 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
T2Net: Synthetic-to-Realistic Translation for Solving Single-Image Depth Estimation Tasks
Aug 04, 2018

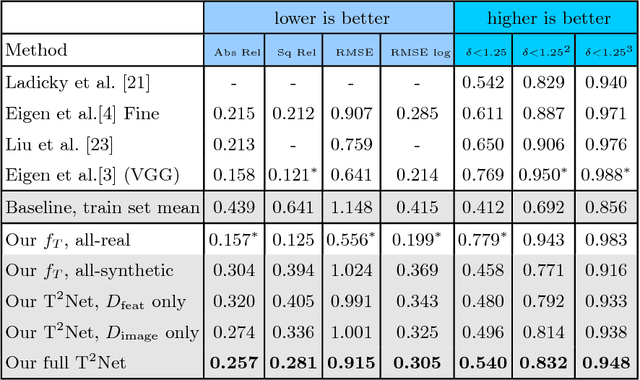
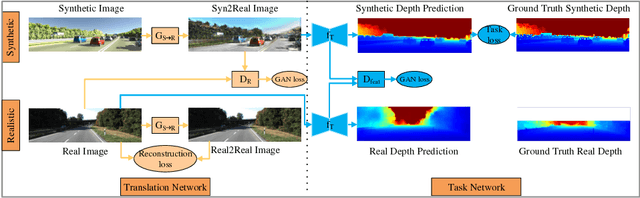
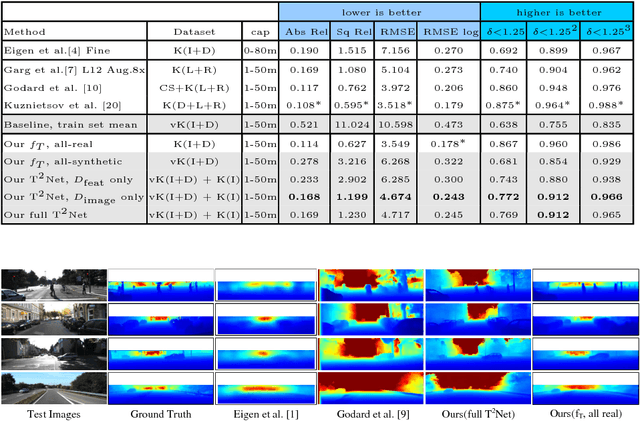
Current methods for single-image depth estimation use training datasets with real image-depth pairs or stereo pairs, which are not easy to acquire. We propose a framework, trained on synthetic image-depth pairs and unpaired real images, that comprises an image translation network for enhancing realism of input images, followed by a depth prediction network. A key idea is having the first network act as a wide-spectrum input translator, taking in either synthetic or real images, and ideally producing minimally modified realistic images. This is done via a reconstruction loss when the training input is real, and GAN loss when synthetic, removing the need for heuristic self-regularization. The second network is trained on a task loss for synthetic image-depth pairs, with extra GAN loss to unify real and synthetic feature distributions. Importantly, the framework can be trained end-to-end, leading to good results, even surpassing early deep-learning methods that use real paired data.
Camera-Space Hand Mesh Recovery via Semantic Aggregation and Adaptive 2D-1D Registration
Mar 04, 2021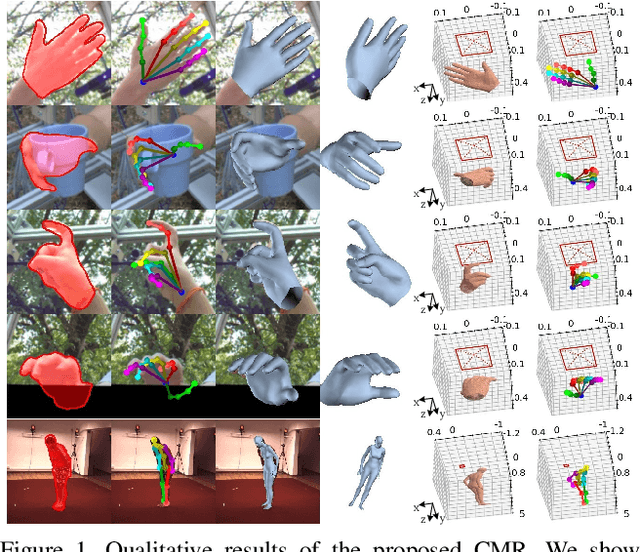
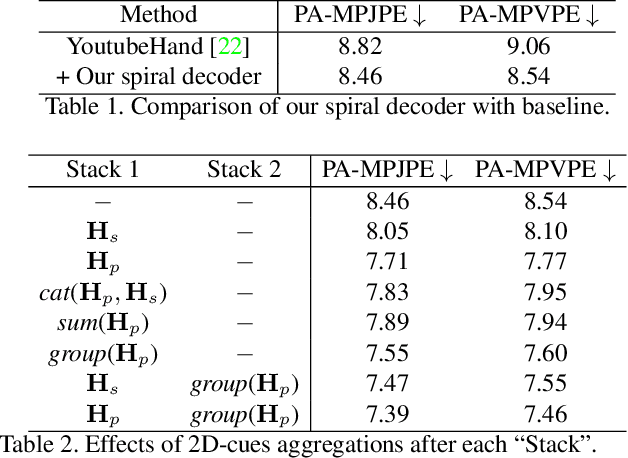
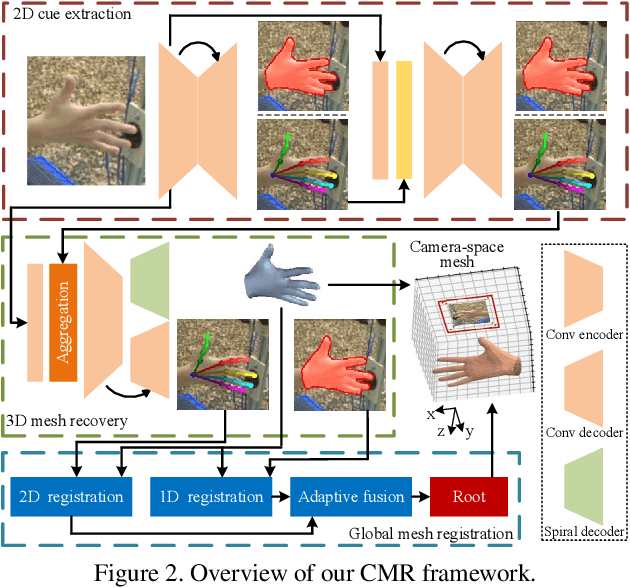
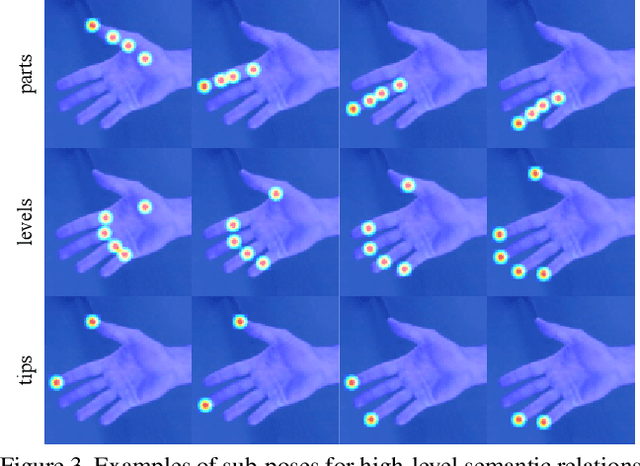
Recent years have witnessed significant progress in 3D hand mesh recovery. Nevertheless, because of the intrinsic 2D-to-3D ambiguity, recovering camera-space 3D information from a single RGB image remains challenging. To tackle this problem, we divide camera-space mesh recovery into two sub-tasks, i.e., root-relative mesh recovery and root recovery. First, joint landmarks and silhouette are extracted from a single input image to provide 2D cues for the 3D tasks. In the root-relative mesh recovery task, we exploit semantic relations among joints to generate a 3D mesh from the extracted 2D cues. Such generated 3D mesh coordinates are expressed relative to a root position, i.e., wrist of the hand. In the root recovery task, the root position is registered to the camera space by aligning the generated 3D mesh back to 2D cues, thereby completing camera-space 3D mesh recovery. Our pipeline is novel in that (1) it explicitly makes use of known semantic relations among joints and (2) it exploits 1D projections of the silhouette and mesh to achieve robust registration. Extensive experiments on popular datasets such as FreiHAND, RHD, and Human3.6M demonstrate that our approach achieves state-of-the-art performance on both root-relative mesh recovery and root recovery. Our code is publicly available at https://github.com/SeanChenxy/HandMesh.
Human Activity Recognition using Continuous Wavelet Transform and Convolutional Neural Networks
Jun 29, 2021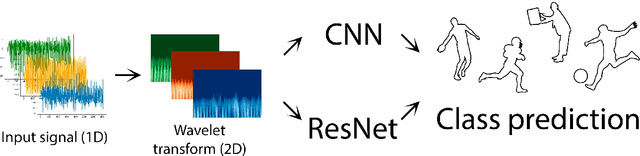
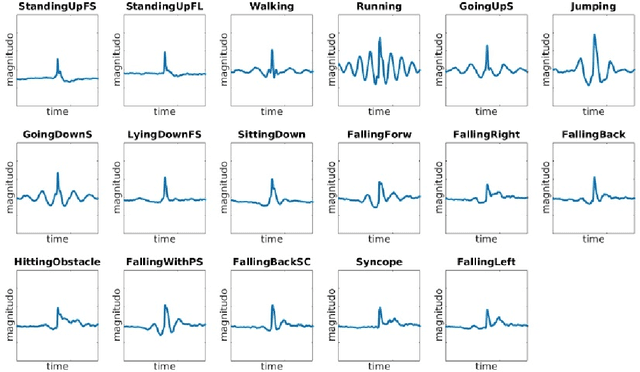
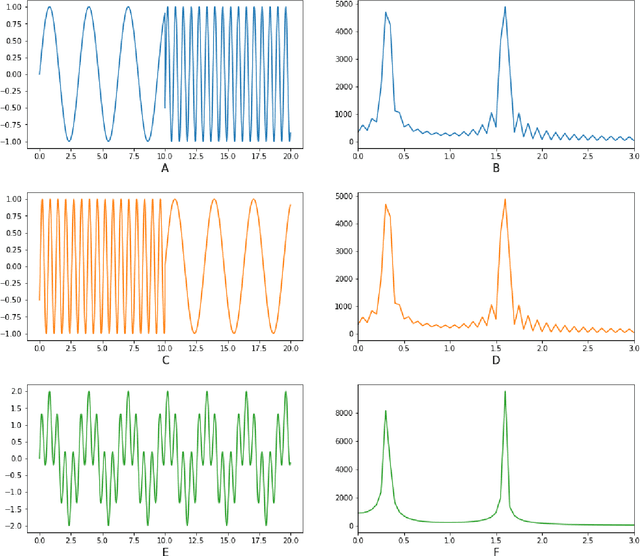
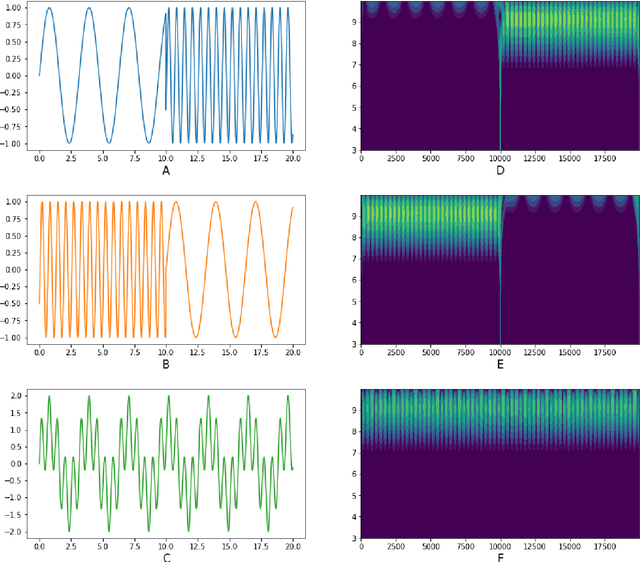
Quite a few people in the world have to stay under permanent surveillance for health reasons; they include diabetic people or people with some other chronic conditions, the elderly and the disabled.These groups may face heightened risk of having life-threatening falls or of being struck by a syncope. Due to limited availability of resources a substantial part of people at risk can not receive necessary monitoring and thus are exposed to excessive danger. Nowadays, this problem is usually solved via applying Human Activity Recognition (HAR) methods. HAR is a perspective and fast-paced Data Science field, which has a wide range of application areas such as healthcare, sport, security etc. However, the currently techniques of recognition are markedly lacking in accuracy, hence, the present paper suggests a highly accurate method for human activity classification. Wepropose a new workflow to address the HAR problem and evaluate it on the UniMiB SHAR dataset, which consists of the accelerometer signals. The model we suggest is based on continuous wavelet transform (CWT) and convolutional neural networks (CNNs). Wavelet transform localizes signal features both in time and frequency domains and after that a CNN extracts these features and recognizes activity. It is also worth noting that CWT converts 1D accelerometer signal into 2D images and thus enables to obtain better results as 2D networks have a significantly higher predictive capacity. In the course of the work we build a convolutional neural network and vary such model parameters as number of spatial axes, number of layers, number of neurons in each layer, image size, type of mother wavelet, the order of zero moment of mother wavelet etc. Besides, we also apply models with residual blocks which resulted in significantly higher metric values. Finally, we succeed to reach 99.26 % accuracy and it is a worthy performance for this problem.
A Perceptual Model for Eccentricity-dependent Spatio-temporal Flicker Fusion and its Applications to Foveated Graphics
May 20, 2021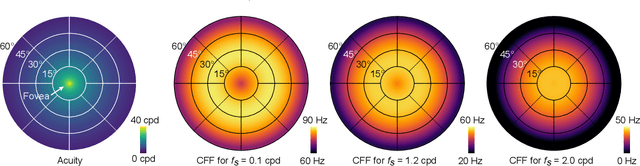
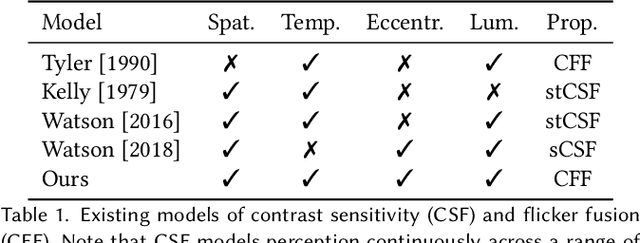

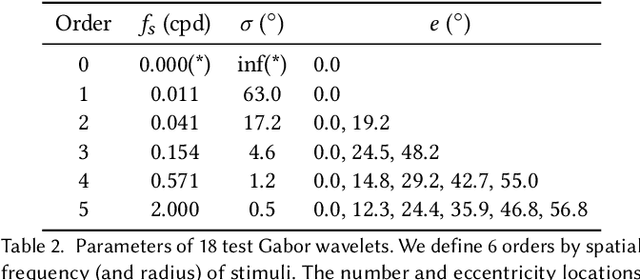
Virtual and augmented reality (VR/AR) displays strive to provide a resolution, framerate and field of view that matches the perceptual capabilities of the human visual system, all while constrained by limited compute budgets and transmission bandwidths of wearable computing systems. Foveated graphics techniques have emerged that could achieve these goals by exploiting the falloff of spatial acuity in the periphery of the visual field. However, considerably less attention has been given to temporal aspects of human vision, which also vary across the retina. This is in part due to limitations of current eccentricity-dependent models of the visual system. We introduce a new model, experimentally measuring and computationally fitting eccentricity-dependent critical flicker fusion thresholds jointly for both space and time. In this way, our model is unique in enabling the prediction of temporal information that is imperceptible for a certain spatial frequency, eccentricity, and range of luminance levels. We validate our model with an image quality user study, and use it to predict potential bandwidth savings 7x higher than those afforded by current spatial-only foveated models. As such, this work forms the enabling foundation for new temporally foveated graphics techniques.
Advanced Hough-based method for on-device document localization
Jun 18, 2021
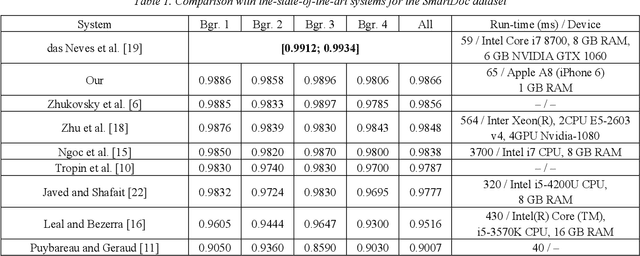
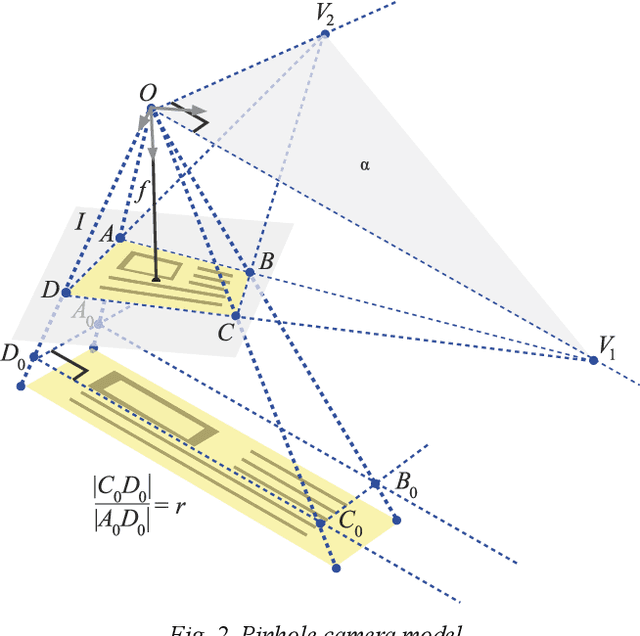

The demand for on-device document recognition systems increases in conjunction with the emergence of more strict privacy and security requirements. In such systems, there is no data transfer from the end device to a third-party information processing servers. The response time is vital to the user experience of on-device document recognition. Combined with the unavailability of discrete GPUs, powerful CPUs, or a large RAM capacity on consumer-grade end devices such as smartphones, the time limitations put significant constraints on the computational complexity of the applied algorithms for on-device execution. In this work, we consider document location in an image without prior knowledge of the document content or its internal structure. In accordance with the published works, at least 5 systems offer solutions for on-device document location. All these systems use a location method which can be considered Hough-based. The precision of such systems seems to be lower than that of the state-of-the-art solutions which were not designed to account for the limited computational resources. We propose an advanced Hough-based method. In contrast with other approaches, it accounts for the geometric invariants of the central projection model and combines both edge and color features for document boundary detection. The proposed method allowed for the second best result for SmartDoc dataset in terms of precision, surpassed by U-net like neural network. When evaluated on a more challenging MIDV-500 dataset, the proposed algorithm guaranteed the best precision compared to published methods. Our method retained the applicability to on-device computations.
Tokens-to-Token ViT: Training Vision Transformers from Scratch on ImageNet
Jan 28, 2021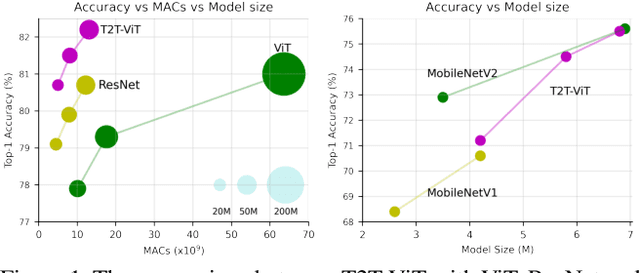
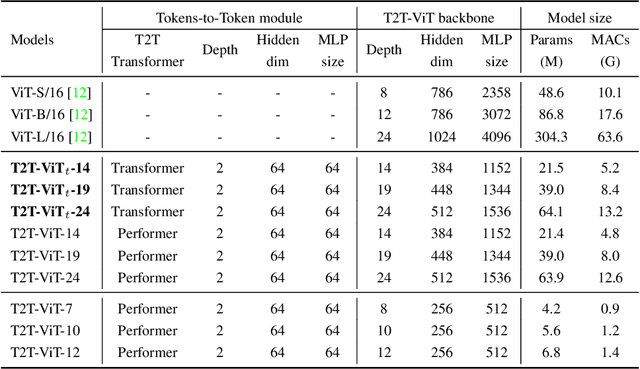

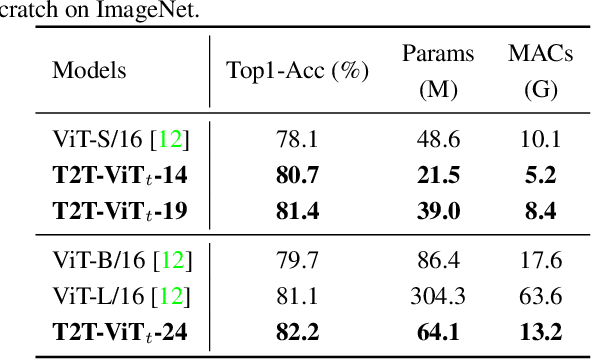
Transformers, which are popular for language modeling, have been explored for solving vision tasks recently, e.g., the Vision Transformers (ViT) for image classification. The ViT model splits each image into a sequence of tokens with fixed length and then applies multiple Transformer layers to model their global relation for classification. However, ViT achieves inferior performance compared with CNNs when trained from scratch on a midsize dataset (e.g., ImageNet). We find it is because: 1) the simple tokenization of input images fails to model the important local structure (e.g., edges, lines) among neighboring pixels, leading to its low training sample efficiency; 2) the redundant attention backbone design of ViT leads to limited feature richness in fixed computation budgets and limited training samples. To overcome such limitations, we propose a new Tokens-To-Token Vision Transformers (T2T-ViT), which introduces 1) a layer-wise Tokens-to-Token (T2T) transformation to progressively structurize the image to tokens by recursively aggregating neighboring Tokens into one Token (Tokens-to-Token), such that local structure presented by surrounding tokens can be modeled and tokens length can be reduced; 2) an efficient backbone with a deep-narrow structure for vision transformers motivated by CNN architecture design after extensive study. Notably, T2T-ViT reduces the parameter counts and MACs of vanilla ViT by 200\%, while achieving more than 2.5\% improvement when trained from scratch on ImageNet. It also outperforms ResNets and achieves comparable performance with MobileNets when directly training on ImageNet. For example, T2T-ViT with ResNet50 comparable size can achieve 80.7\% top-1 accuracy on ImageNet. (Code: https://github.com/yitu-opensource/T2T-ViT)
Self-Supervised Annotation of Seismic Images using Latent Space Factorization
Sep 10, 2020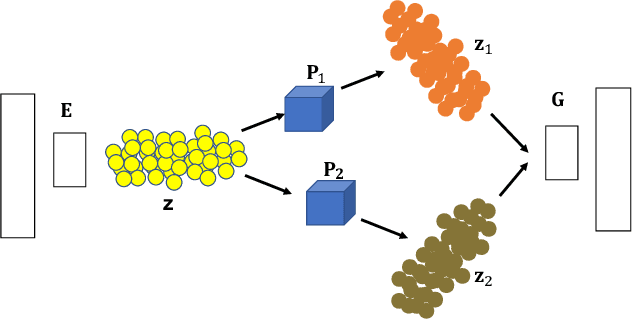
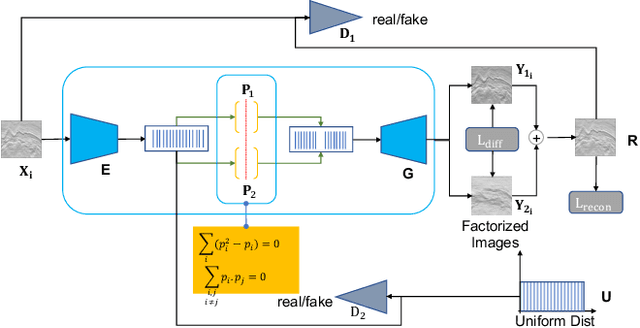
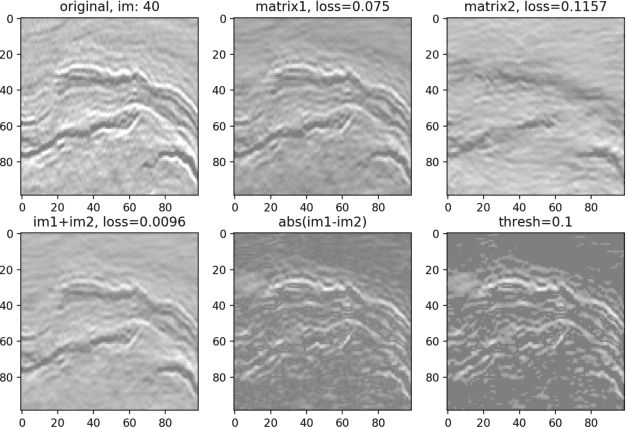
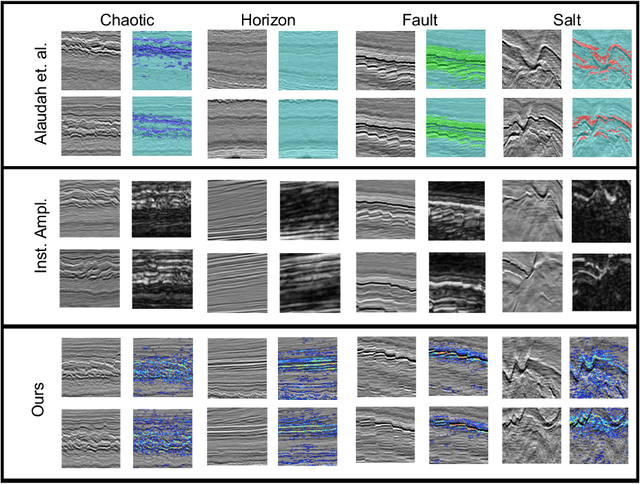
Annotating seismic data is expensive, laborious and subjective due to the number of years required for seismic interpreters to attain proficiency in interpretation. In this paper, we develop a framework to automate annotating pixels of a seismic image to delineate geological structural elements given image-level labels assigned to each image. Our framework factorizes the latent space of a deep encoder-decoder network by projecting the latent space to learned sub-spaces. Using constraints in the pixel space, the seismic image is further factorized to reveal confidence values on pixels associated with the geological element of interest. Details of the annotated image are provided for analysis and qualitative comparison is made with similar frameworks.
Mining Artifacts in Mycelium SEM Micrographs
Mar 12, 2021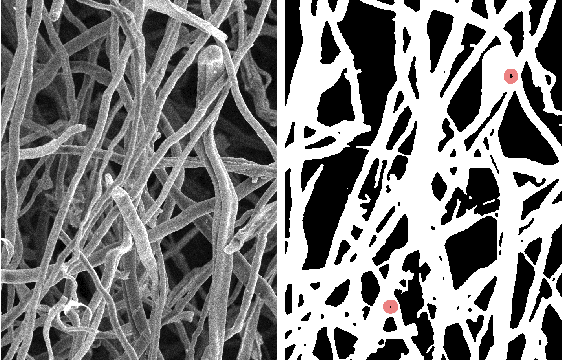
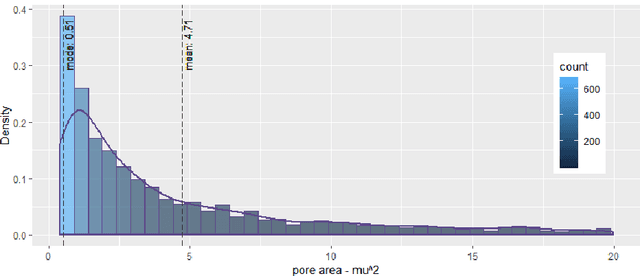
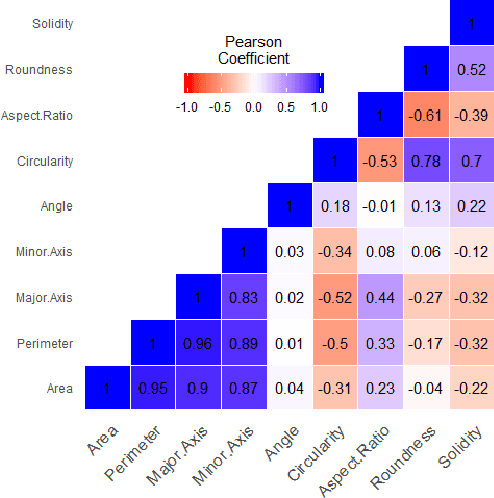
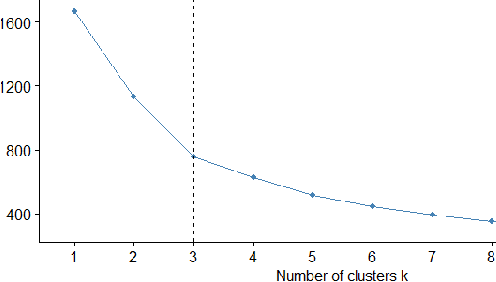
Mycelium is a promising biomaterial based on fungal mycelium, a highly porous, nanofibrous structure. Scanning electron micrographs are used to characterize its network, but the currently available tools for nanofibrous microstructures do not contemplate the particularities of biomaterials. The adoption of a software for artificial nanofibrous in mycelium characterization adds the uncertainty of imaging artifact formation to the analysis. The reported work combines supervised and unsupervised machine learning methods to automate the identification of artifacts in the mapped pores of mycelium microstructure. Keywords: Machine learning; unsupervised learning; image processing; mycelium; microstructure informatics
Towards Fully Automated Manga Translation
Dec 28, 2020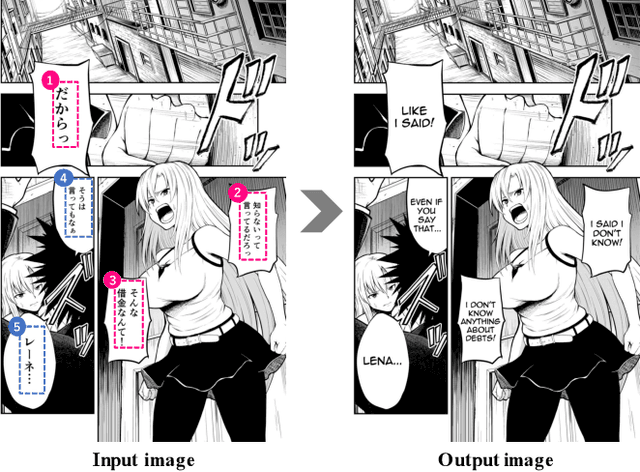
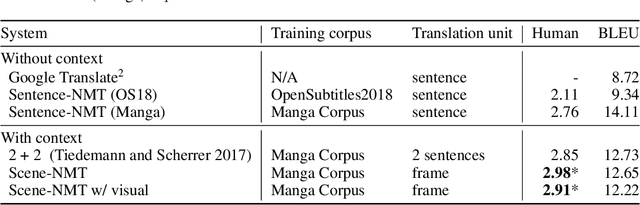
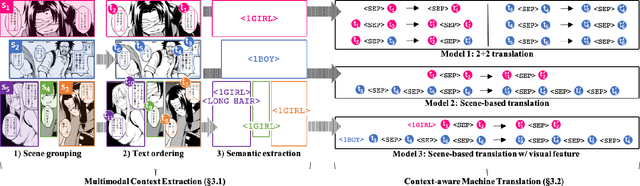
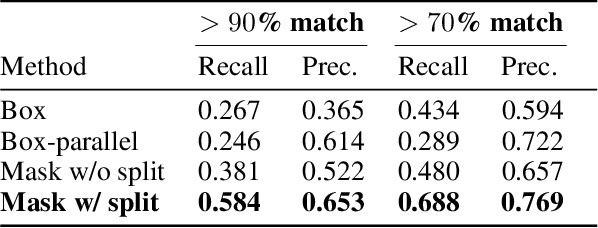
We tackle the problem of machine translation of manga, Japanese comics. Manga translation involves two important problems in machine translation: context-aware and multimodal translation. Since text and images are mixed up in an unstructured fashion in Manga, obtaining context from the image is essential for manga translation. However, it is still an open problem how to extract context from image and integrate into MT models. In addition, corpus and benchmarks to train and evaluate such model is currently unavailable. In this paper, we make the following four contributions that establishes the foundation of manga translation research. First, we propose multimodal context-aware translation framework. We are the first to incorporate context information obtained from manga image. It enables us to translate texts in speech bubbles that cannot be translated without using context information (e.g., texts in other speech bubbles, gender of speakers, etc.). Second, for training the model, we propose the approach to automatic corpus construction from pairs of original manga and their translations, by which large parallel corpus can be constructed without any manual labeling. Third, we created a new benchmark to evaluate manga translation. Finally, on top of our proposed methods, we devised a first comprehensive system for fully automated manga translation.
Learning to Regress 3D Face Shape and Expression from an Image without 3D Supervision
May 16, 2019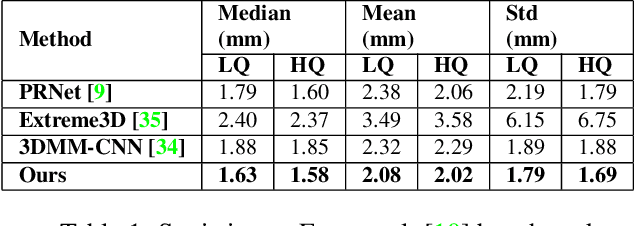
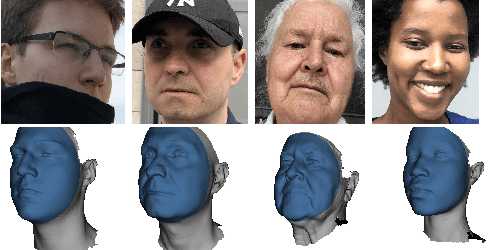
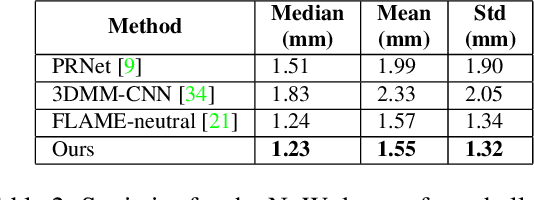
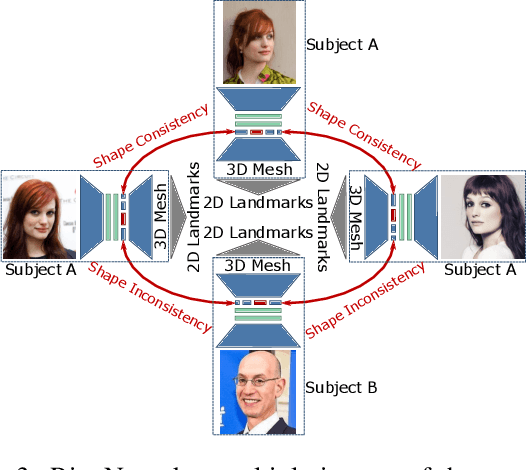
The estimation of 3D face shape from a single image must be robust to variations in lighting, head pose, expression, facial hair, makeup, and occlusions. Robustness requires a large training set of in-the-wild images, which by construction, lack ground truth 3D shape. To train a network without any 2D-to-3D supervision, we present RingNet, which learns to compute 3D face shape from a single image. Our key observation is that an individual's face shape is constant across images, regardless of expression, pose, lighting, etc. RingNet leverages multiple images of a person and automatically detected 2D face features. It uses a novel loss that encourages the face shape to be similar when the identity is the same and different for different people. We achieve invariance to expression by representing the face using the FLAME model. Once trained, our method takes a single image and outputs the parameters of FLAME, which can be readily animated. Additionally we create a new database of faces `not quite in-the-wild' (NoW) with 3D head scans and high-resolution images of the subjects in a wide variety of conditions. We evaluate publicly available methods and find that RingNet is more accurate than methods that use 3D supervision. The dataset, model, and results are available for research purposes at http://ringnet.is.tuebingen.mpg.de.