 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
What is Wrong with Continual Learning in Medical Image Segmentation?
Oct 21, 2020
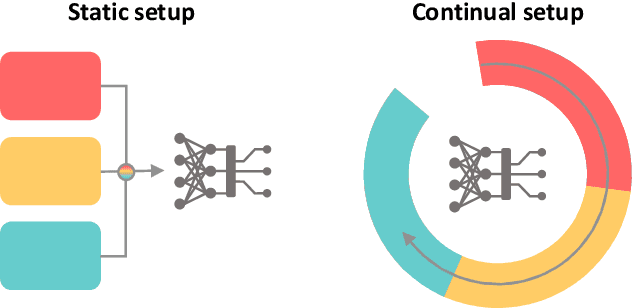
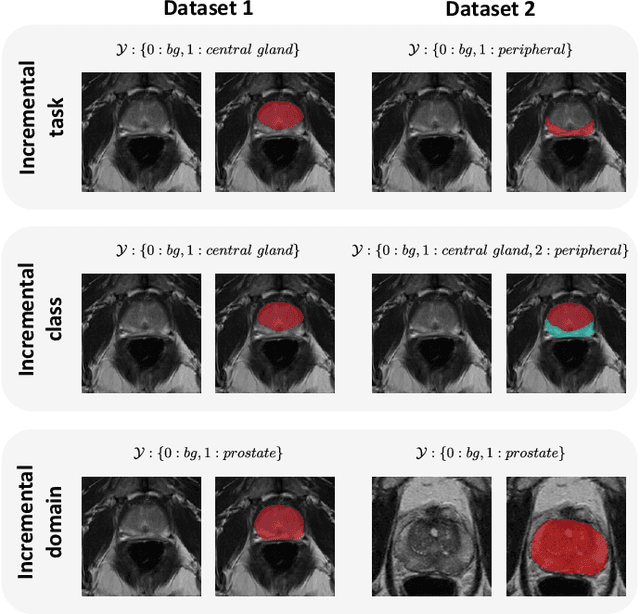
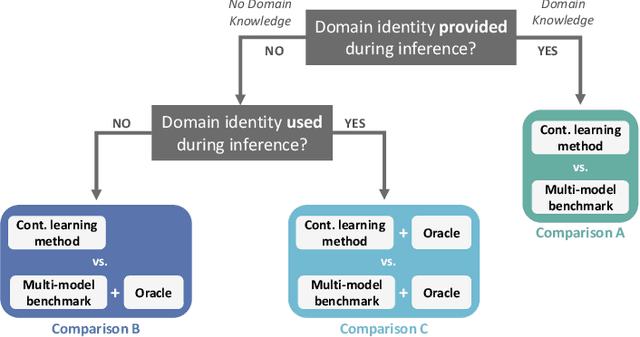
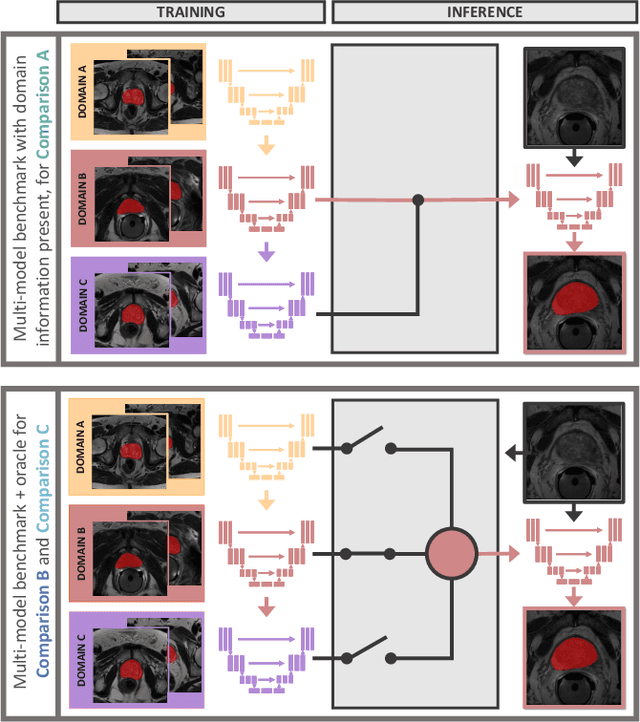
Continual learning protocols are attracting increasing attention from the medical imaging community. In a continual setup, data from different sources arrives sequentially and each batch is only available for a limited period. Given the inherent privacy risks associated with medical data, this setup reflects the reality of deployment for deep learning diagnostic radiology systems. Many techniques exist to learn continuously for classification tasks, and several have been adapted to semantic segmentation. Yet most have at least one of the following flaws: a) they rely too heavily on domain identity information during inference, or b) data as seen in early training stages does not profit from training with later data. In this work, we propose an evaluation framework that addresses both concerns, and introduce a fair multi-model benchmark. We show that the benchmark outperforms two popular continual learning methods for the task of T2-weighted MR prostate segmentation.
SREDS: A dichromatic separation based measure of skin color
Apr 07, 2021


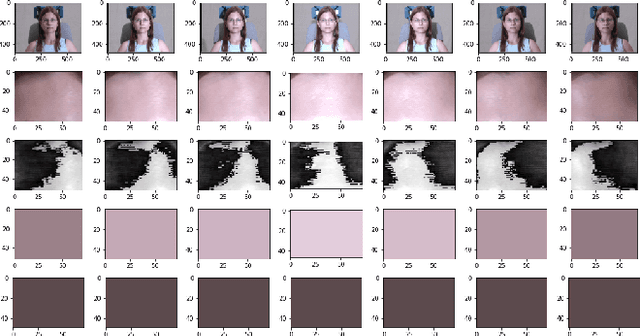
Face recognition (FR) systems are fast becoming ubiquitous. However, differential performance among certain demographics was identified in several widely used FR models. The skin tone of the subject is an important factor in addressing the differential performance. Previous work has used modeling methods to propose skin tone measures of subjects across different illuminations or utilized subjective labels of skin color and demographic information. However, such models heavily rely on consistent background and lighting for calibration, or utilize labeled datasets, which are time-consuming to generate or are unavailable. In this work, we have developed a novel and data-driven skin color measure capable of accurately representing subjects' skin tone from a single image, without requiring a consistent background or illumination. Our measure leverages the dichromatic reflection model in RGB space to decompose skin patches into diffuse and specular bases.
Wide-Depth-Range 6D Object Pose Estimation in Space
Apr 01, 2021
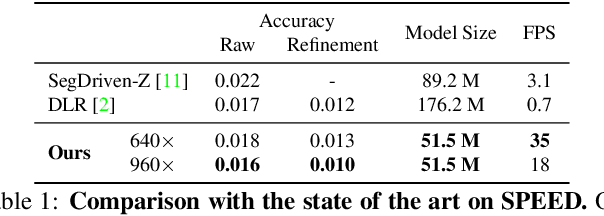
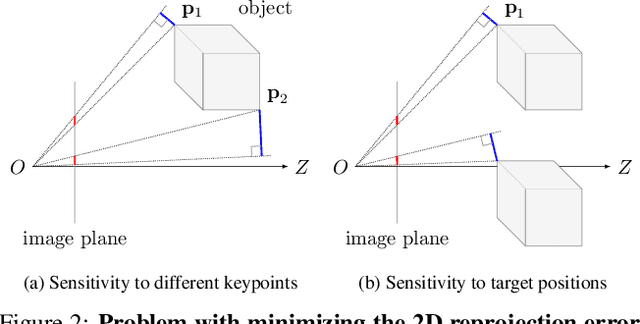
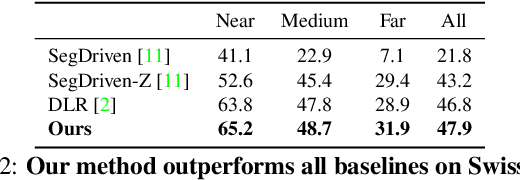
6D pose estimation in space poses unique challenges that are not commonly encountered in the terrestrial setting. One of the most striking differences is the lack of atmospheric scattering, allowing objects to be visible from a great distance while complicating illumination conditions. Currently available benchmark datasets do not place a sufficient emphasis on this aspect and mostly depict the target in close proximity. Prior work tackling pose estimation under large scale variations relies on a two-stage approach to first estimate scale, followed by pose estimation on a resized image patch. We instead propose a single-stage hierarchical end-to-end trainable network that is more robust to scale variations. We demonstrate that it outperforms existing approaches not only on images synthesized to resemble images taken in space but also on standard benchmarks.
Evaluating ResNeXt Model Architecture for Image Classification
May 09, 2018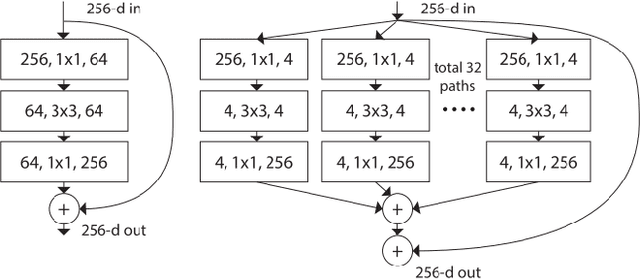
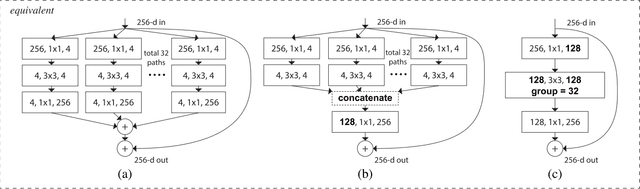
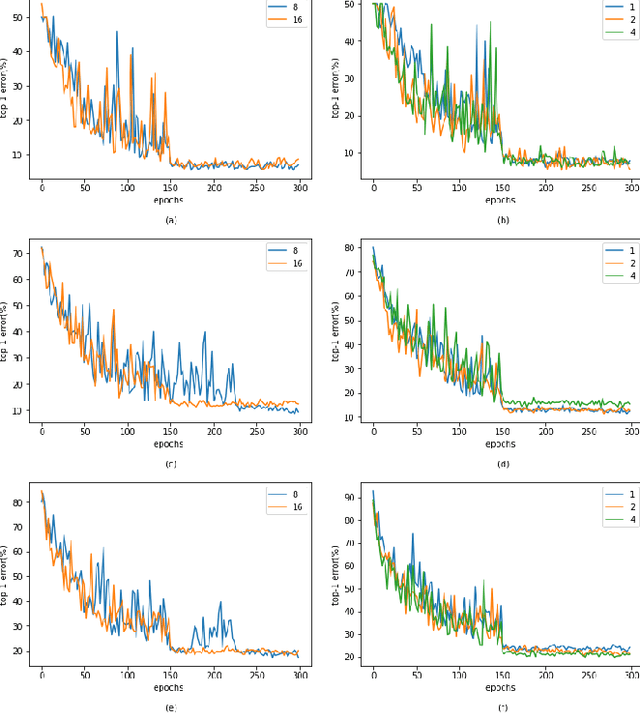
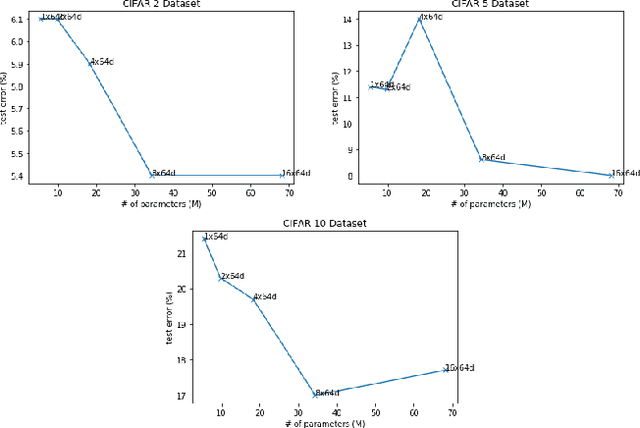
In recent years, deep learning methods have been successfully applied to image classification tasks. Many such deep neural networks exist today that can easily differentiate cats from dogs. One such model is the ResNeXt model that uses a homogeneous, multi-branch architecture for image classification. This paper aims at implementing and evaluating the ResNeXt model architecture on subsets of the CIFAR-10 dataset. It also tweaks the original ResNeXt hyper-parameters such as cardinality, depth and base-width and compares the performance of the modified model with the original. Analysis of the experiments performed in this paper show that a slight decrease in depth or base-width does not affect the performance of the model much leading to comparable results.
Refractive Light-Field Features for Curved Transparent Objects in Structure from Motion
Apr 17, 2021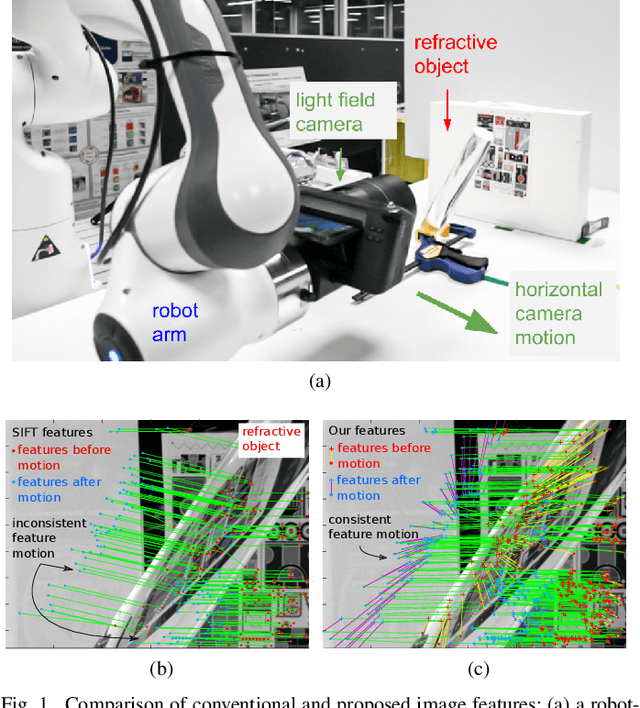
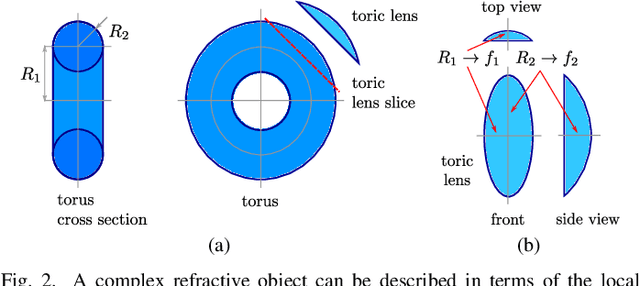
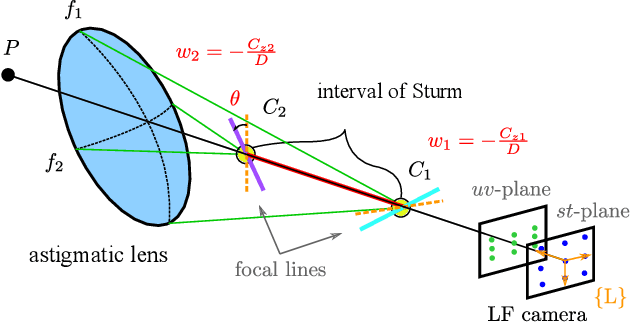
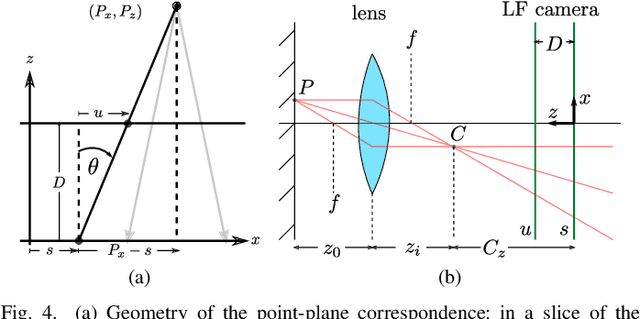
Curved refractive objects are common in the human environment, and have a complex visual appearance that can cause robotic vision algorithms to fail. Light-field cameras allow us to address this challenge by capturing the view-dependent appearance of such objects in a single exposure. We propose a novel image feature for light fields that detects and describes the patterns of light refracted through curved transparent objects. We derive characteristic points based on these features allowing them to be used in place of conventional 2D features. Using our features, we demonstrate improved structure-from-motion performance in challenging scenes containing refractive objects, including quantitative evaluations that show improved camera pose estimates and 3D reconstructions. Additionally, our methods converge 15-35% more frequently than the state-of-the-art. Our method is a critical step towards allowing robots to operate around refractive objects, with applications in manufacturing, quality assurance, pick-and-place, and domestic robots working with acrylic, glass and other transparent materials.
Distant Domain Transfer Learning for Medical Imaging
Dec 10, 2020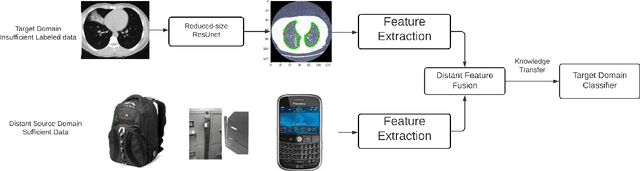
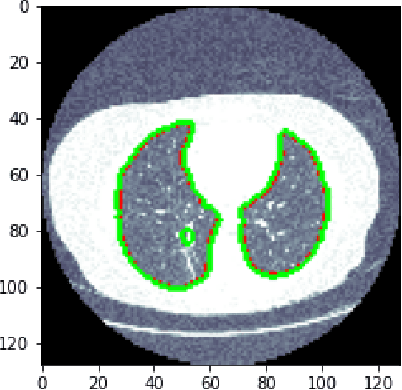
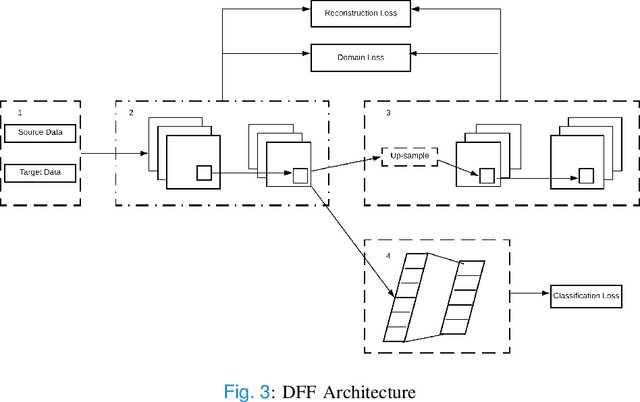
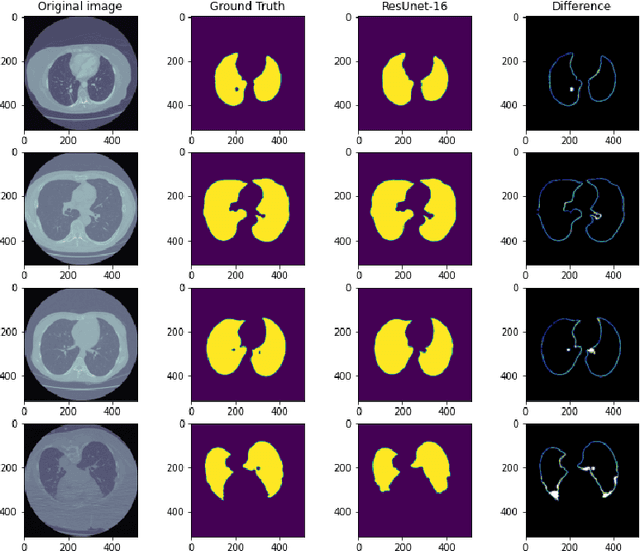
Medical image processing is one of the most important topics in the field of the Internet of Medical Things (IoMT). Recently, deep learning methods have carried out state-of-the-art performances on medical image tasks. However, conventional deep learning have two main drawbacks: 1) insufficient training data and 2) the domain mismatch between the training data and the testing data. In this paper, we propose a distant domain transfer learning (DDTL) method for medical image classification. Moreover, we apply our methods to a recent issue (Coronavirus diagnose). Several current studies indicate that lung Computed Tomography (CT) images can be used for a fast and accurate COVID-19 diagnosis. However, the well-labeled training data cannot be easily accessed due to the novelty of the disease and a number of privacy policies. Moreover, the proposed method has two components: Reduced-size Unet Segmentation model and Distant Feature Fusion (DFF) classification model. It is related to a not well-investigated but important transfer learning problem, termed Distant Domain Transfer Learning (DDTL). DDTL aims to make efficient transfers even when the domains or the tasks are entirely different. In this study, we develop a DDTL model for COVID-19 diagnose using unlabeled Office-31, Catech-256, and chest X-ray image data sets as the source data, and a small set of COVID-19 lung CT as the target data. The main contributions of this study: 1) the proposed method benefits from unlabeled data collected from distant domains which can be easily accessed, 2) it can effectively handle the distribution shift between the training data and the testing data, 3) it has achieved 96\% classification accuracy, which is 13\% higher classification accuracy than "non-transfer" algorithms, and 8\% higher than existing transfer and distant transfer algorithms.
Gated Fusion Network for Single Image Dehazing
Mar 31, 2018

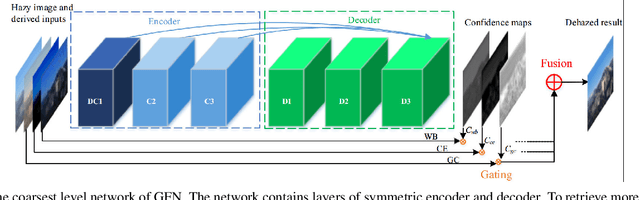

In this paper, we propose an efficient algorithm to directly restore a clear image from a hazy input. The proposed algorithm hinges on an end-to-end trainable neural network that consists of an encoder and a decoder. The encoder is exploited to capture the context of the derived input images, while the decoder is employed to estimate the contribution of each input to the final dehazed result using the learned representations attributed to the encoder. The constructed network adopts a novel fusion-based strategy which derives three inputs from an original hazy image by applying White Balance (WB), Contrast Enhancing (CE), and Gamma Correction (GC). We compute pixel-wise confidence maps based on the appearance differences between these different inputs to blend the information of the derived inputs and preserve the regions with pleasant visibility. The final dehazed image is yielded by gating the important features of the derived inputs. To train the network, we introduce a multi-scale approach such that the halo artifacts can be avoided. Extensive experimental results on both synthetic and real-world images demonstrate that the proposed algorithm performs favorably against the state-of-the-art algorithms.
Omnimatte: Associating Objects and Their Effects in Video
May 14, 2021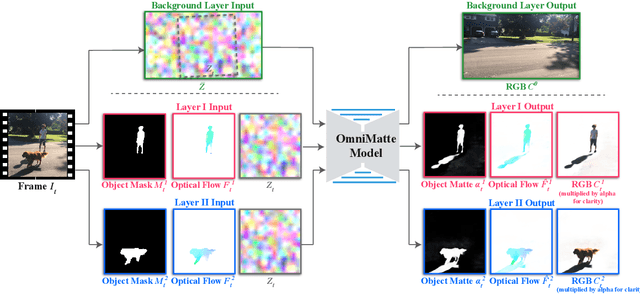



Computer vision is increasingly effective at segmenting objects in images and videos; however, scene effects related to the objects---shadows, reflections, generated smoke, etc---are typically overlooked. Identifying such scene effects and associating them with the objects producing them is important for improving our fundamental understanding of visual scenes, and can also assist a variety of applications such as removing, duplicating, or enhancing objects in video. In this work, we take a step towards solving this novel problem of automatically associating objects with their effects in video. Given an ordinary video and a rough segmentation mask over time of one or more subjects of interest, we estimate an omnimatte for each subject---an alpha matte and color image that includes the subject along with all its related time-varying scene elements. Our model is trained only on the input video in a self-supervised manner, without any manual labels, and is generic---it produces omnimattes automatically for arbitrary objects and a variety of effects. We show results on real-world videos containing interactions between different types of subjects (cars, animals, people) and complex effects, ranging from semi-transparent elements such as smoke and reflections, to fully opaque effects such as objects attached to the subject.
Semi-Supervised Few-Shot Classification with Deep Invertible Hybrid Models
May 22, 2021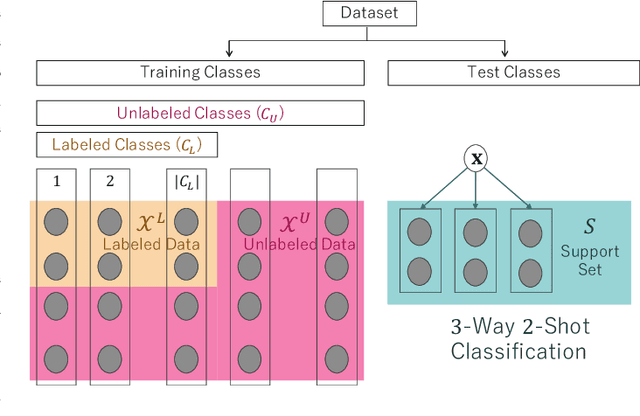
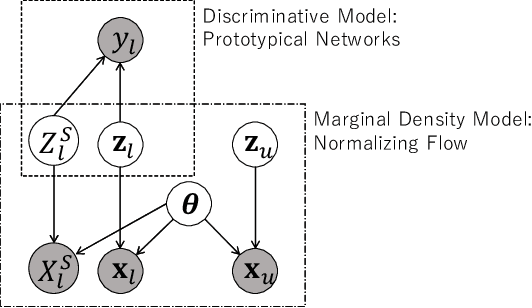
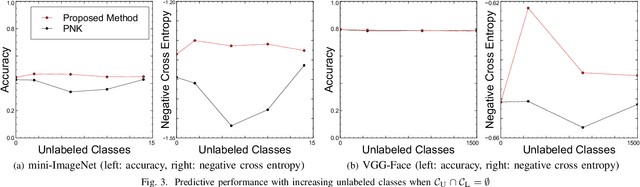
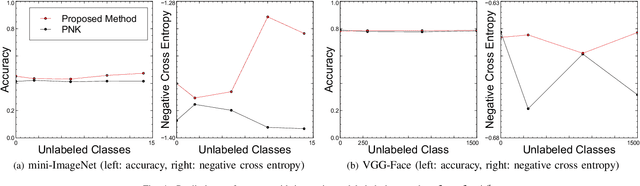
In this paper, we propose a deep invertible hybrid model which integrates discriminative and generative learning at a latent space level for semi-supervised few-shot classification. Various tasks for classifying new species from image data can be modeled as a semi-supervised few-shot classification, which assumes a labeled and unlabeled training examples and a small support set of the target classes. Predicting target classes with a few support examples per class makes the learning task difficult for existing semi-supervised classification methods, including selftraining, which iteratively estimates class labels of unlabeled training examples to learn a classifier for the training classes. To exploit unlabeled training examples effectively, we adopt as the objective function the composite likelihood, which integrates discriminative and generative learning and suits better with deep neural networks than the parameter coupling prior, the other popular integrated learning approach. In our proposed model, the discriminative and generative models are respectively Prototypical Networks, which have shown excellent performance in various kinds of few-shot learning, and Normalizing Flow a deep invertible model which returns the exact marginal likelihood unlike the other three major methods, i.e., VAE, GAN, and autoregressive model. Our main originality lies in our integration of these components at a latent space level, which is effective in preventing overfitting. Experiments using mini-ImageNet and VGG-Face datasets show that our method outperforms selftraining based Prototypical Networks.
StainNet: a fast and robust stain normalization network
Dec 23, 2020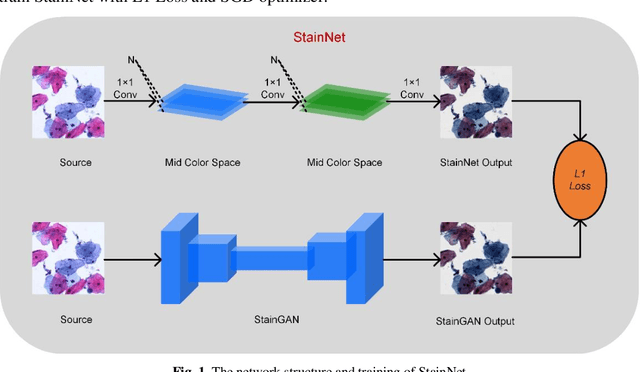
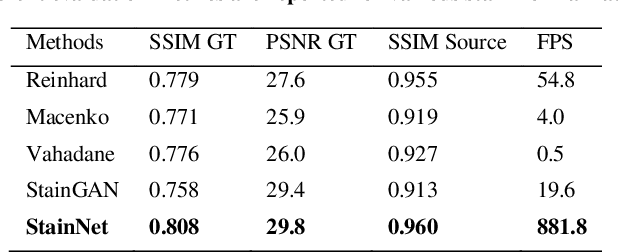
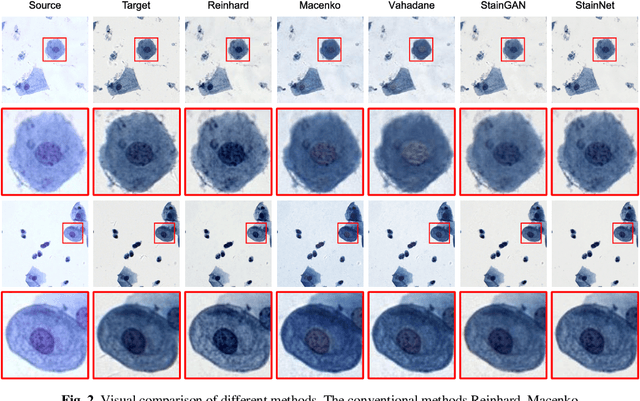
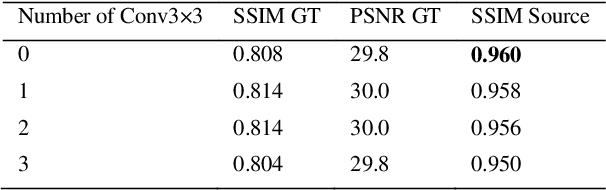
Pathological images may have large variabilities in color intensities due to differences in staining process, operator ability, and scanner specifications. These variations hamper the performance of computer-aided diagnosis (CAD) systems. Stain normalization is used to reduce the variability in color intensities and increase the prediction accuracy. However, the conventional methods highly depend on a reference image, and the current deep learning based methods may have a wrong change in color intensities or texture. In this paper, a fully 1x1 convolutional stain normalization network with only 1.28K parameters is proposed. Our StainNet can learn the color mapping relation from the whole dataset and adjust the color value depended on a single pixel. The proposed method outperforms the state-of-art methods and achieves better accuracy and image quality.