 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Modulating Image Restoration with Continual Levels via Adaptive Feature Modification Layers
Apr 17, 2019

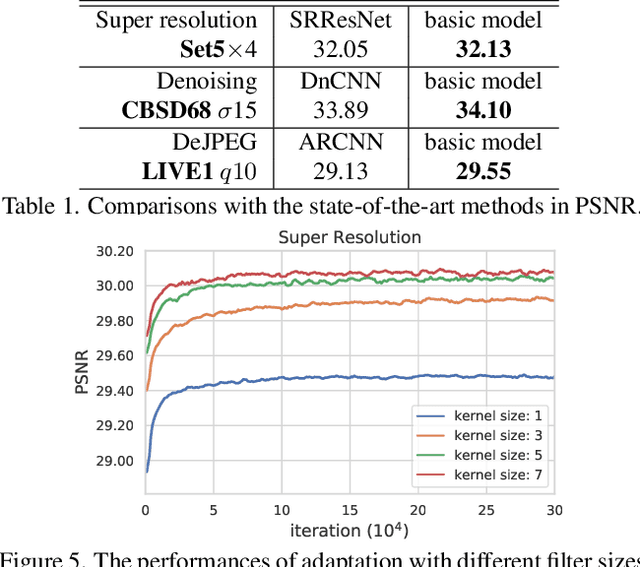

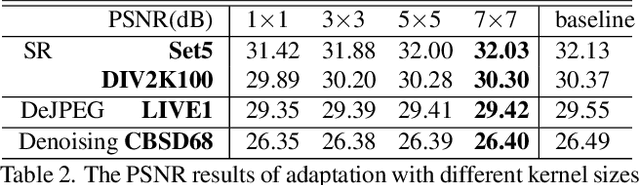
In image restoration tasks, learning from discrete and fixed restoration levels, deep models cannot be easily generalized to data of continuous and unseen levels. We make a step forward by proposing a unified CNN framework that consists of few additional parameters than a single-level model yet could handle arbitrary restoration levels between a start and an end level. The additional module, namely AdaFM layer, performs channel-wise feature modification, and can adapt a model to another restoration level with high accuracy.
Explaining Image Classifiers by Counterfactual Generation
Oct 11, 2018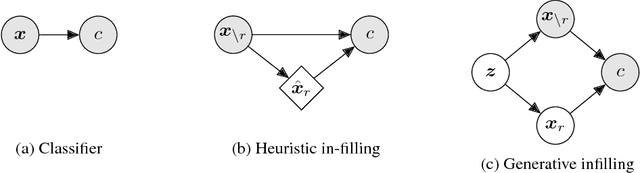

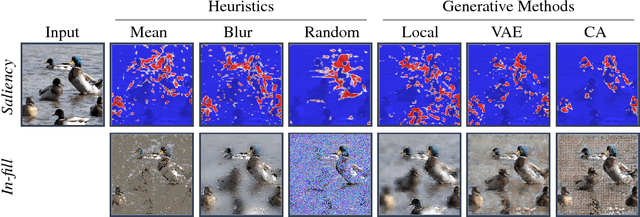

When a black-box classifier processes an input to render a prediction, which input features are relevant and why? We propose to answer this question by efficiently marginalizing over the universe of plausible alternative values for a subset of features by conditioning a generative model of the input distribution on the remaining features. In contrast with recent approaches that compute alternative feature values ad-hoc --- generating counterfactual inputs far from the natural data distribution --- our model-agnostic method produces realistic explanations, generating plausible inputs that either preserve or alter the classification confidence. When applied to image classification, our method produces more compact and relevant per-feature saliency assignment, with fewer artifacts compared to previous methods.
Multi-temporal Sentinel-1 and -2 Data Fusion for Optical Image Simulation
Jul 26, 2018

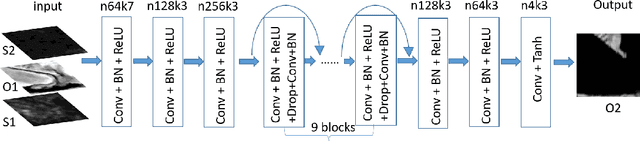
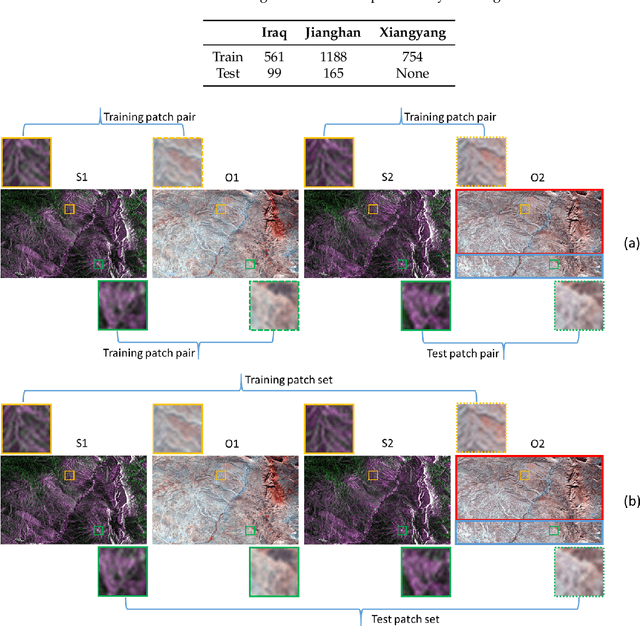
In this paper, we present the optical image simulation from a synthetic aperture radar (SAR) data using deep learning based methods. Two models, i.e., optical image simulation directly from the SAR data and from multi-temporal SARoptical data, are proposed to testify the possibilities. The deep learning based methods that we chose to achieve the models are a convolutional neural network (CNN) with a residual architecture and a conditional generative adversarial network (cGAN). We validate our models using the Sentinel-1 and -2 datasets. The experiments demonstrate that the model with multi-temporal SAR-optical data can successfully simulate the optical image, meanwhile, the model with simple SAR data as input failed. The optical image simulation results indicate the possibility of SARoptical information blending for the subsequent applications such as large-scale cloud removal, and optical data temporal superresolution. We also investigate the sensitivity of the proposed models against the training samples, and reveal possible future directions.
An Enhanced Prohibited Items Recognition Model
Feb 24, 2021
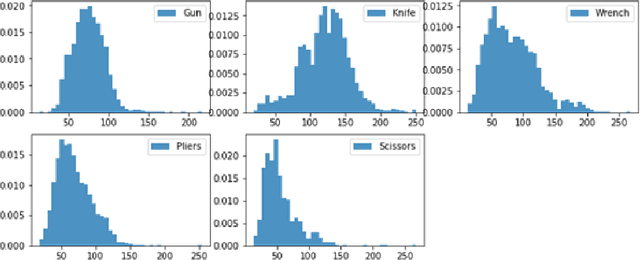


We proposed a new modeling method to promote the performance of prohibited items recognition via X-ray image. We analyzed the characteristics of prohibited items and X-ray images. We found the fact that the scales of some items are too small to be recognized which encumber the model performance. Then we adopted a set of data augmentation and modified the model to adapt the field of prohibited items recognition. The Convolutional Block Attention Module(CBAM) and rescoring mechanism has been assembled into the model. By the modification, our model achieved a mAP of 89.9% on SIXray10, mAP of 74.8%.
Multi-Modal Fusion Transformer for End-to-End Autonomous Driving
Apr 19, 2021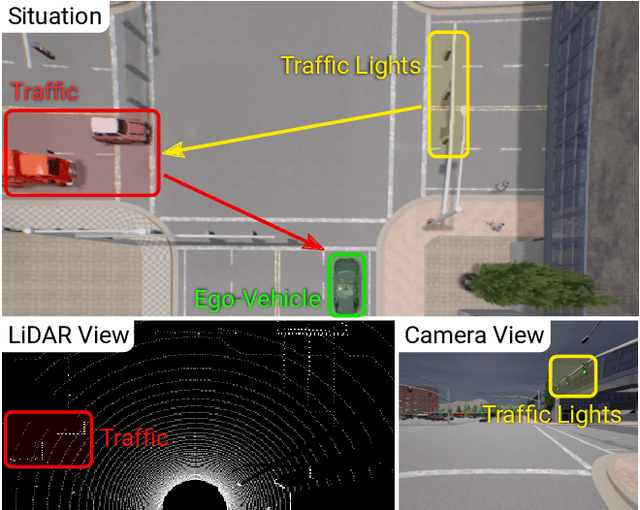
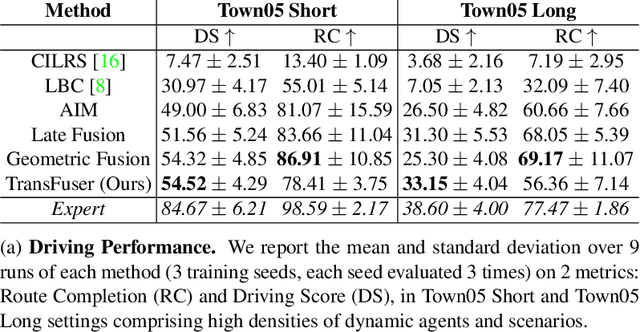
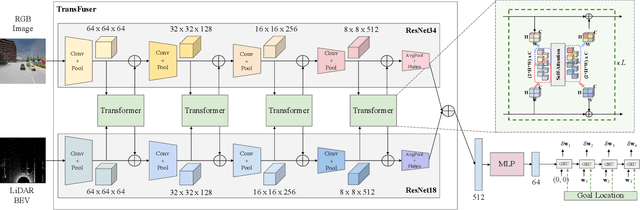
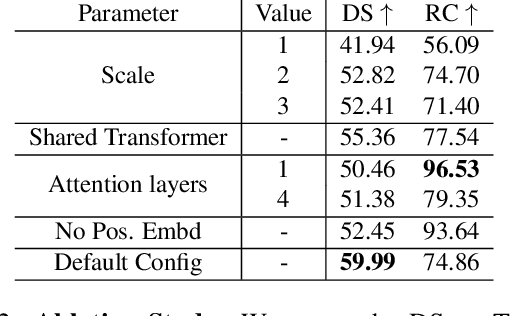
How should representations from complementary sensors be integrated for autonomous driving? Geometry-based sensor fusion has shown great promise for perception tasks such as object detection and motion forecasting. However, for the actual driving task, the global context of the 3D scene is key, e.g. a change in traffic light state can affect the behavior of a vehicle geometrically distant from that traffic light. Geometry alone may therefore be insufficient for effectively fusing representations in end-to-end driving models. In this work, we demonstrate that imitation learning policies based on existing sensor fusion methods under-perform in the presence of a high density of dynamic agents and complex scenarios, which require global contextual reasoning, such as handling traffic oncoming from multiple directions at uncontrolled intersections. Therefore, we propose TransFuser, a novel Multi-Modal Fusion Transformer, to integrate image and LiDAR representations using attention. We experimentally validate the efficacy of our approach in urban settings involving complex scenarios using the CARLA urban driving simulator. Our approach achieves state-of-the-art driving performance while reducing collisions by 76% compared to geometry-based fusion.
Towards Adversarial Retinal Image Synthesis
Jan 31, 2017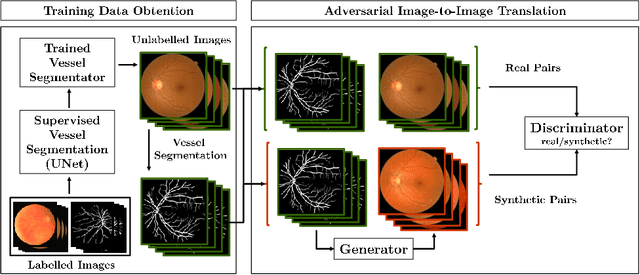
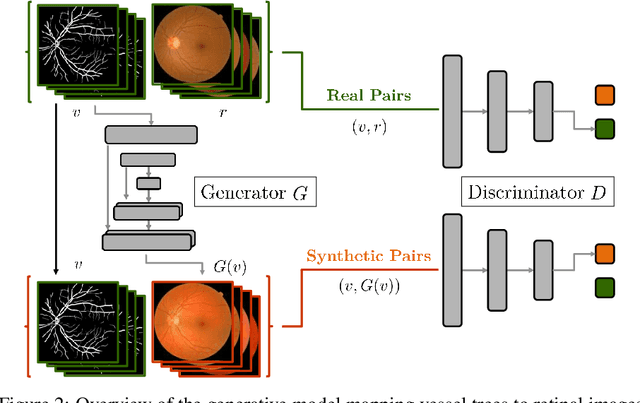

Synthesizing images of the eye fundus is a challenging task that has been previously approached by formulating complex models of the anatomy of the eye. New images can then be generated by sampling a suitable parameter space. In this work, we propose a method that learns to synthesize eye fundus images directly from data. For that, we pair true eye fundus images with their respective vessel trees, by means of a vessel segmentation technique. These pairs are then used to learn a mapping from a binary vessel tree to a new retinal image. For this purpose, we use a recent image-to-image translation technique, based on the idea of adversarial learning. Experimental results show that the original and the generated images are visually different in terms of their global appearance, in spite of sharing the same vessel tree. Additionally, a quantitative quality analysis of the synthetic retinal images confirms that the produced images retain a high proportion of the true image set quality.
Cross-Modal Alignment with Mixture Experts Neural Network for Intral-City Retail Recommendation
Sep 17, 2020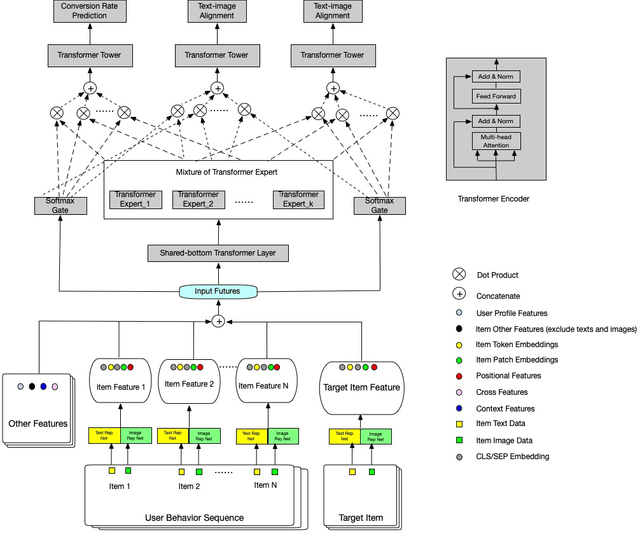
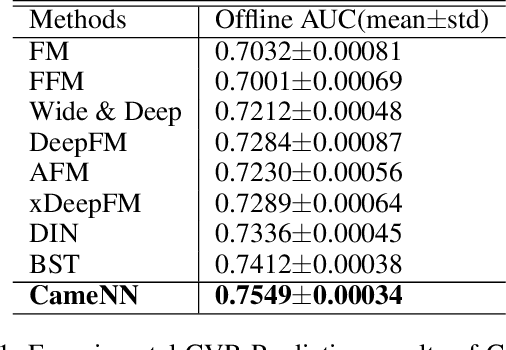
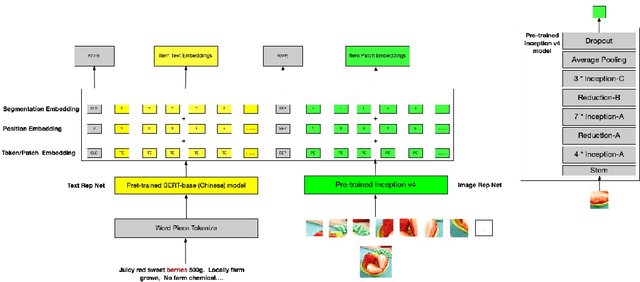

In this paper, we introduce Cross-modal Alignment with mixture experts Neural Network (CameNN) recommendation model for intral-city retail industry, which aims to provide fresh foods and groceries retailing within 5 hours delivery service arising for the outbreak of Coronavirus disease (COVID-19) pandemic around the world. We propose CameNN, which is a multi-task model with three tasks including Image to Text Alignment (ITA) task, Text to Image Alignment (TIA) task and CVR prediction task. We use pre-trained BERT to generate the text embedding and pre-trained InceptionV4 to generate image patch embedding (each image is split into small patches with the same pixels and treat each patch as an image token). Softmax gating networks follow to learn the weight of each transformer expert output and choose only a subset of experts conditioned on the input. Then transformer encoder is applied as the share-bottom layer to learn all input features' shared interaction. Next, mixture of transformer experts (MoE) layer is implemented to model different aspects of tasks. At top of the MoE layer, we deploy a transformer layer for each task as task tower to learn task-specific information. On the real word intra-city dataset, experiments demonstrate CameNN outperform baselines and achieve significant improvements on the image and text representation. In practice, we applied CameNN on CVR prediction in our intra-city recommender system which is one of the leading intra-city platforms operated in China.
TCLR: Temporal Contrastive Learning for Video Representation
Jan 20, 2021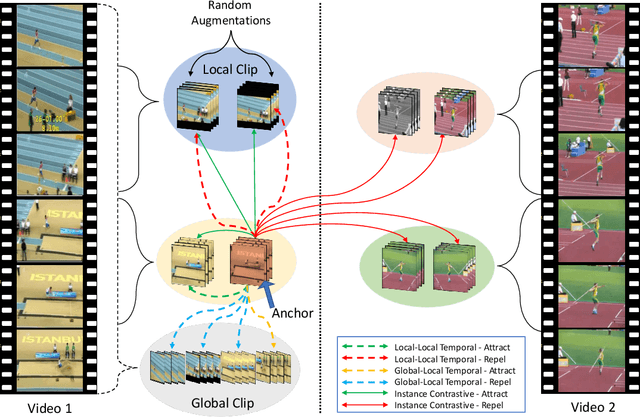
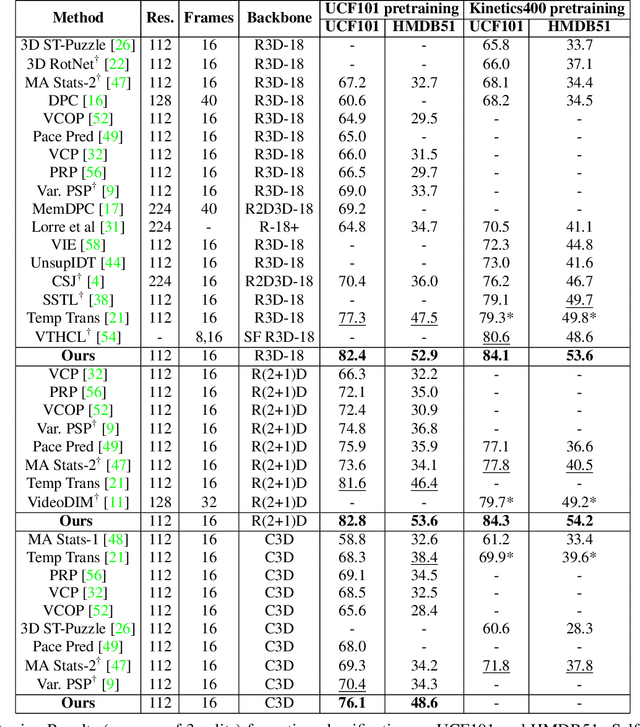
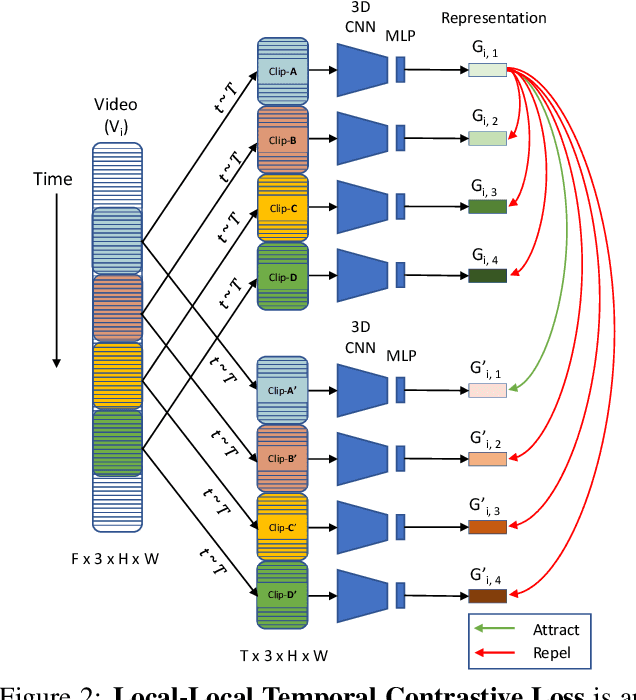
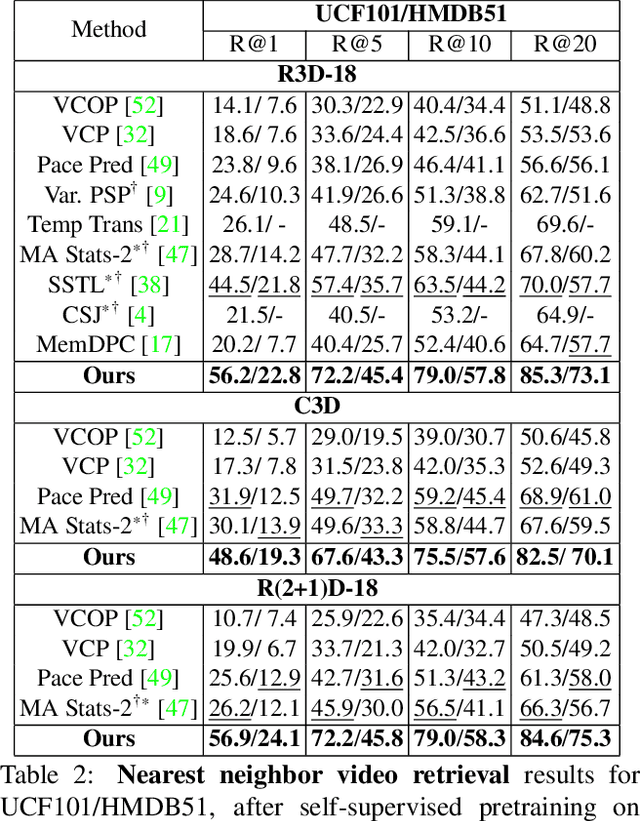
Contrastive learning has nearly closed the gap between supervised and self-supervised learning of image representations. Existing extensions of contrastive learning to the domain of video data however, rely on naive transposition of ideas from image-based methods and do not fully utilize the temporal dimension present in video. We develop a new temporal contrastive learning framework consisting of two novel losses to improve upon existing contrastive self-supervised video representation learning methods. The first loss adds the task of discriminating between non-overlapping clips from the same video, whereas the second loss aims to discriminate between timesteps of the feature map of an input clip in order to increase the temporal diversity of the features. Temporal contrastive learning achieves significant improvement over the state-of-the-art results in downstream video understanding tasks such as action recognition, limited-label action classification, and nearest-neighbor video retrieval on video datasets across multiple 3D CNN architectures. With the commonly used 3D-ResNet-18 architecture, we achieve 82.4% (+5.1% increase over the previous best) top-1 accuracy on UCF101 and 52.9% (+5.4% increase) on HMDB51 action classification, and 56.2% (+11.7% increase) Top-1 Recall on UCF101 nearest neighbor video retrieval.
Spherical Harmonics for Shape-Constrained 3D Cell Segmentation
Oct 23, 2020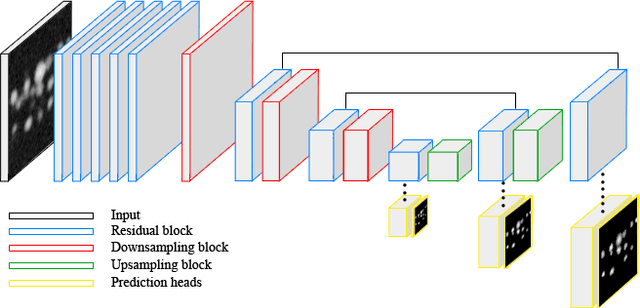
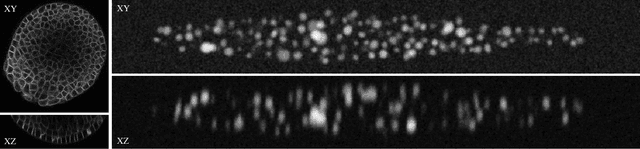
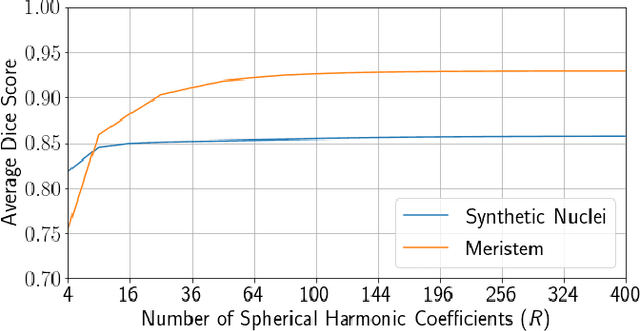
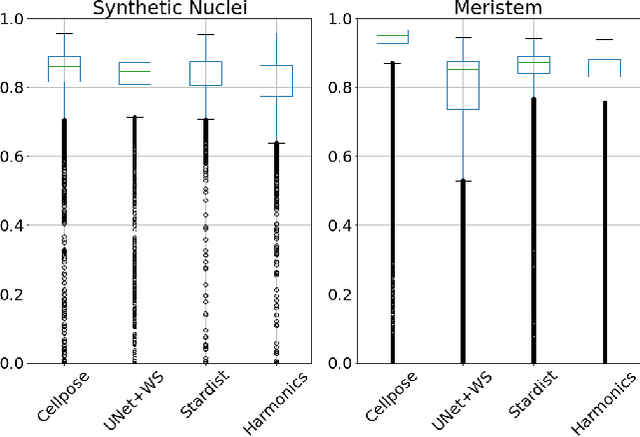
Recent microscopy imaging techniques allow to precisely analyze cell morphology in 3D image data. To process the vast amount of image data generated by current digitized imaging techniques, automated approaches are demanded more than ever. Segmentation approaches used for morphological analyses, however, are often prone to produce unnaturally shaped predictions, which in conclusion could lead to inaccurate experimental outcomes. In order to minimize further manual interaction, shape priors help to constrain the predictions to the set of natural variations. In this paper, we show how spherical harmonics can be used as an alternative way to inherently constrain the predictions of neural networks for the segmentation of cells in 3D microscopy image data. Benefits and limitations of the spherical harmonic representation are analyzed and final results are compared to other state-of-the-art approaches on two different data sets.
Are we using appropriate segmentation metrics? Identifying correlates of human expert perception for CNN training beyond rolling the DICE coefficient
Mar 10, 2021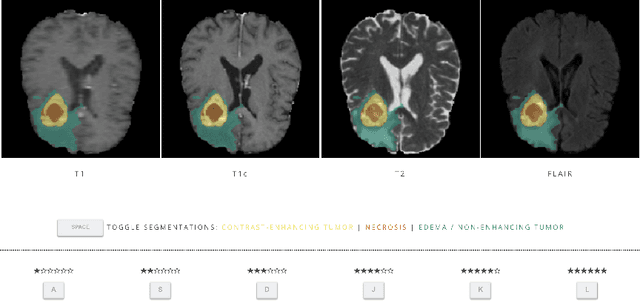

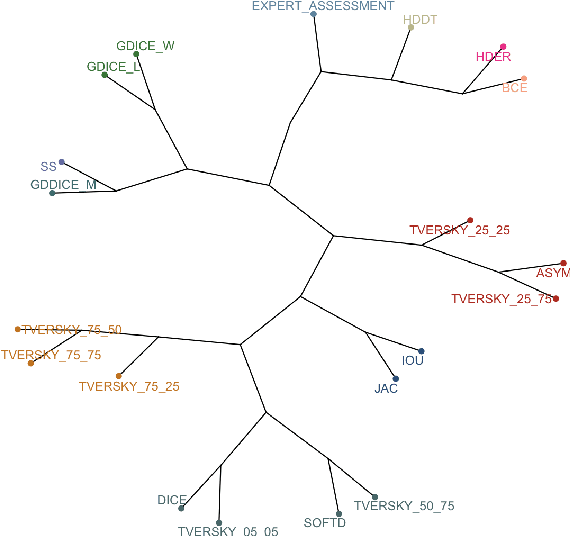

In this study, we explore quantitative correlates of qualitative human expert perception. We discover that current quality metrics and loss functions, considered for biomedical image segmentation tasks, correlate moderately with segmentation quality assessment by experts, especially for small yet clinically relevant structures, such as the enhancing tumor in brain glioma. We propose a method employing classical statistics and experimental psychology to create complementary compound loss functions for modern deep learning methods, towards achieving a better fit with human quality assessment. When training a CNN for delineating adult brain tumor in MR images, all four proposed loss candidates outperform the established baselines on the clinically important and hardest to segment enhancing tumor label, while maintaining performance for other label channels.