 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Emotion Recognition in Horses with Convolutional Neural Networks
May 25, 2021
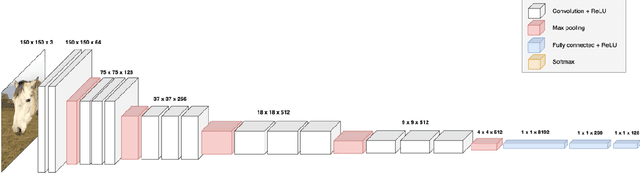
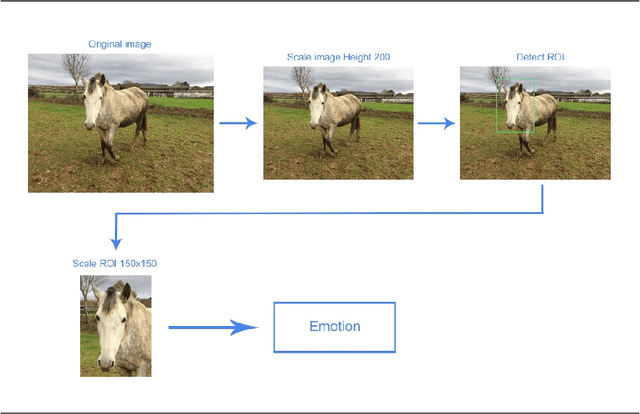
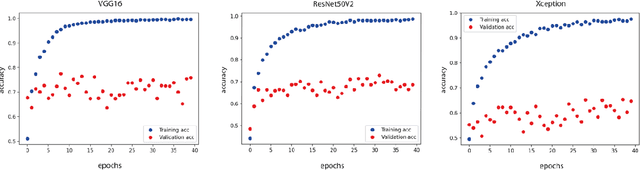
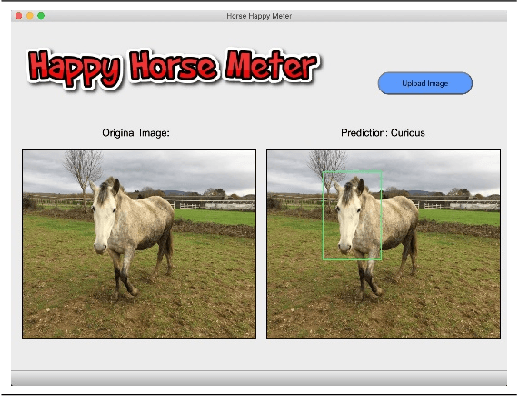
Creating intelligent systems capable of recognizing emotions is a difficult task, especially when looking at emotions in animals. This paper describes the process of designing a "proof of concept" system to recognize emotions in horses. This system is formed by two elements, a detector and a model. The detector is a faster region-based convolutional neural network that detects horses in an image. The second one, the model, is a convolutional neural network that predicts the emotion of those horses. These two models were trained with multiple images of horses until they achieved high accuracy in their tasks, creating therefore the desired system. 400 images of horses were used to train both the detector and the model while 80 were used to validate the system. Once the two components were validated they were combined into a testable system that would detect equine emotions based on established behavioral ethograms indicating emotional affect through head, neck, ear, muzzle, and eye position. The system showed an accuracy of between 69% and 74% on the validation set, demonstrating that it is possible to predict emotions in animals using autonomous intelligent systems. It is a first "proof of concept" approach that can be enhanced in many ways. Such a system has multiple applications including further studies in the growing field of animal emotions as well as in the veterinary field to determine the physical welfare of horses or other livestock.
Risk-Aware Path Planning for Ground Vehicles using Occluded Aerial Images
Apr 23, 2021
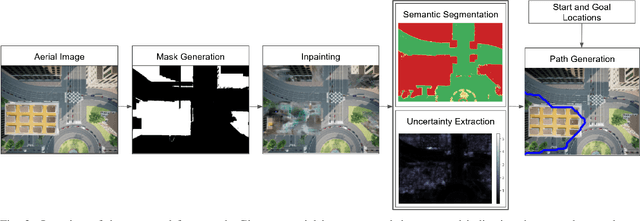
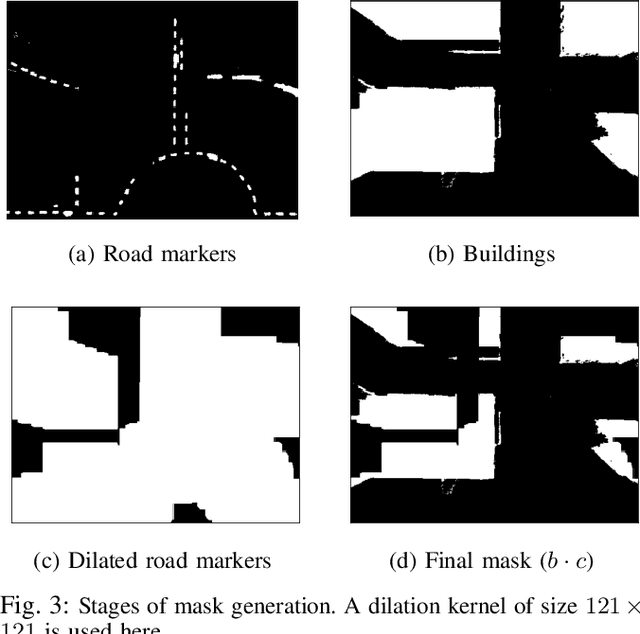
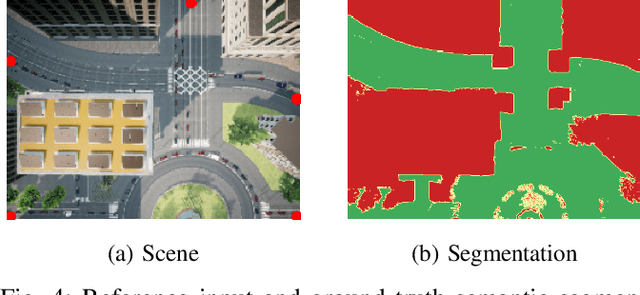
We consider scenarios where a ground vehicle plans its path using data gathered by an aerial vehicle. In the aerial images, navigable areas of the scene may be occluded due to obstacles. Naively planning paths using aerial images may result in longer paths as a conservative planner may try to avoid regions that are occluded. We propose a modular, deep learning-based framework that allows the robot to predict the existence of navigable areas in the occluded regions. Specifically, we use image inpainting methods to fill in parts of the areas that are potentially occluded, which can then be semantically segmented to determine navigability. We use supervised neural networks for both modules. However, these predictions may be incorrect. Therefore, we extract uncertainty in these predictions and use a risk-aware approach that takes these uncertainties into account for path planning. We compare modules in our approach with non-learning-based approaches to show the efficacy of the proposed framework through photo-realistic simulations. The modular pipeline allows further improvement in path planning and deployment in different settings.
Visual Servoing Approach for Autonomous UAV Landing on a Moving Vehicle
Apr 02, 2021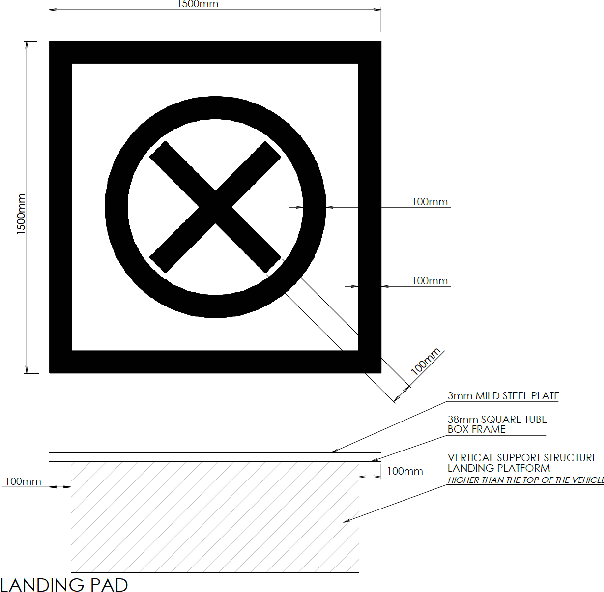
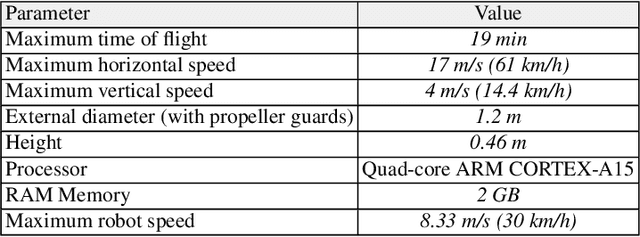
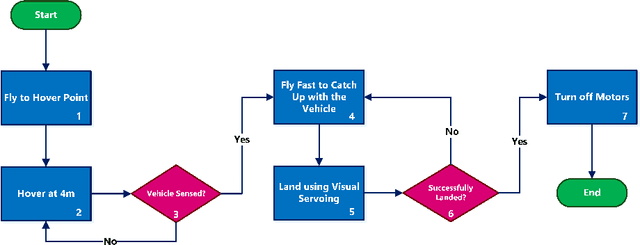
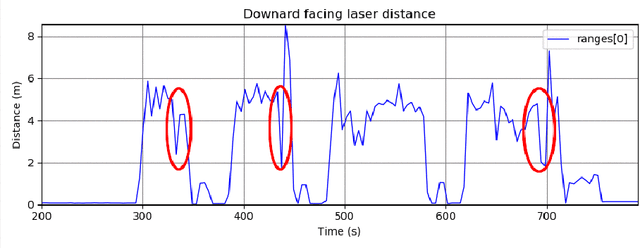
We present a method to autonomously land an Unmanned Aerial Vehicle on a moving vehicle with a circular (or elliptical) pattern on the top. A visual servoing controller approaches the ground vehicle using velocity commands calculated directly in image space. The control laws generate velocity commands in all three dimensions, eliminating the need for a separate height controller. The method has shown the ability to approach and land on the moving deck in simulation, indoor and outdoor environments, and compared to the other available methods, it has provided the fastest landing approach. It does not rely on additional external setup, such as RTK, motion capture system, ground station, offboard processing, or communication with the vehicle, and it requires only a minimal set of hardware and localization sensors. The videos and source codes can be accessed from http://theairlab.org/landing-on-vehicle.
Style Intervention: How to Achieve Spatial Disentanglement with Style-based Generators?
Nov 19, 2020


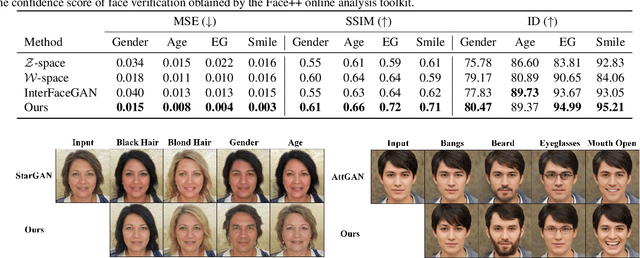
Generative Adversarial Networks (GANs) with style-based generators (e.g. StyleGAN) successfully enable semantic control over image synthesis, and recent studies have also revealed that interpretable image translations could be obtained by modifying the latent code. However, in terms of the low-level image content, traveling in the latent space would lead to `spatially entangled changes' in corresponding images, which is undesirable in many real-world applications where local editing is required. To solve this problem, we analyze properties of the 'style space' and explore the possibility of controlling the local translation with pre-trained style-based generators. Concretely, we propose 'Style Intervention', a lightweight optimization-based algorithm which could adapt to arbitrary input images and render natural translation effects under flexible objectives. We verify the performance of the proposed framework in facial attribute editing on high-resolution images, where both photo-realism and consistency are required. Extensive qualitative results demonstrate the effectiveness of our method, and quantitative measurements also show that the proposed algorithm outperforms state-of-the-art benchmarks in various aspects.
Channel-Recurrent Autoencoding for Image Modeling
Mar 11, 2018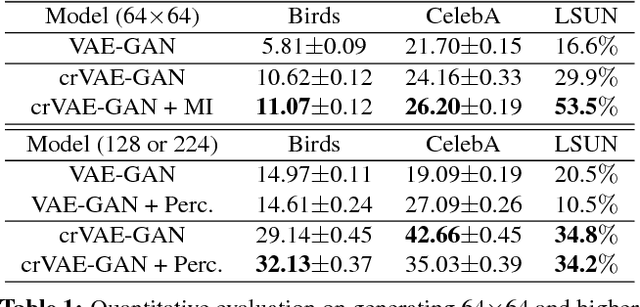
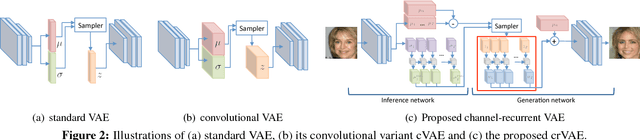
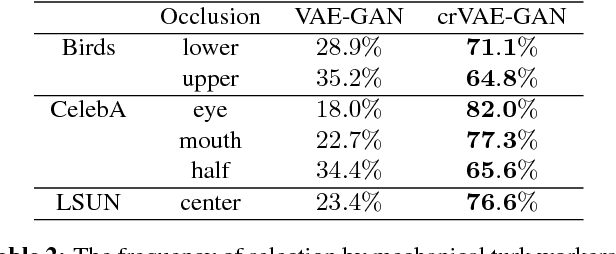

Despite recent successes in synthesizing faces and bedrooms, existing generative models struggle to capture more complex image types, potentially due to the oversimplification of their latent space constructions. To tackle this issue, building on Variational Autoencoders (VAEs), we integrate recurrent connections across channels to both inference and generation steps, allowing the high-level features to be captured in global-to-local, coarse-to-fine manners. Combined with adversarial loss, our channel-recurrent VAE-GAN (crVAE-GAN) outperforms VAE-GAN in generating a diverse spectrum of high resolution images while maintaining the same level of computational efficacy. Our model produces interpretable and expressive latent representations to benefit downstream tasks such as image completion. Moreover, we propose two novel regularizations, namely the KL objective weighting scheme over time steps and mutual information maximization between transformed latent variables and the outputs, to enhance the training.
Recurrent Multimodal Interaction for Referring Image Segmentation
Aug 04, 2017
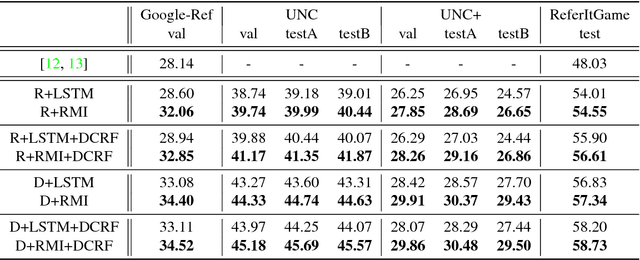
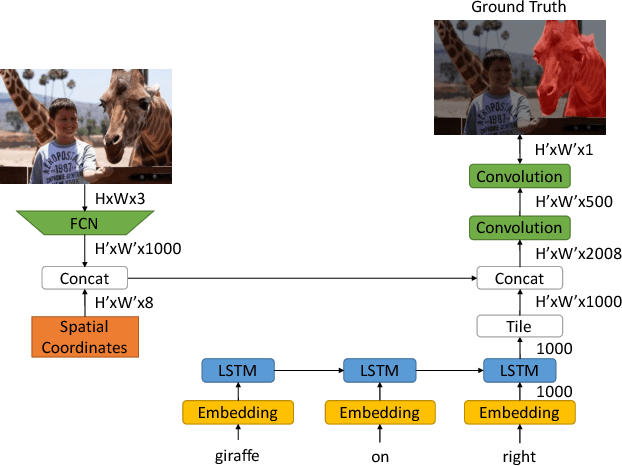
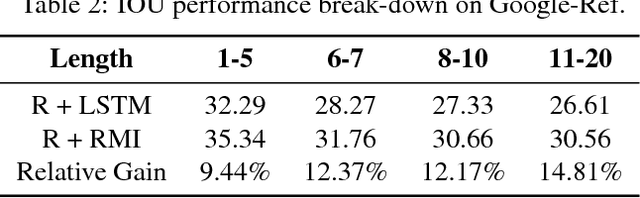
In this paper we are interested in the problem of image segmentation given natural language descriptions, i.e. referring expressions. Existing works tackle this problem by first modeling images and sentences independently and then segment images by combining these two types of representations. We argue that learning word-to-image interaction is more native in the sense of jointly modeling two modalities for the image segmentation task, and we propose convolutional multimodal LSTM to encode the sequential interactions between individual words, visual information, and spatial information. We show that our proposed model outperforms the baseline model on benchmark datasets. In addition, we analyze the intermediate output of the proposed multimodal LSTM approach and empirically explain how this approach enforces a more effective word-to-image interaction.
Shape and Material Capture at Home
Apr 13, 2021

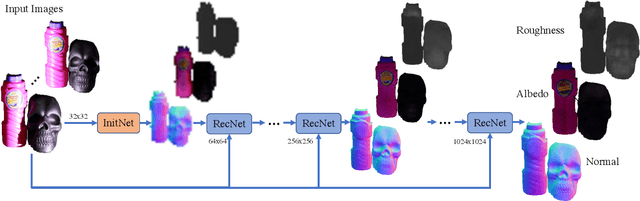

In this paper, we present a technique for estimating the geometry and reflectance of objects using only a camera, flashlight, and optionally a tripod. We propose a simple data capture technique in which the user goes around the object, illuminating it with a flashlight and capturing only a few images. Our main technical contribution is the introduction of a recursive neural architecture, which can predict geometry and reflectance at 2^{k}*2^{k} resolution given an input image at 2^{k}*2^{k} and estimated geometry and reflectance from the previous step at 2^{k-1}*2^{k-1}. This recursive architecture, termed RecNet, is trained with 256x256 resolution but can easily operate on 1024x1024 images during inference. We show that our method produces more accurate surface normal and albedo, especially in regions of specular highlights and cast shadows, compared to previous approaches, given three or fewer input images. For the video and code, please visit the project website http://dlichy.github.io/ShapeAndMaterialAtHome/.
On Hallucination and Predictive Uncertainty in Conditional Language Generation
Mar 28, 2021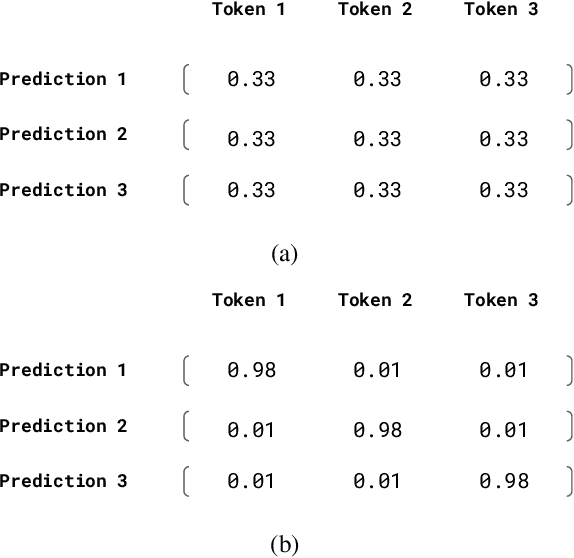
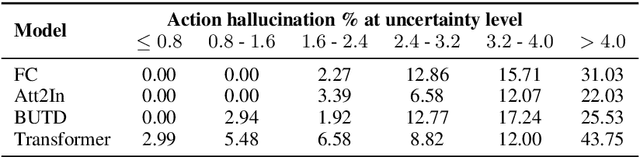
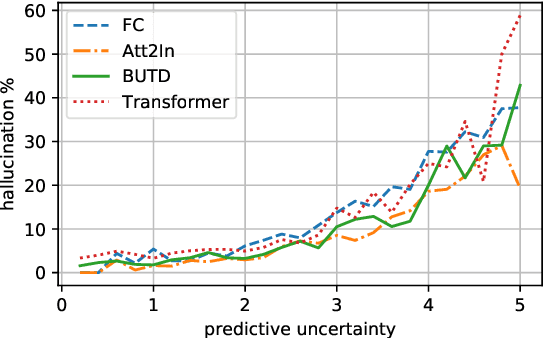
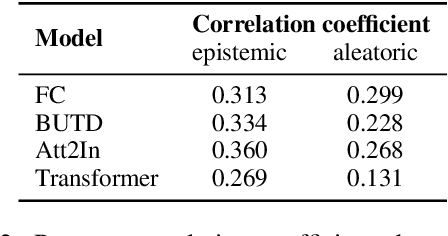
Despite improvements in performances on different natural language generation tasks, deep neural models are prone to hallucinating facts that are incorrect or nonexistent. Different hypotheses are proposed and examined separately for different tasks, but no systematic explanations are available across these tasks. In this study, we draw connections between hallucinations and predictive uncertainty in conditional language generation. We investigate their relationship in both image captioning and data-to-text generation and propose a simple extension to beam search to reduce hallucination. Our analysis shows that higher predictive uncertainty corresponds to a higher chance of hallucination. Epistemic uncertainty is more indicative of hallucination than aleatoric or total uncertainties. It helps to achieve better results of trading performance in standard metric for less hallucination with the proposed beam search variant.
Semantic-Based VPS for Smartphone Localization in Challenging Urban Environments
Nov 21, 2020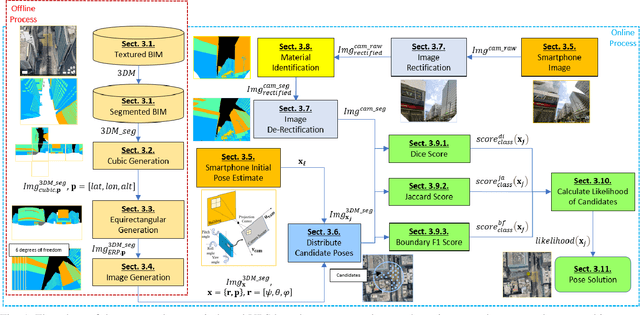
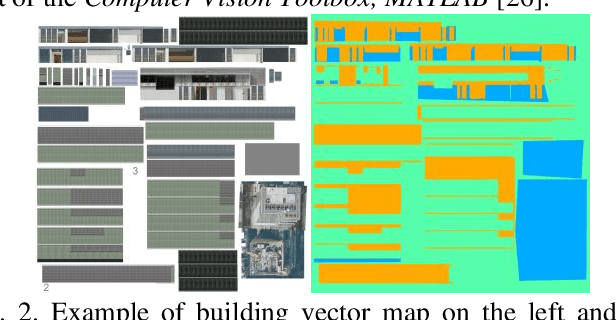
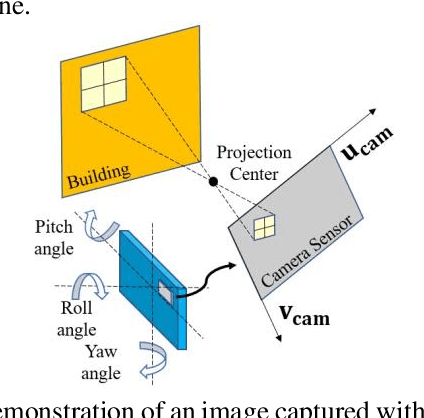

Accurate smartphone-based outdoor localization system in deep urban canyons are increasingly needed for various IoT applications such as augmented reality, intelligent transportation, etc. The recently developed feature-based visual positioning system (VPS) by Google detects edges from smartphone images to match with pre-surveyed edges in their map database. As smart cities develop, the building information modeling (BIM) becomes widely available, which provides an opportunity for a new semantic-based VPS. This article proposes a novel 3D city model and semantic-based VPS for accurate and robust pose estimation in urban canyons where global navigation satellite system (GNSS) tends to fail. In the offline stage, a material segmented city model is used to generate segmented images. In the online stage, an image is taken with a smartphone camera that provides textual information about the surrounding environment. The approach utilizes computer vision algorithms to rectify and hand segment between the different types of material identified in the smartphone image. A semantic-based VPS method is then proposed to match the segmented generated images with the segmented smartphone image. Each generated image holds a pose that contains the latitude, longitude, altitude, yaw, pitch, and roll. The candidate with the maximum likelihood is regarded as the precise pose of the user. The positioning results achieves 2.0m level accuracy in common high rise along street, 5.5m in foliage dense environment and 15.7m in alleyway. A 45% positioning improvement to current state-of-the-art method. The estimation of yaw achieves 2.3{\deg} level accuracy, 8 times the improvement to smartphone IMU.
Fast and Accurate Image Super-Resolution with Deep Laplacian Pyramid Networks
Aug 09, 2018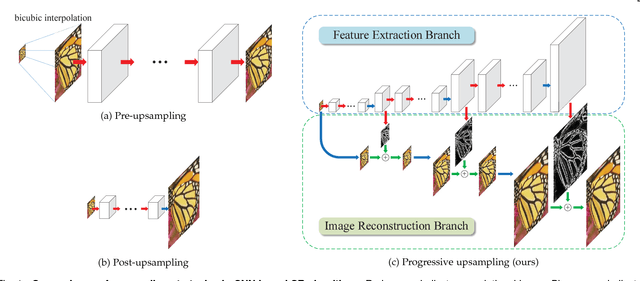
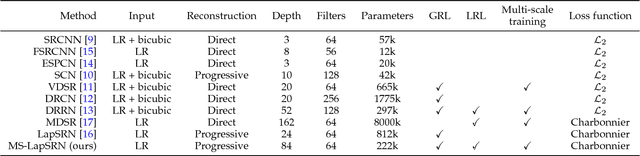
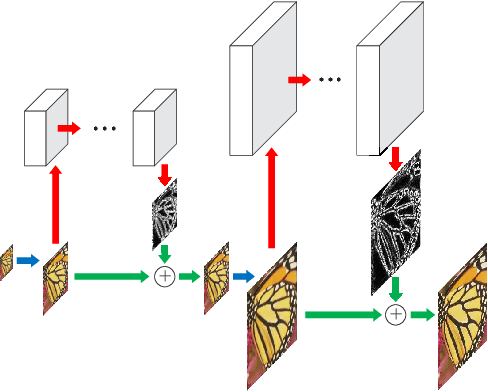
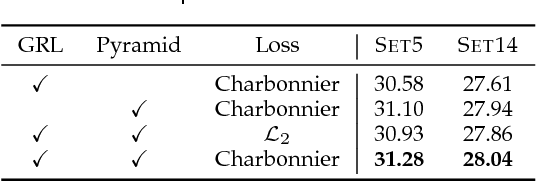
Convolutional neural networks have recently demonstrated high-quality reconstruction for single image super-resolution. However, existing methods often require a large number of network parameters and entail heavy computational loads at runtime for generating high-accuracy super-resolution results. In this paper, we propose the deep Laplacian Pyramid Super-Resolution Network for fast and accurate image super-resolution. The proposed network progressively reconstructs the sub-band residuals of high-resolution images at multiple pyramid levels. In contrast to existing methods that involve the bicubic interpolation for pre-processing (which results in large feature maps), the proposed method directly extracts features from the low-resolution input space and thereby entails low computational loads. We train the proposed network with deep supervision using the robust Charbonnier loss functions and achieve high-quality image reconstruction. Furthermore, we utilize the recursive layers to share parameters across as well as within pyramid levels, and thus drastically reduce the number of parameters. Extensive quantitative and qualitative evaluations on benchmark datasets show that the proposed algorithm performs favorably against the state-of-the-art methods in terms of run-time and image quality.