 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
End-to-End Time-Lapse Video Synthesis from a Single Outdoor Image
Apr 01, 2019


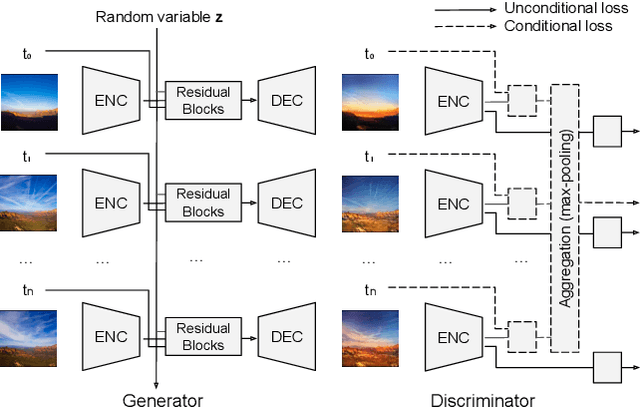
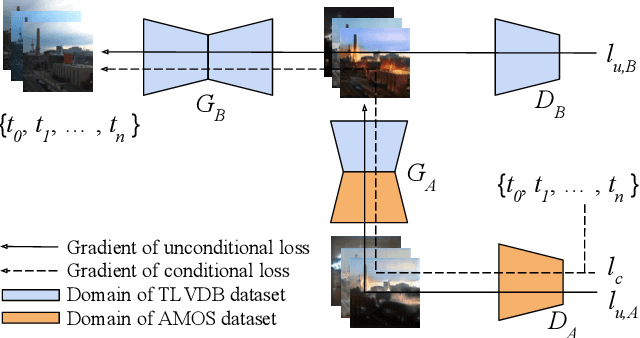
Time-lapse videos usually contain visually appealing content but are often difficult and costly to create. In this paper, we present an end-to-end solution to synthesize a time-lapse video from a single outdoor image using deep neural networks. Our key idea is to train a conditional generative adversarial network based on existing datasets of time-lapse videos and image sequences. We propose a multi-frame joint conditional generation framework to effectively learn the correlation between the illumination change of an outdoor scene and the time of the day. We further present a multi-domain training scheme for robust training of our generative models from two datasets with different distributions and missing timestamp labels. Compared to alternative time-lapse video synthesis algorithms, our method uses the timestamp as the control variable and does not require a reference video to guide the synthesis of the final output. We conduct ablation studies to validate our algorithm and compare with state-of-the-art techniques both qualitatively and quantitatively.
From Selective Deep Convolutional Features to Compact Binary Representations for Image Retrieval
Jul 20, 2018

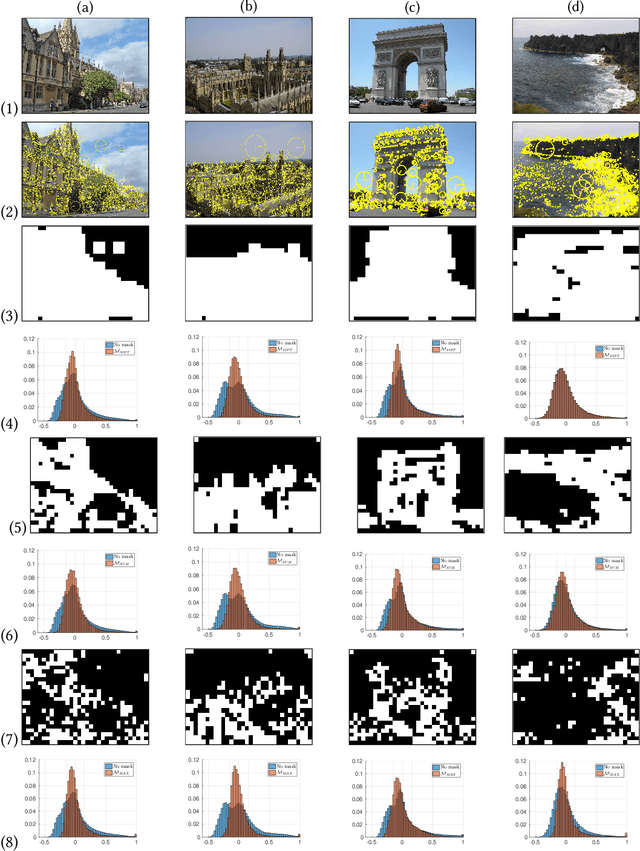

In the large-scale image retrieval task, the two most important requirements are the discriminability of image representations and the efficiency in computation and storage of representations. Regarding the former requirement, Convolutional Neural Network (CNN) is proven to be a very powerful tool to extract highly discriminative local descriptors for effective image search. Additionally, in order to further improve the discriminative power of the descriptors, recent works adopt fine-tuned strategies. In this paper, taking a different approach, we propose a novel, computationally efficient, and competitive framework. Specifically, we firstly propose various strategies to compute masks, namely SIFT-mask, SUM-mask, and MAX-mask, to select a representative subset of local convolutional features and eliminate redundant features. Our in-depth analyses demonstrate that proposed masking schemes are effective to address the burstiness drawback and improve retrieval accuracy. Secondly, we propose to employ recent embedding and aggregating methods which can significantly boost the feature discriminability. Regarding the computation and storage efficiency, we include a hashing module to produce very compact binary image representations. Extensive experiments on six image retrieval benchmarks demonstrate that our proposed framework achieves the state-of-the-art retrieval performances.
Exploiting Invariance in Training Deep Neural Networks
Mar 30, 2021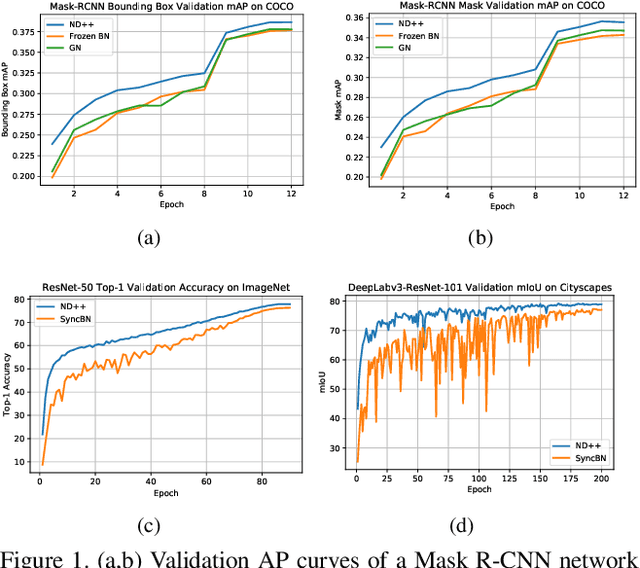
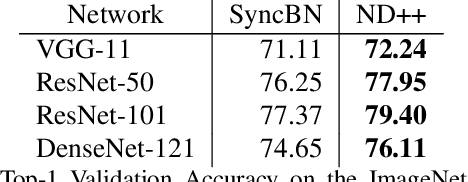
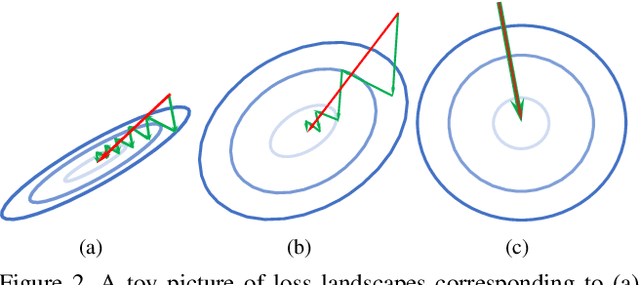

Inspired by two basic mechanisms in animal visual systems, we introduce a feature transform technique that imposes invariance properties in the training of deep neural networks. The resulting algorithm requires less parameter tuning, trains well with an initial learning rate 1.0, and easily generalizes to different tasks. We enforce scale invariance with local statistics in the data to align similar samples generated in diverse situations. To accelerate convergence, we enforce a GL(n)-invariance property with global statistics extracted from a batch that the gradient descent solution should remain invariant under basis change. Tested on ImageNet, MS COCO, and Cityscapes datasets, our proposed technique requires fewer iterations to train, surpasses all baselines by a large margin, seamlessly works on both small and large batch size training, and applies to different computer vision tasks of image classification, object detection, and semantic segmentation.
Large-Scale Image Retrieval with Attentive Deep Local Features
Feb 03, 2018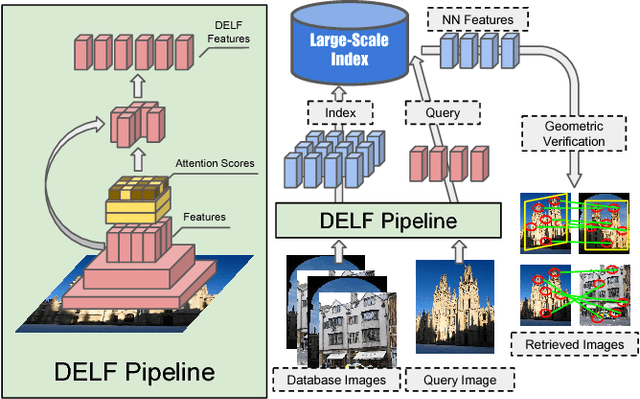
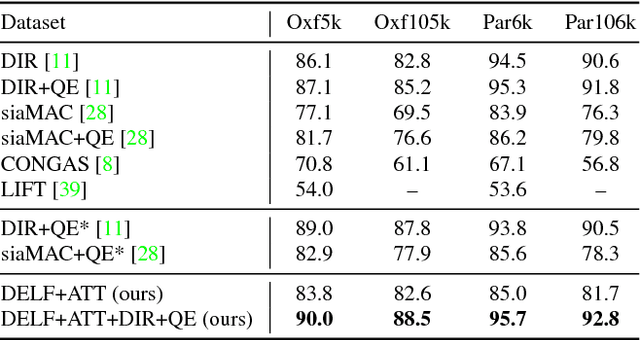

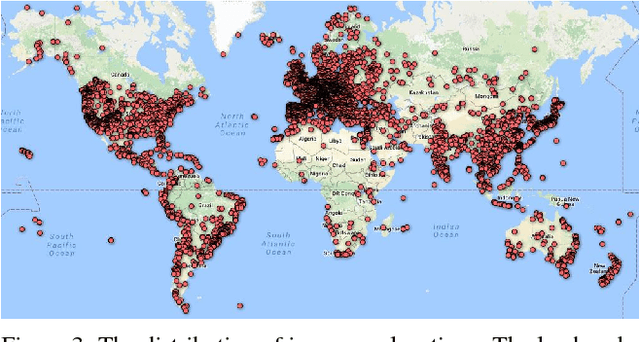
We propose an attentive local feature descriptor suitable for large-scale image retrieval, referred to as DELF (DEep Local Feature). The new feature is based on convolutional neural networks, which are trained only with image-level annotations on a landmark image dataset. To identify semantically useful local features for image retrieval, we also propose an attention mechanism for keypoint selection, which shares most network layers with the descriptor. This framework can be used for image retrieval as a drop-in replacement for other keypoint detectors and descriptors, enabling more accurate feature matching and geometric verification. Our system produces reliable confidence scores to reject false positives---in particular, it is robust against queries that have no correct match in the database. To evaluate the proposed descriptor, we introduce a new large-scale dataset, referred to as Google-Landmarks dataset, which involves challenges in both database and query such as background clutter, partial occlusion, multiple landmarks, objects in variable scales, etc. We show that DELF outperforms the state-of-the-art global and local descriptors in the large-scale setting by significant margins. Code and dataset can be found at the project webpage: https://github.com/tensorflow/models/tree/master/research/delf .
FusiformNet: Extracting Discriminative Facial Features on Different Levels
Nov 06, 2020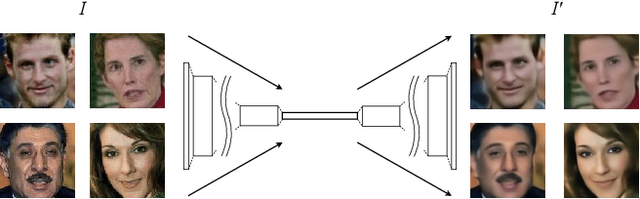
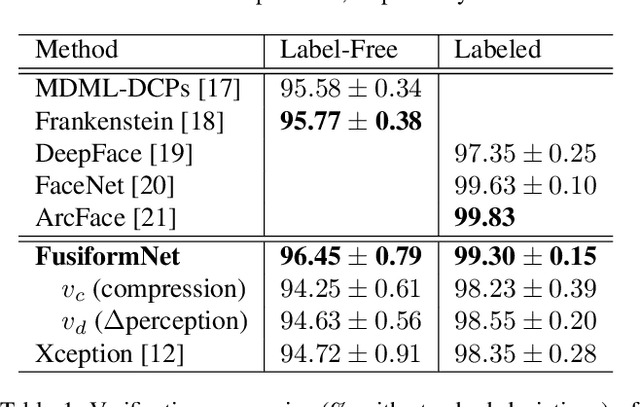
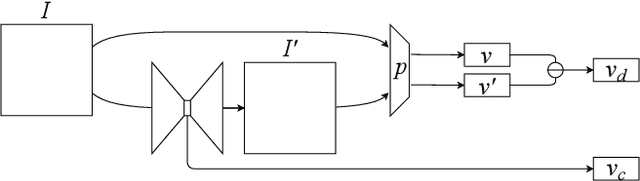
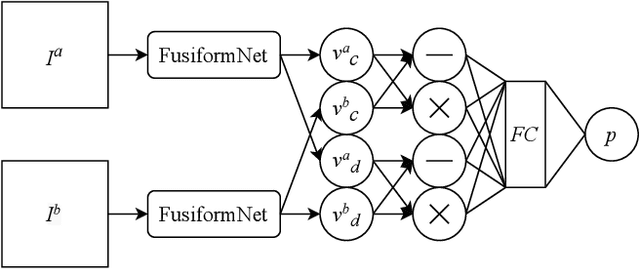
Over the last several years, research on facial recognition based on Deep Neural Network has evolved with approaches like task-specific loss functions, image normalization and augmentation, network architectures, etc. However, there have been few approaches with attention to how human faces differ from person to person. Premising that inter-personal differences are found both generally and locally on the human face, I propose FusiformNet, a novel framework for feature extraction that leverages the nature of discriminative facial features. Tested on Image-Unrestricted setting of Labeled Face in the Wild benchmark, this method achieved a state-of-the-art accuracy of 96.67% without labeled outside data, image augmentation, normalization, or special loss functions. Likewise, the method also performed on par with previous state-of-the-arts when pre-trained on CASIA-WebFace dataset. Considering its ability to extract both general and local facial features, the utility of FusiformNet may not be limited to facial recognition but also extend to other DNN-based tasks.
Preprocessing Methods of Lane Detection and Tracking for Autonomous Driving
Apr 10, 2021

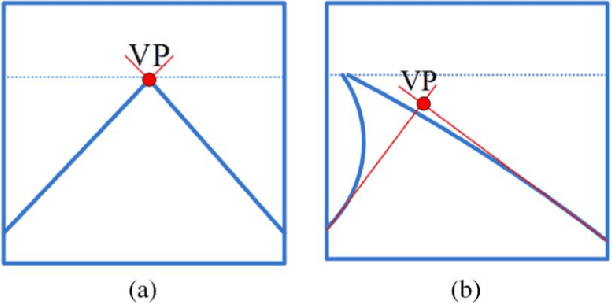

In the past few years, researches on advanced driver assistance systems (ADASs) have been carried out and deployed in intelligent vehicles. Systems that have been developed can perform different tasks, such as lane keeping assistance (LKA), lane departure warning (LDW), lane change warning (LCW) and adaptive cruise control (ACC). Real time lane detection and tracking (LDT) is one of the most consequential parts to performing the above tasks. Images which are extracted from the video, contain noise and other unwanted factors such as variation in lightening, shadow from nearby objects and etc. that requires robust preprocessing methods for lane marking detection and tracking. Preprocessing is critical for the subsequent steps and real time performance because its main function is to remove the irrelevant image parts and enhance the feature of interest. In this paper, we survey preprocessing methods for detecting lane marking as well as tracking lane boundaries in real time focusing on vision-based system.
Action Recognition with Dynamic Image Networks
Aug 19, 2017



We introduce the concept of "dynamic image", a novel compact representation of videos useful for video analysis, particularly in combination with convolutional neural networks (CNNs). A dynamic image encodes temporal data such as RGB or optical flow videos by using the concept of `rank pooling'. The idea is to learn a ranking machine that captures the temporal evolution of the data and to use the parameters of the latter as a representation. When a linear ranking machine is used, the resulting representation is in the form of an image, which we call dynamic because it summarizes the video dynamics in addition of appearance. This is a powerful idea because it allows to convert any video to an image so that existing CNN models pre-trained for the analysis of still images can be immediately extended to videos. We also present an efficient and effective approximate rank pooling operator, accelerating standard rank pooling algorithms by orders of magnitude, and formulate that as a CNN layer. This new layer allows generalizing dynamic images to dynamic feature maps. We demonstrate the power of the new representations on standard benchmarks in action recognition achieving state-of-the-art performance.
Robotic Inspection and 3D GPR-based Reconstruction for Underground Utilities
Jun 03, 2021

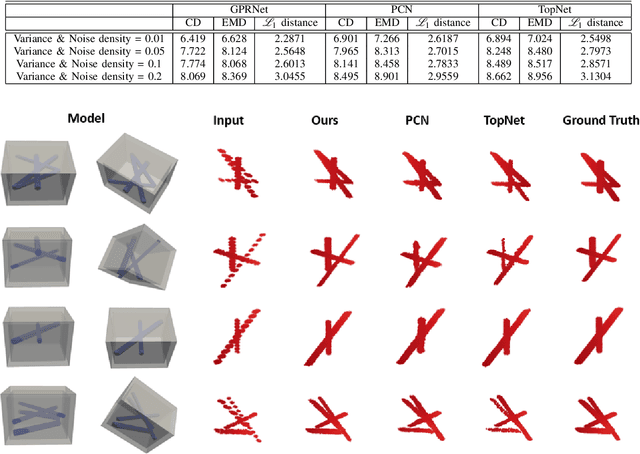
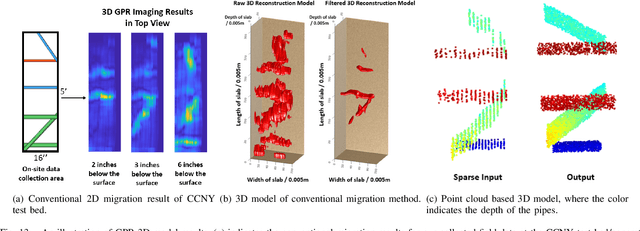
Ground Penetrating Radar (GPR) is an effective non-destructive evaluation (NDE) device for inspecting and surveying subsurface objects (i.e., rebars, utility pipes) in complex environments. However, the current practice for GPR data collection requires a human inspector to move a GPR cart along pre-marked grid lines and record the GPR data in both X and Y directions for post-processing by 3D GPR imaging software. It is time-consuming and tedious work to survey a large area. Furthermore, identifying the subsurface targets depends on the knowledge of an experienced engineer, who has to make manual and subjective interpretation that limits the GPR applications, especially in large-scale scenarios. In addition, the current GPR imaging technology is not intuitive, and not for normal users to understand, and not friendly to visualize. To address the above challenges, this paper presents a novel robotic system to collect GPR data, interpret GPR data, localize the underground utilities, reconstruct and visualize the underground objects' dense point cloud model in a user-friendly manner. This system is composed of three modules: 1) a vision-aided Omni-directional robotic data collection platform, which enables the GPR antenna to scan the target area freely with an arbitrary trajectory while using a visual-inertial-based positioning module tags the GPR measurements with positioning information; 2) a deep neural network (DNN) migration module to interpret the raw GPR B-scan image into a cross-section of object model; 3) a DNN-based 3D reconstruction method, i.e., GPRNet, to generate underground utility model represented as fine 3D point cloud. Comparative studies on synthetic and field GPR raw data with various incompleteness and noise are performed.
Adaptive Focus for Efficient Video Recognition
May 07, 2021
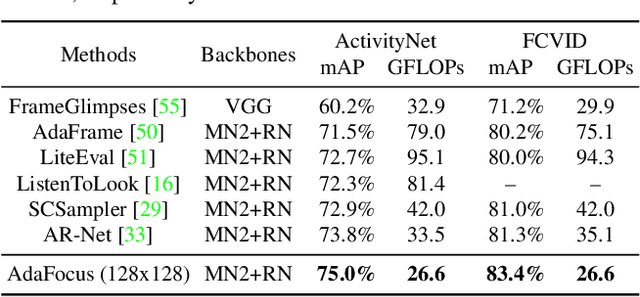
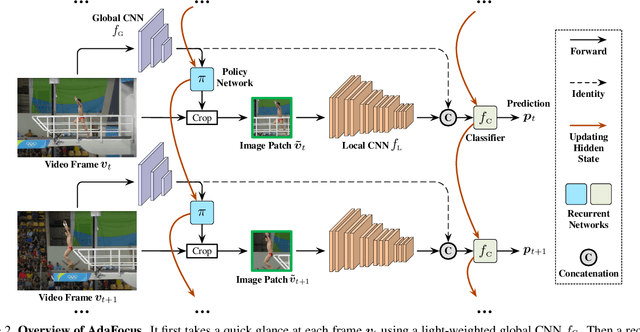
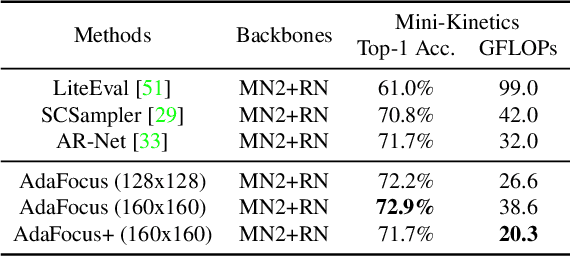
In this paper, we explore the spatial redundancy in video recognition with the aim to improve the computational efficiency. It is observed that the most informative region in each frame of a video is usually a small image patch, which shifts smoothly across frames. Therefore, we model the patch localization problem as a sequential decision task, and propose a reinforcement learning based approach for efficient spatially adaptive video recognition (AdaFocus). In specific, a light-weighted ConvNet is first adopted to quickly process the full video sequence, whose features are used by a recurrent policy network to localize the most task-relevant regions. Then the selected patches are inferred by a high-capacity network for the final prediction. During offline inference, once the informative patch sequence has been generated, the bulk of computation can be done in parallel, and is efficient on modern GPU devices. In addition, we demonstrate that the proposed method can be easily extended by further considering the temporal redundancy, e.g., dynamically skipping less valuable frames. Extensive experiments on five benchmark datasets, i.e., ActivityNet, FCVID, Mini-Kinetics, Something-Something V1&V2, demonstrate that our method is significantly more efficient than the competitive baselines. Code will be available at https://github.com/blackfeather-wang/AdaFocus.
Searching Collaborative Agents for Multi-plane Localization in 3D Ultrasound
May 22, 2021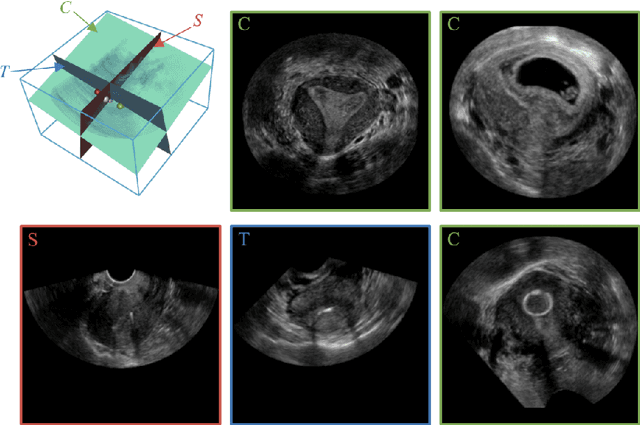
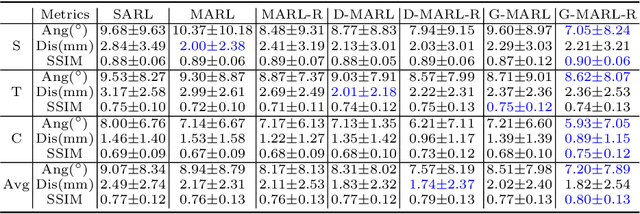
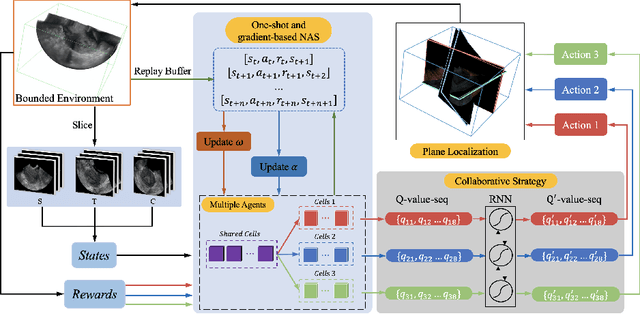

3D ultrasound (US) has become prevalent due to its rich spatial and diagnostic information not contained in 2D US. Moreover, 3D US can contain multiple standard planes (SPs) in one shot. Thus, automatically localizing SPs in 3D US has the potential to improve user-independence and scanning-efficiency. However, manual SP localization in 3D US is challenging because of the low image quality, huge search space and large anatomical variability. In this work, we propose a novel multi-agent reinforcement learning (MARL) framework to simultaneously localize multiple SPs in 3D US. Our contribution is four-fold. First, our proposed method is general and it can accurately localize multiple SPs in different challenging US datasets. Second, we equip the MARL system with a recurrent neural network (RNN) based collaborative module, which can strengthen the communication among agents and learn the spatial relationship among planes effectively. Third, we explore to adopt the neural architecture search (NAS) to automatically design the network architecture of both the agents and the collaborative module. Last, we believe we are the first to realize automatic SP localization in pelvic US volumes, and note that our approach can handle both normal and abnormal uterus cases. Extensively validated on two challenging datasets of the uterus and fetal brain, our proposed method achieves the average localization accuracy of 7.03 degrees/1.59mm and 9.75 degrees/1.19mm. Experimental results show that our light-weight MARL model has higher accuracy than state-of-the-art methods.