 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Risk-Aware Path Planning for Ground Vehicles using Occluded Aerial Images
Apr 23, 2021
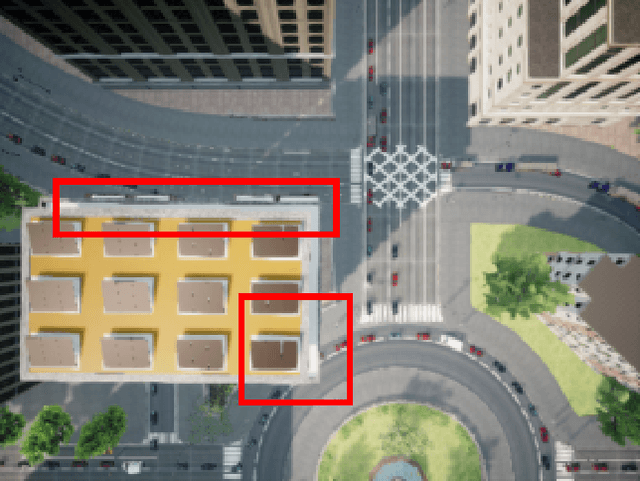
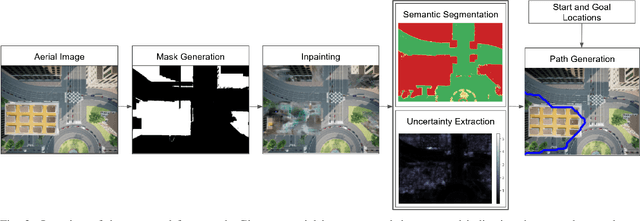
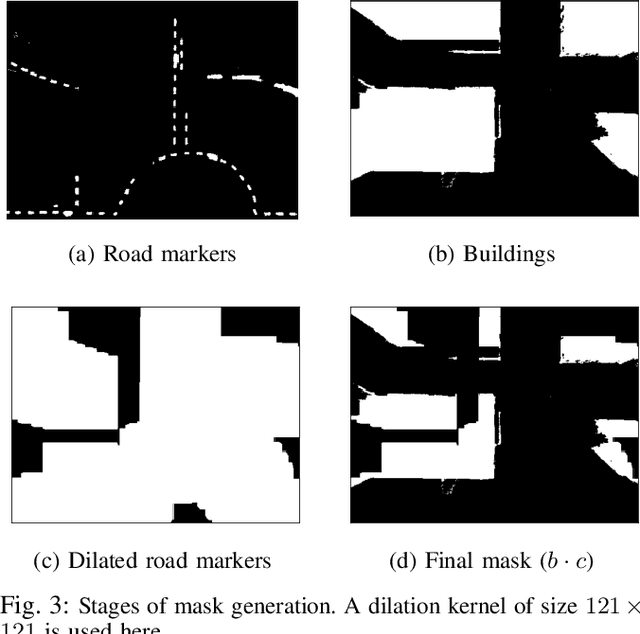
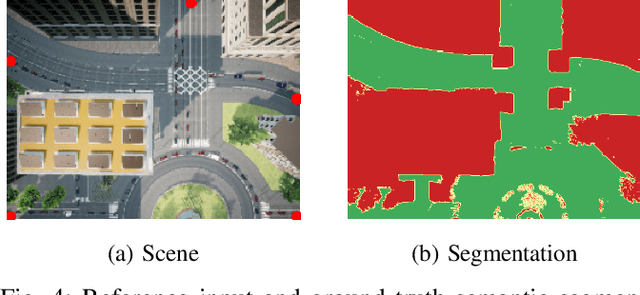
We consider scenarios where a ground vehicle plans its path using data gathered by an aerial vehicle. In the aerial images, navigable areas of the scene may be occluded due to obstacles. Naively planning paths using aerial images may result in longer paths as a conservative planner may try to avoid regions that are occluded. We propose a modular, deep learning-based framework that allows the robot to predict the existence of navigable areas in the occluded regions. Specifically, we use image inpainting methods to fill in parts of the areas that are potentially occluded, which can then be semantically segmented to determine navigability. We use supervised neural networks for both modules. However, these predictions may be incorrect. Therefore, we extract uncertainty in these predictions and use a risk-aware approach that takes these uncertainties into account for path planning. We compare modules in our approach with non-learning-based approaches to show the efficacy of the proposed framework through photo-realistic simulations. The modular pipeline allows further improvement in path planning and deployment in different settings.
A Modified Image Comparison Algorithm Using Histogram Features
Apr 03, 2018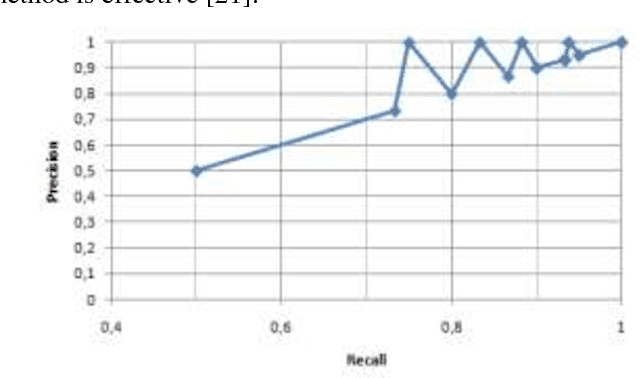
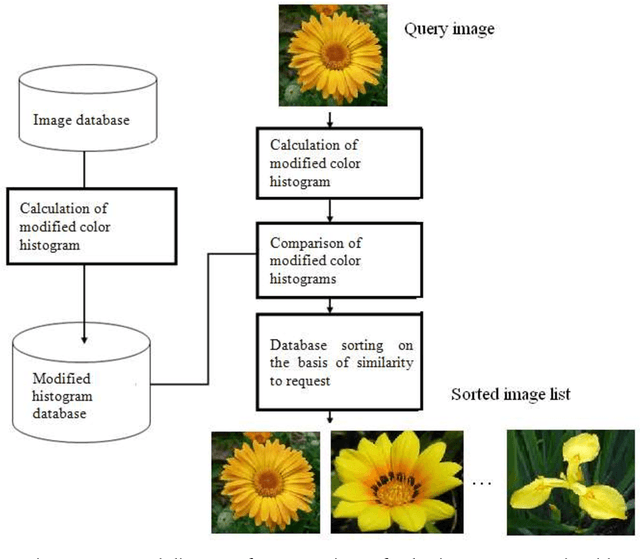

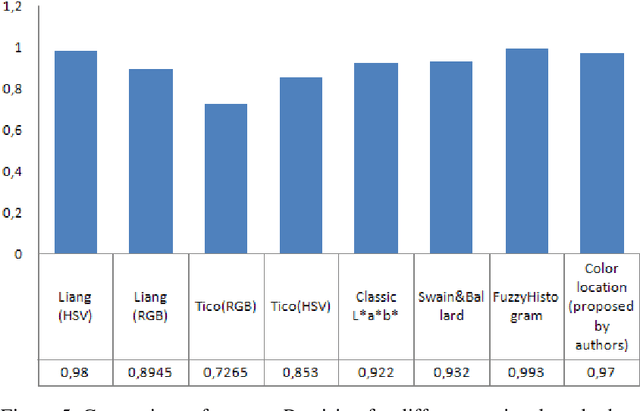
This article discuss the problem of color image content comparison. Particularly, methods of image content comparison are analyzed, restrictions of color histogram are described and a modified method of images content comparison is proposed. This method uses the color histograms and considers color locations. Testing and analyzing of based and modified algorithms are performed. The modified method shows 97% average precision for a collection containing about 700 images without loss of the advantages of based method, i.e. scale and rotation invariant.
* 8 pages, 7 figures
Visual Servoing Approach for Autonomous UAV Landing on a Moving Vehicle
Apr 02, 2021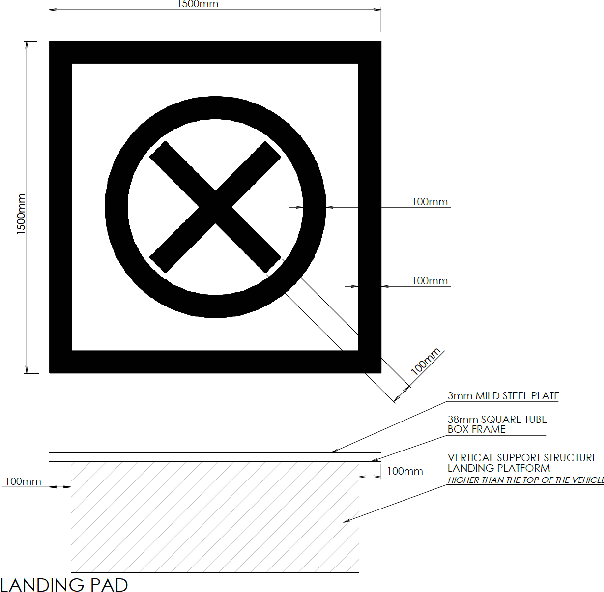
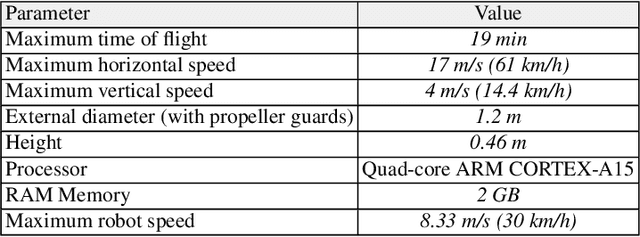
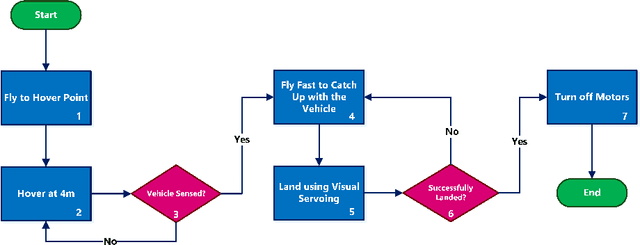
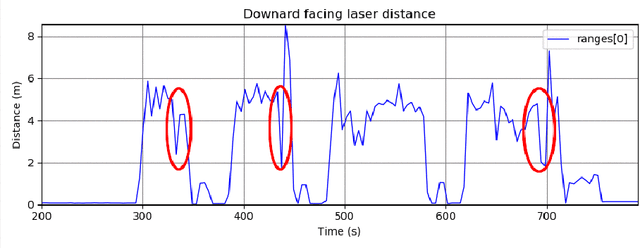
We present a method to autonomously land an Unmanned Aerial Vehicle on a moving vehicle with a circular (or elliptical) pattern on the top. A visual servoing controller approaches the ground vehicle using velocity commands calculated directly in image space. The control laws generate velocity commands in all three dimensions, eliminating the need for a separate height controller. The method has shown the ability to approach and land on the moving deck in simulation, indoor and outdoor environments, and compared to the other available methods, it has provided the fastest landing approach. It does not rely on additional external setup, such as RTK, motion capture system, ground station, offboard processing, or communication with the vehicle, and it requires only a minimal set of hardware and localization sensors. The videos and source codes can be accessed from http://theairlab.org/landing-on-vehicle.
Local Radon Descriptors for Image Search
Oct 11, 2017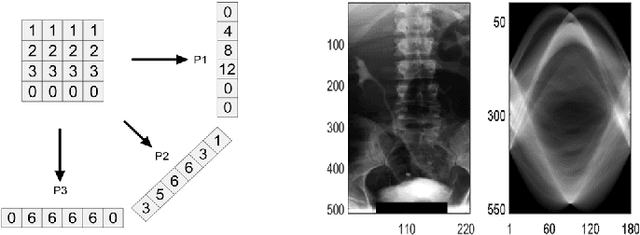
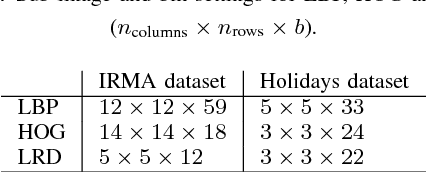
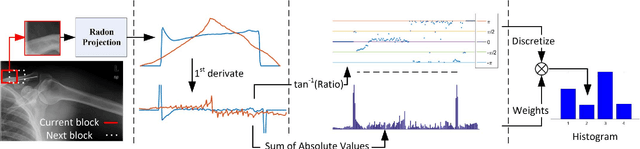
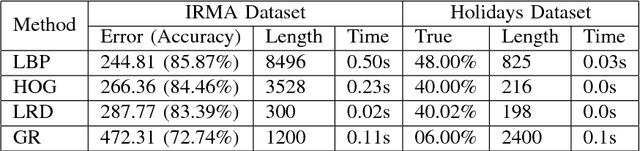
Radon transform and its inverse operation are important techniques in medical imaging tasks. Recently, there has been renewed interest in Radon transform for applications such as content-based medical image retrieval. However, all studies so far have used Radon transform as a global or quasi-global image descriptor by extracting projections of the whole image or large sub-images. This paper attempts to show that the dense sampling to generate the histogram of local Radon projections has a much higher discrimination capability than the global one. In this paper, we introduce Local Radon Descriptor (LRD) and apply it to the IRMA dataset, which contains 14,410 x-ray images as well as to the INRIA Holidays dataset with 1,990 images. Our results show significant improvement in retrieval performance by using LRD versus its global version. We also demonstrate that LRD can deliver results comparable to well-established descriptors like LBP and HOG.
Shape and Material Capture at Home
Apr 13, 2021

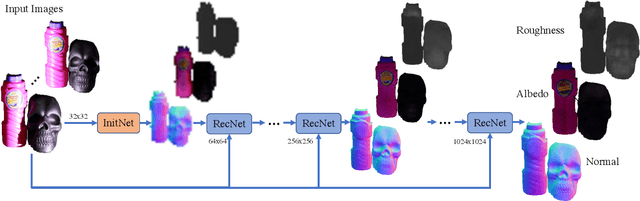

In this paper, we present a technique for estimating the geometry and reflectance of objects using only a camera, flashlight, and optionally a tripod. We propose a simple data capture technique in which the user goes around the object, illuminating it with a flashlight and capturing only a few images. Our main technical contribution is the introduction of a recursive neural architecture, which can predict geometry and reflectance at 2^{k}*2^{k} resolution given an input image at 2^{k}*2^{k} and estimated geometry and reflectance from the previous step at 2^{k-1}*2^{k-1}. This recursive architecture, termed RecNet, is trained with 256x256 resolution but can easily operate on 1024x1024 images during inference. We show that our method produces more accurate surface normal and albedo, especially in regions of specular highlights and cast shadows, compared to previous approaches, given three or fewer input images. For the video and code, please visit the project website http://dlichy.github.io/ShapeAndMaterialAtHome/.
On Hallucination and Predictive Uncertainty in Conditional Language Generation
Mar 28, 2021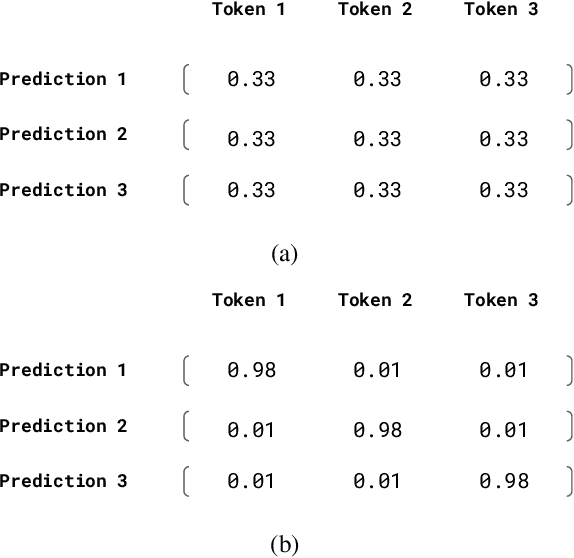
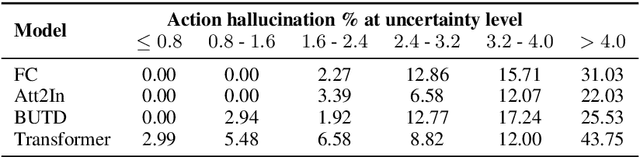
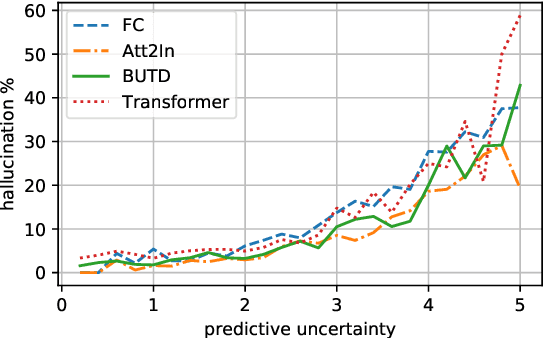
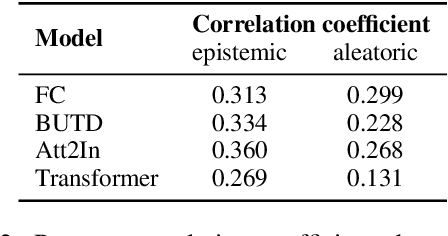
Despite improvements in performances on different natural language generation tasks, deep neural models are prone to hallucinating facts that are incorrect or nonexistent. Different hypotheses are proposed and examined separately for different tasks, but no systematic explanations are available across these tasks. In this study, we draw connections between hallucinations and predictive uncertainty in conditional language generation. We investigate their relationship in both image captioning and data-to-text generation and propose a simple extension to beam search to reduce hallucination. Our analysis shows that higher predictive uncertainty corresponds to a higher chance of hallucination. Epistemic uncertainty is more indicative of hallucination than aleatoric or total uncertainties. It helps to achieve better results of trading performance in standard metric for less hallucination with the proposed beam search variant.
Learning Interclass Relations for Image Classification
Jun 24, 2020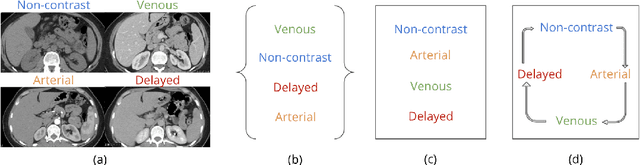
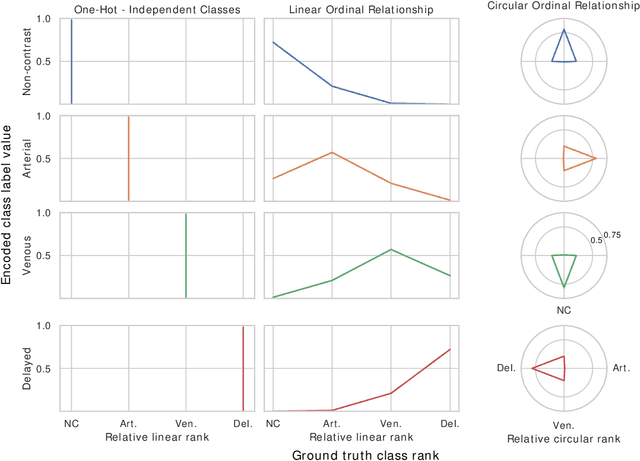
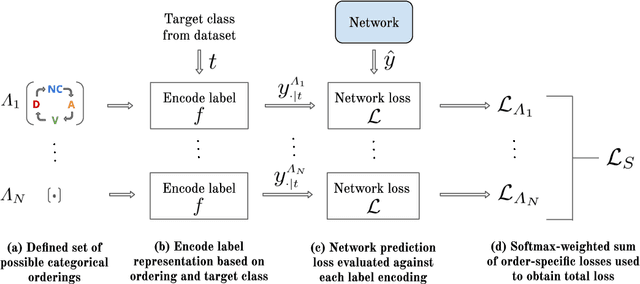
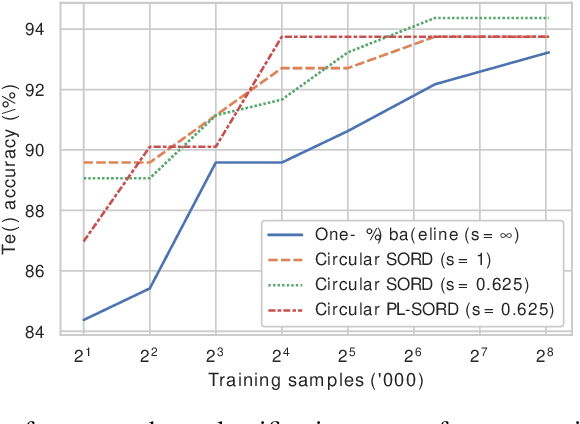
In standard classification, we typically treat class categories as independent of one-another. In many problems, however, we would be neglecting the natural relations that exist between categories, which are often dictated by an underlying biological or physical process. In this work, we propose novel formulations of the classification problem, based on a realization that the assumption of class-independence is a limiting factor that leads to the requirement of more training data. First, we propose manual ways to reduce our data needs by reintroducing knowledge about problem-specific interclass relations into the training process. Second, we propose a general approach to jointly learn categorical label representations that can implicitly encode natural interclass relations, alleviating the need for strong prior assumptions, which are not always available. We demonstrate this in the domain of medical images, where access to large amounts of labelled data is not trivial. Specifically, our experiments show the advantages of this approach in the classification of Intravenous Contrast enhancement phases in CT images, which encapsulate multiple interesting inter-class relations.
Adversarial Joint Image and Pose Distribution Learning for Camera Pose Regression and Refinement
Mar 26, 2019

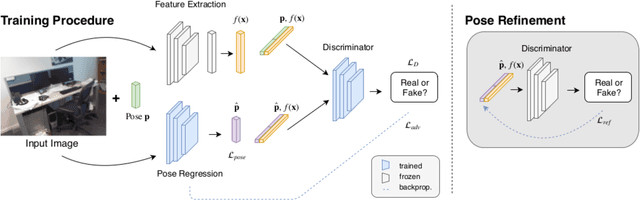
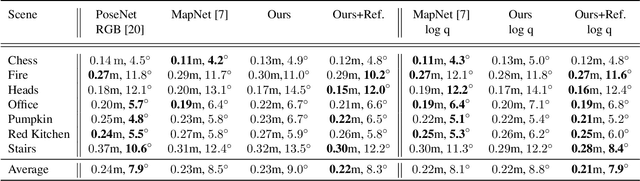
Despite recent advances on the topic of direct camera pose regression using neural networks, accurately estimating the camera pose of a single RGB image still remains a challenging task. To address this problem, we introduce a novel framework based, in its core, on the idea of modeling the joint distribution of RGB images and their corresponding camera poses using adversarial learning. Our method allows not only to regress the camera pose from a single image, however, also offers a solely RGB-based solution for camera pose refinement using the discriminator network. Further, we show that our method can effectively be used to optimize the predicted camera poses and thus improve the localization accuracy. To this end, we validate our proposed method on the publicly available 7-Scenes dataset improving upon the results of current state-of-the-art direct camera pose regression methods.
Exploring Autoencoder-Based Error-Bounded Compression for Scientific Data
May 25, 2021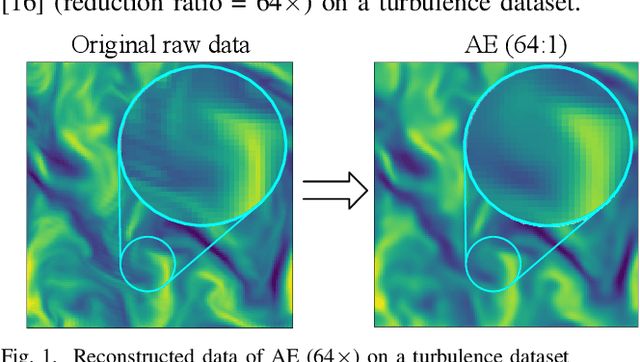
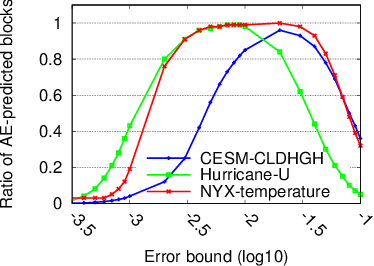
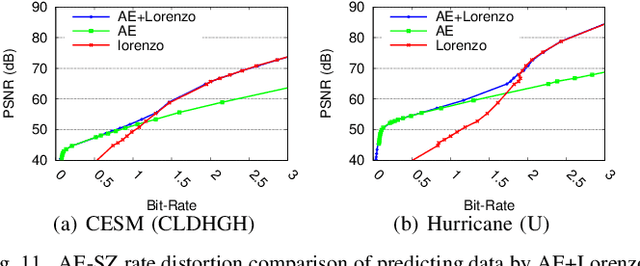
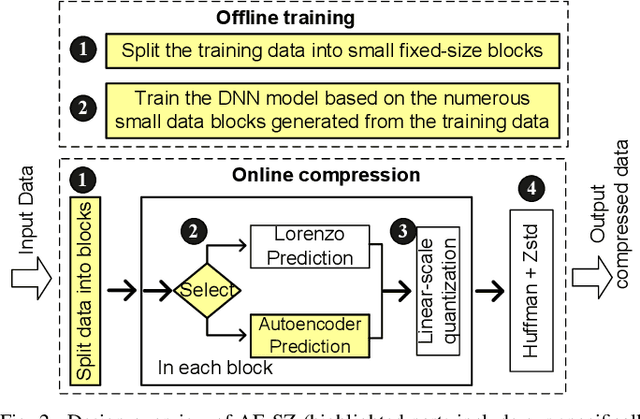
Error-bounded lossy compression is becoming an indispensable technique for the success of today's scientific projects with vast volumes of data produced during the simulations or instrument data acquisitions. Not only can it significantly reduce data size, but it also can control the compression errors based on user-specified error bounds. Autoencoder (AE) models have been widely used in image compression, but few AE-based compression approaches support error-bounding features, which are highly required by scientific applications. To address this issue, we explore using convolutional autoencoders to improve error-bounded lossy compression for scientific data, with the following three key contributions. (1) We provide an in-depth investigation of the characteristics of various autoencoder models and develop an error-bounded autoencoder-based framework in terms of the SZ model. (2) We optimize the compression quality for main stages in our designed AE-based error-bounded compression framework, fine-tuning the block sizes and latent sizes and also optimizing the compression efficiency of latent vectors. (3) We evaluate our proposed solution using five real-world scientific datasets and comparing them with six other related works. Experiments show that our solution exhibits a very competitive compression quality from among all the compressors in our tests. In absolute terms, it can obtain a much better compression quality (100% ~ 800% improvement in compression ratio with the same data distortion) compared with SZ2.1 and ZFP in cases with a high compression ratio.
Sparse-GAN: Sparsity-constrained Generative Adversarial Network for Anomaly Detection in Retinal OCT Image
Jan 07, 2020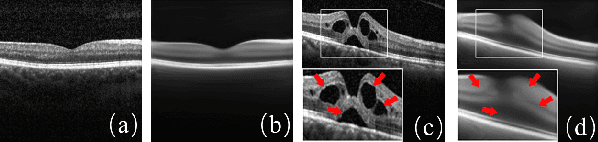
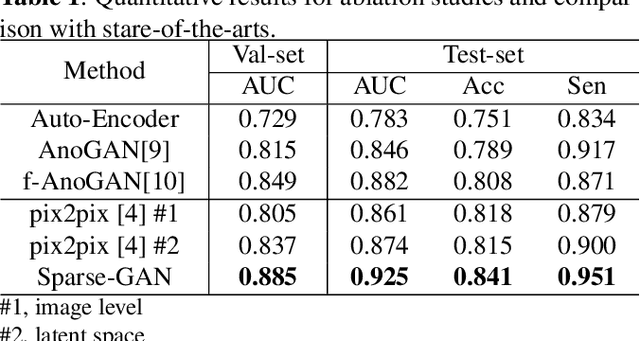
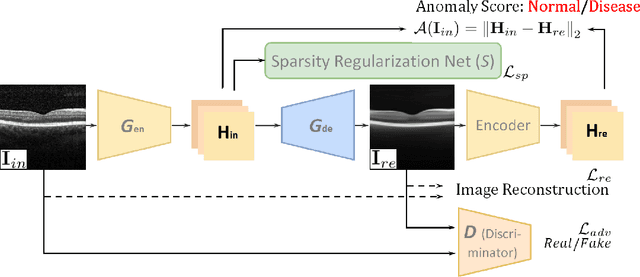
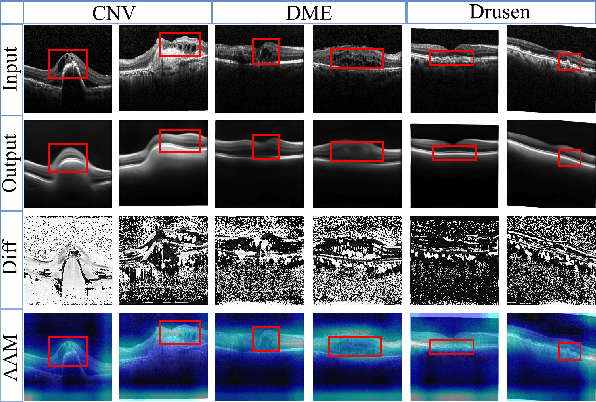
With the development of convolutional neural network, deep learning has shown its success for retinal disease detection from optical coherence tomography (OCT) images. However, deep learning often relies on large scale labelled data for training, which is oftentimes challenging especially for disease with low occurrence. Moreover, a deep learning system trained from data-set with one or a few diseases is unable to detect other unseen diseases, which limits the practical usage of the system in disease screening. To address the limitation, we propose a novel anomaly detection framework termed Sparsity-constrained Generative Adversarial Network (Sparse-GAN) for disease screening where only healthy data are available in the training set. The contributions of Sparse-GAN are two-folds: 1) The proposed Sparse-GAN predicts the anomalies in latent space rather than image-level; 2) Sparse-GAN is constrained by a novel Sparsity Regularization Net. Furthermore, in light of the role of lesions for disease screening, we present to leverage on an anomaly activation map to show the heatmap of lesions. We evaluate our proposed Sparse-GAN on a publicly available dataset, and the results show that the proposed method outperforms the state-of-the-art methods.