 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Neural Networks for Learning Counterfactual G-Invariances from Single Environments
Apr 20, 2021
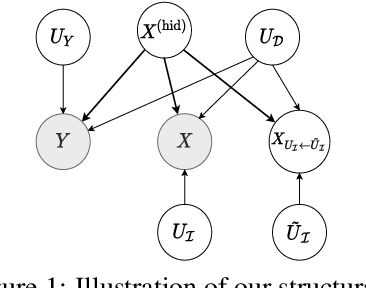

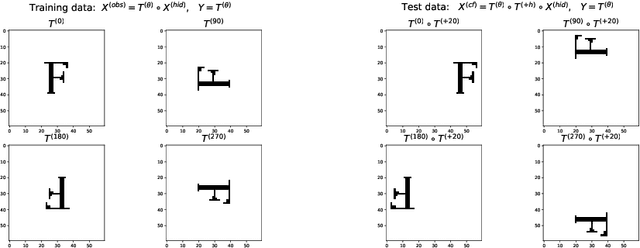

Despite -- or maybe because of -- their astonishing capacity to fit data, neural networks are believed to have difficulties extrapolating beyond training data distribution. This work shows that, for extrapolations based on finite transformation groups, a model's inability to extrapolate is unrelated to its capacity. Rather, the shortcoming is inherited from a learning hypothesis: Examples not explicitly observed with infinitely many training examples have underspecified outcomes in the learner's model. In order to endow neural networks with the ability to extrapolate over group transformations, we introduce a learning framework counterfactually-guided by the learning hypothesis that any group invariance to (known) transformation groups is mandatory even without evidence, unless the learner deems it inconsistent with the training data. Unlike existing invariance-driven methods for (counterfactual) extrapolations, this framework allows extrapolations from a single environment. Finally, we introduce sequence and image extrapolation tasks that validate our framework and showcase the shortcomings of traditional approaches.
Deep regression for uncertainty-aware and interpretable analysis of large-scale body MRI
May 17, 2021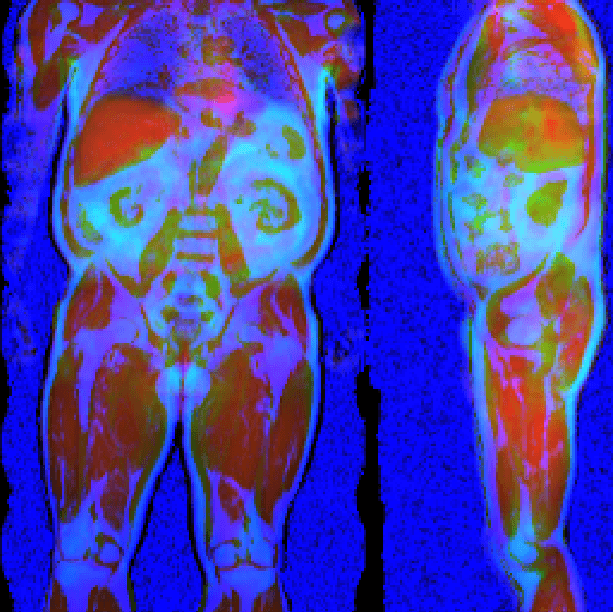
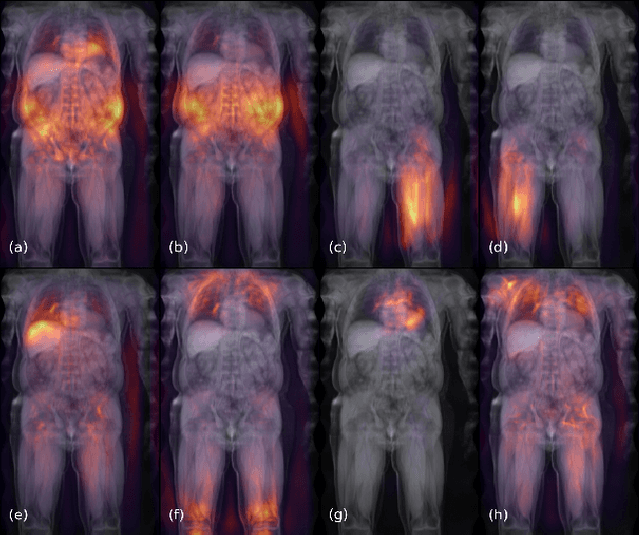
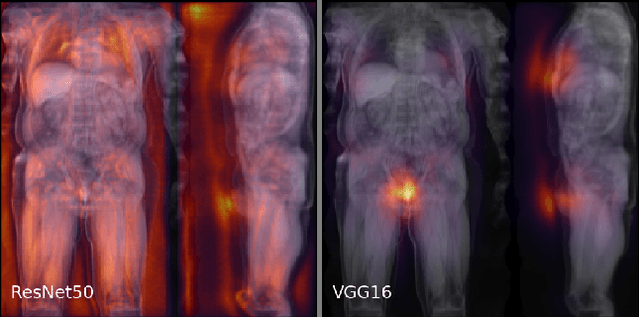
Large-scale medical studies such as the UK Biobank examine thousands of volunteer participants with medical imaging techniques. Combined with the vast amount of collected metadata, anatomical information from these images has the potential for medical analyses at unprecedented scale. However, their evaluation often requires manual input and long processing times, limiting the amount of reference values for biomarkers and other measurements available for research. Recent approaches with convolutional neural networks for regression can perform these evaluations automatically. On magnetic resonance imaging (MRI) data of more than 40,000 UK Biobank subjects, these systems can estimate human age, body composition and more. This style of analysis is almost entirely data-driven and no manual intervention or guidance with manually segmented ground truth images is required. The networks often closely emulate the reference method that provided their training data and can reach levels of agreement comparable to the expected variability between established medical gold standard techniques. The risk of silent failure can be individually quantified by predictive uncertainty obtained from a mean-variance criterion and ensembling. Saliency analysis furthermore enables an interpretation of the underlying relevant image features and showed that the networks learned to correctly target specific organs, limbs, and regions of interest.
Learning Regional Attention over Multi-resolution Deep Convolutional Features for Trademark Retrieval
Apr 15, 2021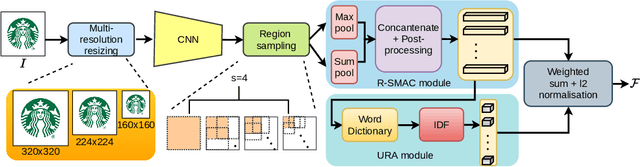
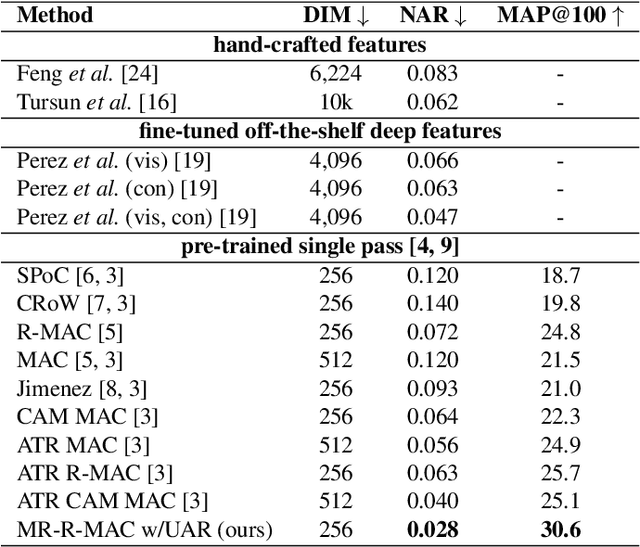

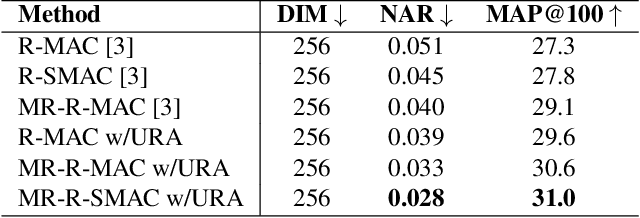
Large-scale trademark retrieval is an important content-based image retrieval task. A recent study shows that off-the-shelf deep features aggregated with Regional-Maximum Activation of Convolutions (R-MAC) achieve state-of-the-art results. However, R-MAC suffers in the presence of background clutter/trivial regions and scale variance, and discards important spatial information. We introduce three simple but effective modifications to R-MAC to overcome these drawbacks. First, we propose the use of both sum and max pooling to minimise the loss of spatial information. We also employ domain-specific unsupervised soft-attention to eliminate background clutter and unimportant regions. Finally, we add multi-resolution inputs to enhance the scale-invariance of R-MAC. We evaluate these three modifications on the million-scale METU dataset. Our results show that all modifications bring non-trivial improvements, and surpass previous state-of-the-art results.
Generating 3D structures from a 2D slice with GAN-based dimensionality expansion
Feb 10, 2021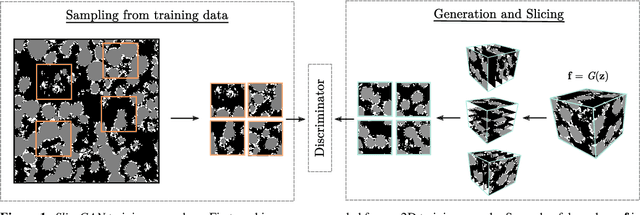
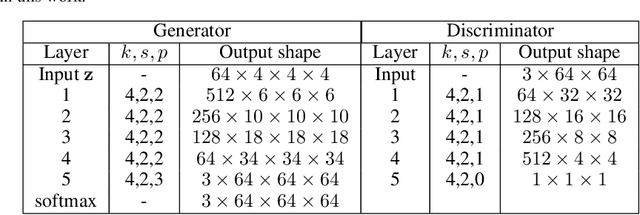
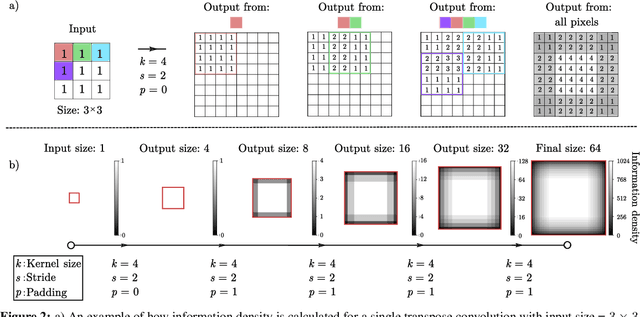

Generative adversarial networks (GANs) can be trained to generate 3D image data, which is useful for design optimisation. However, this conventionally requires 3D training data, which is challenging to obtain. 2D imaging techniques tend to be faster, higher resolution, better at phase identification and more widely available. Here, we introduce a generative adversarial network architecture, SliceGAN, which is able to synthesise high fidelity 3D datasets using a single representative 2D image. This is especially relevant for the task of material microstructure generation, as a cross-sectional micrograph can contain sufficient information to statistically reconstruct 3D samples. Our architecture implements the concept of uniform information density, which both ensures that generated volumes are equally high quality at all points in space, and that arbitrarily large volumes can be generated. SliceGAN has been successfully trained on a diverse set of materials, demonstrating the widespread applicability of this tool. The quality of generated micrographs is shown through a statistical comparison of synthetic and real datasets of a battery electrode in terms of key microstructural metrics. Finally, we find that the generation time for a $10^8$ voxel volume is on the order of a few seconds, yielding a path for future studies into high-throughput microstructural optimisation.
Learning Single-Image Depth from Videos using Quality Assessment Networks
Jun 25, 2018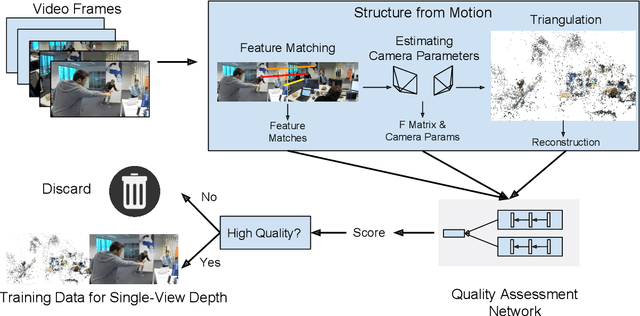
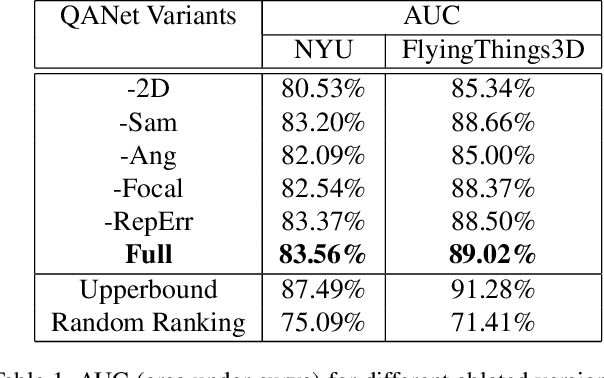
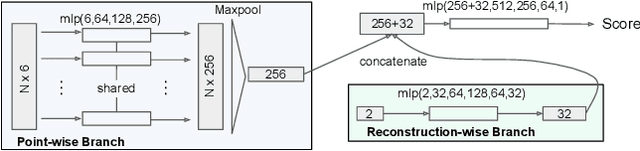
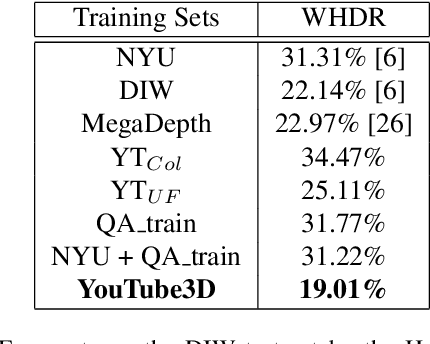
Although significant progress has been made in recent years, depth estimation from a single image in the wild is still a very challenging problem. One reason is the lack of high-quality image-depth data in the wild. In this paper we propose a fully automatic pipeline based on Structure-from-Motion (SfM) to generate such data from arbitrary videos. The core of this pipeline is a Quality Assessment Network that can distinguish correct and incorrect reconstructions obtained from SfM. With the proposed pipeline, we generate image-depth data from the NYU Depth dataset and random YouTube videos. We show that depth-prediction networks trained on such data can achieve competitive performance on the NYU Depth and the Depth-in-the-Wild benchmarks.
Camera-based Image Forgery Localization using Convolutional Neural Networks
Aug 29, 2018
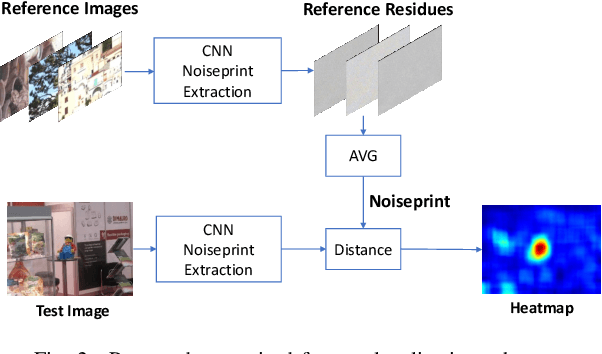
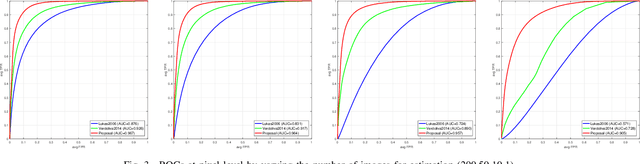
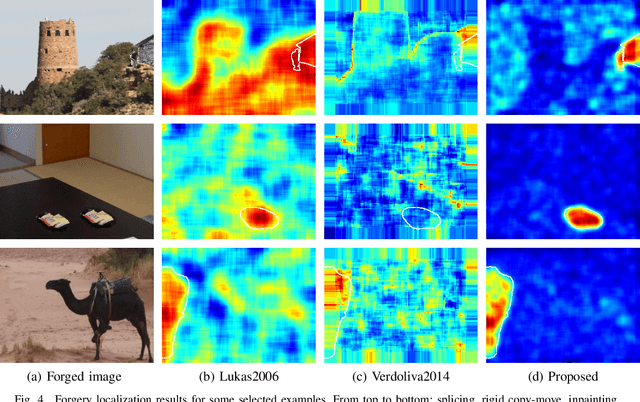
Camera fingerprints are precious tools for a number of image forensics tasks. A well-known example is the photo response non-uniformity (PRNU) noise pattern, a powerful device fingerprint. Here, to address the image forgery localization problem, we rely on noiseprint, a recently proposed CNN-based camera model fingerprint. The CNN is trained to minimize the distance between same-model patches, and maximize the distance otherwise. As a result, the noiseprint accounts for model-related artifacts just like the PRNU accounts for device-related non-uniformities. However, unlike the PRNU, it is only mildly affected by residuals of high-level scene content. The experiments show that the proposed noiseprint-based forgery localization method improves over the PRNU-based reference.
Task-driven Semantic Coding via Reinforcement Learning
Jun 07, 2021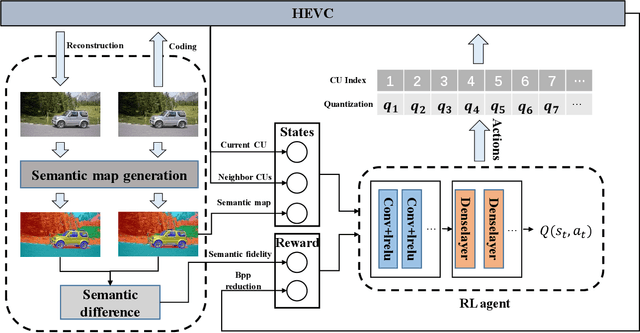
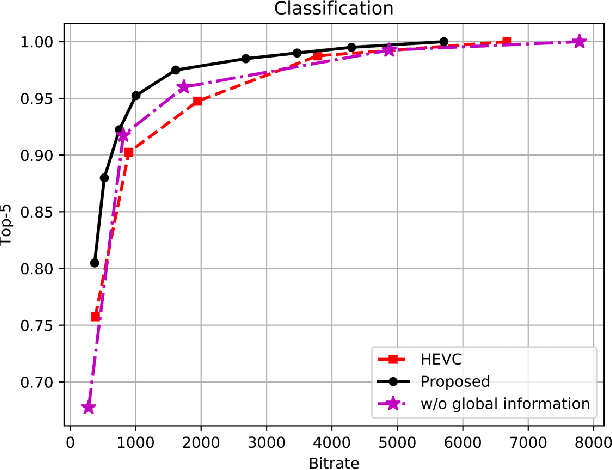
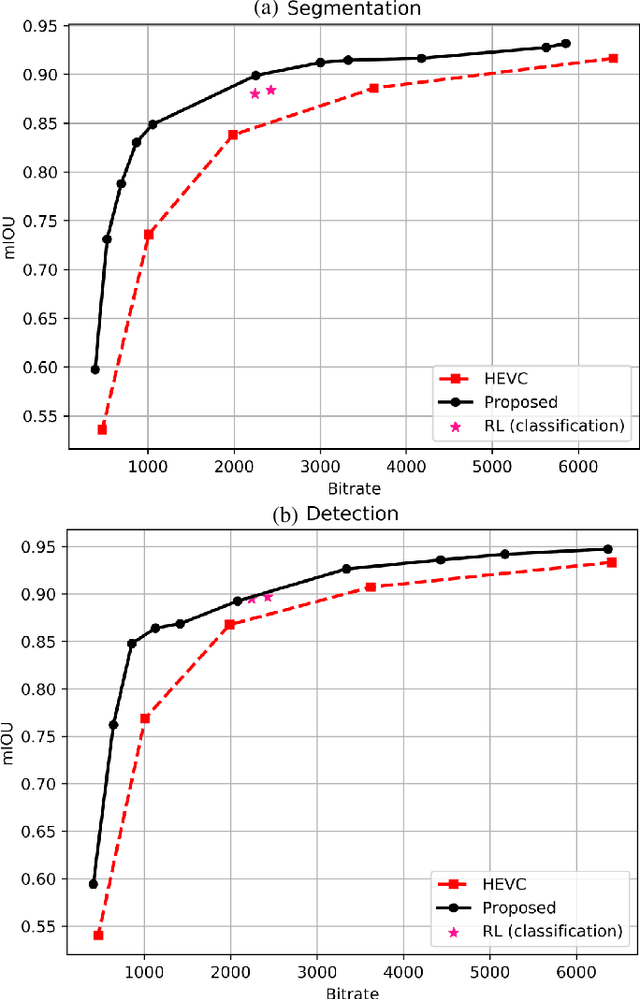
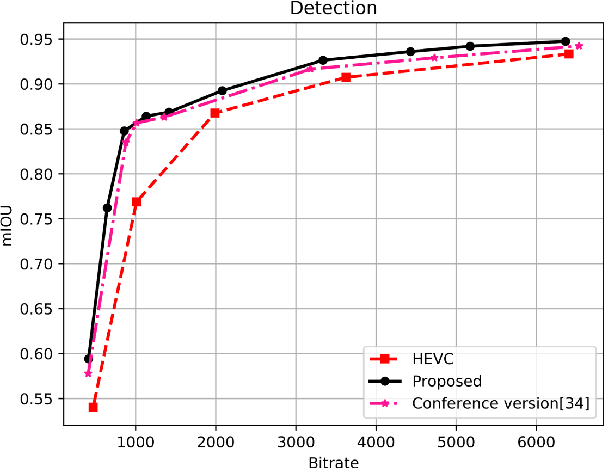
Task-driven semantic video/image coding has drawn considerable attention with the development of intelligent media applications, such as license plate detection, face detection, and medical diagnosis, which focuses on maintaining the semantic information of videos/images. Deep neural network (DNN)-based codecs have been studied for this purpose due to their inherent end-to-end optimization mechanism. However, the traditional hybrid coding framework cannot be optimized in an end-to-end manner, which makes task-driven semantic fidelity metric unable to be automatically integrated into the rate-distortion optimization process. Therefore, it is still attractive and challenging to implement task-driven semantic coding with the traditional hybrid coding framework, which should still be widely used in practical industry for a long time. To solve this challenge, we design semantic maps for different tasks to extract the pixelwise semantic fidelity for videos/images. Instead of directly integrating the semantic fidelity metric into traditional hybrid coding framework, we implement task-driven semantic coding by implementing semantic bit allocation based on reinforcement learning (RL). We formulate the semantic bit allocation problem as a Markov decision process (MDP) and utilize one RL agent to automatically determine the quantization parameters (QPs) for different coding units (CUs) according to the task-driven semantic fidelity metric. Extensive experiments on different tasks, such as classification, detection and segmentation, have demonstrated the superior performance of our approach by achieving an average bitrate saving of 34.39% to 52.62% over the High Efficiency Video Coding (H.265/HEVC) anchor under equivalent task-related semantic fidelity.
Dataset and Performance Comparison of Deep Learning Architectures for Plum Detection and Robotic Harvesting
May 09, 2021

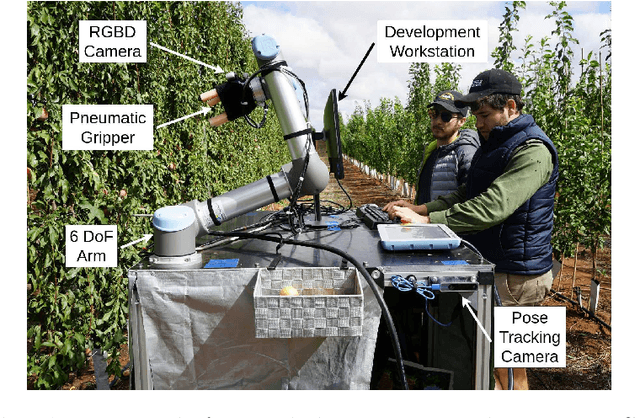
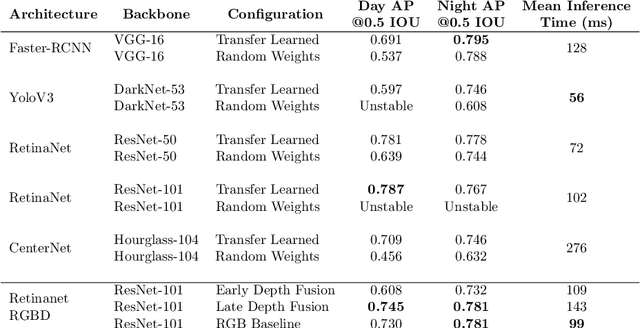
Many automated operations in agriculture, such as weeding and plant counting, require robust and accurate object detectors. Robotic fruit harvesting is one of these, and is an important technology to address the increasing labour shortages and uncertainty suffered by tree crop growers. An eye-in-hand sensing setup is commonly used in harvesting systems and provides benefits to sensing accuracy and flexibility. However, as the hand and camera move from viewing the entire trellis to picking a specific fruit, large changes in lighting, colour, obscuration and exposure occur. Object detection algorithms used in harvesting should be robust to these challenges, but few datasets for assessing this currently exist. In this work, two new datasets are gathered during day and night operation of an actual robotic plum harvesting system. A range of current generation deep learning object detectors are benchmarked against these. Additionally, two methods for fusing depth and image information are tested for their impact on detector performance. Significant differences between day and night accuracy of different detectors is found, transfer learning is identified as essential in all cases, and depth information fusion is assessed as only marginally effective. The dataset and benchmark models are made available online.
Multilingual Multimodal Pre-training for Zero-Shot Cross-Lingual Transfer of Vision-Language Models
Apr 15, 2021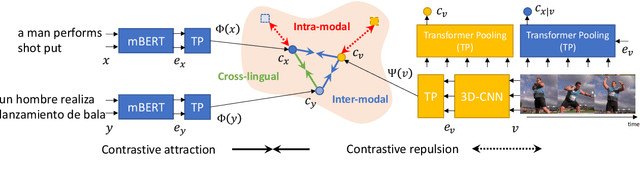

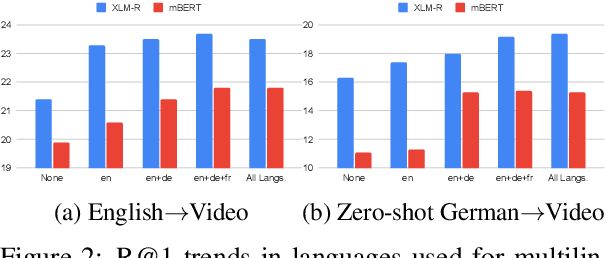
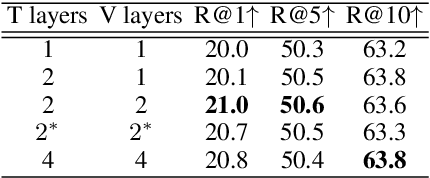
This paper studies zero-shot cross-lingual transfer of vision-language models. Specifically, we focus on multilingual text-to-video search and propose a Transformer-based model that learns contextualized multilingual multimodal embeddings. Under a zero-shot setting, we empirically demonstrate that performance degrades significantly when we query the multilingual text-video model with non-English sentences. To address this problem, we introduce a multilingual multimodal pre-training strategy, and collect a new multilingual instructional video dataset (MultiHowTo100M) for pre-training. Experiments on VTT show that our method significantly improves video search in non-English languages without additional annotations. Furthermore, when multilingual annotations are available, our method outperforms recent baselines by a large margin in multilingual text-to-video search on VTT and VATEX; as well as in multilingual text-to-image search on Multi30K. Our model and Multi-HowTo100M is available at http://github.com/berniebear/Multi-HT100M.
Recurrent neural networks for aortic image sequence segmentation with sparse annotations
Aug 01, 2018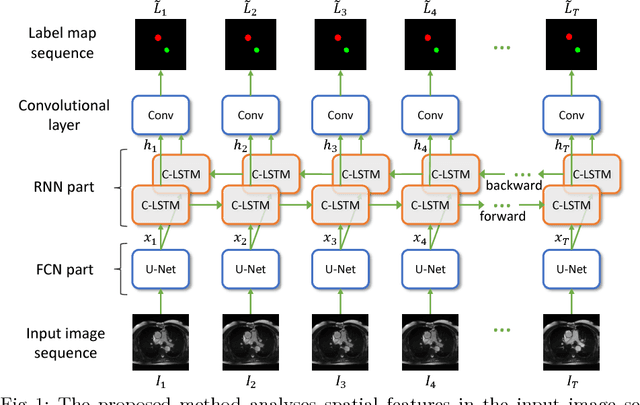
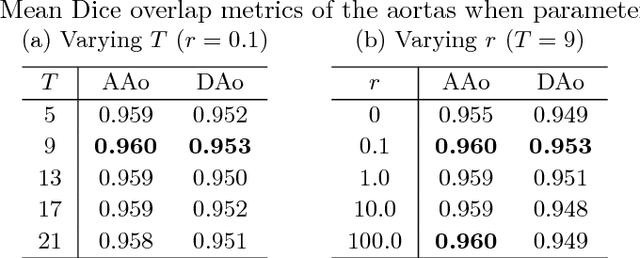
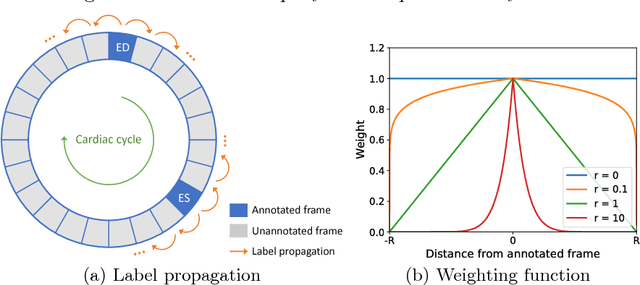

Segmentation of image sequences is an important task in medical image analysis, which enables clinicians to assess the anatomy and function of moving organs. However, direct application of a segmentation algorithm to each time frame of a sequence may ignore the temporal continuity inherent in the sequence. In this work, we propose an image sequence segmentation algorithm by combining a fully convolutional network with a recurrent neural network, which incorporates both spatial and temporal information into the segmentation task. A key challenge in training this network is that the available manual annotations are temporally sparse, which forbids end-to-end training. We address this challenge by performing non-rigid label propagation on the annotations and introducing an exponentially weighted loss function for training. Experiments on aortic MR image sequences demonstrate that the proposed method significantly improves both accuracy and temporal smoothness of segmentation, compared to a baseline method that utilises spatial information only. It achieves an average Dice metric of 0.960 for the ascending aorta and 0.953 for the descending aorta.