 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Detection of Transformer Winding Axial Displacement by Kirchhoff and Delay and sum Radar Imaging Algorithms
Feb 21, 2021
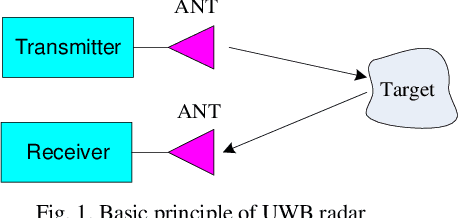
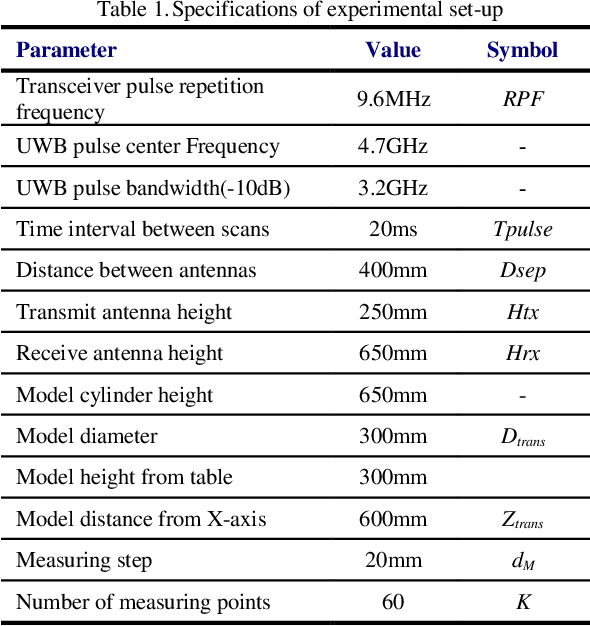
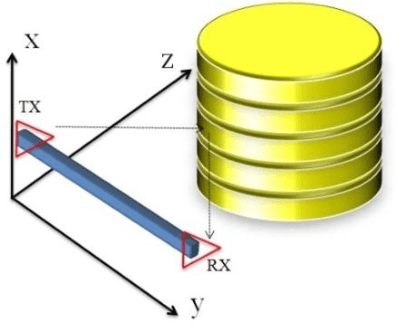
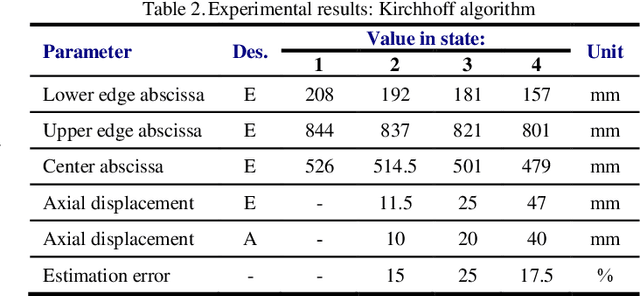
In this paper, a novel method for in detail detection of the winding axial displacement in power transformers based on UWB imaging is presented. In this method, the radar imaging process is implemented on the power transformer by using an ultra-wide band (UWB) transceiver. The result is a 2-D image of the transformer winding, which is analyzed to determine the occurrence as well as the magnitude of the winding axial displacement. The method is implemented on a transformer model. The experimental results illustrate the effectiveness of the proposed method.
HNMTP Conv: Optimize Convolution Algorithm for Single-Image Convolution Neural Network Inference on Mobile GPUs
Sep 06, 2019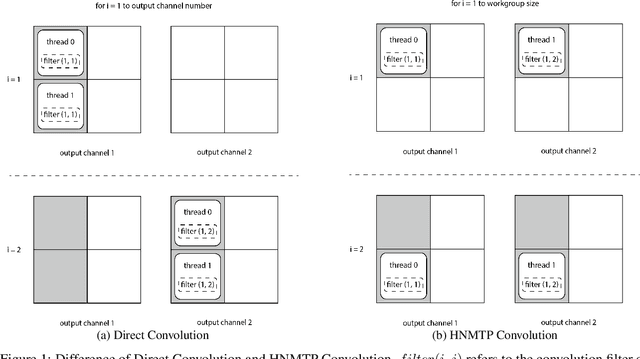


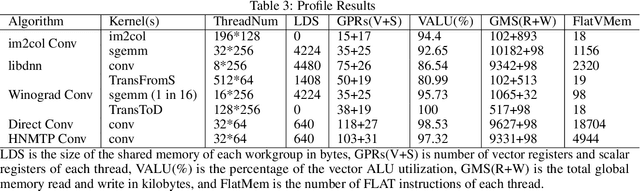
Convolution neural networks are widely used for mobile applications. However, GPU convolution algorithms are designed for mini-batch neural network training, the single-image convolution neural network inference algorithm on mobile GPUs is not well-studied. After discussing the usage difference and examining the existing convolution algorithms, we proposed the HNTMP convolution algorithm. The HNTMP convolution algorithm achieves $14.6 \times$ speedup than the most popular \textit{im2col} convolution algorithm, and $2.1 \times$ speedup than the fastest existing convolution algorithm (direct convolution) as far as we know.
Disc-aware Ensemble Network for Glaucoma Screening from Fundus Image
May 19, 2018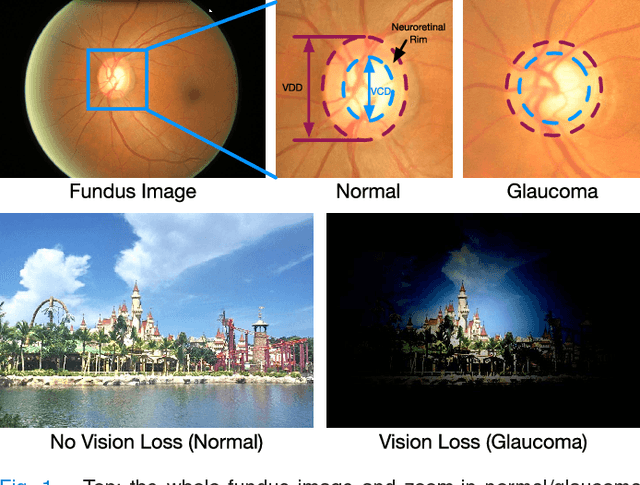
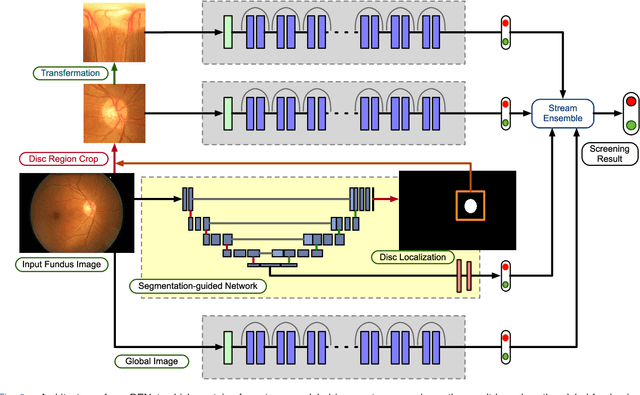
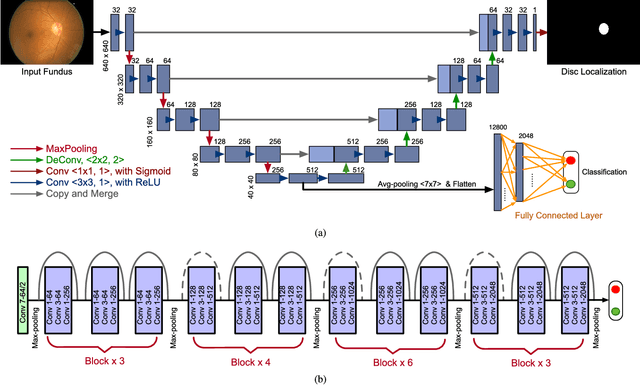
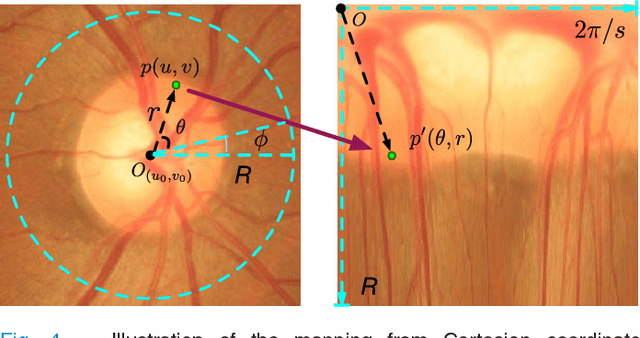
Glaucoma is a chronic eye disease that leads to irreversible vision loss. Most of the existing automatic screening methods firstly segment the main structure, and subsequently calculate the clinical measurement for detection and screening of glaucoma. However, these measurement-based methods rely heavily on the segmentation accuracy, and ignore various visual features. In this paper, we introduce a deep learning technique to gain additional image-relevant information, and screen glaucoma from the fundus image directly. Specifically, a novel Disc-aware Ensemble Network (DENet) for automatic glaucoma screening is proposed, which integrates the deep hierarchical context of the global fundus image and the local optic disc region. Four deep streams on different levels and modules are respectively considered as global image stream, segmentation-guided network, local disc region stream, and disc polar transformation stream. Finally, the output probabilities of different streams are fused as the final screening result. The experiments on two glaucoma datasets (SCES and new SINDI datasets) show our method outperforms other state-of-the-art algorithms.
Infrared and Visible Image Fusion using a Deep Learning Framework
May 19, 2018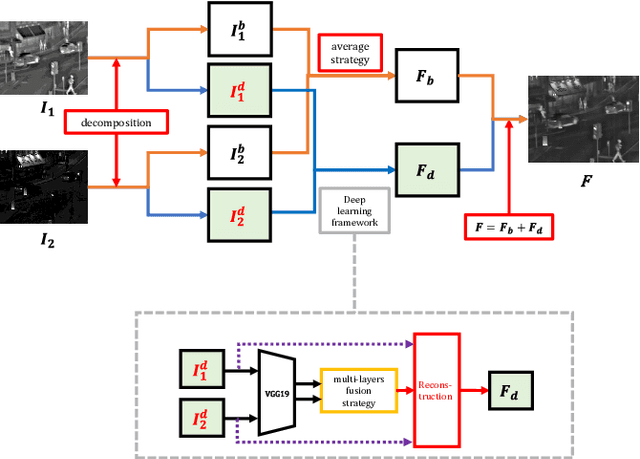
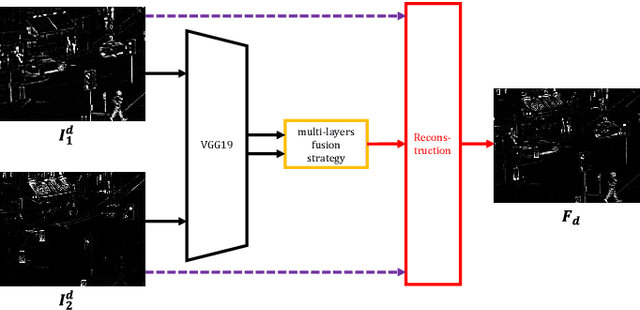
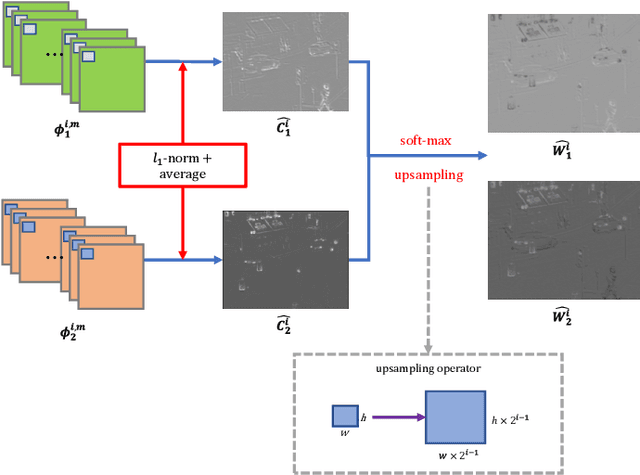

In recent years, deep learning has become a very active research tool which is used in many image processing fields. In this paper, we propose an effective image fusion method using a deep learning framework to generate a single image which contains all the features from infrared and visible images. First, the source images are decomposed into base parts and detail content. Then the base parts are fused by weighted-averaging. For the detail content, we use a deep learning network to extract multi-layer features. Using these features, we use l_1-norm and weighted-average strategy to generate several candidates of the fused detail content. Once we get these candidates, the max selection strategy is used to get final fused detail content. Finally, the fused image will be reconstructed by combining the fused base part and detail content. The experimental results demonstrate that our proposed method achieves state-of-the-art performance in both objective assessment and visual quality. The Code of our fusion method is available at https://github.com/exceptionLi/imagefusion_deeplearning
FaceDet3D: Facial Expressions with 3D Geometric Detail Prediction
Dec 23, 2020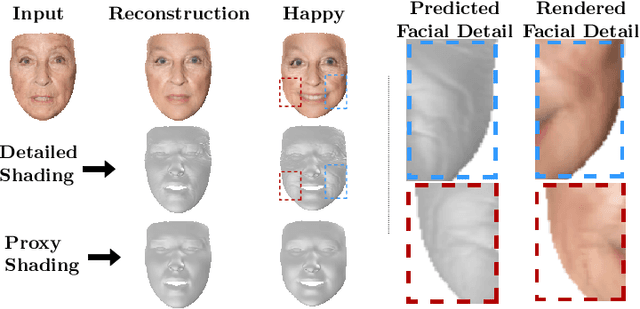
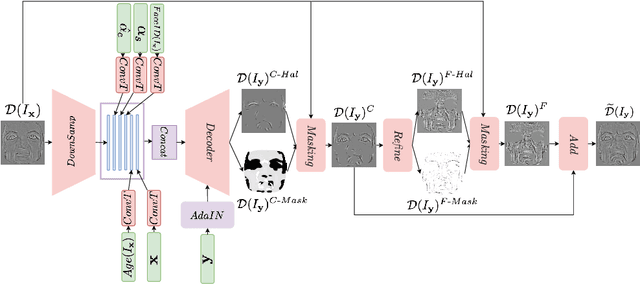
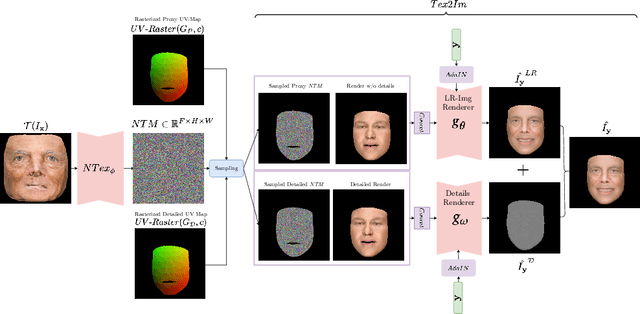

Facial Expressions induce a variety of high-level details on the 3D face geometry. For example, a smile causes the wrinkling of cheeks or the formation of dimples, while being angry often causes wrinkling of the forehead. Morphable Models (3DMMs) of the human face fail to capture such fine details in their PCA-based representations and consequently cannot generate such details when used to edit expressions. In this work, we introduce FaceDet3D, a first-of-its-kind method that generates - from a single image - geometric facial details that are consistent with any desired target expression. The facial details are represented as a vertex displacement map and used then by a Neural Renderer to photo-realistically render novel images of any single image in any desired expression and view. The project website is: http://shahrukhathar.github.io/2020/12/14/FaceDet3D.html
Emotion Recognition in Horses with Convolutional Neural Networks
May 25, 2021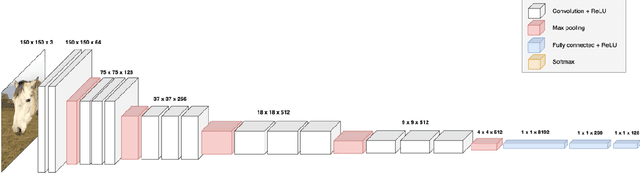
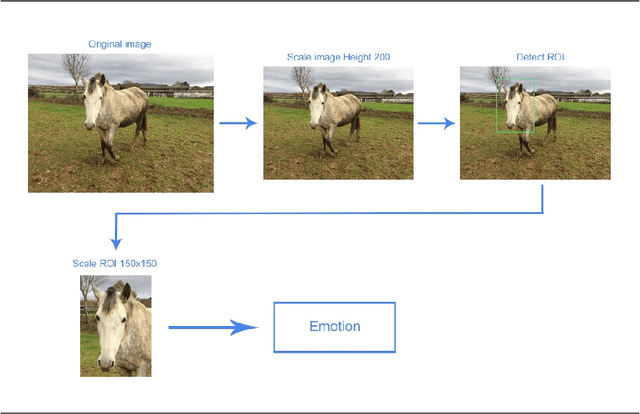
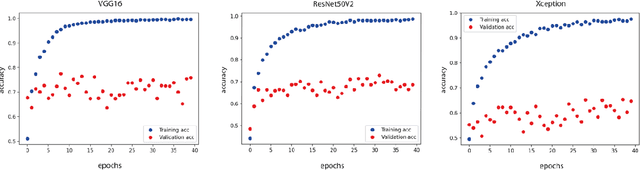
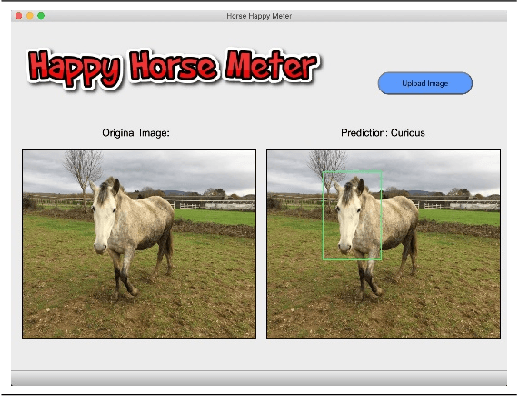
Creating intelligent systems capable of recognizing emotions is a difficult task, especially when looking at emotions in animals. This paper describes the process of designing a "proof of concept" system to recognize emotions in horses. This system is formed by two elements, a detector and a model. The detector is a faster region-based convolutional neural network that detects horses in an image. The second one, the model, is a convolutional neural network that predicts the emotion of those horses. These two models were trained with multiple images of horses until they achieved high accuracy in their tasks, creating therefore the desired system. 400 images of horses were used to train both the detector and the model while 80 were used to validate the system. Once the two components were validated they were combined into a testable system that would detect equine emotions based on established behavioral ethograms indicating emotional affect through head, neck, ear, muzzle, and eye position. The system showed an accuracy of between 69% and 74% on the validation set, demonstrating that it is possible to predict emotions in animals using autonomous intelligent systems. It is a first "proof of concept" approach that can be enhanced in many ways. Such a system has multiple applications including further studies in the growing field of animal emotions as well as in the veterinary field to determine the physical welfare of horses or other livestock.
Knowledge Distillation with Adaptive Asymmetric Label Sharpening for Semi-supervised Fracture Detection in Chest X-rays
Dec 30, 2020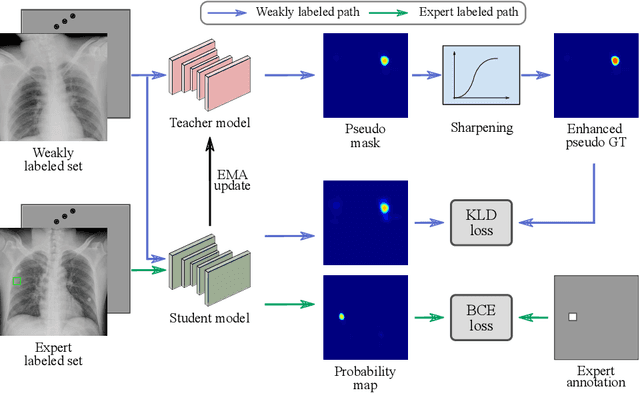
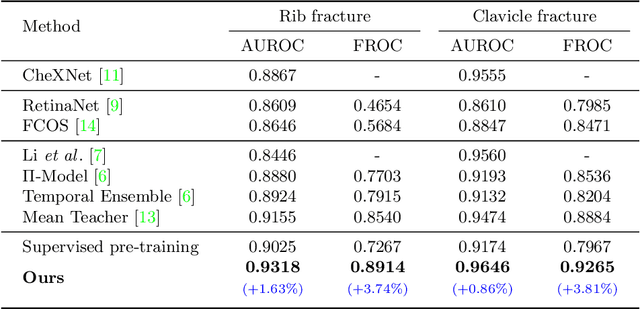
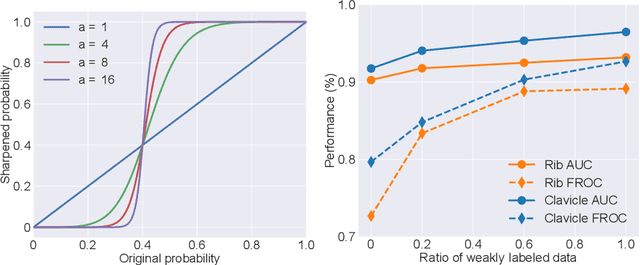
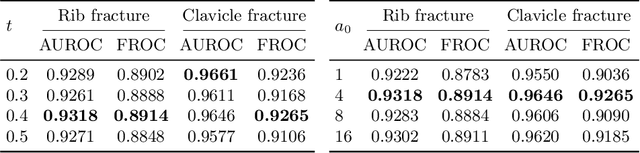
Exploiting available medical records to train high performance computer-aided diagnosis (CAD) models via the semi-supervised learning (SSL) setting is emerging to tackle the prohibitively high labor costs involved in large-scale medical image annotations. Despite the extensive attentions received on SSL, previous methods failed to 1) account for the low disease prevalence in medical records and 2) utilize the image-level diagnosis indicated from the medical records. Both issues are unique to SSL for CAD models. In this work, we propose a new knowledge distillation method that effectively exploits large-scale image-level labels extracted from the medical records, augmented with limited expert annotated region-level labels, to train a rib and clavicle fracture CAD model for chest X-ray (CXR). Our method leverages the teacher-student model paradigm and features a novel adaptive asymmetric label sharpening (AALS) algorithm to address the label imbalance problem that specially exists in medical domain. Our approach is extensively evaluated on all CXR (N = 65,845) from the trauma registry of anonymous hospital over a period of 9 years (2008-2016), on the most common rib and clavicle fractures. The experiment results demonstrate that our method achieves the state-of-the-art fracture detection performance, i.e., an area under receiver operating characteristic curve (AUROC) of 0.9318 and a free-response receiver operating characteristic (FROC) score of 0.8914 on the rib fractures, significantly outperforming previous approaches by an AUROC gap of 1.63% and an FROC improvement by 3.74%. Consistent performance gains are also observed for clavicle fracture detection.
Scaling Laws for Autoregressive Generative Modeling
Oct 28, 2020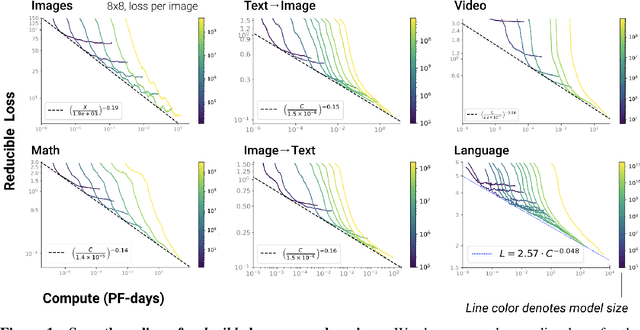
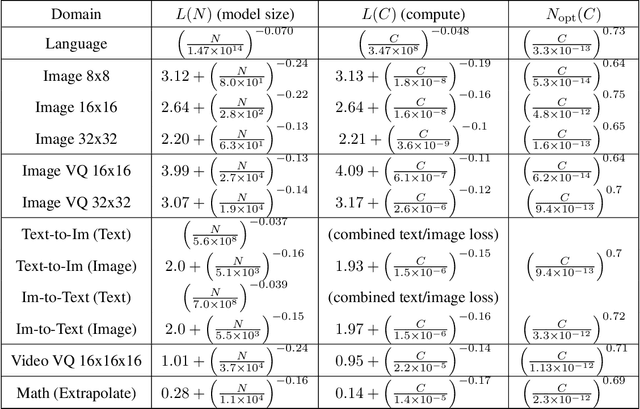
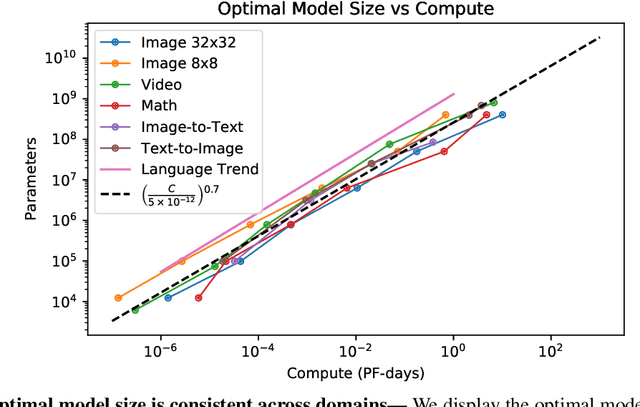

We identify empirical scaling laws for the cross-entropy loss in four domains: generative image modeling, video modeling, multimodal image$\leftrightarrow$text models, and mathematical problem solving. In all cases autoregressive Transformers smoothly improve in performance as model size and compute budgets increase, following a power-law plus constant scaling law. The optimal model size also depends on the compute budget through a power-law, with exponents that are nearly universal across all data domains. The cross-entropy loss has an information theoretic interpretation as $S($True$) + D_{\mathrm{KL}}($True$||$Model$)$, and the empirical scaling laws suggest a prediction for both the true data distribution's entropy and the KL divergence between the true and model distributions. With this interpretation, billion-parameter Transformers are nearly perfect models of the YFCC100M image distribution downsampled to an $8\times 8$ resolution, and we can forecast the model size needed to achieve any given reducible loss (ie $D_{\mathrm{KL}}$) in nats/image for other resolutions. We find a number of additional scaling laws in specific domains: (a) we identify a scaling relation for the mutual information between captions and images in multimodal models, and show how to answer the question "Is a picture worth a thousand words?"; (b) in the case of mathematical problem solving, we identify scaling laws for model performance when extrapolating beyond the training distribution; (c) we finetune generative image models for ImageNet classification and find smooth scaling of the classification loss and error rate, even as the generative loss levels off. Taken together, these results strengthen the case that scaling laws have important implications for neural network performance, including on downstream tasks.
Wider Channel Attention Network for Remote Sensing Image Super-resolution
Dec 13, 2018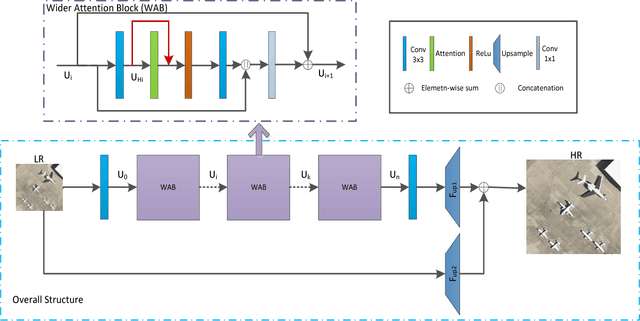



Recently, deep convolutional neural networks (CNNs) have obtained promising results in image processing tasks including super-resolution (SR). However, most CNN-based SR methods treat low-resolution (LR) inputs and features equally across channels, rarely notice the loss of information flow caused by the activation function and fail to leverage the representation ability of CNNs. In this letter, we propose a novel single-image super-resolution (SISR) algorithm named Wider Channel Attention Network (WCAN) for remote sensing images. Firstly, the channel attention mechanism is used to adaptively recalibrate the importance of each channel at the middle of the wider attention block (WAB). Secondly, we propose the Local Memory Connection (LMC) to enhance the information flow. Finally, the features within each WAB are fused to take advantage of the network's representation capability and further improve information and gradient flow. Analytic experiments on a public remote sensing data set (UC Merced) show that our WCAN achieves better accuracy and visual improvements against most state-of-the-art methods.
Self-supervised Pre-training with Hard Examples Improves Visual Representations
Jan 04, 2021
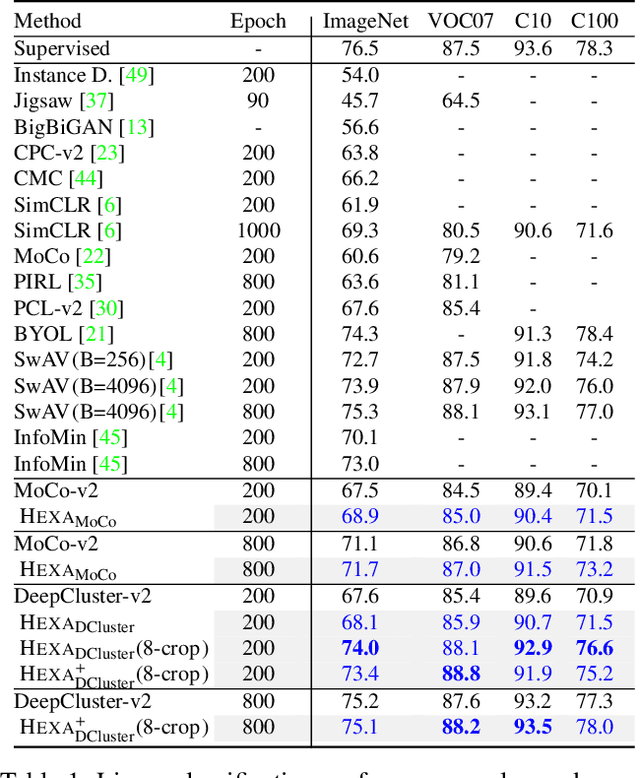
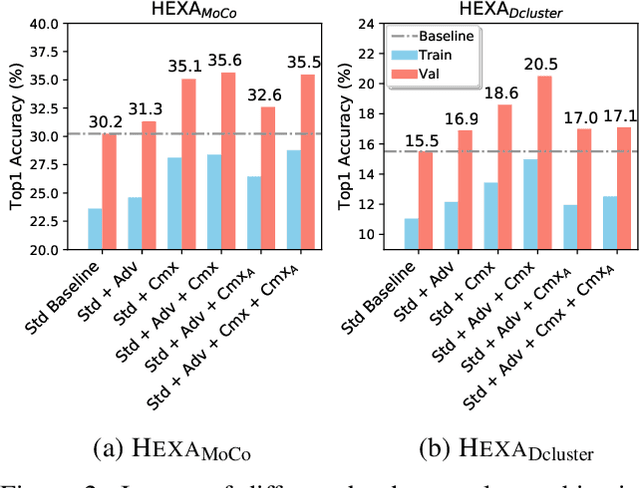
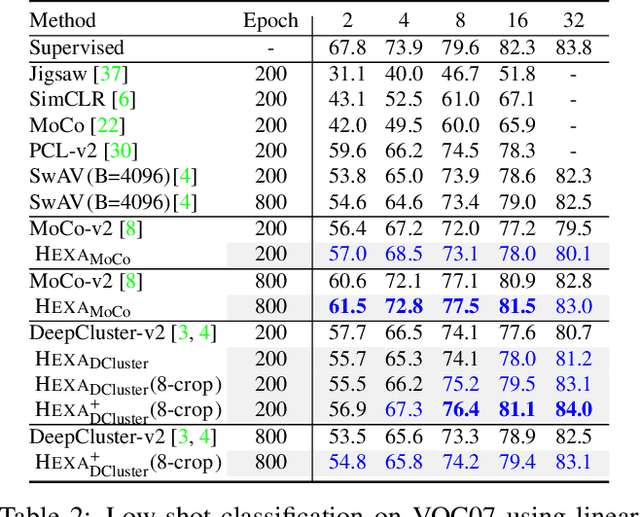
Self-supervised pre-training (SSP) employs random image transformations to generate training data for visual representation learning. In this paper, we first present a modeling framework that unifies existing SSP methods as learning to predict pseudo-labels. Then, we propose new data augmentation methods of generating training examples whose pseudo-labels are harder to predict than those generated via random image transformations. Specifically, we use adversarial training and CutMix to create hard examples (HEXA) to be used as augmented views for MoCo-v2 and DeepCluster-v2, leading to two variants HEXA_{MoCo} and HEXA_{DCluster}, respectively. In our experiments, we pre-train models on ImageNet and evaluate them on multiple public benchmarks. Our evaluation shows that the two new algorithm variants outperform their original counterparts, and achieve new state-of-the-art on a wide range of tasks where limited task supervision is available for fine-tuning. These results verify that hard examples are instrumental in improving the generalization of the pre-trained models.