 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Bayesian imaging using Plug & Play priors: when Langevin meets Tweedie
Mar 19, 2021



Since the seminal work of Venkatakrishnan et al. (2013), Plug & Play (PnP) methods have become ubiquitous in Bayesian imaging. These methods derive Minimum Mean Square Error (MMSE) or Maximum A Posteriori (MAP) estimators for inverse problems in imaging by combining an explicit likelihood function with a prior that is implicitly defined by an image denoising algorithm. The PnP algorithms proposed in the literature mainly differ in the iterative schemes they use for optimisation or for sampling. In the case of optimisation schemes, some recent works guarantee the convergence to a fixed point, albeit not necessarily a MAP estimate. In the case of sampling schemes, to the best of our knowledge, there is no known proof of convergence. There also remain important open questions regarding whether the underlying Bayesian models and estimators are well defined, well-posed, and have the basic regularity properties required to support these numerical schemes. To address these limitations, this paper develops theory, methods, and provably convergent algorithms for performing Bayesian inference with PnP priors. We introduce two algorithms: 1) PnP-ULA (Unadjusted Langevin Algorithm) for Monte Carlo sampling and MMSE inference; and 2) PnP-SGD (Stochastic Gradient Descent) for MAP inference. Using recent results on the quantitative convergence of Markov chains, we establish detailed convergence guarantees for these two algorithms under realistic assumptions on the denoising operators used, with special attention to denoisers based on deep neural networks. We also show that these algorithms approximately target a decision-theoretically optimal Bayesian model that is well-posed. The proposed algorithms are demonstrated on several canonical problems such as image deblurring, inpainting, and denoising, where they are used for point estimation as well as for uncertainty visualisation and quantification.
Phrase-based Image Captioning with Hierarchical LSTM Model
Nov 11, 2017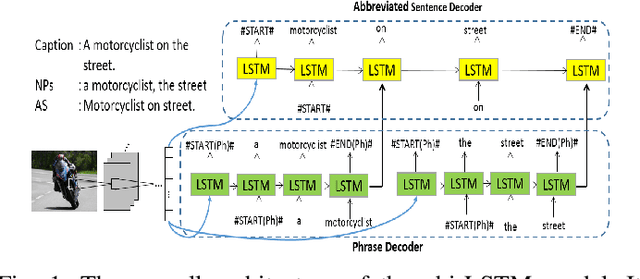



Automatic generation of caption to describe the content of an image has been gaining a lot of research interests recently, where most of the existing works treat the image caption as pure sequential data. Natural language, however possess a temporal hierarchy structure, with complex dependencies between each subsequence. In this paper, we propose a phrase-based hierarchical Long Short-Term Memory (phi-LSTM) model to generate image description. In contrast to the conventional solutions that generate caption in a pure sequential manner, our proposed model decodes image caption from phrase to sentence. It consists of a phrase decoder at the bottom hierarchy to decode noun phrases of variable length, and an abbreviated sentence decoder at the upper hierarchy to decode an abbreviated form of the image description. A complete image caption is formed by combining the generated phrases with sentence during the inference stage. Empirically, our proposed model shows a better or competitive result on the Flickr8k, Flickr30k and MS-COCO datasets in comparison to the state-of-the art models. We also show that our proposed model is able to generate more novel captions (not seen in the training data) which are richer in word contents in all these three datasets.
Robust Pollen Imagery Classification with Generative Modeling and Mixup Training
Feb 25, 2021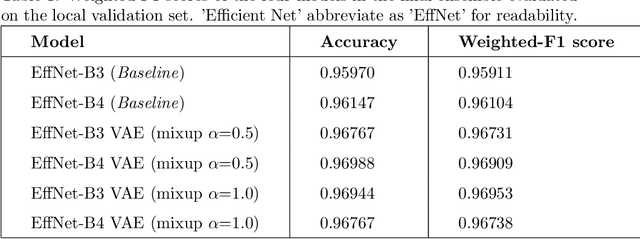
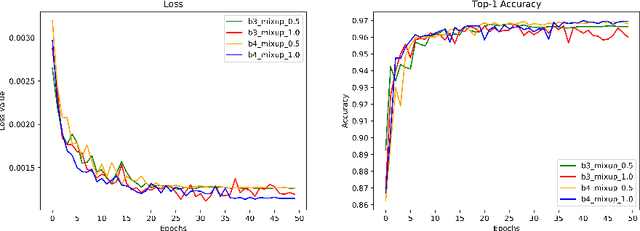
Deep learning approaches have shown great success in image classification tasks and can aid greatly towards the fast and reliable classification of pollen grain aerial imagery. However, often-times deep learning methods in the setting of natural images can suffer generalization problems and yield poor performance on unseen test distribution. In this work, we present and a robust deep learning framework that can generalize well for pollen grain aerobiological imagery classification. We develop a convolutional neural network-based pollen grain classification approach and combine some of the best practices in deep learning for better generalization. In addition to commonplace approaches like data-augmentation and weight regularization, we utilize implicit regularization methods like manifold mixup to allow learning of smoother decision boundaries. We also make use of proven state-of-the-art architectural choices like EfficientNet convolutional neural networks. Inspired by the success of generative modeling with variational autoencoders, we train models with a richer learning objective which can allow the model to focus on the relevant parts of the image. Finally, we create an ensemble of neural networks, for the robustness of the test set predictions. Based on our experiments, we show improved generalization performance as measured with a weighted F1-score with the aforementioned approaches. The proposed approach earned a fourth-place in the final rankings in the ICPR-2020 Pollen Grain Classification Challenge; with a 0.972578 weighted F1 score,0.950828 macro average F1 scores, and 0.972877 recognition accuracy.
Learning Equivariant Representations
Dec 04, 2020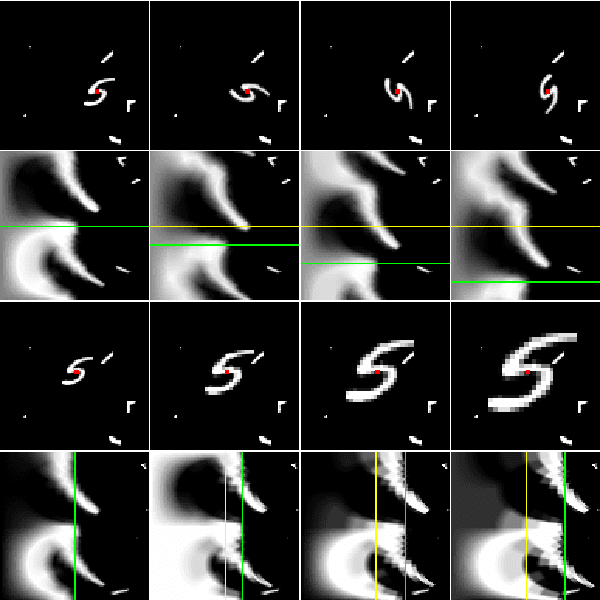
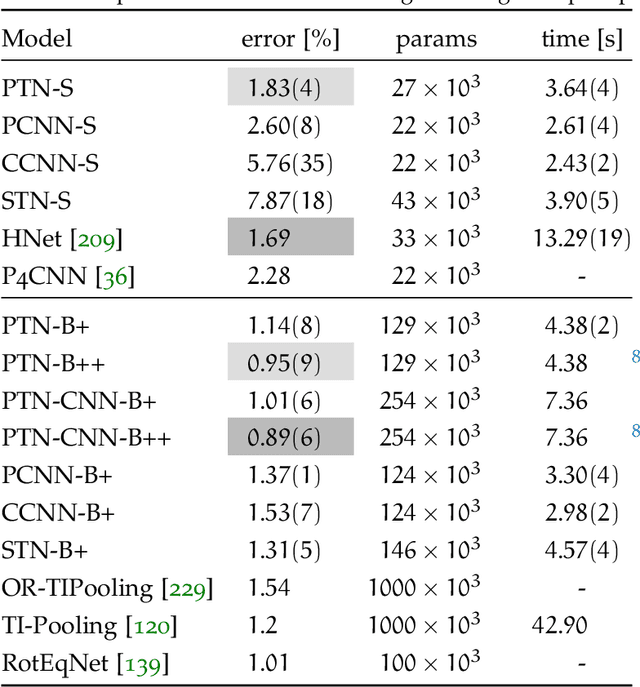
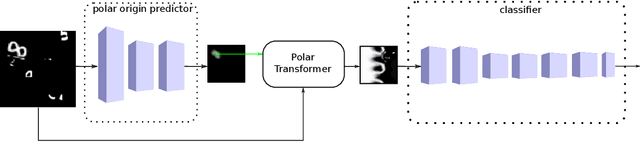
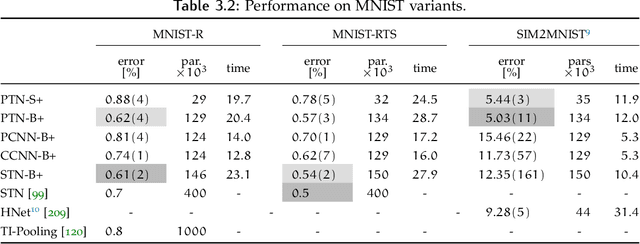
State-of-the-art deep learning systems often require large amounts of data and computation. For this reason, leveraging known or unknown structure of the data is paramount. Convolutional neural networks (CNNs) are successful examples of this principle, their defining characteristic being the shift-equivariance. By sliding a filter over the input, when the input shifts, the response shifts by the same amount, exploiting the structure of natural images where semantic content is independent of absolute pixel positions. This property is essential to the success of CNNs in audio, image and video recognition tasks. In this thesis, we extend equivariance to other kinds of transformations, such as rotation and scaling. We propose equivariant models for different transformations defined by groups of symmetries. The main contributions are (i) polar transformer networks, achieving equivariance to the group of similarities on the plane, (ii) equivariant multi-view networks, achieving equivariance to the group of symmetries of the icosahedron, (iii) spherical CNNs, achieving equivariance to the continuous 3D rotation group, (iv) cross-domain image embeddings, achieving equivariance to 3D rotations for 2D inputs, and (v) spin-weighted spherical CNNs, generalizing the spherical CNNs and achieving equivariance to 3D rotations for spherical vector fields. Applications include image classification, 3D shape classification and retrieval, panoramic image classification and segmentation, shape alignment and pose estimation. What these models have in common is that they leverage symmetries in the data to reduce sample and model complexity and improve generalization performance. The advantages are more significant on (but not limited to) challenging tasks where data is limited or input perturbations such as arbitrary rotations are present.
Unsupervised Joint Mining of Deep Features and Image Labels for Large-scale Radiology Image Categorization and Scene Recognition
Dec 27, 2017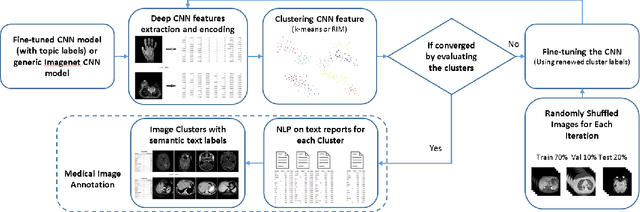
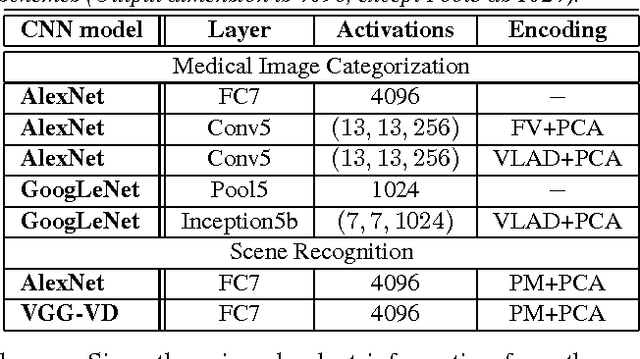
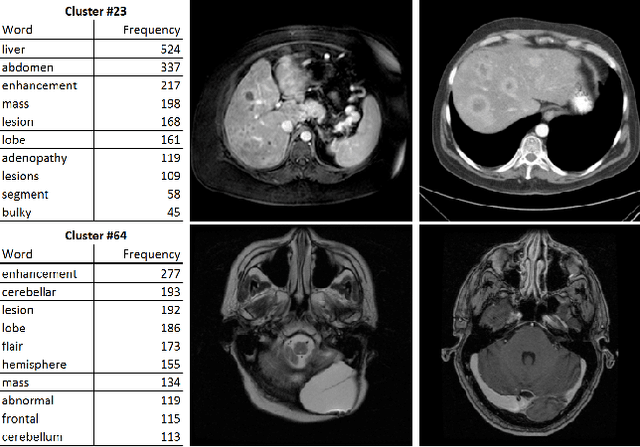
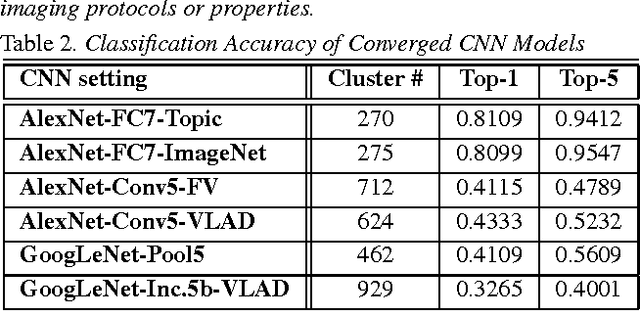
The recent rapid and tremendous success of deep convolutional neural networks (CNN) on many challenging computer vision tasks largely derives from the accessibility of the well-annotated ImageNet and PASCAL VOC datasets. Nevertheless, unsupervised image categorization (i.e., without the ground-truth labeling) is much less investigated, yet critically important and difficult when annotations are extremely hard to obtain in the conventional way of "Google Search" and crowd sourcing. We address this problem by presenting a looped deep pseudo-task optimization (LDPO) framework for joint mining of deep CNN features and image labels. Our method is conceptually simple and rests upon the hypothesized "convergence" of better labels leading to better trained CNN models which in turn feed more discriminative image representations to facilitate more meaningful clusters/labels. Our proposed method is validated in tackling two important applications: 1) Large-scale medical image annotation has always been a prohibitively expensive and easily-biased task even for well-trained radiologists. Significantly better image categorization results are achieved via our proposed approach compared to the previous state-of-the-art method. 2) Unsupervised scene recognition on representative and publicly available datasets with our proposed technique is examined. The LDPO achieves excellent quantitative scene classification results. On the MIT indoor scene dataset, it attains a clustering accuracy of 75.3%, compared to the state-of-the-art supervised classification accuracy of 81.0% (when both are based on the VGG-VD model).
ConTNet: Why not use convolution and transformer at the same time?
May 06, 2021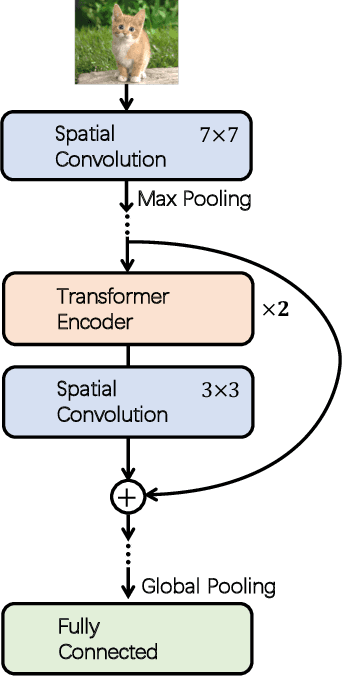
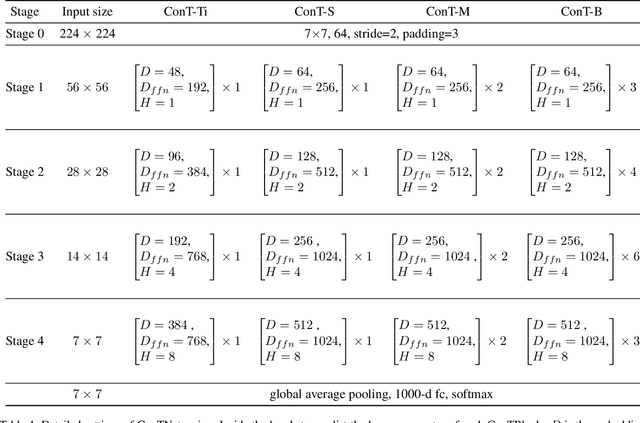

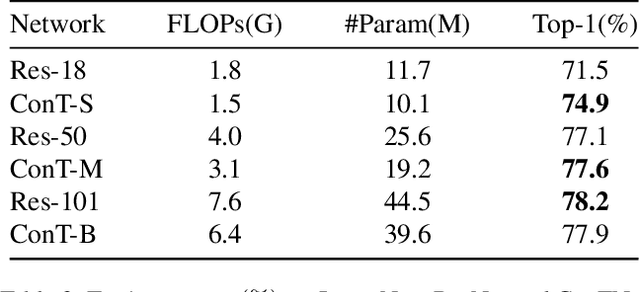
Although convolutional networks (ConvNets) have enjoyed great success in computer vision (CV), it suffers from capturing global information crucial to dense prediction tasks such as object detection and segmentation. In this work, we innovatively propose ConTNet (ConvolutionTransformer Network), combining transformer with ConvNet architectures to provide large receptive fields. Unlike the recently-proposed transformer-based models (e.g., ViT, DeiT) that are sensitive to hyper-parameters and extremely dependent on a pile of data augmentations when trained from scratch on a midsize dataset (e.g., ImageNet1k), ConTNet can be optimized like normal ConvNets (e.g., ResNet) and preserve an outstanding robustness. It is also worth pointing that, given identical strong data augmentations, the performance improvement of ConTNet is more remarkable than that of ResNet. We present its superiority and effectiveness on image classification and downstream tasks. For example, our ConTNet achieves 81.8% top-1 accuracy on ImageNet which is the same as DeiT-B with less than 40% computational complexity. ConTNet-M also outperforms ResNet50 as the backbone of both Faster-RCNN (by 2.6%) and Mask-RCNN (by 3.2%) on COCO2017 dataset. We hope that ConTNet could serve as a useful backbone for CV tasks and bring new ideas for model design
Tracking e-cigarette warning label compliance on Instagram with deep learning
Feb 08, 2021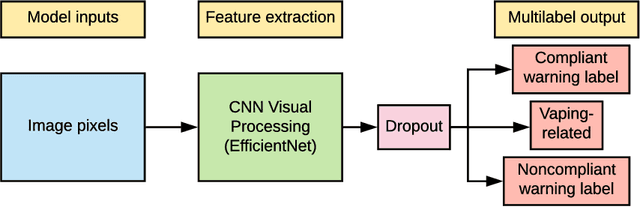

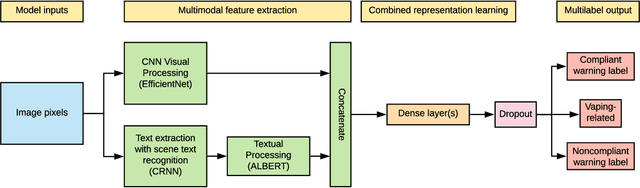
The U.S. Food & Drug Administration (FDA) requires that e-cigarette advertisements include a prominent warning label that reminds consumers that nicotine is addictive. However, the high volume of vaping-related posts on social media makes compliance auditing expensive and time-consuming, suggesting that an automated, scalable method is needed. We sought to develop and evaluate a deep learning system designed to automatically determine if an Instagram post promotes vaping, and if so, if an FDA-compliant warning label was included or if a non-compliant warning label was visible in the image. We compiled and labeled a dataset of 4,363 Instagram images, of which 44% were vaping-related, 3% contained FDA-compliant warning labels, and 4% contained non-compliant labels. Using a 20% test set for evaluation, we tested multiple neural network variations: image processing backbone model (Inceptionv3, ResNet50, EfficientNet), data augmentation, progressive layer unfreezing, output bias initialization designed for class imbalance, and multitask learning. Our final model achieved an area under the curve (AUC) and [accuracy] of 0.97 [92%] on vaping classification, 0.99 [99%] on FDA-compliant warning labels, and 0.94 [97%] on non-compliant warning labels. We conclude that deep learning models can effectively identify vaping posts on Instagram and track compliance with FDA warning label requirements.
Deep J-Sense: Accelerated MRI Reconstruction via Unrolled Alternating Optimization
Apr 01, 2021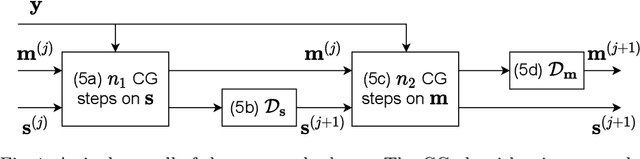
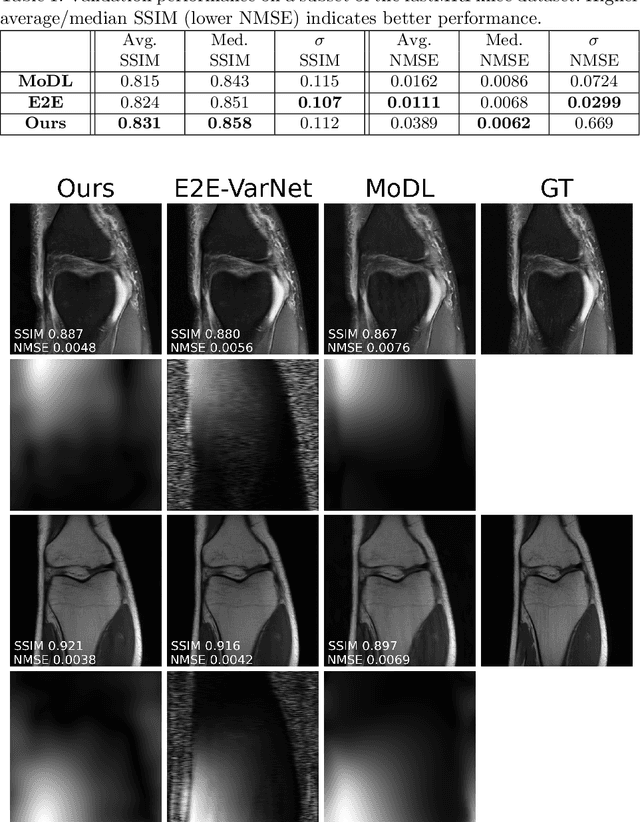
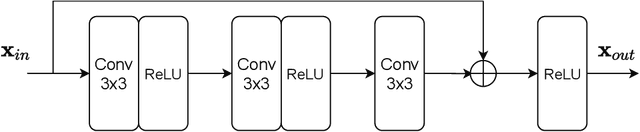
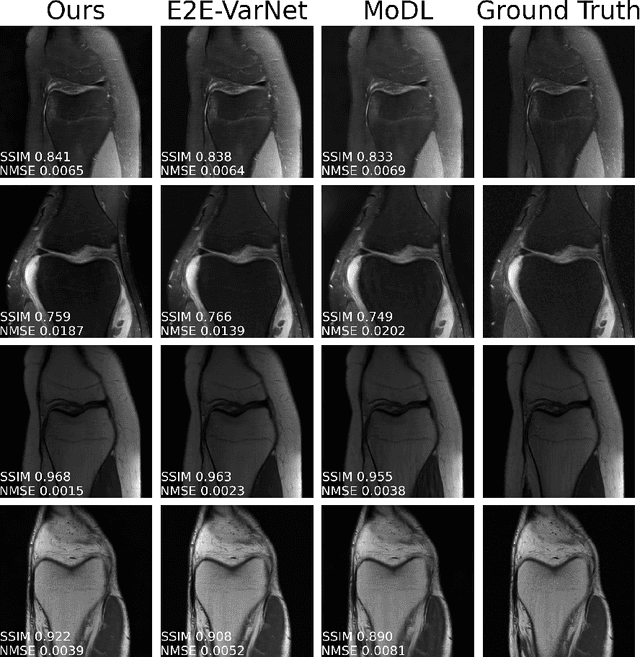
Accelerated multi-coil magnetic resonance imaging reconstruction has seen a substantial recent improvement combining compressed sensing with deep learning. However, most of these methods rely on estimates of the coil sensitivity profiles, or on calibration data for estimating model parameters. Prior work has shown that these methods degrade in performance when the quality of these estimators are poor or when the scan parameters differ from the training conditions. Here we introduce Deep J-Sense as a deep learning approach that builds on unrolled alternating minimization and increases robustness: our algorithm refines both the magnetization (image) kernel and the coil sensitivity maps. Experimental results on a subset of the knee fastMRI dataset show that this increases reconstruction performance and provides a significant degree of robustness to varying acceleration factors and calibration region sizes.
SREDS: A dichromatic separation based measure of skin color
Apr 07, 2021


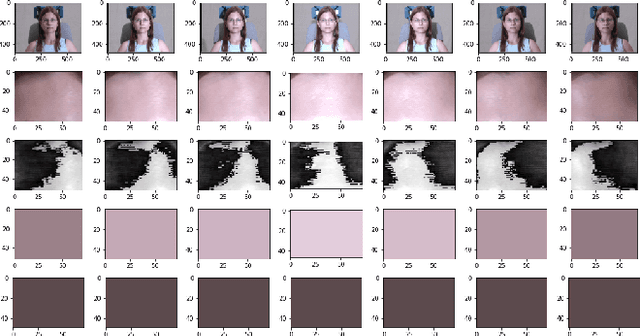
Face recognition (FR) systems are fast becoming ubiquitous. However, differential performance among certain demographics was identified in several widely used FR models. The skin tone of the subject is an important factor in addressing the differential performance. Previous work has used modeling methods to propose skin tone measures of subjects across different illuminations or utilized subjective labels of skin color and demographic information. However, such models heavily rely on consistent background and lighting for calibration, or utilize labeled datasets, which are time-consuming to generate or are unavailable. In this work, we have developed a novel and data-driven skin color measure capable of accurately representing subjects' skin tone from a single image, without requiring a consistent background or illumination. Our measure leverages the dichromatic reflection model in RGB space to decompose skin patches into diffuse and specular bases.
Omnimatte: Associating Objects and Their Effects in Video
May 14, 2021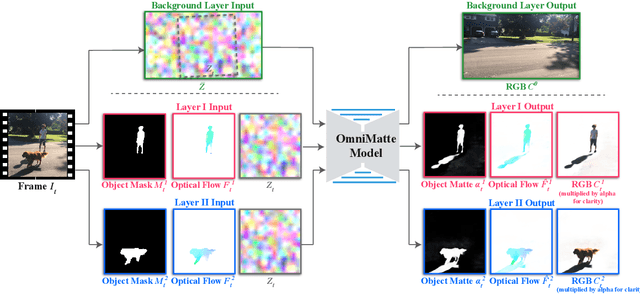



Computer vision is increasingly effective at segmenting objects in images and videos; however, scene effects related to the objects---shadows, reflections, generated smoke, etc---are typically overlooked. Identifying such scene effects and associating them with the objects producing them is important for improving our fundamental understanding of visual scenes, and can also assist a variety of applications such as removing, duplicating, or enhancing objects in video. In this work, we take a step towards solving this novel problem of automatically associating objects with their effects in video. Given an ordinary video and a rough segmentation mask over time of one or more subjects of interest, we estimate an omnimatte for each subject---an alpha matte and color image that includes the subject along with all its related time-varying scene elements. Our model is trained only on the input video in a self-supervised manner, without any manual labels, and is generic---it produces omnimattes automatically for arbitrary objects and a variety of effects. We show results on real-world videos containing interactions between different types of subjects (cars, animals, people) and complex effects, ranging from semi-transparent elements such as smoke and reflections, to fully opaque effects such as objects attached to the subject.