 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Semantic-Based VPS for Smartphone Localization in Challenging Urban Environments
Nov 21, 2020
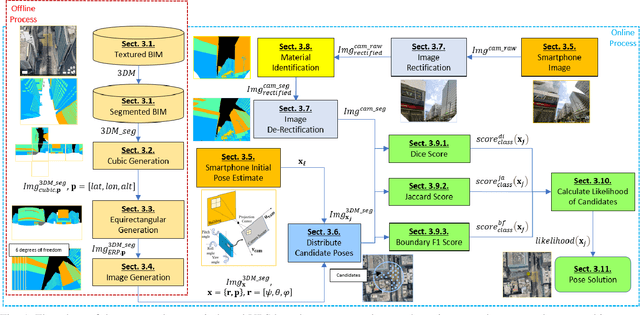
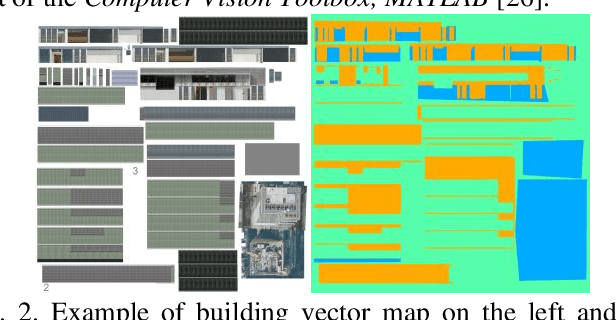
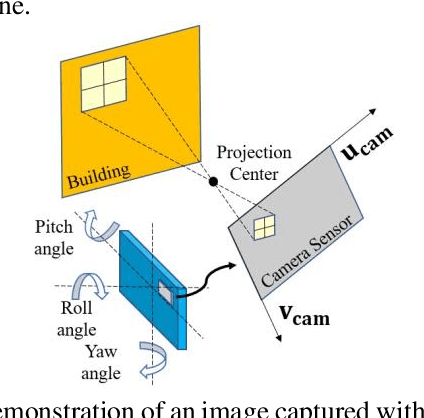

Accurate smartphone-based outdoor localization system in deep urban canyons are increasingly needed for various IoT applications such as augmented reality, intelligent transportation, etc. The recently developed feature-based visual positioning system (VPS) by Google detects edges from smartphone images to match with pre-surveyed edges in their map database. As smart cities develop, the building information modeling (BIM) becomes widely available, which provides an opportunity for a new semantic-based VPS. This article proposes a novel 3D city model and semantic-based VPS for accurate and robust pose estimation in urban canyons where global navigation satellite system (GNSS) tends to fail. In the offline stage, a material segmented city model is used to generate segmented images. In the online stage, an image is taken with a smartphone camera that provides textual information about the surrounding environment. The approach utilizes computer vision algorithms to rectify and hand segment between the different types of material identified in the smartphone image. A semantic-based VPS method is then proposed to match the segmented generated images with the segmented smartphone image. Each generated image holds a pose that contains the latitude, longitude, altitude, yaw, pitch, and roll. The candidate with the maximum likelihood is regarded as the precise pose of the user. The positioning results achieves 2.0m level accuracy in common high rise along street, 5.5m in foliage dense environment and 15.7m in alleyway. A 45% positioning improvement to current state-of-the-art method. The estimation of yaw achieves 2.3{\deg} level accuracy, 8 times the improvement to smartphone IMU.
Learning Semantic Concepts and Order for Image and Sentence Matching
Dec 06, 2017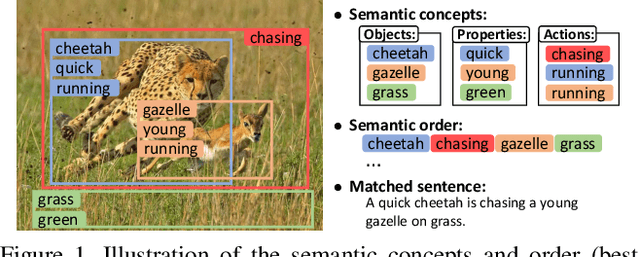
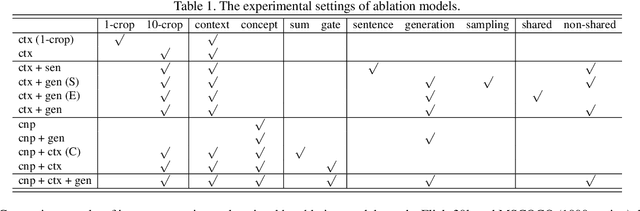
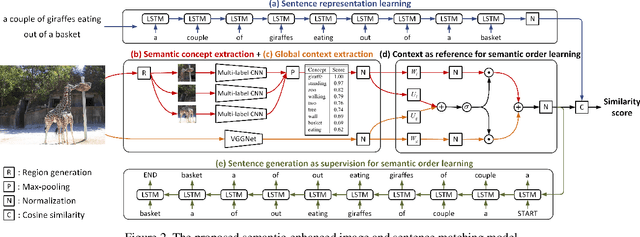
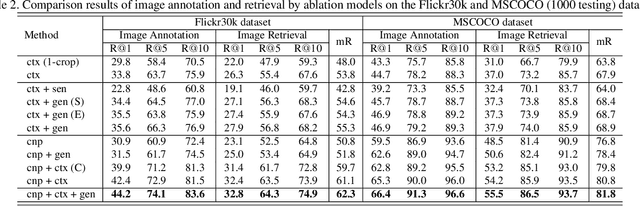
Image and sentence matching has made great progress recently, but it remains challenging due to the large visual-semantic discrepancy. This mainly arises from that the representation of pixel-level image usually lacks of high-level semantic information as in its matched sentence. In this work, we propose a semantic-enhanced image and sentence matching model, which can improve the image representation by learning semantic concepts and then organizing them in a correct semantic order. Given an image, we first use a multi-regional multi-label CNN to predict its semantic concepts, including objects, properties, actions, etc. Then, considering that different orders of semantic concepts lead to diverse semantic meanings, we use a context-gated sentence generation scheme for semantic order learning. It simultaneously uses the image global context containing concept relations as reference and the groundtruth semantic order in the matched sentence as supervision. After obtaining the improved image representation, we learn the sentence representation with a conventional LSTM, and then jointly perform image and sentence matching and sentence generation for model learning. Extensive experiments demonstrate the effectiveness of our learned semantic concepts and order, by achieving the state-of-the-art results on two public benchmark datasets.
ILP-M Conv: Optimize Convolution Algorithm for Single-Image Convolution Neural Network Inference on Mobile GPUs
Oct 03, 2019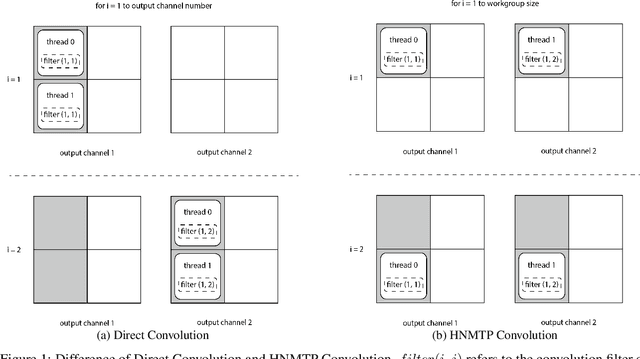


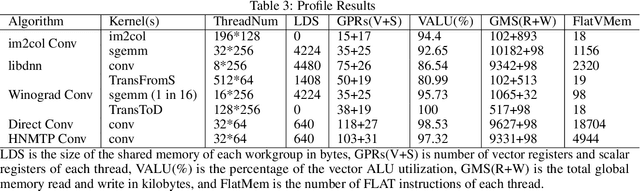
Convolution neural networks are widely used for mobile applications. However, GPU convolution algorithms are designed for mini-batch neural network training, the single-image convolution neural network inference algorithm on mobile GPUs is not well-studied. After discussing the usage difference and examining the existing convolution algorithms, we proposed the HNTMP convolution algorithm. The HNTMP convolution algorithm achieves $14.6 \times$ speedup than the most popular \textit{im2col} convolution algorithm, and $2.30 \times$ speedup than the fastest existing convolution algorithm (direct convolution) as far as we know.
Cross-Domain Image Matching with Deep Feature Maps
Oct 01, 2018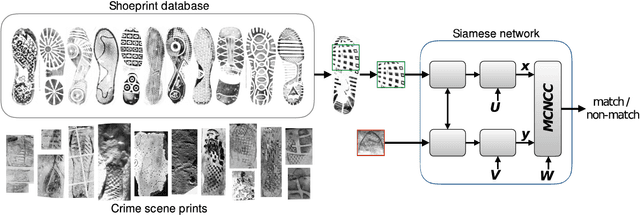
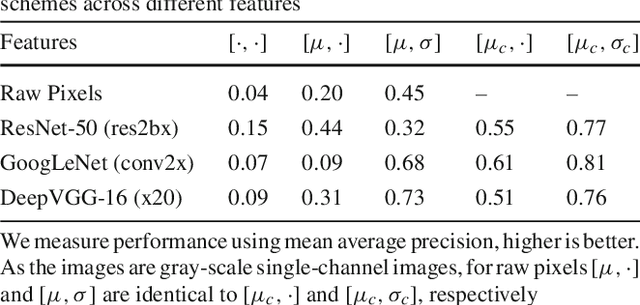
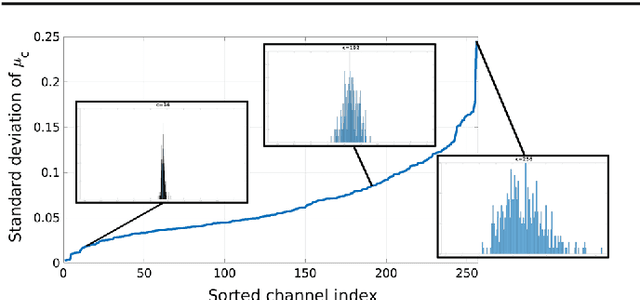
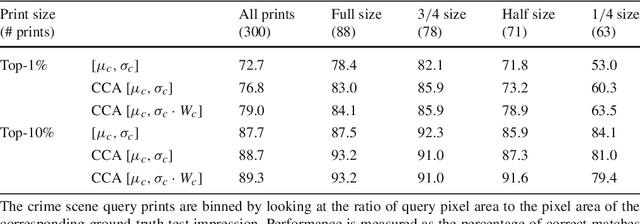
We investigate the problem of automatically determining what type of shoe left an impression found at a crime scene. This recognition problem is made difficult by the variability in types of crime scene evidence (ranging from traces of dust or oil on hard surfaces to impressions made in soil) and the lack of comprehensive databases of shoe outsole tread patterns. We find that mid-level features extracted by pre-trained convolutional neural nets are surprisingly effective descriptors for this specialized domains. However, the choice of similarity measure for matching exemplars to a query image is essential to good performance. For matching multi-channel deep features, we propose the use of multi-channel normalized cross-correlation and analyze its effectiveness. Our proposed metric significantly improves performance in matching crime scene shoeprints to laboratory test impressions. We also show its effectiveness in other cross-domain image retrieval problems: matching facade images to segmentation labels and aerial photos to map images. Finally, we introduce a discriminatively trained variant and fine-tune our system through our proposed metric, obtaining state-of-the-art performance.
Channel-Recurrent Autoencoding for Image Modeling
Mar 11, 2018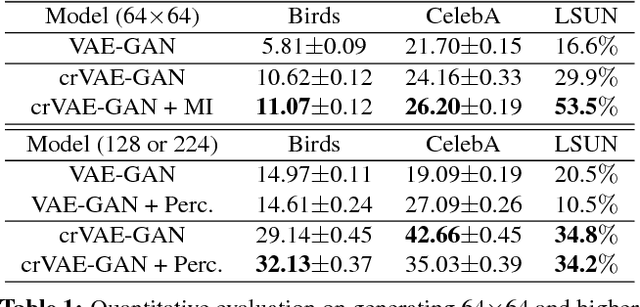
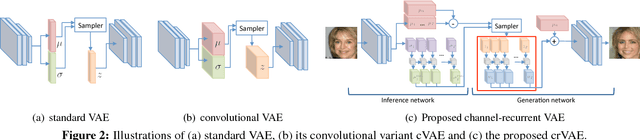
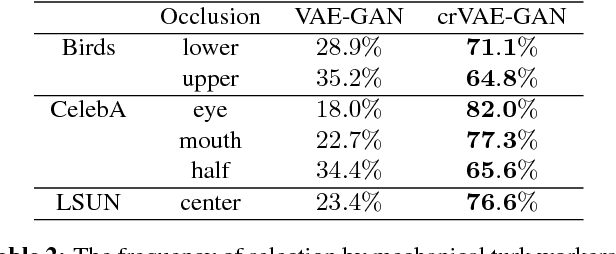

Despite recent successes in synthesizing faces and bedrooms, existing generative models struggle to capture more complex image types, potentially due to the oversimplification of their latent space constructions. To tackle this issue, building on Variational Autoencoders (VAEs), we integrate recurrent connections across channels to both inference and generation steps, allowing the high-level features to be captured in global-to-local, coarse-to-fine manners. Combined with adversarial loss, our channel-recurrent VAE-GAN (crVAE-GAN) outperforms VAE-GAN in generating a diverse spectrum of high resolution images while maintaining the same level of computational efficacy. Our model produces interpretable and expressive latent representations to benefit downstream tasks such as image completion. Moreover, we propose two novel regularizations, namely the KL objective weighting scheme over time steps and mutual information maximization between transformed latent variables and the outputs, to enhance the training.
Differences between human and machine perception in medical diagnosis
Nov 28, 2020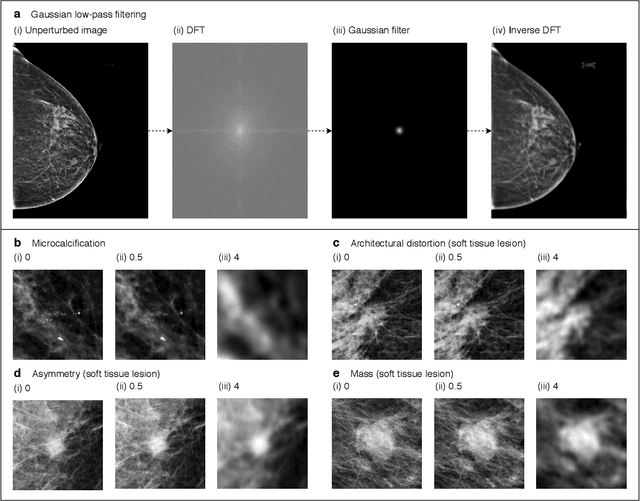
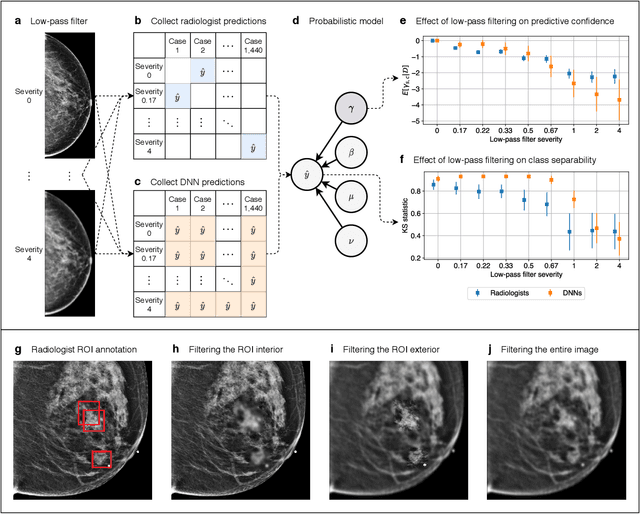
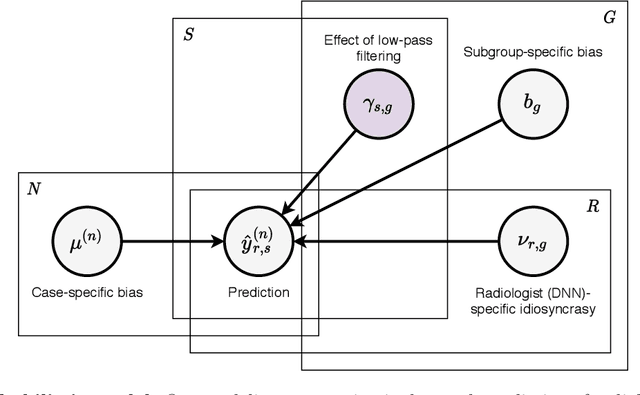
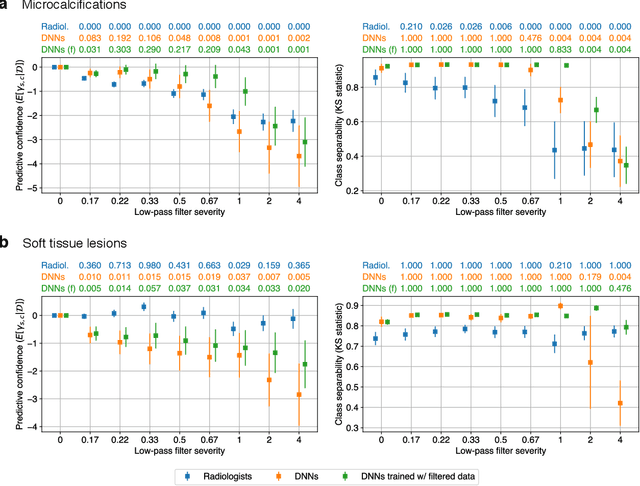
Deep neural networks (DNNs) show promise in image-based medical diagnosis, but cannot be fully trusted since their performance can be severely degraded by dataset shifts to which human perception remains invariant. If we can better understand the differences between human and machine perception, we can potentially characterize and mitigate this effect. We therefore propose a framework for comparing human and machine perception in medical diagnosis. The two are compared with respect to their sensitivity to the removal of clinically meaningful information, and to the regions of an image deemed most suspicious. Drawing inspiration from the natural image domain, we frame both comparisons in terms of perturbation robustness. The novelty of our framework is that separate analyses are performed for subgroups with clinically meaningful differences. We argue that this is necessary in order to avert Simpson's paradox and draw correct conclusions. We demonstrate our framework with a case study in breast cancer screening, and reveal significant differences between radiologists and DNNs. We compare the two with respect to their robustness to Gaussian low-pass filtering, performing a subgroup analysis on microcalcifications and soft tissue lesions. For microcalcifications, DNNs use a separate set of high frequency components than radiologists, some of which lie outside the image regions considered most suspicious by radiologists. These features run the risk of being spurious, but if not, could represent potential new biomarkers. For soft tissue lesions, the divergence between radiologists and DNNs is even starker, with DNNs relying heavily on spurious high frequency components ignored by radiologists. Importantly, this deviation in soft tissue lesions was only observable through subgroup analysis, which highlights the importance of incorporating medical domain knowledge into our comparison framework.
FCFR-Net: Feature Fusion based Coarse-to-Fine Residual Learning for Monocular Depth Completion
Dec 15, 2020
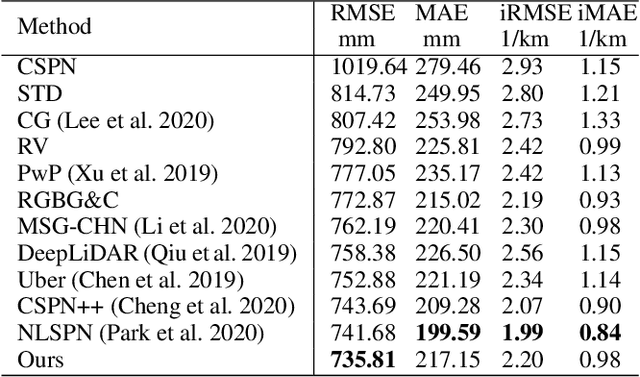
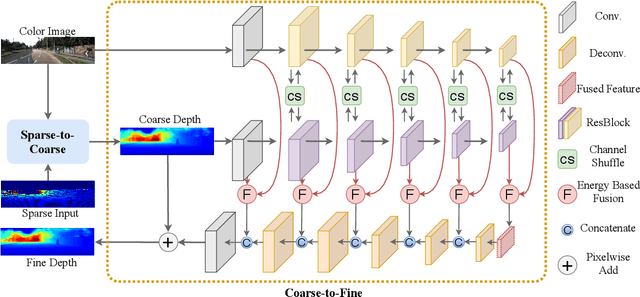
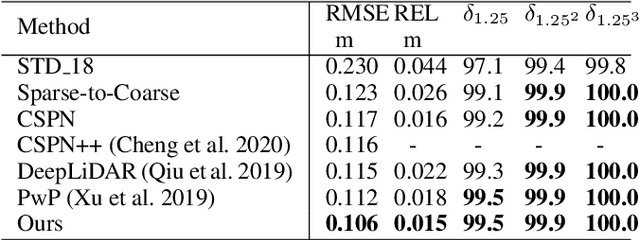
Depth completion aims to recover a dense depth map from a sparse depth map with the corresponding color image as input. Recent approaches mainly formulate the depth completion as a one-stage end-to-end learning task, which outputs dense depth maps directly. However, the feature extraction and supervision in one-stage frameworks are insufficient, limiting the performance of these approaches. To address this problem, we propose a novel end-to-end residual learning framework, which formulates the depth completion as a two-stage learning task, i.e., a sparse-to-coarse stage and a coarse-to-fine stage. First, a coarse dense depth map is obtained by a simple CNN framework. Then, a refined depth map is further obtained using a residual learning strategy in the coarse-to-fine stage with coarse depth map and color image as input. Specially, in the coarse-to-fine stage, a channel shuffle extraction operation is utilized to extract more representative features from color image and coarse depth map, and an energy based fusion operation is exploited to effectively fuse these features obtained by channel shuffle operation, thus leading to more accurate and refined depth maps. We achieve SoTA performance in RMSE on KITTI benchmark. Extensive experiments on other datasets future demonstrate the superiority of our approach over current state-of-the-art depth completion approaches.
Minimizing L1 over L2 norms on the gradient
Jan 04, 2021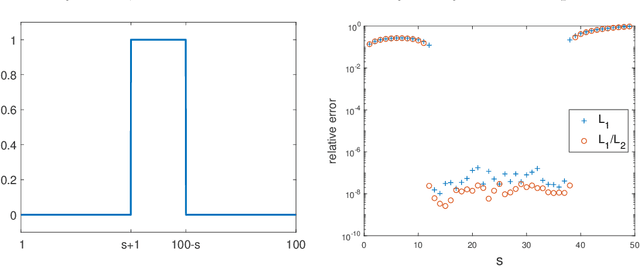
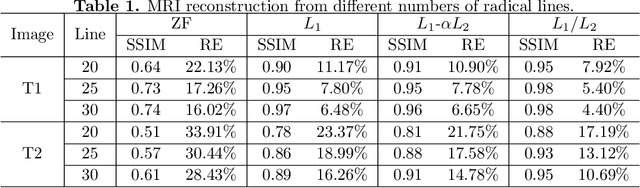
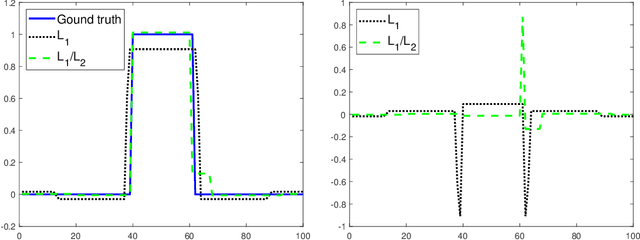
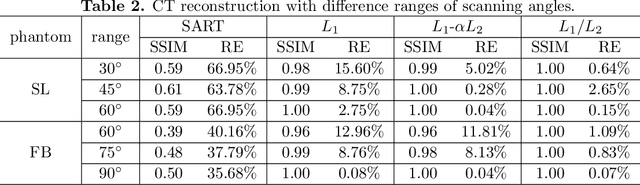
In this paper, we study the L1/L2 minimization on the gradient for imaging applications. Several recent works have demonstrated that L1/L2 is better than the L1 norm when approximating the L0 norm to promote sparsity. Consequently, we postulate that applying L1/L2 on the gradient is better than the classic total variation (the L1 norm on the gradient) to enforce the sparsity of the image gradient. To verify our hypothesis, we consider a constrained formulation to reveal empirical evidence on the superiority of L1/L2 over L1 when recovering piecewise constant signals from low-frequency measurements. Numerically, we design a specific splitting scheme, under which we can prove the subsequential convergence for the alternating direction method of multipliers (ADMM). Experimentally, we demonstrate visible improvements of L1/L2 over L1 and other nonconvex regularizations for image recovery from low-frequency measurements and two medical applications of MRI and CT reconstruction. All the numerical results show the efficiency of our proposed approach.
Fast Predictive Image Registration
Jul 08, 2016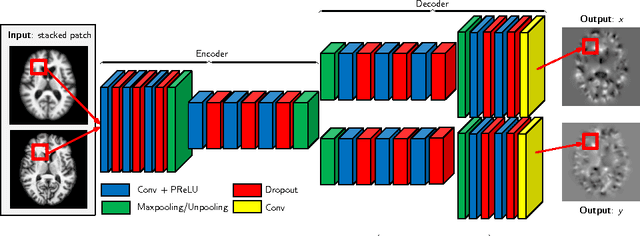
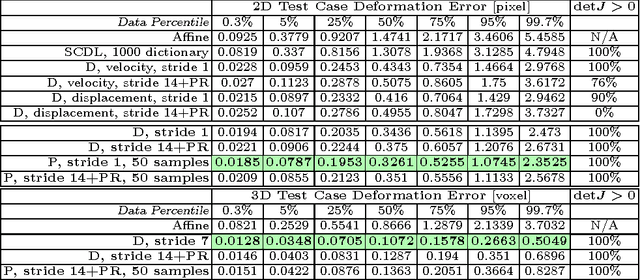
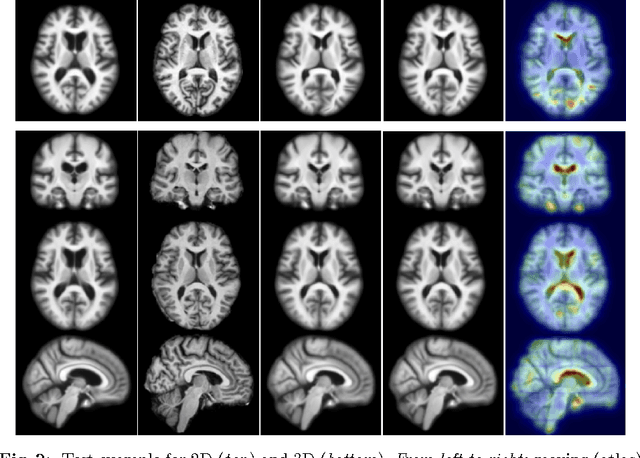
We present a method to predict image deformations based on patch-wise image appearance. Specifically, we design a patch-based deep encoder-decoder network which learns the pixel/voxel-wise mapping between image appearance and registration parameters. Our approach can predict general deformation parameterizations, however, we focus on the large deformation diffeomorphic metric mapping (LDDMM) registration model. By predicting the LDDMM momentum-parameterization we retain the desirable theoretical properties of LDDMM, while reducing computation time by orders of magnitude: combined with patch pruning, we achieve a 1500x/66x speed up compared to GPU-based optimization for 2D/3D image registration. Our approach has better prediction accuracy than predicting deformation or velocity fields and results in diffeomorphic transformations. Additionally, we create a Bayesian probabilistic version of our network, which allows evaluation of deformation field uncertainty through Monte Carlo sampling using dropout at test time. We show that deformation uncertainty highlights areas of ambiguous deformations. We test our method on the OASIS brain image dataset in 2D and 3D.
Interpretable Methods for Identifying Product Variants
Apr 12, 2021

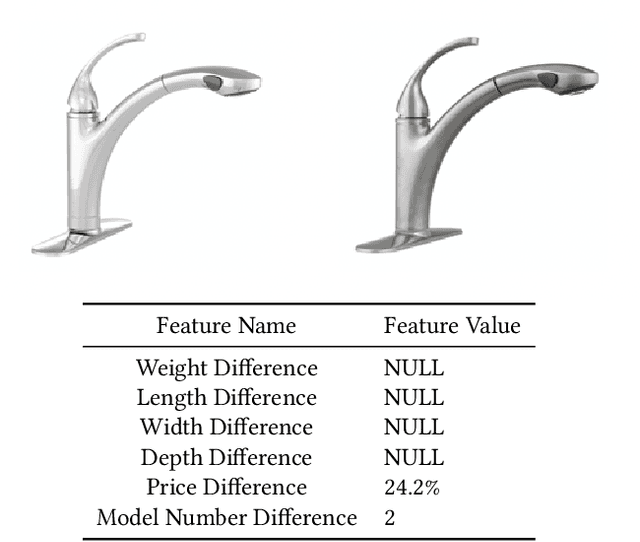

For e-commerce companies with large product selections, the organization and grouping of products in meaningful ways is important for creating great customer shopping experiences and cultivating an authoritative brand image. One important way of grouping products is to identify a family of product variants, where the variants are mostly the same with slight and yet distinct differences (e.g. color or pack size). In this paper, we introduce a novel approach to identifying product variants. It combines both constrained clustering and tailored NLP techniques (e.g. extraction of product family name from unstructured product title and identification of products with similar model numbers) to achieve superior performance compared with an existing baseline using a vanilla classification approach. In addition, we design the algorithm to meet certain business criteria, including meeting high accuracy requirements on a wide range of categories (e.g. appliances, decor, tools, and building materials, etc.) as well as prioritizing the interpretability of the model to make it accessible and understandable to all business partners.