 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Self-Training Ensemble Networks for Zero-Shot Image Recognition
May 18, 2018
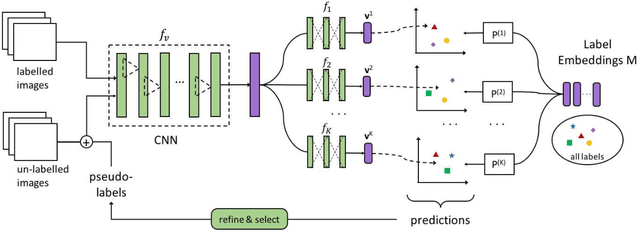
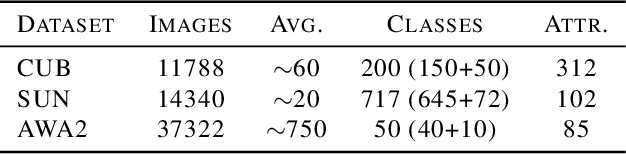
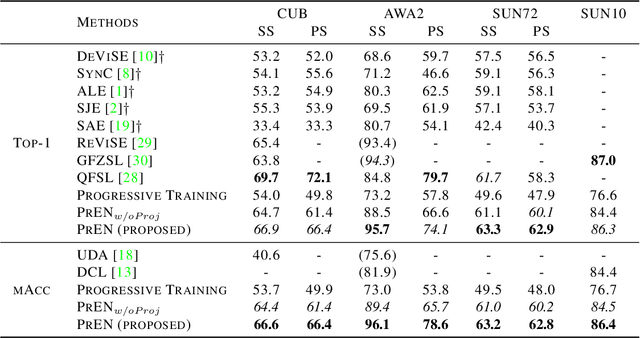
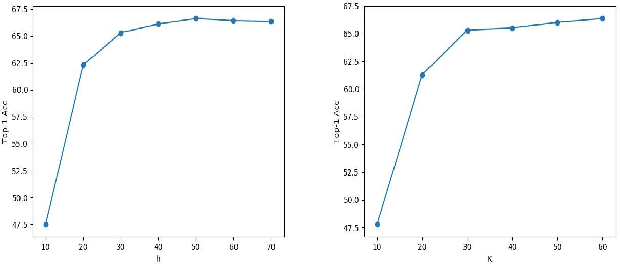
Despite the advancement of supervised image recognition algorithms, their de- pendence on the availability of labeled data and the rapid expansion of image categories raise the significant challenge of zero-shot learning. Zero-shot learn- ing (ZSL) aims to transfer knowledge from labeled classes into unlabeled classes to reduce human labeling effort. In this paper, we propose a novel self-training ensemble network model to address zero-shot image recognition. The ensemble network is built by learning multiple image classification functions with a shared feature extraction network but different label embedding representations, each of which facilitates information transfer to different subsets of unlabeled classes. A self-training framework is then deployed to iteratively label the most confident images in each unlabeled class with predicted pseudo-labels and update the ensem- ble network with the training data augmented by the pseudo-labels. The proposed model performs training on both labeled and unlabeled data. It can naturally bridge the domain shift problem in visual appearances and be extended to the generalized zero-shot learning scenario. We conduct experiments on multiple standard ZSL datasets and the empirical results demonstrate the efficacy of the proposed model.
OAAE: Adversarial Autoencoders for Novelty Detection in Multi-modal Normality Case via Orthogonalized Latent Space
Jan 07, 2021
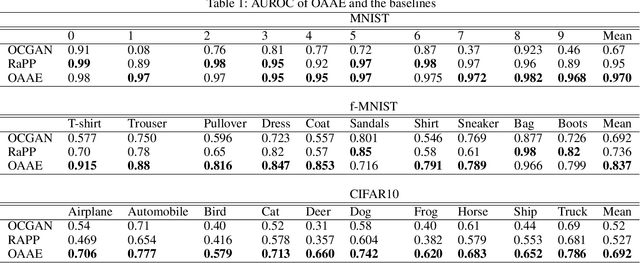
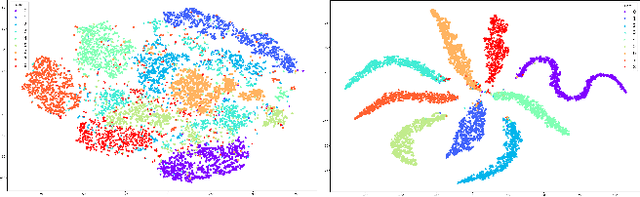
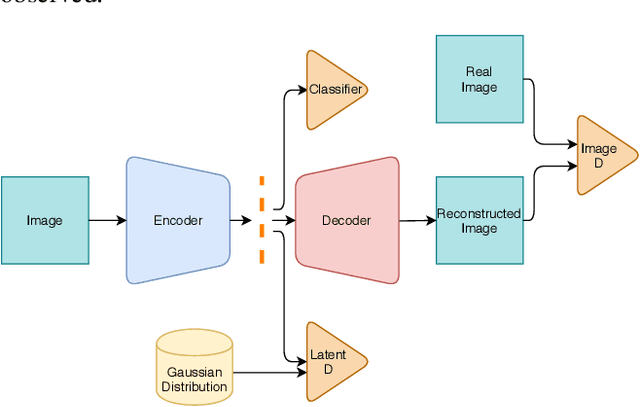
Novelty detection using deep generative models such as autoencoder, generative adversarial networks mostly takes image reconstruction error as novelty score function. However, image data, high dimensional as it is, contains a lot of different features other than class information which makes models hard to detect novelty data. The problem gets harder in multi-modal normality case. To address this challenge, we propose a new way of measuring novelty score in multi-modal normality cases using orthogonalized latent space. Specifically, we employ orthogonal low-rank embedding in the latent space to disentangle the features in the latent space using mutual class information. With the orthogonalized latent space, novelty score is defined by the change of each latent vector. Proposed algorithm was compared to state-of-the-art novelty detection algorithms using GAN such as RaPP and OCGAN, and experimental results show that ours outperforms those algorithms.
Generating 3D structures from a 2D slice with GAN-based dimensionality expansion
Feb 10, 2021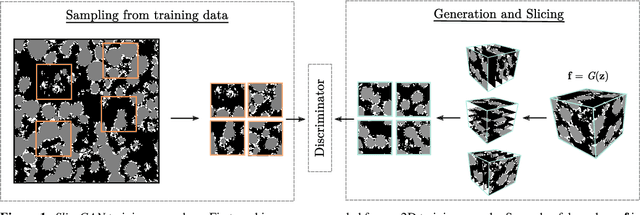
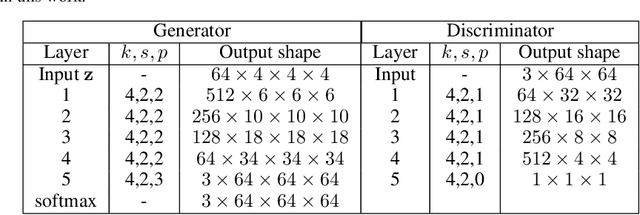
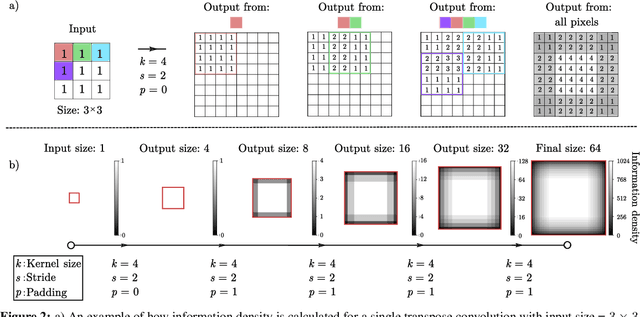

Generative adversarial networks (GANs) can be trained to generate 3D image data, which is useful for design optimisation. However, this conventionally requires 3D training data, which is challenging to obtain. 2D imaging techniques tend to be faster, higher resolution, better at phase identification and more widely available. Here, we introduce a generative adversarial network architecture, SliceGAN, which is able to synthesise high fidelity 3D datasets using a single representative 2D image. This is especially relevant for the task of material microstructure generation, as a cross-sectional micrograph can contain sufficient information to statistically reconstruct 3D samples. Our architecture implements the concept of uniform information density, which both ensures that generated volumes are equally high quality at all points in space, and that arbitrarily large volumes can be generated. SliceGAN has been successfully trained on a diverse set of materials, demonstrating the widespread applicability of this tool. The quality of generated micrographs is shown through a statistical comparison of synthetic and real datasets of a battery electrode in terms of key microstructural metrics. Finally, we find that the generation time for a $10^8$ voxel volume is on the order of a few seconds, yielding a path for future studies into high-throughput microstructural optimisation.
Hardware Architecture of Embedded Inference Accelerator and Analysis of Algorithms for Depthwise and Large-Kernel Convolutions
Apr 29, 2021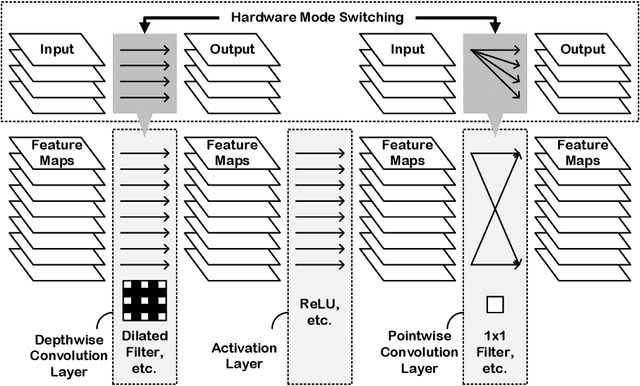
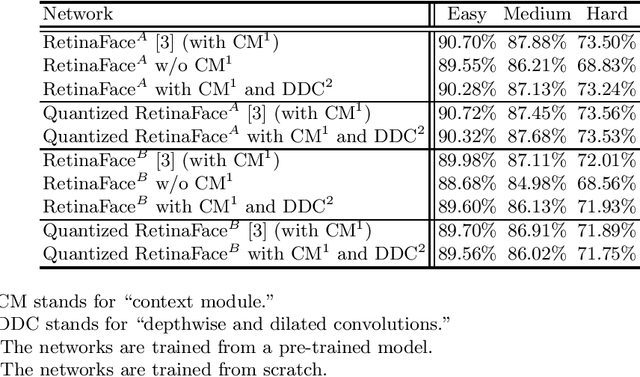
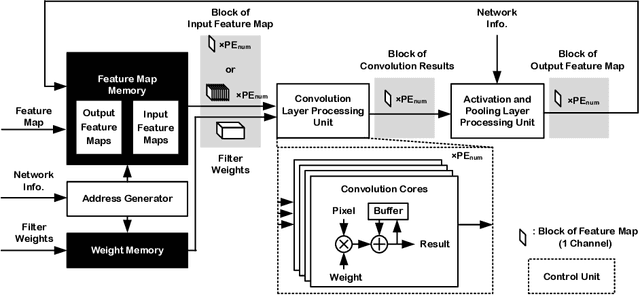
In order to handle modern convolutional neural networks (CNNs) efficiently, a hardware architecture of CNN inference accelerator is proposed to handle depthwise convolutions and regular convolutions, which are both essential building blocks for embedded-computer-vision algorithms. Different from related works, the proposed architecture can support filter kernels with different sizes with high flexibility since it does not require extra costs for intra-kernel parallelism, and it can generate convolution results faster than the architecture of the related works. The experimental results show the importance of supporting depthwise convolutions and dilated convolutions with the proposed hardware architecture. In addition to depthwise convolutions with large-kernels, a new structure called DDC layer, which includes the combination of depthwise convolutions and dilated convolutions, is also analyzed in this paper. For face detection, the computational costs decrease by 30%, and the model size decreases by 20% when the DDC layers are applied to the network. For image classification, the accuracy is increased by 1% by simply replacing $3 \times 3$ filters with $5 \times 5$ filters in depthwise convolutions.
* Camera-ready version for ECCV 2020 workshop (Embedded Vision Workshop)
RankSRGAN: Generative Adversarial Networks with Ranker for Image Super-Resolution
Aug 18, 2019
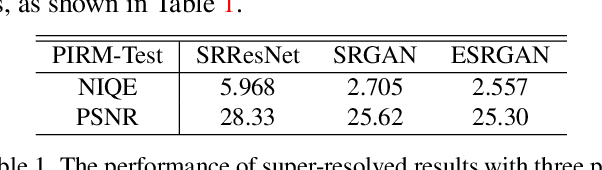
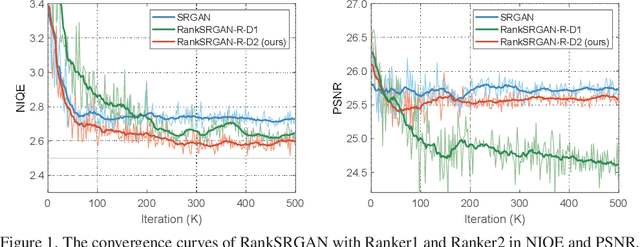
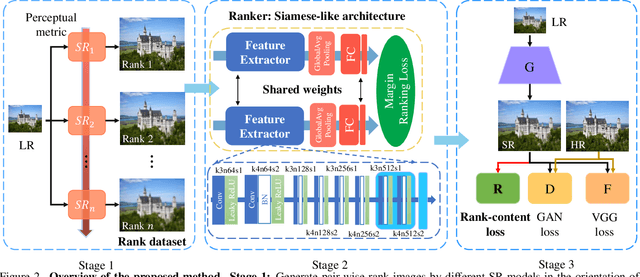
Generative Adversarial Networks (GAN) have demonstrated the potential to recover realistic details for single image super-resolution (SISR). To further improve the visual quality of super-resolved results, PIRM2018-SR Challenge employed perceptual metrics to assess the perceptual quality, such as PI, NIQE, and Ma. However, existing methods cannot directly optimize these indifferentiable perceptual metrics, which are shown to be highly correlated with human ratings. To address the problem, we propose Super-Resolution Generative Adversarial Networks with Ranker (RankSRGAN) to optimize generator in the direction of perceptual metrics. Specifically, we first train a Ranker which can learn the behavior of perceptual metrics and then introduce a novel rank-content loss to optimize the perceptual quality. The most appealing part is that the proposed method can combine the strengths of different SR methods to generate better results. Extensive experiments show that RankSRGAN achieves visually pleasing results and reaches state-of-the-art performance in perceptual metrics. Project page: https://wenlongzhang0724.github.io/Projects/RankSRGAN
Temporal Consistency Loss for High Resolution Textured and Clothed 3DHuman Reconstruction from Monocular Video
Apr 19, 2021
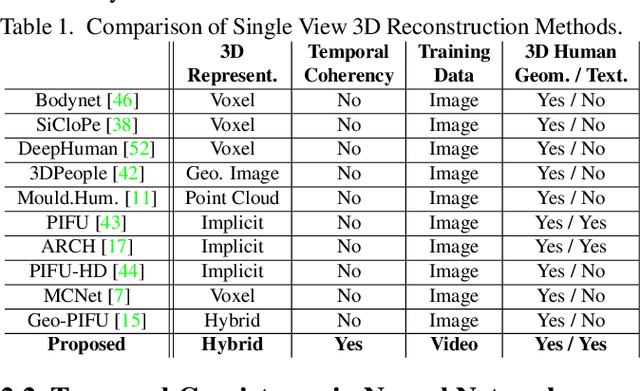
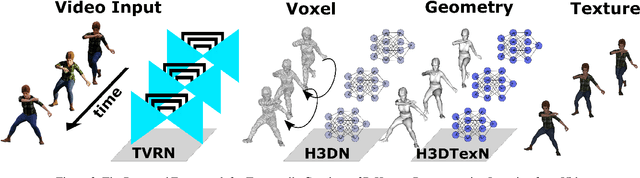
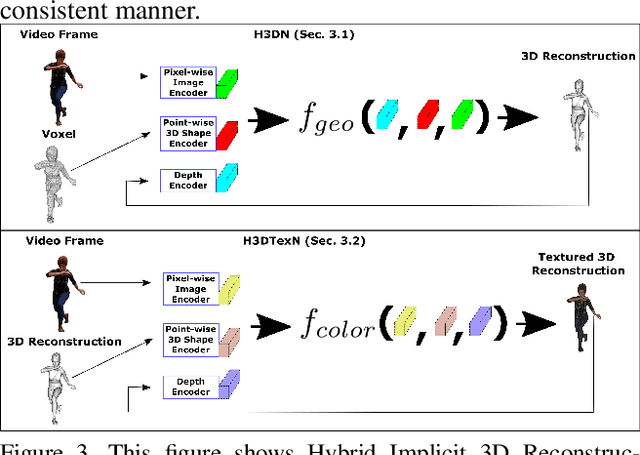
We present a novel method to learn temporally consistent 3D reconstruction of clothed people from a monocular video. Recent methods for 3D human reconstruction from monocular video using volumetric, implicit or parametric human shape models, produce per frame reconstructions giving temporally inconsistent output and limited performance when applied to video. In this paper, we introduce an approach to learn temporally consistent features for textured reconstruction of clothed 3D human sequences from monocular video by proposing two advances: a novel temporal consistency loss function; and hybrid representation learning for implicit 3D reconstruction from 2D images and coarse 3D geometry. The proposed advances improve the temporal consistency and accuracy of both the 3D reconstruction and texture prediction from a monocular video. Comprehensive comparative performance evaluation on images of people demonstrates that the proposed method significantly outperforms the state-of-the-art learning-based single image 3D human shape estimation approaches achieving significant improvement of reconstruction accuracy, completeness, quality and temporal consistency.
Understanding Compositional Structures in Art Historical Images using Pose and Gaze Priors
Sep 08, 2020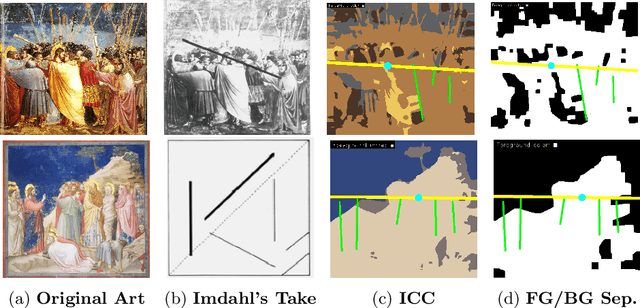
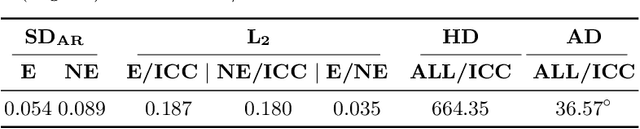
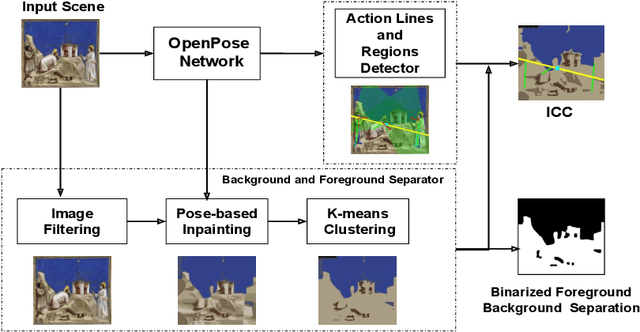

Image compositions as a tool for analysis of artworks is of extreme significance for art historians. These compositions are useful in analyzing the interactions in an image to study artists and their artworks. Max Imdahl in his work called Ikonik, along with other prominent art historians of the 20th century, underlined the aesthetic and semantic importance of the structural composition of an image. Understanding underlying compositional structures within images is challenging and a time consuming task. Generating these structures automatically using computer vision techniques (1) can help art historians towards their sophisticated analysis by saving lot of time; providing an overview and access to huge image repositories and (2) also provide an important step towards an understanding of man made imagery by machines. In this work, we attempt to automate this process using the existing state of the art machine learning techniques, without involving any form of training. Our approach, inspired by Max Imdahl's pioneering work, focuses on two central themes of image composition: (a) detection of action regions and action lines of the artwork; and (b) pose-based segmentation of foreground and background. Currently, our approach works for artworks comprising of protagonists (persons) in an image. In order to validate our approach qualitatively and quantitatively, we conduct a user study involving experts and non-experts. The outcome of the study highly correlates with our approach and also demonstrates its domain-agnostic capability. We have open-sourced the code at https://github.com/image-compostion-canvas-group/image-compostion-canvas.
Plants Don't Walk on the Street: Common-Sense Reasoning for Reliable Semantic Segmentation
Apr 19, 2021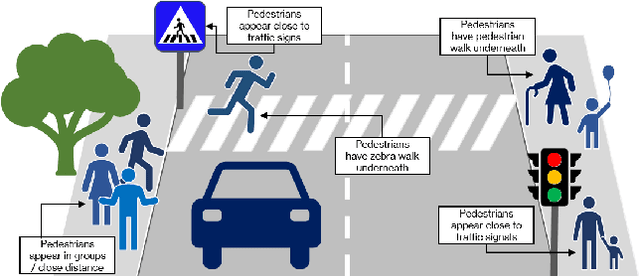

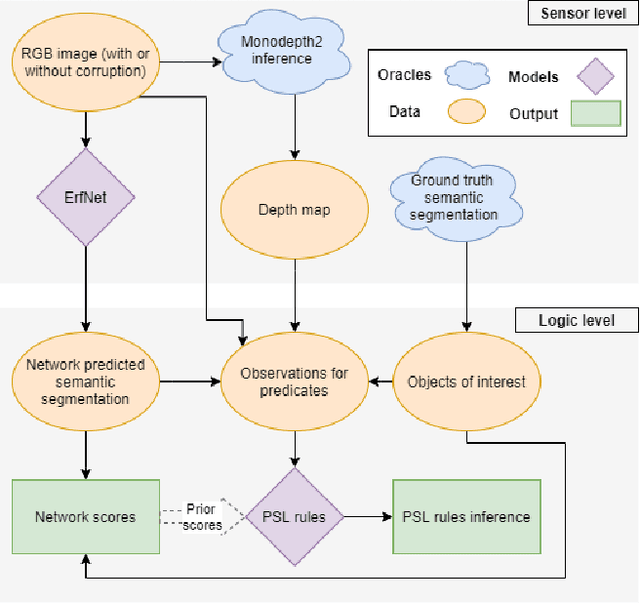

Data-driven sensor interpretation in autonomous driving can lead to highly implausible predictions as can most of the time be verified with common-sense knowledge. However, learning common knowledge only from data is hard and approaches for knowledge integration are an active research area. We propose to use a partly human-designed, partly learned set of rules to describe relations between objects of a traffic scene on a high level of abstraction. In doing so, we improve and robustify existing deep neural networks consuming low-level sensor information. We present an initial study adapting the well-established Probabilistic Soft Logic (PSL) framework to validate and improve on the problem of semantic segmentation. We describe in detail how we integrate common knowledge into the segmentation pipeline using PSL and verify our approach in a set of experiments demonstrating the increase in robustness against several severe image distortions applied to the A2D2 autonomous driving data set.
Neural Twins Talk
Sep 26, 2020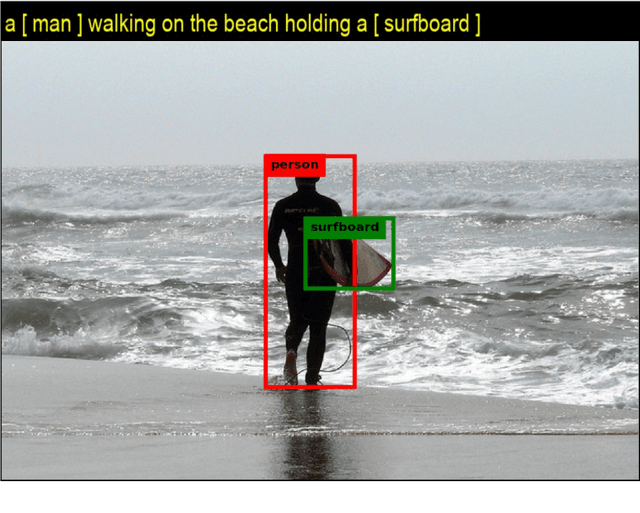
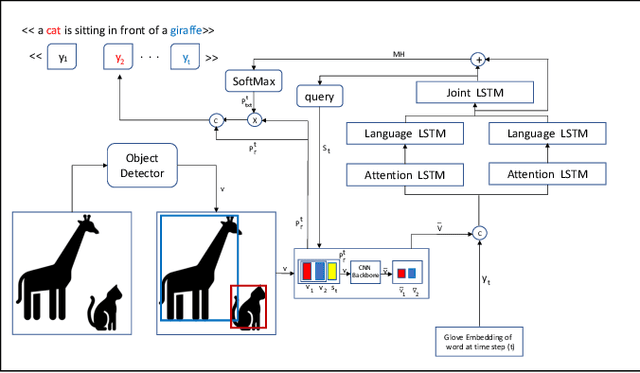
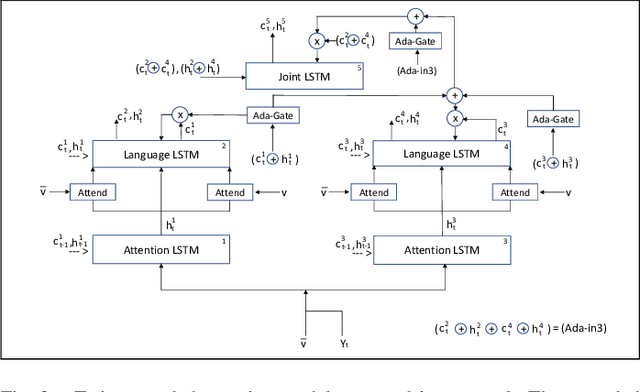

Inspired by how the human brain employs more neural pathways when increasing the focus on a subject, we introduce a novel twin cascaded attention model that outperforms a state-of-the-art image captioning model that was originally implemented using one channel of attention for the visual grounding task. Visual grounding ensures the existence of words in the caption sentence that are grounded into a particular region in the input image. After a deep learning model is trained on visual grounding task, the model employs the learned patterns regarding the visual grounding and the order of objects in the caption sentences, when generating captions. We report the results of our experiments in three image captioning tasks on the COCO dataset. The results are reported using standard image captioning metrics to show the improvements achieved by our model over the previous image captioning model. The results gathered from our experiments suggest that employing more parallel attention pathways in a deep neural network leads to higher performance. Our implementation of NTT is publicly available at: https://github.com/zanyarz/NeuralTwinsTalk.
* Copyright 2020 IEEE. Personal use of this material is permitted. Permission from IEEE must be obtained for all other uses, in any current or future media, including reprinting/republishing this material for advertising or promotional purposes, creating new collective works, for resale or redistribution to servers or lists, or reuse of any copyrighted component of this work in other works
One Shot Audio to Animated Video Generation
Feb 19, 2021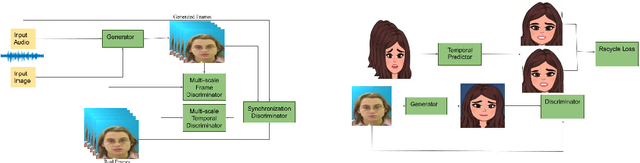
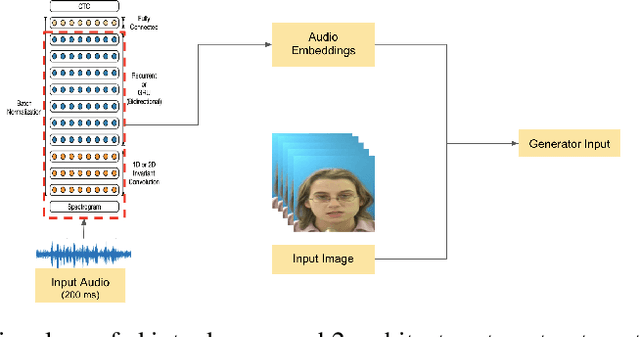


We consider the challenging problem of audio to animated video generation. We propose a novel method OneShotAu2AV to generate an animated video of arbitrary length using an audio clip and a single unseen image of a person as an input. The proposed method consists of two stages. In the first stage, OneShotAu2AV generates the talking-head video in the human domain given an audio and a person's image. In the second stage, the talking-head video from the human domain is converted to the animated domain. The model architecture of the first stage consists of spatially adaptive normalization based multi-level generator and multiple multilevel discriminators along with multiple adversarial and non-adversarial losses. The second stage leverages attention based normalization driven GAN architecture along with temporal predictor based recycle loss and blink loss coupled with lipsync loss, for unsupervised generation of animated video. In our approach, the input audio clip is not restricted to any specific language, which gives the method multilingual applicability. OneShotAu2AV can generate animated videos that have: (a) lip movements that are in sync with the audio, (b) natural facial expressions such as blinks and eyebrow movements, (c) head movements. Experimental evaluation demonstrates superior performance of OneShotAu2AV as compared to U-GAT-IT and RecycleGan on multiple quantitative metrics including KID(Kernel Inception Distance), Word error rate, blinks/sec