 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Small Noisy and Perspective Face Detection using Deformable Symmetric Gabor Wavelet Network
Oct 30, 2020
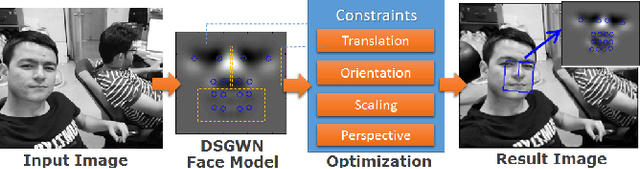


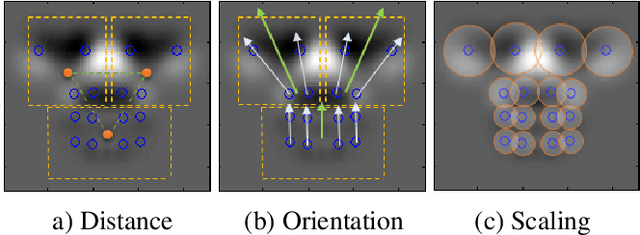
Face detection and tracking in low resolution image is not a trivial task due to the limitation in the appearance features for face characterization. Moreover, facial expression gives additional distortion on this small and noisy face. In this paper, we propose deformable symmetric Gabor wavelet network face model for face detection in low resolution image. Our model optimizes the rotation, translation, dilation, perspective and partial deformation amount of the face model with symmetry constraints. Symmetry constraints help our model to be more robust to noise and distortion. Experimental results on our low resolution face image dataset and videos show promising face detection and tracking results under various challenging conditions.
Automatic Exposure Compensation for Multi-Exposure Image Fusion
May 29, 2018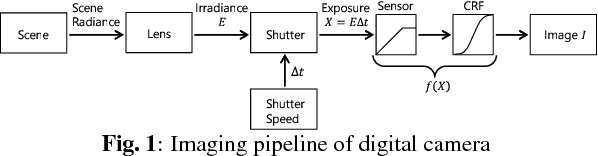



This paper proposes a novel luminance adjustment method based on automatic exposure compensation for multi-exposure image fusion. Multi-exposure image fusion is a method to produce images without saturation regions, by using photos with different exposures. In conventional works, it has been pointed out that the quality of those multi-exposure images can be improved by adjusting the luminance of them. However, how to determine the degree of adjustment has never been discussed. This paper therefore proposes a way to automatically determines the degree on the basis of the luminance distribution of input multi-exposure images. Moreover, new weights, called "simple weights", for image fusion are also considered for the proposed luminance adjustment method. Experimental results show that the multi-exposure images adjusted by the proposed method have better quality than the input multi-exposure ones in terms of the well-exposedness. It is also confirmed that the proposed simple weights provide the highest score of statistical naturalness and discrete entropy in all fusion methods.
Image Processing Operations Identification via Convolutional Neural Network
Sep 09, 2017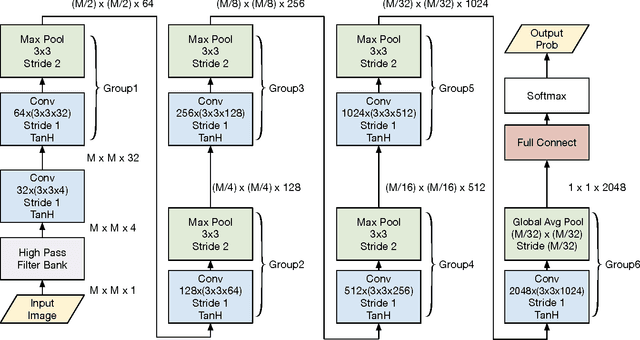
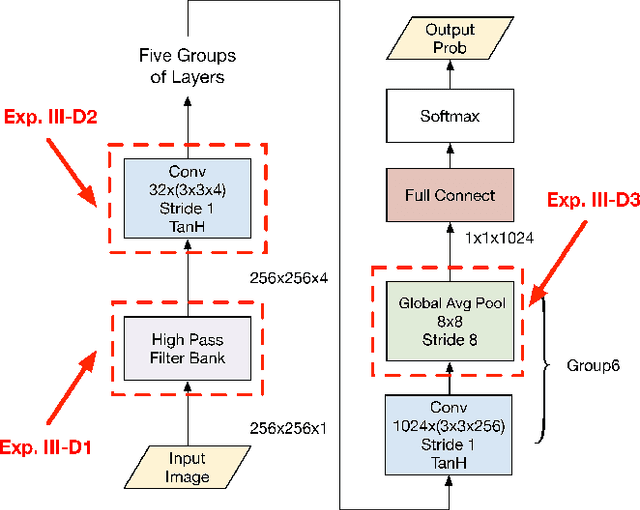
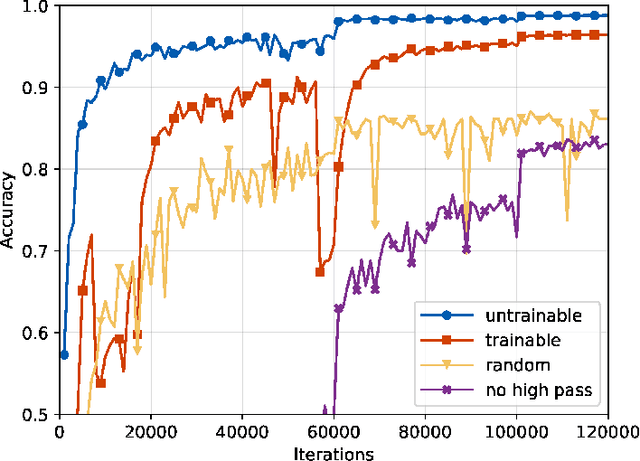
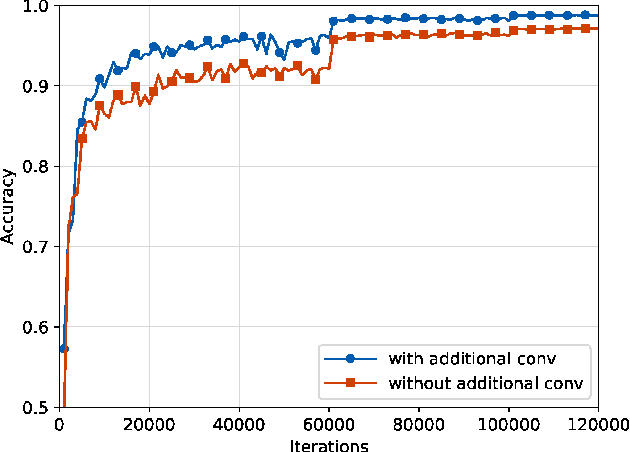
In recent years, image forensics has attracted more and more attention, and many forensic methods have been proposed for identifying image processing operations. Up to now, most existing methods are based on hand crafted features, and just one specific operation is considered in their methods. In many forensic scenarios, however, multiple classification for various image processing operations is more practical. Besides, it is difficult to obtain effective features by hand for some image processing operations. In this paper, therefore, we propose a new convolutional neural network (CNN) based method to adaptively learn discriminative features for identifying typical image processing operations. We carefully design the high pass filter bank to get the image residuals of the input image, the channel expansion layer to mix up the resulting residuals, the pooling layers, and the activation functions employed in our method. The extensive results show that the proposed method can outperform the currently best method based on hand crafted features and three related methods based on CNN for image steganalysis and/or forensics, achieving the state-of-the-art results. Furthermore, we provide more supplementary results to show the rationality and robustness of the proposed model.
Self-Supervised Shadow Removal
Oct 22, 2020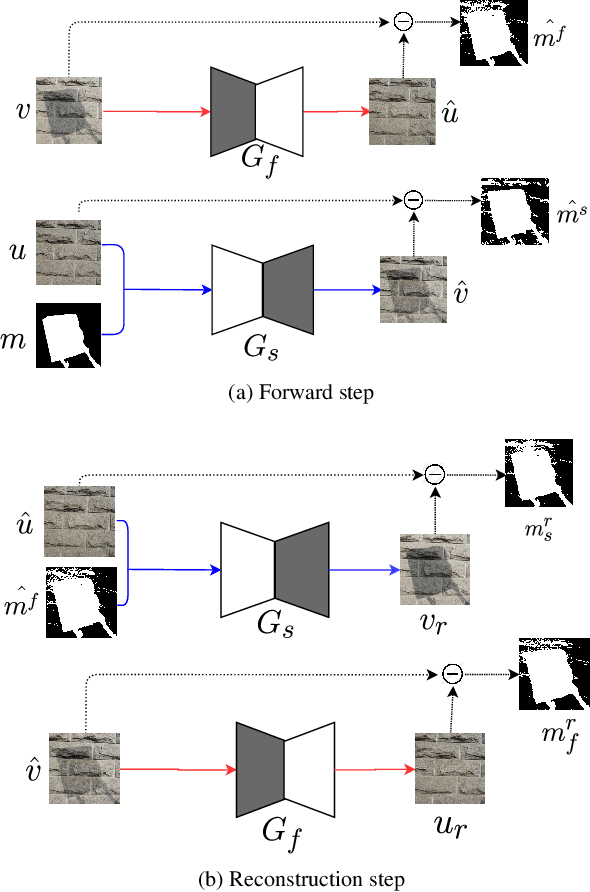



Shadow removal is an important computer vision task aiming at the detection and successful removal of the shadow produced by an occluded light source and a photo-realistic restoration of the image contents. Decades of re-search produced a multitude of hand-crafted restoration techniques and, more recently, learned solutions from shad-owed and shadow-free training image pairs. In this work,we propose an unsupervised single image shadow removal solution via self-supervised learning by using a conditioned mask. In contrast to existing literature, we do not require paired shadowed and shadow-free images, instead we rely on self-supervision and jointly learn deep models to remove and add shadows to images. We validate our approach on the recently introduced ISTD and USR datasets. We largely improve quantitatively and qualitatively over the compared methods and set a new state-of-the-art performance in single image shadow removal.
Joint Reconstruction and Calibration using Regularization by Denoising
Nov 26, 2020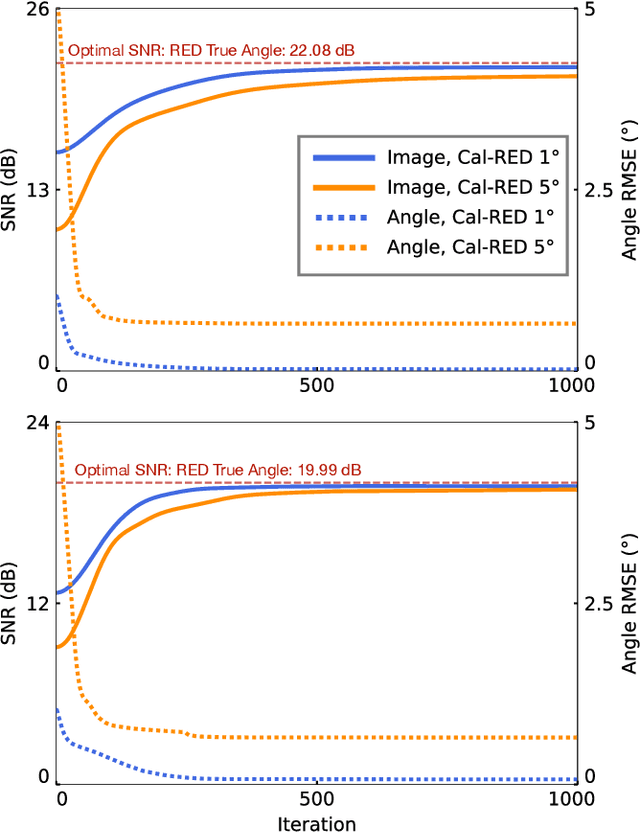

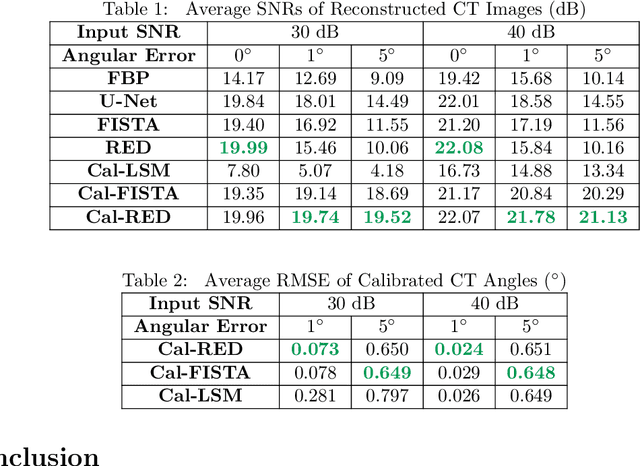
Regularization by denoising (RED) is a broadly applicable framework for solving inverse problems by using priors specified as denoisers. While RED has been shown to provide state-of-the-art performance in a number of applications, existing RED algorithms require exact knowledge of the measurement operator characterizing the imaging system, limiting their applicability in problems where the measurement operator has parametric uncertainties. We propose a new method, called Calibrated RED (Cal-RED), that enables joint calibration of the measurement operator along with reconstruction of the unknown image. Cal-RED extends the traditional RED methodology to imaging problems that require the calibration of the measurement operator. We validate Cal-RED on the problem of image reconstruction in computerized tomography (CT) under perturbed projection angles. Our results corroborate the effectiveness of Cal-RED for joint calibration and reconstruction using pre-trained deep denoisers as image priors.
Automatic Visual Inspection of Rare Defects: A Framework based on GP-WGAN and Enhanced Faster R-CNN
May 02, 2021
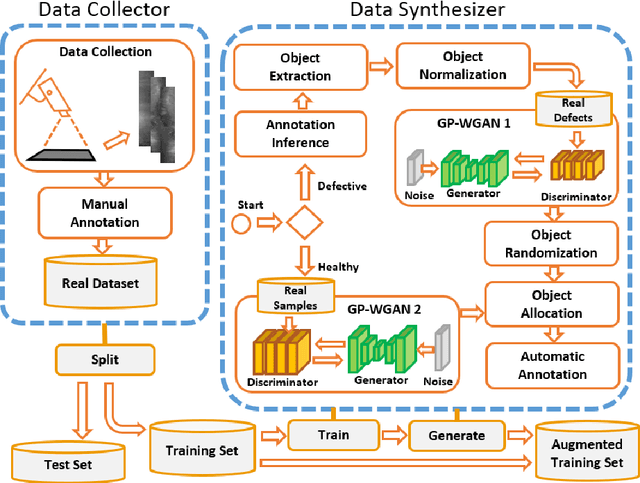
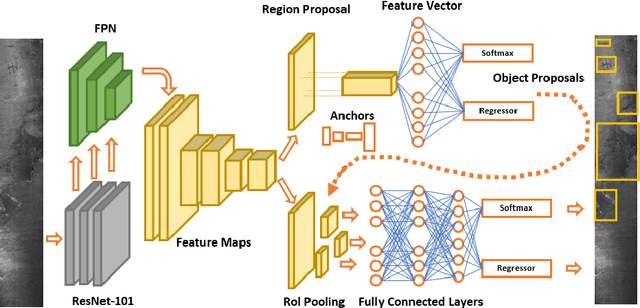
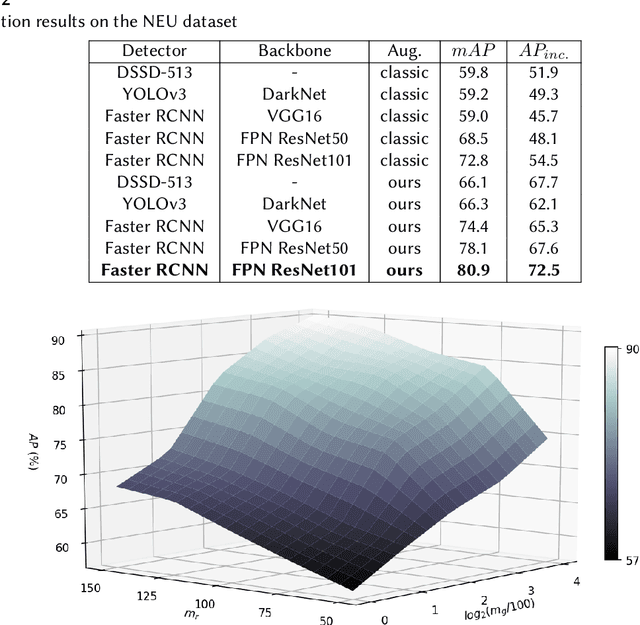
A current trend in industries such as semiconductors and foundry is to shift their visual inspection processes to Automatic Visual Inspection (AVI) systems, to reduce their costs, mistakes, and dependency on human experts. This paper proposes a two-staged fault diagnosis framework for AVI systems. In the first stage, a generation model is designed to synthesize new samples based on real samples. The proposed augmentation algorithm extracts objects from the real samples and blends them randomly, to generate new samples and enhance the performance of the image processor. In the second stage, an improved deep learning architecture based on Faster R-CNN, Feature Pyramid Network (FPN), and a Residual Network is proposed to perform object detection on the enhanced dataset. The performance of the algorithm is validated and evaluated on two multi-class datasets. The experimental results performed over a range of imbalance severities demonstrate the superiority of the proposed framework compared to other solutions.
DeFMO: Deblurring and Shape Recovery of Fast Moving Objects
Dec 01, 2020
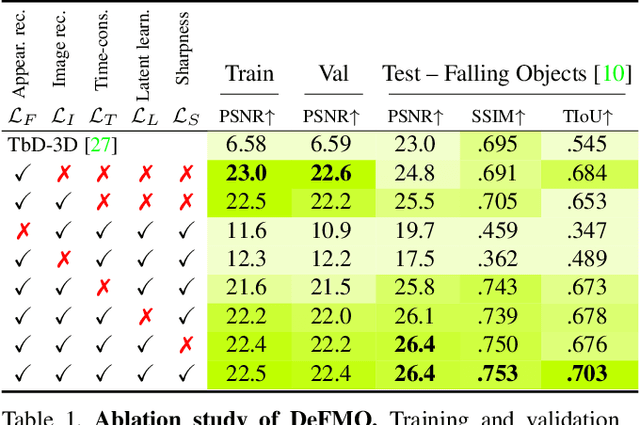
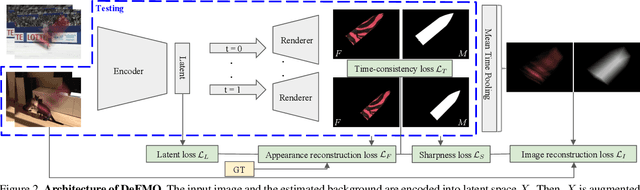
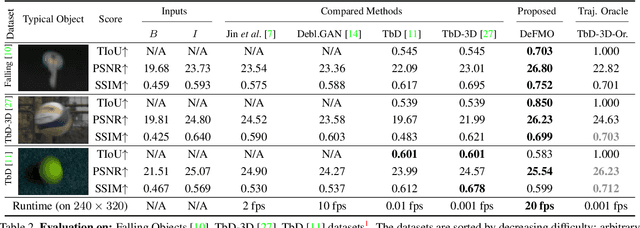
Objects moving at high speed appear significantly blurred when captured with cameras. The blurry appearance is especially ambiguous when the object has complex shape or texture. In such cases, classical methods, or even humans, are unable to recover the object's appearance and motion. We propose a method that, given a single image with its estimated background, outputs the object's appearance and position in a series of sub-frames as if captured by a high-speed camera (i.e. temporal super-resolution). The proposed generative model embeds an image of the blurred object into a latent space representation, disentangles the background, and renders the sharp appearance. Inspired by the image formation model, we design novel self-supervised loss function terms that boost performance and show good generalization capabilities. The proposed DeFMO method is trained on a complex synthetic dataset, yet it performs well on real-world data from several datasets. DeFMO outperforms the state of the art and generates high-quality temporal super-resolution frames.
Towards Fully Automated Manga Translation
Dec 29, 2020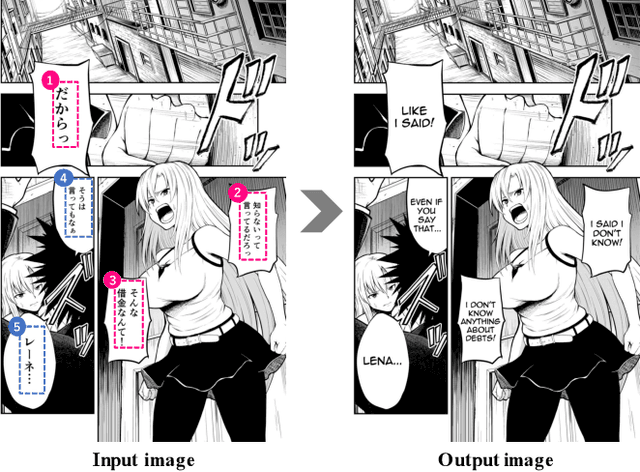
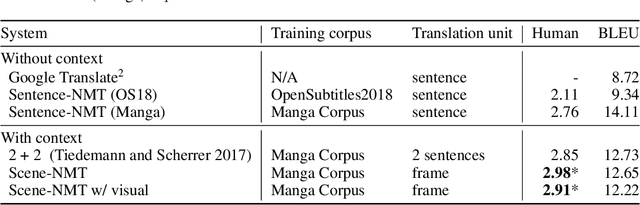
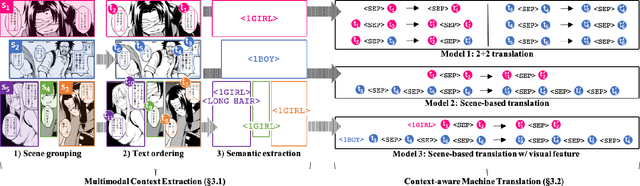
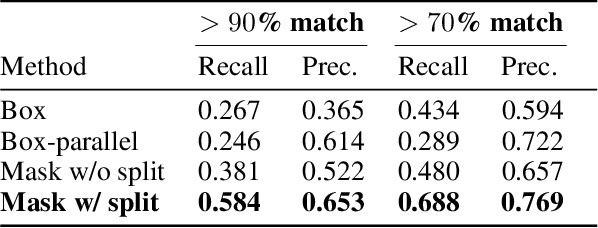
We tackle the problem of machine translation of manga, Japanese comics. Manga translation involves two important problems in machine translation: context-aware and multimodal translation. Since text and images are mixed up in an unstructured fashion in Manga, obtaining context from the image is essential for manga translation. However, it is still an open problem how to extract context from image and integrate into MT models. In addition, corpus and benchmarks to train and evaluate such model is currently unavailable. In this paper, we make the following four contributions that establishes the foundation of manga translation research. First, we propose multimodal context-aware translation framework. We are the first to incorporate context information obtained from manga image. It enables us to translate texts in speech bubbles that cannot be translated without using context information (e.g., texts in other speech bubbles, gender of speakers, etc.). Second, for training the model, we propose the approach to automatic corpus construction from pairs of original manga and their translations, by which large parallel corpus can be constructed without any manual labeling. Third, we created a new benchmark to evaluate manga translation. Finally, on top of our proposed methods, we devised a first comprehensive system for fully automated manga translation.
Estimating Nonplanar Flow from 2D Motion-blurred Widefield Microscopy Images via Deep Learning
Feb 14, 2021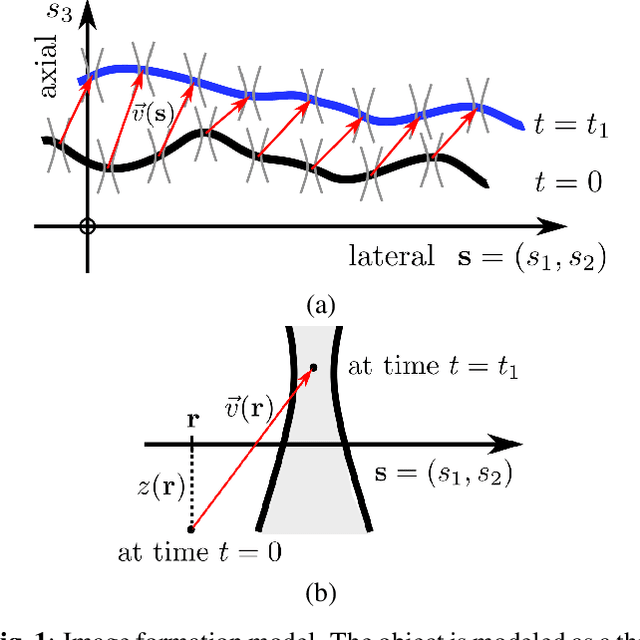


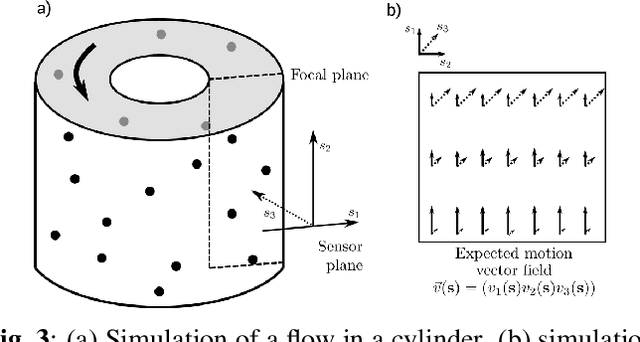
Optical flow is a method aimed at predicting the movement velocity of any pixel in the image and is used in medicine and biology to estimate flow of particles in organs or organelles. However, a precise optical flow measurement requires images taken at high speed and low exposure time, which induces phototoxicity due to the increase in illumination power. We are looking here to estimate the three-dimensional movement vector field of moving out-of-plane particles using normal light conditions and a standard microscope camera. We present a method to predict, from a single textured wide-field microscopy image, the movement of out-of-plane particles using the local characteristics of the motion blur. We estimated the velocity vector field from the local estimation of the blur model parameters using an deep neural network and achieved a prediction with a regression coefficient of 0.92 between the ground truth simulated vector field and the output of the network. This method could enable microscopists to gain insights about the dynamic properties of samples without the need for high-speed cameras or high-intensity light exposure.
Open Set Domain Adaptation for Image and Action Recognition
Jul 30, 2019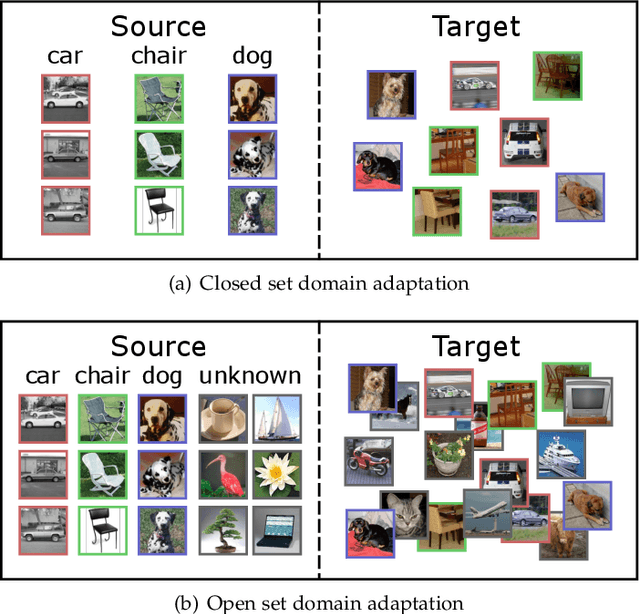
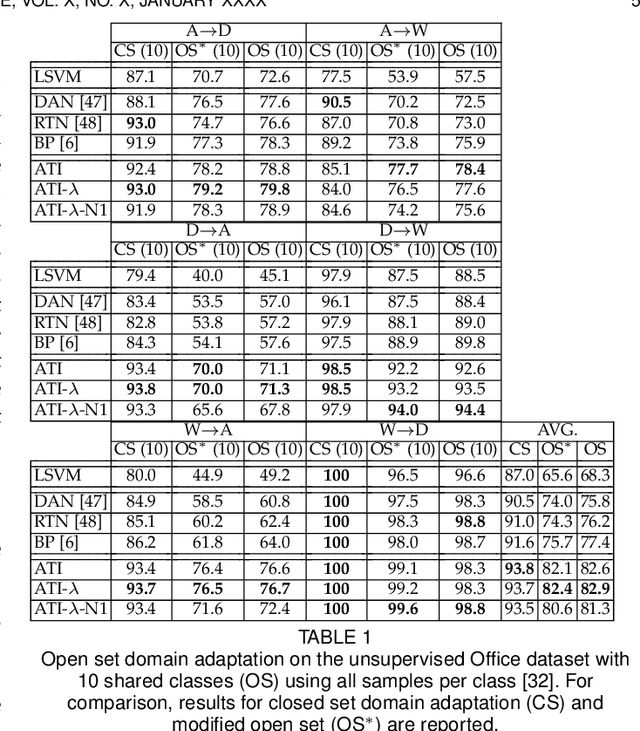
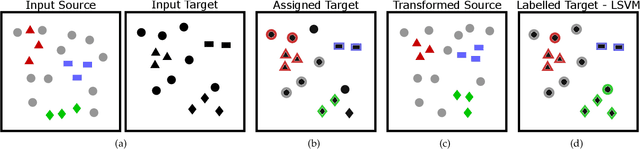

Since annotating and curating large datasets is very expensive, there is a need to transfer the knowledge from existing annotated datasets to unlabelled data. Data that is relevant for a specific application, however, usually differs from publicly available datasets since it is sampled from a different domain. While domain adaptation methods compensate for such a domain shift, they assume that all categories in the target domain are known and match the categories in the source domain. Since this assumption is violated under real-world conditions, we propose an approach for open set domain adaptation where the target domain contains instances of categories that are not present in the source domain. The proposed approach achieves state-of-the-art results on various datasets for image classification and action recognition. Since the approach can be used for open set and closed set domain adaptation, as well as unsupervised and semi-supervised domain adaptation, it is a versatile tool for many applications.