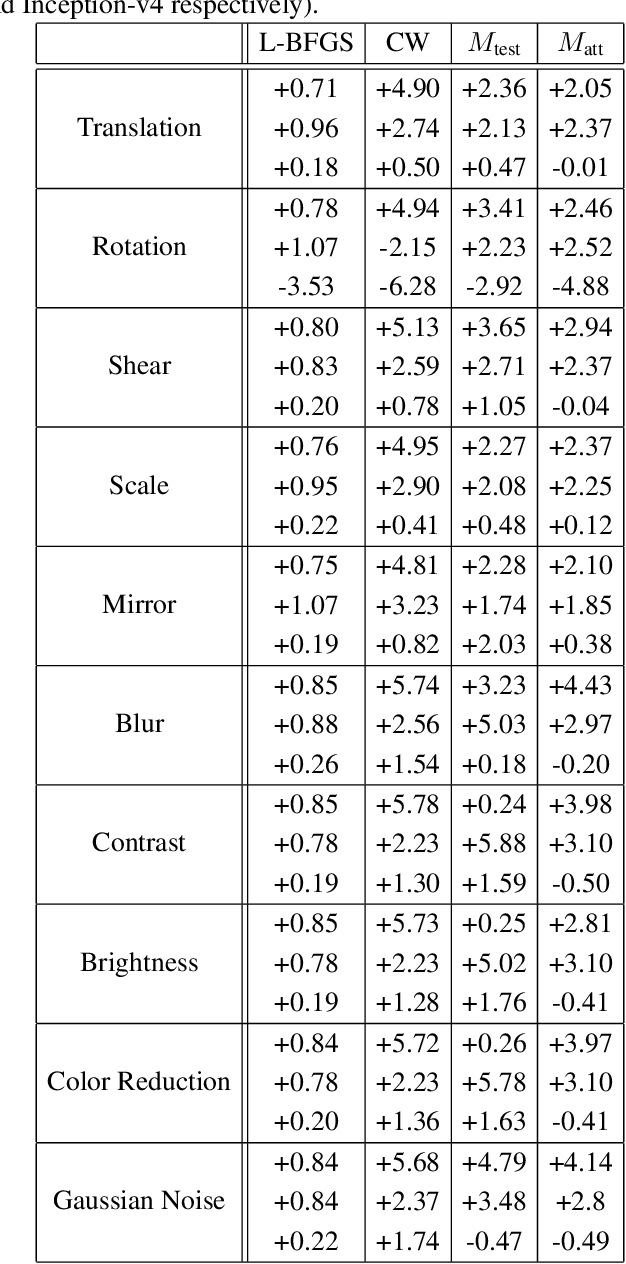
Over the last few years, convolutional neural networks (CNNs) have proved to reach super-human performance in visual recognition tasks. However, CNNs can easily be fooled by adversarial examples, i.e., maliciously-crafted images that force the networks to predict an incorrect output while being extremely similar to those for which a correct output is predicted. Regular adversarial examples are not robust to input image transformations, which can then be used to detect whether an adversarial example is presented to the network. Nevertheless, it is still possible to generate adversarial examples that are robust to such transformations. This paper extensively explores the detection of adversarial examples via image transformations and proposes a novel methodology, called \textit{defense perturbation}, to detect robust adversarial examples with the same input transformations the adversarial examples are robust to. Such a \textit{defense perturbation} is shown to be an effective counter-measure to robust adversarial examples. Furthermore, multi-network adversarial examples are introduced. This kind of adversarial examples can be used to simultaneously fool multiple networks, which is critical in systems that use network redundancy, such as those based on architectures with majority voting over multiple CNNs. An extensive set of experiments based on state-of-the-art CNNs trained on the Imagenet dataset is finally reported.
Slower is Better: Revisiting the Forgetting Mechanism in LSTM for Slower Information Decay
May 12, 2021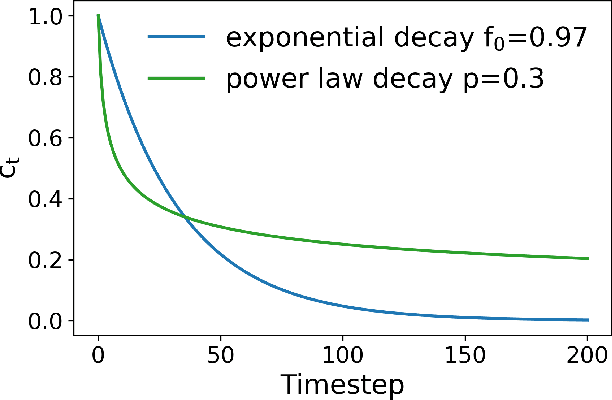
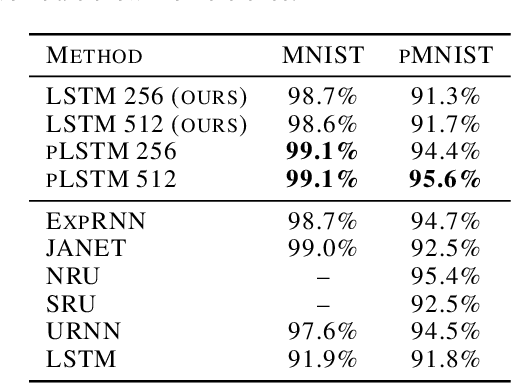
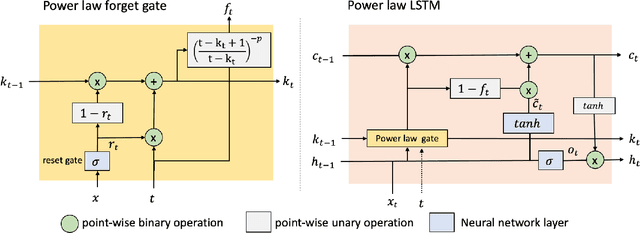
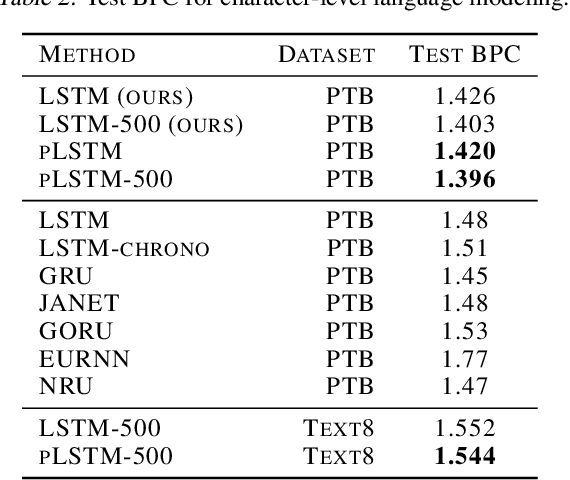
Sequential information contains short- to long-range dependencies; however, learning long-timescale information has been a challenge for recurrent neural networks. Despite improvements in long short-term memory networks (LSTMs), the forgetting mechanism results in the exponential decay of information, limiting their capacity to capture long-timescale information. Here, we propose a power law forget gate, which instead learns to forget information along a slower power law decay function. Specifically, the new gate learns to control the power law decay factor, p, allowing the network to adjust the information decay rate according to task demands. Our experiments show that an LSTM with power law forget gates (pLSTM) can effectively capture long-range dependencies beyond hundreds of elements on image classification, language modeling, and categorization tasks, improving performance over the vanilla LSTM. We also inspected the revised forget gate by varying the initialization of p, setting p to a fixed value, and ablating cells in the pLSTM network. The results show that the information decay can be controlled by the learnable decay factor p, which allows pLSTM to achieve its superior performance. Altogether, we found that LSTM with the proposed forget gate can learn long-term dependencies, outperforming other recurrent networks in multiple domains; such gating mechanism can be integrated into other architectures for improving the learning of long timescale information in recurrent neural networks.
Segmentation overlapping wear particles with few labelled data and imbalance sample
Nov 20, 2020
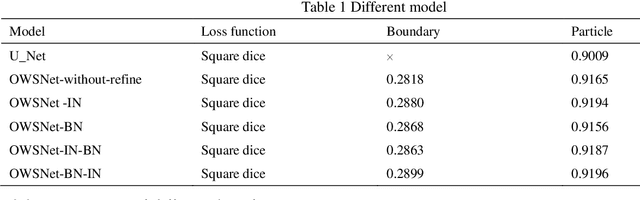
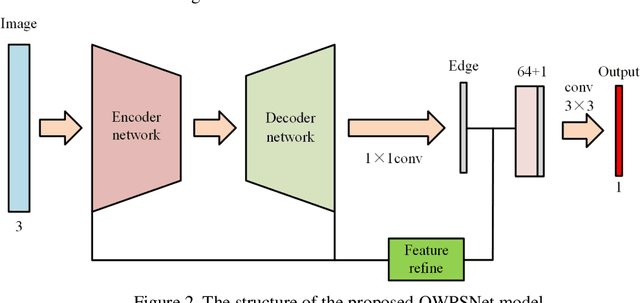

Ferrograph image segmentation is of significance for obtaining features of wear particles. However, wear particles are usually overlapped in the form of debris chains, which makes challenges to segment wear debris. An overlapping wear particle segmentation network (OWPSNet) is proposed in this study to segment the overlapped debris chains. The proposed deep learning model includes three parts: a region segmentation network, an edge detection network and a feature refine module. The region segmentation network is an improved U shape network, and it is applied to separate the wear debris form background of ferrograph image. The edge detection network is used to detect the edges of wear particles. Then, the feature refine module combines low-level features and high-level semantic features to obtain the final results. In order to solve the problem of sample imbalance, we proposed a square dice loss function to optimize the model. Finally, extensive experiments have been carried out on a ferrograph image dataset. Results show that the proposed model is capable of separating overlapping wear particles. Moreover, the proposed square dice loss function can improve the segmentation results, especially for the segmentation results of wear particle edge.
3D-GMNet: Learning to Estimate 3D Shape from A Single Image As A Gaussian Mixture
Dec 10, 2019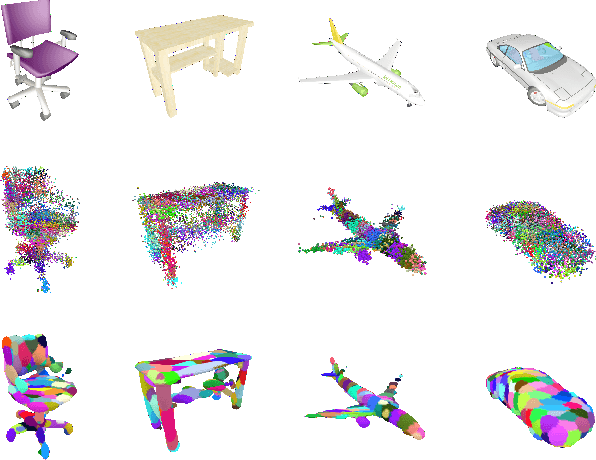

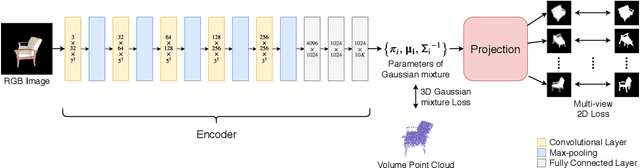

In this paper, we introduce 3D-GMNet, a deep neural network for single-image 3D shape recovery. As the name suggests, 3D-GMNet recovers 3D shape as a Gaussian mixture model. In contrast to voxels, point clouds, or meshes, a Gaussian mixture representation requires a much smaller footprint for representing 3D shapes and, at the same time, offers a number of additional advantages including instant pose estimation, automatic level-of-detail computation, and a distance measure. The proposed 3D-GMNet is trained end-to-end with single input images and corresponding 3D models by using two novel loss functions: a 3D Gaussian mixture loss and a multi-view 2D loss. The first maximizes the likelihood of the Gaussian mixture shape representation by considering the target point cloud as samples from the true distribution, and the latter improves the consistency between the input silhouette and the projection of the Gaussian mixture shape model. Extensive quantitative evaluations with synthesized and real images demonstrate the effectiveness of the proposed method.
A Graph Neural Network Approach for Product Relationship Prediction
May 12, 2021
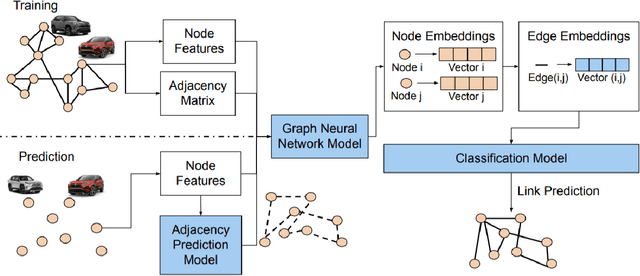
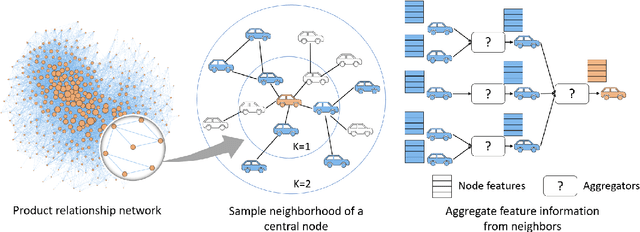
Graph Neural Networks have revolutionized many machine learning tasks in recent years, ranging from drug discovery, recommendation systems, image classification, social network analysis to natural language understanding. This paper shows their efficacy in modeling relationships between products and making predictions for unseen product networks. By representing products as nodes and their relationships as edges of a graph, we show how an inductive graph neural network approach, named GraphSAGE, can efficiently learn continuous representations for nodes and edges. These representations also capture product feature information such as price, brand, or engineering attributes. They are combined with a classification model for predicting the existence of the relationship between products. Using a case study of the Chinese car market, we find that our method yields double the prediction performance compared to an Exponential Random Graph Model-based method for predicting the co-consideration relationship between cars. While a vanilla GraphSAGE requires a partial network to make predictions, we introduce an `adjacency prediction model' to circumvent this limitation. This enables us to predict product relationships when no neighborhood information is known. Finally, we demonstrate how a permutation-based interpretability analysis can provide insights on how design attributes impact the predictions of relationships between products. This work provides a systematic method to predict the relationships between products in many different markets.
Visual-Semantic Embedding Model Informed by Structured Knowledge
Sep 21, 2020
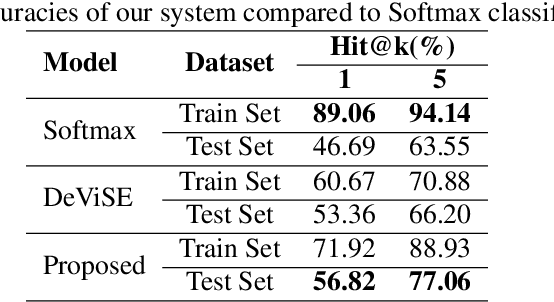
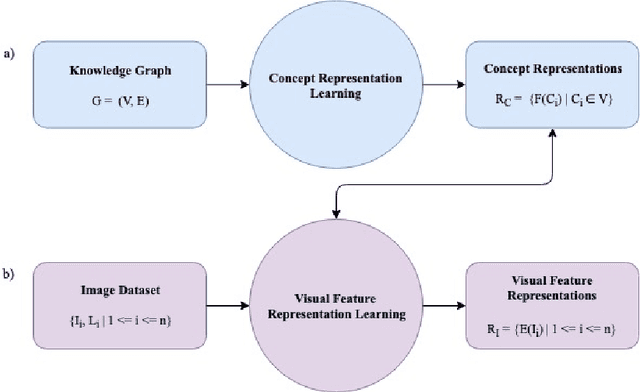

We propose a novel approach to improve a visual-semantic embedding model by incorporating concept representations captured from an external structured knowledge base. We investigate its performance on image classification under both standard and zero-shot settings. We propose two novel evaluation frameworks to analyse classification errors with respect to the class hierarchy indicated by the knowledge base. The approach is tested using the ILSVRC 2012 image dataset and a WordNet knowledge base. With respect to both standard and zero-shot image classification, our approach shows superior performance compared with the original approach, which uses word embeddings.
RoBIC: A benchmark suite for assessing classifiers robustness
Feb 10, 2021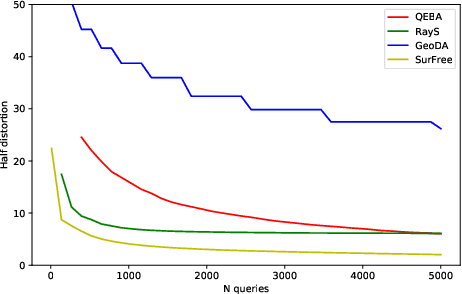
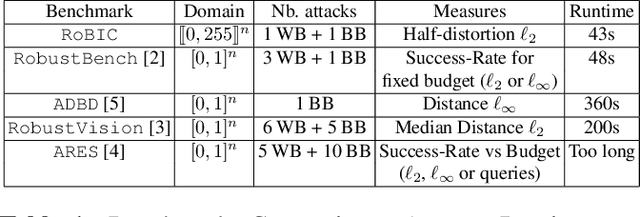
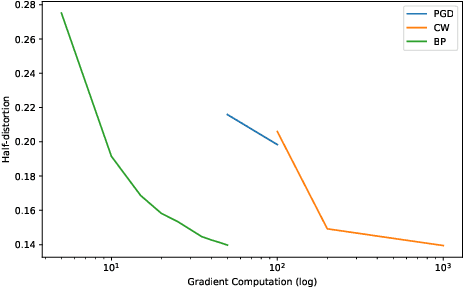
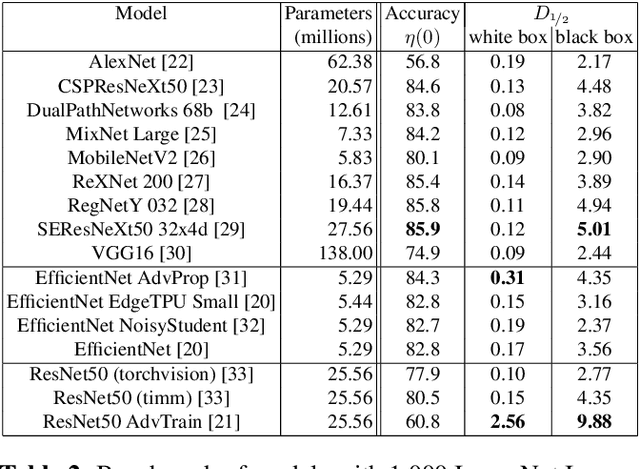
Many defenses have emerged with the development of adversarial attacks. Models must be objectively evaluated accordingly. This paper systematically tackles this concern by proposing a new parameter-free benchmark we coin RoBIC. RoBIC fairly evaluates the robustness of image classifiers using a new half-distortion measure. It gauges the robustness of the network against white and black box attacks, independently of its accuracy. RoBIC is faster than the other available benchmarks. We present the significant differences in the robustness of 16 recent models as assessed by RoBIC.