 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Canonical Correlation Analysis for Misaligned Satellite Image Change Detection
Dec 21, 2018
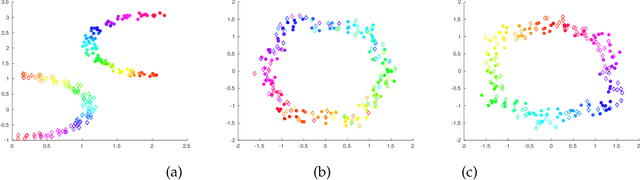

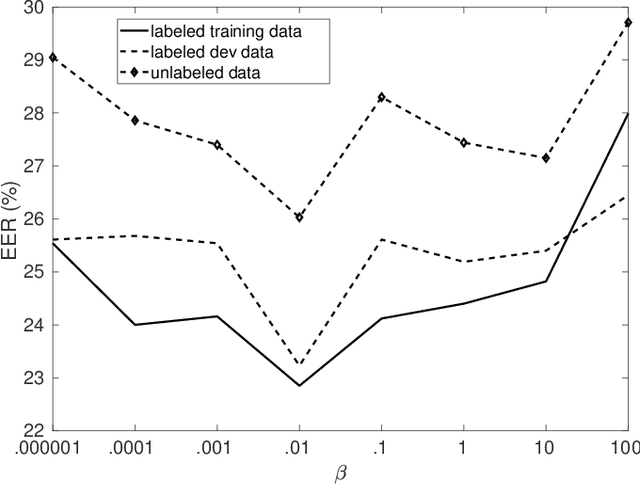
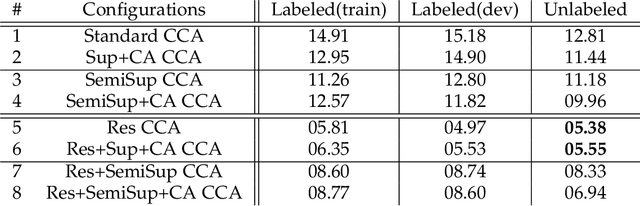
Canonical correlation analysis (CCA) is a statistical learning method that seeks to build view-independent latent representations from multi-view data. This method has been successfully applied to several pattern analysis tasks such as image-to-text mapping and view-invariant object/action recognition. However, this success is highly dependent on the quality of data pairing (i.e., alignments) and mispairing adversely affects the generalization ability of the learned CCA representations. In this paper, we address the issue of alignment errors using a new variant of canonical correlation analysis referred to as alignment-agnostic (AA) CCA. Starting from erroneously paired data taken from different views, this CCA finds transformation matrices by optimizing a constrained maximization problem that mixes a data correlation term with context regularization; the particular design of these two terms mitigates the effect of alignment errors when learning the CCA transformations. Experiments conducted on multi-view tasks, including multi-temporal satellite image change detection, show that our AA CCA method is highly effective and resilient to mispairing errors.
Real-time super-resolution mapping of locally anisotropic grain orientations for ultrasonic non-destructive evaluation of crystalline material
May 10, 2021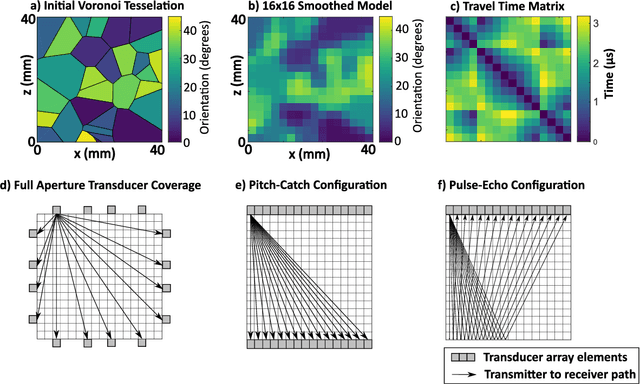
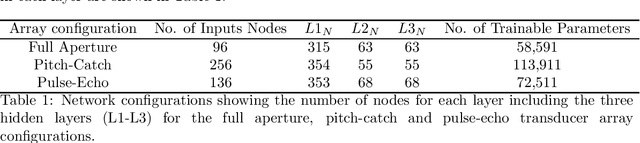
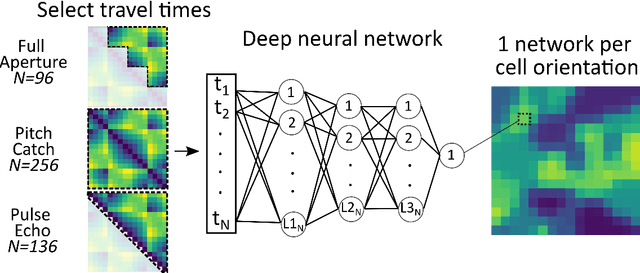
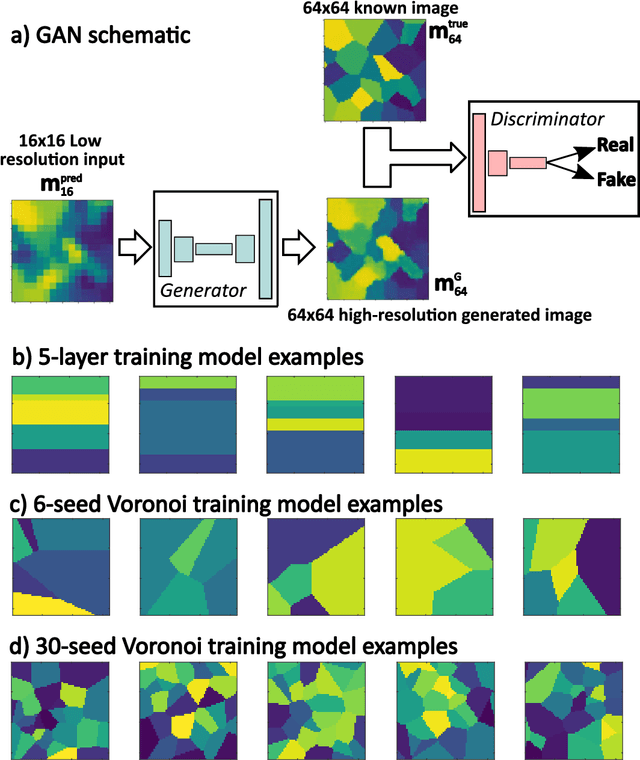
Estimating the spatially varying microstructures of heterogeneous and locally anisotropic media non-destructively is necessary for the accurate detection of flaws and reliable monitoring of manufacturing processes. Conventional algorithms used for solving this inverse problem come with significant computational cost, particularly in the case of high dimensional non-linear tomographic problems. In this paper, we propose a framework which uses deep neural networks (DNNs) with full aperture, pitch-catch and pulse-echo transducer configurations to reconstruct material maps of crystallographic orientation. We also present the first ever application of generative adversarial networks (GANs) to achieve super resolution of ultrasonic tomographic images, providing a factor-four increase in image resolution and up to a 50% increase in structural similarity. The importance of including appropriate prior knowledge in the GAN training dataset to increase inversion accuracy is highlighted; known information about the material's structure should be present in the training data. We show that after a computationally expensive training process, the DNNs and GANs can be used in less that one second (0.9 seconds on a standard desktop computer) to provide a high resolution map of the material's grain orientations.
Enhancing Deep Neural Network Saliency Visualizations with Gradual Extrapolation
Apr 11, 2021



We propose an enhancement technique of the Class Activation Mapping methods like Grad-CAM or Excitation Backpropagation, which presents visual explanations of decisions from CNN-based models. Our idea, called Gradual Extrapolation, can supplement any method that generates a heatmap picture by sharpening the output. Instead of producing a coarse localization map highlighting the important predictive regions in the image, our method outputs the specific shape that most contributes to the model output. Thus, it improves the accuracy of saliency maps. Effect has been achieved by gradual propagation of the crude map obtained in deep layer through all preceding layers with respect to their activations. In validation tests conducted on a selected set of images, the proposed method significantly improved the localization detection of the neural networks' attention. Furthermore, the proposed method is applicable to any deep neural network model.
Lite-FPN for Keypoint-based Monocular 3D Object Detection
May 01, 2021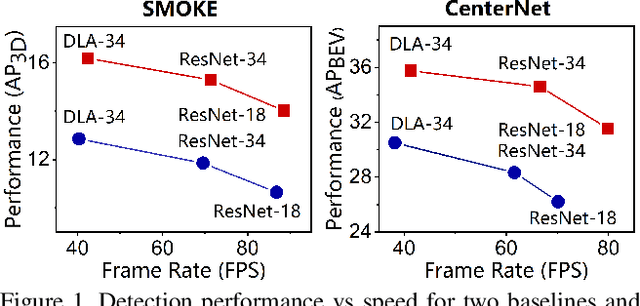
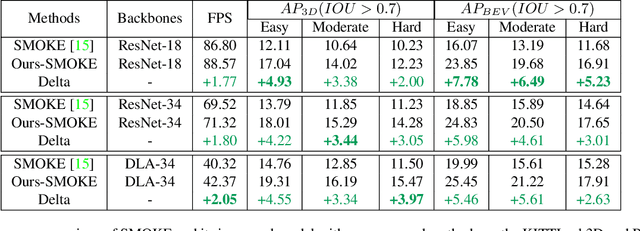
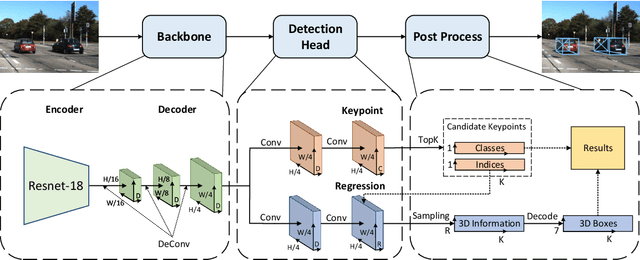
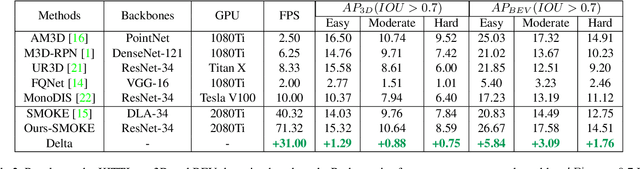
3D object detection with a single image is an essential and challenging task for autonomous driving. Recently, keypoint-based monocular 3D object detection has made tremendous progress and achieved great speed-accuracy trade-off. However, there still exists a huge gap with LIDAR-based methods in terms of accuracy. To improve their performance without sacrificing efficiency, we propose a sort of lightweight feature pyramid network called Lite-FPN to achieve multi-scale feature fusion in an effective and efficient way, which can boost the multi-scale detection capability of keypoint-based detectors. Besides, the misalignment between the classification score and the localization precision is further relieved by introducing a novel regression loss named attention loss. With the proposed loss, predictions with high confidence but poor localization are treated with more attention during the training phase. Comparative experiments based on several state-of-the-art keypoint-based detectors on the KITTI dataset show that our proposed method achieves significantly higher accuracy and frame rate at the same time. The code and pretrained models will be available at https://github.com/yanglei18/Lite-FPN.
Point-Based Modeling of Human Clothing
Apr 16, 2021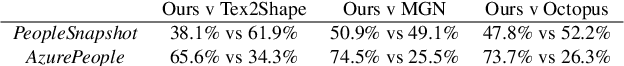
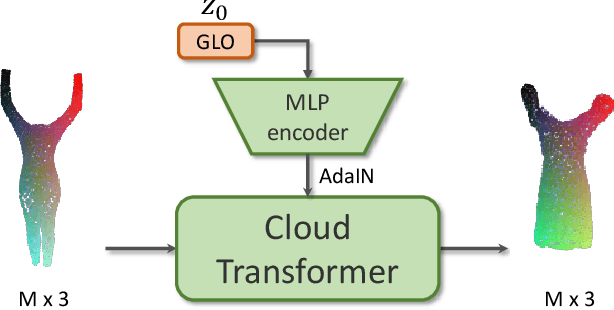
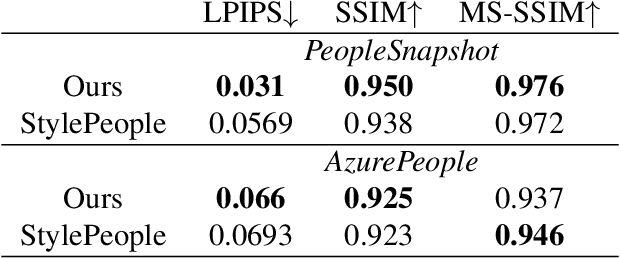
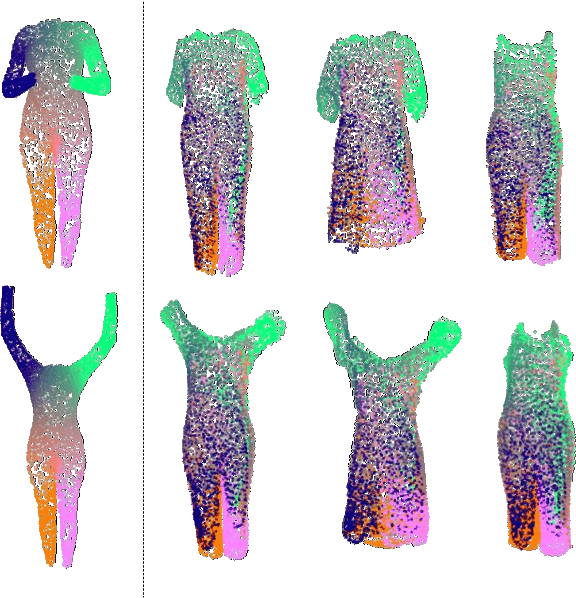
We propose a new approach to human clothing modeling based on point clouds. Within this approach, we learn a deep model that can predict point clouds of various outfits, for various human poses and for various human body shapes. Notably, outfits of various types and topologies can be handled by the same model. Using the learned model, we can infer geometry of new outfits from as little as a singe image, and perform outfit retargeting to new bodies in new poses. We complement our geometric model with appearance modeling that uses the point cloud geometry as a geometric scaffolding, and employs neural point-based graphics to capture outfit appearance from videos and to re-render the captured outfits. We validate both geometric modeling and appearance modeling aspects of the proposed approach against recently proposed methods, and establish the viability of point-based clothing modeling.
Learning Joint 2D-3D Representations for Depth Completion
Dec 22, 2020
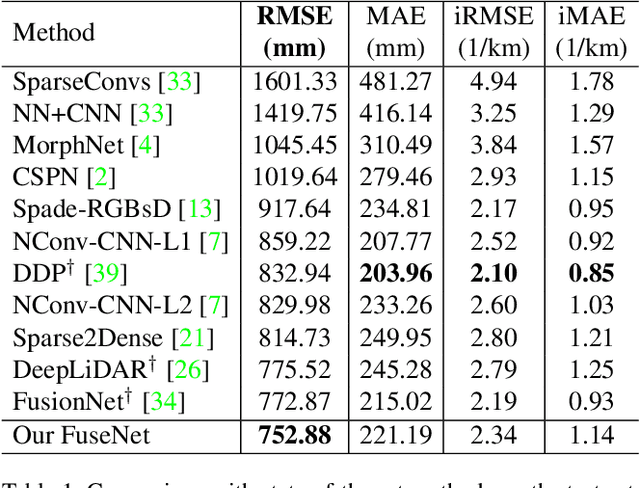
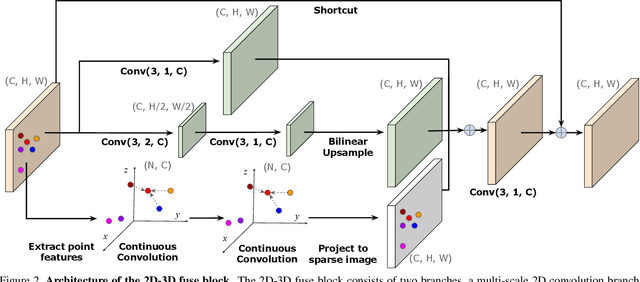

In this paper, we tackle the problem of depth completion from RGBD data. Towards this goal, we design a simple yet effective neural network block that learns to extract joint 2D and 3D features. Specifically, the block consists of two domain-specific sub-networks that apply 2D convolution on image pixels and continuous convolution on 3D points, with their output features fused in image space. We build the depth completion network simply by stacking the proposed block, which has the advantage of learning hierarchical representations that are fully fused between 2D and 3D spaces at multiple levels. We demonstrate the effectiveness of our approach on the challenging KITTI depth completion benchmark and show that our approach outperforms the state-of-the-art.
Bayesian matrix completion with a spectral scaled Student prior: theoretical guarantee and efficient sampling
Apr 16, 2021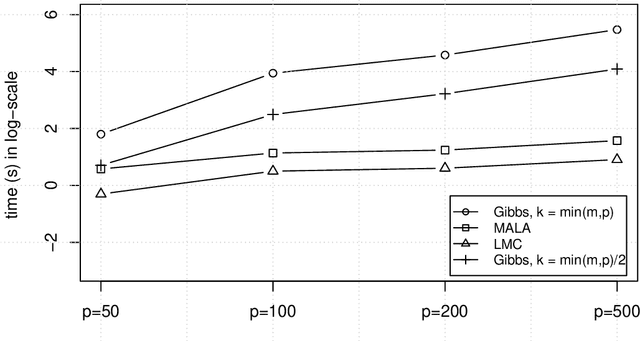
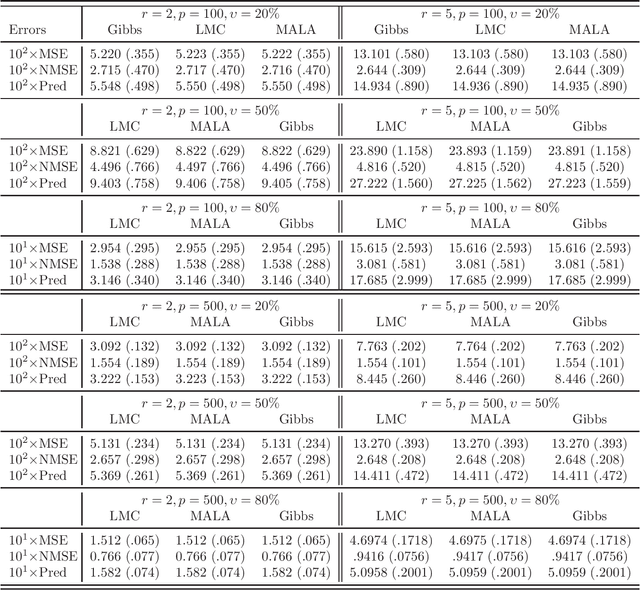
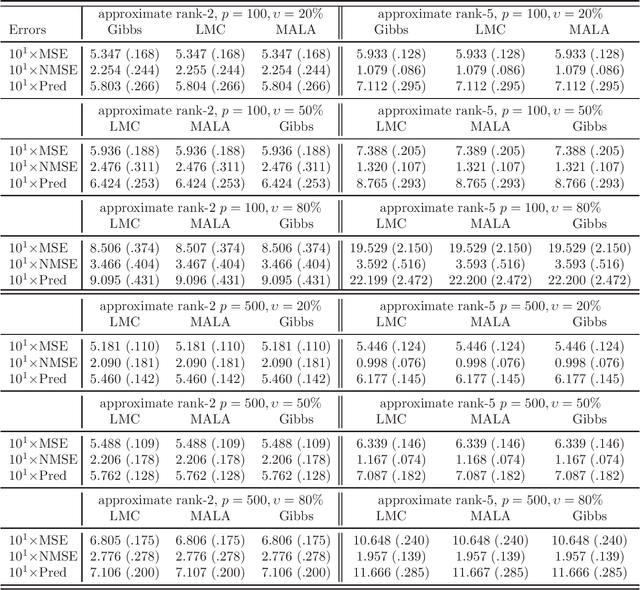

We study the problem of matrix completion in this paper. A spectral scaled Student prior is exploited to favour the underlying low-rank structure of the data matrix. Importantly, we provide a thorough theoretical investigation for our approach, while such an analysis is hard to obtain and limited in theoretical understanding of Bayesian matrix completion. More precisely, we show that our Bayesian approach enjoys a minimax-optimal oracle inequality which guarantees that our method works well under model misspecification and under general sampling distribution. Interestingly, we also provide efficient gradient-based sampling implementations for our approach by using Langevin Monte Carlo which is novel in Bayesian matrix completion. More specifically, we show that our algorithms are significantly faster than Gibbs sampler in this problem. To illustrate the attractive features of our inference strategy, some numerical simulations are conducted and an application to image inpainting is demonstrated.
Image Classification with Deep Learning in the Presence of Noisy Labels: A Survey
Dec 11, 2019
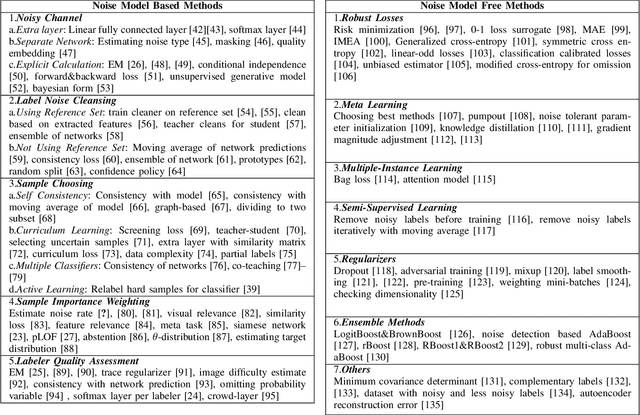
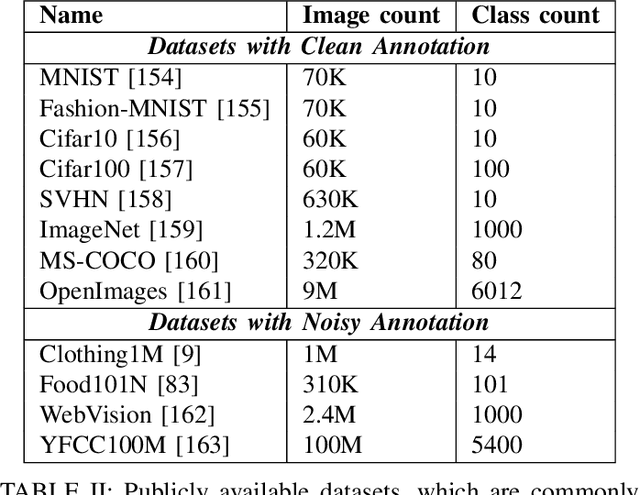
Image classification systems recently made a big leap with the advancement of deep neural networks. However, these systems require excessive amount of labeled data in order to be trained properly. This is not always feasible due to several factors, such as expensiveness of labeling process or difficulty of correctly classifying data even for the experts. Because of these practical challenges, label noise is a common problem in datasets and numerous methods to train deep networks with label noise are proposed in literature. Deep networks are known to be relatively robust to label noise, however their tendency to overfit data makes them vulnerable to memorizing even total random noise. Therefore, it is crucial to consider the existence of label noise and develop counter algorithms to fade away its negative effects for training deep neural networks efficiently. Even though an extensive survey of machine learning techniques under label noise exists, literature lacks a comprehensive survey of methodologies specifically centered around deep learning in the presence of noisy labels. This paper aims to present these algorithms while categorizing them according to their similarity in proposed methodology.
Active image restoration
Sep 22, 2018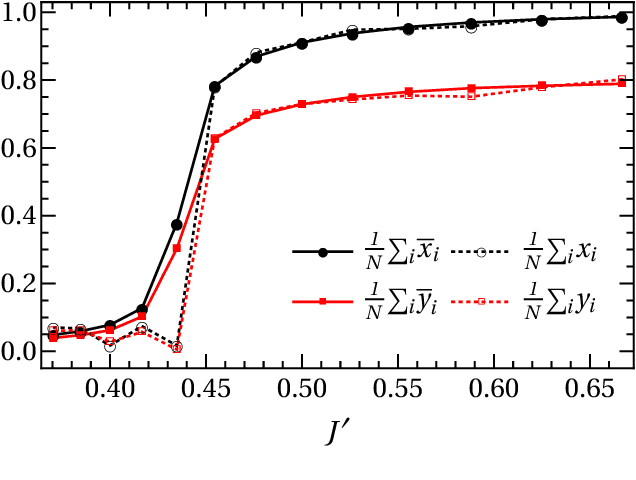


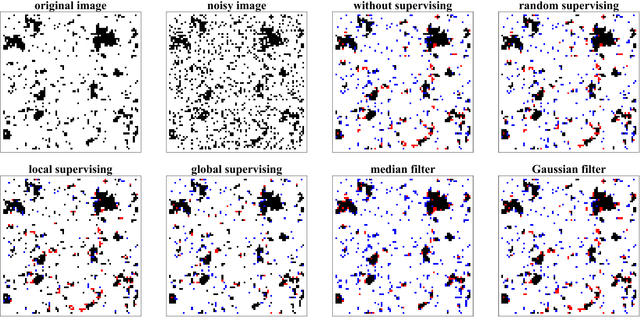
We study active restoration of noise-corrupted images generated via the Gibbs probability of an Ising ferromagnet in external magnetic field. Ferromagnetism accounts for the prior expectation of data smoothness, i.e. a positive correlation between neighbouring pixels (Ising spins), while the magnetic field refers to the bias. The restoration is actively supervised by requesting the true values of certain pixels after a noisy observation. This additional information improves restoration of other pixels. The optimal strategy of active inference is not known for realistic (two-dimensional) images. We determine this strategy for the mean-field version of the model and show that it amounts to supervising the values of spins (pixels) that do not agree with the sign of the average magnetization. The strategy leads to a transparent analytical expression for the minimal Bayesian risk, and shows that there is a maximal number of pixels beyond of which the supervision is useless. We show numerically that this strategy applies for two-dimensional images away from the critical regime. Within this regime the strategy is outperformed by its local (adaptive) version, which supervises pixels that do not agree with their Bayesian estimate. We show on transparent examples how active supervising can be essential in recovering noise-corrupted images and advocate for a wider usage of active methods in image restoration.
An Attention-Fused Network for Semantic Segmentation of Very-High-Resolution Remote Sensing Imagery
May 10, 2021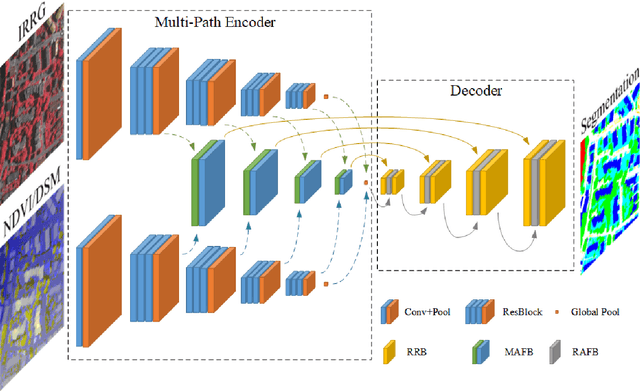
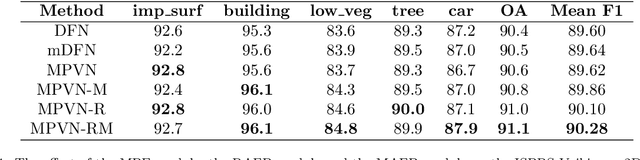
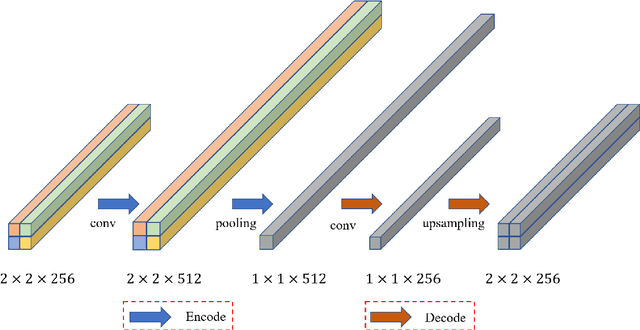
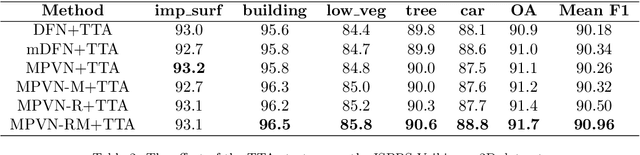
Semantic segmentation is an essential part of deep learning. In recent years, with the development of remote sensing big data, semantic segmentation has been increasingly used in remote sensing. Deep convolutional neural networks (DCNNs) face the challenge of feature fusion: very-high-resolution remote sensing image multisource data fusion can increase the network's learnable information, which is conducive to correctly classifying target objects by DCNNs; simultaneously, the fusion of high-level abstract features and low-level spatial features can improve the classification accuracy at the border between target objects. In this paper, we propose a multipath encoder structure to extract features of multipath inputs, a multipath attention-fused block module to fuse multipath features, and a refinement attention-fused block module to fuse high-level abstract features and low-level spatial features. Furthermore, we propose a novel convolutional neural network architecture, named attention-fused network (AFNet). Based on our AFNet, we achieve state-of-the-art performance with an overall accuracy of 91.7% and a mean F1 score of 90.96% on the ISPRS Vaihingen 2D dataset and an overall accuracy of 92.1% and a mean F1 score of 93.44% on the ISPRS Potsdam 2D dataset.