 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Compensating Supervision Incompleteness with Prior Knowledge in Semantic Image Interpretation
Oct 01, 2019
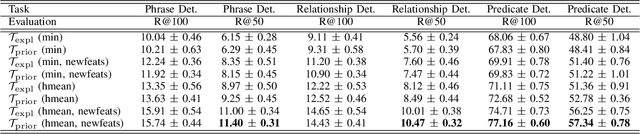
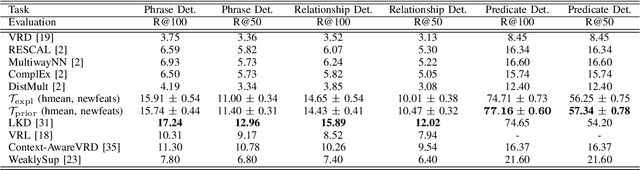
Semantic Image Interpretation is the task of extracting a structured semantic description from images. This requires the detection of visual relationships: triples (subject,relation,object) describing a semantic relation between a subject and an object. A pure supervised approach to visual relationship detection requires a complete and balanced training set for all the possible combinations of (subject, relation, object). However, such training sets are not available and would require a prohibitive human effort. This implies the ability of predicting triples which do not appear in the training set. This problem is called zero-shot learning. State-of-the-art approaches to zero-shot learning exploit similarities among relationships in the training set or external linguistic knowledge. In this paper, we perform zero-shot learning by using Logic Tensor Networks, a novel Statistical Relational Learning framework that exploits both the similarities with other seen relationships and background knowledge, expressed with logical constraints between subjects, relations and objects. The experiments on the Visual Relationship Dataset show that the use of logical constraints outperforms the current methods. This implies that background knowledge can be used to alleviate the incompleteness of training sets.
Single Reference Image based Scene Relighting via Material Guided Filtering
Aug 23, 2017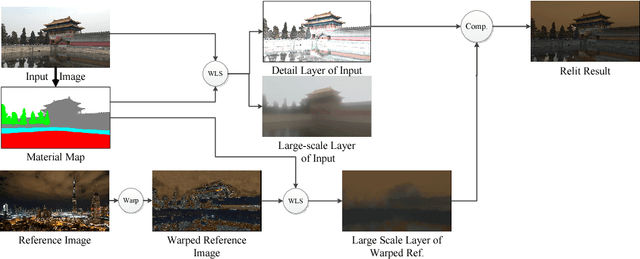
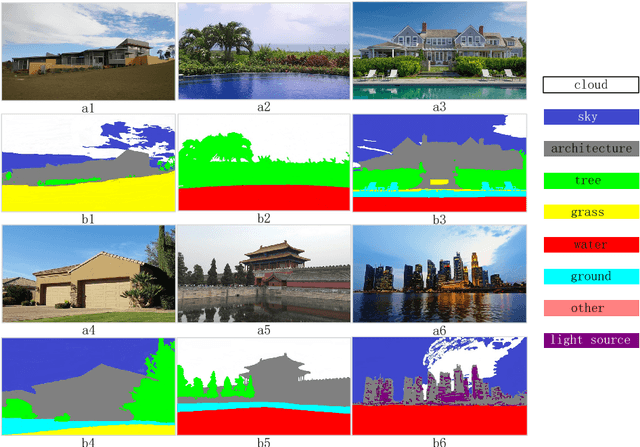


Image relighting is to change the illumination of an image to a target illumination effect without known the original scene geometry, material information and illumination condition. We propose a novel outdoor scene relighting method, which needs only a single reference image and is based on material constrained layer decomposition. Firstly, the material map is extracted from the input image. Then, the reference image is warped to the input image through patch match based image warping. Lastly, the input image is relit using material constrained layer decomposition. The experimental results reveal that our method can produce similar illumination effect as that of the reference image on the input image using only a single reference image.
3D Vehicle Detection Using Camera and Low-Resolution LiDAR
May 04, 2021
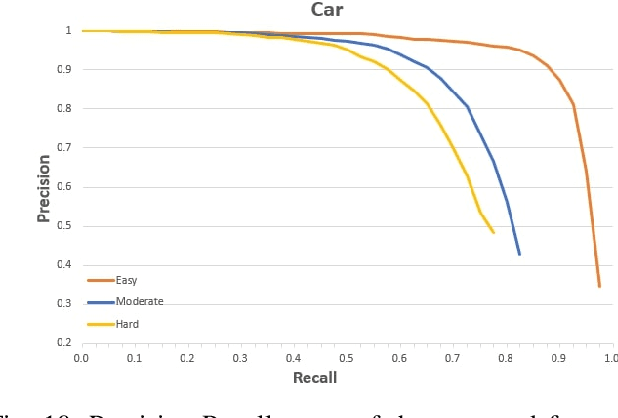
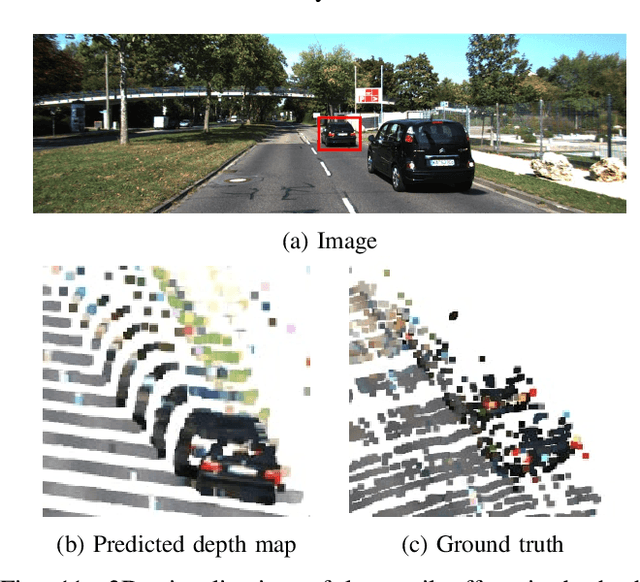
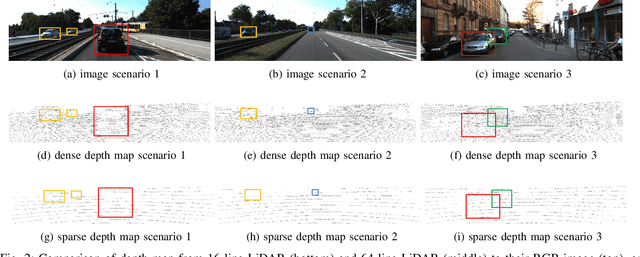
Nowadays, Light Detection And Ranging (LiDAR) has been widely used in autonomous vehicles for perception and localization. However, the cost of a high-resolution LiDAR is still prohibitively expensive, while its low-resolution counterpart is much more affordable. Therefore, using low-resolution LiDAR for autonomous driving perception tasks instead of high-resolution LiDAR is an economically feasible solution. In this paper, we propose a novel framework for 3D object detection in Bird-Eye View (BEV) using a low-resolution LiDAR and a monocular camera. Taking the low-resolution LiDAR point cloud and the monocular image as input, our depth completion network is able to produce dense point cloud that is subsequently processed by a voxel-based network for 3D object detection. Evaluated with KITTI dataset, the experimental results shows that the proposed approach performs significantly better than directly applying the 16-line LiDAR point cloud for object detection. For both easy and moderate cases, our detection results are comparable to those from 64-line high-resolution LiDAR. The network architecture and performance evaluations are analyzed in detail.
How Convolutional Neural Networks Deal with Aliasing
Feb 15, 2021
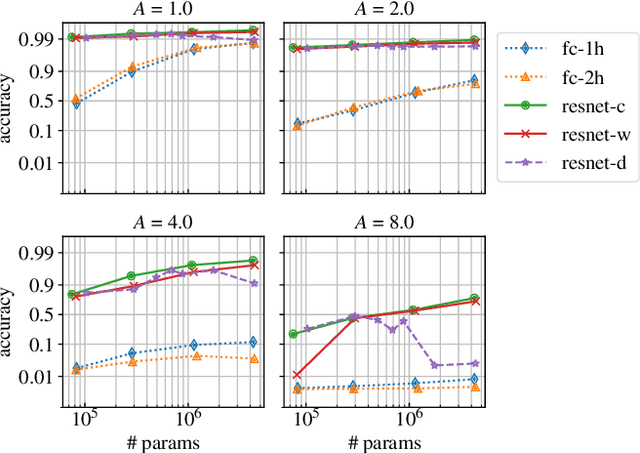
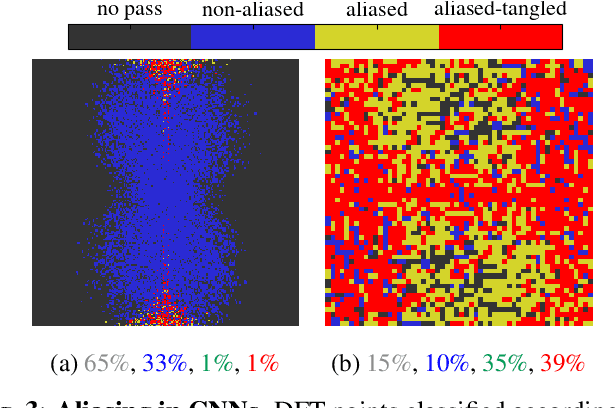
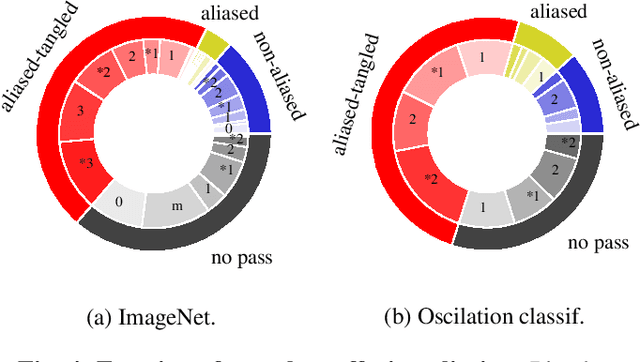
The convolutional neural network (CNN) remains an essential tool in solving computer vision problems. Standard convolutional architectures consist of stacked layers of operations that progressively downscale the image. Aliasing is a well-known side-effect of downsampling that may take place: it causes high-frequency components of the original signal to become indistinguishable from its low-frequency components. While downsampling takes place in the max-pooling layers or in the strided-convolutions in these models, there is no explicit mechanism that prevents aliasing from taking place in these layers. Due to the impressive performance of these models, it is natural to suspect that they, somehow, implicitly deal with this distortion. The question we aim to answer in this paper is simply: "how and to what extent do CNNs counteract aliasing?" We explore the question by means of two examples: In the first, we assess the CNNs capability of distinguishing oscillations at the input, showing that the redundancies in the intermediate channels play an important role in succeeding at the task; In the second, we show that an image classifier CNN while, in principle, capable of implementing anti-aliasing filters, does not prevent aliasing from taking place in the intermediate layers.
An Enriched Automated PV Registry: Combining Image Recognition and 3D Building Data
Dec 07, 2020
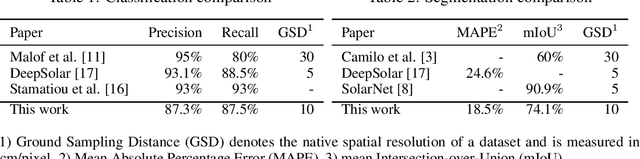
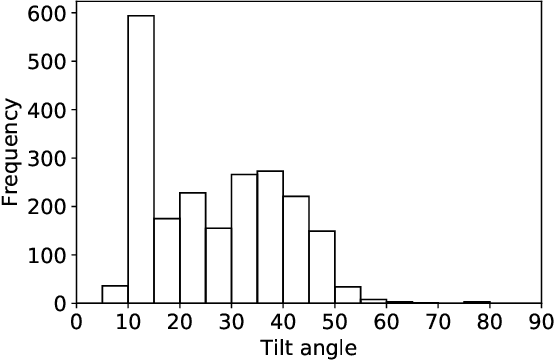

While photovoltaic (PV) systems are installed at an unprecedented rate, reliable information on an installation level remains scarce. As a result, automatically created PV registries are a timely contribution to optimize grid planning and operations. This paper demonstrates how aerial imagery and three-dimensional building data can be combined to create an address-level PV registry, specifying area, tilt, and orientation angles. We demonstrate the benefits of this approach for PV capacity estimation. In addition, this work presents, for the first time, a comparison between automated and officially-created PV registries. Our results indicate that our enriched automated registry proves to be useful to validate, update, and complement official registries.
Pyramid Vision Transformer: A Versatile Backbone for Dense Prediction without Convolutions
Feb 24, 2021
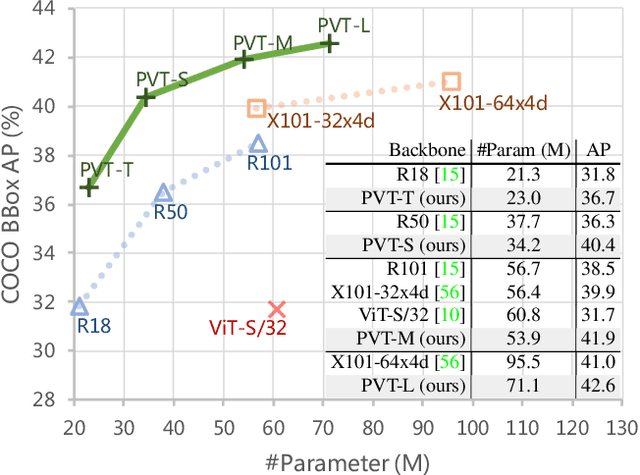
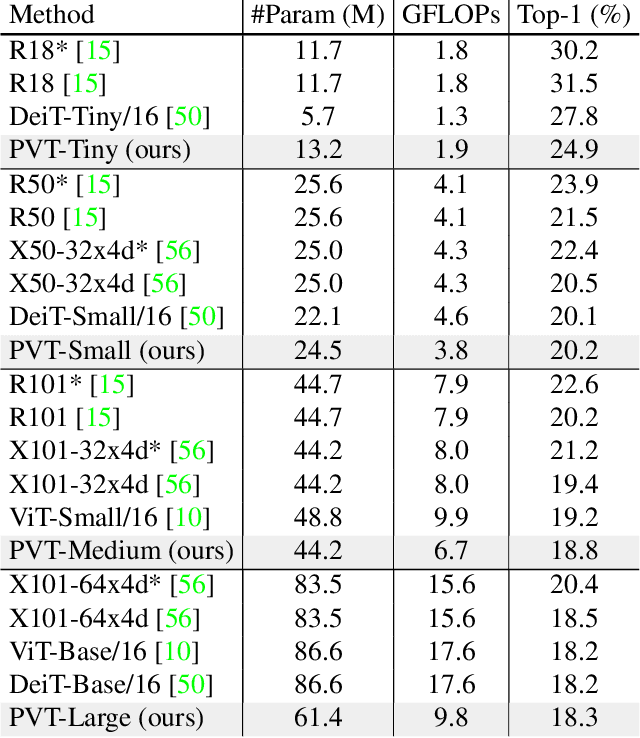
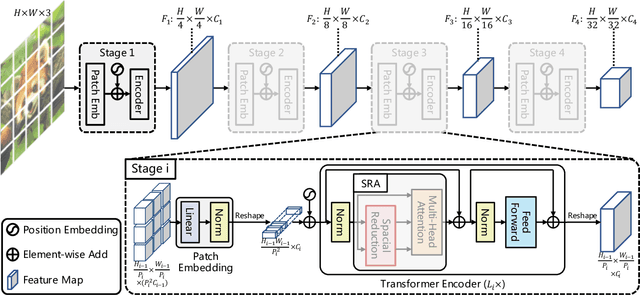
Although using convolutional neural networks (CNNs) as backbones achieves great successes in computer vision, this work investigates a simple backbone network useful for many dense prediction tasks without convolutions. Unlike the recently-proposed Transformer model (e.g., ViT) that is specially designed for image classification, we propose Pyramid Vision Transformer~(PVT), which overcomes the difficulties of porting Transformer to various dense prediction tasks. PVT has several merits compared to prior arts. (1) Different from ViT that typically has low-resolution outputs and high computational and memory cost, PVT can be not only trained on dense partitions of the image to achieve high output resolution, which is important for dense predictions but also using a progressive shrinking pyramid to reduce computations of large feature maps. (2) PVT inherits the advantages from both CNN and Transformer, making it a unified backbone in various vision tasks without convolutions by simply replacing CNN backbones. (3) We validate PVT by conducting extensive experiments, showing that it boosts the performance of many downstream tasks, e.g., object detection, semantic, and instance segmentation. For example, with a comparable number of parameters, RetinaNet+PVT achieves 40.4 AP on the COCO dataset, surpassing RetinNet+ResNet50 (36.3 AP) by 4.1 absolute AP. We hope PVT could serve as an alternative and useful backbone for pixel-level predictions and facilitate future researches. Code is available at https://github.com/whai362/PVT.
Properties of the After Kernel
May 21, 2021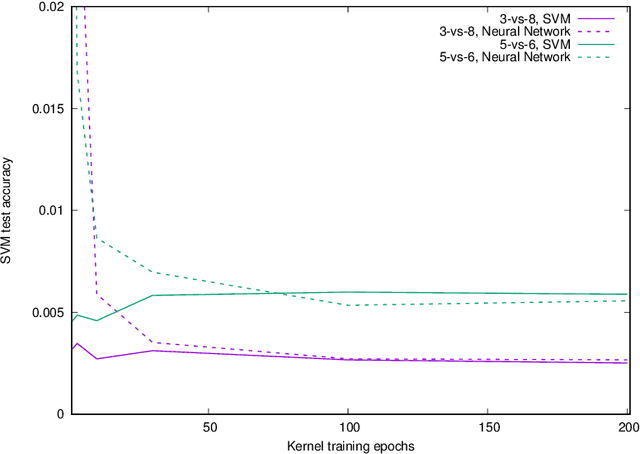
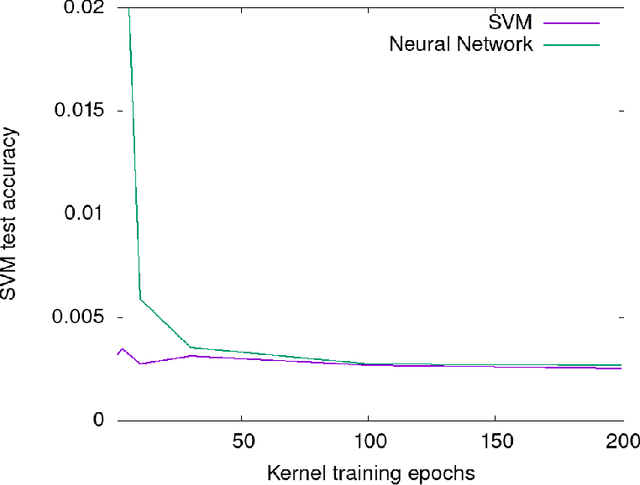
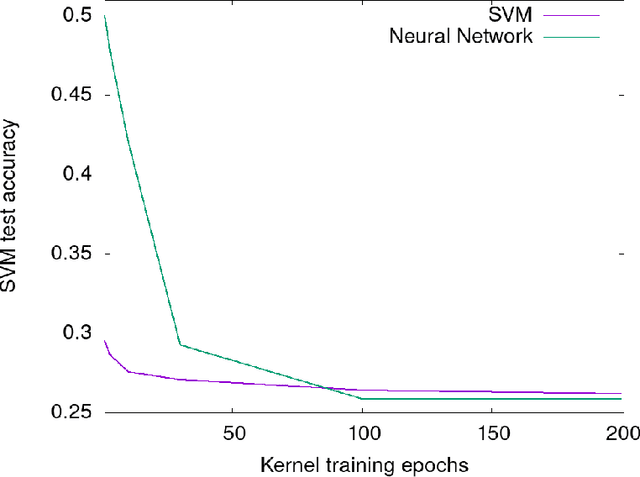
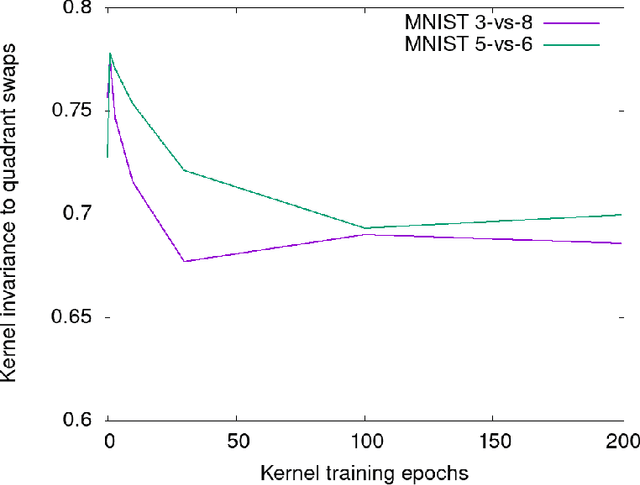
The Neural Tangent Kernel (NTK) is the wide-network limit of a kernel defined using neural networks at initialization, whose embedding is the gradient of the output of the network with respect to its parameters. We study the "after kernel", which is defined using the same embedding, except after training, for neural networks with standard architectures, on binary classification problems extracted from MNIST and CIFAR-10, trained using SGD in a standard way. Lyu and Li described a sense in which neural networks, under certain conditions, are equivalent to SVM with the after kernel. Our experiments are consistent with this proposition under natural conditions. For networks with an architecure similar to VGG, the after kernel is more "global", in the sense that it is less invariant to transformations of input images that disrupt the global structure of the image while leaving the local statistics largely intact. For fully connected networks, the after kernel is less global in this sense. The after kernel tends to be more invariant to small shifts, rotations and zooms; data augmentation does not improve these invariances. The (finite approximation to the) conjugate kernel, obtained using the last layer of hidden nodes, sometimes, but not always, provides a good approximation to the NTK and the after kernel.
Security Consideration For Deep Learning-Based Image Forensics
Apr 03, 2018

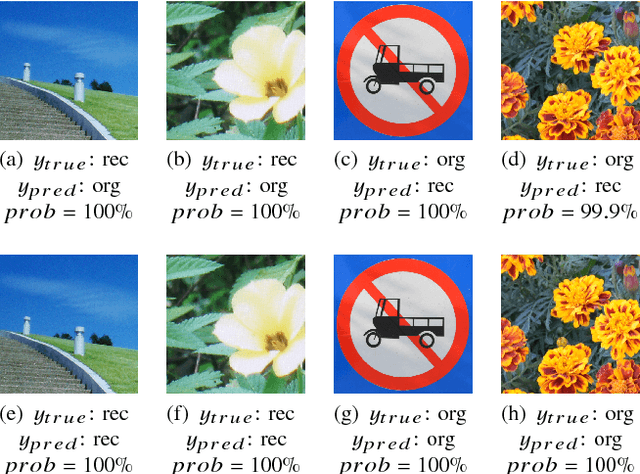
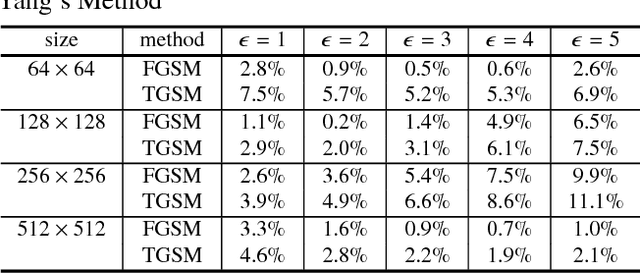
Recently, image forensics community has paied attention to the research on the design of effective algorithms based on deep learning technology and facts proved that combining the domain knowledge of image forensics and deep learning would achieve more robust and better performance than the traditional schemes. Instead of improving it, in this paper, the safety of deep learning based methods in the field of image forensics is taken into account. To the best of our knowledge, this is a first work focusing on this topic. Specifically, we experimentally find that the method using deep learning would fail when adding the slight noise into the images (adversarial images). Furthermore, two kinds of strategys are proposed to enforce security of deep learning-based method. Firstly, an extra penalty term to the loss function is added, which is referred to the 2-norm of the gradient of the loss with respect to the input images, and then an novel training method are adopt to train the model by fusing the normal and adversarial images. Experimental results show that the proposed algorithm can achieve good performance even in the case of adversarial images and provide a safety consideration for deep learning-based image forensics
Optical Flow Super-Resolution Based on Image Guidence Using Convolutional Neural Network
Sep 03, 2018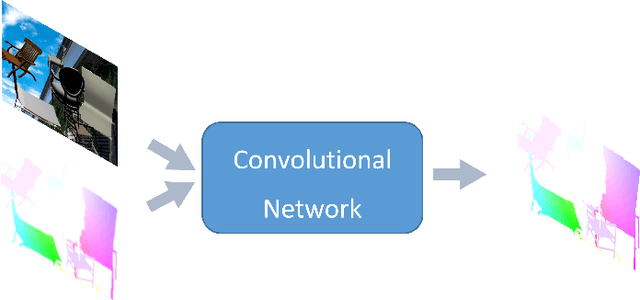
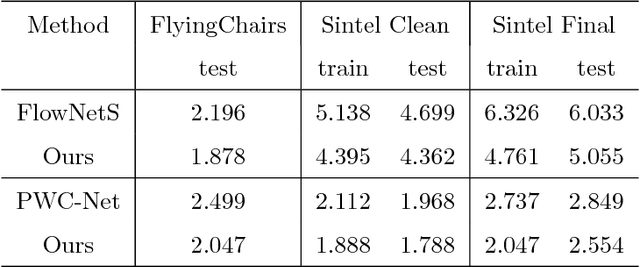
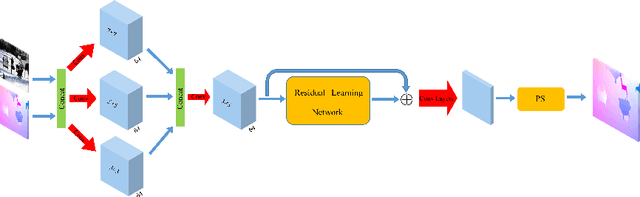
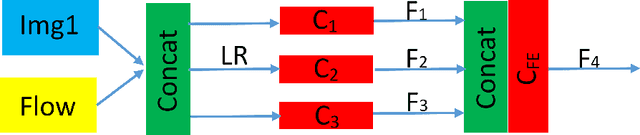
The convolutional neural network model for optical flow estimation usually outputs a low-resolution(LR) optical flow field. To obtain the corresponding full image resolution,interpolation and variational approach are the most common options, which do not effectively improve the results. With the motivation of various convolutional neural network(CNN) structures succeeded in single image super-resolution(SISR) task, an end-to-end convolutional neural network is proposed to reconstruct the high resolution(HR) optical flow field from initial LR optical flow with the guidence of the first frame used in optical flow estimation. Our optical flow super-resolution(OFSR) problem differs from the general SISR problem in two main aspects. Firstly, the optical flow includes less texture information than image so that the SISR CNN structures can't be directly used in our OFSR problem. Secondly, the initial LR optical flow data contains estimation error, while the LR image data for SISR is generally a bicubic downsampled, blurred, and noisy version of HR ground truth. We evaluate the proposed approach on two different optical flow estimation mehods and show that it can not only obtain the full image resolution, but generate more accurate optical flow field (Accuracy improve 15% on FlyingChairs, 13% on MPI Sintel) with sharper edges than the estimation result of original method.
Adversarial Robustness Across Representation Spaces
Dec 01, 2020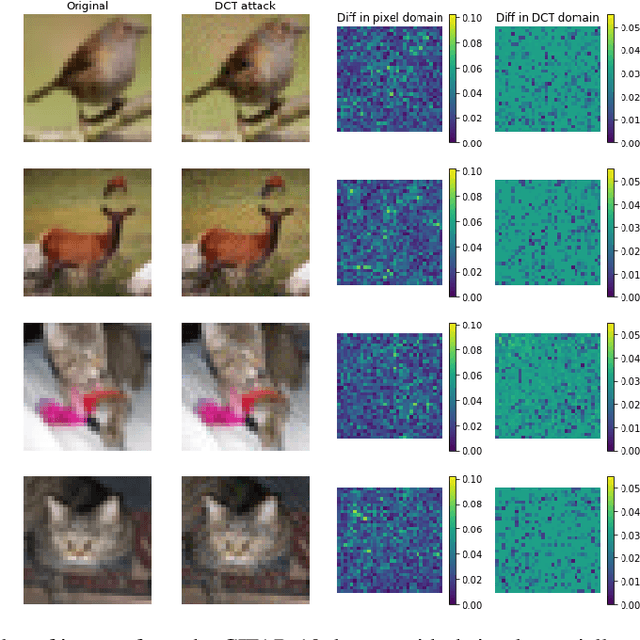
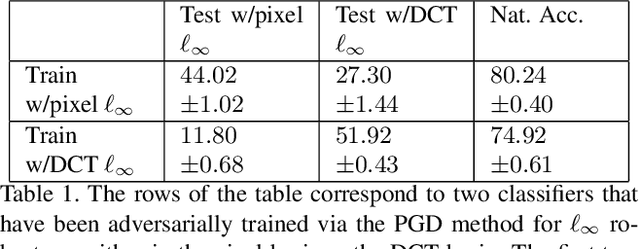

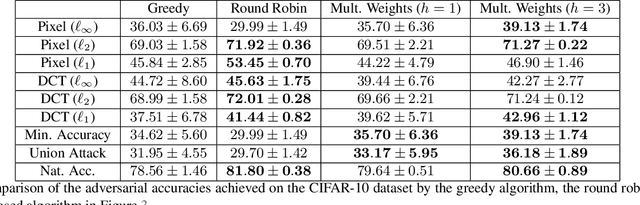
Adversarial robustness corresponds to the susceptibility of deep neural networks to imperceptible perturbations made at test time. In the context of image tasks, many algorithms have been proposed to make neural networks robust to adversarial perturbations made to the input pixels. These perturbations are typically measured in an $\ell_p$ norm. However, robustness often holds only for the specific attack used for training. In this work we extend the above setting to consider the problem of training of deep neural networks that can be made simultaneously robust to perturbations applied in multiple natural representation spaces. For the case of image data, examples include the standard pixel representation as well as the representation in the discrete cosine transform~(DCT) basis. We design a theoretically sound algorithm with formal guarantees for the above problem. Furthermore, our guarantees also hold when the goal is to require robustness with respect to multiple $\ell_p$ norm based attacks. We then derive an efficient practical implementation and demonstrate the effectiveness of our approach on standard datasets for image classification.