 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Ultrasound Matrix Imaging. II. The distortion matrix for aberration correction over multiple isoplanatic patches
Mar 02, 2021
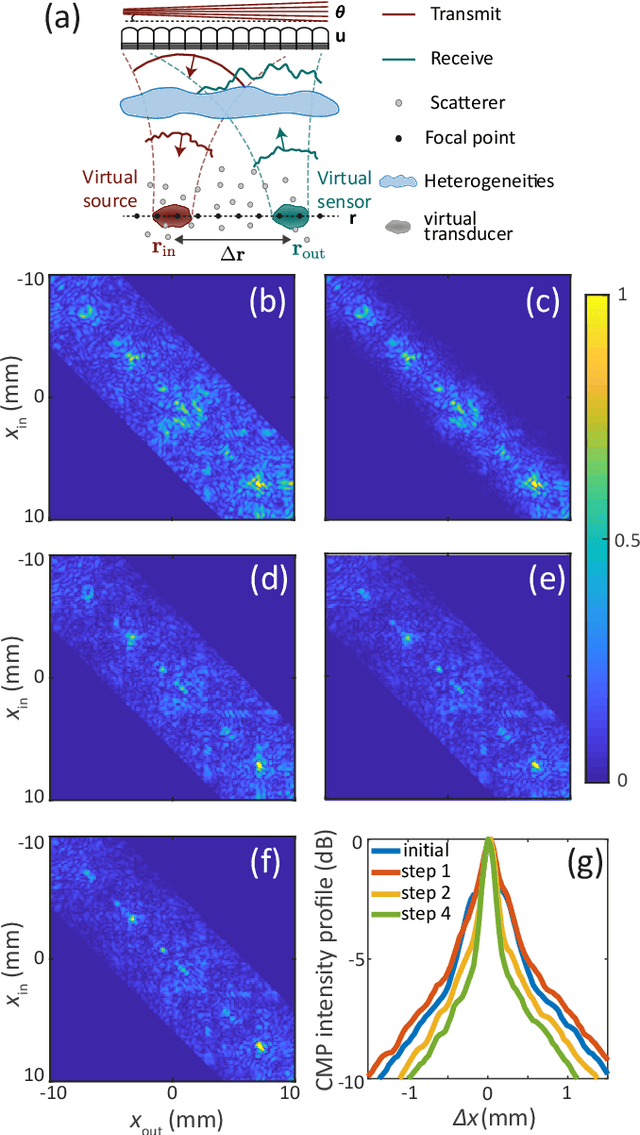
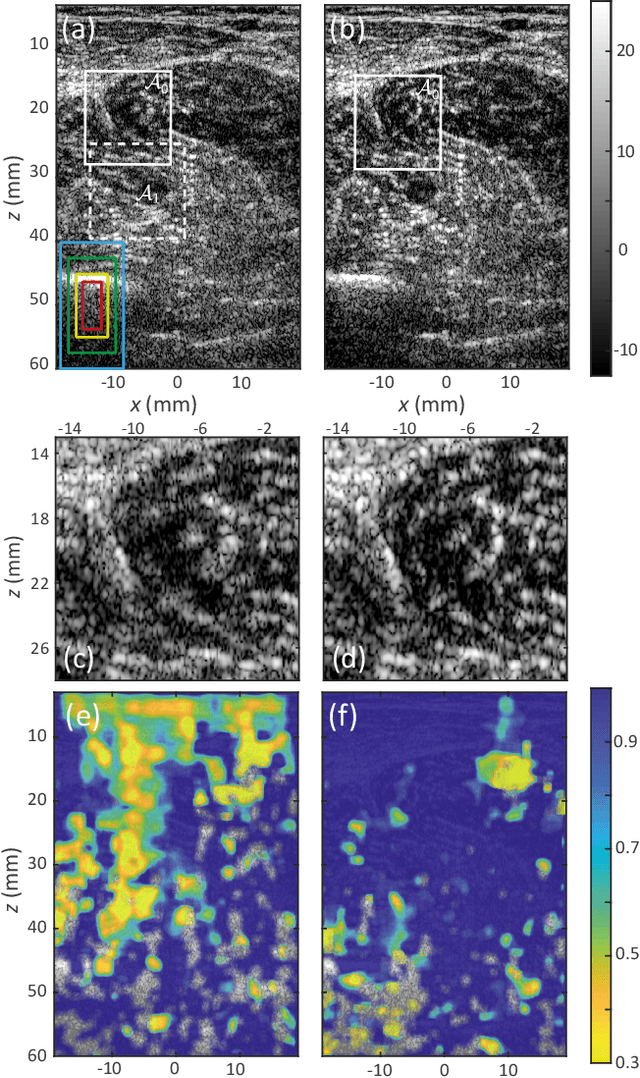
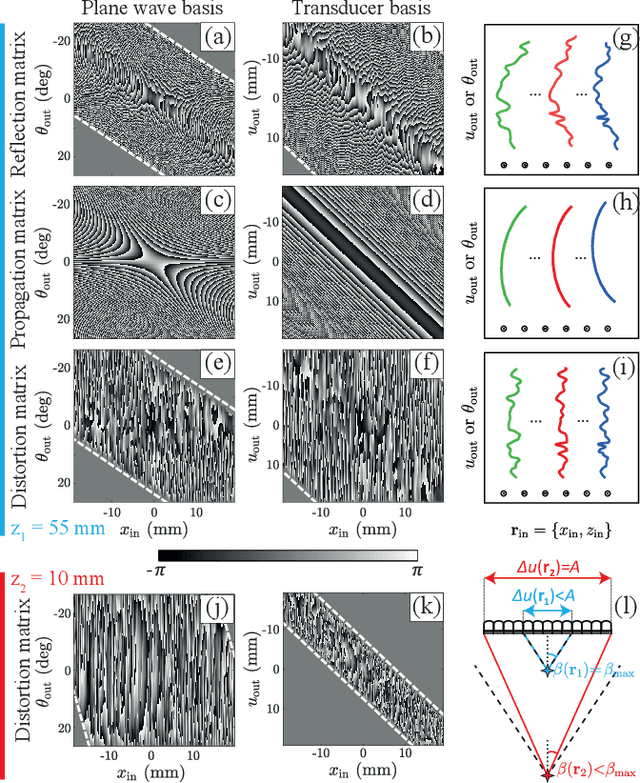
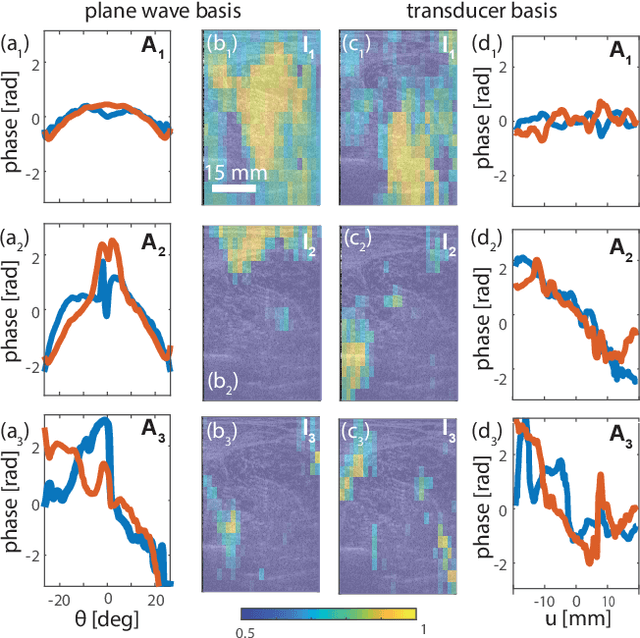
This is the second article in a series of two which report on a matrix approach for ultrasound imaging in heterogeneous media. This article describes the quantification and correction of aberration, i.e. the distortion of an image caused by spatial variations in the medium speed-of-sound. Adaptive focusing can compensate for aberration, but is only effective over a restricted area called the isoplanatic patch. Here, we use an experimentally-recorded matrix of reflected acoustic signals to synthesize a set of virtual transducers. We then examine wave propagation between these virtual transducers and an arbitrary correction plane. Such wave-fronts consist of two components: (i) An ideal geometric wave-front linked to diffraction and the input focusing point, and; (ii) Phase distortions induced by the speed-of-sound variations. These distortions are stored in a so-called distortion matrix, the singular value decomposition of which gives access to an optimized focusing law at any point. We show that, by decoupling the aberrations undergone by the outgoing and incoming waves and applying an iterative strategy, compensation for even high-order and spatially-distributed aberrations can be achieved. As a proof-of-concept, ultrasound matrix imaging (UMI) is applied to the in-vivo imaging of a human calf. A map of isoplanatic patches is retrieved and is shown to be strongly correlated with the arrangement of tissues constituting the medium. The corresponding focusing laws yield an ultrasound image with an optimal contrast and a transverse resolution close to the ideal value predicted by diffraction theory. UMI thus provides a flexible and powerful route towards computational ultrasound.
TransPose: Towards Explainable Human Pose Estimation by Transformer
Dec 31, 2020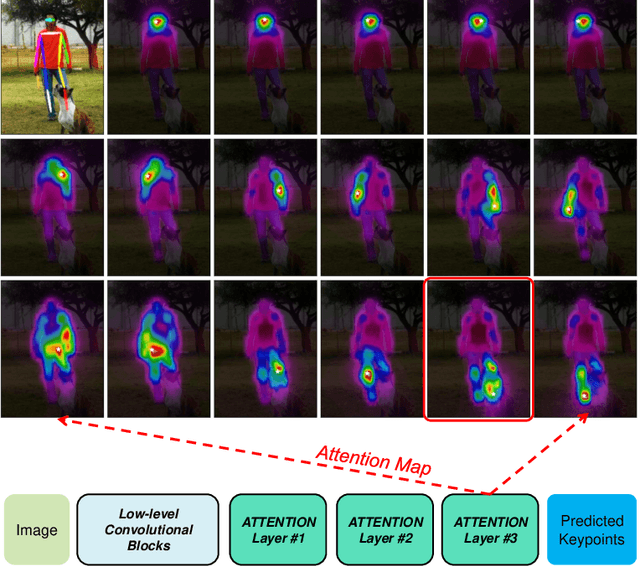
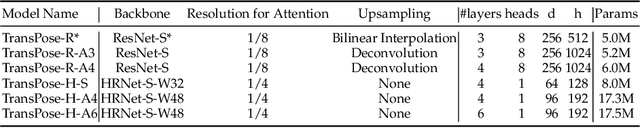
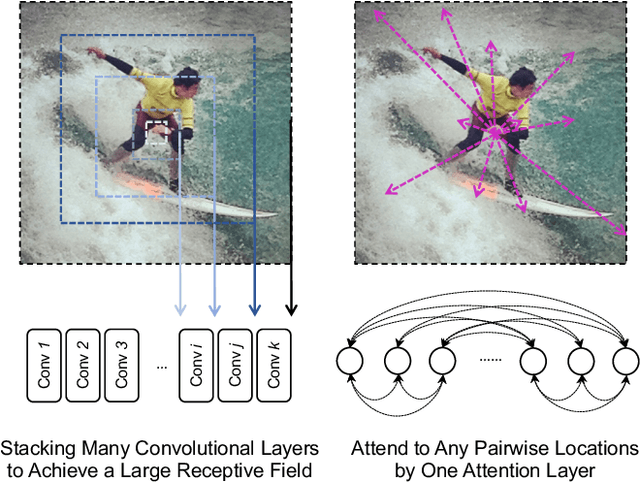
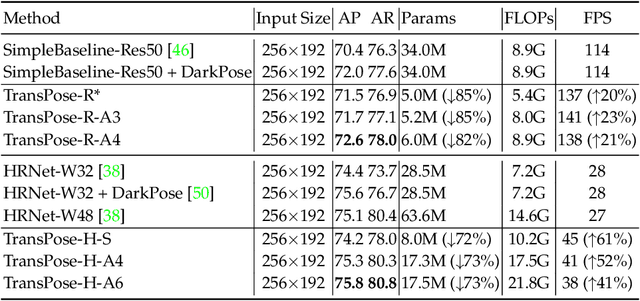
Deep Convolutional Neural Networks (CNNs) have made remarkable progress on human pose estimation task. However, there is no explicit understanding of how the locations of body keypoints are predicted by CNN, and it is also unknown what spatial dependency relationships between structural variables are learned in the model. To explore these questions, we construct an explainable model named TransPose based on Transformer architecture and low-level convolutional blocks. Given an image, the attention layers built in Transformer can capture long-range spatial relationships between keypoints and explain what dependencies the predicted keypoints locations highly rely on. We analyze the rationality of using attention as the explanation to reveal the spatial dependencies in this task. The revealed dependencies are image-specific and variable for different keypoint types, layer depths, or trained models. The experiments show that TransPose can accurately predict the positions of keypoints. It achieves state-of-the-art performance on COCO dataset, while being more interpretable, lightweight, and efficient than mainstream fully convolutional architectures.
Deep BCD-Net Using Identical Encoding-Decoding CNN Structures for Iterative Image Recovery
Apr 28, 2018
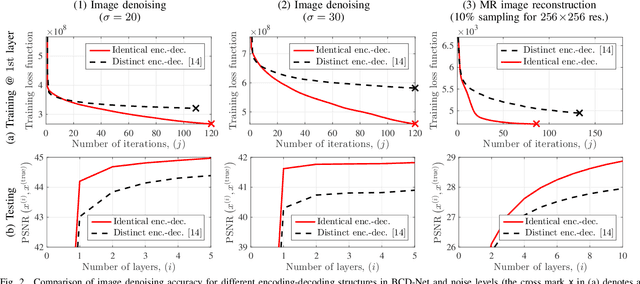
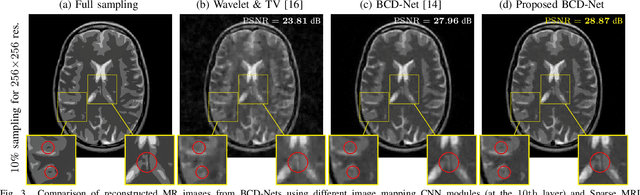
In "extreme" computational imaging that collects extremely undersampled or noisy measurements, obtaining an accurate image within a reasonable computing time is challenging. Incorporating image mapping convolutional neural networks (CNN) into iterative image recovery has great potential to resolve this issue. This paper 1) incorporates image mapping CNN using identical convolutional kernels in both encoders and decoders into a block coordinate descent (BCD) signal recovery method and 2) applies alternating direction method of multipliers to train the aforementioned image mapping CNN. We refer to the proposed recurrent network as BCD-Net using identical encoding-decoding CNN structures. Numerical experiments show that, for a) denoising low signal-to-noise-ratio images and b) extremely undersampled magnetic resonance imaging, the proposed BCD-Net achieves significantly more accurate image recovery, compared to BCD-Net using distinct encoding-decoding structures and/or the conventional image recovery model using both wavelets and total variation.
Profiling Visual Dynamic Complexity Using a Bio-Robotic Approach
May 20, 2021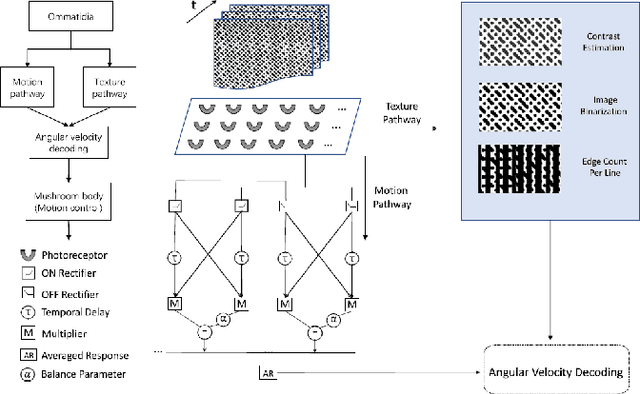
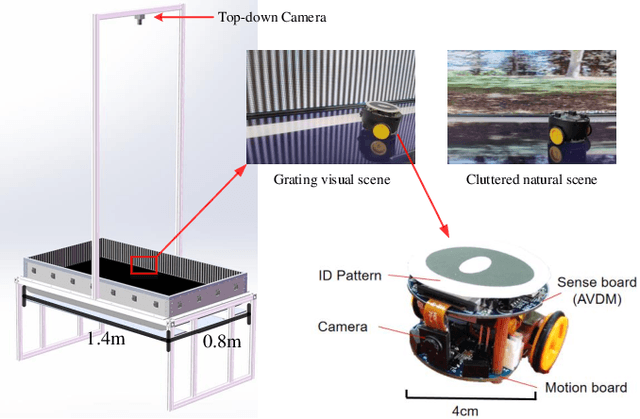
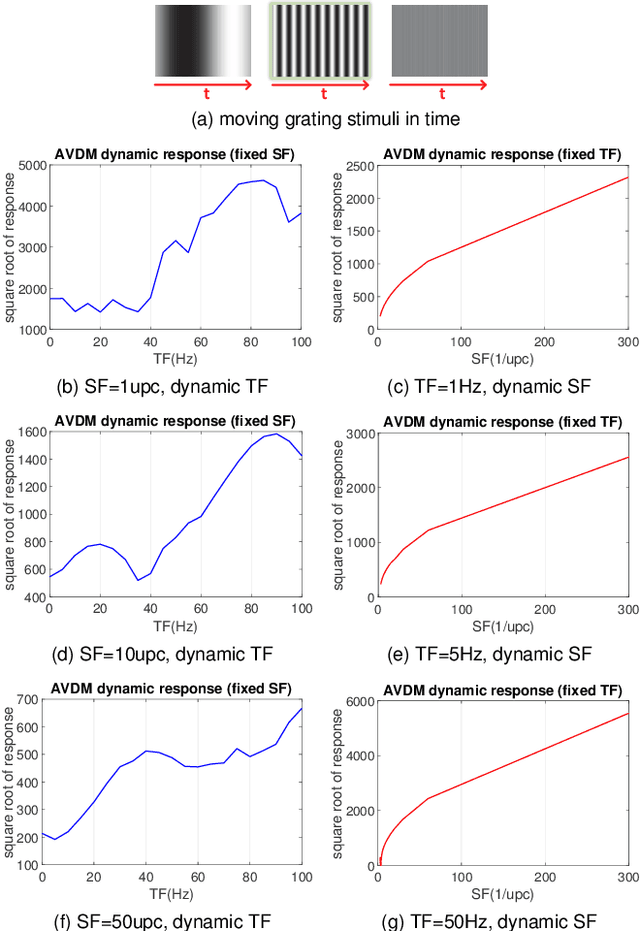
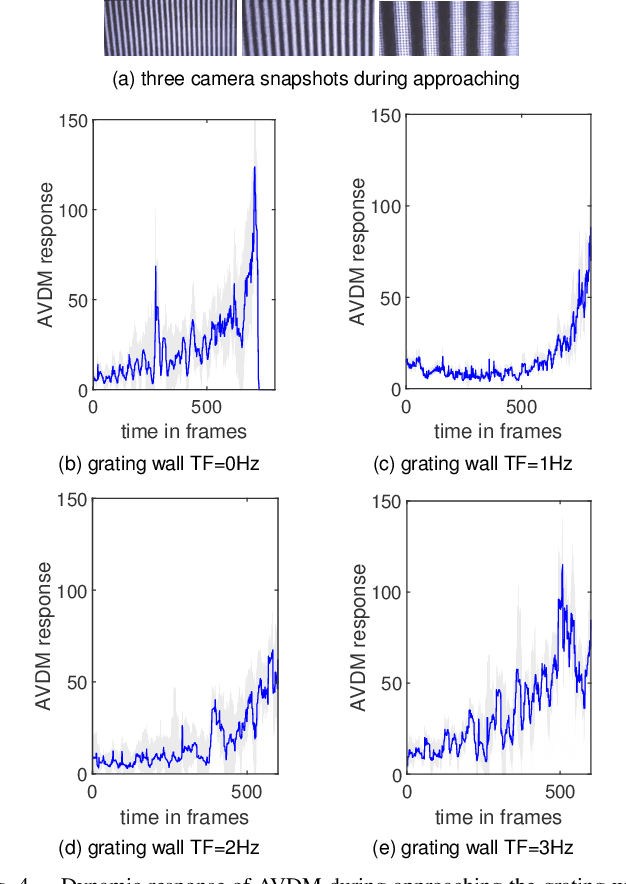
Visual dynamic complexity is a ubiquitous, hidden attribute of the visual world that every dynamic vision system is faced with. However, it is implicit and intractable which has never been quantitatively described due to the difficulty in defending temporal features correlated to spatial image complexity. To fill this vacancy, we propose a novel bio-robotic approach to profile visual dynamic complexity which can be used as a new metric. Here we apply a state-of-the-art brain-inspired motion detection neural network model to explicitly profile such complexity associated with spatial-temporal frequency (SF-TF) of visual scene. This model is for the first time implemented in an autonomous micro-mobile robot which navigates freely in an arena with visual walls displaying moving sine-wave grating or cluttered natural scene. The neural dynamic response can make reasonable prediction on surrounding complexity since it can be mapped monotonically to varying SF-TF of visual scene. The experiments show this approach is flexible to different visual scenes for profiling the dynamic complexity. We also use this metric as a predictor to investigate the boundary of another collision detection visual system performing in changing environment with increasing dynamic complexity. This research demonstrates a new paradigm of using biologically plausible visual processing scheme to estimate dynamic complexity of visual scene from both spatial and temporal perspectives, which could be beneficial to predicting input complexity when evaluating dynamic vision systems.
A Semi-supervised Framework for Image Captioning
Jun 24, 2017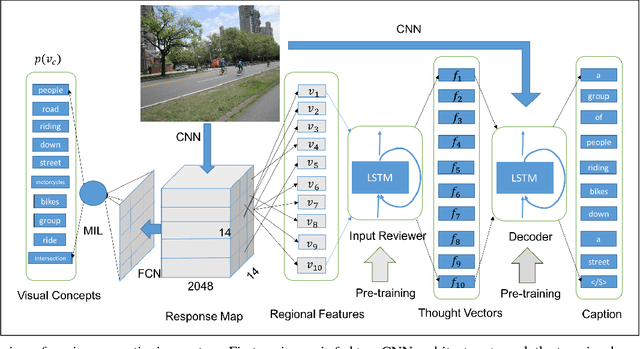
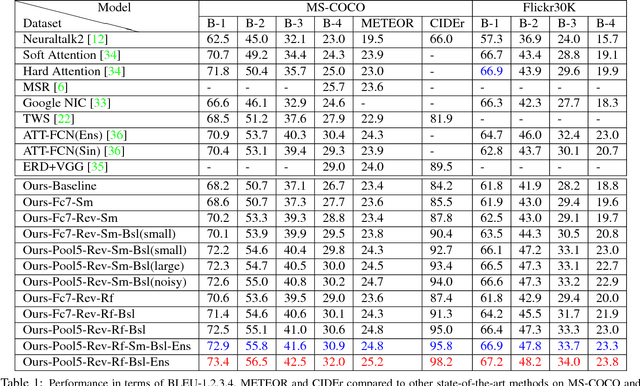


State-of-the-art approaches for image captioning require supervised training data consisting of captions with paired image data. These methods are typically unable to use unsupervised data such as textual data with no corresponding images, which is a much more abundant commodity. We here propose a novel way of using such textual data by artificially generating missing visual information. We evaluate this learning approach on a newly designed model that detects visual concepts present in an image and feed them to a reviewer-decoder architecture with an attention mechanism. Unlike previous approaches that encode visual concepts using word embeddings, we instead suggest using regional image features which capture more intrinsic information. The main benefit of this architecture is that it synthesizes meaningful thought vectors that capture salient image properties and then applies a soft attentive decoder to decode the thought vectors and generate image captions. We evaluate our model on both Microsoft COCO and Flickr30K datasets and demonstrate that this model combined with our semi-supervised learning method can largely improve performance and help the model to generate more accurate and diverse captions.
An Enhanced Prohibited Items Recognition Model
Feb 24, 2021


We proposed a new modeling method to promote the performance of prohibited items recognition via X-ray image. We analyzed the characteristics of prohibited items and X-ray images. We found the fact that the scales of some items are too small to be recognized which encumber the model performance. Then we adopted a set of data augmentation and modified the model to adapt the field of prohibited items recognition. The Convolutional Block Attention Module(CBAM) and rescoring mechanism has been assembled into the model. By the modification, our model achieved a mAP of 89.9% on SIXray10, mAP of 74.8%.
Multi-scale Regional Attention Deeplab3+: Multiple Myeloma Plasma Cells Segmentation in Microscopic Images
May 13, 2021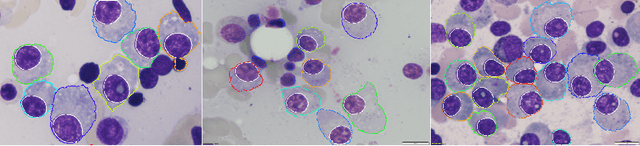
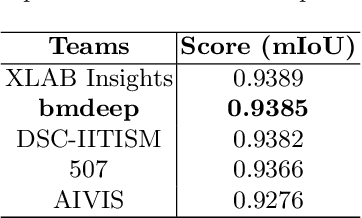
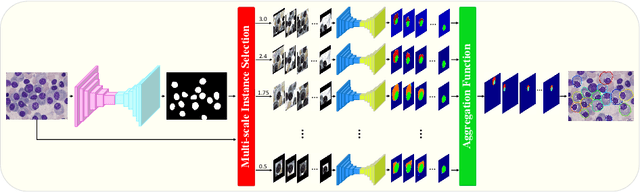
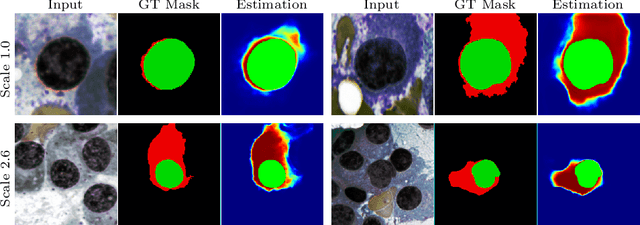
Multiple myeloma cancer is a type of blood cancer that happens when the growth of abnormal plasma cells becomes out of control in the bone marrow. There are various ways to diagnose multiple myeloma in bone marrow such as complete blood count test (CBC) or counting myeloma plasma cell in aspirate slide images using manual visualization or through image processing technique. In this work, an automatic deep learning method for the detection and segmentation of multiple myeloma plasma cell have been explored. To this end, a two-stage deep learning method is designed. In the first stage, the nucleus detection network is utilized to extract each instance of a cell of interest. The extracted instance is then fed to the multi-scale function to generate a multi-scale representation. The objective of the multi-scale function is to capture the shape variation and reduce the effect of object scale on the cytoplasm segmentation network. The generated scales are then fed into a pyramid of cytoplasm networks to learn the segmentation map in various scales. On top of the cytoplasm segmentation network, we included a scale aggregation function to refine and generate a final prediction. The proposed approach has been evaluated on the SegPC2021 grand-challenge and ranked second on the final test phase among all teams.
Bayesian imaging using Plug & Play priors: when Langevin meets Tweedie
Mar 09, 2021



Since the seminal work of Venkatakrishnan et al. (2013), Plug & Play (PnP) methods have become ubiquitous in Bayesian imaging. These methods derive Minimum Mean Square Error (MMSE) or Maximum A Posteriori (MAP) estimators for inverse problems in imaging by combining an explicit likelihood function with a prior that is implicitly defined by an image denoising algorithm. The PnP algorithms proposed in the literature mainly differ in the iterative schemes they use for optimisation or for sampling. In the case of optimisation schemes, some recent works guarantee the convergence to a fixed point, albeit not necessarily a MAP estimate. In the case of sampling schemes, to the best of our knowledge, there is no known proof of convergence. There also remain important open questions regarding whether the underlying Bayesian models and estimators are well defined, well-posed, and have the basic regularity properties required to support these numerical schemes. To address these limitations, this paper develops theory, methods, and provably convergent algorithms for performing Bayesian inference with PnP priors. We introduce two algorithms: 1) PnP-ULA (Unadjusted Langevin Algorithm) for Monte Carlo sampling and MMSE inference; and 2) PnP-SGD (Stochastic Gradient Descent) for MAP inference. Using recent results on the quantitative convergence of Markov chains, we establish detailed convergence guarantees for these two algorithms under realistic assumptions on the denoising operators used, with special attention to denoisers based on deep neural networks. We also show that these algorithms approximately target a decision-theoretically optimal Bayesian model that is well-posed. The proposed algorithms are demonstrated on several canonical problems such as image deblurring, inpainting, and denoising, where they are used for point estimation as well as for uncertainty visualisation and quantification.
Convolutional Neural Networks in Orthodontics: a review
Apr 18, 2021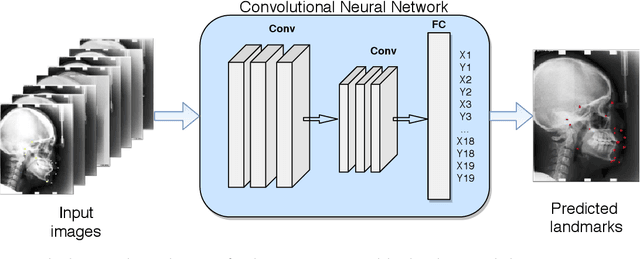
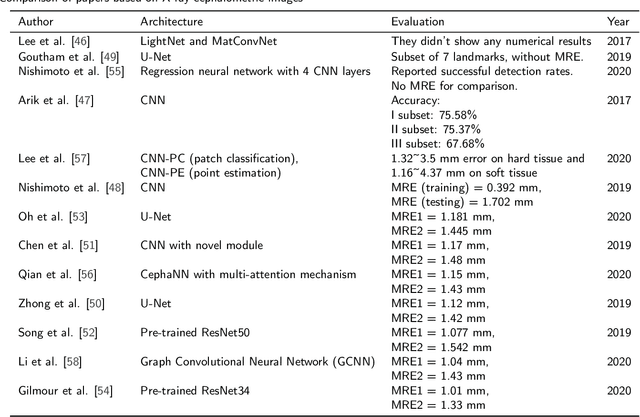
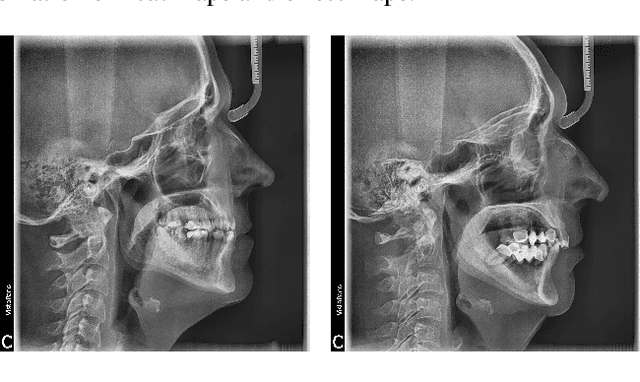
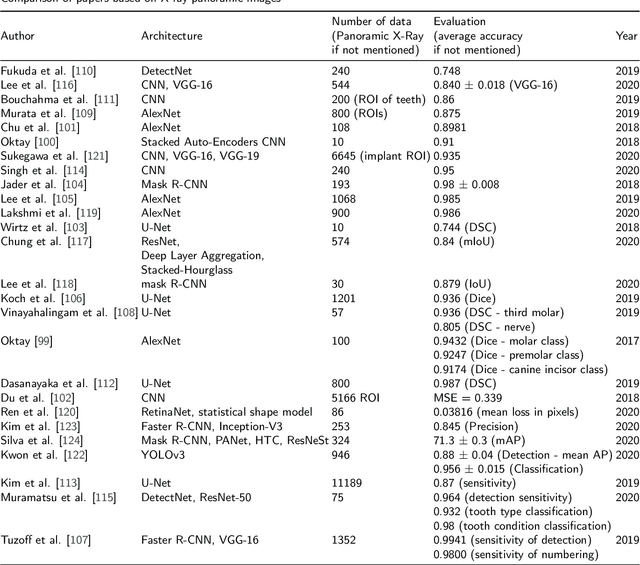
Convolutional neural networks (CNNs) are used in many areas of computer vision, such as object tracking and recognition, security, military, and biomedical image analysis. This review presents the application of convolutional neural networks in one of the fields of dentistry - orthodontics. Advances in medical imaging technologies and methods allow CNNs to be used in orthodontics to shorten the planning time of orthodontic treatment, including an automatic search of landmarks on cephalometric X-ray images, tooth segmentation on Cone-Beam Computed Tomography (CBCT) images or digital models, and classification of defects on X-Ray panoramic images. In this work, we describe the current methods, the architectures of deep convolutional neural networks used, and their implementations, together with a comparison of the results achieved by them. The promising results and visualizations of the described studies show that the use of methods based on convolutional neural networks allows for the improvement of computer-based orthodontic treatment planning, both by reducing the examination time and, in many cases, by performing the analysis much more accurately than a manual orthodontist does.
Fine-Tuning DARTS for Image Classification
Jun 16, 2020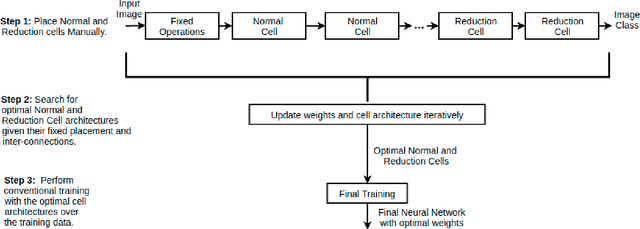
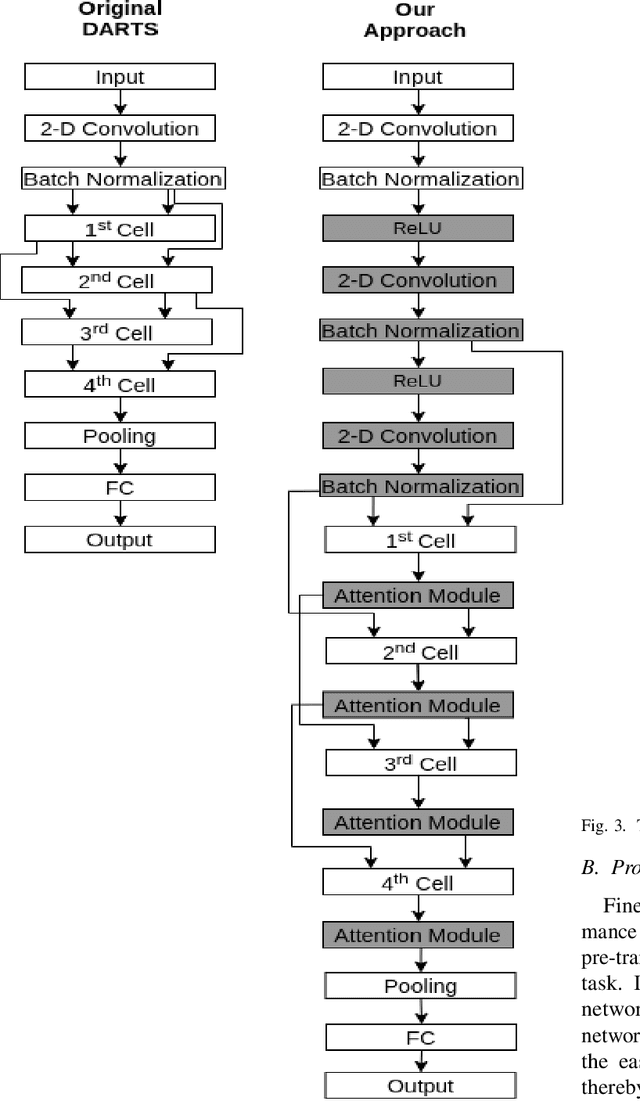
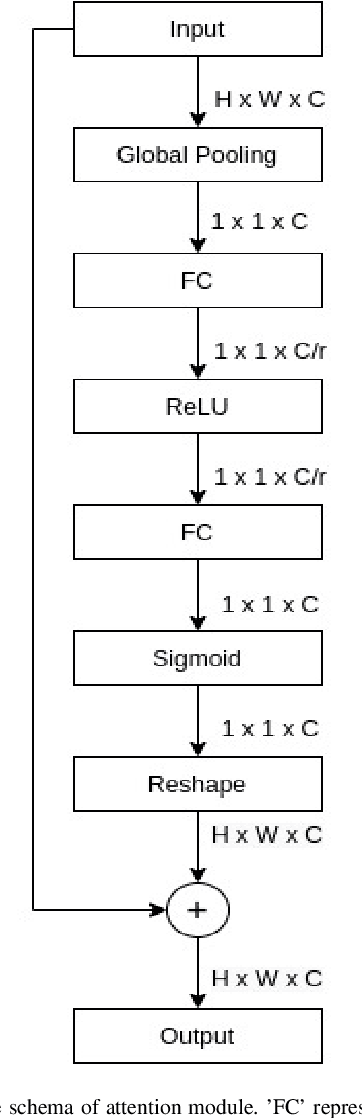
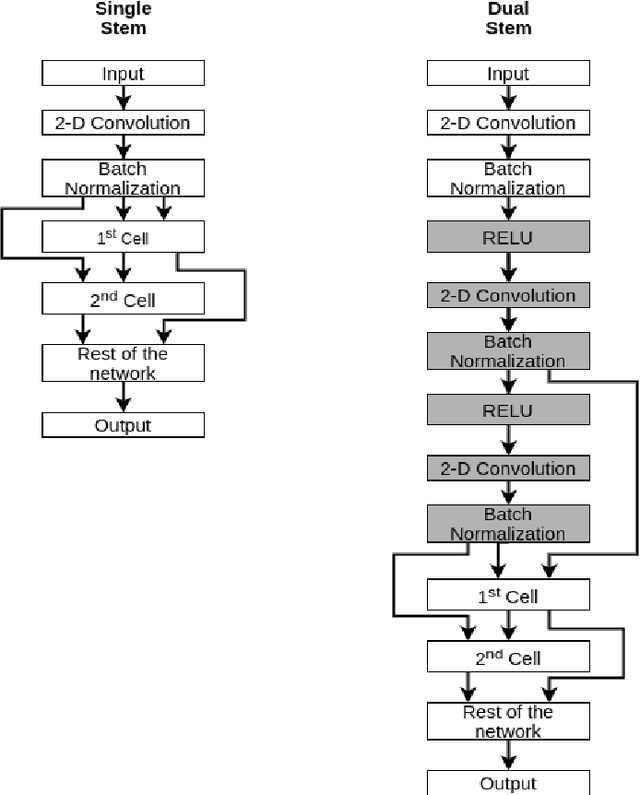
Neural Architecture Search (NAS) has gained attraction due to superior classification performance. Differential Architecture Search (DARTS) is a computationally light method. To limit computational resources DARTS makes numerous approximations. These approximations result in inferior performance. We propose to fine-tune DARTS using fixed operations as they are independent of these approximations. Our method offers a good trade-off between the number of parameters and classification accuracy. Our approach improves the top-1 accuracy on Fashion-MNIST, CompCars, and MIO-TCD datasets by 0.56%, 0.50%, and 0.39%, respectively compared to the state-of-the-art approaches. Our approach performs better than DARTS, improving the accuracy by 0.28%, 1.64%, 0.34%, 4.5%, and 3.27% compared to DARTS, on CIFAR-10, CIFAR-100, Fashion-MNIST, CompCars, and MIO-TCD datasets, respectively.