 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Towards Unbiased COVID-19 Lesion Localisation and Segmentation via Weakly Supervised Learning
Mar 01, 2021
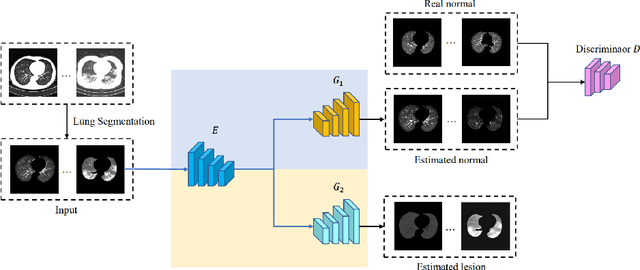
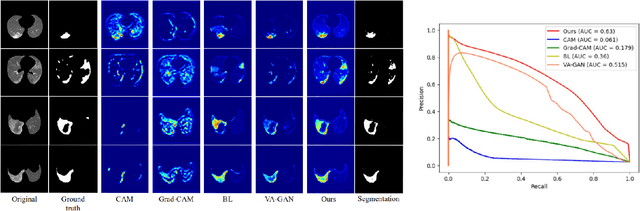
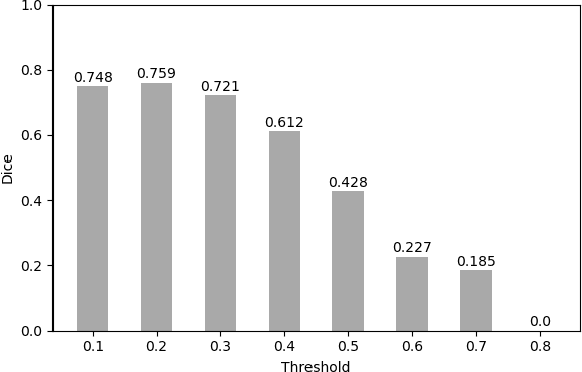
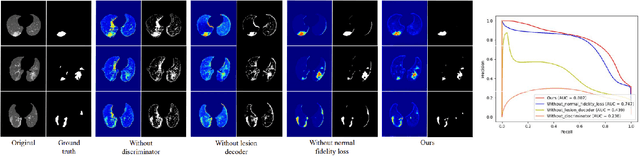
Despite tremendous efforts, it is very challenging to generate a robust model to assist in the accurate quantification assessment of COVID-19 on chest CT images. Due to the nature of blurred boundaries, the supervised segmentation methods usually suffer from annotation biases. To support unbiased lesion localisation and to minimise the labeling costs, we propose a data-driven framework supervised by only image-level labels. The framework can explicitly separate potential lesions from original images, with the help of a generative adversarial network and a lesion-specific decoder. Experiments on two COVID-19 datasets demonstrate the effectiveness of the proposed framework and its superior performance to several existing methods.
Deep Learning-based Damage Mapping with InSAR Coherence Time Series
May 24, 2021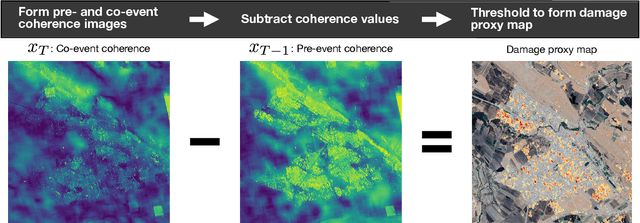
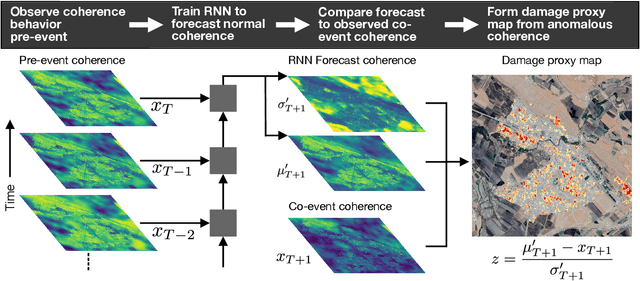
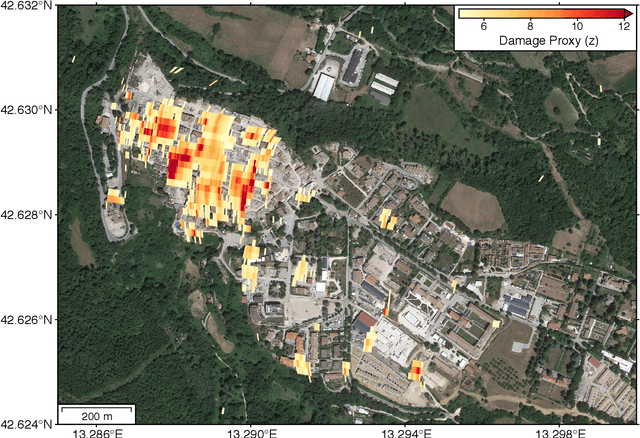
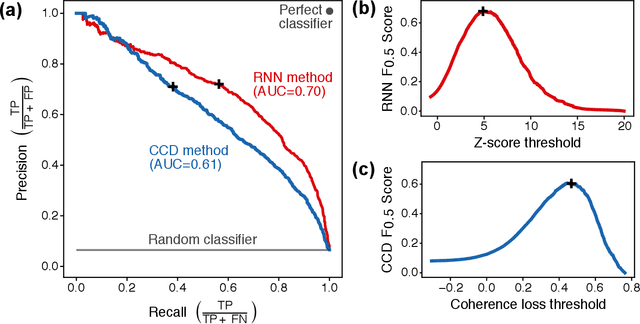
Satellite remote sensing is playing an increasing role in the rapid mapping of damage after natural disasters. In particular, synthetic aperture radar (SAR) can image the Earth's surface and map damage in all weather conditions, day and night. However, current SAR damage mapping methods struggle to separate damage from other changes in the Earth's surface. In this study, we propose a novel approach to damage mapping, combining deep learning with the full time history of SAR observations of an impacted region in order to detect anomalous variations in the Earth's surface properties due to a natural disaster. We quantify Earth surface change using time series of Interferometric SAR coherence, then use a recurrent neural network (RNN) as a probabilistic anomaly detector on these coherence time series. The RNN is first trained on pre-event coherence time series, and then forecasts a probability distribution of the coherence between pre- and post-event SAR images. The difference between the forecast and observed co-event coherence provides a measure of the confidence in the identification of damage. The method allows the user to choose a damage detection threshold that is customized for each location, based on the local behavior of coherence through time before the event. We apply this method to calculate estimates of damage for three earthquakes using multi-year time series of Sentinel-1 SAR acquisitions. Our approach shows good agreement with observed damage and quantitative improvement compared to using pre- to co-event coherence loss as a damage proxy.
Fast Bayesian Uncertainty Estimation of Batch Normalized Single Image Super-Resolution Network
Mar 22, 2019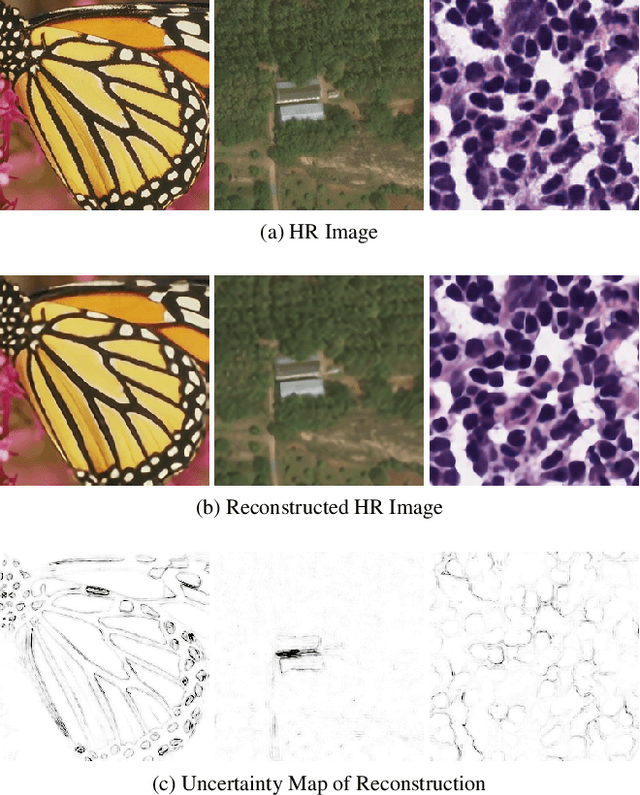

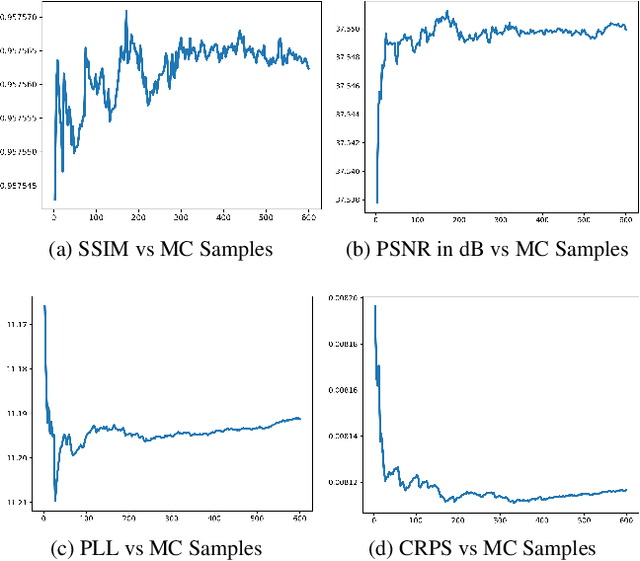
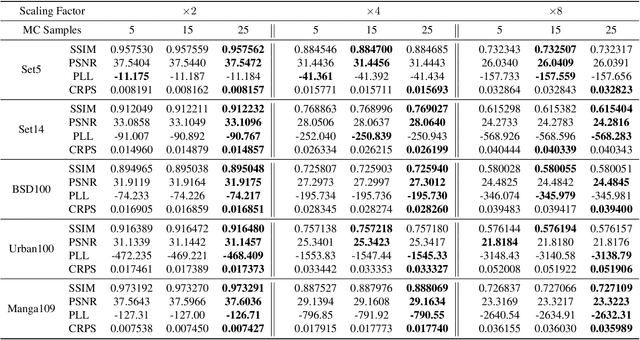
In recent years, deep convolutional neural network (CNN) has achieved unprecedented success in image super-resolution (SR) task. But the black-box nature of the neural network and due to its lack of transparency, it is hard to trust the outcome. In this regards, we introduce a Bayesian approach for uncertainty estimation in super-resolution network. We generate Monte Carlo (MC) samples from a posterior distribution by using batch mean and variance as a stochastic parameter in the batch-normalization layer during test time. Those MC samples not only reconstruct the image from its low-resolution counterpart but also provides a confidence map of reconstruction which will be very impactful for practical use. We also introduce a faster approach for estimating the uncertainty, and it can be useful for real-time applications. We validate our results using standard datasets for performance analysis and also for different domain-specific super-resolution task. We also estimate uncertainty quality using standard statistical metrics and also provides a qualitative evaluation of uncertainty for SR applications.
Learning Better Visual Dialog Agents with Pretrained Visual-Linguistic Representation
May 24, 2021

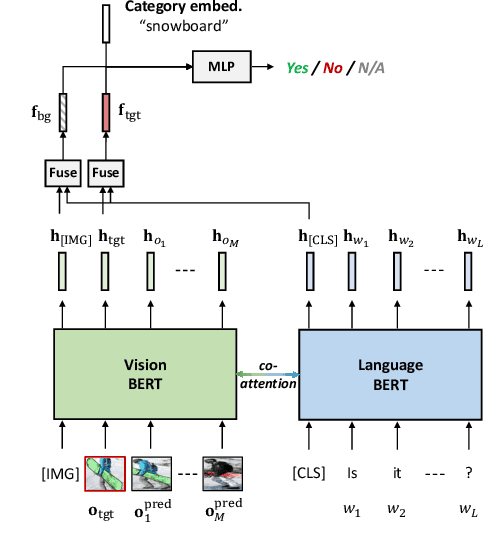
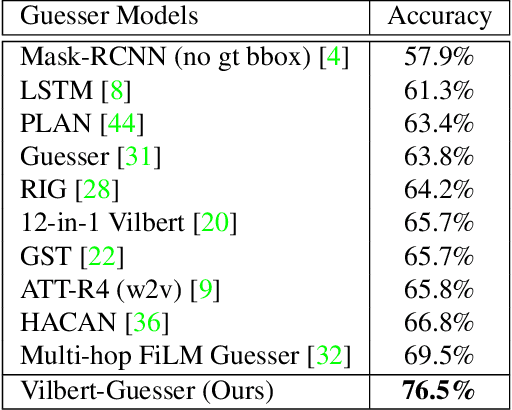
GuessWhat?! is a two-player visual dialog guessing game where player A asks a sequence of yes/no questions (Questioner) and makes a final guess (Guesser) about a target object in an image, based on answers from player B (Oracle). Based on this dialog history between the Questioner and the Oracle, a Guesser makes a final guess of the target object. Previous baseline Oracle model encodes no visual information in the model, and it cannot fully understand complex questions about color, shape, relationships and so on. Most existing work for Guesser encode the dialog history as a whole and train the Guesser models from scratch on the GuessWhat?! dataset. This is problematic since language encoder tend to forget long-term history and the GuessWhat?! data is sparse in terms of learning visual grounding of objects. Previous work for Questioner introduces state tracking mechanism into the model, but it is learned as a soft intermediates without any prior vision-linguistic insights. To bridge these gaps, in this paper we propose Vilbert-based Oracle, Guesser and Questioner, which are all built on top of pretrained vision-linguistic model, Vilbert. We introduce two-way background/target fusion mechanism into Vilbert-Oracle to account for both intra and inter-object questions. We propose a unified framework for Vilbert-Guesser and Vilbert-Questioner, where state-estimator is introduced to best utilize Vilbert's power on single-turn referring expression comprehension. Experimental results show that our proposed models outperform state-of-the-art models significantly by 7%, 10%, 12% for Oracle, Guesser and End-to-End Questioner respectively.
Flickr1024: A Dataset for Stereo Image Super-Resolution
Mar 15, 2019
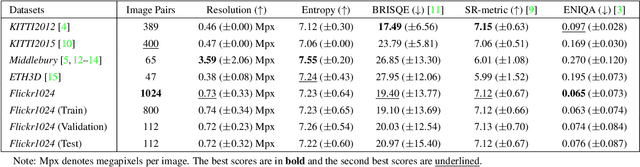


With the popularity of dual cameras in recently released smart phones, a growing number of super-resolution (SR) methods have been proposed to enhance the resolution of stereo image pairs. However, the lack of high-quality stereo datasets has limited the research in this area. To facilitate the training and evaluation of novel stereo SR algorithms, in this paper, we propose a large-scale stereo dataset named Flickr1024. Compared to the existing stereo datasets, the proposed dataset contains much more high-quality images and covers diverse scenarios. We train two state-of-the-art stereo SR methods (i.e., StereoSR and PASSRnet) on the KITTI2015, Middlebury, and Flickr1024 datasets. Experimental results demonstrate that our dataset can improve the performance of stereo SR algorithms. The Flickr1024 dataset is available online at: https://yingqianwang.github.io/Flickr1024.
Deep Convolutional Neural Networks in the Face of Caricature: Identity and Image Revealed
Dec 28, 2018

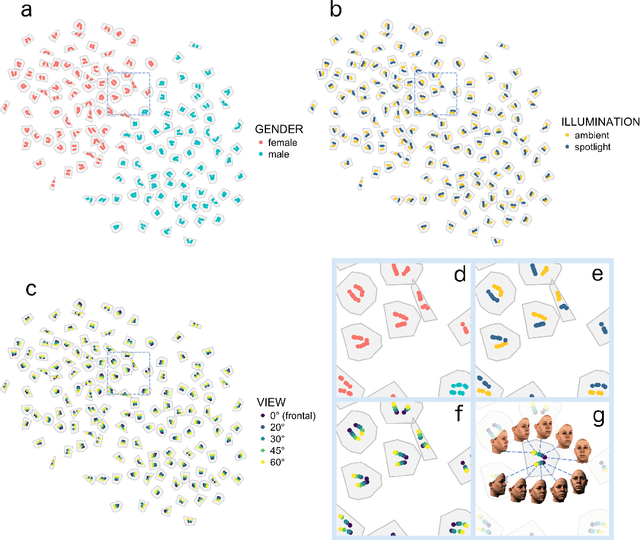
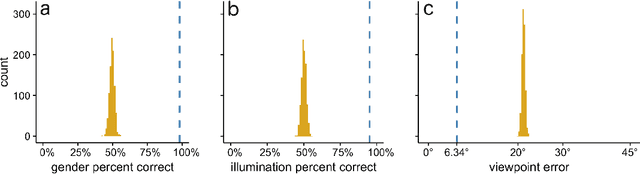
Real-world face recognition requires an ability to perceive the unique features of an individual face across multiple, variable images. The primate visual system solves the problem of image invariance using cascades of neurons that convert images of faces into categorical representations of facial identity. Deep convolutional neural networks (DCNNs) also create generalizable face representations, but with cascades of simulated neurons. DCNN representations can be examined in a multidimensional "face space", with identities and image parameters quantified via their projections onto the axes that define the space. We examined the organization of viewpoint, illumination, gender, and identity in this space. We show that the network creates a highly organized, hierarchically nested, face similarity structure in which information about face identity and imaging characteristics coexist. Natural image variation is accommodated in this hierarchy, with face identity nested under gender, illumination nested under identity, and viewpoint nested under illumination. To examine identity, we caricatured faces and found that network identification accuracy increased with caricature level, and--mimicking human perception--a caricatured distortion of a face "resembled" its veridical counterpart. Caricatures improved performance by moving the identity away from other identities in the face space and minimizing the effects of illumination and viewpoint. Deep networks produce face representations that solve long-standing computational problems in generalized face recognition. They also provide a unitary theoretical framework for reconciling decades of behavioral and neural results that emphasized either the image or the object/face in representations, without understanding how a neural code could seamlessly accommodate both.
Improving Generalization of Deep Networks for Inverse Reconstruction of Image Sequences
Mar 05, 2019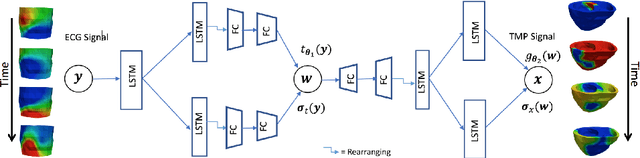
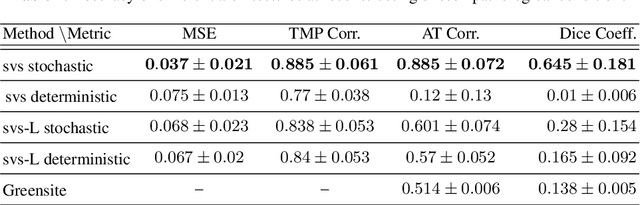
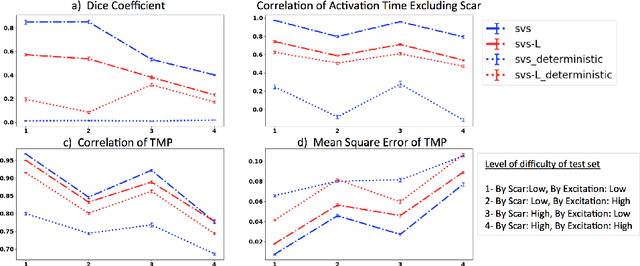
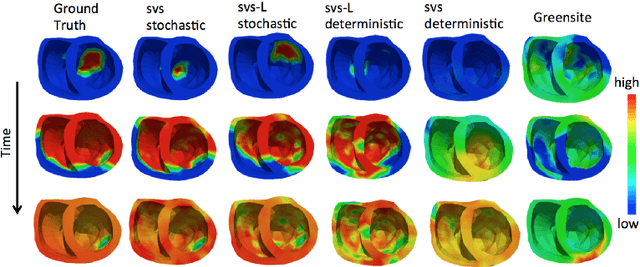
Deep learning networks have shown state-of-the-art performance in many image reconstruction problems. However, it is not well understood what properties of representation and learning may improve the generalization ability of the network. In this paper, we propose that the generalization ability of an encoder-decoder network for inverse reconstruction can be improved in two means. First, drawing from analytical learning theory, we theoretically show that a stochastic latent space will improve the ability of a network to generalize to test data outside the training distribution. Second, following the information bottleneck principle, we show that a latent representation minimally informative of the input data will help a network generalize to unseen input variations that are irrelevant to the output reconstruction. Therefore, we present a sequence image reconstruction network optimized by a variational approximation of the information bottleneck principle with stochastic latent space. In the application setting of reconstructing the sequence of cardiac transmembrane potential from bodysurface potential, we assess the two types of generalization abilities of the presented network against its deterministic counterpart. The results demonstrate that the generalization ability of an inverse reconstruction network can be improved by stochasticity as well as the information bottleneck.
GUIGAN: Learning to Generate GUI Designs Using Generative Adversarial Networks
Jan 27, 2021
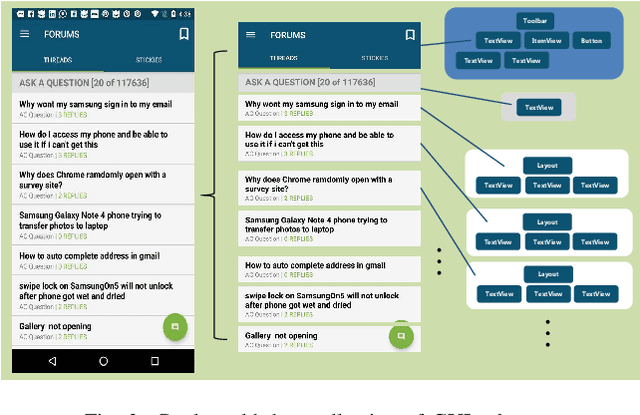
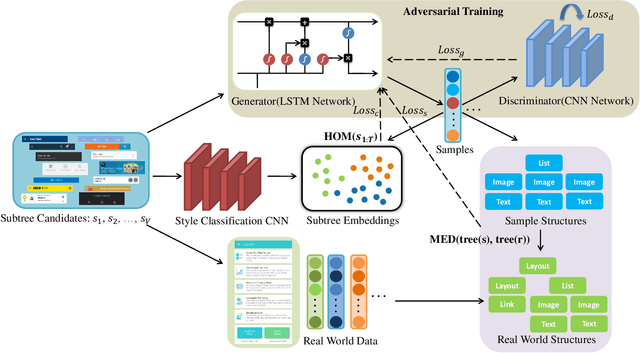
Graphical User Interface (GUI) is ubiquitous in almost all modern desktop software, mobile applications, and online websites. A good GUI design is crucial to the success of the software in the market, but designing a good GUI which requires much innovation and creativity is difficult even to well-trained designers. Besides, the requirement of the rapid development of GUI design also aggravates designers' working load. So, the availability of various automated generated GUIs can help enhance the design personalization and specialization as they can cater to the taste of different designers. To assist designers, we develop a model GUIGAN to automatically generate GUI designs. Different from conventional image generation models based on image pixels, our GUIGAN is to reuse GUI components collected from existing mobile app GUIs for composing a new design that is similar to natural-language generation. Our GUIGAN is based on SeqGAN by modeling the GUI component style compatibility and GUI structure. The evaluation demonstrates that our model significantly outperforms the best of the baseline methods by 30.77% in Frechet Inception distance (FID) and 12.35% in 1-Nearest Neighbor Accuracy (1-NNA). Through a pilot user study, we provide initial evidence of the usefulness of our approach for generating acceptable brand new GUI designs.
Learning to Recognize Patch-Wise Consistency for Deepfake Detection
Dec 16, 2020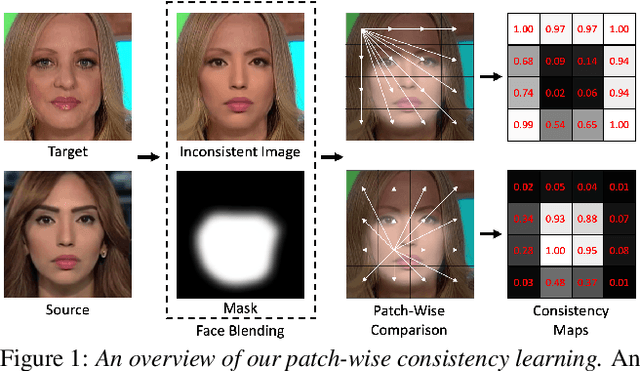

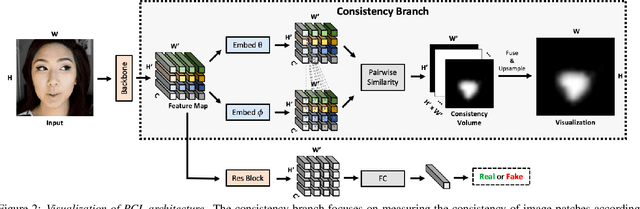
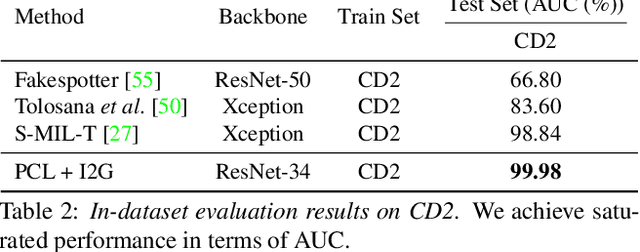
We propose to detect Deepfake generated by face manipulation based on one of their fundamental features: images are blended by patches from multiple sources, carrying distinct and persistent source features. In particular, we propose a novel representation learning approach for this task, called patch-wise consistency learning (PCL). It learns by measuring the consistency of image source features, resulting to representation with good interpretability and robustness to multiple forgery methods. We develop an inconsistency image generator (I2G) to generate training data for PCL and boost its robustness. We evaluate our approach on seven popular Deepfake detection datasets. Our model achieves superior detection accuracy and generalizes well to unseen generation methods. On average, our model outperforms the state-of-the-art in terms of AUC by 2% and 8% in the in- and cross-dataset evaluation, respectively.
Dilated Spatial Generative Adversarial Networks for Ergodic Image Generation
May 15, 2019


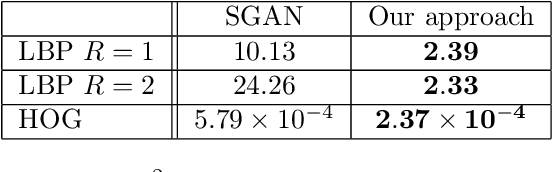
Generative models have recently received renewed attention as a result of adversarial learning. Generative adversarial networks consist of samples generation model and a discrimination model able to distinguish between genuine and synthetic samples. In combination with convolutional (for the discriminator) and de-convolutional (for the generator) layers, they are particularly suitable for image generation, especially of natural scenes. However, the presence of fully connected layers adds global dependencies in the generated images. This may lead to high and global variations in the generated sample for small local variations in the input noise. In this work we propose to use architec-tures based on fully convolutional networks (including among others dilated layers), architectures specifically designed to generate globally ergodic images, that is images without global dependencies. Conducted experiments reveal that these architectures are well suited for generating natural textures such as geologic structures .