 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Transfer learning from language models to image caption generators: Better models may not transfer better
Jan 01, 2019
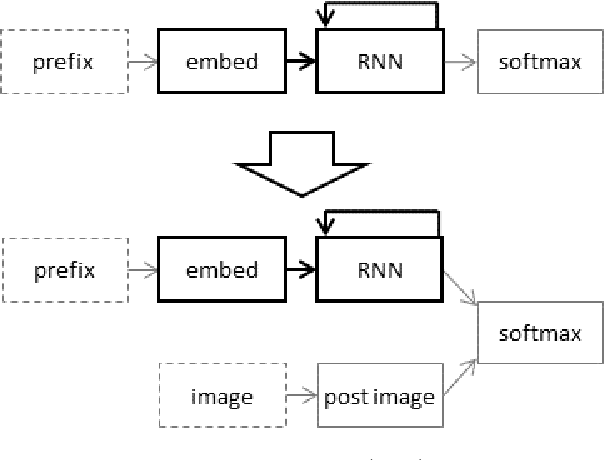

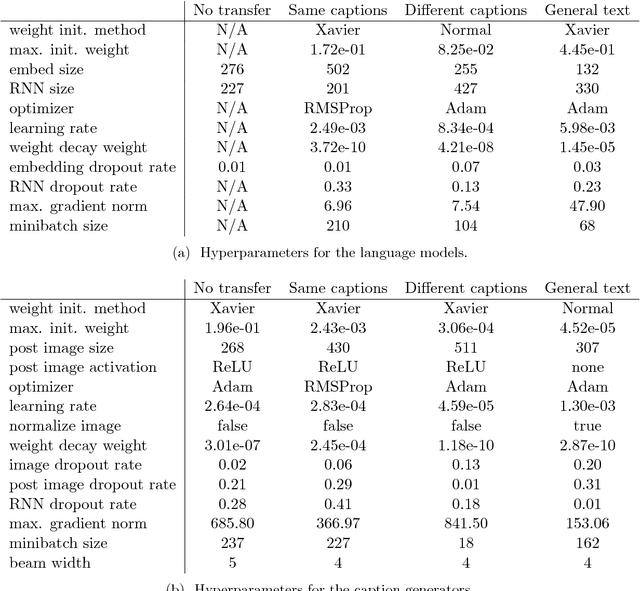
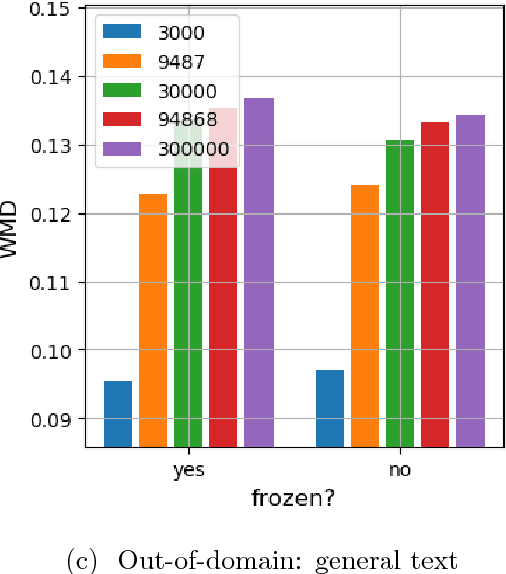
When designing a neural caption generator, a convolutional neural network can be used to extract image features. Is it possible to also use a neural language model to extract sentence prefix features? We answer this question by trying different ways to transfer the recurrent neural network and embedding layer from a neural language model to an image caption generator. We find that image caption generators with transferred parameters perform better than those trained from scratch, even when simply pre-training them on the text of the same captions dataset it will later be trained on. We also find that the best language models (in terms of perplexity) do not result in the best caption generators after transfer learning.
Structured dataset documentation: a datasheet for CheXpert
May 07, 2021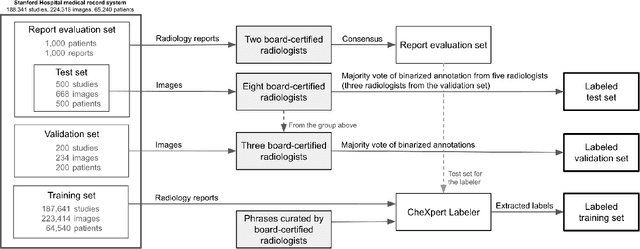
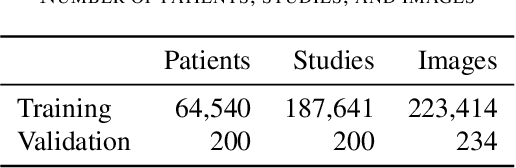
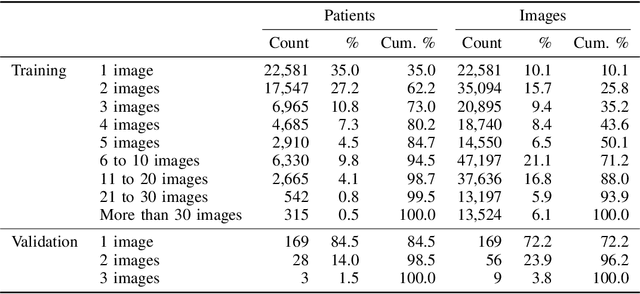

Billions of X-ray images are taken worldwide each year. Machine learning, and deep learning in particular, has shown potential to help radiologists triage and diagnose images. However, deep learning requires large datasets with reliable labels. The CheXpert dataset was created with the participation of board-certified radiologists, resulting in the strong ground truth needed to train deep learning networks. Following the structured format of Datasheets for Datasets, this paper expands on the original CheXpert paper and other sources to show the critical role played by radiologists in the creation of reliable labels and to describe the different aspects of the dataset composition in detail. Such structured documentation intends to increase the awareness in the machine learning and medical communities of the strengths, applications, and evolution of CheXpert, thereby advancing the field of medical image analysis. Another objective of this paper is to put forward this dataset datasheet as an example to the community of how to create detailed and structured descriptions of datasets. We believe that clearly documenting the creation process, the contents, and applications of datasets accelerates the creation of useful and reliable models.
Point Transformer
Dec 16, 2020
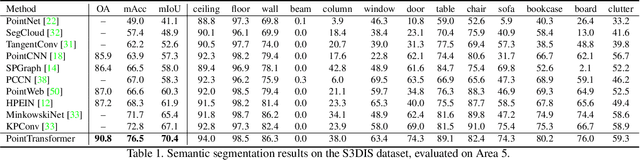
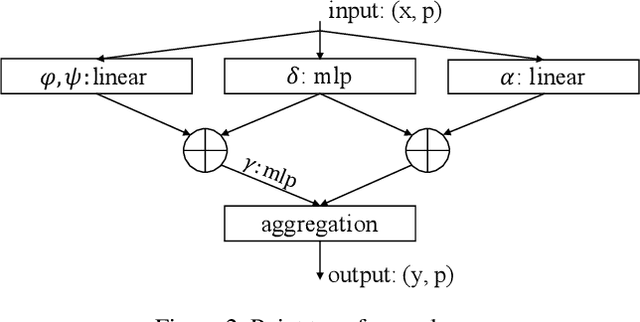
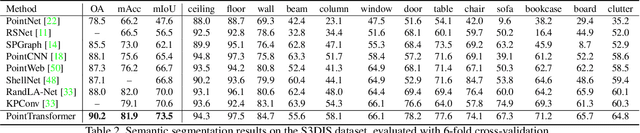
Self-attention networks have revolutionized natural language processing and are making impressive strides in image analysis tasks such as image classification and object detection. Inspired by this success, we investigate the application of self-attention networks to 3D point cloud processing. We design self-attention layers for point clouds and use these to construct self-attention networks for tasks such as semantic scene segmentation, object part segmentation, and object classification. Our Point Transformer design improves upon prior work across domains and tasks. For example, on the challenging S3DIS dataset for large-scale semantic scene segmentation, the Point Transformer attains an mIoU of 70.4% on Area 5, outperforming the strongest prior model by 3.3 absolute percentage points and crossing the 70% mIoU threshold for the first time.
SREDS: A dichromatic separation based measure of skin color
Apr 07, 2021


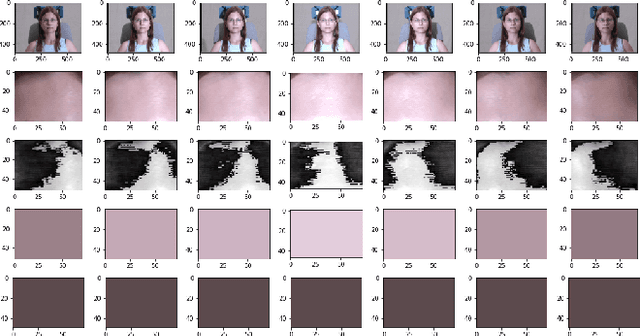
Face recognition (FR) systems are fast becoming ubiquitous. However, differential performance among certain demographics was identified in several widely used FR models. The skin tone of the subject is an important factor in addressing the differential performance. Previous work has used modeling methods to propose skin tone measures of subjects across different illuminations or utilized subjective labels of skin color and demographic information. However, such models heavily rely on consistent background and lighting for calibration, or utilize labeled datasets, which are time-consuming to generate or are unavailable. In this work, we have developed a novel and data-driven skin color measure capable of accurately representing subjects' skin tone from a single image, without requiring a consistent background or illumination. Our measure leverages the dichromatic reflection model in RGB space to decompose skin patches into diffuse and specular bases.
Wide-Depth-Range 6D Object Pose Estimation in Space
Apr 01, 2021
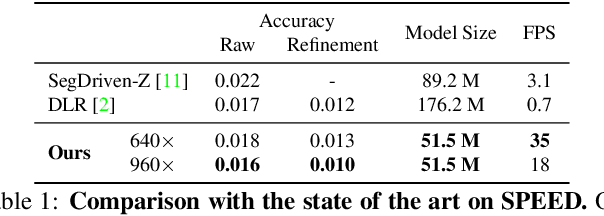
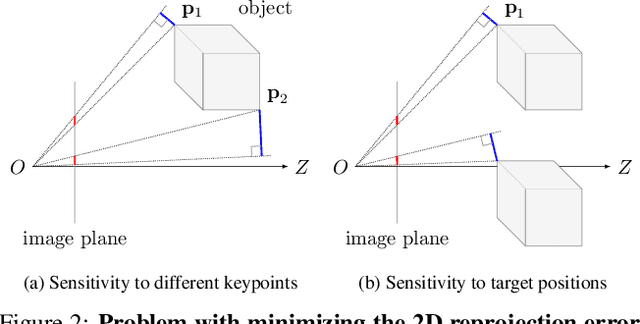
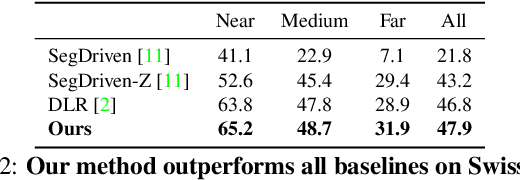
6D pose estimation in space poses unique challenges that are not commonly encountered in the terrestrial setting. One of the most striking differences is the lack of atmospheric scattering, allowing objects to be visible from a great distance while complicating illumination conditions. Currently available benchmark datasets do not place a sufficient emphasis on this aspect and mostly depict the target in close proximity. Prior work tackling pose estimation under large scale variations relies on a two-stage approach to first estimate scale, followed by pose estimation on a resized image patch. We instead propose a single-stage hierarchical end-to-end trainable network that is more robust to scale variations. We demonstrate that it outperforms existing approaches not only on images synthesized to resemble images taken in space but also on standard benchmarks.
Image Labeling with Markov Random Fields and Conditional Random Fields
Nov 28, 2018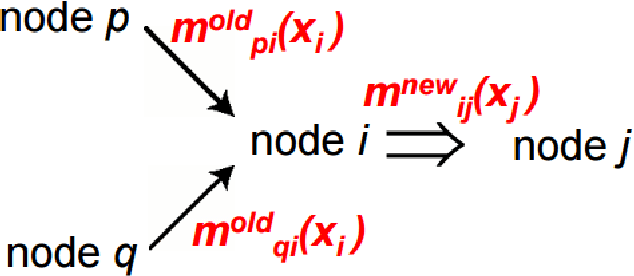

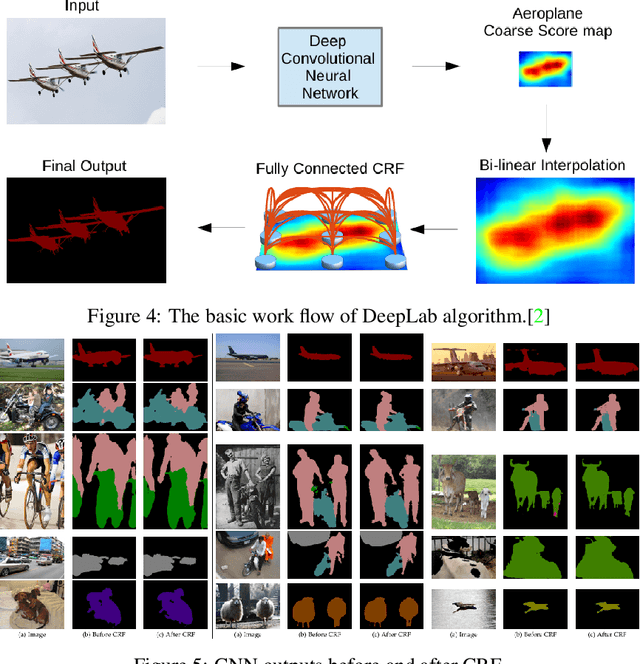
Most existing methods for object segmentation in computer vision are formulated as a labeling task. This, in general, could be transferred to a pixel-wise label assignment task, which is quite similar to the structure of hidden Markov random field. In terms of Markov random field, each pixel can be regarded as a state and has a transition probability to its neighbor pixel, the label behind each pixel is a latent variable and has an emission probability from its corresponding state. In this paper, we reviewed several modern image labeling methods based on Markov random field and conditional random Field. And we compare the result of these methods with some classical image labeling methods. The experiment demonstrates that the introduction of Markov random field and conditional random field make a big difference in the segmentation result.
PDE-constrained optimization in medical image analysis
Feb 28, 2018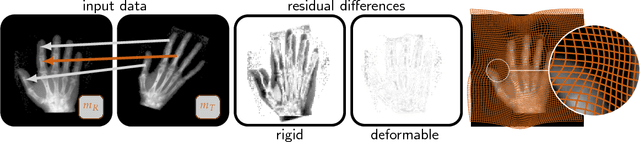

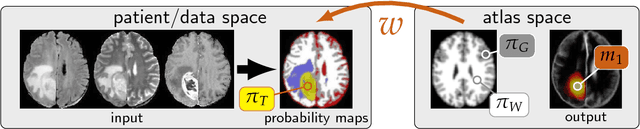

PDE-constrained optimization problems find many applications in medical image analysis, for example, neuroimaging, cardiovascular imaging, and oncological imaging. We review related literature and give examples on the formulation, discretization, and numerical solution of PDE-constrained optimization problems for medical imaging. We discuss three examples. The first one is image registration. The second one is data assimilation for brain tumor patients, and the third one data assimilation in cardiovascular imaging. The image registration problem is a classical task in medical image analysis and seeks to find pointwise correspondences between two or more images. The data assimilation problems use a PDE-constrained formulation to link a biophysical model to patient-specific data obtained from medical images. The associated optimality systems turn out to be sets of nonlinear, multicomponent PDEs that are challenging to solve in an efficient way. The ultimate goal of our work is the design of inversion methods that integrate complementary data, and rigorously follow mathematical and physical principles, in an attempt to support clinical decision making. This requires reliable, high-fidelity algorithms with a short time-to-solution. This task is complicated by model and data uncertainties, and by the fact that PDE-constrained optimization problems are ill-posed in nature, and in general yield high-dimensional, severely ill-conditioned systems after discretization. These features make regularization, effective preconditioners, and iterative solvers that, in many cases, have to be implemented on distributed-memory architectures to be practical, a prerequisite. We showcase state-of-the-art techniques in scientific computing to tackle these challenges.
ConTNet: Why not use convolution and transformer at the same time?
May 06, 2021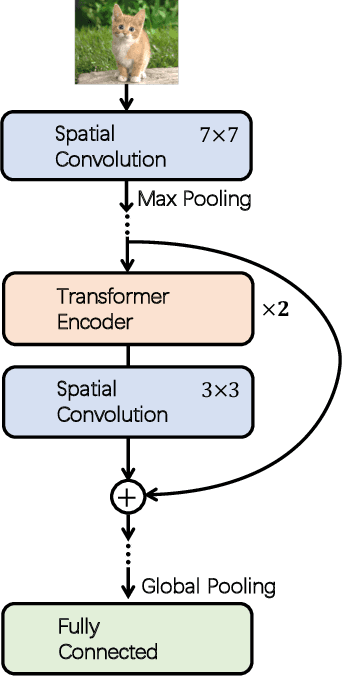
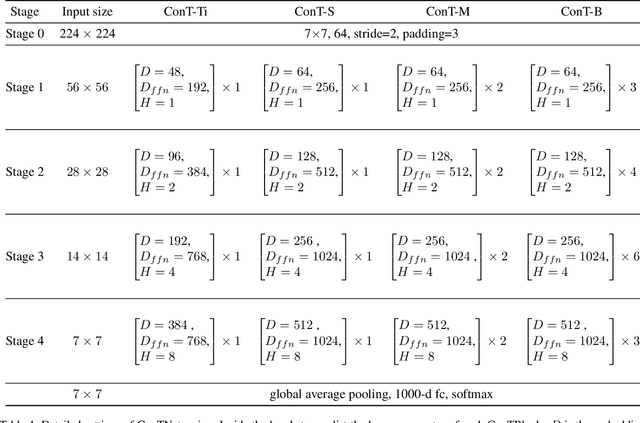

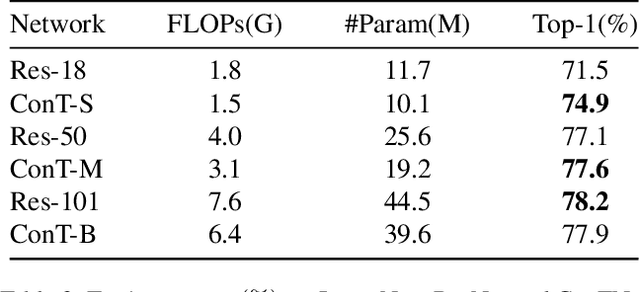
Although convolutional networks (ConvNets) have enjoyed great success in computer vision (CV), it suffers from capturing global information crucial to dense prediction tasks such as object detection and segmentation. In this work, we innovatively propose ConTNet (ConvolutionTransformer Network), combining transformer with ConvNet architectures to provide large receptive fields. Unlike the recently-proposed transformer-based models (e.g., ViT, DeiT) that are sensitive to hyper-parameters and extremely dependent on a pile of data augmentations when trained from scratch on a midsize dataset (e.g., ImageNet1k), ConTNet can be optimized like normal ConvNets (e.g., ResNet) and preserve an outstanding robustness. It is also worth pointing that, given identical strong data augmentations, the performance improvement of ConTNet is more remarkable than that of ResNet. We present its superiority and effectiveness on image classification and downstream tasks. For example, our ConTNet achieves 81.8% top-1 accuracy on ImageNet which is the same as DeiT-B with less than 40% computational complexity. ConTNet-M also outperforms ResNet50 as the backbone of both Faster-RCNN (by 2.6%) and Mask-RCNN (by 3.2%) on COCO2017 dataset. We hope that ConTNet could serve as a useful backbone for CV tasks and bring new ideas for model design
PixelNN: Example-based Image Synthesis
Aug 17, 2017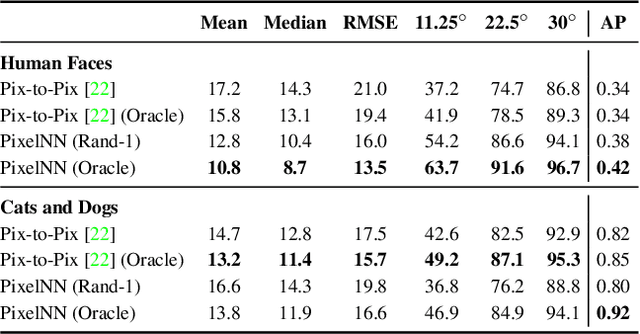
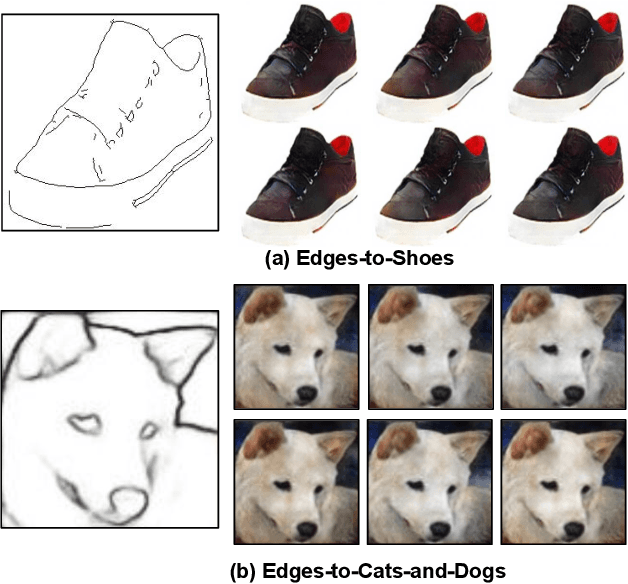
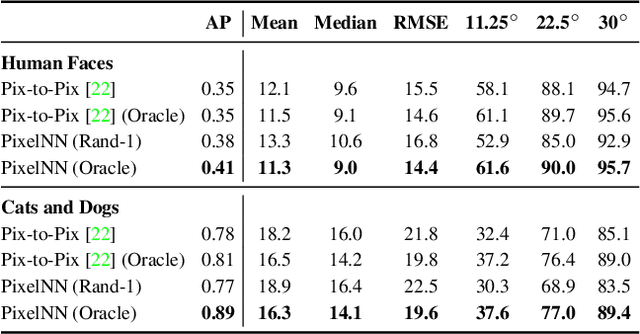

We present a simple nearest-neighbor (NN) approach that synthesizes high-frequency photorealistic images from an "incomplete" signal such as a low-resolution image, a surface normal map, or edges. Current state-of-the-art deep generative models designed for such conditional image synthesis lack two important things: (1) they are unable to generate a large set of diverse outputs, due to the mode collapse problem. (2) they are not interpretable, making it difficult to control the synthesized output. We demonstrate that NN approaches potentially address such limitations, but suffer in accuracy on small datasets. We design a simple pipeline that combines the best of both worlds: the first stage uses a convolutional neural network (CNN) to maps the input to a (overly-smoothed) image, and the second stage uses a pixel-wise nearest neighbor method to map the smoothed output to multiple high-quality, high-frequency outputs in a controllable manner. We demonstrate our approach for various input modalities, and for various domains ranging from human faces to cats-and-dogs to shoes and handbags.
Learning-Based Algorithms for Vessel Tracking: A Review
Dec 16, 2020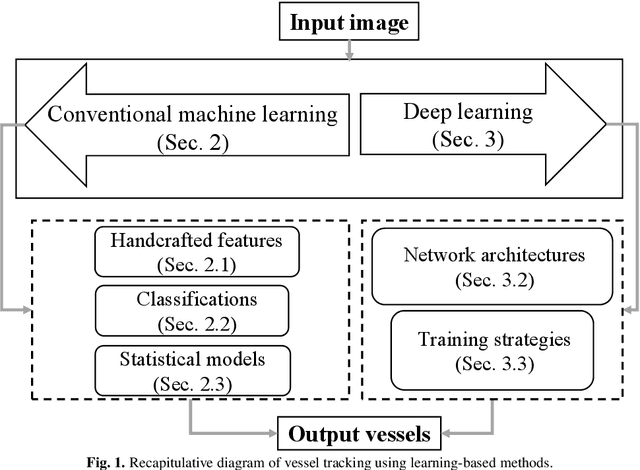
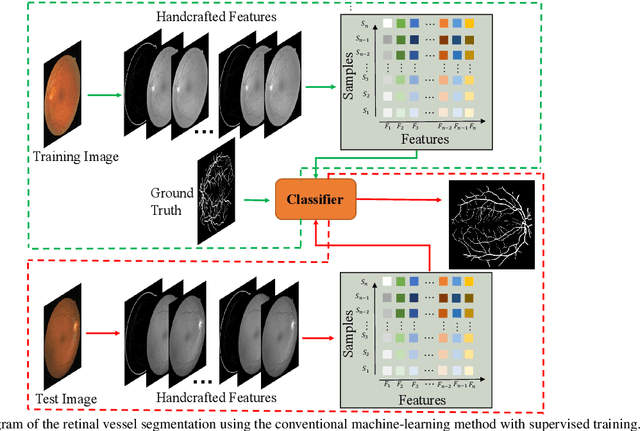
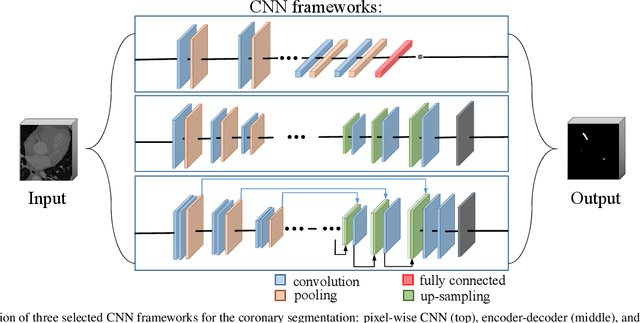
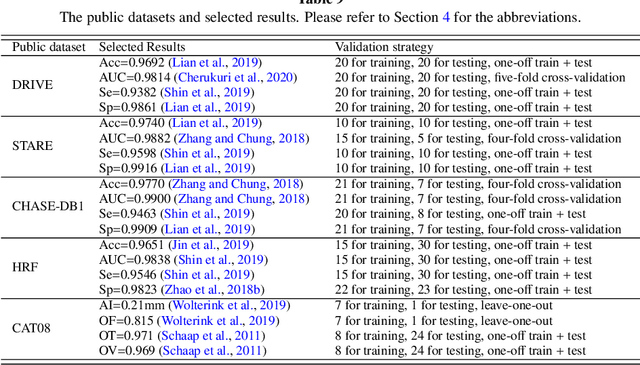
Developing efficient vessel-tracking algorithms is crucial for imaging-based diagnosis and treatment of vascular diseases. Vessel tracking aims to solve recognition problems such as key (seed) point detection, centerline extraction, and vascular segmentation. Extensive image-processing techniques have been developed to overcome the problems of vessel tracking that are mainly attributed to the complex morphologies of vessels and image characteristics of angiography. This paper presents a literature review on vessel-tracking methods, focusing on machine-learning-based methods. First, the conventional machine-learning-based algorithms are reviewed, and then, a general survey of deep-learning-based frameworks is provided. On the basis of the reviewed methods, the evaluation issues are introduced. The paper is concluded with discussions about the remaining exigencies and future research.