 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
"Weak AI" is Likely to Never Become "Strong AI", So What is its Greatest Value for us?
Mar 29, 2021
AI has surpassed humans across a variety of tasks such as image classification, playing games (e.g., go, "Starcraft" and poker), and protein structure prediction. However, at the same time, AI is also bearing serious controversies. Many researchers argue that little substantial progress has been made for AI in recent decades. In this paper, the author (1) explains why controversies about AI exist; (2) discriminates two paradigms of AI research, termed "weak AI" and "strong AI" (a.k.a. artificial general intelligence); (3) clarifies how to judge which paradigm a research work should be classified into; (4) discusses what is the greatest value of "weak AI" if it has no chance to develop into "strong AI".
RankSRGAN: Generative Adversarial Networks with Ranker for Image Super-Resolution
Aug 26, 2019
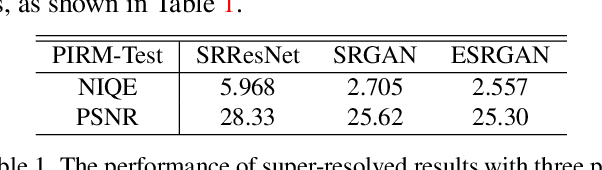
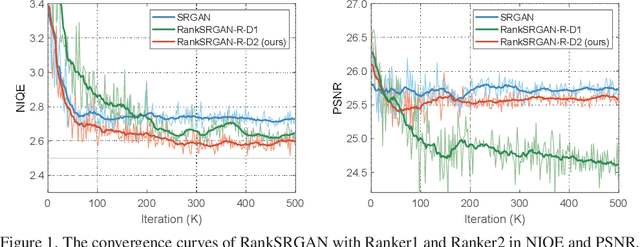
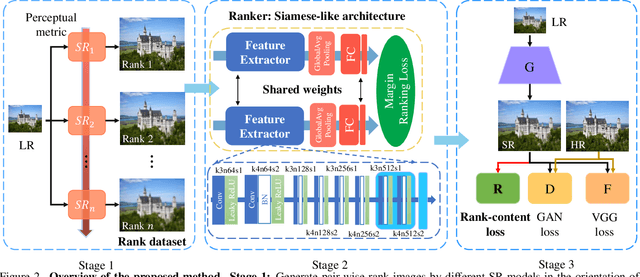
Generative Adversarial Networks (GAN) have demonstrated the potential to recover realistic details for single image super-resolution (SISR). To further improve the visual quality of super-resolved results, PIRM2018-SR Challenge employed perceptual metrics to assess the perceptual quality, such as PI, NIQE, and Ma. However, existing methods cannot directly optimize these indifferentiable perceptual metrics, which are shown to be highly correlated with human ratings. To address the problem, we propose Super-Resolution Generative Adversarial Networks with Ranker (RankSRGAN) to optimize generator in the direction of perceptual metrics. Specifically, we first train a Ranker which can learn the behavior of perceptual metrics and then introduce a novel rank-content loss to optimize the perceptual quality. The most appealing part is that the proposed method can combine the strengths of different SR methods to generate better results. Extensive experiments show that RankSRGAN achieves visually pleasing results and reaches state-of-the-art performance in perceptual metrics. Project page: https://wenlongzhang0724.github.io/Projects/RankSRGAN
SteganoGAN: Pushing the Limits of Image Steganography
Jan 12, 2019
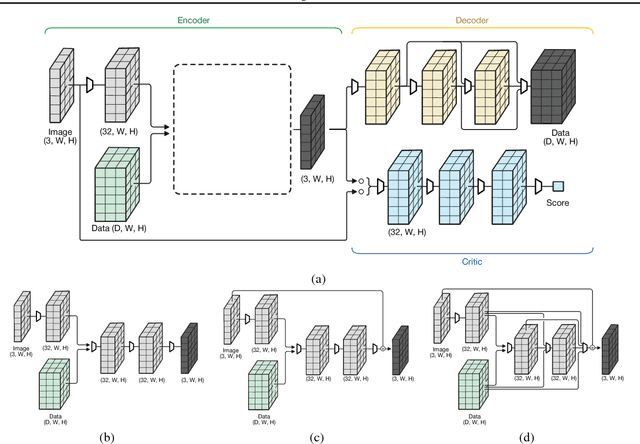

Image steganography is a procedure for hiding messages inside pictures. While other techniques such as cryptography aim to prevent adversaries from reading the secret message, steganography aims to hide the presence of the message itself. In this paper, we propose a novel technique based on generative adversarial networks for hiding arbitrary binary data in images. We show that our approach achieves state-of-the-art payloads of 4.4 bits per pixel, evades detection by steganalysis tools, and is effective on images from multiple datasets. To enable fair comparisons, we have released an open source library that is available online at https://github.com/DAI-Lab/SteganoGAN.
A Comprehensive Study of ImageNet Pre-Training for Historical Document Image Analysis
May 22, 2019


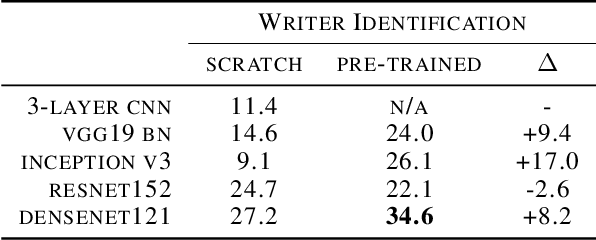
Automatic analysis of scanned historical documents comprises a wide range of image analysis tasks, which are often challenging for machine learning due to a lack of human-annotated learning samples. With the advent of deep neural networks, a promising way to cope with the lack of training data is to pre-train models on images from a different domain and then fine-tune them on historical documents. In the current research, a typical example of such cross-domain transfer learning is the use of neural networks that have been pre-trained on the ImageNet database for object recognition. It remains a mostly open question whether or not this pre-training helps to analyse historical documents, which have fundamentally different image properties when compared with ImageNet. In this paper, we present a comprehensive empirical survey on the effect of ImageNet pre-training for diverse historical document analysis tasks, including character recognition, style classification, manuscript dating, semantic segmentation, and content-based retrieval. While we obtain mixed results for semantic segmentation at pixel-level, we observe a clear trend across different network architectures that ImageNet pre-training has a positive effect on classification as well as content-based retrieval.
Do You Even Need Attention? A Stack of Feed-Forward Layers Does Surprisingly Well on ImageNet
May 06, 2021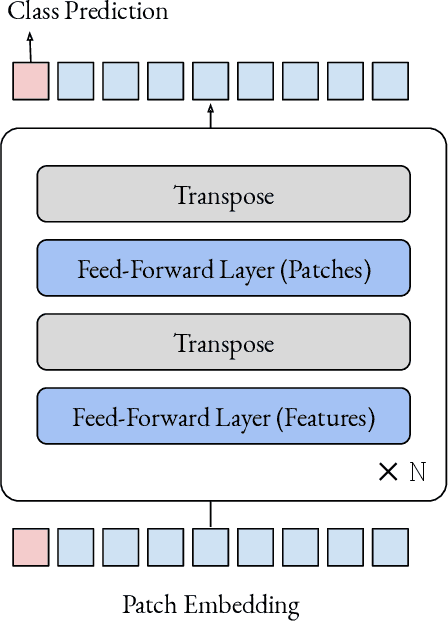
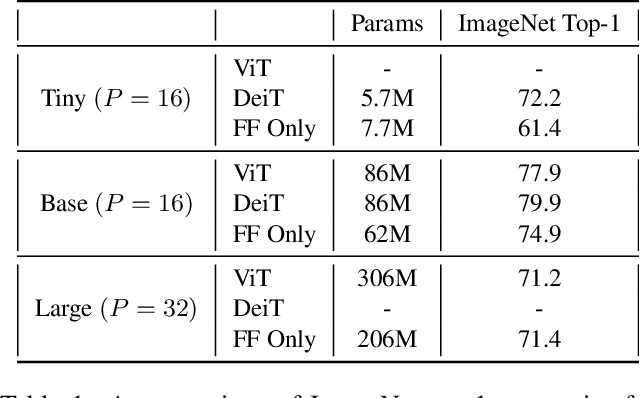

The strong performance of vision transformers on image classification and other vision tasks is often attributed to the design of their multi-head attention layers. However, the extent to which attention is responsible for this strong performance remains unclear. In this short report, we ask: is the attention layer even necessary? Specifically, we replace the attention layer in a vision transformer with a feed-forward layer applied over the patch dimension. The resulting architecture is simply a series of feed-forward layers applied over the patch and feature dimensions in an alternating fashion. In experiments on ImageNet, this architecture performs surprisingly well: a ViT/DeiT-base-sized model obtains 74.9\% top-1 accuracy, compared to 77.9\% and 79.9\% for ViT and DeiT respectively. These results indicate that aspects of vision transformers other than attention, such as the patch embedding, may be more responsible for their strong performance than previously thought. We hope these results prompt the community to spend more time trying to understand why our current models are as effective as they are.
Deep Continuous Fusion for Multi-Sensor 3D Object Detection
Dec 20, 2020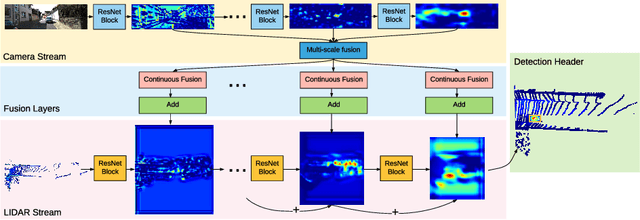
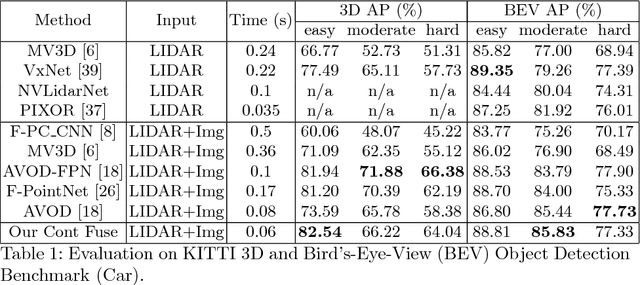
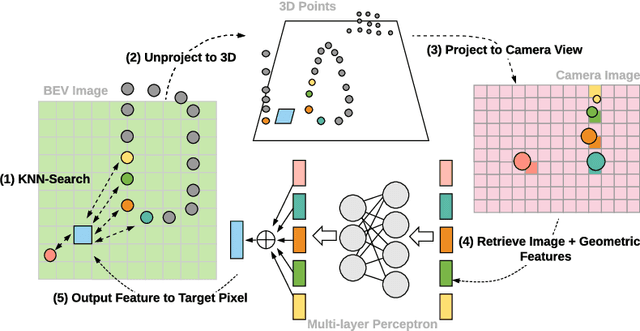
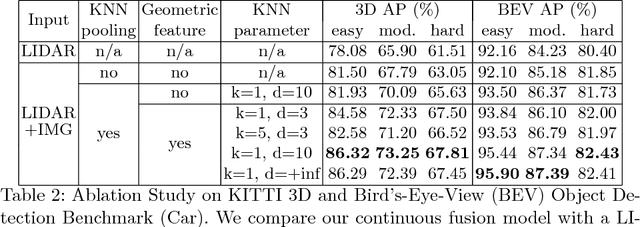
In this paper, we propose a novel 3D object detector that can exploit both LIDAR as well as cameras to perform very accurate localization. Towards this goal, we design an end-to-end learnable architecture that exploits continuous convolutions to fuse image and LIDAR feature maps at different levels of resolution. Our proposed continuous fusion layer encode both discrete-state image features as well as continuous geometric information. This enables us to design a novel, reliable and efficient end-to-end learnable 3D object detector based on multiple sensors. Our experimental evaluation on both KITTI as well as a large scale 3D object detection benchmark shows significant improvements over the state of the art.
Weakly Supervised Volumetric Segmentation via Self-taught Shape Denoising Model
May 06, 2021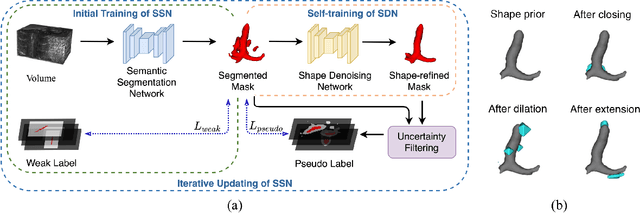
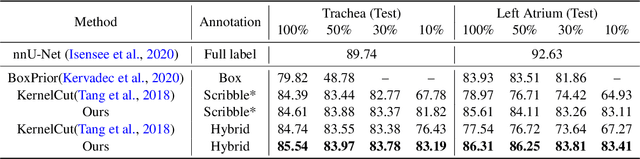


Weakly supervised segmentation is an important problem in medical image analysis due to the high cost of pixelwise annotation. Prior methods, while often focusing on weak labels of 2D images, exploit few structural cues of volumetric medical images. To address this, we propose a novel weakly-supervised segmentation strategy capable of better capturing 3D shape prior in both model prediction and learning. Our main idea is to extract a self-taught shape representation by leveraging weak labels, and then integrate this representation into segmentation prediction for shape refinement. To this end, we design a deep network consisting of a segmentation module and a shape denoising module, which are trained by an iterative learning strategy. Moreover, we introduce a weak annotation scheme with a hybrid label design for volumetric images, which improves model learning without increasing the overall annotation cost. The empirical experiments show that our approach outperforms existing SOTA strategies on three organ segmentation benchmarks with distinctive shape properties. Notably, we can achieve strong performance with even 10\% labeled slices, which is significantly superior to other methods.
Optical Flow Method for Measuring Deformation of Soil Specimen Subjected to Torsional Shearing
Jan 19, 2021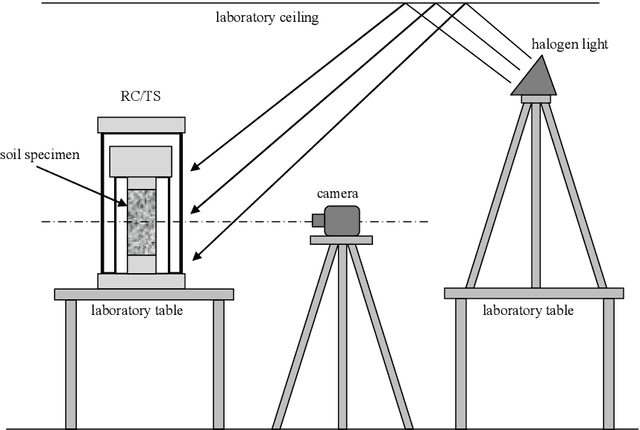



In this study optical flow method was used for soil small deformation measurement in laboratory tests. The main objective was to observe how the deformation distributes along the whole height of cylindrical soil specimen subjected to torsional shearing (TS test). The experiments were conducted on dry non-cohesive soil specimens under two values of isotropic pressure. Specimens were loaded with low-amplitude cyclic torque to analyze the deformation within the small strain range (0.001-0.01%). Optical flow method variant by Ce Liu (2009) was used for motion estimation from series of images. This algorithm uses scale-invariant feature transform (SIFT) for image feature extraction and coarse-to-fine matching scheme for faster calculations. The results were validated with the Particle Image Velocimetry (PIV). The results show that the displacement distribution deviates from commonly assumed linearity. Moreover, the observed deformation mechanisms analysis suggest that the shear modulus $G$ commonly determined through TS tests can be considerably overestimated.
Deep Image Set Hashing
Oct 01, 2016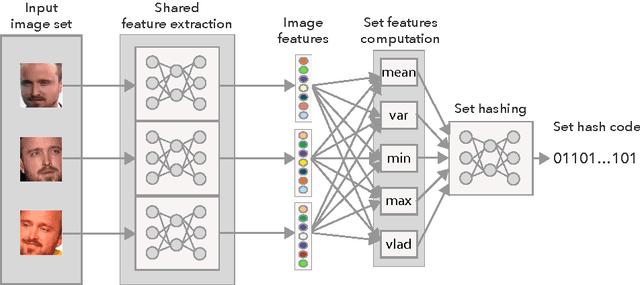
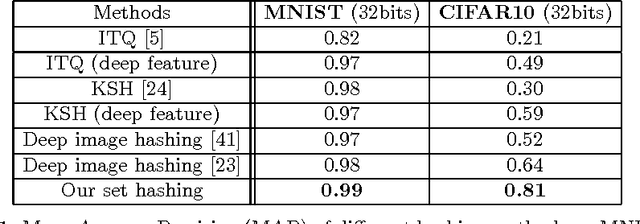

In applications involving matching of image sets, the information from multiple images must be effectively exploited to represent each set. State-of-the-art methods use probabilistic distribution or subspace to model a set and use specific distance measure to compare two sets. These methods are slow to compute and not compact to use in a large scale scenario. Learning-based hashing is often used in large scale image retrieval as they provide a compact representation of each sample and the Hamming distance can be used to efficiently compare two samples. However, most hashing methods encode each image separately and discard knowledge that multiple images in the same set represent the same object or person. We investigate the set hashing problem by combining both set representation and hashing in a single deep neural network. An image set is first passed to a CNN module to extract image features, then these features are aggregated using two types of set feature to capture both set specific and database-wide distribution information. The computed set feature is then fed into a multilayer perceptron to learn a compact binary embedding. Triplet loss is used to train the network by forming set similarity relations using class labels. We extensively evaluate our approach on datasets used for image matching and show highly competitive performance compared to state-of-the-art methods.
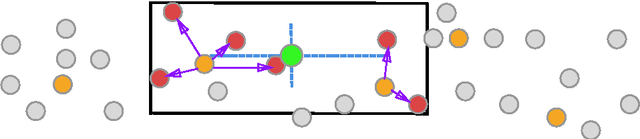
Real-time Autonomous Robot for Object Tracking using Vision System
Apr 26, 2021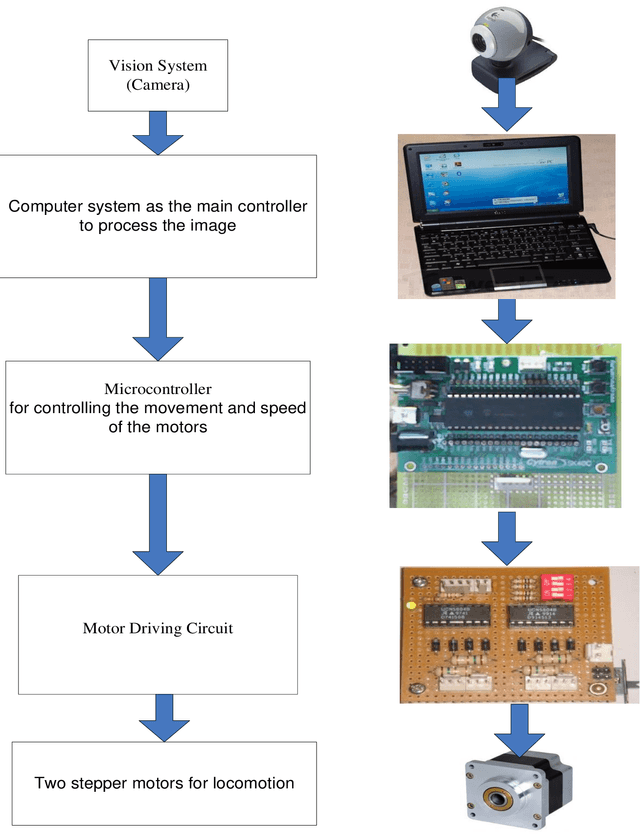


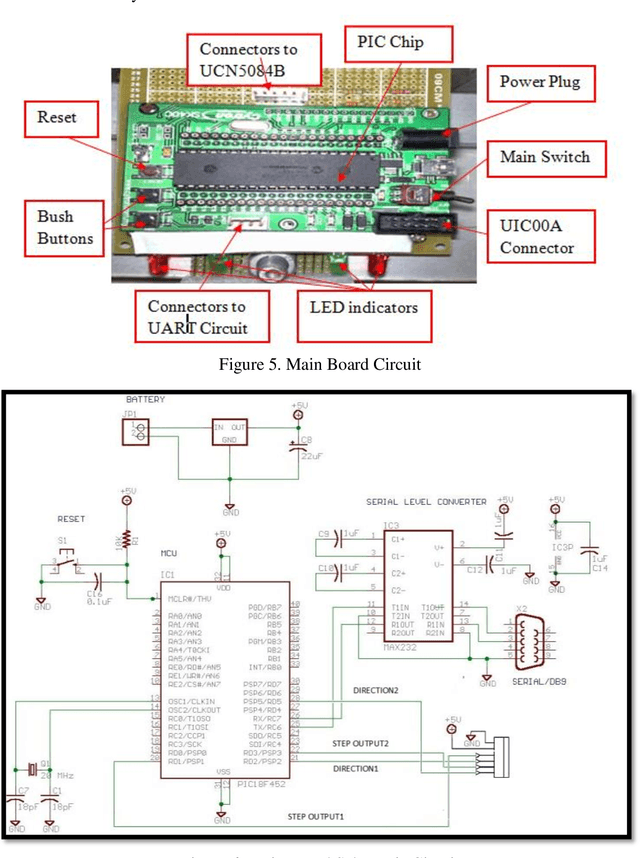
Researchers and robotic development groups have recently started paying special attention to autonomous mobile robot navigation in indoor environments using vision sensors. The required data is provided for robot navigation and object detection using a camera as a sensor. The aim of the project is to construct a mobile robot that has integrated vision system capability used by a webcam to locate, track and follow a moving object. To achieve this task, multiple image processing algorithms are implemented and processed in real-time. A mini-laptop was used for collecting the necessary data to be sent to a PIC microcontroller that turns the processes of data obtained to provide the robot's proper orientation. A vision system can be utilized in object recognition for robot control applications. The results demonstrate that the proposed mobile robot can be successfully operated through a webcam that detects the object and distinguishes a tennis ball based on its color and shape.