 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Semi-Supervised Few-Shot Classification with Deep Invertible Hybrid Models
May 22, 2021
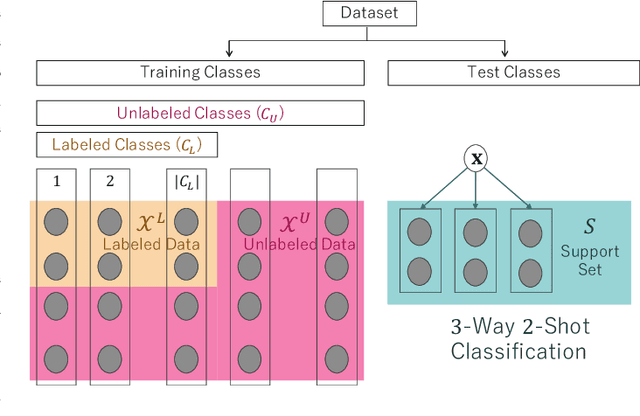
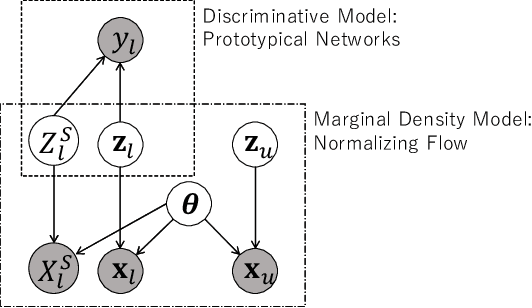
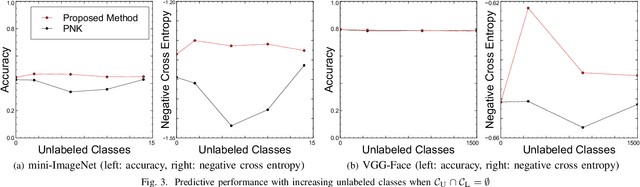
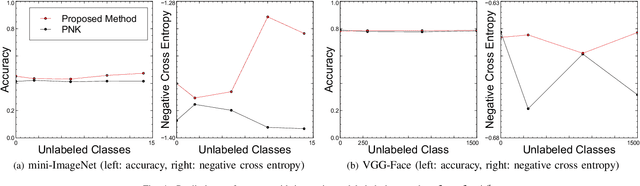
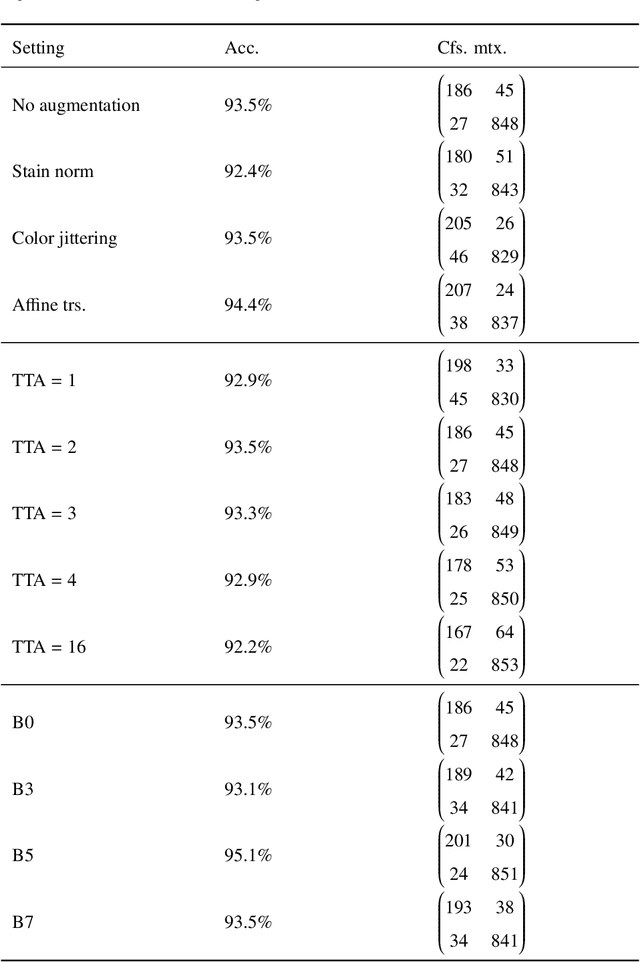
In this paper, we propose a deep invertible hybrid model which integrates discriminative and generative learning at a latent space level for semi-supervised few-shot classification. Various tasks for classifying new species from image data can be modeled as a semi-supervised few-shot classification, which assumes a labeled and unlabeled training examples and a small support set of the target classes. Predicting target classes with a few support examples per class makes the learning task difficult for existing semi-supervised classification methods, including selftraining, which iteratively estimates class labels of unlabeled training examples to learn a classifier for the training classes. To exploit unlabeled training examples effectively, we adopt as the objective function the composite likelihood, which integrates discriminative and generative learning and suits better with deep neural networks than the parameter coupling prior, the other popular integrated learning approach. In our proposed model, the discriminative and generative models are respectively Prototypical Networks, which have shown excellent performance in various kinds of few-shot learning, and Normalizing Flow a deep invertible model which returns the exact marginal likelihood unlike the other three major methods, i.e., VAE, GAN, and autoregressive model. Our main originality lies in our integration of these components at a latent space level, which is effective in preventing overfitting. Experiments using mini-ImageNet and VGG-Face datasets show that our method outperforms selftraining based Prototypical Networks.
High Definition image classification in Geoscience using Machine Learning
Sep 25, 2020
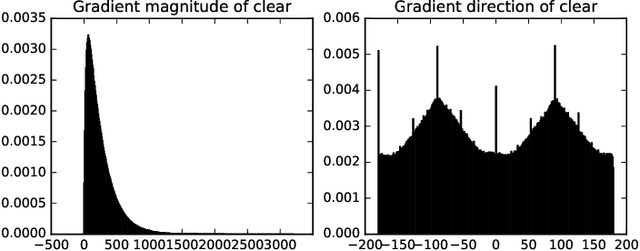
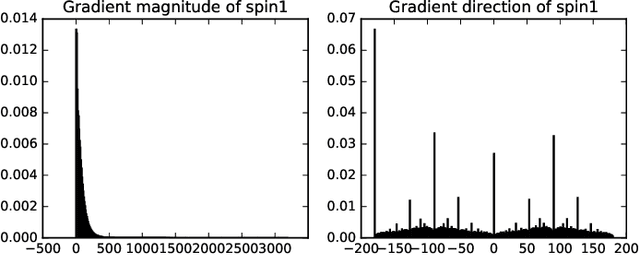

High Definition (HD) digital photos taken with drones are widely used in the study of Geoscience. However, blurry images are often taken in collected data, and it takes a lot of time and effort to distinguish clear images from blurry ones. In this work, we apply Machine learning techniques, such as Support Vector Machine (SVM) and Neural Network (NN) to classify HD images in Geoscience as clear and blurry, and therefore automate data cleaning in Geoscience. We compare the results of classification based on features abstracted from several mathematical models. Some of the implementation of our machine learning tool is freely available at: https://github.com/zachgolden/geoai.
Rank-One Prior: Toward Real-Time Scene Recovery
Mar 31, 2021

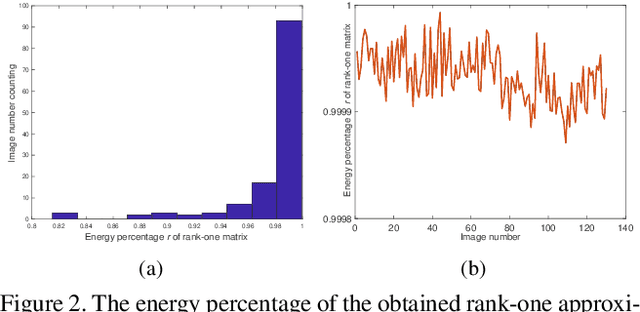
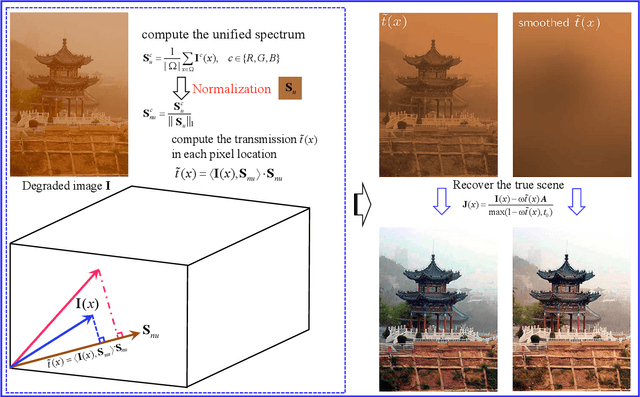
Scene recovery is a fundamental imaging task for several practical applications, e.g., video surveillance and autonomous vehicles, etc. To improve visual quality under different weather/imaging conditions, we propose a real-time light correction method to recover the degraded scenes in the cases of sandstorms, underwater, and haze. The heart of our work is that we propose an intensity projection strategy to estimate the transmission. This strategy is motivated by a straightforward rank-one transmission prior. The complexity of transmission estimation is $O(N)$ where $N$ is the size of the single image. Then we can recover the scene in real-time. Comprehensive experiments on different types of weather/imaging conditions illustrate that our method outperforms competitively several state-of-the-art imaging methods in terms of efficiency and robustness.
RUArt: A Novel Text-Centered Solution for Text-Based Visual Question Answering
Oct 24, 2020
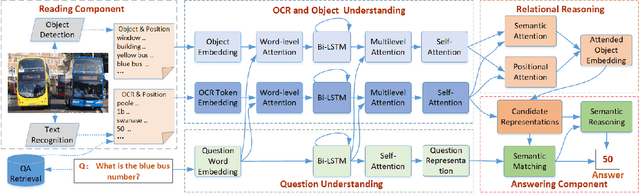

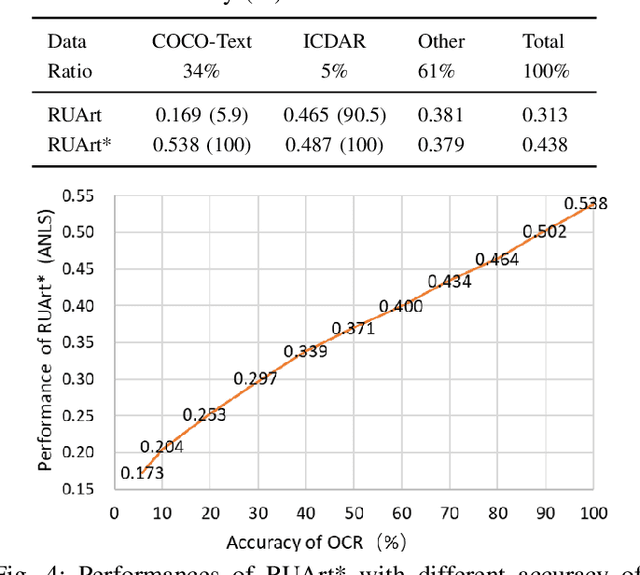
Text-based visual question answering (VQA) requires to read and understand text in an image to correctly answer a given question. However, most current methods simply add optical character recognition (OCR) tokens extracted from the image into the VQA model without considering contextual information of OCR tokens and mining the relationships between OCR tokens and scene objects. In this paper, we propose a novel text-centered method called RUArt (Reading, Understanding and Answering the Related Text) for text-based VQA. Taking an image and a question as input, RUArt first reads the image and obtains text and scene objects. Then, it understands the question, OCRed text and objects in the context of the scene, and further mines the relationships among them. Finally, it answers the related text for the given question through text semantic matching and reasoning. We evaluate our RUArt on two text-based VQA benchmarks (ST-VQA and TextVQA) and conduct extensive ablation studies for exploring the reasons behind RUArt's effectiveness. Experimental results demonstrate that our method can effectively explore the contextual information of the text and mine the stable relationships between the text and objects.
Overcoming the limitations of patch-based learning to detect cancer in whole slide images
Dec 01, 2020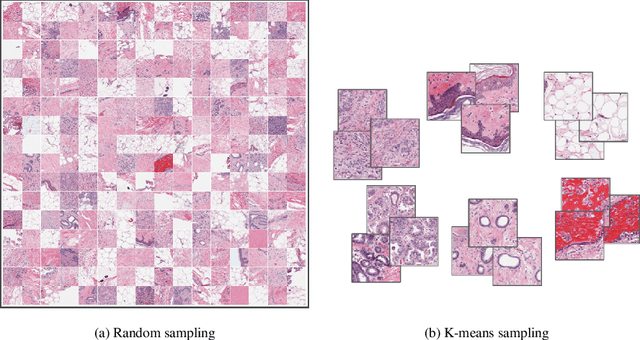
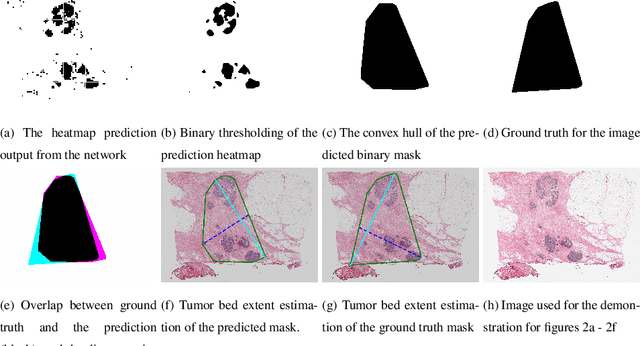
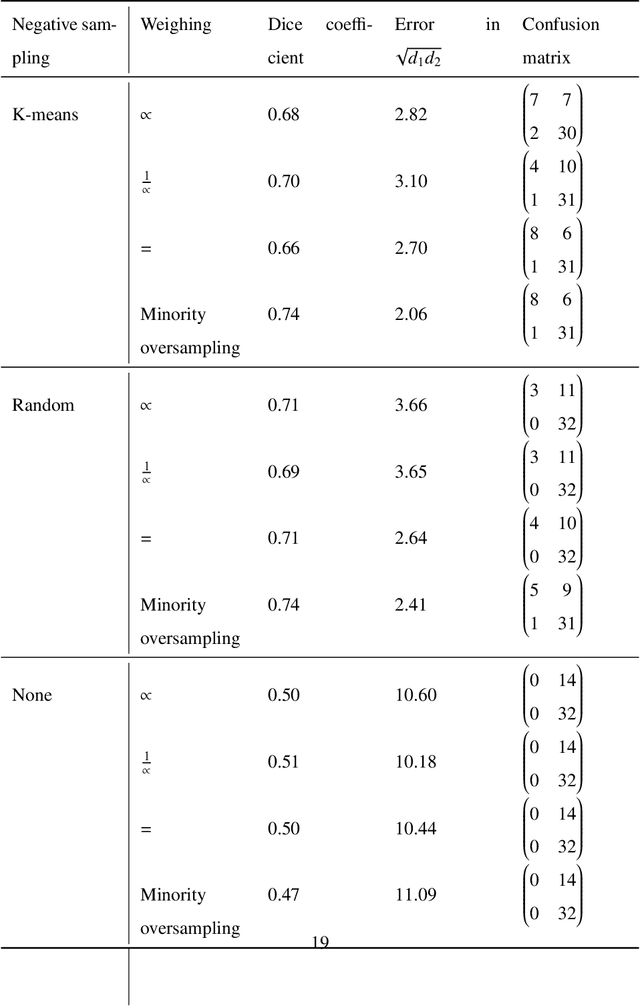
Whole slide images (WSIs) pose unique challenges when training deep learning models. They are very large which makes it necessary to break each image down into smaller patches for analysis, image features have to be extracted at multiple scales in order to capture both detail and context, and extreme class imbalances may exist. Significant progress has been made in the analysis of these images, thanks largely due to the availability of public annotated datasets. We postulate, however, that even if a method scores well on a challenge task, this success may not translate to good performance in a more clinically relevant workflow. Many datasets consist of image patches which may suffer from data curation bias; other datasets are only labelled at the whole slide level and the lack of annotations across an image may mask erroneous local predictions so long as the final decision is correct. In this paper, we outline the differences between patch or slide-level classification versus methods that need to localize or segment cancer accurately across the whole slide, and we experimentally verify that best practices differ in both cases. We apply a binary cancer detection network on post neoadjuvant therapy breast cancer WSIs to find the tumor bed outlining the extent of cancer, a task which requires sensitivity and precision across the whole slide. We extensively study multiple design choices and their effects on the outcome, including architectures and augmentations. Furthermore, we propose a negative data sampling strategy, which drastically reduces the false positive rate (7% on slide level) and improves each metric pertinent to our problem, with a 15% reduction in the error of tumor extent.
MBA-VO: Motion Blur Aware Visual Odometry
Mar 25, 2021
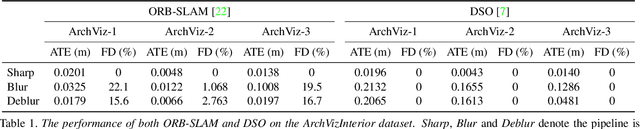
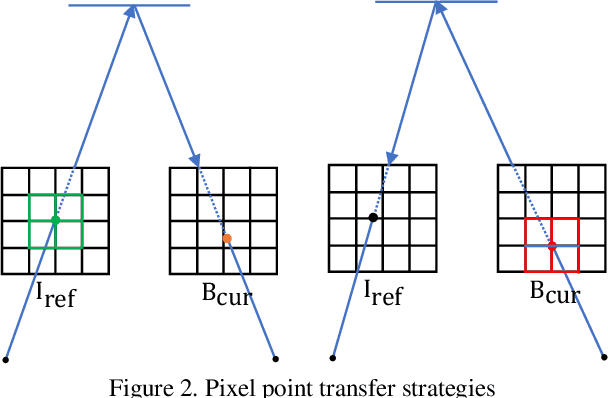
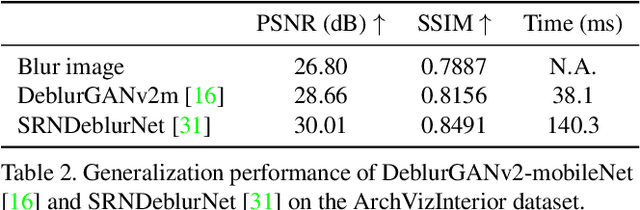
Motion blur is one of the major challenges remaining for visual odometry methods. In low-light conditions where longer exposure times are necessary, motion blur can appear even for relatively slow camera motions. In this paper we present a novel hybrid visual odometry pipeline with direct approach that explicitly models and estimates the camera's local trajectory within the exposure time. This allows us to actively compensate for any motion blur that occurs due to the camera motion. In addition, we also contribute a novel benchmarking dataset for motion blur aware visual odometry. In experiments we show that by directly modeling the image formation process, we are able to improve robustness of the visual odometry, while keeping comparable accuracy as that for images without motion blur.
Recurrent Multimodal Interaction for Referring Image Segmentation
Aug 04, 2017
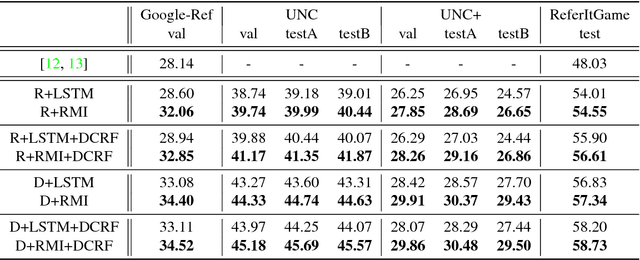
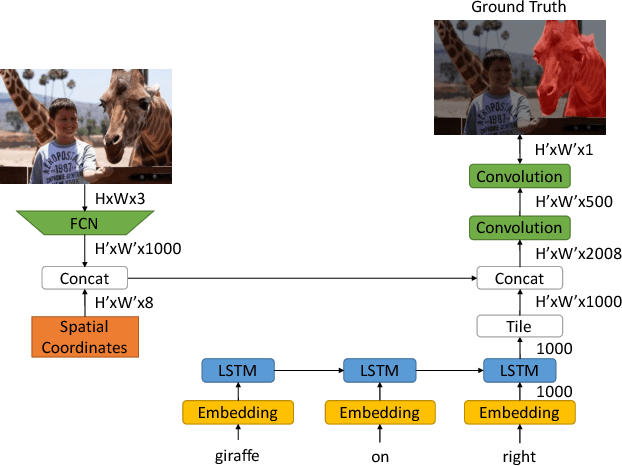
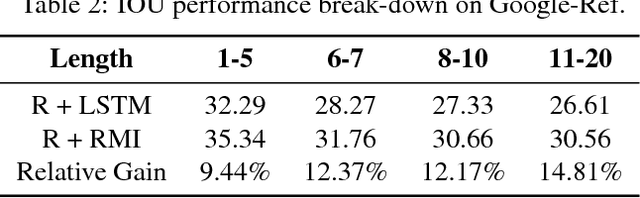
In this paper we are interested in the problem of image segmentation given natural language descriptions, i.e. referring expressions. Existing works tackle this problem by first modeling images and sentences independently and then segment images by combining these two types of representations. We argue that learning word-to-image interaction is more native in the sense of jointly modeling two modalities for the image segmentation task, and we propose convolutional multimodal LSTM to encode the sequential interactions between individual words, visual information, and spatial information. We show that our proposed model outperforms the baseline model on benchmark datasets. In addition, we analyze the intermediate output of the proposed multimodal LSTM approach and empirically explain how this approach enforces a more effective word-to-image interaction.
Adversarial Joint Image and Pose Distribution Learning for Camera Pose Regression and Refinement
Mar 26, 2019

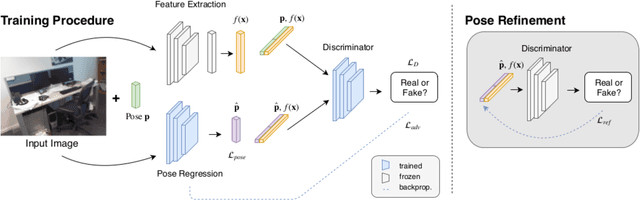
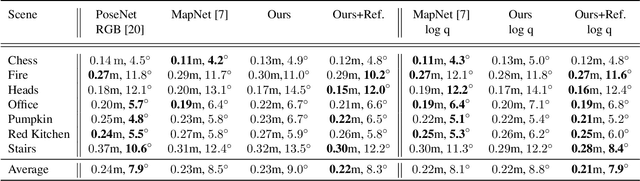
Despite recent advances on the topic of direct camera pose regression using neural networks, accurately estimating the camera pose of a single RGB image still remains a challenging task. To address this problem, we introduce a novel framework based, in its core, on the idea of modeling the joint distribution of RGB images and their corresponding camera poses using adversarial learning. Our method allows not only to regress the camera pose from a single image, however, also offers a solely RGB-based solution for camera pose refinement using the discriminator network. Further, we show that our method can effectively be used to optimize the predicted camera poses and thus improve the localization accuracy. To this end, we validate our proposed method on the publicly available 7-Scenes dataset improving upon the results of current state-of-the-art direct camera pose regression methods.
Multi-Modal Retrieval using Graph Neural Networks
Oct 04, 2020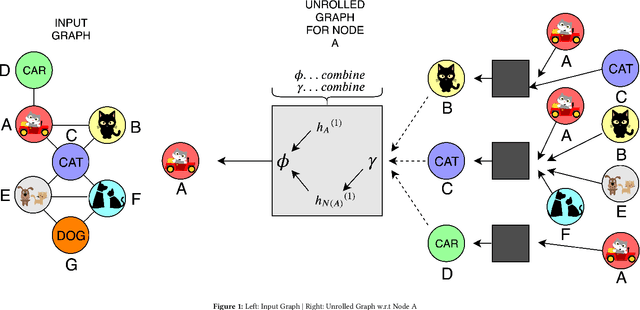

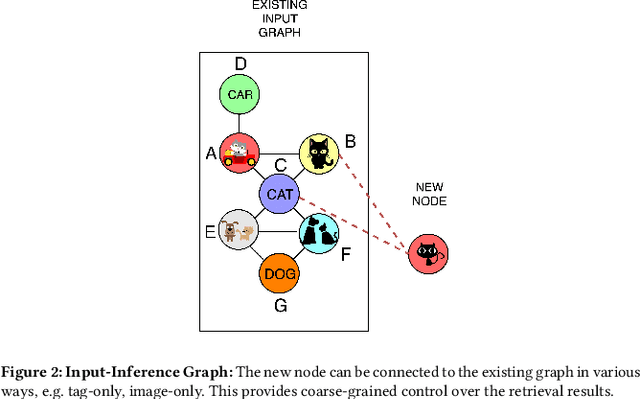

Most real world applications of image retrieval such as Adobe Stock, which is a marketplace for stock photography and illustrations, need a way for users to find images which are both visually (i.e. aesthetically) and conceptually (i.e. containing the same salient objects) as a query image. Learning visual-semantic representations from images is a well studied problem for image retrieval. Filtering based on image concepts or attributes is traditionally achieved with index-based filtering (e.g. on textual tags) or by re-ranking after an initial visual embedding based retrieval. In this paper, we learn a joint vision and concept embedding in the same high-dimensional space. This joint model gives the user fine-grained control over the semantics of the result set, allowing them to explore the catalog of images more rapidly. We model the visual and concept relationships as a graph structure, which captures the rich information through node neighborhood. This graph structure helps us learn multi-modal node embeddings using Graph Neural Networks. We also introduce a novel inference time control, based on selective neighborhood connectivity allowing the user control over the retrieval algorithm. We evaluate these multi-modal embeddings quantitatively on the downstream relevance task of image retrieval on MS-COCO dataset and qualitatively on MS-COCO and an Adobe Stock dataset.
SAR-U-Net: squeeze-and-excitation block and atrous spatial pyramid pooling based residual U-Net for automatic liver CT segmentation
Mar 11, 2021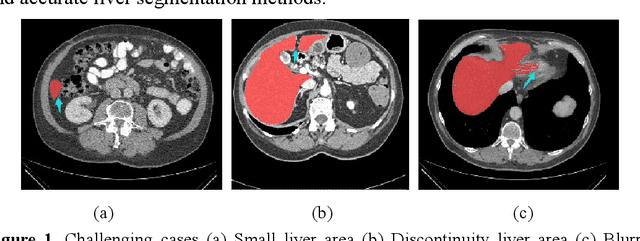
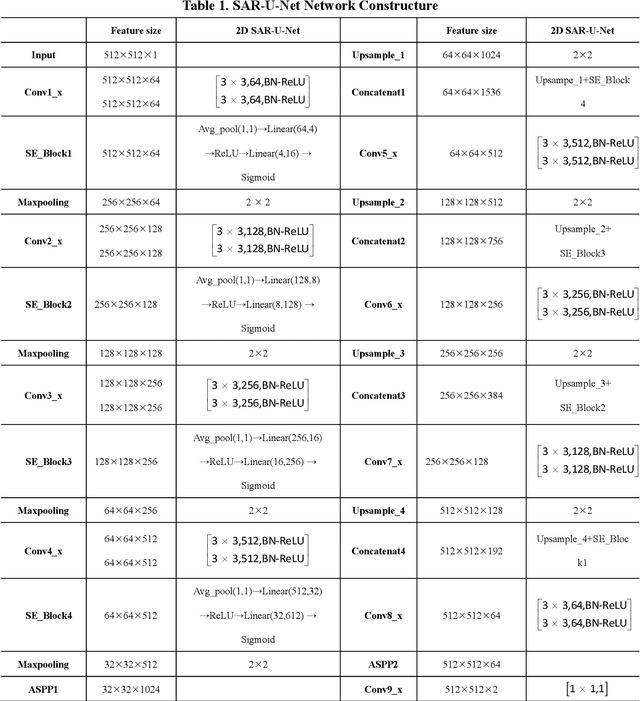
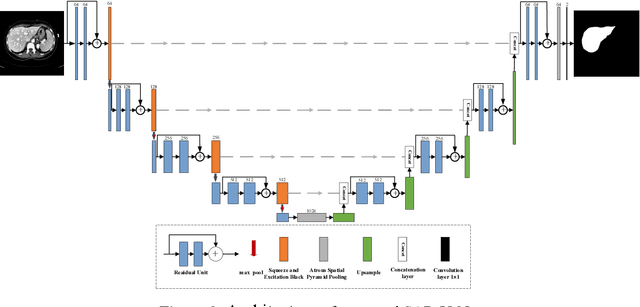
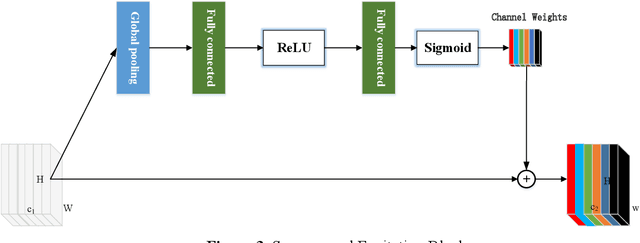
Background and objective: In this paper, a modified U-Net based framework is presented, which leverages techniques from Squeeze-and-Excitation (SE) block, Atrous Spatial Pyramid Pooling (ASPP) and residual learning for accurate and robust liver CT segmentation, and the effectiveness of the proposed method was tested on two public datasets LiTS17 and SLiver07. Methods: A new network architecture called SAR-U-Net was designed. Firstly, the SE block is introduced to adaptively extract image features after each convolution in the U-Net encoder, while suppressing irrelevant regions, and highlighting features of specific segmentation task; Secondly, ASPP was employed to replace the transition layer and the output layer, and acquire multi-scale image information via different receptive fields. Thirdly, to alleviate the degradation problem, the traditional convolution block was replaced with the residual block and thus prompt the network to gain accuracy from considerably increased depth. Results: In the LiTS17 experiment, the mean values of Dice, VOE, RVD, ASD and MSD were 95.71, 9.52, -0.84, 1.54 and 29.14, respectively. Compared with other closely related 2D-based models, the proposed method achieved the highest accuracy. In the experiment of the SLiver07, the mean values of Dice, VOE, RVD, ASD and MSD were 97.31, 5.37, -1.08, 1.85 and 27.45, respectively. Compared with other closely related models, the proposed method achieved the highest segmentation accuracy except for the RVD. Conclusion: The proposed model enables a great improvement on the accuracy compared to 2D-based models, and its robustness in circumvent challenging problems, such as small liver regions, discontinuous liver regions, and fuzzy liver boundaries, is also well demonstrated and validated.