 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
FDRN: A Fast Deformable Registration Network for Medical Images
Nov 04, 2020
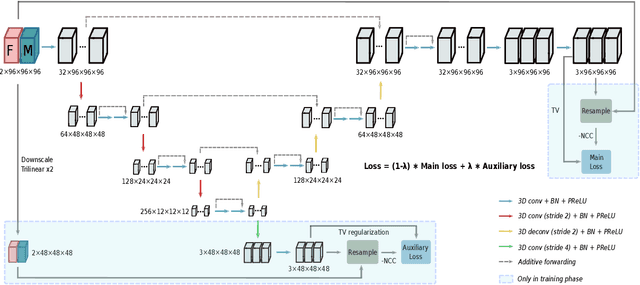
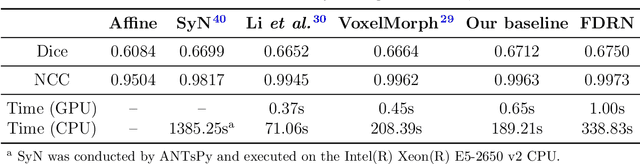
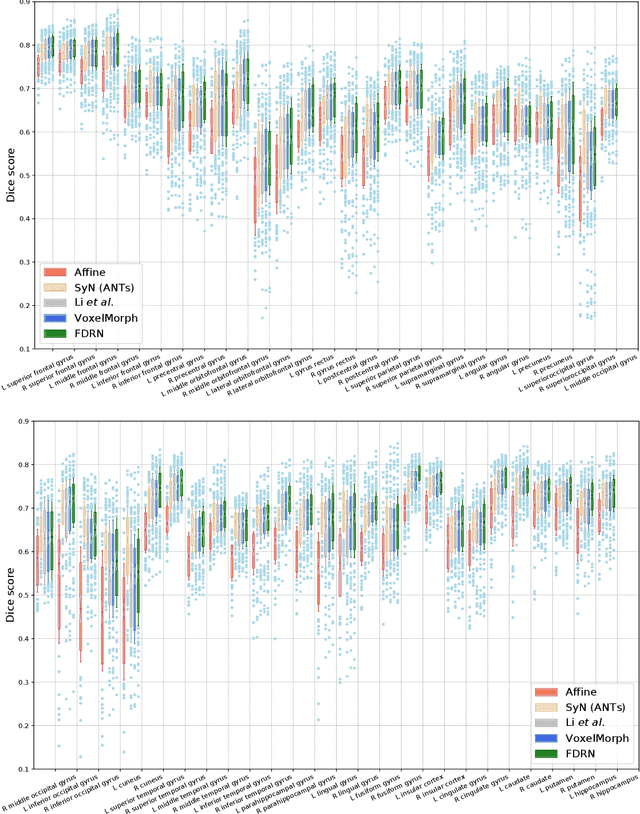
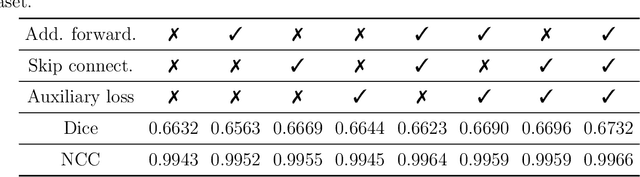
Deformable image registration is a fundamental task in medical imaging. Due to the large computational complexity of deformable registration of volumetric images, conventional iterative methods usually face the tradeoff between the registration accuracy and the computation time in practice. In order to boost the registration performance in both accuracy and runtime, we propose a fast unsupervised convolutional neural network for deformable image registration. Specially, the proposed FDRN possesses a compact encoder-decoder structure and exploits deep supervision, additive forwarding and residual learning. We conducted comparison with the existing state-of-the-art registration methods on the LPBA40 brain MRI dataset. Experimental results demonstrate that our FDRN performs better than the investigated methods qualitatively and quantitatively in Dice score and normalized cross correlation (NCC). Besides, FDRN is a generalized framework for image registration which is not confined to a particular type of medical images or anatomy. It can also be applied to other anatomical structures or CT images.
A Multi-Task Deep Learning Framework for Building Footprint Segmentation
Apr 19, 2021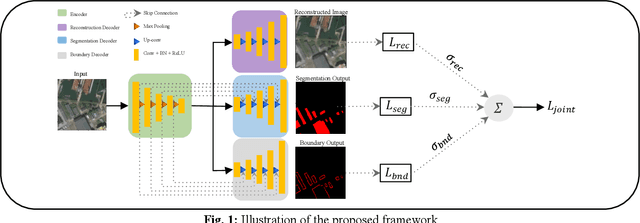
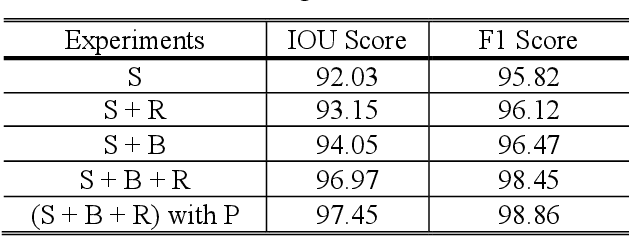

The task of building footprint segmentation has been well-studied in the context of remote sensing (RS) as it provides valuable information in many aspects, however, difficulties brought by the nature of RS images such as variations in the spatial arrangements and in-consistent constructional patterns require studying further, since it often causes poorly classified segmentation maps. We address this need by designing a joint optimization scheme for the task of building footprint delineation and introducing two auxiliary tasks; image reconstruction and building footprint boundary segmentation with the intent to reveal the common underlying structure to advance the classification accuracy of a single task model under the favor of auxiliary tasks. In particular, we propose a deep multi-task learning (MTL) based unified fully convolutional framework which operates in an end-to-end manner by making use of joint loss function with learnable loss weights considering the homoscedastic uncertainty of each task loss. Experimental results conducted on the SpaceNet6 dataset demonstrate the potential of the proposed MTL framework as it improves the classification accuracy considerably compared to single-task and lesser compounded tasks.
Multispectral Image Intrinsic Decomposition via Low Rank Constraint
Feb 24, 2018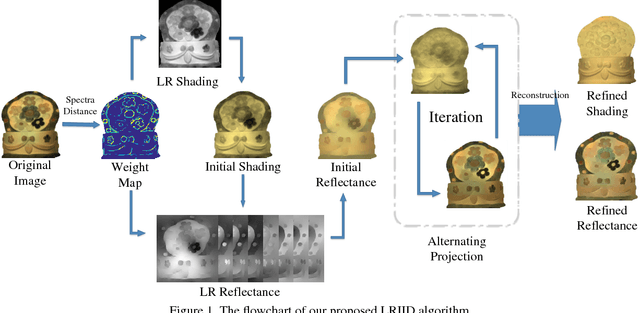
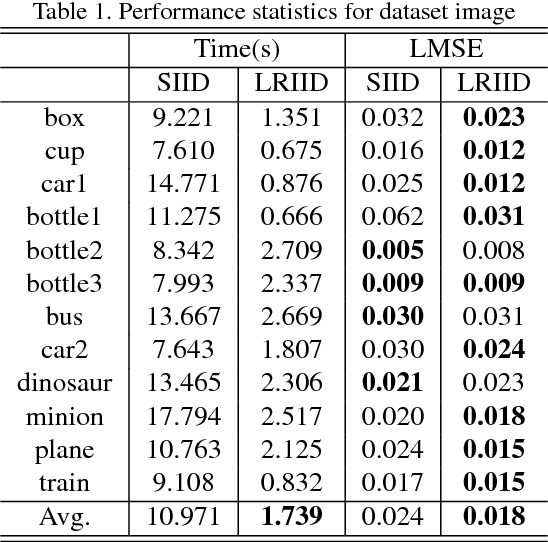
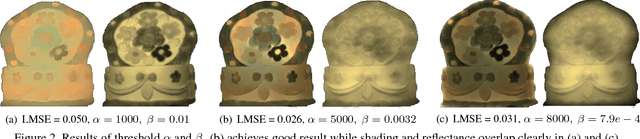
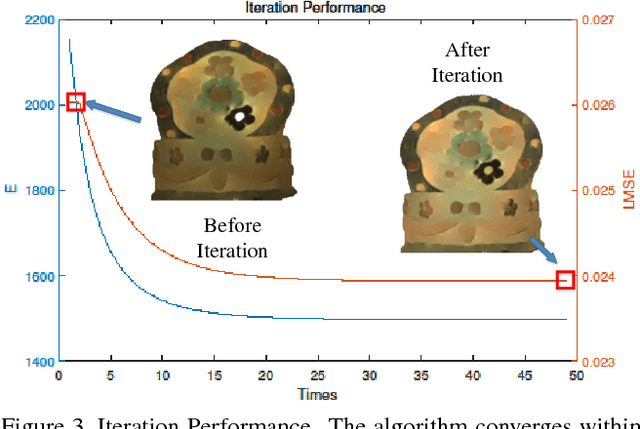
Multispectral images contain many clues of surface characteristics of the objects, thus can be widely used in many computer vision tasks, e.g., recolorization and segmentation. However, due to the complex illumination and the geometry structure of natural scenes, the spectra curves of a same surface can look very different. In this paper, a Low Rank Multispectral Image Intrinsic Decomposition model (LRIID) is presented to decompose the shading and reflectance from a single multispectral image. We extend the Retinex model, which is proposed for RGB image intrinsic decomposition, for multispectral domain. Based on this, a low rank constraint is proposed to reduce the ill-posedness of the problem and make the algorithm solvable. A dataset of 12 images is given with the ground truth of shadings and reflectance, so that the objective evaluations can be conducted. The experiments demonstrate the effectiveness of proposed method.
The Power of Complementary Regularizers: Image Recovery via Transform Learning and Low-Rank Modeling
Aug 03, 2018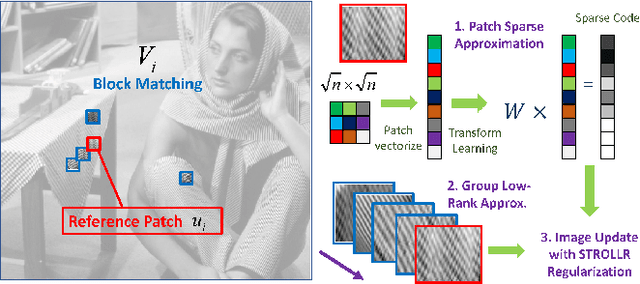


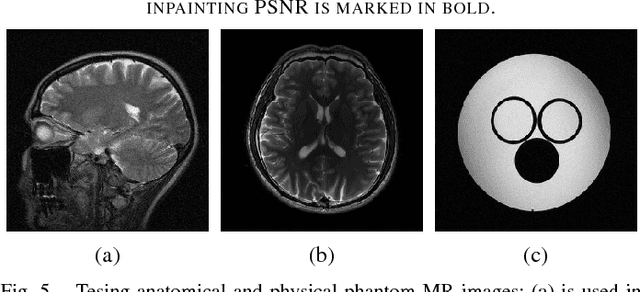
Recent works on adaptive sparse and on low-rank signal modeling have demonstrated their usefulness in various image / video processing applications. Patch-based methods exploit local patch sparsity, whereas other works apply low-rankness of grouped patches to exploit image non-local structures. However, using either approach alone usually limits performance in image reconstruction or recovery applications. In this work, we propose a simultaneous sparsity and low-rank model, dubbed STROLLR, to better represent natural images. In order to fully utilize both the local and non-local image properties, we develop an image restoration framework using a transform learning scheme with joint low-rank regularization. The approach owes some of its computational efficiency and good performance to the use of transform learning for adaptive sparse representation rather than the popular synthesis dictionary learning algorithms, which involve approximation of NP-hard sparse coding and expensive learning steps. We demonstrate the proposed framework in various applications to image denoising, inpainting, and compressed sensing based magnetic resonance imaging. Results show promising performance compared to state-of-the-art competing methods.
GLAC Net: GLocal Attention Cascading Networks for Multi-image Cued Story Generation
Jun 24, 2018
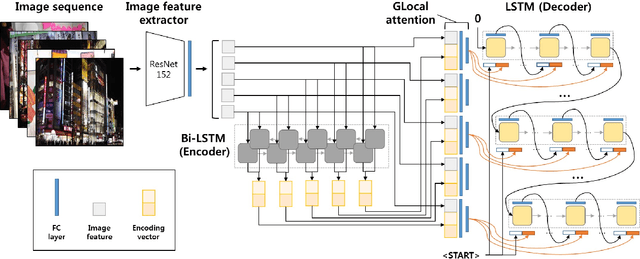

The task of multi-image cued story generation, such as visual storytelling dataset (VIST) challenge, is to compose multiple coherent sentences from a given sequence of images. The main difficulty is how to generate image-specific sentences within the context of overall images. Here we propose a deep learning network model, GLAC Net, that generates visual stories by combining global-local (glocal) attention and context cascading mechanisms. The model incorporates two levels of attention, i.e., overall encoding level and image feature level, to construct image-dependent sentences. While standard attention configuration needs a large number of parameters, the GLAC Net implements them in a very simple way via hard connections from the outputs of encoders or image features onto the sentence generators. The coherency of the generated story is further improved by conveying (cascading) the information of the previous sentence to the next sentence serially. We evaluate the performance of the GLAC Net on the visual storytelling dataset (VIST) and achieve very competitive results compared to the state-of-the-art techniques.
Hierarchical Complementary Learning for Weakly Supervised Object Localization
Nov 16, 2020
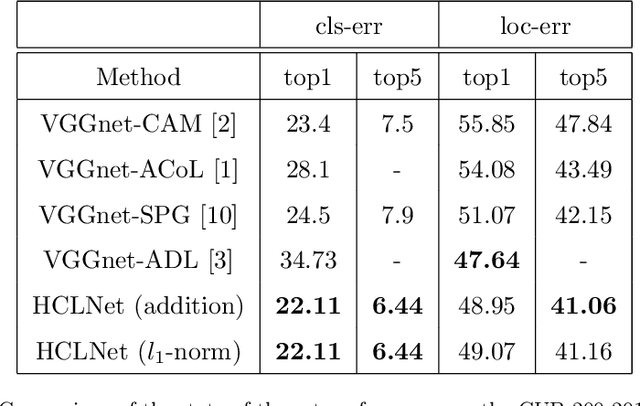
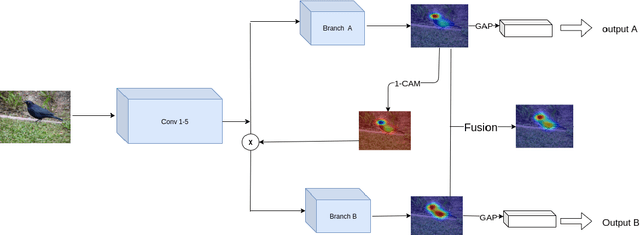
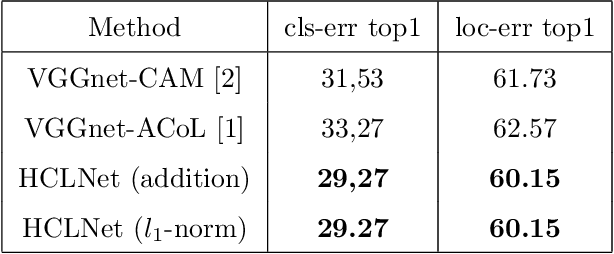
Weakly supervised object localization (WSOL) is a challenging problem which aims to localize objects with only image-level labels. Due to the lack of ground truth bounding boxes, class labels are mainly employed to train the model. This model generates a class activation map (CAM) which activates the most discriminate features. However, the main drawback of CAM is the ability to detect just a part of the object. To solve this problem, some researchers have removed parts from the detected object \cite{b1, b2, b4}, or the image \cite{b3}. The aim of removing parts from image or detected parts of the object is to force the model to detect the other features. However, these methods require one or many hyper-parameters to erase the appropriate pixels on the image, which could involve a loss of information. In contrast, this paper proposes a Hierarchical Complementary Learning Network method (HCLNet) that helps the CNN to perform better classification and localization of objects on the images. HCLNet uses a complementary map to force the network to detect the other parts of the object. Unlike previous works, this method does not need any extras hyper-parameters to generate different CAMs, as well as does not introduce a big loss of information. In order to fuse these different maps, two different fusion strategies known as the addition strategy and the l1-norm strategy have been used. These strategies allowed to detect the whole object while excluding the background. Extensive experiments show that HCLNet obtains better performance than state-of-the-art methods.
Machine Learning based Efficient QT-MTT Partitioning Scheme for VVC Intra Encoders
Mar 10, 2021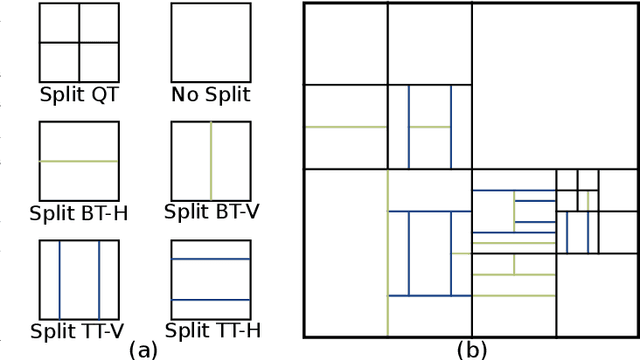
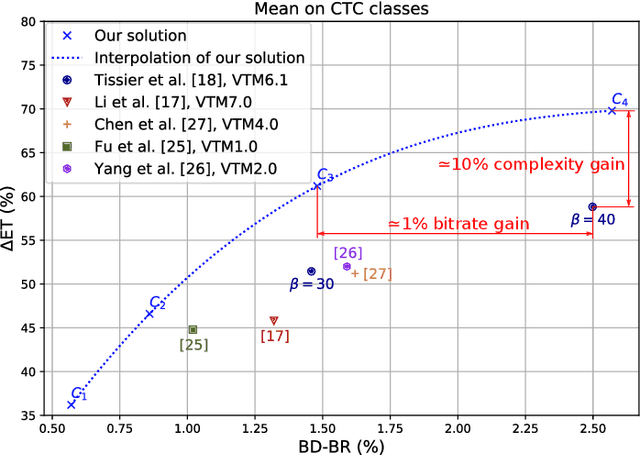
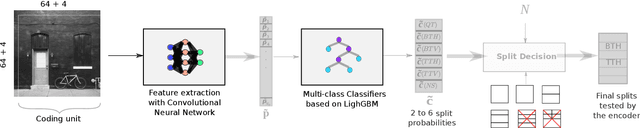
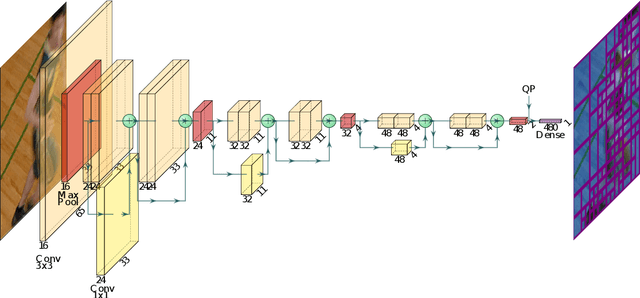
The next-generation Versatile Video Coding (VVC) standard introduces a new Multi-Type Tree (MTT) block partitioning structure that supports Binary-Tree (BT) and Ternary-Tree (TT) splits in both vertical and horizontal directions. This new approach leads to five possible splits at each block depth and thereby improves the coding efficiency of VVC over that of the preceding High Efficiency Video Coding (HEVC) standard, which only supports Quad-Tree (QT) partitioning with a single split per block depth. However, MTT also has brought a considerable impact on encoder computational complexity. In this paper, a two-stage learning-based technique is proposed to tackle the complexity overhead of MTT in VVC intra encoders. In our scheme, the input block is first processed by a Convolutional Neural Network (CNN) to predict its spatial features through a vector of probabilities describing the partition at each 4x4 edge. Subsequently, a Decision Tree (DT) model leverages this vector of spatial features to predict the most likely splits at each block. Finally, based on this prediction, only the N most likely splits are processed by the Rate-Distortion (RD) process of the encoder. In order to train our CNN and DT models on a wide range of image contents, we also propose a public VVC frame partitioning dataset based on existing image dataset encoded with the VVC reference software encoder. Our proposal relying on the top-3 configuration reaches 46.6% complexity reduction for a negligible bitrate increase of 0.86%. A top-2 configuration enables a higher complexity reduction of 69.8% for 2.57% bitrate loss. These results emphasis a better trade-off between VTM intra coding efficiency and complexity reduction compared to the state-of-the-art solutions.
HistoGAN: Controlling Colors of GAN-Generated and Real Images via Color Histograms
Nov 23, 2020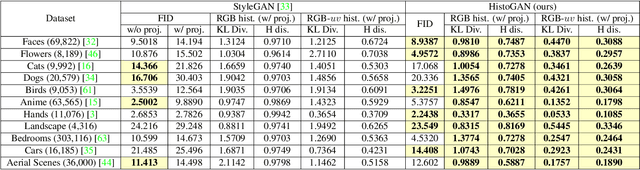
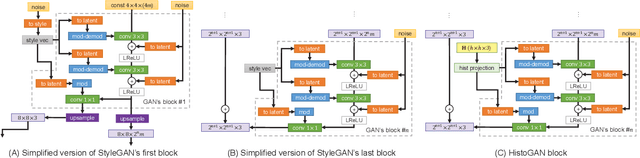

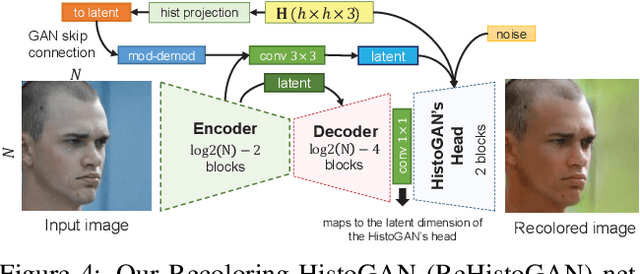
While generative adversarial networks (GANs) can successfully produce high-quality images, they can be challenging to control. Simplifying GAN-based image generation is critical for their adoption in graphic design and artistic work. This goal has led to significant interest in methods that can intuitively control the appearance of images generated by GANs. In this paper, we present HistoGAN, a color histogram-based method for controlling GAN-generated images' colors. We focus on color histograms as they provide an intuitive way to describe image color while remaining decoupled from domain-specific semantics. Specifically, we introduce an effective modification of the recent StyleGAN architecture to control the colors of GAN-generated images specified by a target color histogram feature. We then describe how to expand HistoGAN to recolor real images. For image recoloring, we jointly train an encoder network along with HistoGAN. The recoloring model, ReHistoGAN, is an unsupervised approach trained to encourage the network to keep the original image's content while changing the colors based on the given target histogram. We show that this histogram-based approach offers a better way to control GAN-generated and real images' colors while producing more compelling results compared to existing alternative strategies.
TransPose: Towards Explainable Human Pose Estimation by Transformer
Dec 31, 2020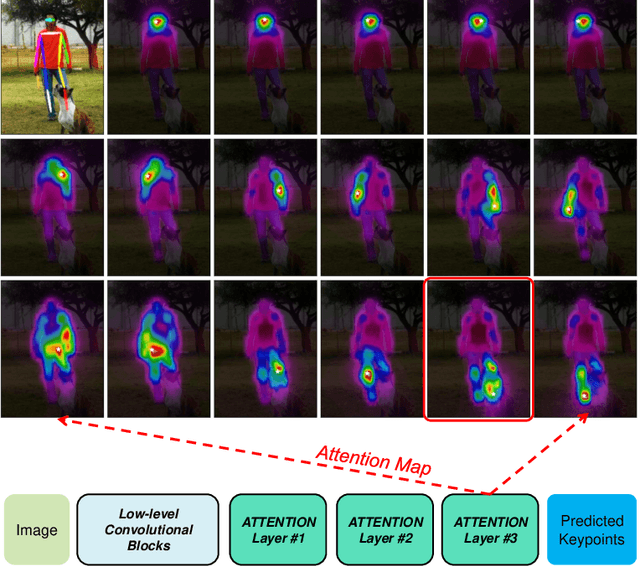
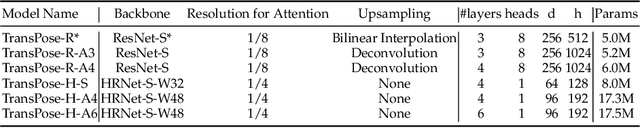
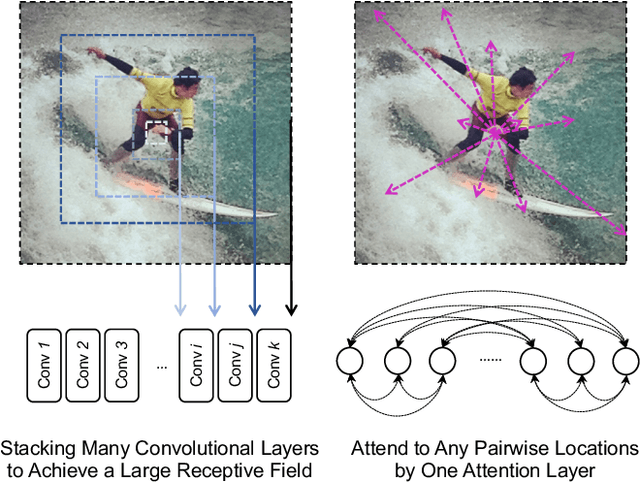
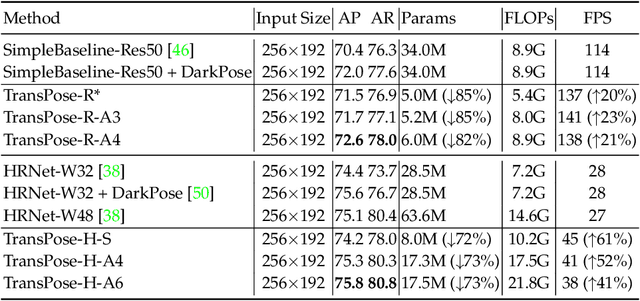
Deep Convolutional Neural Networks (CNNs) have made remarkable progress on human pose estimation task. However, there is no explicit understanding of how the locations of body keypoints are predicted by CNN, and it is also unknown what spatial dependency relationships between structural variables are learned in the model. To explore these questions, we construct an explainable model named TransPose based on Transformer architecture and low-level convolutional blocks. Given an image, the attention layers built in Transformer can capture long-range spatial relationships between keypoints and explain what dependencies the predicted keypoints locations highly rely on. We analyze the rationality of using attention as the explanation to reveal the spatial dependencies in this task. The revealed dependencies are image-specific and variable for different keypoint types, layer depths, or trained models. The experiments show that TransPose can accurately predict the positions of keypoints. It achieves state-of-the-art performance on COCO dataset, while being more interpretable, lightweight, and efficient than mainstream fully convolutional architectures.
Minimizing Perceived Image Quality Loss Through Adversarial Attack Scoping
Apr 23, 2019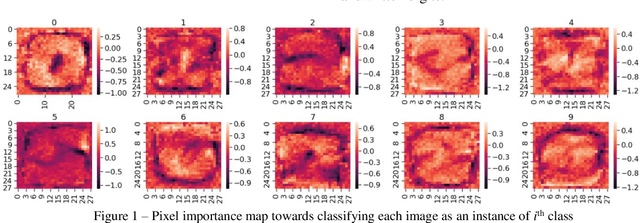
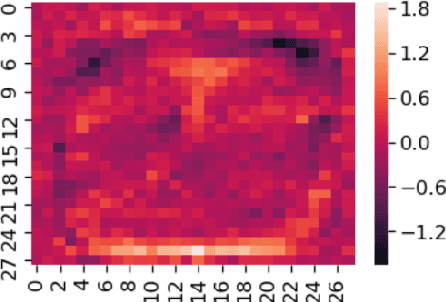
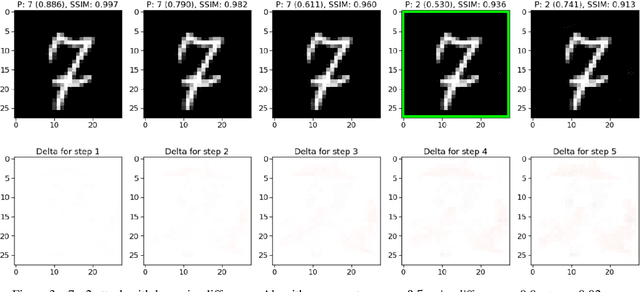
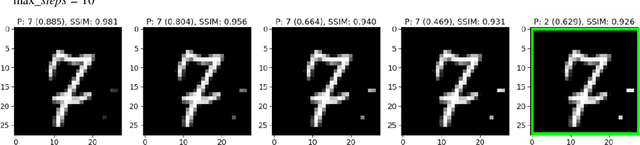
Neural networks are now actively being used for computer vision tasks in security critical areas such as robotics, face recognition, autonomous vehicles yet their safety is under question after the discovery of adversarial attacks. In this paper we develop simplified adversarial attack algorithms based on a scoping idea, which enables execution of fast adversarial attacks that minimize structural image quality (SSIM) loss, allows performing efficient transfer attacks with low target inference network call count and opens a possibility of an attack using pen-only drawings on a paper for the MNIST handwritten digit dataset. The presented adversarial attack analysis and the idea of attack scoping can be easily expanded to different datasets, thus making the paper's results applicable to a wide range of practical tasks.