 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Modeling Graph Node Correlations with Neighbor Mixture Models
Apr 18, 2021

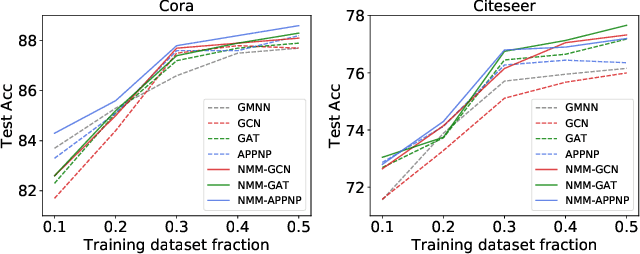
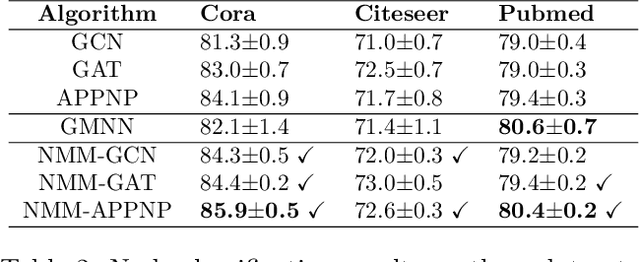
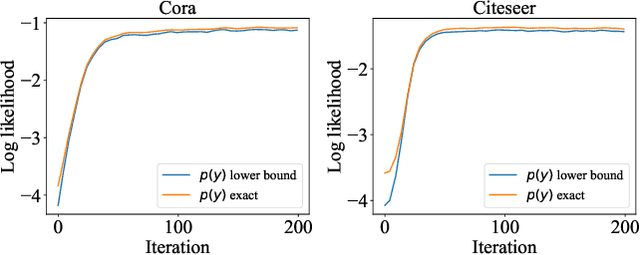
We propose a new model, the Neighbor Mixture Model (NMM), for modeling node labels in a graph. This model aims to capture correlations between the labels of nodes in a local neighborhood. We carefully design the model so it could be an alternative to a Markov Random Field but with more affordable computations. In particular, drawing samples and evaluating marginal probabilities of single labels can be done in linear time. To scale computations to large graphs, we devise a variational approximation without introducing extra parameters. We further use graph neural networks (GNNs) to parameterize the NMM, which reduces the number of learnable parameters while allowing expressive representation learning. The proposed model can be either fit directly to large observed graphs or used to enable scalable inference that preserves correlations for other distributions such as deep generative graph models. Across a diverse set of node classification, image denoising, and link prediction tasks, we show our proposed NMM advances the state-of-the-art in modeling real-world labeled graphs.
Peeking Behind Objects: Layered Depth Prediction from a Single Image
Jul 23, 2018
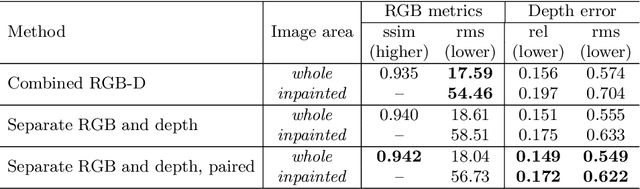
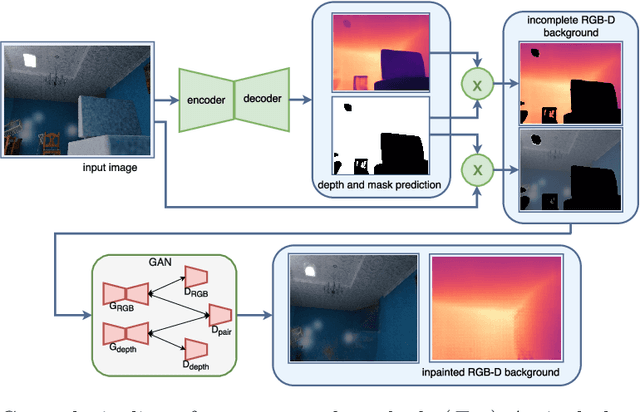
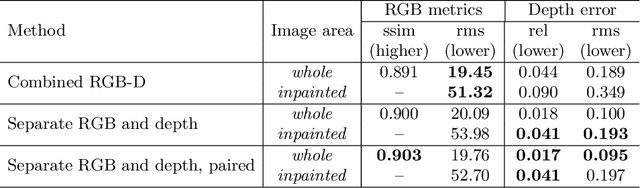
While conventional depth estimation can infer the geometry of a scene from a single RGB image, it fails to estimate scene regions that are occluded by foreground objects. This limits the use of depth prediction in augmented and virtual reality applications, that aim at scene exploration by synthesizing the scene from a different vantage point, or at diminished reality. To address this issue, we shift the focus from conventional depth map prediction to the regression of a specific data representation called Layered Depth Image (LDI), which contains information about the occluded regions in the reference frame and can fill in occlusion gaps in case of small view changes. We propose a novel approach based on Convolutional Neural Networks (CNNs) to jointly predict depth maps and foreground separation masks used to condition Generative Adversarial Networks (GANs) for hallucinating plausible color and depths in the initially occluded areas. We demonstrate the effectiveness of our approach for novel scene view synthesis from a single image.
Temporally-Transferable Perturbations: Efficient, One-Shot Adversarial Attacks for Online Visual Object Trackers
Dec 30, 2020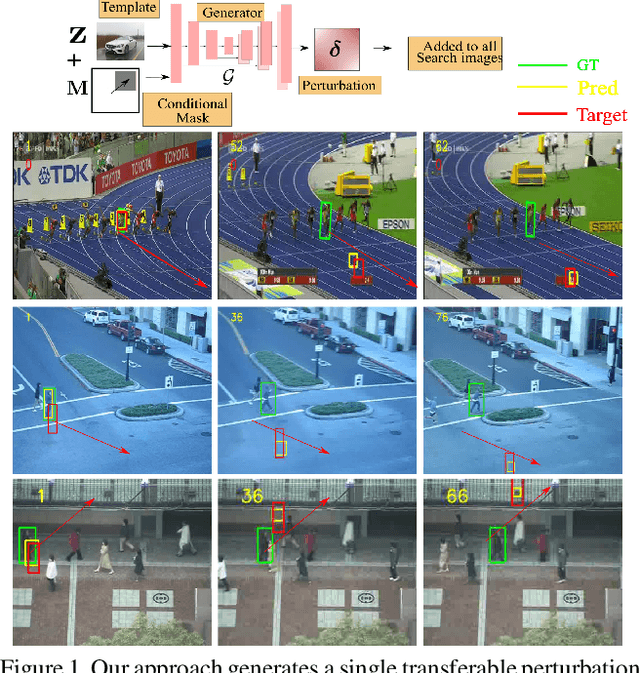
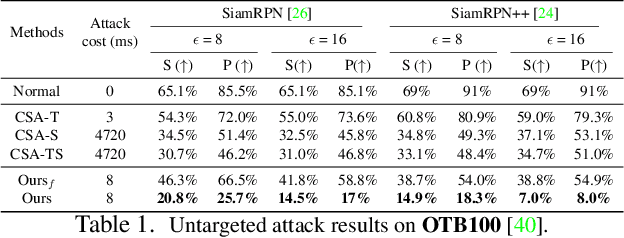
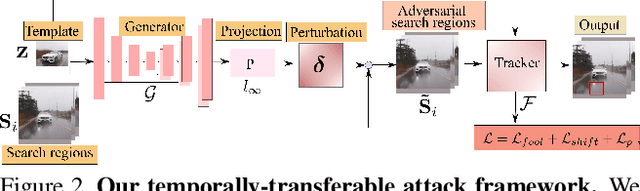
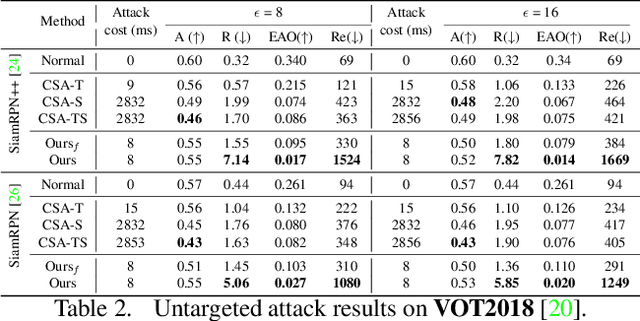
In recent years, the trackers based on Siamese networks have emerged as highly effective and efficient for visual object tracking (VOT). While these methods were shown to be vulnerable to adversarial attacks, as most deep networks for visual recognition tasks, the existing attacks for VOT trackers all require perturbing the search region of every input frame to be effective, which comes at a non-negligible cost, considering that VOT is a real-time task. In this paper, we propose a framework to generate a single temporally transferable adversarial perturbation from the object template image only. This perturbation can then be added to every search image, which comes at virtually no cost, and still, successfully fool the tracker. Our experiments evidence that our approach outperforms the state-of-the-art attacks on the standard VOT benchmarks in the untargeted scenario. Furthermore, we show that our formalism naturally extends to targeted attacks that force the tracker to follow any given trajectory by precomputing diverse directional perturbations.
Cloud-based Image Classification Service Is Not Robust To Simple Transformations: A Forgotten Battlefield
Jun 19, 2019
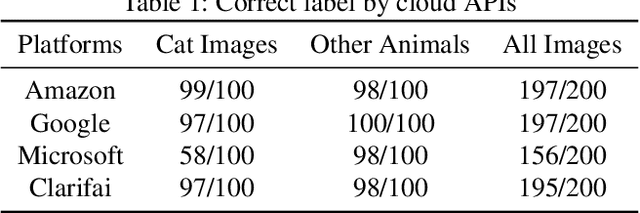

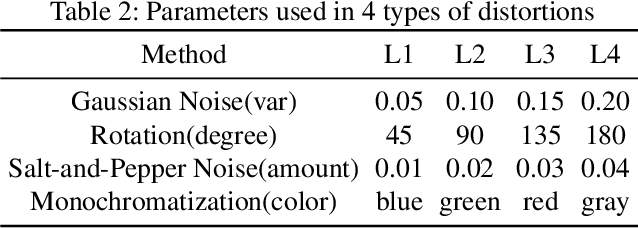
Many recent works demonstrated that Deep Learning models are vulnerable to adversarial examples.Fortunately, generating adversarial examples usually requires white-box access to the victim model, and the attacker can only access the APIs opened by cloud platforms. Thus, keeping models in the cloud can usually give a (false) sense of security.Unfortunately, cloud-based image classification service is not robust to simple transformations such as Gaussian Noise, Salt-and-Pepper Noise, Rotation and Monochromatization. In this paper,(1) we propose one novel attack method called Image Fusion(IF) attack, which achieve a high bypass rate,can be implemented only with OpenCV and is difficult to defend; and (2) we make the first attempt to conduct an extensive empirical study of Simple Transformation (ST) attacks against real-world cloud-based classification services. Through evaluations on four popular cloud platforms including Amazon, Google, Microsoft, Clarifai, we demonstrate that ST attack has a success rate of approximately 100% except Amazon approximately 50%, IF attack have a success rate over 98% among different classification services. (3) We discuss the possible defenses to address these security challenges.Experiments show that our defense technology can effectively defend known ST attacks.
GANchors: Realistic Image Perturbation Distributions for Anchors Using Generative Models
Jun 01, 2019
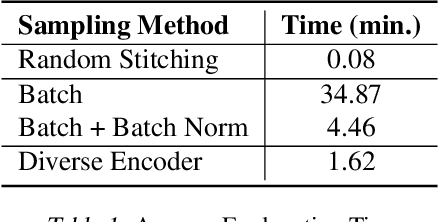

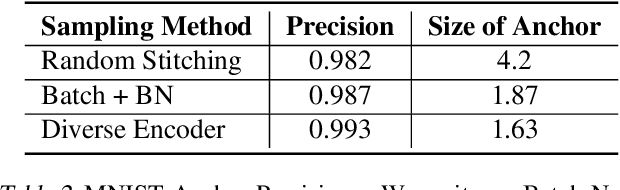
We extend and improve the work of Model Agnostic Anchors for explanations on image classification through the use of generative adversarial networks (GANs). Using GANs, we generate samples from a more realistic perturbation distribution, by optimizing under a lower dimensional latent space. This increases the trust in an explanation, as results now come from images that are more likely to be found in the original training set of a classifier, rather than an overlay of random images. A large drawback to our method is the computational complexity of sampling through optimization; to address this, we implement more efficient algorithms, including a diverse encoder. Lastly, we share results from the MNIST and CelebA datasets, and note that our explanations can lead to smaller and higher precision anchors.
Synthetic Sample Selection via Reinforcement Learning
Aug 26, 2020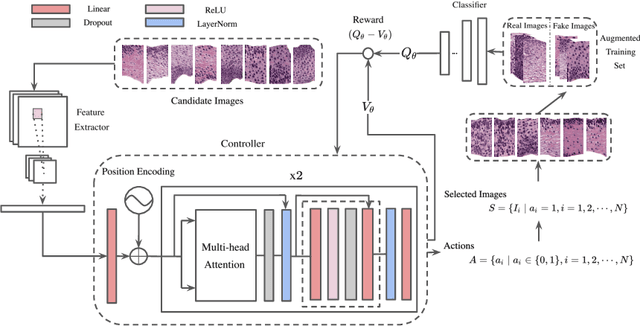
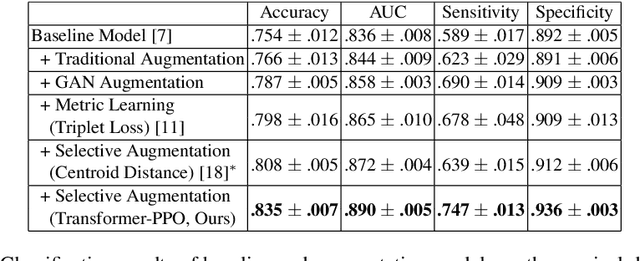
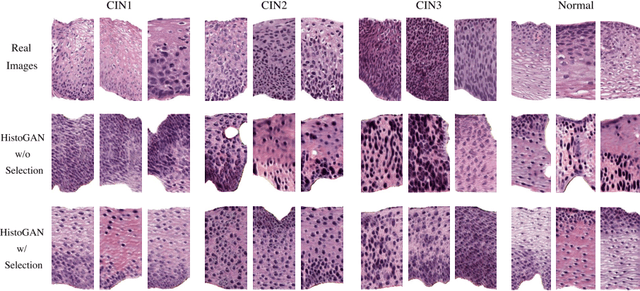
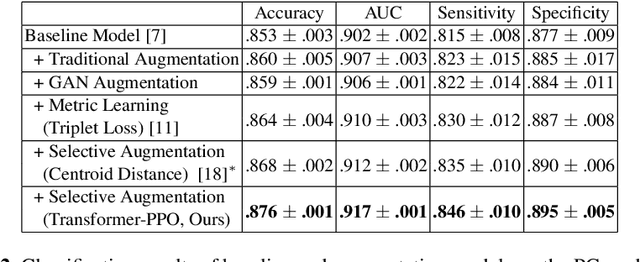
Synthesizing realistic medical images provides a feasible solution to the shortage of training data in deep learning based medical image recognition systems. However, the quality control of synthetic images for data augmentation purposes is under-investigated, and some of the generated images are not realistic and may contain misleading features that distort data distribution when mixed with real images. Thus, the effectiveness of those synthetic images in medical image recognition systems cannot be guaranteed when they are being added randomly without quality assurance. In this work, we propose a reinforcement learning (RL) based synthetic sample selection method that learns to choose synthetic images containing reliable and informative features. A transformer based controller is trained via proximal policy optimization (PPO) using the validation classification accuracy as the reward. The selected images are mixed with the original training data for improved training of image recognition systems. To validate our method, we take the pathology image recognition as an example and conduct extensive experiments on two histopathology image datasets. In experiments on a cervical dataset and a lymph node dataset, the image classification performance is improved by 8.1% and 2.3%, respectively, when utilizing high-quality synthetic images selected by our RL framework. Our proposed synthetic sample selection method is general and has great potential to boost the performance of various medical image recognition systems given limited annotation.
Statistical evaluation of visual quality metrics for image denoising
Nov 02, 2017
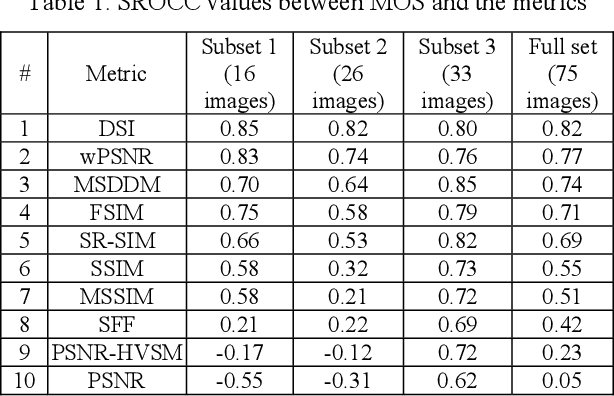

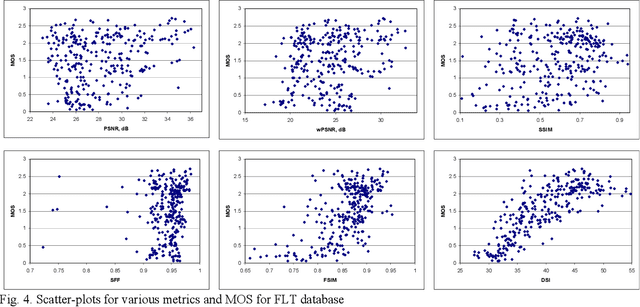
This paper studies the problem of full reference visual quality assessment of denoised images with a special emphasis on images with low contrast and noise-like texture. Denoising of such images together with noise removal often results in image details loss or smoothing. A new test image database, FLT, containing 75 noise-free "reference" images and 300 filtered ("distorted") images is developed. Each reference image, corrupted by an additive white Gaussian noise, is denoised by the BM3D filter with four different values of threshold parameter (four levels of noise suppression). After carrying out a perceptual quality assessment of distorted images, the mean opinion scores (MOS) are obtained and compared with the values of known full reference quality metrics. As a result, the Spearman Rank Order Correlation Coefficient (SROCC) between PSNR values and MOS has a value close to zero, and SROCC between values of known full-reference image visual quality metrics and MOS does not exceed 0.82 (which is reached by a new visual quality metric proposed in this paper). The FLT dataset is more complex than earlier datasets used for assessment of visual quality for image denoising. Thus, it can be effectively used to design new image visual quality metrics for image denoising.
Discriminative Cross-Modal Data Augmentation for Medical Imaging Applications
Oct 07, 2020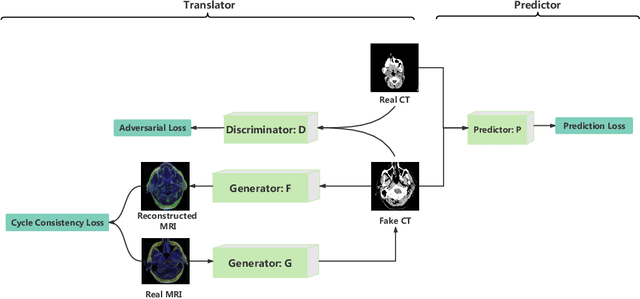
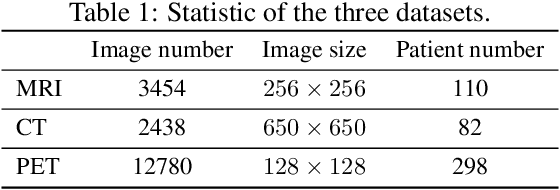

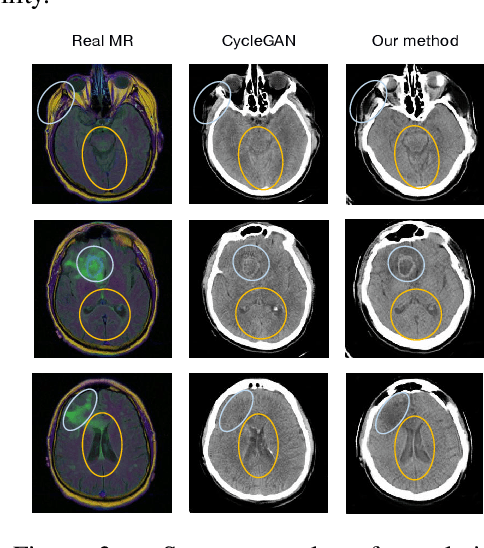
While deep learning methods have shown great success in medical image analysis, they require a number of medical images to train. Due to data privacy concerns and unavailability of medical annotators, it is oftentimes very difficult to obtain a lot of labeled medical images for model training. In this paper, we study cross-modality data augmentation to mitigate the data deficiency issue in the medical imaging domain. We propose a discriminative unpaired image-to-image translation model which translates images in source modality into images in target modality where the translation task is conducted jointly with the downstream prediction task and the translation is guided by the prediction. Experiments on two applications demonstrate the effectiveness of our method.
Spatio-Contextual Deep Network Based Multimodal Pedestrian Detection For Autonomous Driving
May 26, 2021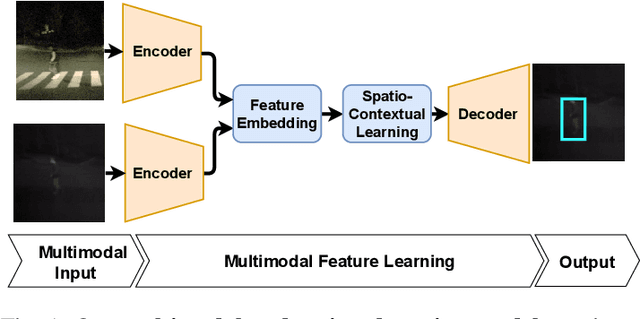
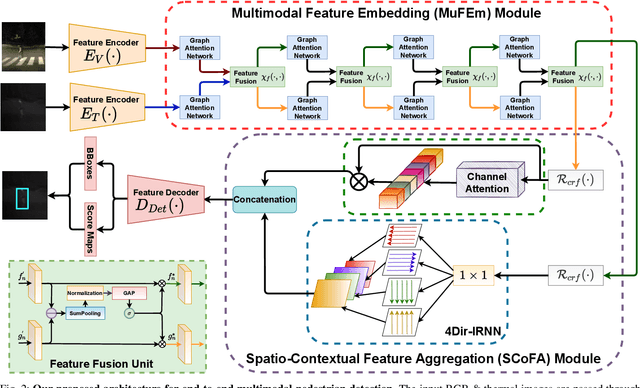


Pedestrian Detection is the most critical module of an Autonomous Driving system. Although a camera is commonly used for this purpose, its quality degrades severely in low-light night time driving scenarios. On the other hand, the quality of a thermal camera image remains unaffected in similar conditions. This paper proposes an end-to-end multimodal fusion model for pedestrian detection using RGB and thermal images. Its novel spatio-contextual deep network architecture is capable of exploiting the multimodal input efficiently. It consists of two distinct deformable ResNeXt-50 encoders for feature extraction from the two modalities. Fusion of these two encoded features takes place inside a multimodal feature embedding module (MuFEm) consisting of several groups of a pair of Graph Attention Network and a feature fusion unit. The output of the last feature fusion unit of MuFEm is subsequently passed to two CRFs for their spatial refinement. Further enhancement of the features is achieved by applying channel-wise attention and extraction of contextual information with the help of four RNNs traversing in four different directions. Finally, these feature maps are used by a single-stage decoder to generate the bounding box of each pedestrian and the score map. We have performed extensive experiments of the proposed framework on three publicly available multimodal pedestrian detection benchmark datasets, namely KAIST, CVC-14, and UTokyo. The results on each of them improved the respective state-of-the-art performance. A short video giving an overview of this work along with its qualitative results can be seen at https://youtu.be/FDJdSifuuCs.
Total Variation with Overlapping Group Sparsity and Lp Quasinorm for Infrared Image Deblurring under Salt-and-Pepper Noise
Jan 01, 2019Because of the limitations of the infrared imaging principle and the properties of infrared imaging systems, infrared images have some drawbacks, including a lack of details, indistinct edges, and a large amount of salt-andpepper noise. To improve the sparse characteristics of the image while maintaining the image edges and weakening staircase artifacts, this paper proposes a method that uses the Lp quasinorm instead of the L1 norm and for infrared image deblurring with an overlapping group sparse total variation method. The Lp quasinorm introduces another degree of freedom, better describes image sparsity characteristics, and improves image restoration. Furthermore, we adopt the accelerated alternating direction method of multipliers and fast Fourier transform theory in the proposed method to improve the efficiency and robustness of our algorithm. Experiments show that under different conditions for blur and salt-and-pepper noise, the proposed method leads to excellent performance in terms of objective evaluation and subjective visual results.