 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
An Efficient Method of Detection and Recognition in Remote Sensing Image Based on multi-angle Region of Interests
Jul 22, 2019
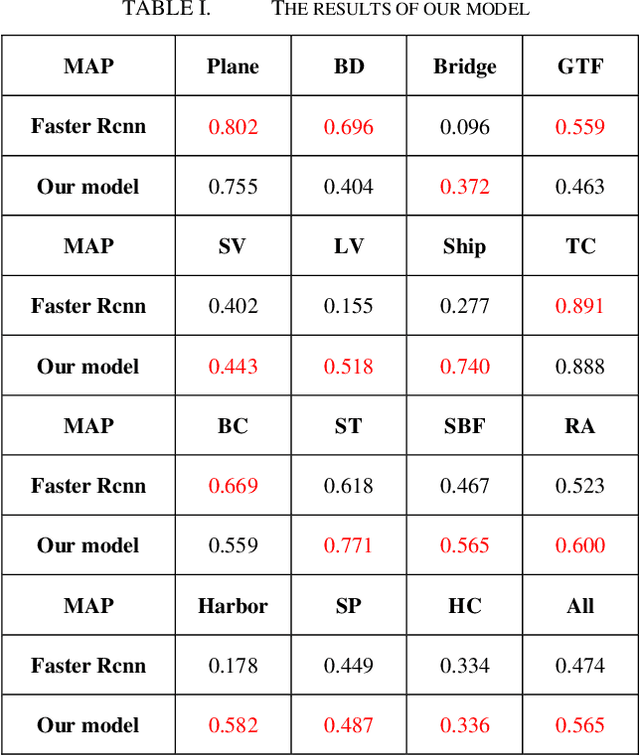
Presently, deep learning technology has been widely used in the field of image recognition. However, it mainly aims at the recognition and detection of ordinary pictures and common scenes. As special images, remote sensing images have different shooting angles and shooting methods compared with ordinary ones, which makes remote sensing images play an irreplaceable role in some areas. In this paper, based on a deep convolution neural network for providing multi-level information of images and combines RPN (Region Proposal Network) for generating multi-angle ROIs (Region of Interest), a new model for object detection and recognition in remote sensing images is proposed. In the experiment, it achieves better results than traditional ways, which demonstrate that the model proposed here would have a huge potential application in remote sensing image recognition.
Image denoising via group sparsity residual constraint
Mar 03, 2017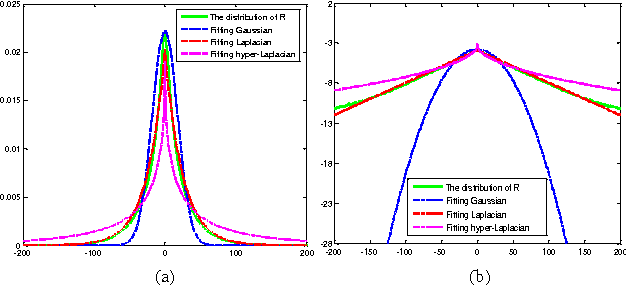
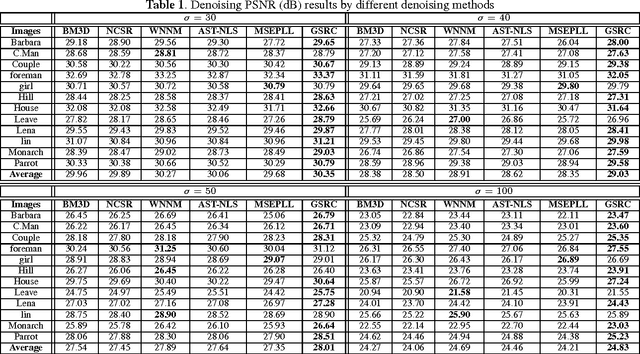


Group sparsity has shown great potential in various low-level vision tasks (e.g, image denoising, deblurring and inpainting). In this paper, we propose a new prior model for image denoising via group sparsity residual constraint (GSRC). To enhance the performance of group sparse-based image denoising, the concept of group sparsity residual is proposed, and thus, the problem of image denoising is translated into one that reduces the group sparsity residual. To reduce the residual, we first obtain some good estimation of the group sparse coefficients of the original image by the first-pass estimation of noisy image, and then centralize the group sparse coefficients of noisy image to the estimation. Experimental results have demonstrated that the proposed method not only outperforms many state-of-the-art denoising methods such as BM3D and WNNM, but results in a faster speed.
Classification of Hematoma: Joint Learning of Semantic Segmentation and Classification
Mar 31, 2021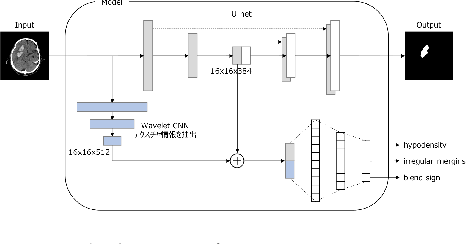
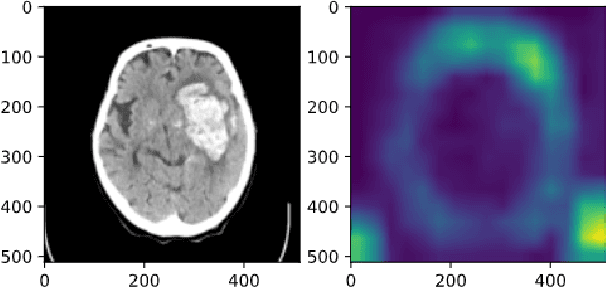
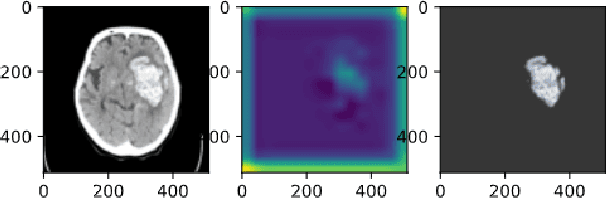
Cerebral hematoma grows rapidly in 6-24 hours and misprediction of the growth can be fatal if it is not operated by a brain surgeon. There are two types of cerebral hematomas: one that grows rapidly and the other that does not grow rapidly. We are developing the technique of artificial intelligence to determine whether the CT image includes the cerebral hematoma which leads to the rapid growth. This problem has various difficulties: the few positive cases in this classification problem of cerebral hematoma and the targeted hematoma has deformable object. Other difficulties include the imbalance classification, the covariate shift, the small data, and the spurious correlation problems. It is difficult with the plain CNN classification such as VGG. This paper proposes the joint learning of semantic segmentation and classification and evaluate the performance of this.
FusiformNet: Extracting Discriminative Facial Features on Different Levels
Nov 06, 2020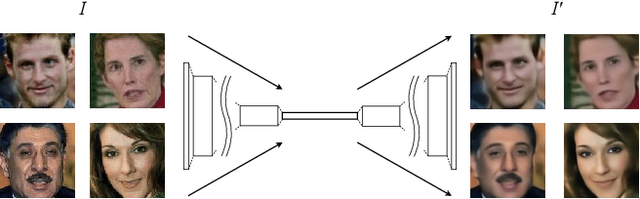
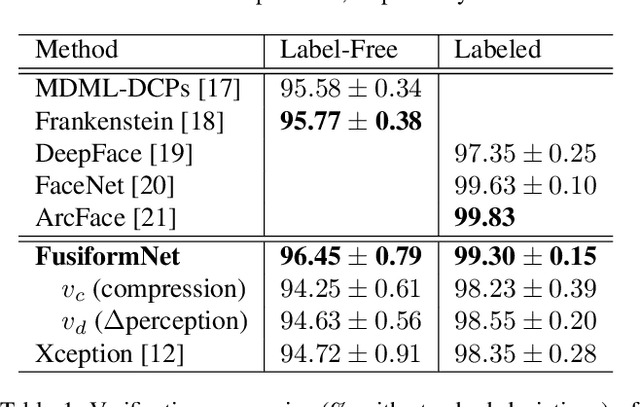
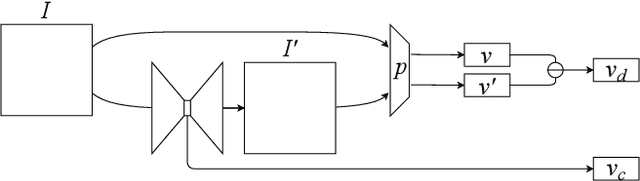
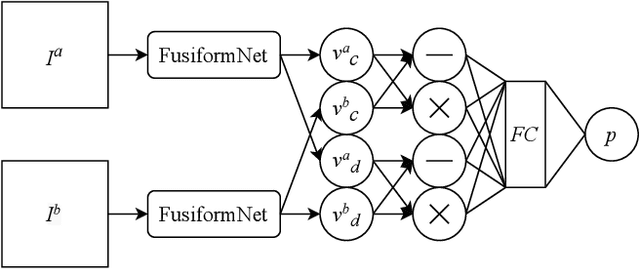
Over the last several years, research on facial recognition based on Deep Neural Network has evolved with approaches like task-specific loss functions, image normalization and augmentation, network architectures, etc. However, there have been few approaches with attention to how human faces differ from person to person. Premising that inter-personal differences are found both generally and locally on the human face, I propose FusiformNet, a novel framework for feature extraction that leverages the nature of discriminative facial features. Tested on Image-Unrestricted setting of Labeled Face in the Wild benchmark, this method achieved a state-of-the-art accuracy of 96.67% without labeled outside data, image augmentation, normalization, or special loss functions. Likewise, the method also performed on par with previous state-of-the-arts when pre-trained on CASIA-WebFace dataset. Considering its ability to extract both general and local facial features, the utility of FusiformNet may not be limited to facial recognition but also extend to other DNN-based tasks.
Style transfer-based image synthesis as an efficient regularization technique in deep learning
May 27, 2019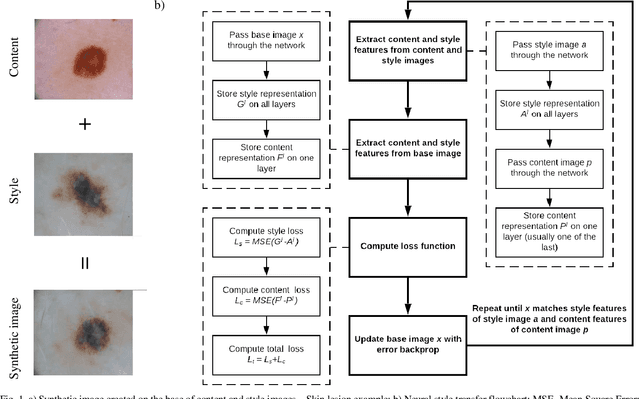
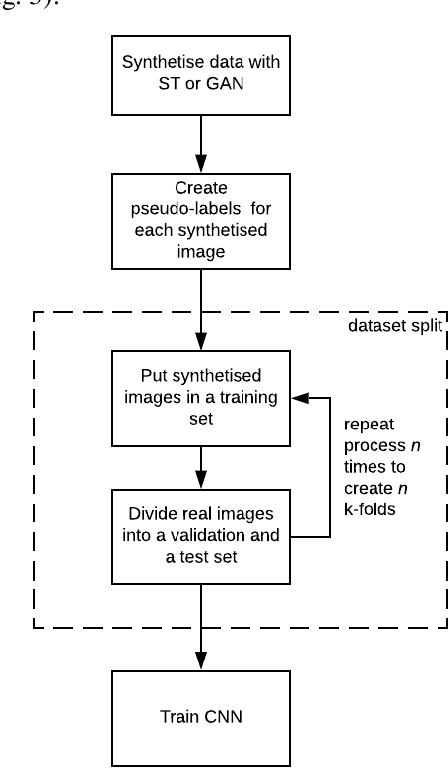
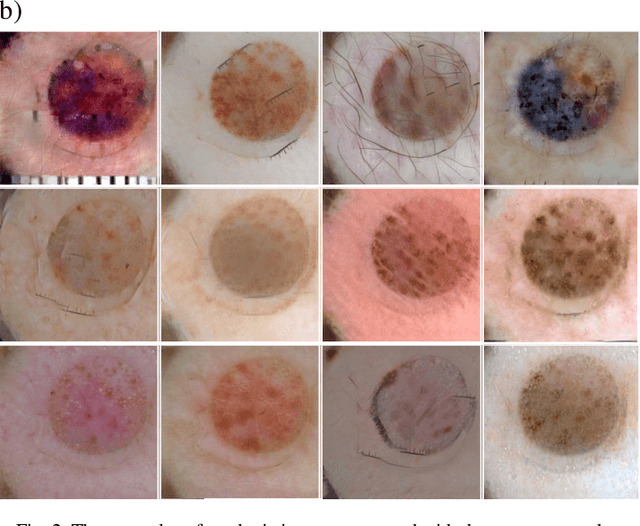
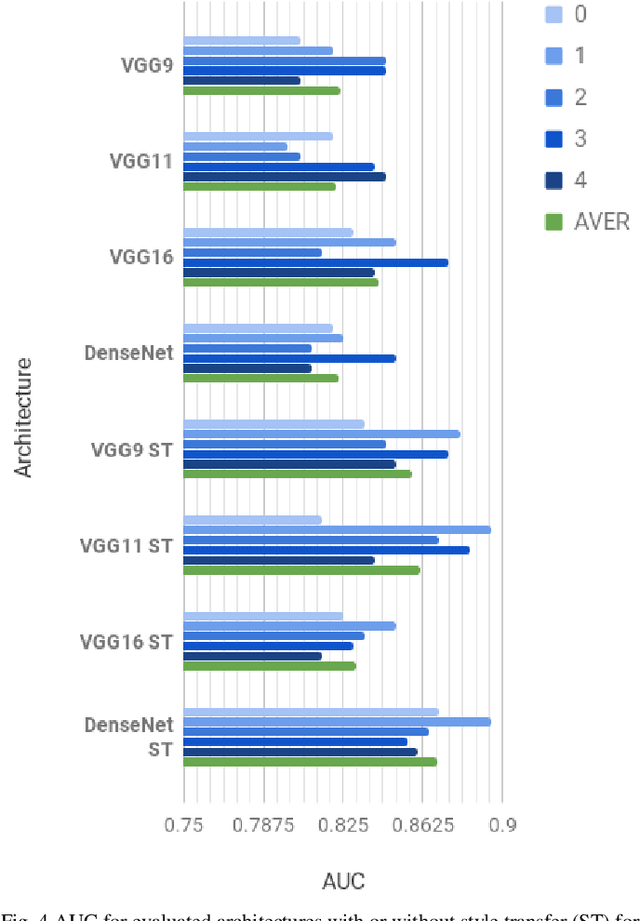
These days deep learning is the fastest-growing area in the field of Machine Learning. Convolutional Neural Networks are currently the main tool used for image analysis and classification purposes. Although great achievements and perspectives, deep neural networks and accompanying learning algorithms have some relevant challenges to tackle. In this paper, we have focused on the most frequently mentioned problem in the field of machine learning, that is relatively poor generalization abilities. Partial remedies for this are regularization techniques e.g. dropout, batch normalization, weight decay, transfer learning, early stopping and data augmentation. In this paper, we have focused on data augmentation. We propose to use a method based on a neural style transfer, which allows generating new unlabeled images of a high perceptual quality that combine the content of a base image with the appearance of another one. In a proposed approach, the newly created images are described with pseudo-labels, and then used as a training dataset. Real, labeled images are divided into the validation and test set. We validated the proposed method on a challenging skin lesion classification case study. Four representative neural architectures are examined. Obtained results show the strong potential of the proposed approach.
Learning to synthesize: splitting and recombining low and high spatial frequencies for image recovery
Nov 19, 2018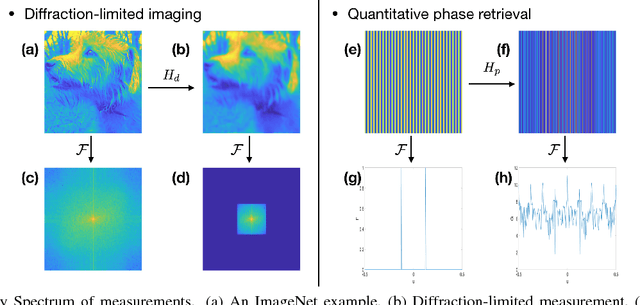

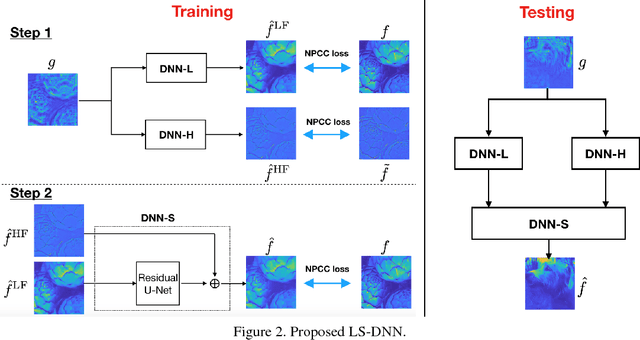

Deep Neural Network (DNN)-based image reconstruction, despite many successes, often exhibits uneven fidelity between high and low spatial frequency bands. In this paper we propose the Learning Synthesis by DNN (LS-DNN) approach where two DNNs process the low and high spatial frequencies, respectively, and, improving over [30], the two DNNs are trained separately and a third DNN combines them into an image with high fidelity at all bands. We demonstrate LS-DNN in two canonical inverse problems: super-resolution (SR) in diffraction-limited imaging (DLI), and quantitative phase retrieval (QPR). Our results also show comparable or improved performance over perceptual-loss based SR [21], and can be generalized to a wider range of image recovery problems.
Learning Discriminative Features using Multi-label Dual Space
Feb 25, 2021

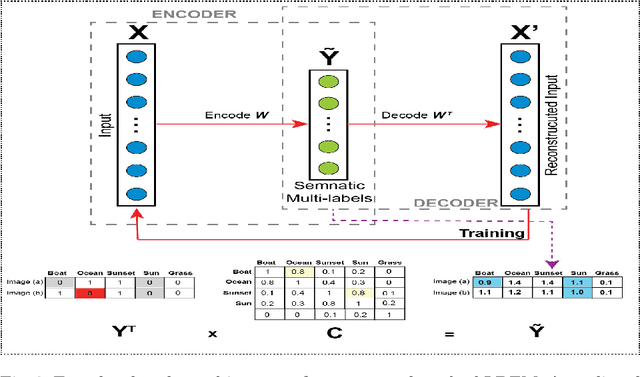
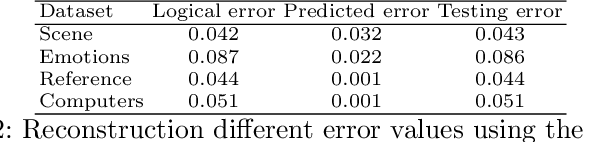
Multi-label learning handles instances associated with multiple class labels. The original label space is a logical matrix with entries from the Boolean domain $\in \left \{ 0,1 \right \}$. Logical labels are not able to show the relative importance of each semantic label to the instances. The vast majority of existing methods map the input features to the label space using linear projections with taking into consideration the label dependencies using logical label matrix. However, the discriminative features are learned using one-way projection from the feature representation of an instance into a logical label space. Given that there is no manifold in the learning space of logical labels, which limits the potential of learned models. In this work, inspired from a real-world example in image annotation to reconstruct an image from the label importance and feature weights. We propose a novel method in multi-label learning to learn the projection matrix from the feature space to semantic label space and projects it back to the original feature space using encoder-decoder deep learning architecture. The key intuition which guides our method is that the discriminative features are identified due to map the features back and forth using two linear projections. To the best of our knowledge, this is one of the first attempts to study the ability to reconstruct the original features from the label manifold in multi-label learning. We show that the learned projection matrix identifies a subset of discriminative features across multiple semantic labels. Extensive experiments on real-world datasets show the superiority of the proposed method.
* 12 pages
Secure 3D medical Imaging
Oct 06, 2020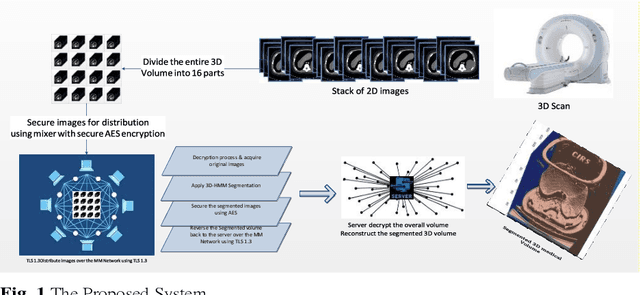
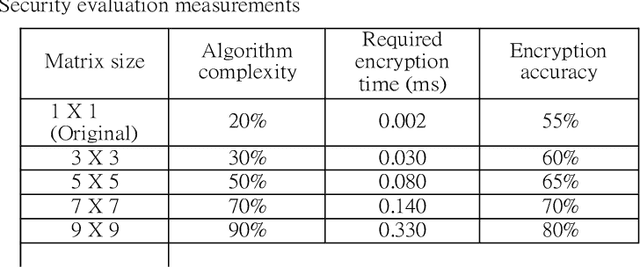

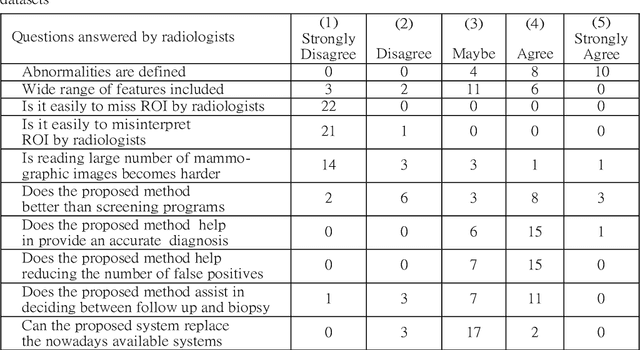
Image segmentation has proved its importance and plays an important role in various domains such as health systems and satellite-oriented military applications. In this context, accuracy, image quality, and execution time deem to be the major issues to always consider. Although many techniques have been applied, and their experimental results have shown appealing achievements for 2D images in real-time environments, however, there is a lack of works about 3D image segmentation despite its importance in improving segmentation accuracy. Specifically, HMM was used in this domain. However, it suffers from the time complexity, which was updated using different accelerators. As it is important to have efficient 3D image segmentation, we propose in this paper a novel system for partitioning the 3D segmentation process across several distributed machines. The concepts behind distributed multi-media network segmentation were employed to accelerate the segmentation computational time of training Hidden Markov Model (HMMs). Furthermore, a secure transmission has been considered in this distributed environment and various bidirectional multimedia security algorithms have been applied. The contribution of this work lies in providing an efficient and secure algorithm for 3D image segmentation. Through a number of extensive experiments, it was proved that our proposed system is of comparable efficiency to the state of art methods in terms of segmentation accuracy, security and execution time.
Joint Motion Estimation and Segmentation from Undersampled Cardiac MR Image
Aug 20, 2019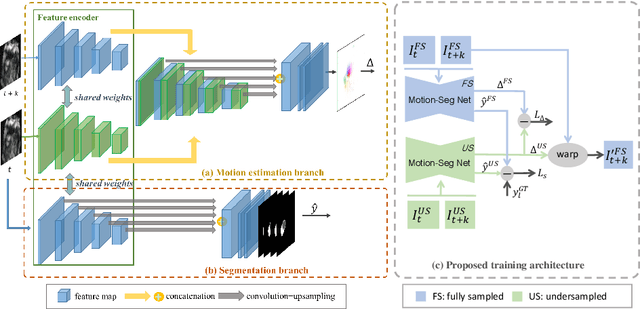
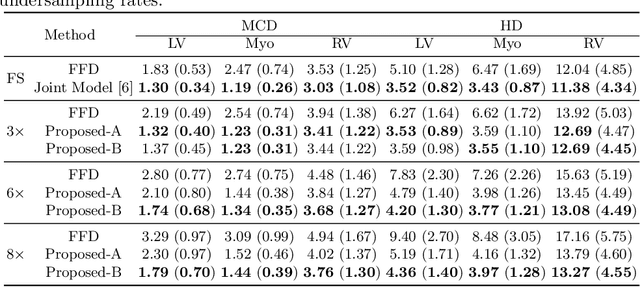
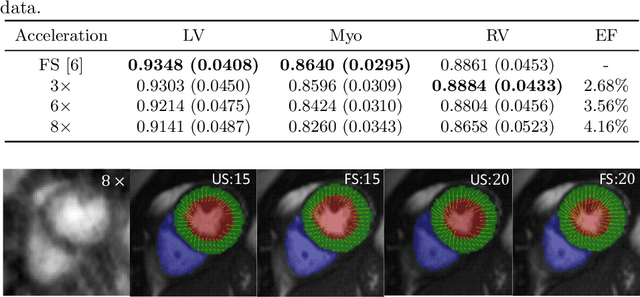
Accelerating the acquisition of magnetic resonance imaging (MRI) is a challenging problem, and many works have been proposed to reconstruct images from undersampled k-space data. However, if the main purpose is to extract certain quantitative measures from the images, perfect reconstructions may not always be necessary as long as the images enable the means of extracting the clinically relevant measures. In this paper, we work on jointly predicting cardiac motion estimation and segmentation directly from undersampled data, which are two important steps in quantitatively assessing cardiac function and diagnosing cardiovascular diseases. In particular, a unified model consisting of both motion estimation branch and segmentation branch is learned by optimising the two tasks simultaneously. Additional corresponding fully-sampled images are incorporated into the network as a parallel sub-network to enhance and guide the learning during the training process. Experimental results using cardiac MR images from 220 subjects show that the proposed model is robust to undersampled data and is capable of predicting results that are close to that from fully-sampled ones, while bypassing the usual image reconstruction stage.
Multi-Dataset Benchmarks for Masked Identification using Contrastive Representation Learning
Jun 10, 2021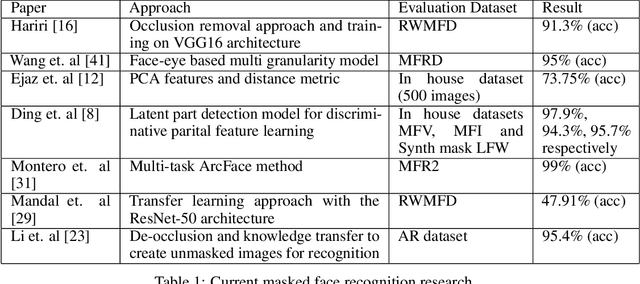

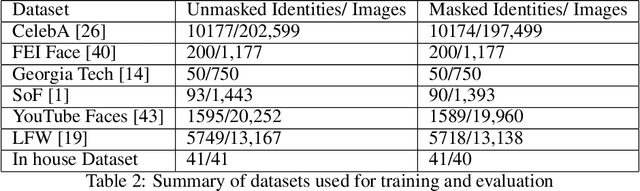

The COVID-19 pandemic has drastically changed accepted norms globally. Within the past year, masks have been used as a public health response to limit the spread of the virus. This sudden change has rendered many face recognition based access control, authentication and surveillance systems ineffective. Official documents such as passports, driving license and national identity cards are enrolled with fully uncovered face images. However, in the current global situation, face matching systems should be able to match these reference images with masked face images. As an example, in an airport or security checkpoint it is safer to match the unmasked image of the identifying document to the masked person rather than asking them to remove the mask. We find that current facial recognition techniques are not robust to this form of occlusion. To address this unique requirement presented due to the current circumstance, we propose a set of re-purposed datasets and a benchmark for researchers to use. We also propose a contrastive visual representation learning based pre-training workflow which is specialized to masked vs unmasked face matching. We ensure that our method learns robust features to differentiate people across varying data collection scenarios. We achieve this by training over many different datasets and validating our result by testing on various holdout datasets. The specialized weights trained by our method outperform standard face recognition features for masked to unmasked face matching. We believe the provided synthetic mask generating code, our novel training approach and the trained weights from the masked face models will help in adopting existing face recognition systems to operate in the current global environment. We open-source all contributions for broader use by the research community.