 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Cross-modal Learning for Domain Adaptation in 3D Semantic Segmentation
Jan 18, 2021
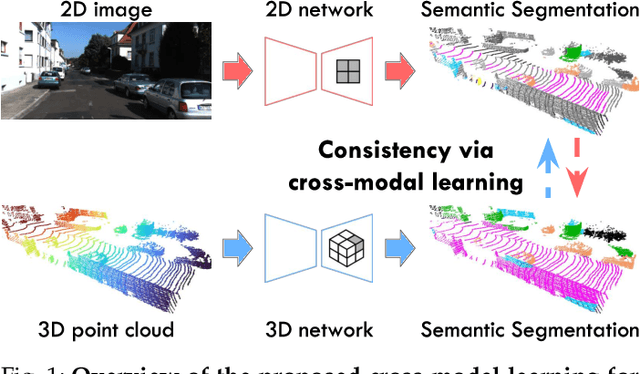
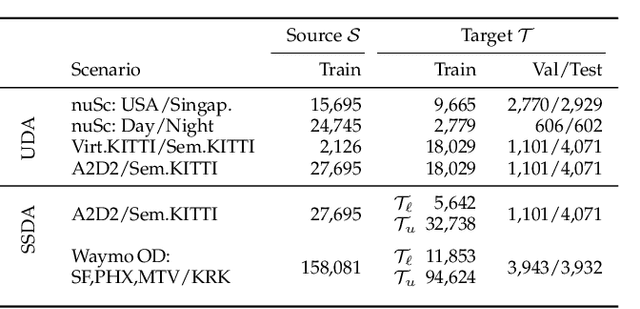
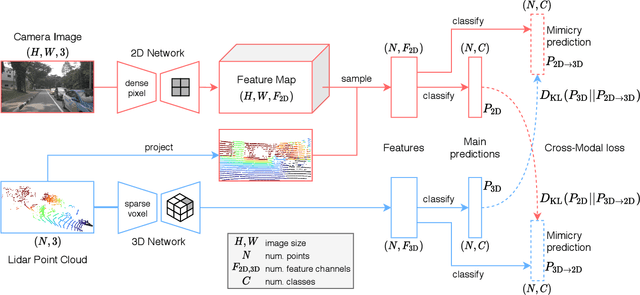
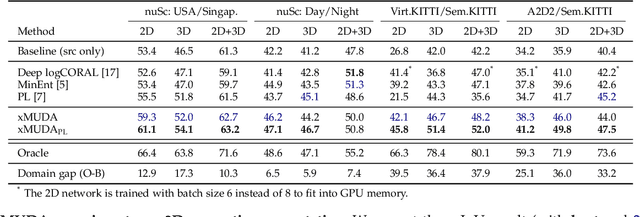
Domain adaptation is an important task to enable learning when labels are scarce. While most works focus only on the image modality, there are many important multi-modal datasets. In order to leverage multi-modality for domain adaptation, we propose cross-modal learning, where we enforce consistency between the predictions of two modalities via mutual mimicking. We constrain our network to make correct predictions on labeled data and consistent predictions across modalities on unlabeled target-domain data. Experiments in unsupervised and semi-supervised domain adaptation settings prove the effectiveness of this novel domain adaptation strategy. Specifically, we evaluate on the task of 3D semantic segmentation using the image and point cloud modality. We leverage recent autonomous driving datasets to produce a wide variety of domain adaptation scenarios including changes in scene layout, lighting, sensor setup and weather, as well as the synthetic-to-real setup. Our method significantly improves over previous uni-modal adaptation baselines on all adaption scenarios. Code will be made available.
Attention-Enhanced Cross-Task Network for Analysing Multiple Attributes of Lung Nodules in CT
Mar 05, 2021
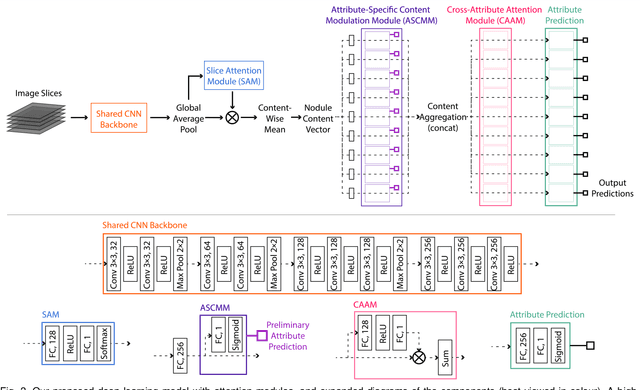
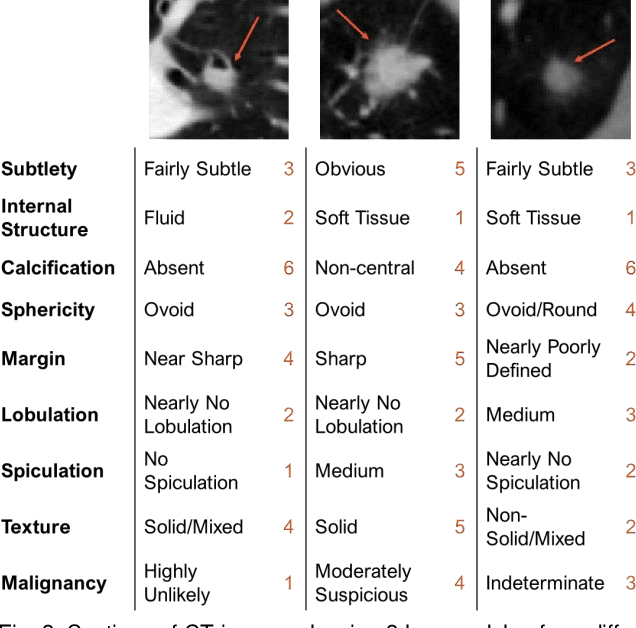
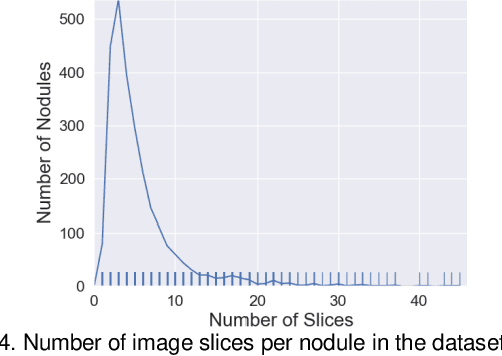
Accurate characterisation of visual attributes such as spiculation, lobulation, and calcification of lung nodules is critical in cancer management. The characterisation of these attributes is often subjective, which may lead to high inter- and intra-observer variability. Furthermore, lung nodules are often heterogeneous in the cross-sectional image slices of a 3D volume. Current state-of-the-art methods that score multiple attributes rely on deep learning-based multi-task learning (MTL) schemes. These methods, however, extract shared visual features across attributes and then examine each attribute without explicitly leveraging their inherent intercorrelations. Furthermore, current methods either treat each slice with equal importance without considering their relevance or heterogeneity, or restrict the number of input slices, which limits performance. In this study, we address these challenges with a new convolutional neural network (CNN)-based MTL model that incorporates attention modules to simultaneously score 9 visual attributes of lung nodules in computed tomography (CT) image volumes. Our model processes entire nodule volumes of arbitrary depth and uses a slice attention module to filter out irrelevant slices. We also introduce cross-attribute and attribute specialisation attention modules that learn an optimal amalgamation of meaningful representations to leverage relationships between attributes. We demonstrate that our model outperforms previous state-of-the-art methods at scoring attributes using the well-known public LIDC-IDRI dataset of pulmonary nodules from over 1,000 patients. Our attention modules also provide easy-to-interpret weights that offer insights into the predictions of the model.
From Points to Multi-Object 3D Reconstruction
Dec 21, 2020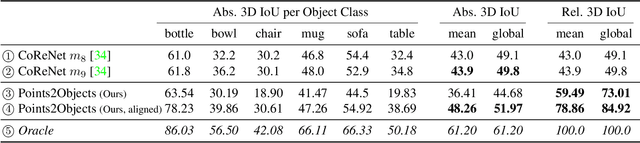
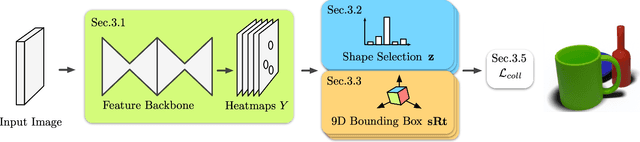

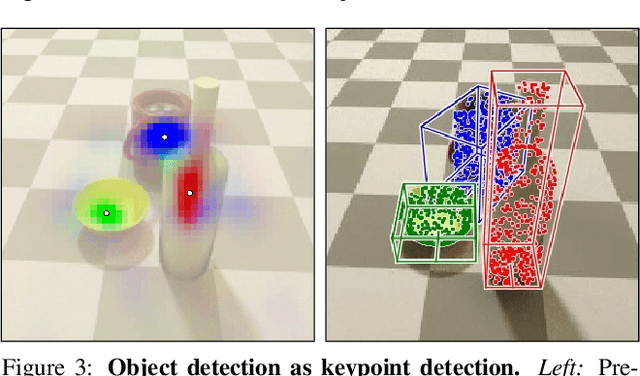
We propose a method to detect and reconstruct multiple 3D objects from a single RGB image. The key idea is to optimize for detection, alignment and shape jointly over all objects in the RGB image, while focusing on realistic and physically plausible reconstructions. To this end, we propose a keypoint detector that localizes objects as center points and directly predicts all object properties, including 9-DoF bounding boxes and 3D shapes -- all in a single forward pass. The proposed method formulates 3D shape reconstruction as a shape selection problem, i.e. it selects among exemplar shapes from a given database. This makes it agnostic to shape representations, which enables a lightweight reconstruction of realistic and visually-pleasing shapes based on CAD-models, while the training objective is formulated around point clouds and voxel representations. A collision-loss promotes non-intersecting objects, further increasing the reconstruction realism. Given the RGB image, the presented approach performs lightweight reconstruction in a single-stage, it is real-time capable, fully differentiable and end-to-end trainable. Our experiments compare multiple approaches for 9-DoF bounding box estimation, evaluate the novel shape-selection mechanism and compare to recent methods in terms of 3D bounding box estimation and 3D shape reconstruction quality.
Empty Cities: a Dynamic-Object-Invariant Space for Visual SLAM
Oct 15, 2020

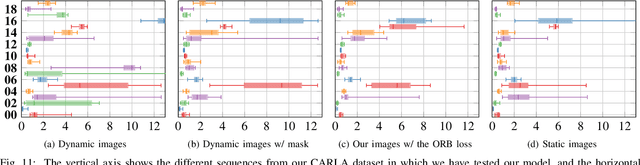
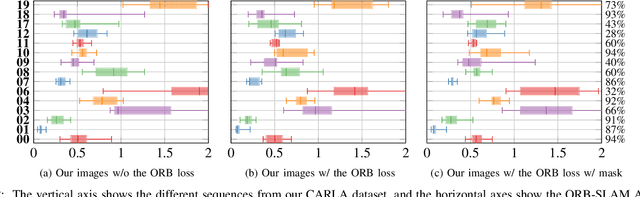
In this paper we present a data-driven approach to obtain the static image of a scene, eliminating dynamic objects that might have been present at the time of traversing the scene with a camera. The general objective is to improve vision-based localization and mapping tasks in dynamic environments, where the presence (or absence) of different dynamic objects in different moments makes these tasks less robust. We introduce an end-to-end deep learning framework to turn images of an urban environment that include dynamic content, such as vehicles or pedestrians, into realistic static frames suitable for localization and mapping. This objective faces two main challenges: detecting the dynamic objects, and inpainting the static occluded back-ground. The first challenge is addressed by the use of a convolutional network that learns a multi-class semantic segmentation of the image. The second challenge is approached with a generative adversarial model that, taking as input the original dynamic image and the computed dynamic/static binary mask, is capable of generating the final static image. This framework makes use of two new losses, one based on image steganalysis techniques, useful to improve the inpainting quality, and another one based on ORB features, designed to enhance feature matching between real and hallucinated image regions. To validate our approach, we perform an extensive evaluation on different tasks that are affected by dynamic entities, i.e., visual odometry, place recognition and multi-view stereo, with the hallucinated images. Code has been made available on https://github.com/bertabescos/EmptyCities_SLAM.
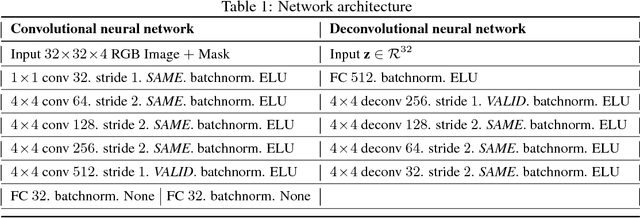
TextureWGAN: Texture Preserving WGAN with MLE Regularizer for Inverse Problems
Aug 12, 2020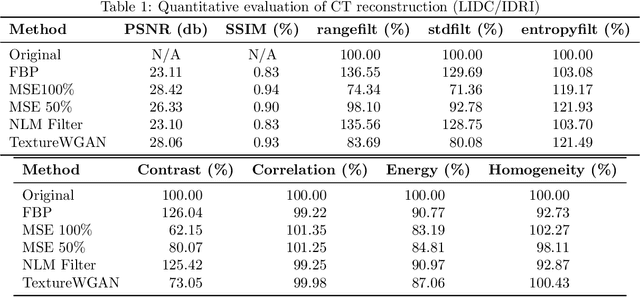
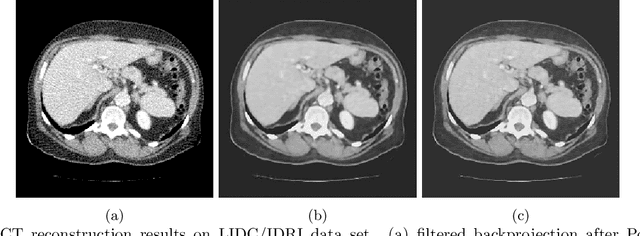
Many algorithms and methods have been proposed for inverse problems particularly with the recent surge of interest in machine learning and deep learning methods. Among all proposed methods, the most popular and effective method is the convolutional neural network (CNN) with mean square error (MSE). This method has been proven effective in super-resolution, image de-noising, and image reconstruction. However, this method is known to over-smooth images due to the nature of MSE. MSE based methods minimize Euclidean distance for all pixels between a baseline image and a generated image by CNN and ignore the spatial information of the pixels such as image texture. In this paper, we proposed a new method based on Wasserstein GAN (WGAN) for inverse problems. We showed that the WGAN-based method was effective to preserve image texture. It also used a maximum likelihood estimation (MLE) regularizer to preserve pixel fidelity. Maintaining image texture and pixel fidelity is the most important requirement for medical imaging. We used Peak Signal to Noise Ratio (PSNR) and Structure Similarity (SSIM) to evaluate the proposed method quantitatively. We also conducted first-order and second-order statistical image texture analysis to assess image texture.
Controllable Semantic Image Inpainting
Jun 15, 2018
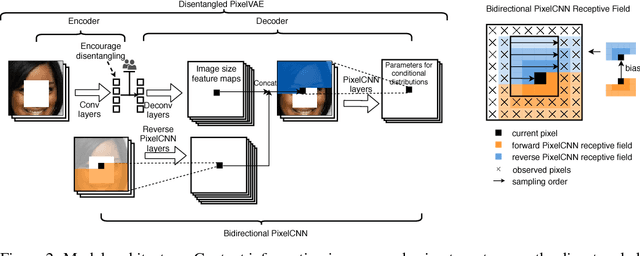

We develop a method for user-controllable semantic image inpainting: Given an arbitrary set of observed pixels, the unobserved pixels can be imputed in a user-controllable range of possibilities, each of which is semantically coherent and locally consistent with the observed pixels. We achieve this using a deep generative model bringing together: an encoder which can encode an arbitrary set of observed pixels, latent variables which are trained to represent disentangled factors of variations, and a bidirectional PixelCNN model. We experimentally demonstrate that our method can generate plausible inpainting results matching the user-specified semantics, but is still coherent with observed pixels. We justify our choices of architecture and training regime through more experiments.
Adaptive Deconvolution-based stereo matching Net for Local Stereo Matching
Jan 01, 2021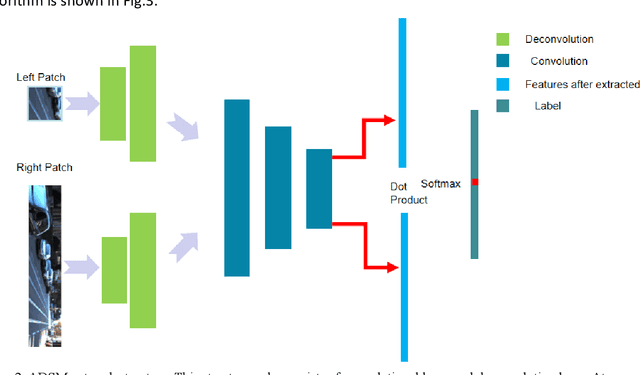
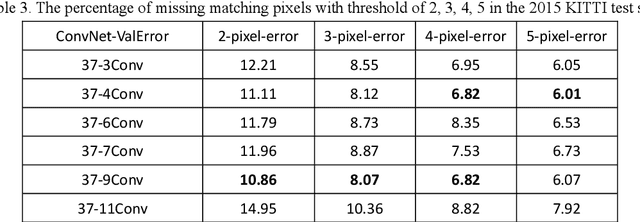
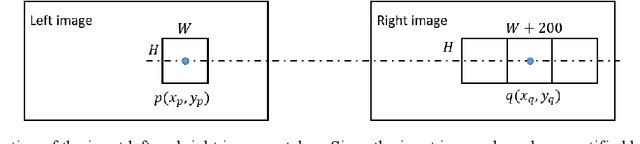
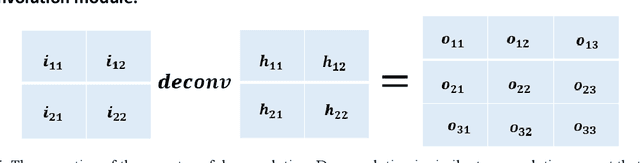
In deep learning-based local stereo matching methods, larger image patches usually bring better stereo matching accuracy. However, it is unrealistic to increase the size of the image patch size without restriction. Arbitrarily extending the patch size will change the local stereo matching method into the global stereo matching method, and the matching accuracy will be saturated. We simplified the existing Siamese convolutional network by reducing the number of network parameters and propose an efficient CNN based structure, namely Adaptive Deconvolution-based disparity matching Net (ADSM net) by adding deconvolution layers to learn how to enlarge the size of input feature map for the following convolution layers. Experimental results on the KITTI 2012 and 2015 datasets demonstrate that the proposed method can achieve a good trade-off between accuracy and complexity.
RGB-Topography and X-rays Image Registration for Idiopathic Scoliosis Children Patient Follow-up
Mar 20, 2020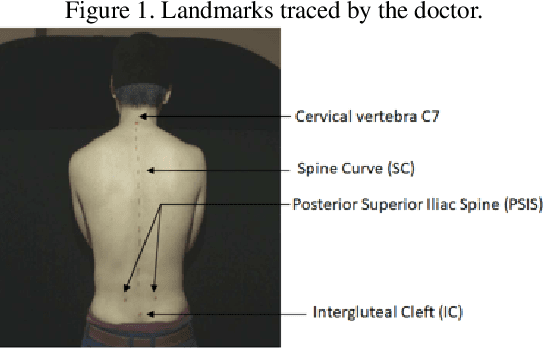

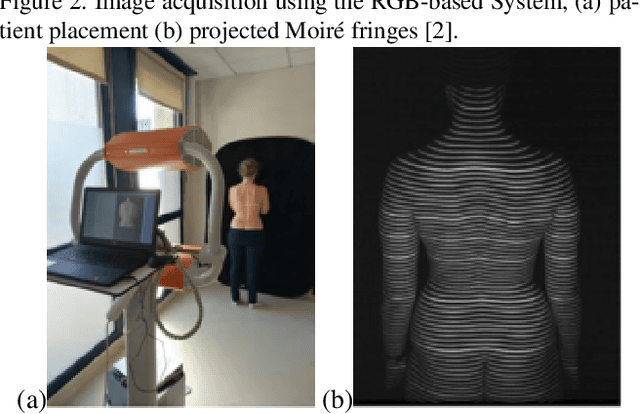
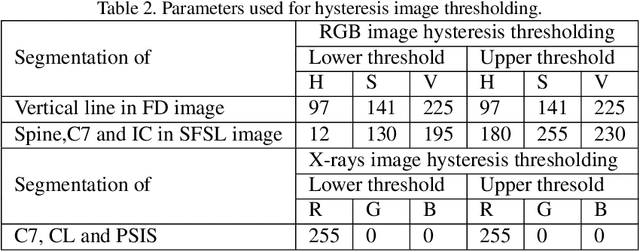
Children diagnosed with a scoliosis pathology are exposed during their follow up to ionic radiations in each X-rays diagnosis. This exposure can have negative effects on the patient's health and cause diseases in the adult age. In order to reduce X-rays scanning, recent systems provide diagnosis of scoliosis patients using solely RGB images. The output of such systems is a set of augmented images and scoliosis related angles. These angles, however, confuse the physicians due to their large number. Moreover, the lack of X-rays scans makes it impossible for the physician to compare RGB and X-rays images, and decide whether to reduce X-rays exposure or not. In this work, we exploit both RGB images of scoliosis captured during clinical diagnosis, and X-rays hard copies provided by patients in order to register both images and give a rich comparison of diagnoses. The work consists in, first, establishing the monomodal (RGB topography of the back) and multimodal (RGB and Xrays) image database, then registering images based on patient landmarks, and finally blending registered images for a visual analysis and follow up by the physician. The proposed registration is based on a rigid transformation that preserves the topology of the patient's back. Parameters of the rigid transformation are estimated using a proposed angle minimization of Cervical vertebra 7, and Posterior Superior Iliac Spine landmarks of a source and target diagnoses. Experiments conducted on the constructed database show a better monomodal and multimodal registration using our proposed method compared to registration using an Equation System Solving based registration.
CondenseNet V2: Sparse Feature Reactivation for Deep Networks
Apr 09, 2021



Reusing features in deep networks through dense connectivity is an effective way to achieve high computational efficiency. The recent proposed CondenseNet has shown that this mechanism can be further improved if redundant features are removed. In this paper, we propose an alternative approach named sparse feature reactivation (SFR), aiming at actively increasing the utility of features for reusing. In the proposed network, named CondenseNetV2, each layer can simultaneously learn to 1) selectively reuse a set of most important features from preceding layers; and 2) actively update a set of preceding features to increase their utility for later layers. Our experiments show that the proposed models achieve promising performance on image classification (ImageNet and CIFAR) and object detection (MS COCO) in terms of both theoretical efficiency and practical speed.
R2U3D: Recurrent Residual 3D U-Net for Lung Segmentation
May 05, 2021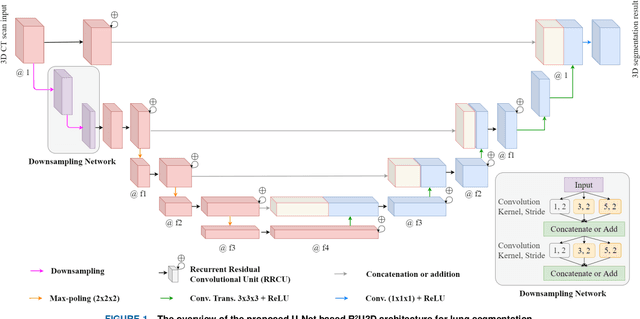
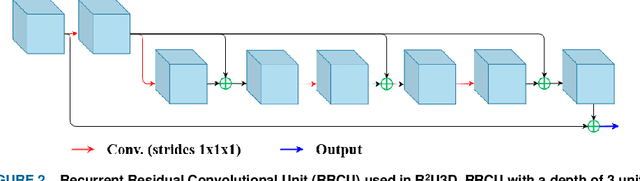
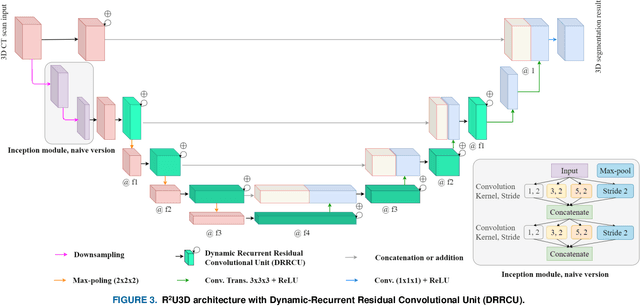
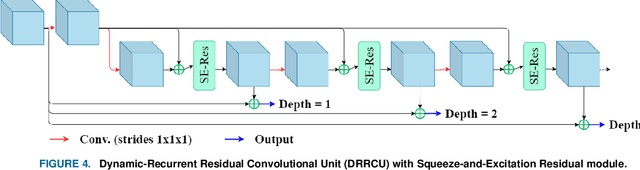
3D lung segmentation is essential since it processes the volumetric information of the lungs, removes the unnecessary areas of the scan, and segments the actual area of the lungs in a 3D volume. Recently, the deep learning model, such as U-Net outperforms other network architectures for biomedical image segmentation. In this paper, we propose a novel model, namely, Recurrent Residual 3D U-Net (R2U3D), for the 3D lung segmentation task. In particular, the proposed model integrates 3D convolution into the Recurrent Residual Neural Network based on U-Net. It helps learn spatial dependencies in 3D and increases the propagation of 3D volumetric information. The proposed R2U3D network is trained on the publicly available dataset LUNA16 and it achieves state-of-the-art performance on both LUNA16 (testing set) and VESSEL12 dataset. In addition, we show that training the R2U3D model with a smaller number of CT scans, i.e., 100 scans, without applying data augmentation achieves an outstanding result in terms of Soft Dice Similarity Coefficient (Soft-DSC) of 0.9920.