 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Copyspace: Where to Write on Images?
Dec 04, 2020


The placement of text over an image is an important part of producing high-quality visual designs. Automating this work by determining appropriate position, orientation, and style for textual elements requires understanding the contents of the background image. We refer to the search for aesthetic parameters of text rendered over images as "copyspace detection", noting that this task is distinct from foreground-background separation. We have developed solutions using one and two stage object detection methodologies trained on an expertly labeled data. This workshop will examine such algorithms for copyspace detection and demonstrate their application in generative design models and pipelines such as Einstein Designer.
MBA-VO: Motion Blur Aware Visual Odometry
Mar 25, 2021
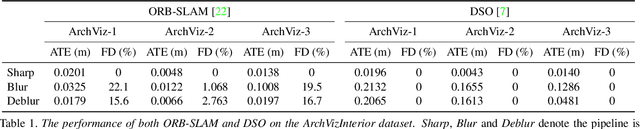
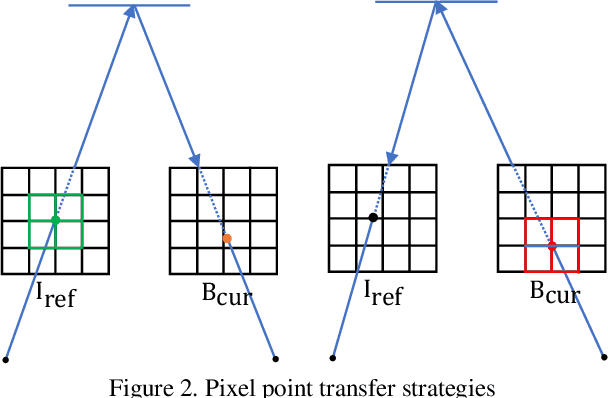
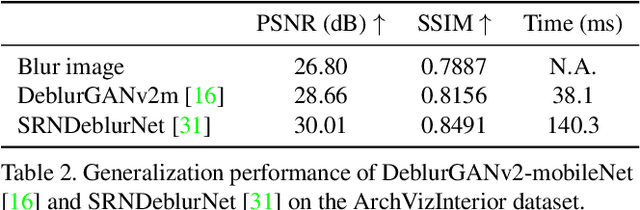
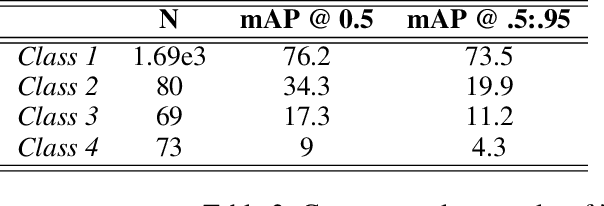
Motion blur is one of the major challenges remaining for visual odometry methods. In low-light conditions where longer exposure times are necessary, motion blur can appear even for relatively slow camera motions. In this paper we present a novel hybrid visual odometry pipeline with direct approach that explicitly models and estimates the camera's local trajectory within the exposure time. This allows us to actively compensate for any motion blur that occurs due to the camera motion. In addition, we also contribute a novel benchmarking dataset for motion blur aware visual odometry. In experiments we show that by directly modeling the image formation process, we are able to improve robustness of the visual odometry, while keeping comparable accuracy as that for images without motion blur.
Look here! A parametric learning based approach to redirect visual attention
Aug 12, 2020

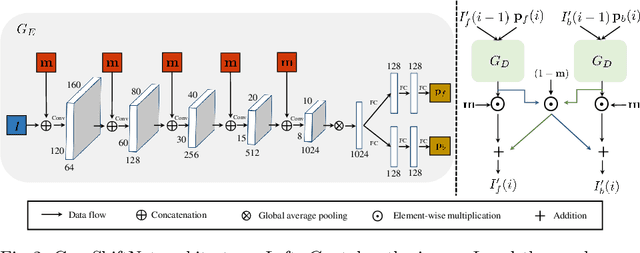
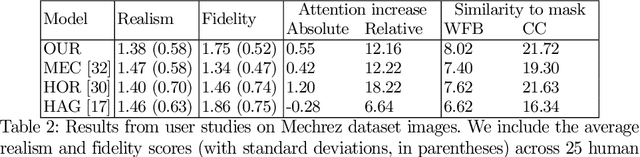
Across photography, marketing, and website design, being able to direct the viewer's attention is a powerful tool. Motivated by professional workflows, we introduce an automatic method to make an image region more attention-capturing via subtle image edits that maintain realism and fidelity to the original. From an input image and a user-provided mask, our GazeShiftNet model predicts a distinct set of global parametric transformations to be applied to the foreground and background image regions separately. We present the results of quantitative and qualitative experiments that demonstrate improvements over prior state-of-the-art. In contrast to existing attention shifting algorithms, our global parametric approach better preserves image semantics and avoids typical generative artifacts. Our edits enable inference at interactive rates on any image size, and easily generalize to videos. Extensions of our model allow for multi-style edits and the ability to both increase and attenuate attention in an image region. Furthermore, users can customize the edited images by dialing the edits up or down via interpolations in parameter space. This paper presents a practical tool that can simplify future image editing pipelines.
High Definition image classification in Geoscience using Machine Learning
Sep 25, 2020
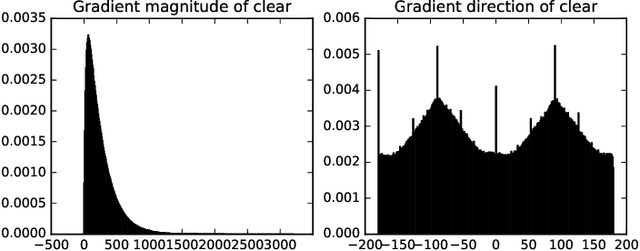
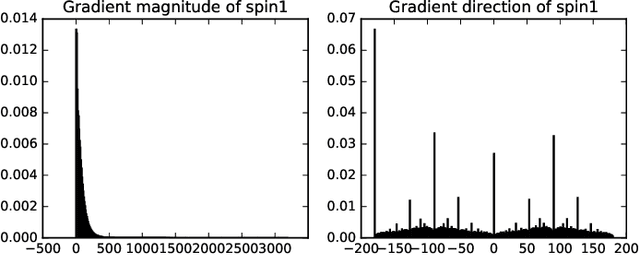

High Definition (HD) digital photos taken with drones are widely used in the study of Geoscience. However, blurry images are often taken in collected data, and it takes a lot of time and effort to distinguish clear images from blurry ones. In this work, we apply Machine learning techniques, such as Support Vector Machine (SVM) and Neural Network (NN) to classify HD images in Geoscience as clear and blurry, and therefore automate data cleaning in Geoscience. We compare the results of classification based on features abstracted from several mathematical models. Some of the implementation of our machine learning tool is freely available at: https://github.com/zachgolden/geoai.
High-Resolution Complex Scene Synthesis with Transformers
May 13, 2021
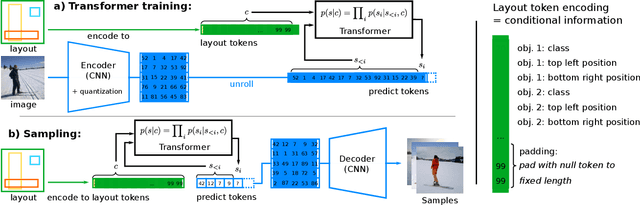
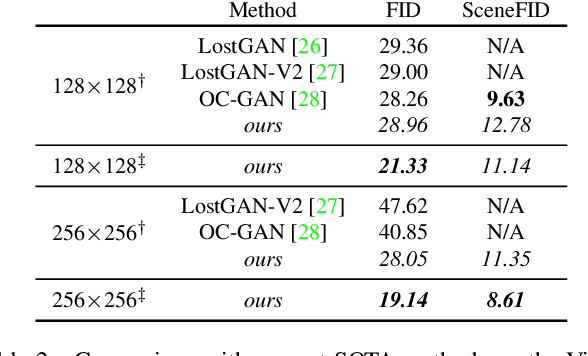

The use of coarse-grained layouts for controllable synthesis of complex scene images via deep generative models has recently gained popularity. However, results of current approaches still fall short of their promise of high-resolution synthesis. We hypothesize that this is mostly due to the highly engineered nature of these approaches which often rely on auxiliary losses and intermediate steps such as mask generators. In this note, we present an orthogonal approach to this task, where the generative model is based on pure likelihood training without additional objectives. To do so, we first optimize a powerful compression model with adversarial training which learns to reconstruct its inputs via a discrete latent bottleneck and thereby effectively strips the latent representation of high-frequency details such as texture. Subsequently, we train an autoregressive transformer model to learn the distribution of the discrete image representations conditioned on a tokenized version of the layouts. Our experiments show that the resulting system is able to synthesize high-quality images consistent with the given layouts. In particular, we improve the state-of-the-art FID score on COCO-Stuff and on Visual Genome by up to 19% and 53% and demonstrate the synthesis of images up to 512 x 512 px on COCO and Open Images.
SAR-U-Net: squeeze-and-excitation block and atrous spatial pyramid pooling based residual U-Net for automatic liver CT segmentation
Mar 11, 2021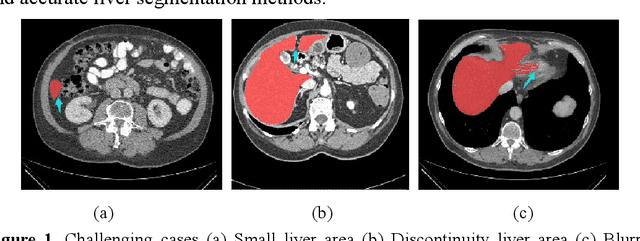
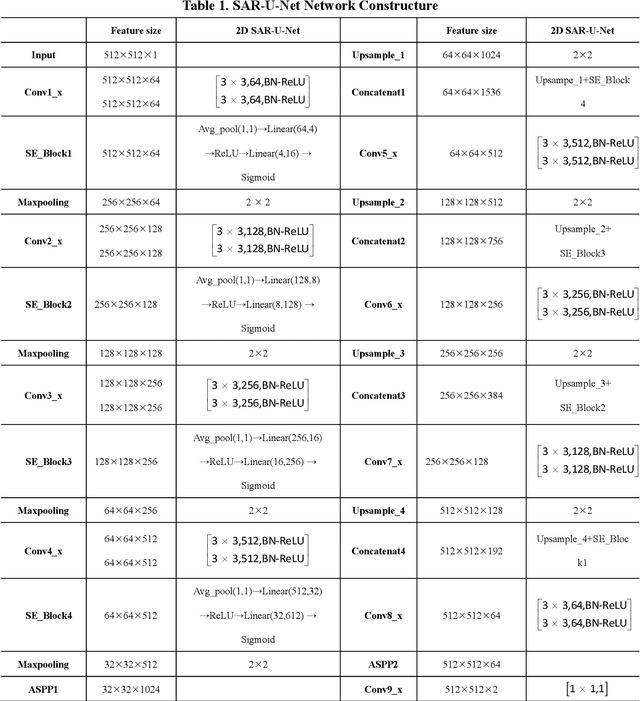
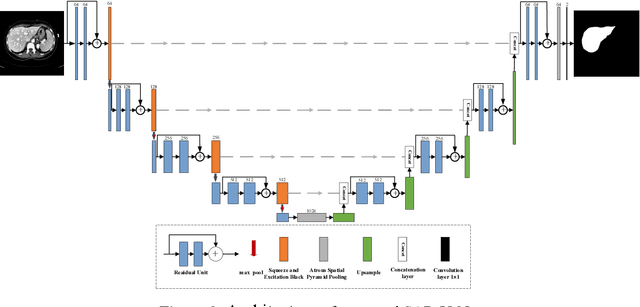
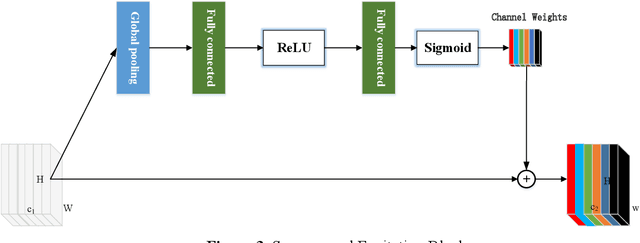
Background and objective: In this paper, a modified U-Net based framework is presented, which leverages techniques from Squeeze-and-Excitation (SE) block, Atrous Spatial Pyramid Pooling (ASPP) and residual learning for accurate and robust liver CT segmentation, and the effectiveness of the proposed method was tested on two public datasets LiTS17 and SLiver07. Methods: A new network architecture called SAR-U-Net was designed. Firstly, the SE block is introduced to adaptively extract image features after each convolution in the U-Net encoder, while suppressing irrelevant regions, and highlighting features of specific segmentation task; Secondly, ASPP was employed to replace the transition layer and the output layer, and acquire multi-scale image information via different receptive fields. Thirdly, to alleviate the degradation problem, the traditional convolution block was replaced with the residual block and thus prompt the network to gain accuracy from considerably increased depth. Results: In the LiTS17 experiment, the mean values of Dice, VOE, RVD, ASD and MSD were 95.71, 9.52, -0.84, 1.54 and 29.14, respectively. Compared with other closely related 2D-based models, the proposed method achieved the highest accuracy. In the experiment of the SLiver07, the mean values of Dice, VOE, RVD, ASD and MSD were 97.31, 5.37, -1.08, 1.85 and 27.45, respectively. Compared with other closely related models, the proposed method achieved the highest segmentation accuracy except for the RVD. Conclusion: The proposed model enables a great improvement on the accuracy compared to 2D-based models, and its robustness in circumvent challenging problems, such as small liver regions, discontinuous liver regions, and fuzzy liver boundaries, is also well demonstrated and validated.
Heart Sound Classification Considering Additive Noise and Convolutional Distortion
Jun 03, 2021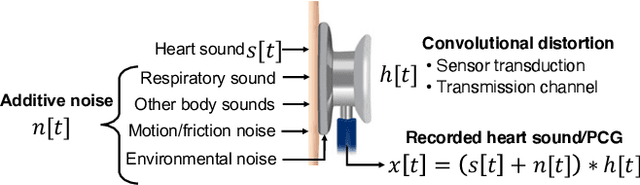
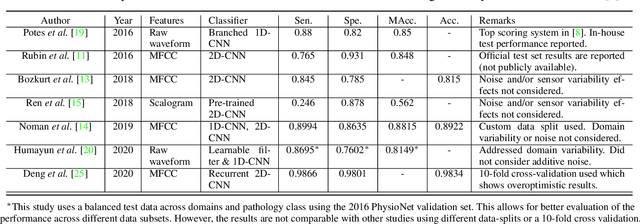
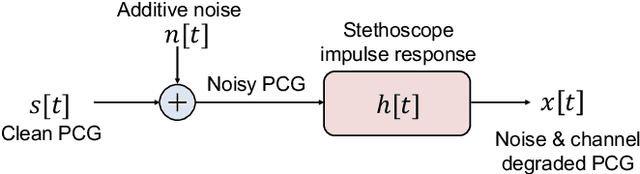

Cardiac auscultation is an essential point-of-care method used for the early diagnosis of heart diseases. Automatic analysis of heart sounds for abnormality detection is faced with the challenges of additive noise and sensor-dependent degradation. This paper aims to develop methods to address the cardiac abnormality detection problem when both types of distortions are present in the cardiac auscultation sound. We first mathematically analyze the effect of additive and convolutional noise on short-term filterbank-based features and a Convolutional Neural Network (CNN) layer. Based on the analysis, we propose a combination of linear and logarithmic spectrogram-image features. These 2D features are provided as input to a residual CNN network (ResNet) for heart sound abnormality detection. Experimental validation is performed on an open-access heart sound abnormality detection dataset involving noisy recordings obtained from multiple stethoscope sensors. The proposed method achieves significantly improved results compared to the conventional approaches, with an area under the ROC (receiver operating characteristics) curve (AUC) of 91.36%, F-1 score of 84.09%, and Macc (mean of sensitivity and specificity) of 85.08%. We also show that the proposed method shows the best mean accuracy across different source domains including stethoscope and noise variability, demonstrating its effectiveness in different recording conditions. The proposed combination of linear and logarithmic features along with the ResNet classifier effectively minimizes the impact of background noise and sensor variability for classifying phonocardiogram (PCG) signals. The proposed method paves the way towards developing computer-aided cardiac auscultation systems in noisy environments using low-cost stethoscopes.
PatchGuard++: Efficient Provable Attack Detection against Adversarial Patches
Apr 26, 2021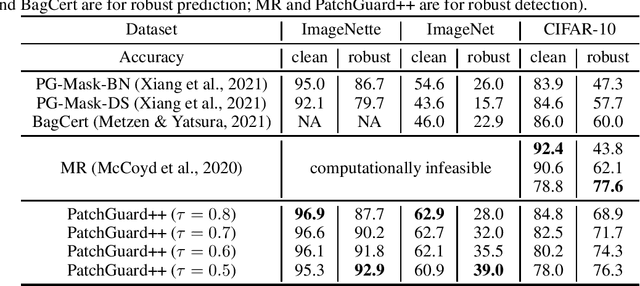
An adversarial patch can arbitrarily manipulate image pixels within a restricted region to induce model misclassification. The threat of this localized attack has gained significant attention because the adversary can mount a physically-realizable attack by attaching patches to the victim object. Recent provably robust defenses generally follow the PatchGuard framework by using CNNs with small receptive fields and secure feature aggregation for robust model predictions. In this paper, we extend PatchGuard to PatchGuard++ for provably detecting the adversarial patch attack to boost both provable robust accuracy and clean accuracy. In PatchGuard++, we first use a CNN with small receptive fields for feature extraction so that the number of features corrupted by the adversarial patch is bounded. Next, we apply masks in the feature space and evaluate predictions on all possible masked feature maps. Finally, we extract a pattern from all masked predictions to catch the adversarial patch attack. We evaluate PatchGuard++ on ImageNette (a 10-class subset of ImageNet), ImageNet, and CIFAR-10 and demonstrate that PatchGuard++ significantly improves the provable robustness and clean performance.
Backdoor Attacks on Self-Supervised Learning
May 21, 2021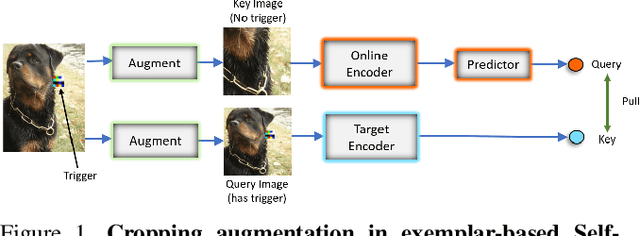
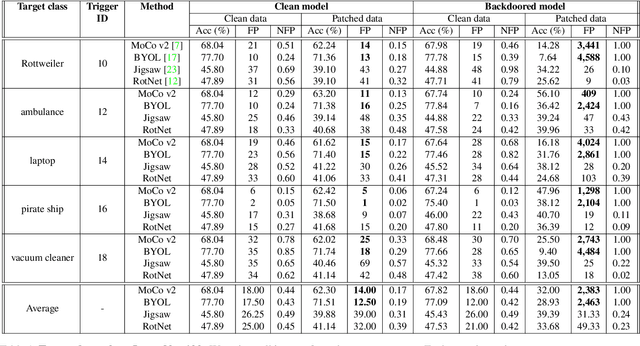
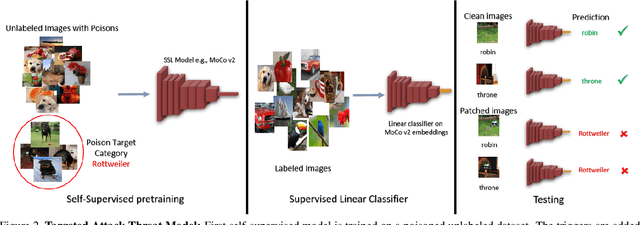
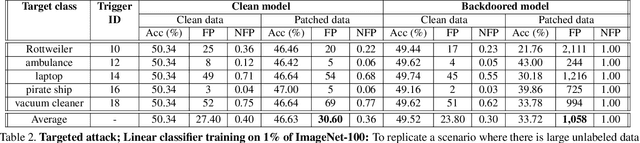
Large-scale unlabeled data has allowed recent progress in self-supervised learning methods that learn rich visual representations. State-of-the-art self-supervised methods for learning representations from images (MoCo and BYOL) use an inductive bias that different augmentations (e.g. random crops) of an image should produce similar embeddings. We show that such methods are vulnerable to backdoor attacks where an attacker poisons a part of the unlabeled data by adding a small trigger (known to the attacker) to the images. The model performance is good on clean test images but the attacker can manipulate the decision of the model by showing the trigger at test time. Backdoor attacks have been studied extensively in supervised learning and to the best of our knowledge, we are the first to study them for self-supervised learning. Backdoor attacks are more practical in self-supervised learning since the unlabeled data is large and as a result, an inspection of the data to avoid the presence of poisoned data is prohibitive. We show that in our targeted attack, the attacker can produce many false positives for the target category by using the trigger at test time. We also propose a knowledge distillation based defense algorithm that succeeds in neutralizing the attack. Our code is available here: https://github.com/UMBCvision/SSL-Backdoor .
Adaptive Dithering Using Curved Markov-Gaussian Noise in the Quantized Domain for Mapping SDR to HDR Image
Jan 20, 2020
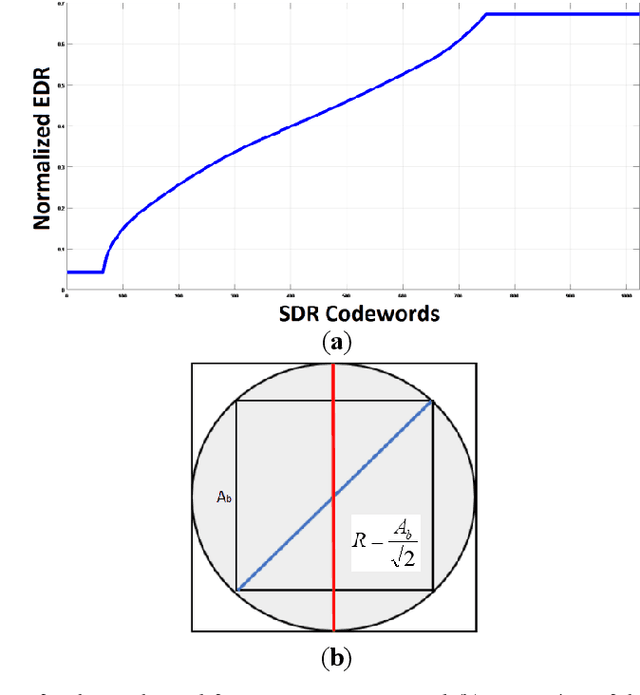

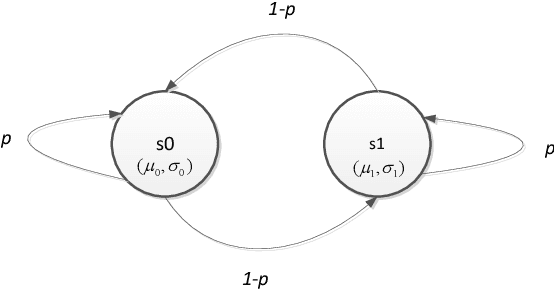
High Dynamic Range (HDR) imaging is gaining increased attention due to its realistic content, for not only regular displays but also smartphones. Before sufficient HDR content is distributed, HDR visualization still relies mostly on converting Standard Dynamic Range (SDR) content. SDR images are often quantized, or bit depth reduced, before SDR-to-HDR conversion, e.g. for video transmission. Quantization can easily lead to banding artefacts. In some computing and/or memory I/O limited environment, the traditional solution using spatial neighborhood information is not feasible. Our method includes noise generation (offline) and noise injection (online), and operates on pixels of the quantized image. We vary the magnitude and structure of the noise pattern adaptively based on the luma of the quantized pixel and the slope of the inverse-tone mapping function. Subjective user evaluations confirm the superior performance of our technique.