 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Learning Semantic Concepts and Order for Image and Sentence Matching
Dec 06, 2017
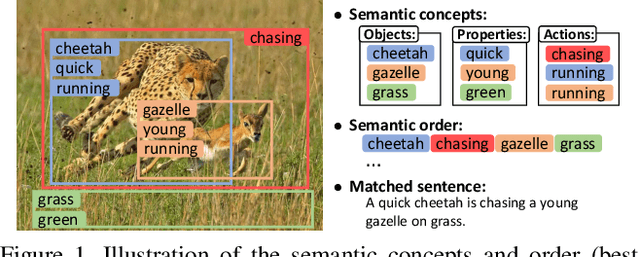
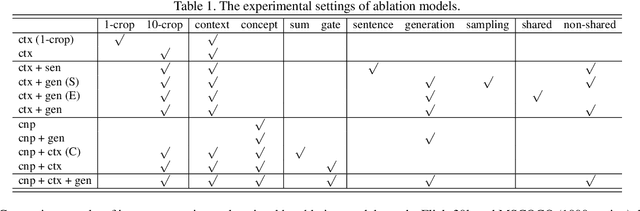
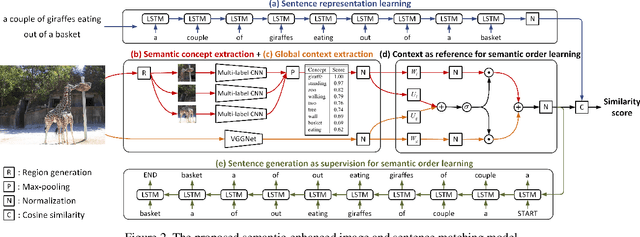
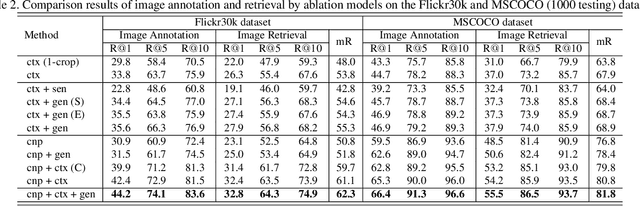
Image and sentence matching has made great progress recently, but it remains challenging due to the large visual-semantic discrepancy. This mainly arises from that the representation of pixel-level image usually lacks of high-level semantic information as in its matched sentence. In this work, we propose a semantic-enhanced image and sentence matching model, which can improve the image representation by learning semantic concepts and then organizing them in a correct semantic order. Given an image, we first use a multi-regional multi-label CNN to predict its semantic concepts, including objects, properties, actions, etc. Then, considering that different orders of semantic concepts lead to diverse semantic meanings, we use a context-gated sentence generation scheme for semantic order learning. It simultaneously uses the image global context containing concept relations as reference and the groundtruth semantic order in the matched sentence as supervision. After obtaining the improved image representation, we learn the sentence representation with a conventional LSTM, and then jointly perform image and sentence matching and sentence generation for model learning. Extensive experiments demonstrate the effectiveness of our learned semantic concepts and order, by achieving the state-of-the-art results on two public benchmark datasets.
High-Resolution Complex Scene Synthesis with Transformers
May 13, 2021
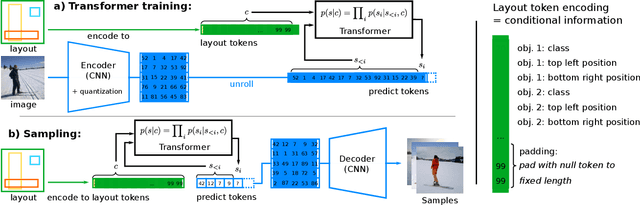
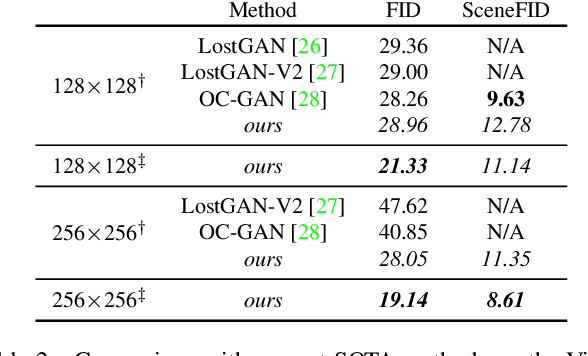

The use of coarse-grained layouts for controllable synthesis of complex scene images via deep generative models has recently gained popularity. However, results of current approaches still fall short of their promise of high-resolution synthesis. We hypothesize that this is mostly due to the highly engineered nature of these approaches which often rely on auxiliary losses and intermediate steps such as mask generators. In this note, we present an orthogonal approach to this task, where the generative model is based on pure likelihood training without additional objectives. To do so, we first optimize a powerful compression model with adversarial training which learns to reconstruct its inputs via a discrete latent bottleneck and thereby effectively strips the latent representation of high-frequency details such as texture. Subsequently, we train an autoregressive transformer model to learn the distribution of the discrete image representations conditioned on a tokenized version of the layouts. Our experiments show that the resulting system is able to synthesize high-quality images consistent with the given layouts. In particular, we improve the state-of-the-art FID score on COCO-Stuff and on Visual Genome by up to 19% and 53% and demonstrate the synthesis of images up to 512 x 512 px on COCO and Open Images.
Robust Trust Region for Weakly Supervised Segmentation
Apr 05, 2021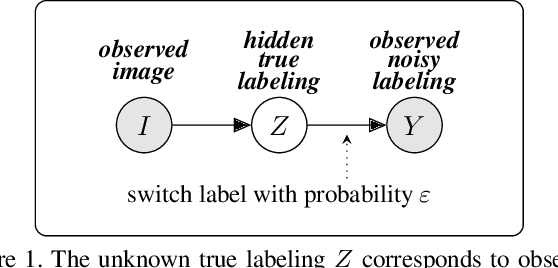
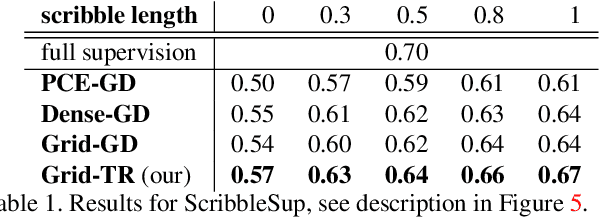

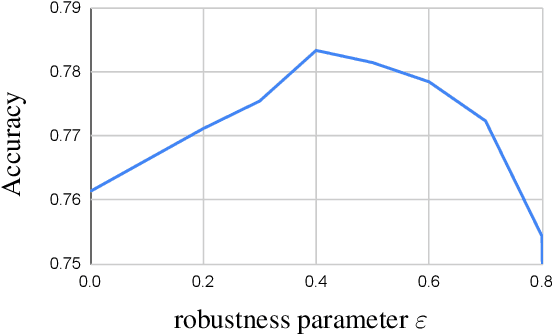
Acquisition of training data for the standard semantic segmentation is expensive if requiring that each pixel is labeled. Yet, current methods significantly deteriorate in weakly supervised settings, e.g. where a fraction of pixels is labeled or when only image-level tags are available. It has been shown that regularized losses - originally developed for unsupervised low-level segmentation and representing geometric priors on pixel labels - can considerably improve the quality of weakly supervised training. However, many common priors require optimization stronger than gradient descent. Thus, such regularizers have limited applicability in deep learning. We propose a new robust trust region approach for regularized losses improving the state-of-the-art results. Our approach can be seen as a higher-order generalization of the classic chain rule. It allows neural network optimization to use strong low-level solvers for the corresponding regularizers, including discrete ones.
A Perceptual Model for Eccentricity-dependent Spatio-temporal Flicker Fusion and its Applications to Foveated Graphics
May 05, 2021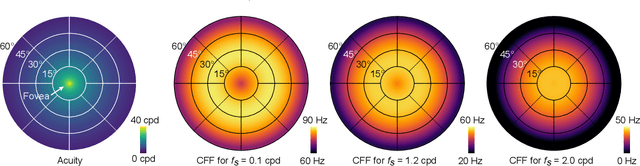
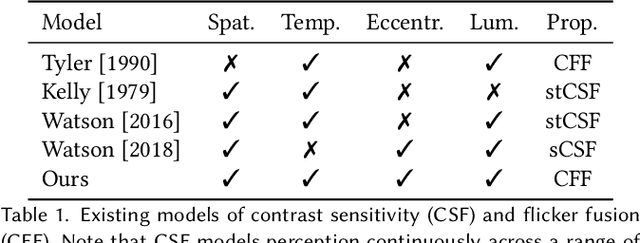

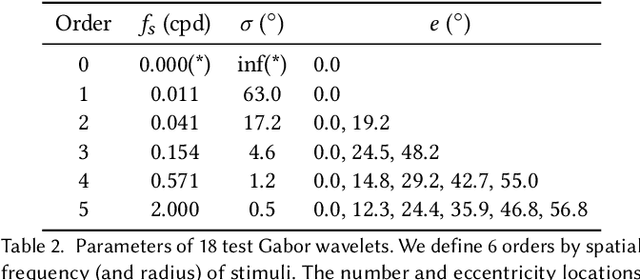
Virtual and augmented reality (VR/AR) displays strive to provide a resolution, framerate and field of view that matches the perceptual capabilities of the human visual system, all while constrained by limited compute budgets and transmission bandwidths of wearable computing systems. Foveated graphics techniques have emerged that could achieve these goals by exploiting the falloff of spatial acuity in the periphery of the visual field. However, considerably less attention has been given to temporal aspects of human vision, which also vary across the retina. This is in part due to limitations of current eccentricity-dependent models of the visual system. We introduce a new model, experimentally measuring and computationally fitting eccentricity-dependent critical flicker fusion thresholds jointly for both space and time. In this way, our model is unique in enabling the prediction of temporal information that is imperceptible for a certain spatial frequency, eccentricity, and range of luminance levels. We validate our model with an image quality user study, and use it to predict potential bandwidth savings 7x higher than those afforded by current spatial-only foveated models. As such, this work forms the enabling foundation for new temporally foveated graphics techniques.
Backdoor Attacks on Self-Supervised Learning
May 21, 2021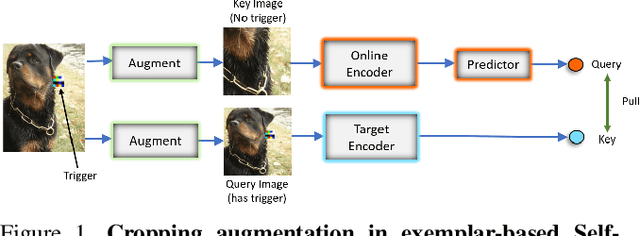
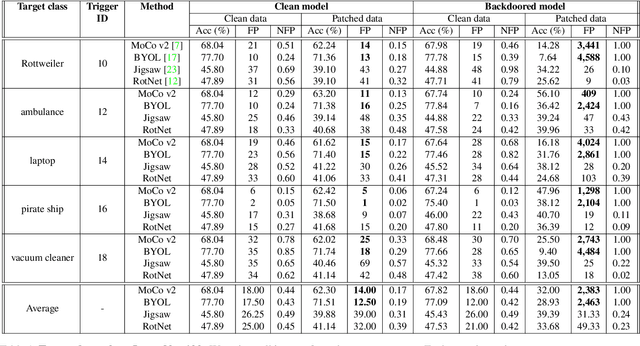
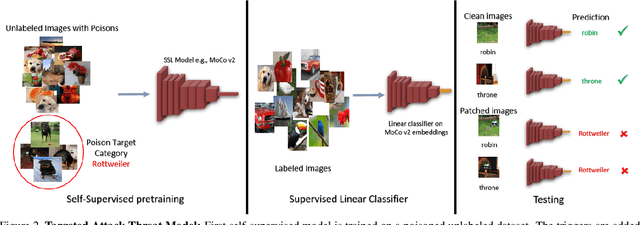
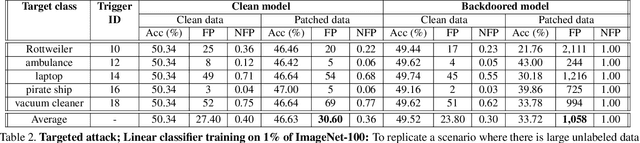
Large-scale unlabeled data has allowed recent progress in self-supervised learning methods that learn rich visual representations. State-of-the-art self-supervised methods for learning representations from images (MoCo and BYOL) use an inductive bias that different augmentations (e.g. random crops) of an image should produce similar embeddings. We show that such methods are vulnerable to backdoor attacks where an attacker poisons a part of the unlabeled data by adding a small trigger (known to the attacker) to the images. The model performance is good on clean test images but the attacker can manipulate the decision of the model by showing the trigger at test time. Backdoor attacks have been studied extensively in supervised learning and to the best of our knowledge, we are the first to study them for self-supervised learning. Backdoor attacks are more practical in self-supervised learning since the unlabeled data is large and as a result, an inspection of the data to avoid the presence of poisoned data is prohibitive. We show that in our targeted attack, the attacker can produce many false positives for the target category by using the trigger at test time. We also propose a knowledge distillation based defense algorithm that succeeds in neutralizing the attack. Our code is available here: https://github.com/UMBCvision/SSL-Backdoor .
Descriptive analysis of computational methods for automating mammograms with practical applications
Oct 06, 2020
Mammography is a vital screening technique for early revealing and identification of breast cancer in order to assist to decrease mortality rate. Practical applications of mammograms are not limited to breast cancer revealing, identification ,but include task based lens design, image compression, image classification, content based image retrieval and a host of others. Mammography computational analysis methods are a useful tool for specialists to reveal hidden features and extract significant information in mammograms. Digital mammograms are mammography images available along with the conventional screen-film mammography to make automation of mammograms easier. In this paper, we descriptively discuss computational advancement in digital mammograms to serve as a compass for research and practice in the domain of computational mammography and related fields. The discussion focuses on research aiming at a variety of applications and automations of mammograms. It covers different perspectives on image pre-processing, feature extraction, application of mammograms, screen-film mammogram, digital mammogram and development of benchmark corpora for experimenting with digital mammograms.
OmniFlow: Human Omnidirectional Optical Flow
Apr 16, 2021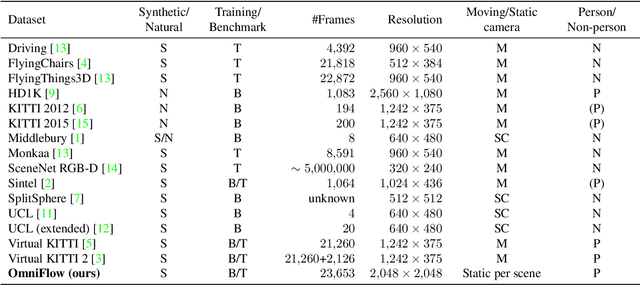
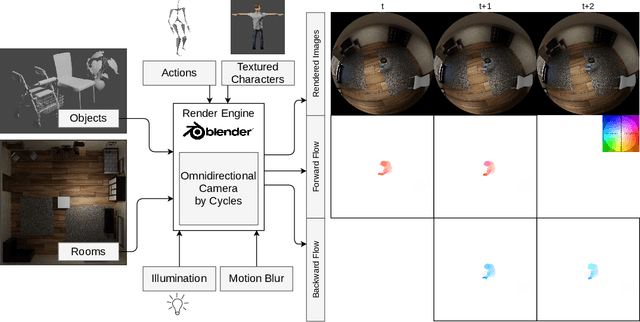
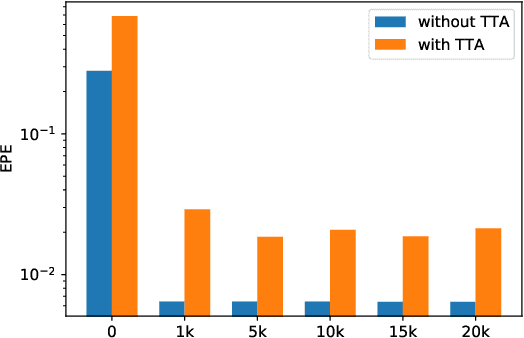
Optical flow is the motion of a pixel between at least two consecutive video frames and can be estimated through an end-to-end trainable convolutional neural network. To this end, large training datasets are required to improve the accuracy of optical flow estimation. Our paper presents OmniFlow: a new synthetic omnidirectional human optical flow dataset. Based on a rendering engine we create a naturalistic 3D indoor environment with textured rooms, characters, actions, objects, illumination and motion blur where all components of the environment are shuffled during the data capturing process. The simulation has as output rendered images of household activities and the corresponding forward and backward optical flow. To verify the data for training volumetric correspondence networks for optical flow estimation we train different subsets of the data and test on OmniFlow with and without Test-Time-Augmentation. As a result we have generated 23,653 image pairs and corresponding forward and backward optical flow. Our dataset can be downloaded from: https://mytuc.org/byfs
Adversarial Joint Image and Pose Distribution Learning for Camera Pose Regression and Refinement
Mar 26, 2019

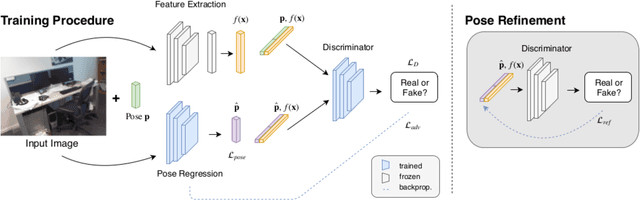
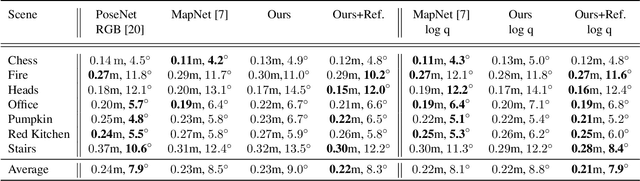
Despite recent advances on the topic of direct camera pose regression using neural networks, accurately estimating the camera pose of a single RGB image still remains a challenging task. To address this problem, we introduce a novel framework based, in its core, on the idea of modeling the joint distribution of RGB images and their corresponding camera poses using adversarial learning. Our method allows not only to regress the camera pose from a single image, however, also offers a solely RGB-based solution for camera pose refinement using the discriminator network. Further, we show that our method can effectively be used to optimize the predicted camera poses and thus improve the localization accuracy. To this end, we validate our proposed method on the publicly available 7-Scenes dataset improving upon the results of current state-of-the-art direct camera pose regression methods.
Heart Sound Classification Considering Additive Noise and Convolutional Distortion
Jun 03, 2021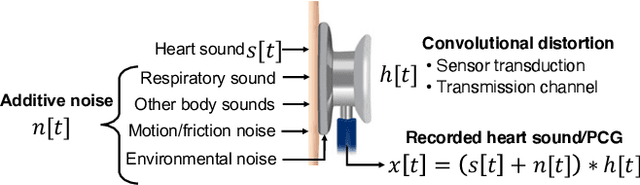
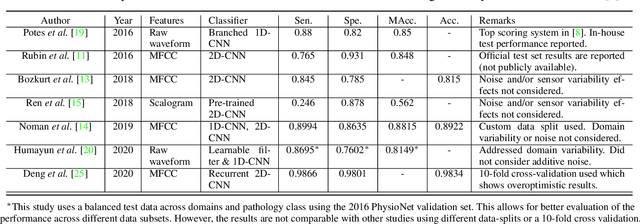
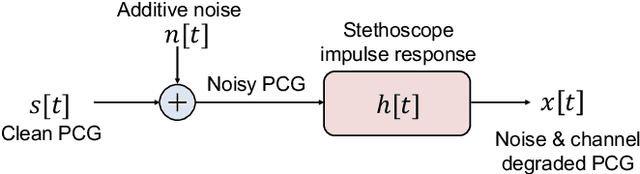

Cardiac auscultation is an essential point-of-care method used for the early diagnosis of heart diseases. Automatic analysis of heart sounds for abnormality detection is faced with the challenges of additive noise and sensor-dependent degradation. This paper aims to develop methods to address the cardiac abnormality detection problem when both types of distortions are present in the cardiac auscultation sound. We first mathematically analyze the effect of additive and convolutional noise on short-term filterbank-based features and a Convolutional Neural Network (CNN) layer. Based on the analysis, we propose a combination of linear and logarithmic spectrogram-image features. These 2D features are provided as input to a residual CNN network (ResNet) for heart sound abnormality detection. Experimental validation is performed on an open-access heart sound abnormality detection dataset involving noisy recordings obtained from multiple stethoscope sensors. The proposed method achieves significantly improved results compared to the conventional approaches, with an area under the ROC (receiver operating characteristics) curve (AUC) of 91.36%, F-1 score of 84.09%, and Macc (mean of sensitivity and specificity) of 85.08%. We also show that the proposed method shows the best mean accuracy across different source domains including stethoscope and noise variability, demonstrating its effectiveness in different recording conditions. The proposed combination of linear and logarithmic features along with the ResNet classifier effectively minimizes the impact of background noise and sensor variability for classifying phonocardiogram (PCG) signals. The proposed method paves the way towards developing computer-aided cardiac auscultation systems in noisy environments using low-cost stethoscopes.
Polynomial Networks in Deep Classifiers
Apr 16, 2021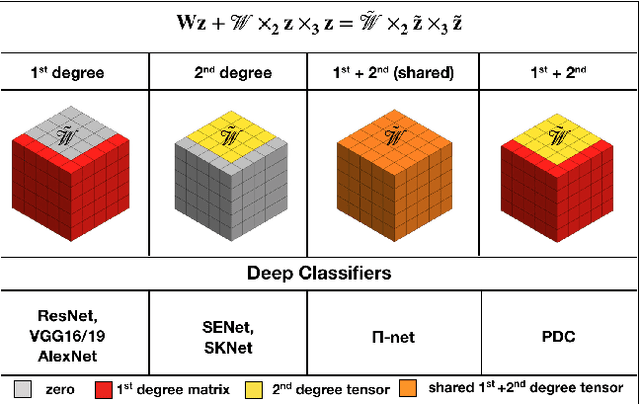
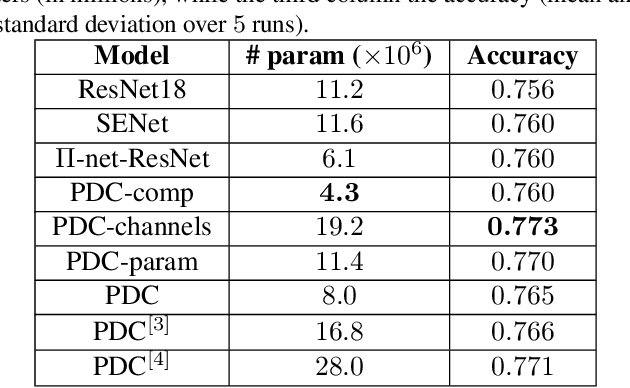
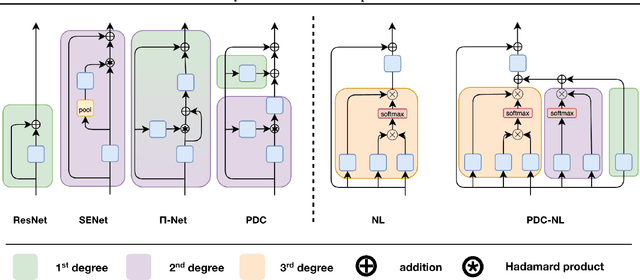
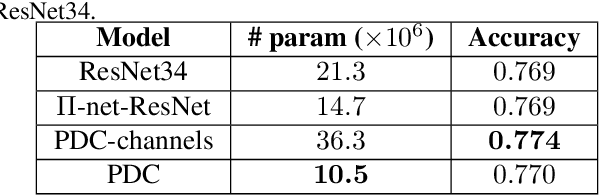
Deep neural networks have been the driving force behind the success in classification tasks, e.g., object and audio recognition. Impressive results and generalization have been achieved by a variety of recently proposed architectures, the majority of which are seemingly disconnected. In this work, we cast the study of deep classifiers under a unifying framework. In particular, we express state-of-the-art architectures (e.g., residual and non-local networks) in the form of different degree polynomials of the input. Our framework provides insights on the inductive biases of each model and enables natural extensions building upon their polynomial nature. The efficacy of the proposed models is evaluated on standard image and audio classification benchmarks. The expressivity of the proposed models is highlighted both in terms of increased model performance as well as model compression. Lastly, the extensions allowed by this taxonomy showcase benefits in the presence of limited data and long-tailed data distributions. We expect this taxonomy to provide links between existing domain-specific architectures.