 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Match What Matters: Generative Implicit Feature Replay for Continual Learning
Jun 09, 2021

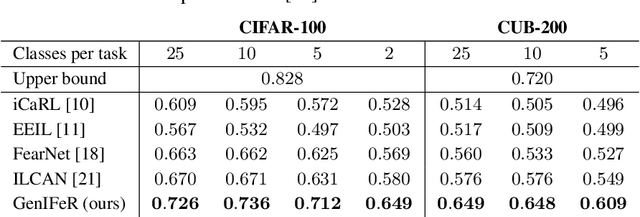
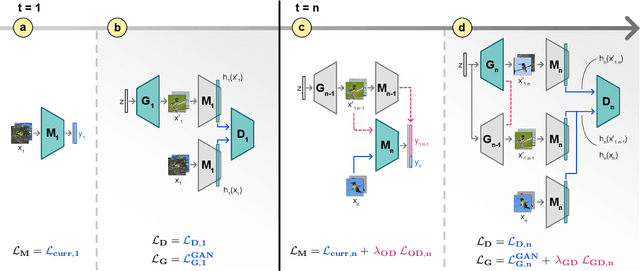

Neural networks are prone to catastrophic forgetting when trained incrementally on different tasks. In order to prevent forgetting, most existing methods retain a small subset of previously seen samples, which in turn can be used for joint training with new tasks. While this is indeed effective, it may not always be possible to store such samples, e.g., due to data protection regulations. In these cases, one can instead employ generative models to create artificial samples or features representing memories from previous tasks. Following a similar direction, we propose GenIFeR (Generative Implicit Feature Replay) for class-incremental learning. The main idea is to train a generative adversarial network (GAN) to generate images that contain realistic features. While the generator creates images at full resolution, the discriminator only sees the corresponding features extracted by the continually trained classifier. Since the classifier compresses raw images into features that are actually relevant for classification, the GAN can match this target distribution more accurately. On the other hand, allowing the generator to create full resolution images has several benefits: In contrast to previous approaches, the feature extractor of the classifier does not have to be frozen. In addition, we can employ augmentations on generated images, which not only boosts classification performance, but also mitigates discriminator overfitting during GAN training. We empirically show that GenIFeR is superior to both conventional generative image and feature replay. In particular, we significantly outperform the state-of-the-art in generative replay for various settings on the CIFAR-100 and CUB-200 datasets.
Dual Contradistinctive Generative Autoencoder
Nov 19, 2020
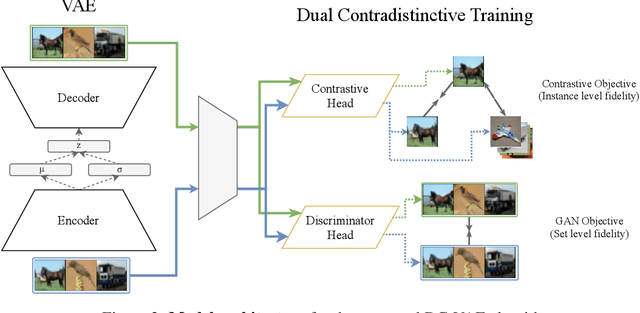
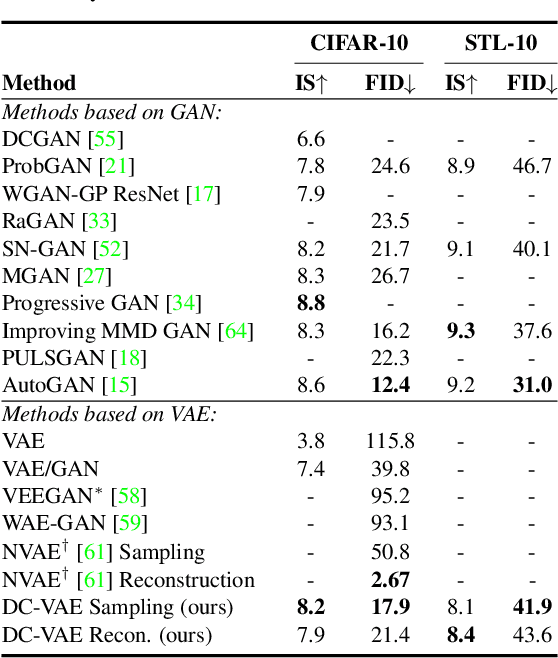

We present a new generative autoencoder model with dual contradistinctive losses to improve generative autoencoder that performs simultaneous inference (reconstruction) and synthesis (sampling). Our model, named dual contradistinctive generative autoencoder (DC-VAE), integrates an instance-level discriminative loss (maintaining the instance-level fidelity for the reconstruction/synthesis) with a set-level adversarial loss (encouraging the set-level fidelity for there construction/synthesis), both being contradistinctive. Extensive experimental results by DC-VAE across different resolutions including 32x32, 64x64, 128x128, and 512x512 are reported. The two contradistinctive losses in VAE work harmoniously in DC-VAE leading to a significant qualitative and quantitative performance enhancement over the baseline VAEs without architectural changes. State-of-the-art or competitive results among generative autoencoders for image reconstruction, image synthesis, image interpolation, and representation learning are observed. DC-VAE is a general-purpose VAE model, applicable to a wide variety of downstream tasks in computer vision and machine learning.
We Can Always Catch You: Detecting Adversarial Patched Objects WITH or WITHOUT Signature
Jun 09, 2021
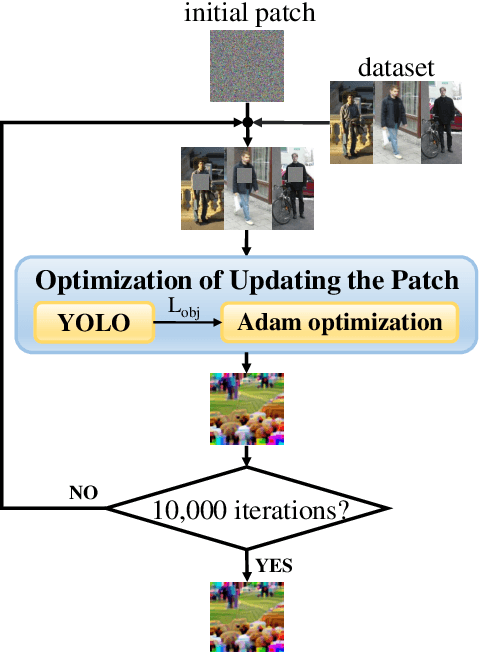
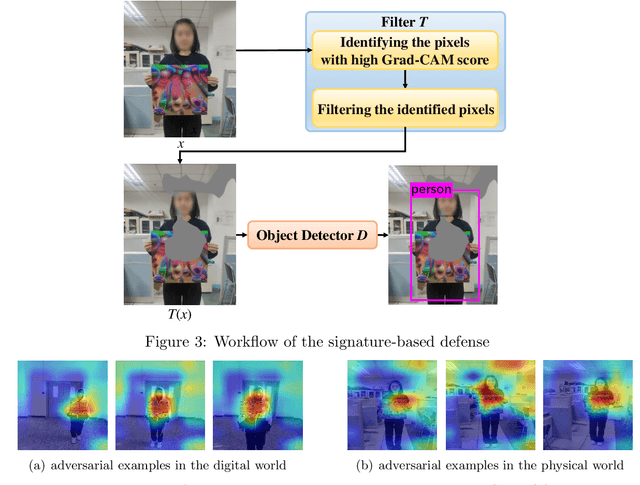

Recently, the object detection based on deep learning has proven to be vulnerable to adversarial patch attacks. The attackers holding a specially crafted patch can hide themselves from the state-of-the-art person detectors, e.g., YOLO, even in the physical world. This kind of attack can bring serious security threats, such as escaping from surveillance cameras. In this paper, we deeply explore the detection problems about the adversarial patch attacks to the object detection. First, we identify a leverageable signature of existing adversarial patches from the point of the visualization explanation. A fast signature-based defense method is proposed and demonstrated to be effective. Second, we design an improved patch generation algorithm to reveal the risk that the signature-based way may be bypassed by the techniques emerging in the future. The newly generated adversarial patches can successfully evade the proposed signature-based defense. Finally, we present a novel signature-independent detection method based on the internal content semantics consistency rather than any attack-specific prior knowledge. The fundamental intuition is that the adversarial object can appear locally but disappear globally in an input image. The experiments demonstrate that the signature-independent method can effectively detect the existing and improved attacks. It has also proven to be a general method by detecting unforeseen and even other types of attacks without any attack-specific prior knowledge. The two proposed detection methods can be adopted in different scenarios, and we believe that combining them can offer a comprehensive protection.
Hierarchical ResNeXt Models for Breast Cancer Histology Image Classification
Oct 21, 2018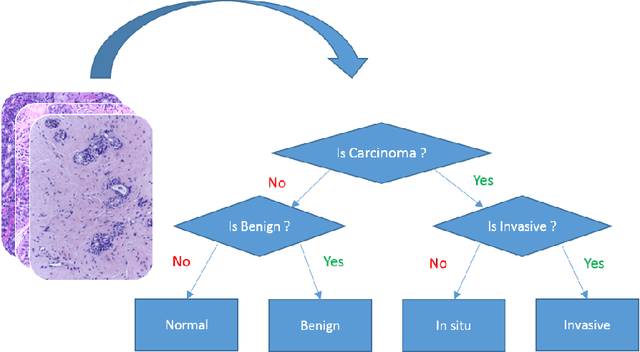
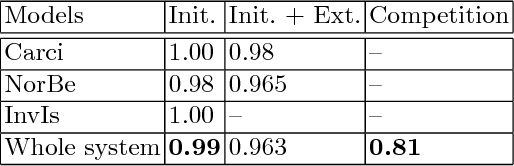
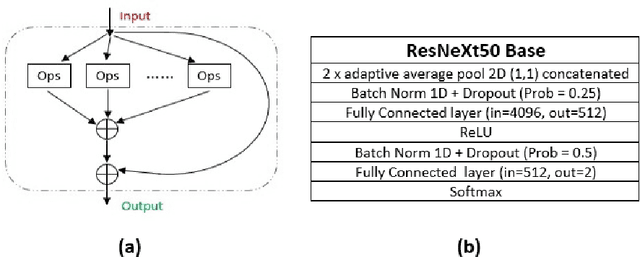
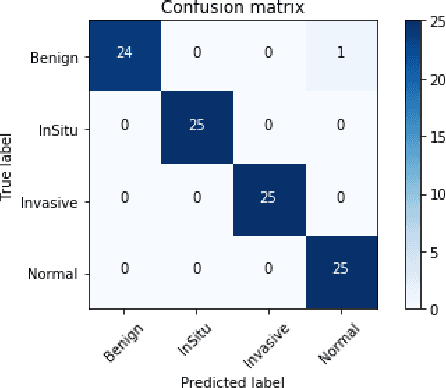
Microscopic histology image analysis is a cornerstone in early detection of breast cancer. However these images are very large and manual analysis is error prone and very time consuming. Thus automating this process is in high demand. We proposed a hierarchical system of convolutional neural networks (CNN) that classifies automatically patches of these images into four pathologies: normal, benign, in situ carcinoma and invasive carcinoma. We evaluated our system on the BACH challenge dataset of image-wise classification and a small dataset that we used to extend it. Using a train/test split of 75%/25%, we achieved an accuracy rate of 0.99 on the test split for the BACH dataset and 0.96 on that of the extension. On the test of the BACH challenge, we've reached an accuracy of 0.81 which rank us to the 8th out of 51 teams.
Phrase-based Image Captioning with Hierarchical LSTM Model
Nov 11, 2017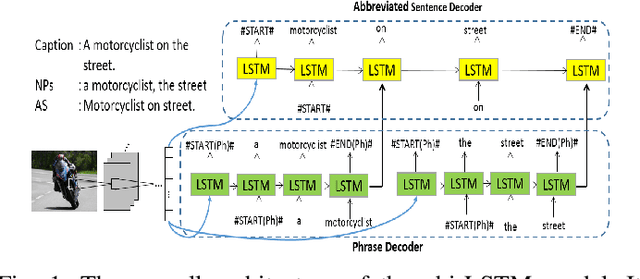



Automatic generation of caption to describe the content of an image has been gaining a lot of research interests recently, where most of the existing works treat the image caption as pure sequential data. Natural language, however possess a temporal hierarchy structure, with complex dependencies between each subsequence. In this paper, we propose a phrase-based hierarchical Long Short-Term Memory (phi-LSTM) model to generate image description. In contrast to the conventional solutions that generate caption in a pure sequential manner, our proposed model decodes image caption from phrase to sentence. It consists of a phrase decoder at the bottom hierarchy to decode noun phrases of variable length, and an abbreviated sentence decoder at the upper hierarchy to decode an abbreviated form of the image description. A complete image caption is formed by combining the generated phrases with sentence during the inference stage. Empirically, our proposed model shows a better or competitive result on the Flickr8k, Flickr30k and MS-COCO datasets in comparison to the state-of-the art models. We also show that our proposed model is able to generate more novel captions (not seen in the training data) which are richer in word contents in all these three datasets.
DumbleDR: Predicting User Preferences of Dimensionality Reduction Projection Quality
May 19, 2021
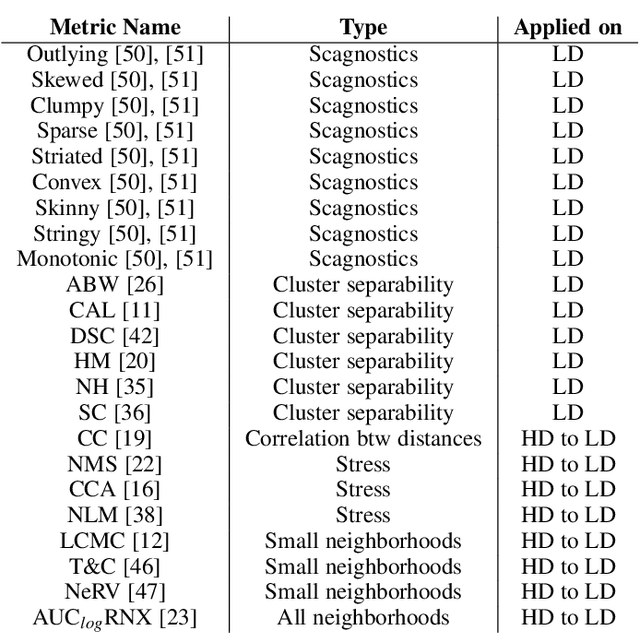
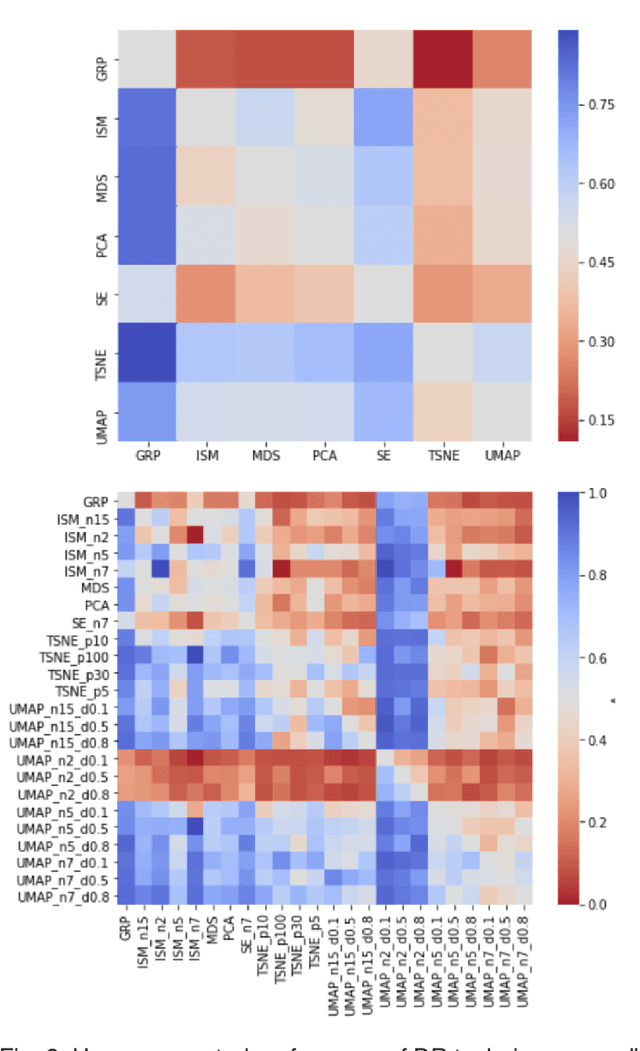
A plethora of dimensionality reduction techniques have emerged over the past decades, leaving researchers and analysts with a wide variety of choices for reducing their data, all the more so given some techniques come with additional parametrization (e.g. t-SNE, UMAP, etc.). Recent studies are showing that people often use dimensionality reduction as a black-box regardless of the specific properties the method itself preserves. Hence, evaluating and comparing 2D projections is usually qualitatively decided, by setting projections side-by-side and letting human judgment decide which projection is the best. In this work, we propose a quantitative way of evaluating projections, that nonetheless places human perception at the center. We run a comparative study, where we ask people to select 'good' and 'misleading' views between scatterplots of low-level projections of image datasets, simulating the way people usually select projections. We use the study data as labels for a set of quality metrics whose purpose is to discover and quantify what exactly people are looking for when deciding between projections. With this proxy for human judgments, we use it to rank projections on new datasets, explain why they are relevant, and quantify the degree of subjectivity in projections selected.
Robust Black-box Watermarking for Deep NeuralNetwork using Inverse Document Frequency
Mar 09, 2021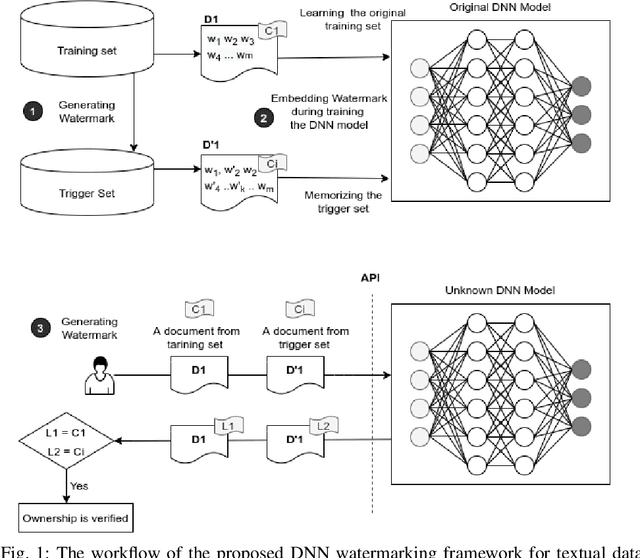
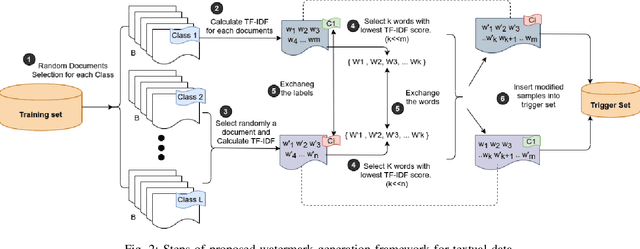

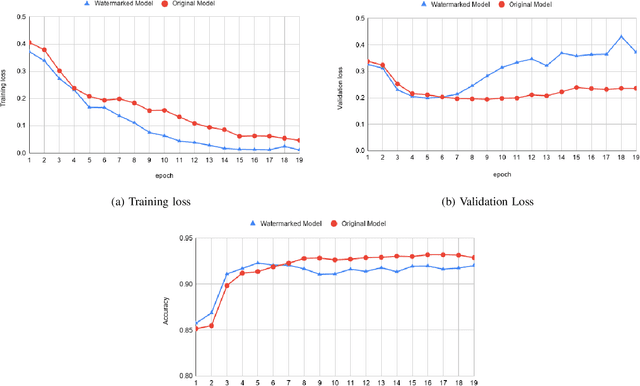
Deep learning techniques are one of the most significant elements of any Artificial Intelligence (AI) services. Recently, these Machine Learning (ML) methods, such as Deep Neural Networks (DNNs), presented exceptional achievement in implementing human-level capabilities for various predicaments, such as Natural Processing Language (NLP), voice recognition, and image processing, etc. Training these models are expensive in terms of computational power and the existence of enough labelled data. Thus, ML-based models such as DNNs establish genuine business value and intellectual property (IP) for their owners. Therefore the trained models need to be protected from any adversary attacks such as illegal redistribution, reproducing, and derivation. Watermarking can be considered as an effective technique for securing a DNN model. However, so far, most of the watermarking algorithm focuses on watermarking the DNN by adding noise to an image. To this end, we propose a framework for watermarking a DNN model designed for a textual domain. The watermark generation scheme provides a secure watermarking method by combining Term Frequency (TF) and Inverse Document Frequency (IDF) of a particular word. The proposed embedding procedure takes place in the model's training time, making the watermark verification stage straightforward by sending the watermarked document to the trained model. The experimental results show that watermarked models have the same accuracy as the original ones. The proposed framework accurately verifies the ownership of all surrogate models without impairing the performance. The proposed algorithm is robust against well-known attacks such as parameter pruning and brute force attack.
More than meets the eye: Self-supervised depth reconstruction from brain activity
Jun 09, 2021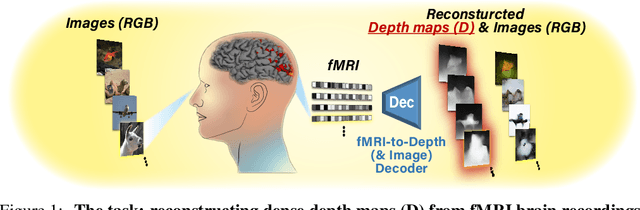
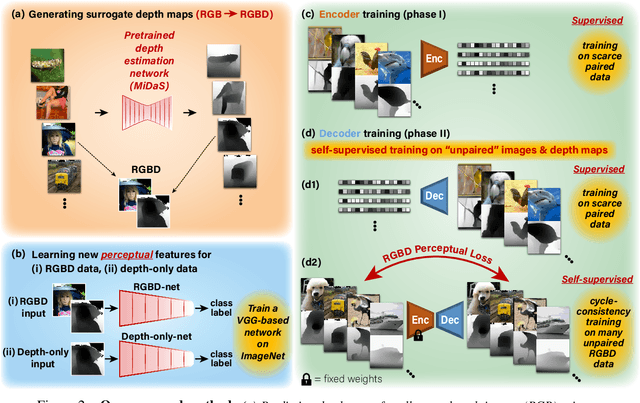

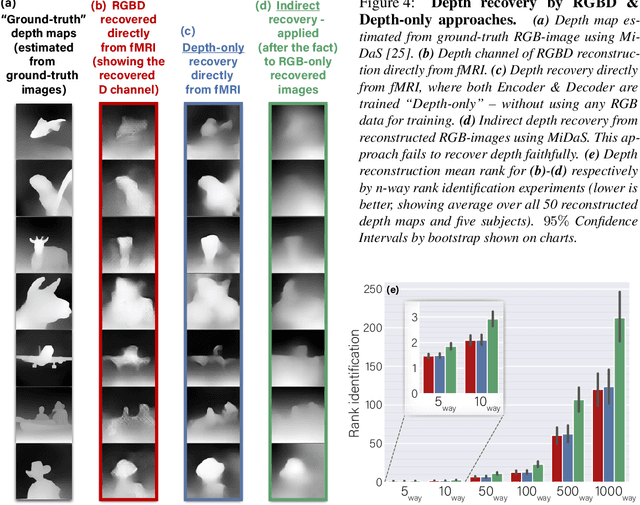
In the past few years, significant advancements were made in reconstruction of observed natural images from fMRI brain recordings using deep-learning tools. Here, for the first time, we show that dense 3D depth maps of observed 2D natural images can also be recovered directly from fMRI brain recordings. We use an off-the-shelf method to estimate the unknown depth maps of natural images. This is applied to both: (i) the small number of images presented to subjects in an fMRI scanner (images for which we have fMRI recordings - referred to as "paired" data), and (ii) a very large number of natural images with no fMRI recordings ("unpaired data"). The estimated depth maps are then used as an auxiliary reconstruction criterion to train for depth reconstruction directly from fMRI. We propose two main approaches: Depth-only recovery and joint image-depth RGBD recovery. Because the number of available "paired" training data (images with fMRI) is small, we enrich the training data via self-supervised cycle-consistent training on many "unpaired" data (natural images & depth maps without fMRI). This is achieved using our newly defined and trained Depth-based Perceptual Similarity metric as a reconstruction criterion. We show that predicting the depth map directly from fMRI outperforms its indirect sequential recovery from the reconstructed images. We further show that activations from early cortical visual areas dominate our depth reconstruction results, and propose means to characterize fMRI voxels by their degree of depth-information tuning. This work adds an important layer of decoded information, extending the current envelope of visual brain decoding capabilities.
Learning Converged Propagations with Deep Prior Ensemble for Image Enhancement
Oct 09, 2018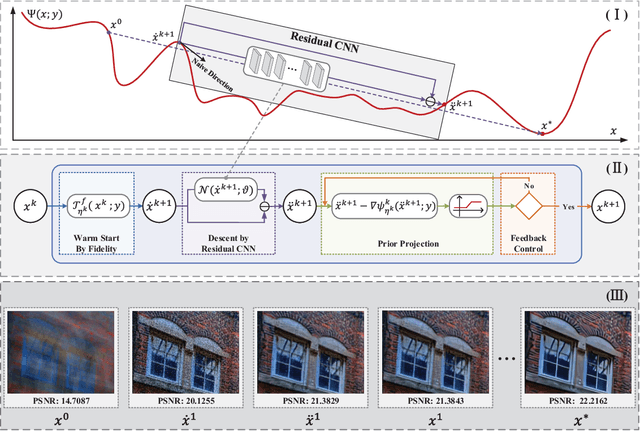



Enhancing visual qualities of images plays very important roles in various vision and learning applications. In the past few years, both knowledge-driven maximum a posterior (MAP) with prior modelings and fully data-dependent convolutional neural network (CNN) techniques have been investigated to address specific enhancement tasks. In this paper, by exploiting the advantages of these two types of mechanisms within a complementary propagation perspective, we propose a unified framework, named deep prior ensemble (DPE), for solving various image enhancement tasks. Specifically, we first establish the basic propagation scheme based on the fundamental image modeling cues and then introduce residual CNNs to help predicting the propagation direction at each stage. By designing prior projections to perform feedback control, we theoretically prove that even with experience-inspired CNNs, DPE is definitely converged and the output will always satisfy our fundamental task constraints. The main advantage against conventional optimization-based MAP approaches is that our descent directions are learned from collected training data, thus are much more robust to unwanted local minimums. While, compared with existing CNN type networks, which are often designed in heuristic manners without theoretical guarantees, DPE is able to gain advantages from rich task cues investigated on the bases of domain knowledges. Therefore, DPE actually provides a generic ensemble methodology to integrate both knowledge and data-based cues for different image enhancement tasks. More importantly, our theoretical investigations verify that the feedforward propagations of DPE are properly controlled toward our desired solution. Experimental results demonstrate that the proposed DPE outperforms state-of-the-arts on a variety of image enhancement tasks in terms of both quantitative measure and visual perception quality.
Polynomial magic! Hermite polynomials for private data generation
Jun 09, 2021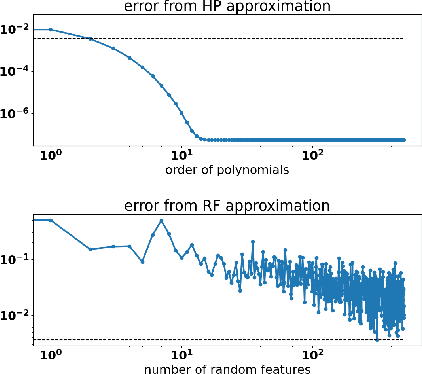

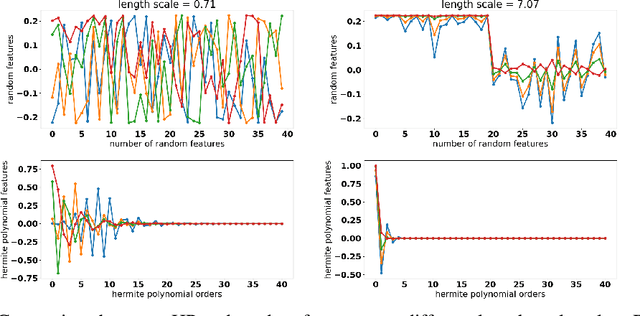
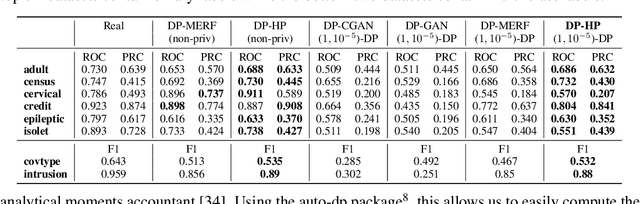
Kernel mean embedding is a useful tool to compare probability measures. Despite its usefulness, kernel mean embedding considers infinite-dimensional features, which are challenging to handle in the context of differentially private data generation. A recent work proposes to approximate the kernel mean embedding of data distribution using finite-dimensional random features, where the sensitivity of the features becomes analytically tractable. More importantly, this approach significantly reduces the privacy cost, compared to other known privatization methods (e.g., DP-SGD), as the approximate kernel mean embedding of the data distribution is privatized only once and can then be repeatedly used during training of a generator without incurring any further privacy cost. However, the required number of random features is excessively high, often ten thousand to a hundred thousand, which worsens the sensitivity of the approximate kernel mean embedding. To improve the sensitivity, we propose to replace random features with Hermite polynomial features. Unlike the random features, the Hermite polynomial features are ordered, where the features at the low orders contain more information on the distribution than those at the high orders. Hence, a relatively low order of Hermite polynomial features can more accurately approximate the mean embedding of the data distribution compared to a significantly higher number of random features. As a result, using the Hermite polynomial features, we significantly improve the privacy-accuracy trade-off, reflected in the high quality and diversity of the generated data, when tested on several heterogeneous tabular datasets, as well as several image benchmark datasets.