 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
3D U$^2$-Net: A 3D Universal U-Net for Multi-Domain Medical Image Segmentation
Sep 04, 2019
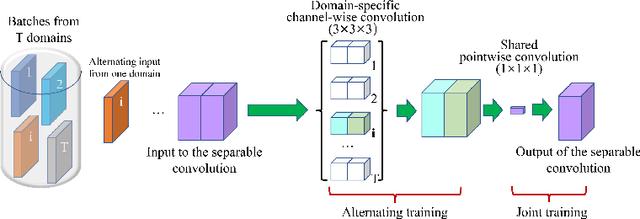

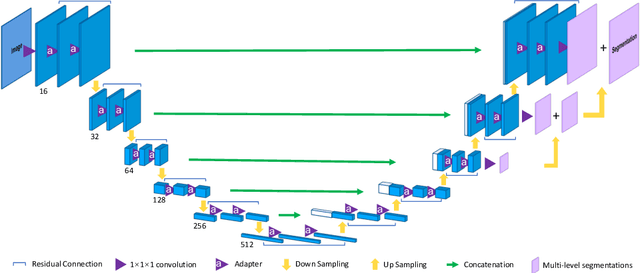
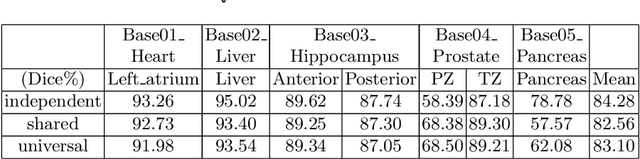
Fully convolutional neural networks like U-Net have been the state-of-the-art methods in medical image segmentation. Practically, a network is highly specialized and trained separately for each segmentation task. Instead of a collection of multiple models, it is highly desirable to learn a universal data representation for different tasks, ideally a single model with the addition of a minimal number of parameters steered to each task. Inspired by the recent success of multi-domain learning in image classification, for the first time we explore a promising universal architecture that handles multiple medical segmentation tasks and is extendable for new tasks, regardless of different organs and imaging modalities. Our 3D Universal U-Net (3D U$^2$-Net) is built upon separable convolution, assuming that {\it images from different domains have domain-specific spatial correlations which can be probed with channel-wise convolution while also share cross-channel correlations which can be modeled with pointwise convolution}. We evaluate the 3D U$^2$-Net on five organ segmentation datasets. Experimental results show that this universal network is capable of competing with traditional models in terms of segmentation accuracy, while requiring only about $1\%$ of the parameters. Additionally, we observe that the architecture can be easily and effectively adapted to a new domain without sacrificing performance in the domains used to learn the shared parameterization of the universal network. We put the code of 3D U$^2$-Net into public domain. \url{https://github.com/huangmozhilv/u2net_torch/}
Spherical Harmonics for Shape-Constrained 3D Cell Segmentation
Oct 23, 2020
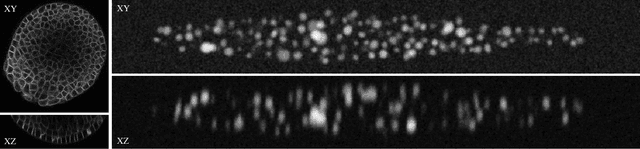
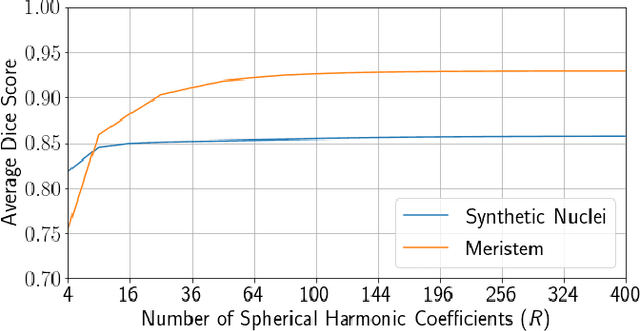
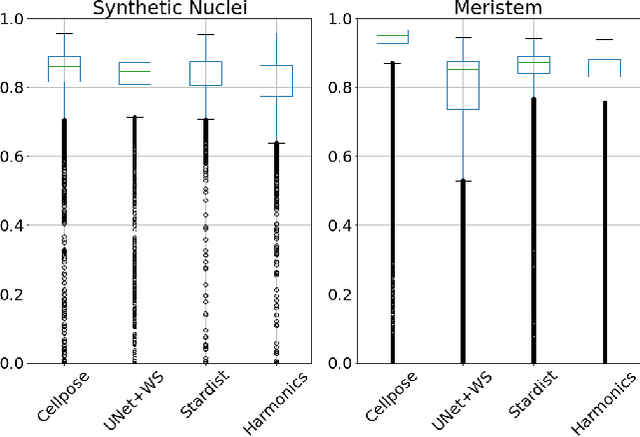
Recent microscopy imaging techniques allow to precisely analyze cell morphology in 3D image data. To process the vast amount of image data generated by current digitized imaging techniques, automated approaches are demanded more than ever. Segmentation approaches used for morphological analyses, however, are often prone to produce unnaturally shaped predictions, which in conclusion could lead to inaccurate experimental outcomes. In order to minimize further manual interaction, shape priors help to constrain the predictions to the set of natural variations. In this paper, we show how spherical harmonics can be used as an alternative way to inherently constrain the predictions of neural networks for the segmentation of cells in 3D microscopy image data. Benefits and limitations of the spherical harmonic representation are analyzed and final results are compared to other state-of-the-art approaches on two different data sets.
A Fully Convolutional Two-Stream Fusion Network for Interactive Image Segmentation
Oct 02, 2018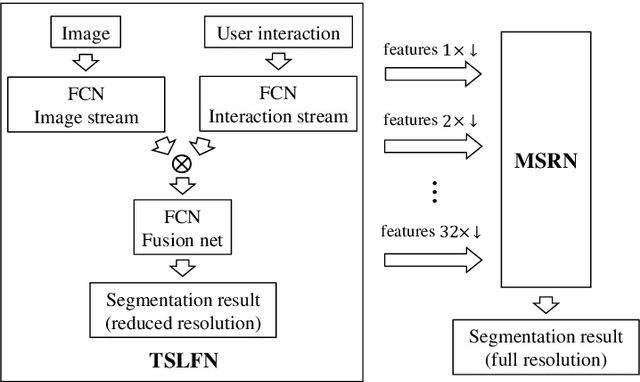
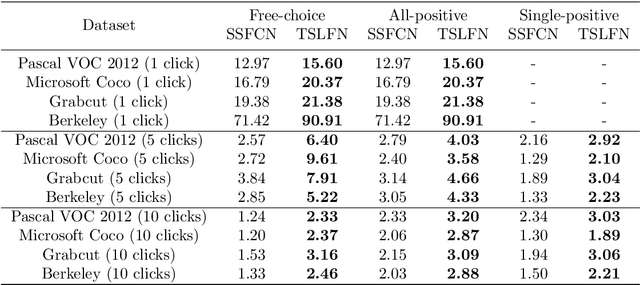
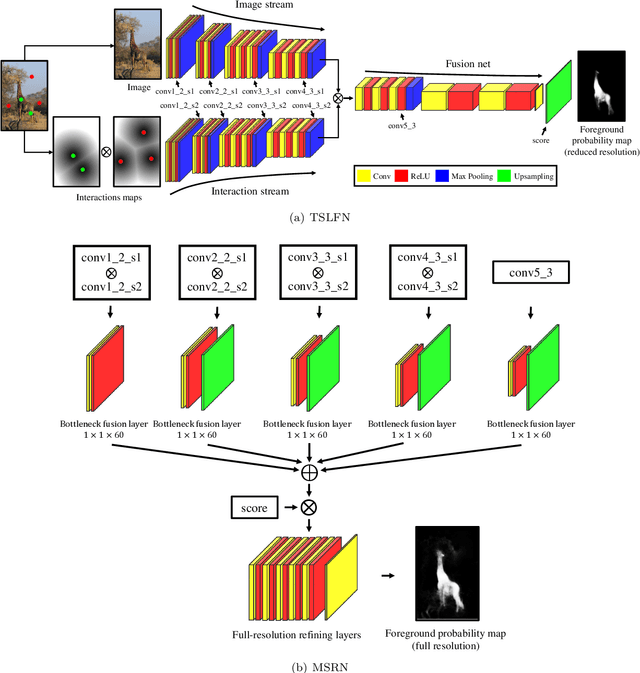
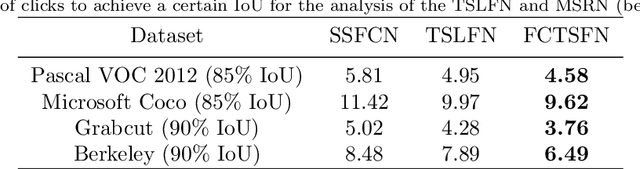
In this paper, we propose a novel fully convolutional two-stream fusion network (FCTSFN) for interactive image segmentation. The proposed network includes two sub-networks: a two-stream late fusion network (TSLFN) that predicts the foreground at a reduced resolution, and a multi-scale refining network (MSRN) that refines the foreground at full resolution. The TSLFN includes two distinct deep streams followed by a fusion network. The intuition is that, since user interactions are more direct information on foreground/background than the image itself, the two-stream structure of the TSLFN reduces the number of layers between the pure user interaction features and the network output, allowing the user interactions to have a more direct impact on the segmentation result. The MSRN fuses the features from different layers of TSLFN with different scales, in order to seek the local to global information on the foreground to refine the segmentation result at full resolution. We conduct comprehensive experiments on four benchmark datasets. The results show that the proposed network achieves competitive performance compared to current state-of-the-art interactive image segmentation methods
SpeakingFaces: A Large-Scale Multimodal Dataset of Voice Commands with Visual and Thermal Video Streams
Dec 18, 2020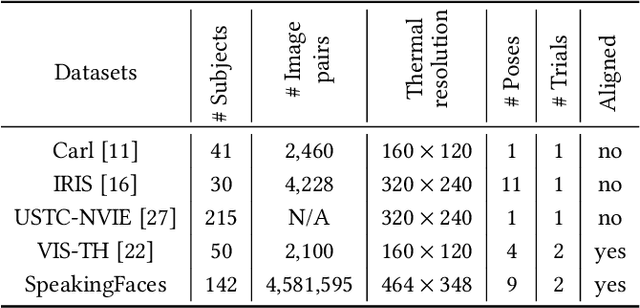


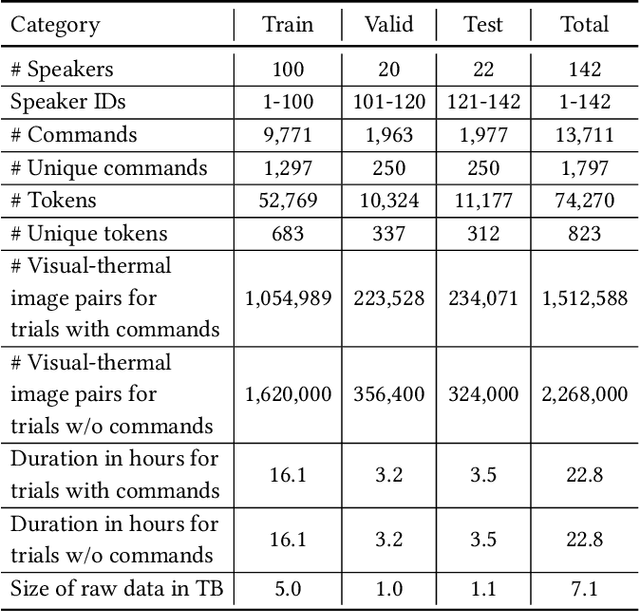
We present SpeakingFaces as a publicly-available large-scale dataset developed to support multimodal machine learning research in contexts that utilize a combination of thermal, visual, and audio data streams; examples include human-computer interaction (HCI), biometric authentication, recognition systems, domain transfer, and speech recognition. SpeakingFaces is comprised of well-aligned high-resolution thermal and visual spectra image streams of fully-framed faces synchronized with audio recordings of each subject speaking approximately 100 imperative phrases. Data were collected from 142 subjects, yielding over 13,000 instances of synchronized data (~3.8 TB). For technical validation, we demonstrate two baseline examples. The first baseline shows classification by gender, utilizing different combinations of the three data streams in both clean and noisy environments. The second example consists of thermal-to-visual facial image translation, as an instance of domain transfer.
An Image Clustering Auto-Encoder Based on Predefined Evenly-Distributed Class Centroids and MMD Distance
Jun 10, 2019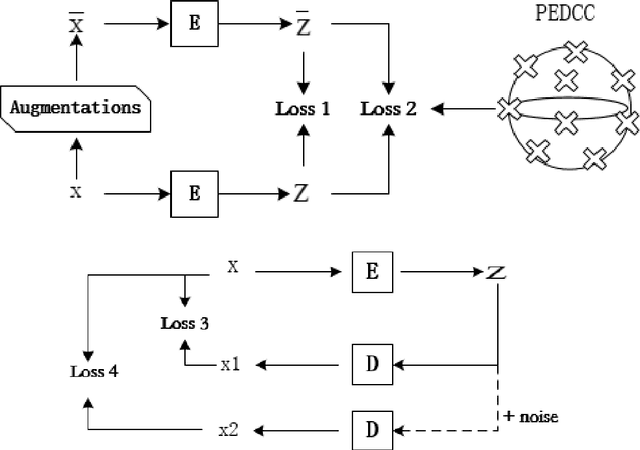
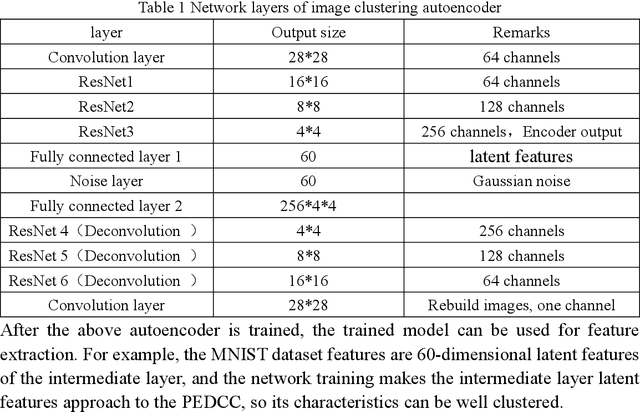

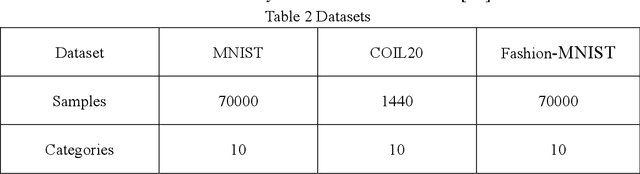
In this paper, we propose an end-to-end image clustering auto-encoder algorithm: ICAE. The algorithm uses PEDCC (Predefined Evenly-Distributed Class Centroids) as the clustering centers of the images, which ensures the inter-class distance of latent features is maximal, and adds data distribution constraint, data augmentation constraint, auto-encoder reconstruction loss constraint and latent features plus noise constraint to improve clustering performance. Specifically, we perform one-to-one data augmentation such as rotation, shear, and shift before data is input to the encoder to learn the more effective features. The data and the enhanced data are simultaneously input into the auto-encoder to obtain latent features and augmented latent features whose similarity are constrained by an augmentation loss. Then, making use of the MMD distance, we combine the latent features and augmented latent features to make their distribution close to the PEDCC distribution (uniform distribution between classes, Dirac distribution within the class) to further learn the features used for clustering. At the same time, the MSE of the original input image and reconstructed image is used as reconstruction constraint, and the noise is added to the latent features to build generalization constraint to improve the generalization ability. Finally, extensive experiments on three common datasets MNIST, Fashion-MNIST, COIL20 are conducted. The experimental results show that the algorithm has achieved the best clustering results so far, and also has good generalization ability. In addition, we can use the pre-defined PEDCC class centers, and the decoding module of the auto-encoder to clearly generate the samples of each class. The code can be downloaded at xxx!
Local Aggressive Adversarial Attacks on 3D Point Cloud
May 19, 2021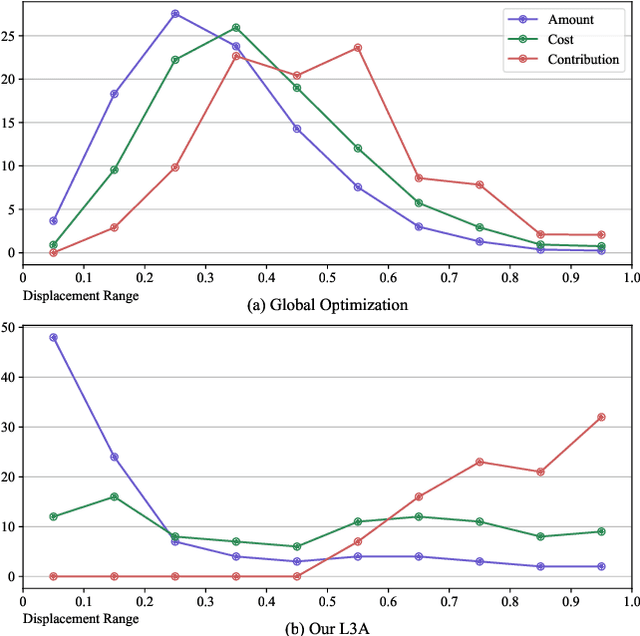
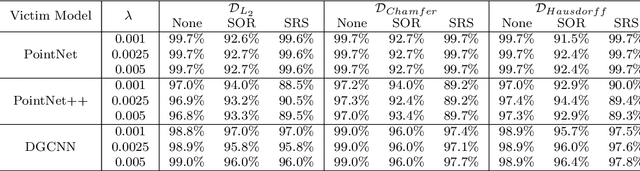
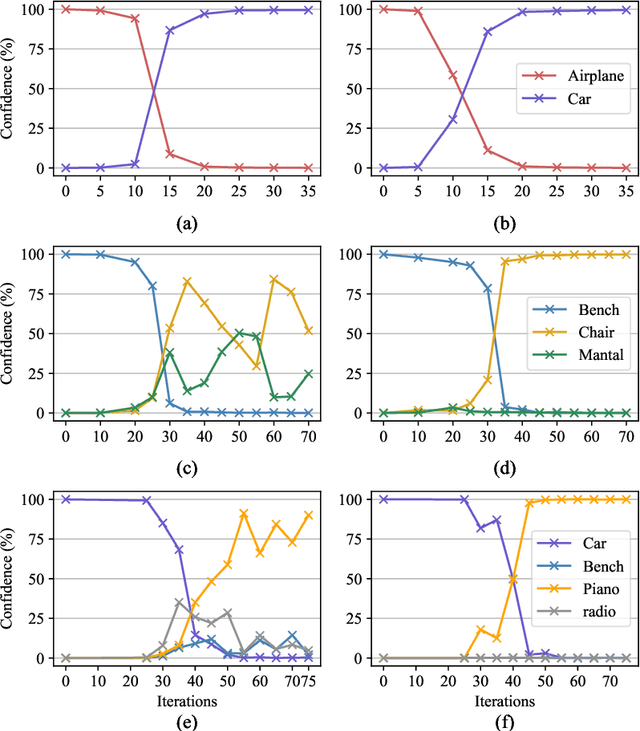
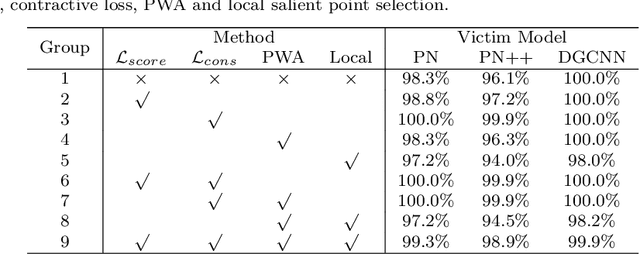
Deep neural networks are found to be prone to adversarial examples which could deliberately fool the model to make mistakes. Recently, a few of works expand this task from 2D image to 3D point cloud by using global point cloud optimization. However, the perturbations of global point are not effective for misleading the victim model. First, not all points are important in optimization toward misleading. Abundant points account considerable distortion budget but contribute trivially to attack. Second, the multi-label optimization is suboptimal for adversarial attack, since it consumes extra energy in finding multi-label victim model collapse and causes instance transformation to be dissimilar to any particular instance. Third, the independent adversarial and perceptibility losses, caring misclassification and dissimilarity separately, treat the updating of each point equally without a focus. Therefore, once perceptibility loss approaches its budget threshold, all points would be stock in the surface of hypersphere and attack would be locked in local optimality. Therefore, we propose a local aggressive adversarial attacks (L3A) to solve above issues. Technically, we select a bunch of salient points, the high-score subset of point cloud according to gradient, to perturb. Then a flow of aggressive optimization strategies are developed to reinforce the unperceptive generation of adversarial examples toward misleading victim models. Extensive experiments on PointNet, PointNet++ and DGCNN demonstrate the state-of-the-art performance of our method against existing adversarial attack methods.
C2FNAS: Coarse-to-Fine Neural Architecture Search for 3D Medical Image Segmentation
Dec 20, 2019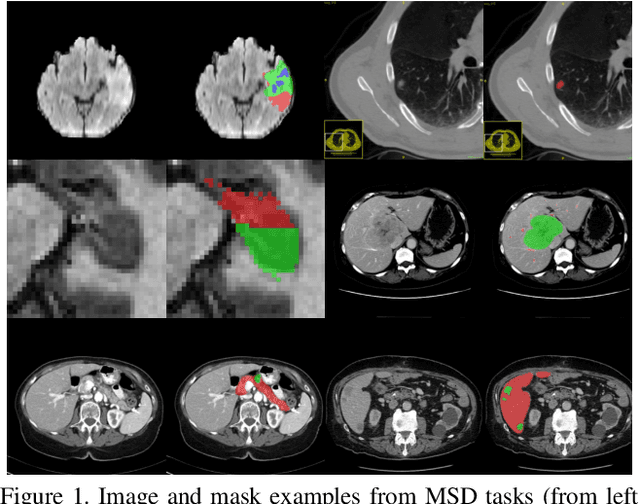
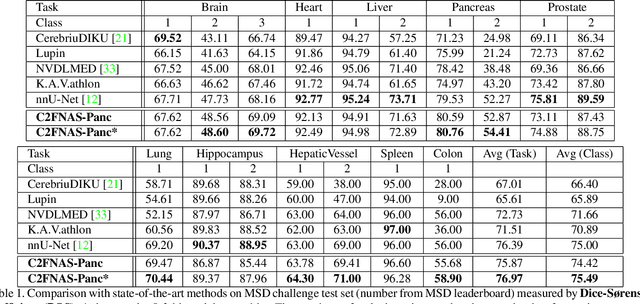

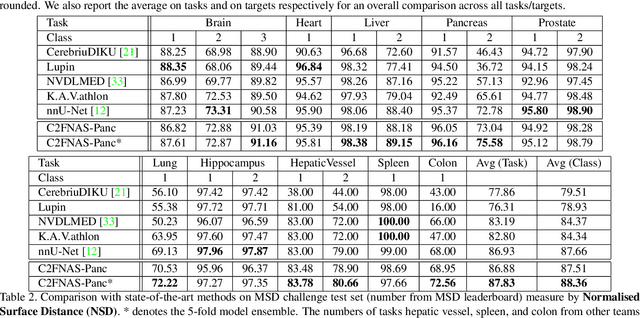
3D convolution neural networks (CNN) have been proved very successful in parsing organs or tumours in 3D medical images, but it remains sophisticated and time-consuming to choose or design proper 3D networks given different task contexts. Recently, Neural Architecture Search (NAS) is proposed to solve this problem by searching for the best network architecture automatically. However, the inconsistency between search stage and deployment stage often exists in NAS algorithms due to memory constraints and large search space, which could become more serious when applying NAS to some memory and time consuming tasks, such as 3D medical image segmentation. In this paper, we propose coarse-to-fine neural architecture search (C2FNAS) to automatically search a 3D segmentation network from scratch without inconsistency on network size or input size. Specifically, we divide the search procedure into two stages: 1) the coarse stage, where we search the macro-level topology of the network, i.e. how each convolution module is connected to other modules; 2) the fine stage, where we search at micro-level for operations in each cell based on previous searched macro-level topology. The coarse-to-fine manner divides the search procedure into two consecutive stages and meanwhile resolves the inconsistency. We evaluate our method on 10 public datasets from Medical Segmentation Decalthon (MSD) challenge, and achieve state-of-the-art performance with the network searched using one dataset, which demonstrates the effectiveness and generalization of our searched models.
Cross-Modal Alignment with Mixture Experts Neural Network for Intral-City Retail Recommendation
Sep 17, 2020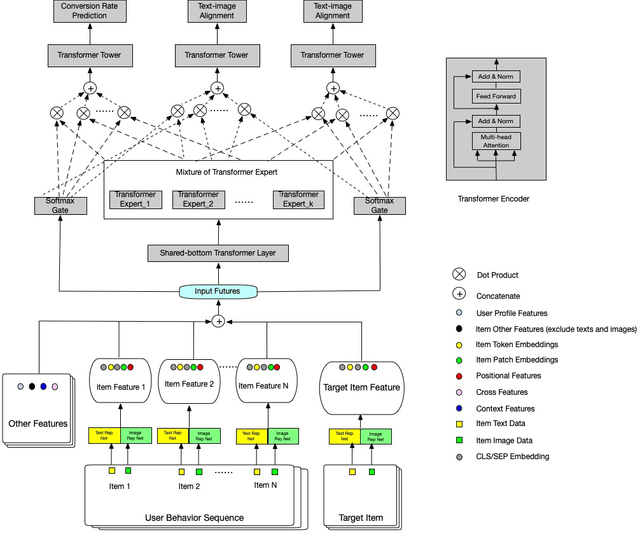
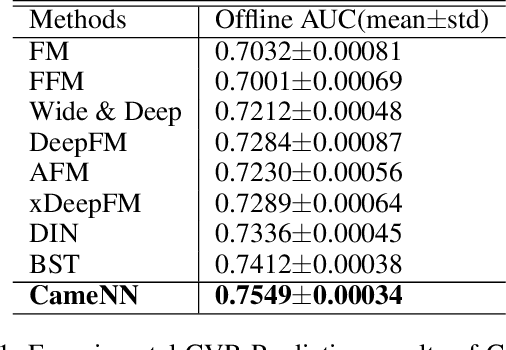
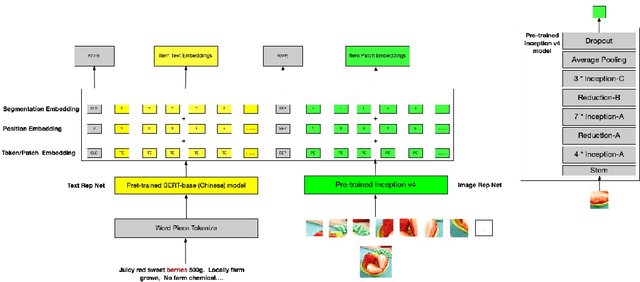

In this paper, we introduce Cross-modal Alignment with mixture experts Neural Network (CameNN) recommendation model for intral-city retail industry, which aims to provide fresh foods and groceries retailing within 5 hours delivery service arising for the outbreak of Coronavirus disease (COVID-19) pandemic around the world. We propose CameNN, which is a multi-task model with three tasks including Image to Text Alignment (ITA) task, Text to Image Alignment (TIA) task and CVR prediction task. We use pre-trained BERT to generate the text embedding and pre-trained InceptionV4 to generate image patch embedding (each image is split into small patches with the same pixels and treat each patch as an image token). Softmax gating networks follow to learn the weight of each transformer expert output and choose only a subset of experts conditioned on the input. Then transformer encoder is applied as the share-bottom layer to learn all input features' shared interaction. Next, mixture of transformer experts (MoE) layer is implemented to model different aspects of tasks. At top of the MoE layer, we deploy a transformer layer for each task as task tower to learn task-specific information. On the real word intra-city dataset, experiments demonstrate CameNN outperform baselines and achieve significant improvements on the image and text representation. In practice, we applied CameNN on CVR prediction in our intra-city recommender system which is one of the leading intra-city platforms operated in China.
Object-Based Augmentation Improves Quality of Remote SensingSemantic Segmentation
May 12, 2021
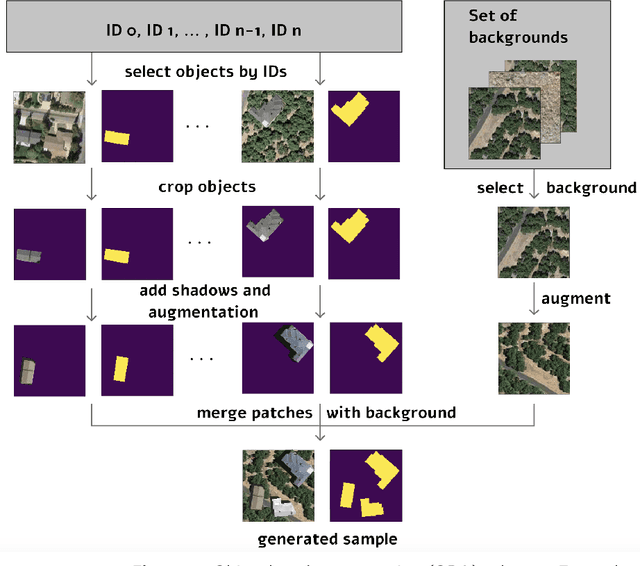


Today deep convolutional neural networks (CNNs) push the limits for most computer vision problems, define trends, and set state-of-the-art results. In remote sensing tasks such as object detection and semantic segmentation, CNNs reach the SotA performance. However, for precise performance, CNNs require much high-quality training data. Rare objects and the variability of environmental conditions strongly affect prediction stability and accuracy. To overcome these data restrictions, it is common to consider various approaches including data augmentation techniques. This study focuses on the development and testing of object-based augmentation. The practical usefulness of the developed augmentation technique is shown in the remote sensing domain, being one of the most demanded ineffective augmentation techniques. We propose a novel pipeline for georeferenced image augmentation that enables a significant increase in the number of training samples. The presented pipeline is called object-based augmentation (OBA) and exploits objects' segmentation masks to produce new realistic training scenes using target objects and various label-free backgrounds. We test the approach on the buildings segmentation dataset with six different CNN architectures and show that the proposed method benefits for all the tested models. We also show that further augmentation strategy optimization can improve the results. The proposed method leads to the meaningful improvement of U-Net model predictions from 0.78 to 0.83 F1-score.
3D Scene Compression through Entropy Penalized Neural Representation Functions
Apr 26, 2021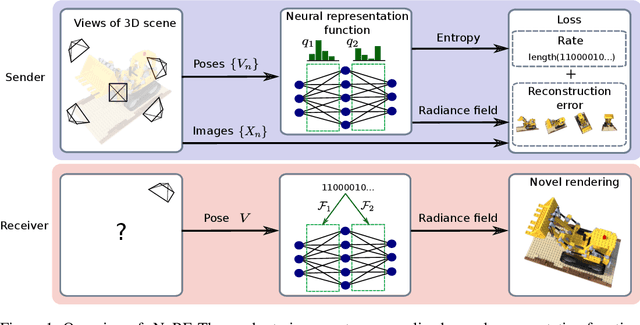
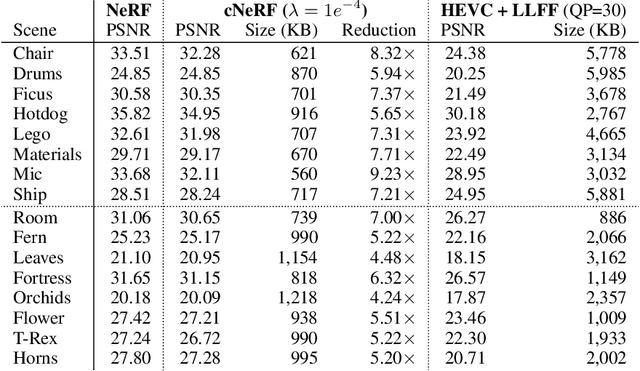
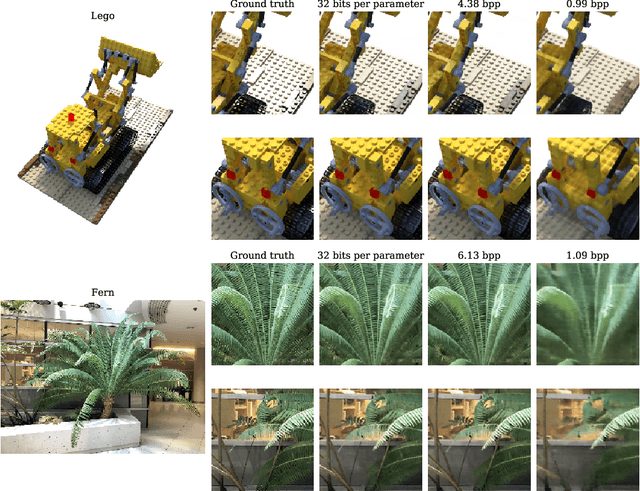
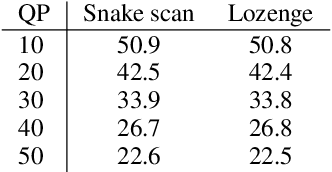
Some forms of novel visual media enable the viewer to explore a 3D scene from arbitrary viewpoints, by interpolating between a discrete set of original views. Compared to 2D imagery, these types of applications require much larger amounts of storage space, which we seek to reduce. Existing approaches for compressing 3D scenes are based on a separation of compression and rendering: each of the original views is compressed using traditional 2D image formats; the receiver decompresses the views and then performs the rendering. We unify these steps by directly compressing an implicit representation of the scene, a function that maps spatial coordinates to a radiance vector field, which can then be queried to render arbitrary viewpoints. The function is implemented as a neural network and jointly trained for reconstruction as well as compressibility, in an end-to-end manner, with the use of an entropy penalty on the parameters. Our method significantly outperforms a state-of-the-art conventional approach for scene compression, achieving simultaneously higher quality reconstructions and lower bitrates. Furthermore, we show that the performance at lower bitrates can be improved by jointly representing multiple scenes using a soft form of parameter sharing.