 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Controllable Image-to-Video Translation: A Case Study on Facial Expression Generation
Aug 09, 2018
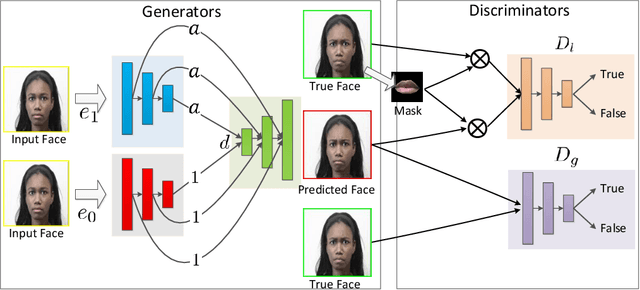


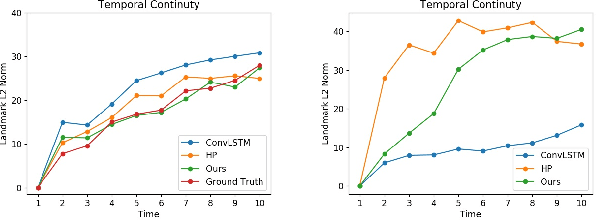
The recent advances in deep learning have made it possible to generate photo-realistic images by using neural networks and even to extrapolate video frames from an input video clip. In this paper, for the sake of both furthering this exploration and our own interest in a realistic application, we study image-to-video translation and particularly focus on the videos of facial expressions. This problem challenges the deep neural networks by another temporal dimension comparing to the image-to-image translation. Moreover, its single input image fails most existing video generation methods that rely on recurrent models. We propose a user-controllable approach so as to generate video clips of various lengths from a single face image. The lengths and types of the expressions are controlled by users. To this end, we design a novel neural network architecture that can incorporate the user input into its skip connections and propose several improvements to the adversarial training method for the neural network. Experiments and user studies verify the effectiveness of our approach. Especially, we would like to highlight that even for the face images in the wild (downloaded from the Web and the authors' own photos), our model can generate high-quality facial expression videos of which about 50\% are labeled as real by Amazon Mechanical Turk workers.
An Image Clustering Auto-Encoder Based on Predefined Evenly-Distributed Class Centroids and MMD Distance
Jun 10, 2019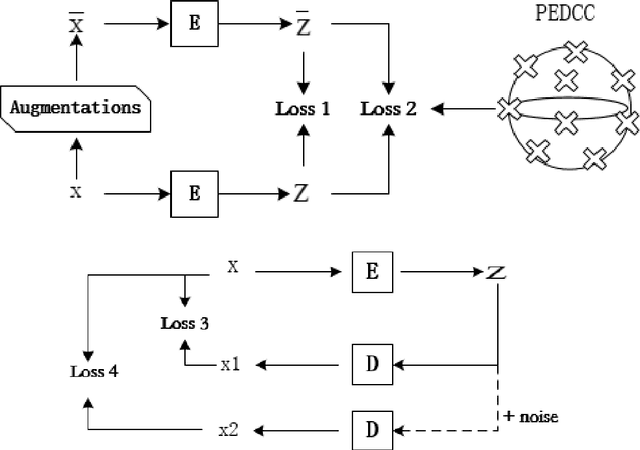
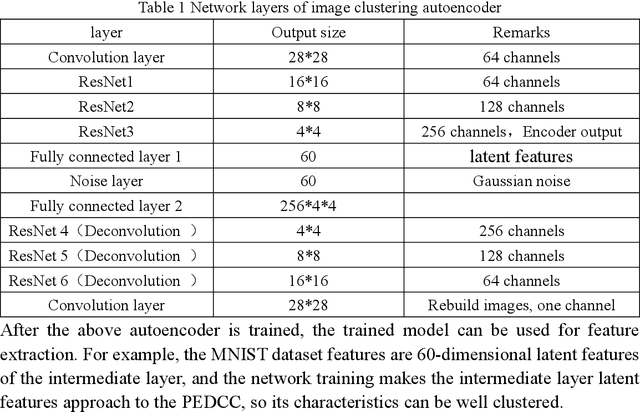

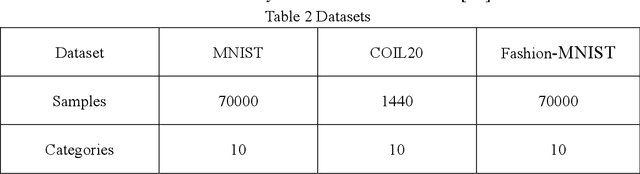
In this paper, we propose an end-to-end image clustering auto-encoder algorithm: ICAE. The algorithm uses PEDCC (Predefined Evenly-Distributed Class Centroids) as the clustering centers of the images, which ensures the inter-class distance of latent features is maximal, and adds data distribution constraint, data augmentation constraint, auto-encoder reconstruction loss constraint and latent features plus noise constraint to improve clustering performance. Specifically, we perform one-to-one data augmentation such as rotation, shear, and shift before data is input to the encoder to learn the more effective features. The data and the enhanced data are simultaneously input into the auto-encoder to obtain latent features and augmented latent features whose similarity are constrained by an augmentation loss. Then, making use of the MMD distance, we combine the latent features and augmented latent features to make their distribution close to the PEDCC distribution (uniform distribution between classes, Dirac distribution within the class) to further learn the features used for clustering. At the same time, the MSE of the original input image and reconstructed image is used as reconstruction constraint, and the noise is added to the latent features to build generalization constraint to improve the generalization ability. Finally, extensive experiments on three common datasets MNIST, Fashion-MNIST, COIL20 are conducted. The experimental results show that the algorithm has achieved the best clustering results so far, and also has good generalization ability. In addition, we can use the pre-defined PEDCC class centers, and the decoding module of the auto-encoder to clearly generate the samples of each class. The code can be downloaded at xxx!
Binary Generative Adversarial Networks for Image Retrieval
Aug 08, 2017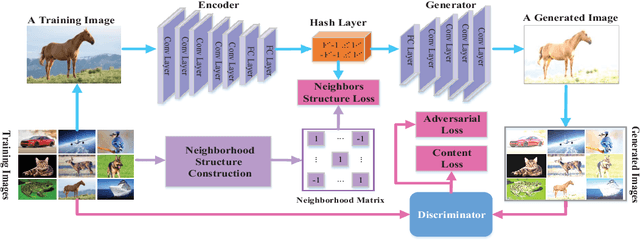
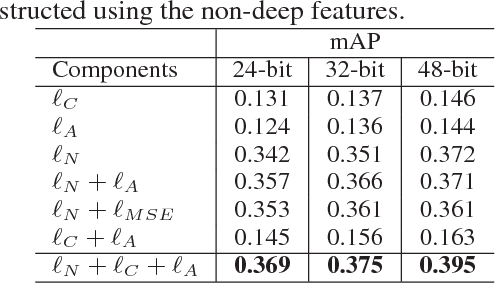
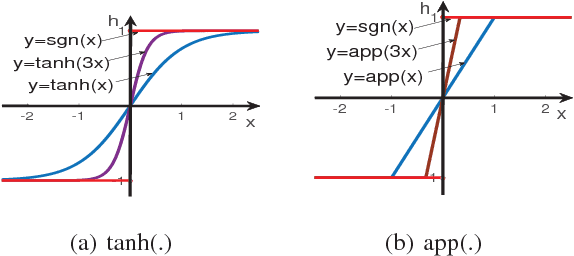
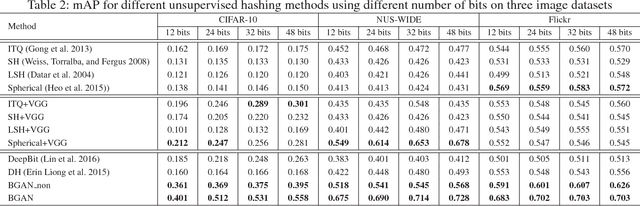
The most striking successes in image retrieval using deep hashing have mostly involved discriminative models, which require labels. In this paper, we use binary generative adversarial networks (BGAN) to embed images to binary codes in an unsupervised way. By restricting the input noise variable of generative adversarial networks (GAN) to be binary and conditioned on the features of each input image, BGAN can simultaneously learn a binary representation per image, and generate an image plausibly similar to the original one. In the proposed framework, we address two main problems: 1) how to directly generate binary codes without relaxation? 2) how to equip the binary representation with the ability of accurate image retrieval? We resolve these problems by proposing new sign-activation strategy and a loss function steering the learning process, which consists of new models for adversarial loss, a content loss, and a neighborhood structure loss. Experimental results on standard datasets (CIFAR-10, NUSWIDE, and Flickr) demonstrate that our BGAN significantly outperforms existing hashing methods by up to 107\% in terms of~mAP (See Table tab.res.map.comp) Our anonymous code is available at: https://github.com/htconquer/BGAN.
TransPose: Towards Explainable Human Pose Estimation by Transformer
Dec 31, 2020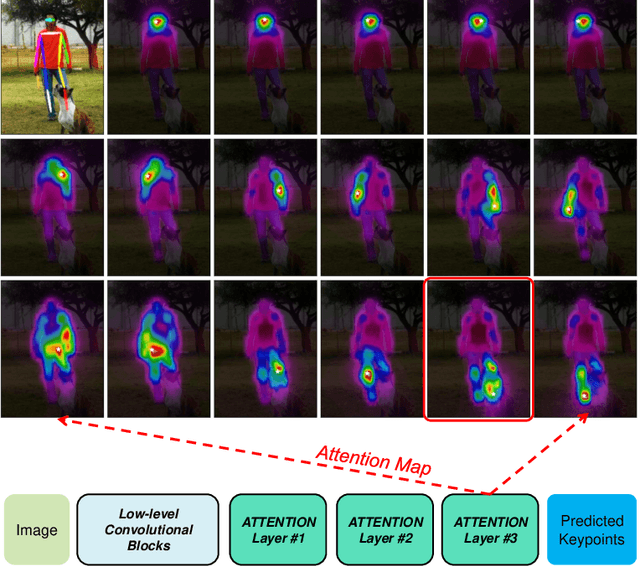
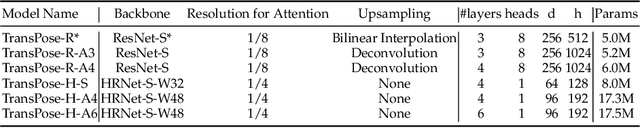
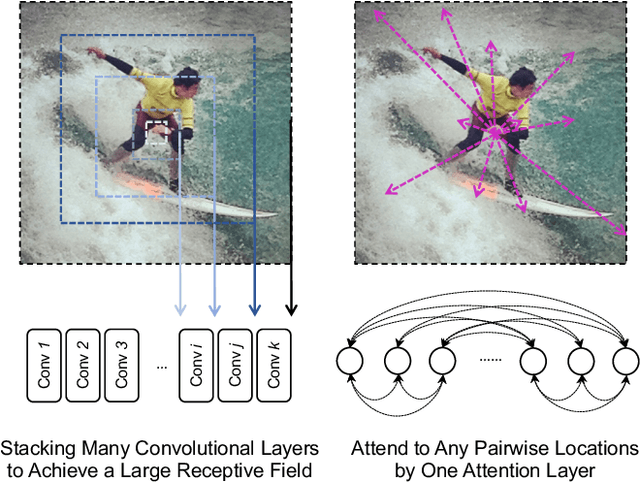
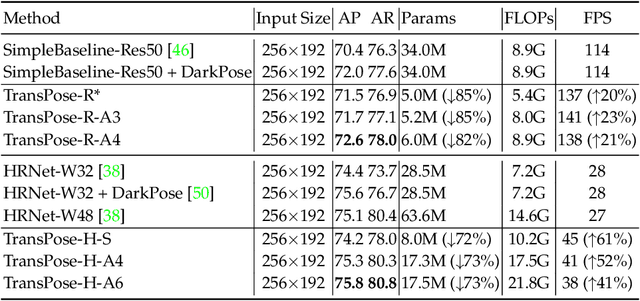
Deep Convolutional Neural Networks (CNNs) have made remarkable progress on human pose estimation task. However, there is no explicit understanding of how the locations of body keypoints are predicted by CNN, and it is also unknown what spatial dependency relationships between structural variables are learned in the model. To explore these questions, we construct an explainable model named TransPose based on Transformer architecture and low-level convolutional blocks. Given an image, the attention layers built in Transformer can capture long-range spatial relationships between keypoints and explain what dependencies the predicted keypoints locations highly rely on. We analyze the rationality of using attention as the explanation to reveal the spatial dependencies in this task. The revealed dependencies are image-specific and variable for different keypoint types, layer depths, or trained models. The experiments show that TransPose can accurately predict the positions of keypoints. It achieves state-of-the-art performance on COCO dataset, while being more interpretable, lightweight, and efficient than mainstream fully convolutional architectures.
Topology-Aware Segmentation Using Discrete Morse Theory
Mar 18, 2021
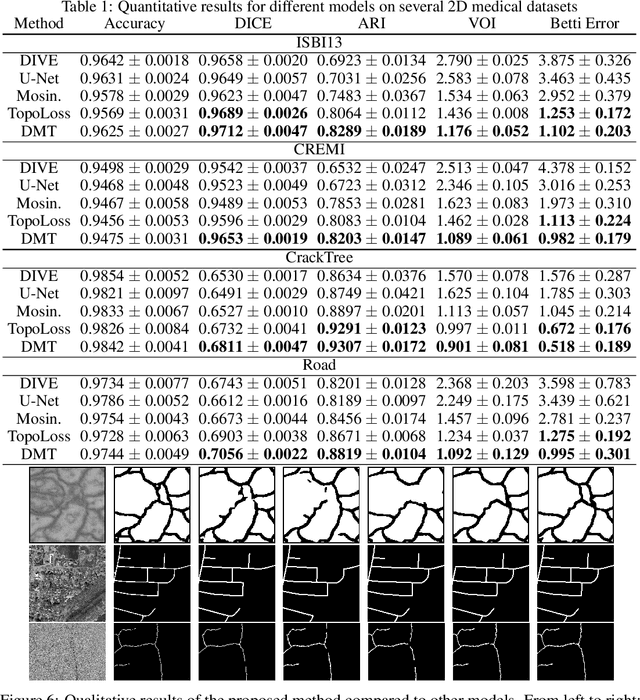
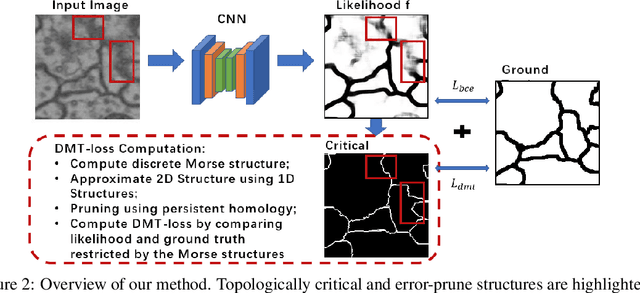
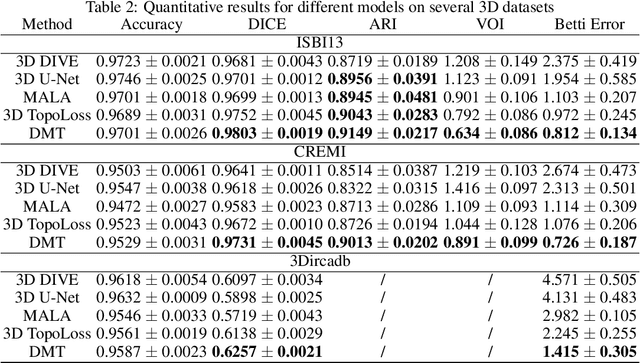
In the segmentation of fine-scale structures from natural and biomedical images, per-pixel accuracy is not the only metric of concern. Topological correctness, such as vessel connectivity and membrane closure, is crucial for downstream analysis tasks. In this paper, we propose a new approach to train deep image segmentation networks for better topological accuracy. In particular, leveraging the power of discrete Morse theory (DMT), we identify global structures, including 1D skeletons and 2D patches, which are important for topological accuracy. Trained with a novel loss based on these global structures, the network performance is significantly improved especially near topologically challenging locations (such as weak spots of connections and membranes). On diverse datasets, our method achieves superior performance on both the DICE score and topological metrics.
SCGAN: Saliency Map-guided Colorization with Generative Adversarial Network
Nov 23, 2020



Given a grayscale photograph, the colorization system estimates a visually plausible colorful image. Conventional methods often use semantics to colorize grayscale images. However, in these methods, only classification semantic information is embedded, resulting in semantic confusion and color bleeding in the final colorized image. To address these issues, we propose a fully automatic Saliency Map-guided Colorization with Generative Adversarial Network (SCGAN) framework. It jointly predicts the colorization and saliency map to minimize semantic confusion and color bleeding in the colorized image. Since the global features from pre-trained VGG-16-Gray network are embedded to the colorization encoder, the proposed SCGAN can be trained with much less data than state-of-the-art methods to achieve perceptually reasonable colorization. In addition, we propose a novel saliency map-based guidance method. Branches of the colorization decoder are used to predict the saliency map as a proxy target. Moreover, two hierarchical discriminators are utilized for the generated colorization and saliency map, respectively, in order to strengthen visual perception performance. The proposed system is evaluated on ImageNet validation set. Experimental results show that SCGAN can generate more reasonable colorized images than state-of-the-art techniques.
A Learning-based Optimization Algorithm:Image Registration Optimizer Network
Nov 23, 2020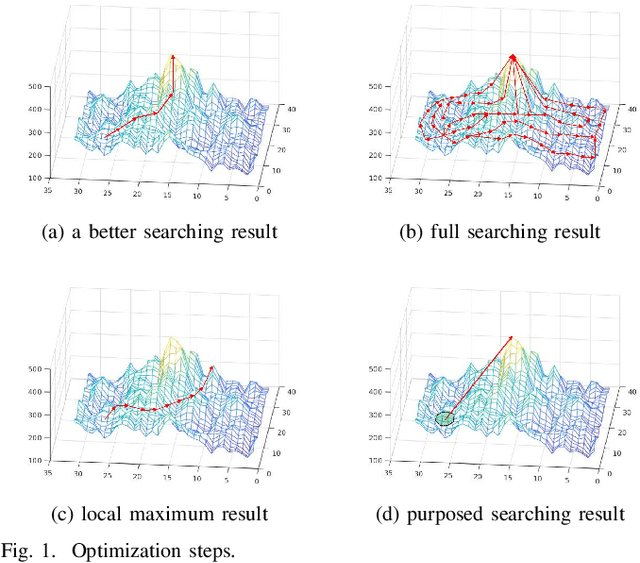
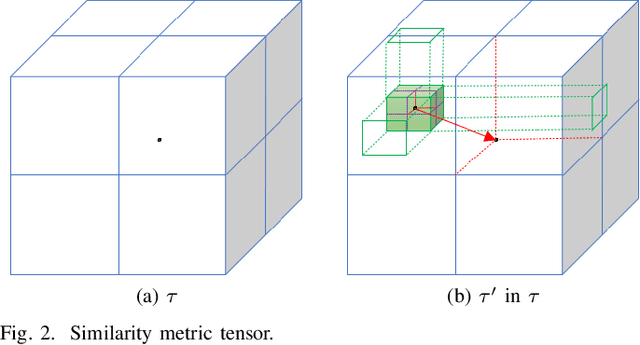
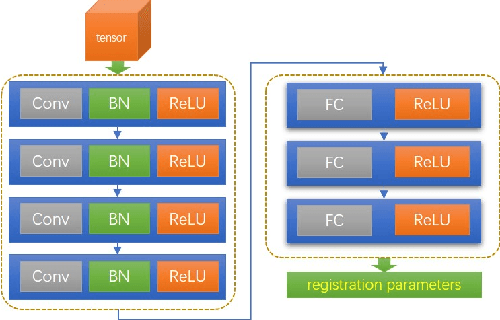
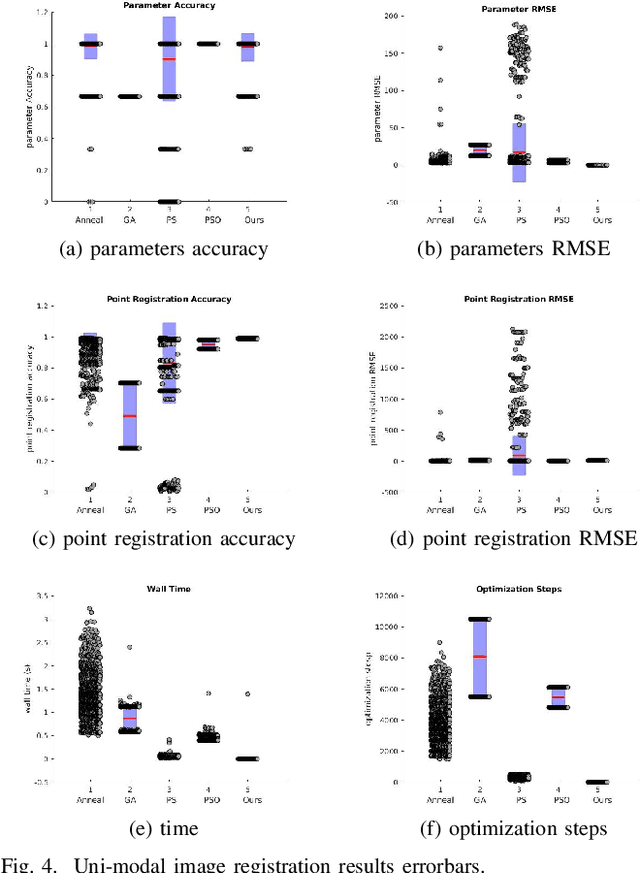
Remote sensing image registration is valuable for image-based navigation system despite posing many challenges. As the search space of registration is usually non-convex, the optimization algorithm, which aims to search the best transformation parameters, is a challenging step. Conventional optimization algorithms can hardly reconcile the contradiction of simultaneous rapid convergence and the global optimization. In this paper, a novel learning-based optimization algorithm named Image Registration Optimizer Network (IRON) is proposed, which can predict the global optimum after single iteration. The IRON is trained by a 3D tensor (9x9x9), which consists of similar metric values. The elements of the 3D tensor correspond to the 9x9x9 neighbors of the initial parameters in the search space. Then, the tensor's label is a vector that points to the global optimal parameters from the initial parameters. Because of the special architecture, the IRON could predict the global optimum directly for any initialization. The experimental results demonstrate that the proposed algorithm performs better than other classical optimization algorithms as it has higher accuracy, lower root of mean square error (RMSE), and more efficiency. Our IRON codes are available for further study.https://www.github.com/jaxwangkd04/IRON
Fine-Tuning DARTS for Image Classification
Jun 16, 2020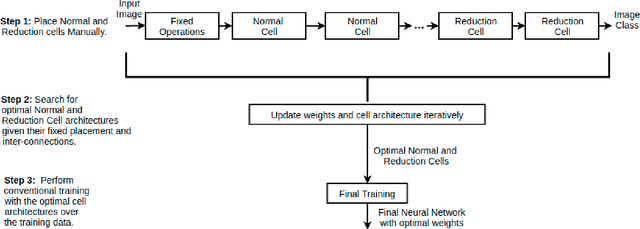
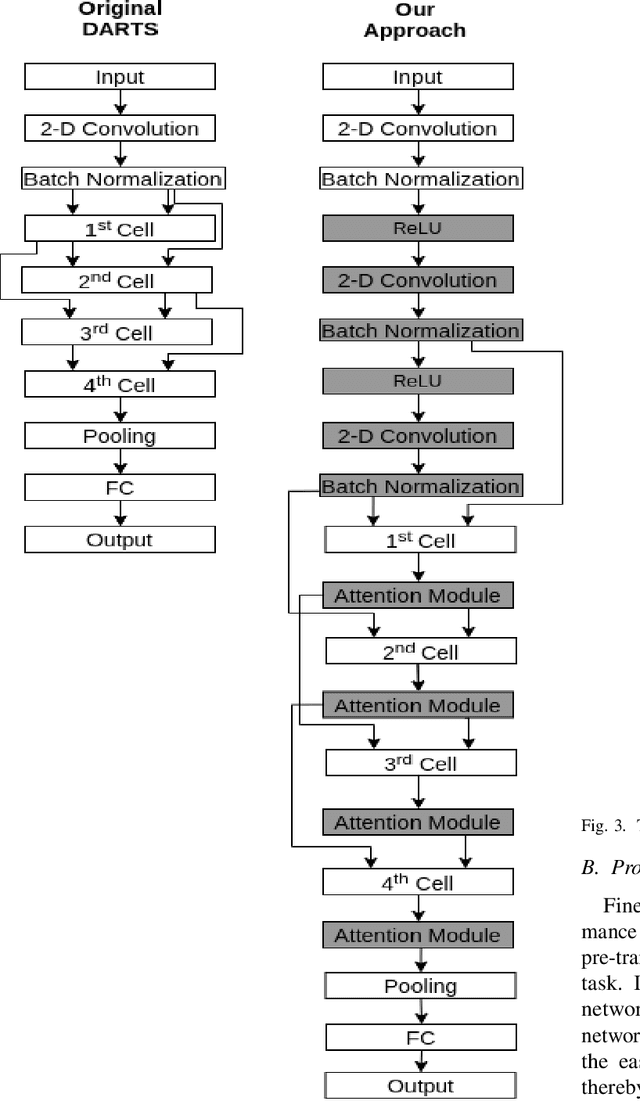
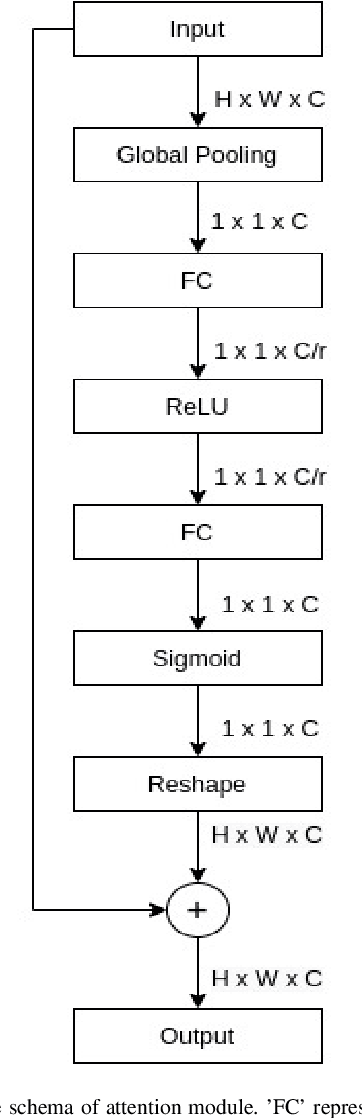
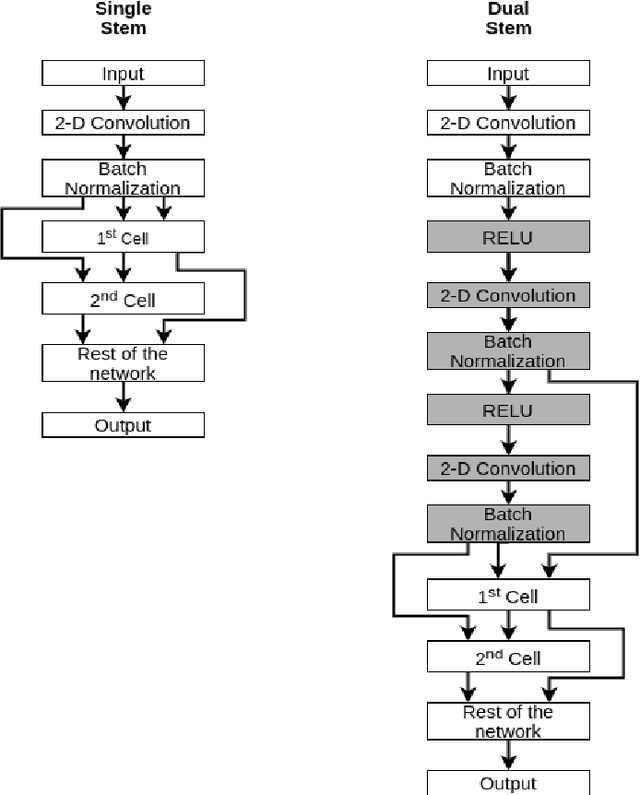
Neural Architecture Search (NAS) has gained attraction due to superior classification performance. Differential Architecture Search (DARTS) is a computationally light method. To limit computational resources DARTS makes numerous approximations. These approximations result in inferior performance. We propose to fine-tune DARTS using fixed operations as they are independent of these approximations. Our method offers a good trade-off between the number of parameters and classification accuracy. Our approach improves the top-1 accuracy on Fashion-MNIST, CompCars, and MIO-TCD datasets by 0.56%, 0.50%, and 0.39%, respectively compared to the state-of-the-art approaches. Our approach performs better than DARTS, improving the accuracy by 0.28%, 1.64%, 0.34%, 4.5%, and 3.27% compared to DARTS, on CIFAR-10, CIFAR-100, Fashion-MNIST, CompCars, and MIO-TCD datasets, respectively.
CASSOD-Net: Cascaded and Separable Structures of Dilated Convolution for Embedded Vision Systems and Applications
Apr 29, 2021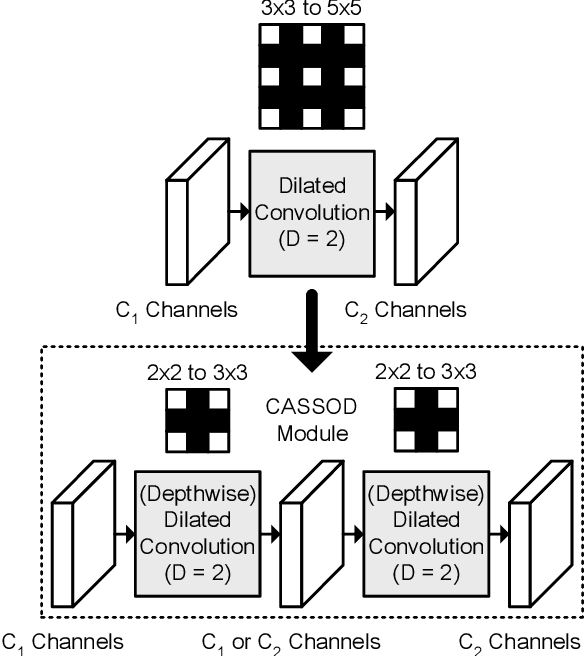

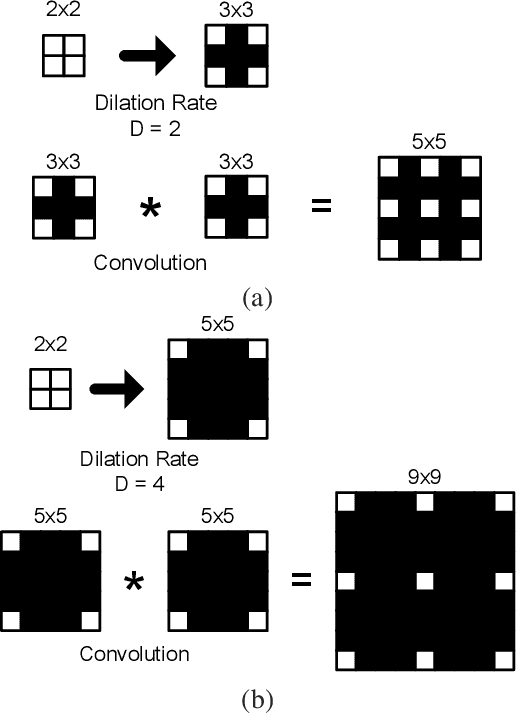
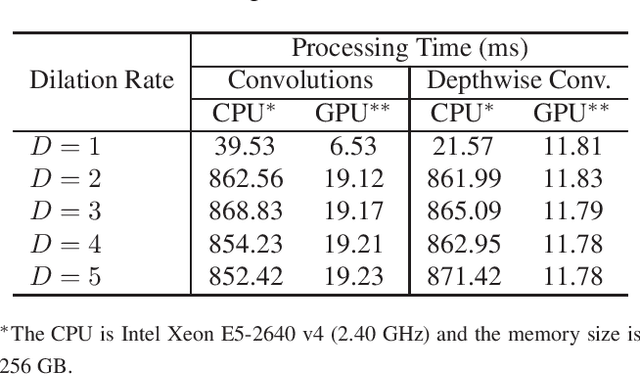
The field of view (FOV) of convolutional neural networks is highly related to the accuracy of inference. Dilated convolutions are known as an effective solution to the problems which require large FOVs. However, for general-purpose hardware or dedicated hardware, it usually takes extra time to handle dilated convolutions compared with standard convolutions. In this paper, we propose a network module, Cascaded and Separable Structure of Dilated (CASSOD) Convolution, and a special hardware system to handle the CASSOD networks efficiently. A CASSOD-Net includes multiple cascaded $2 \times 2$ dilated filters, which can be used to replace the traditional $3 \times 3$ dilated filters without decreasing the accuracy of inference. Two example applications, face detection and image segmentation, are tested with dilated convolutions and the proposed CASSOD modules. The new network for face detection achieves higher accuracy than the previous work with only 47% of filter weights in the dilated convolution layers of the context module. Moreover, the proposed hardware system can accelerate the computations of dilated convolutions, and it is 2.78 times faster than traditional hardware systems when the filter size is $3 \times 3$.
REGRAD: A Large-Scale Relational Grasp Dataset for Safe and Object-Specific Robotic Grasping in Clutter
Apr 29, 2021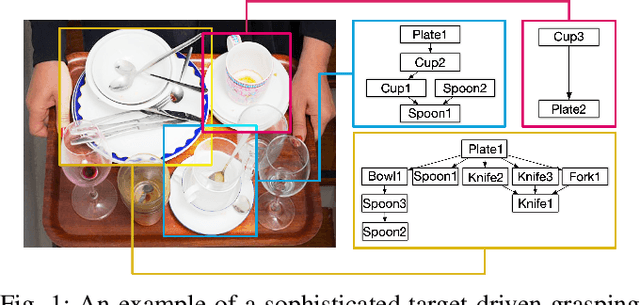
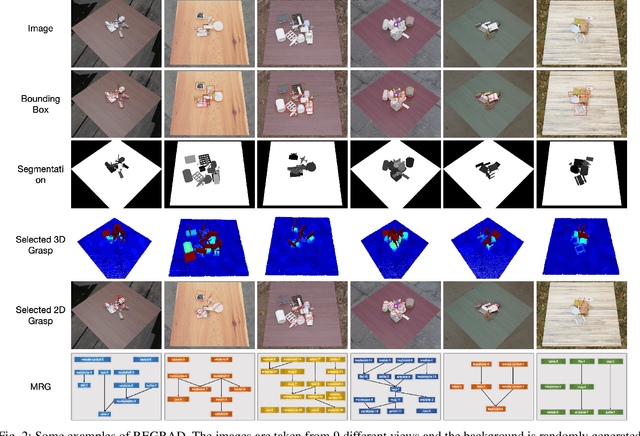
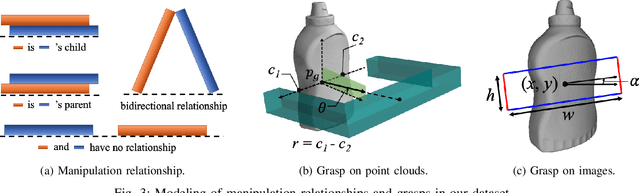
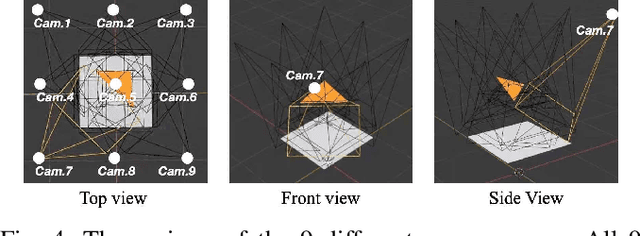
Despite the impressive progress achieved in robust grasp detection, robots are not skilled in sophisticated grasping tasks (e.g. search and grasp a specific object in clutter). Such tasks involve not only grasping, but comprehensive perception of the visual world (e.g. the relationship between objects). Recently, the advanced deep learning techniques provide a promising way for understanding the high-level visual concepts. It encourages robotic researchers to explore solutions for such hard and complicated fields. However, deep learning usually means data-hungry. The lack of data severely limits the performance of deep-learning-based algorithms. In this paper, we present a new dataset named \regrad to sustain the modeling of relationships among objects and grasps. We collect the annotations of object poses, segmentations, grasps, and relationships in each image for comprehensive perception of grasping. Our dataset is collected in both forms of 2D images and 3D point clouds. Moreover, since all the data are generated automatically, users are free to import their own object models for the generation of as many data as they want. We have released our dataset and codes. A video that demonstrates the process of data generation is also available.