 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
FSNet: An Identity-Aware Generative Model for Image-based Face Swapping
Nov 30, 2018

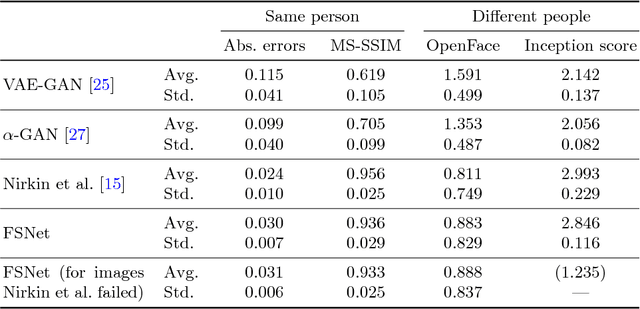
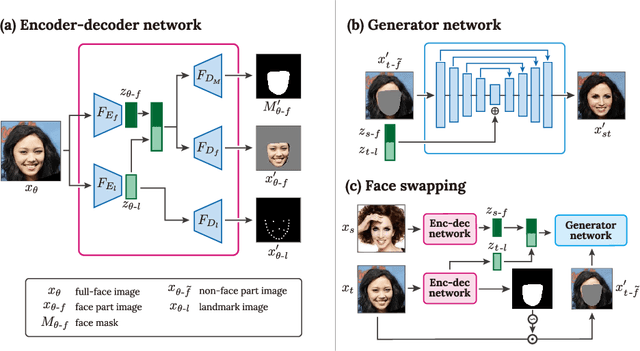

This paper presents FSNet, a deep generative model for image-based face swapping. Traditionally, face-swapping methods are based on three-dimensional morphable models (3DMMs), and facial textures are replaced between the estimated three-dimensional (3D) geometries in two images of different individuals. However, the estimation of 3D geometries along with different lighting conditions using 3DMMs is still a difficult task. We herein represent the face region with a latent variable that is assigned with the proposed deep neural network (DNN) instead of facial textures. The proposed DNN synthesizes a face-swapped image using the latent variable of the face region and another image of the non-face region. The proposed method is not required to fit to the 3DMM; additionally, it performs face swapping only by feeding two face images to the proposed network. Consequently, our DNN-based face swapping performs better than previous approaches for challenging inputs with different face orientations and lighting conditions. Through several experiments, we demonstrated that the proposed method performs face swapping in a more stable manner than the state-of-the-art method, and that its results are compatible with the method thereof.
An Effective Anti-Aliasing Approach for Residual Networks
Nov 20, 2020

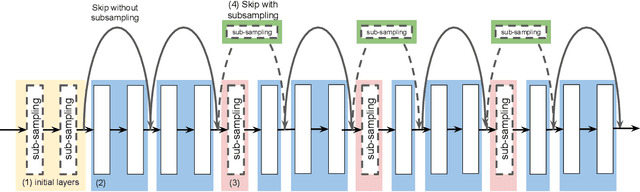

Image pre-processing in the frequency domain has traditionally played a vital role in computer vision and was even part of the standard pipeline in the early days of deep learning. However, with the advent of large datasets, many practitioners concluded that this was unnecessary due to the belief that these priors can be learned from the data itself. Frequency aliasing is a phenomenon that may occur when sub-sampling any signal, such as an image or feature map, causing distortion in the sub-sampled output. We show that we can mitigate this effect by placing non-trainable blur filters and using smooth activation functions at key locations, particularly where networks lack the capacity to learn them. These simple architectural changes lead to substantial improvements in out-of-distribution generalization on both image classification under natural corruptions on ImageNet-C [10] and few-shot learning on Meta-Dataset [17], without introducing additional trainable parameters and using the default hyper-parameters of open source codebases.
Procedural 3D Terrain Generation using Generative Adversarial Networks
Oct 13, 2020
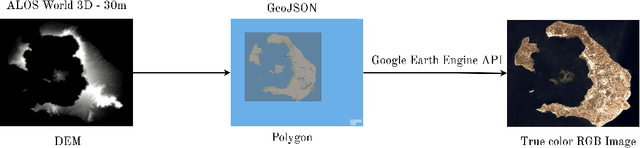

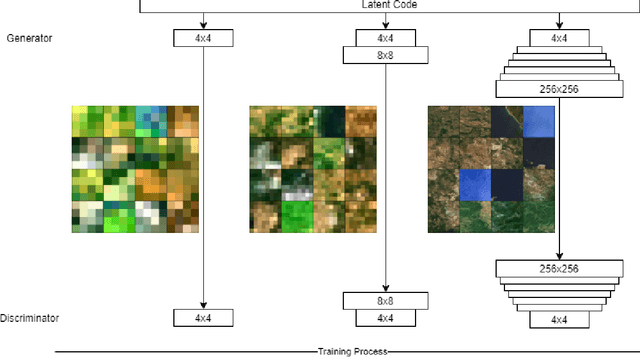
Procedural 3D Terrain generation has become a necessity in open world games, as it can provide unlimited content, through a functionally infinite number of different areas, for players to explore. In our approach, we use Generative Adversarial Networks (GAN) to yield realistic 3D environments based on the distribution of remotely sensed images of landscapes, captured by satellites or drones. Our task consists of synthesizing a random but plausible RGB satellite image and generating a corresponding Height Map in the form of a 3D point cloud that will serve as an appropriate mesh of the landscape. For the first step, we utilize a GAN trained with satellite images that manages to learn the distribution of the dataset, creating novel satellite images. For the second part, we need a one-to-one mapping from RGB images to Digital Elevation Models (DEM). We deploy a Conditional Generative Adversarial network (CGAN), which is the state-of-the-art approach to image-to-image translation, to generate a plausible height map for every randomly generated image of the first model. Combining the generated DEM and RGB image, we are able to construct 3D scenery consisting of a plausible height distribution and colorization, in relation to the remotely sensed landscapes provided during training.
Slide-free MUSE Microscopy to H&E Histology Modality Conversion via Unpaired Image-to-Image Translation GAN Models
Aug 19, 2020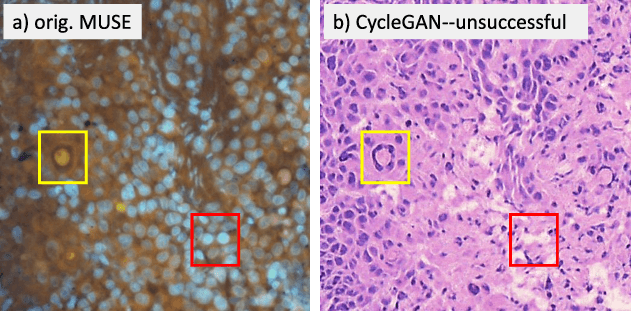
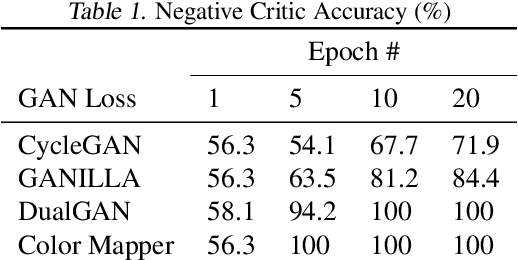
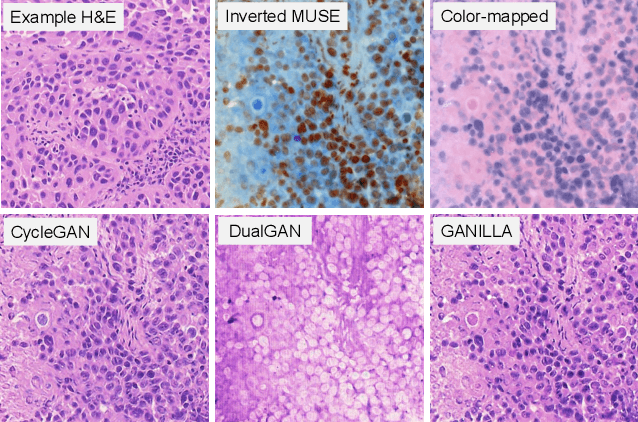
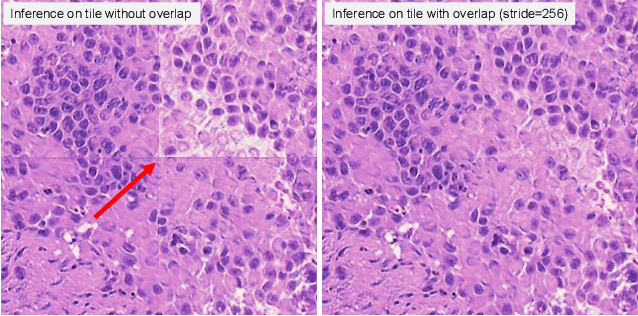
MUSE is a novel slide-free imaging technique for histological examination of tissues that can serve as an alternative to traditional histology. In order to bridge the gap between MUSE and traditional histology, we aim to convert MUSE images to resemble authentic hematoxylin- and eosin-stained (H&E) images. We evaluated four models: a non-machine-learning-based color-mapping unmixing-based tool, CycleGAN, DualGAN, and GANILLA. CycleGAN and GANILLA provided visually compelling results that appropriately transferred H&E style and preserved MUSE content. Based on training an automated critic on real and generated H&E images, we determined that CycleGAN demonstrated the best performance. We have also found that MUSE color inversion may be a necessary step for accurate modality conversion to H&E. We believe that our MUSE-to-H&E model can help improve adoption of novel slide-free methods by bridging a perceptual gap between MUSE imaging and traditional histology.
Image Classification with Deep Learning in the Presence of Noisy Labels: A Survey
Dec 11, 2019
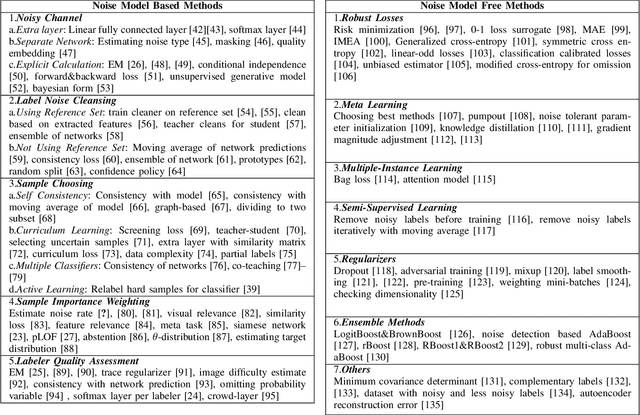
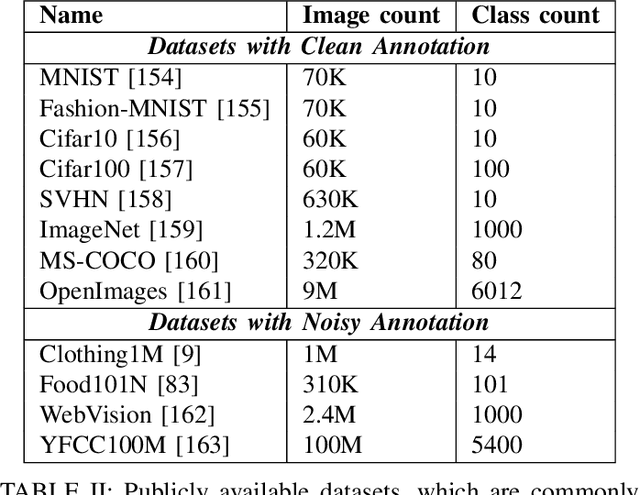
Image classification systems recently made a big leap with the advancement of deep neural networks. However, these systems require excessive amount of labeled data in order to be trained properly. This is not always feasible due to several factors, such as expensiveness of labeling process or difficulty of correctly classifying data even for the experts. Because of these practical challenges, label noise is a common problem in datasets and numerous methods to train deep networks with label noise are proposed in literature. Deep networks are known to be relatively robust to label noise, however their tendency to overfit data makes them vulnerable to memorizing even total random noise. Therefore, it is crucial to consider the existence of label noise and develop counter algorithms to fade away its negative effects for training deep neural networks efficiently. Even though an extensive survey of machine learning techniques under label noise exists, literature lacks a comprehensive survey of methodologies specifically centered around deep learning in the presence of noisy labels. This paper aims to present these algorithms while categorizing them according to their similarity in proposed methodology.
Rank-One Prior: Toward Real-Time Scene Recovery
Apr 07, 2021

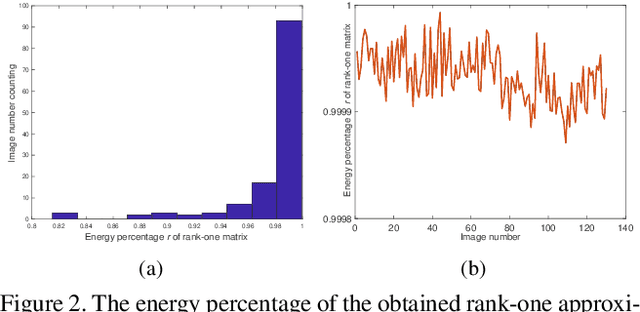
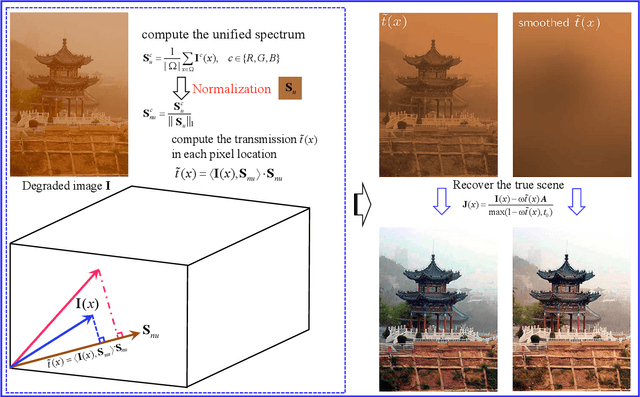
Scene recovery is a fundamental imaging task for several practical applications, e.g., video surveillance and autonomous vehicles, etc. To improve visual quality under different weather/imaging conditions, we propose a real-time light correction method to recover the degraded scenes in the cases of sandstorms, underwater, and haze. The heart of our work is that we propose an intensity projection strategy to estimate the transmission. This strategy is motivated by a straightforward rank-one transmission prior. The complexity of transmission estimation is $O(N)$ where $N$ is the size of the single image. Then we can recover the scene in real-time. Comprehensive experiments on different types of weather/imaging conditions illustrate that our method outperforms competitively several state-of-the-art imaging methods in terms of efficiency and robustness.
Sandwich Batch Normalization
Feb 22, 2021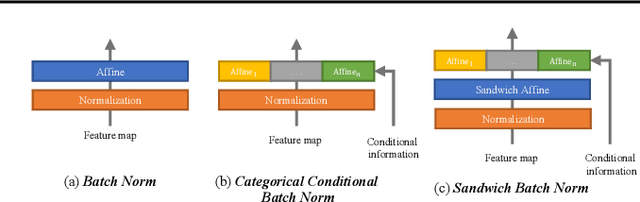

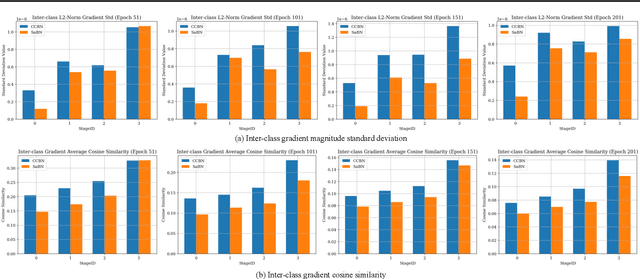

We present Sandwich Batch Normalization (SaBN), an embarrassingly easy improvement of Batch Normalization (BN) with only a few lines of code changes. SaBN is motivated by addressing the inherent feature distribution heterogeneity that one can be identified in many tasks, which can arise from data heterogeneity (multiple input domains) or model heterogeneity (dynamic architectures, model conditioning, etc.). Our SaBN factorizes the BN affine layer into one shared sandwich affine layer, cascaded by several parallel independent affine layers. Concrete analysis reveals that, during optimization, SaBN promotes balanced gradient norms while still preserving diverse gradient directions: a property that many application tasks seem to favor. We demonstrate the prevailing effectiveness of SaBN as a drop-in replacement in four tasks: $\textbf{conditional image generation}$, $\textbf{neural architecture search}$ (NAS), $\textbf{adversarial training}$, and $\textbf{arbitrary style transfer}$. Leveraging SaBN immediately achieves better Inception Score and FID on CIFAR-10 and ImageNet conditional image generation with three state-of-the-art GANs; boosts the performance of a state-of-the-art weight-sharing NAS algorithm significantly on NAS-Bench-201; substantially improves the robust and standard accuracies for adversarial defense; and produces superior arbitrary stylized results. We also provide visualizations and analysis to help understand why SaBN works. Codes are available at https://github.com/VITA-Group/Sandwich-Batch-Normalization.
TextOCR: Towards large-scale end-to-end reasoning for arbitrary-shaped scene text
May 12, 2021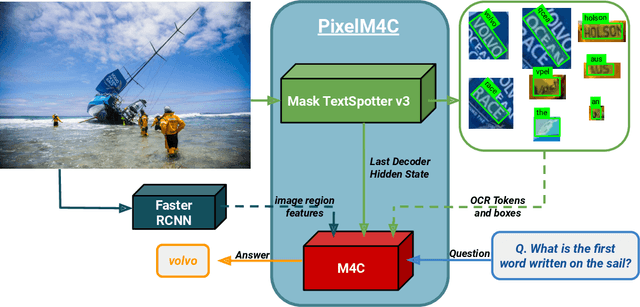
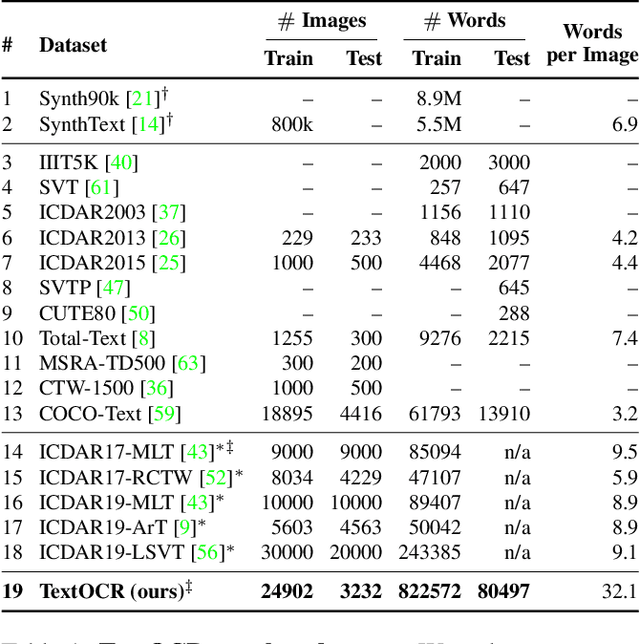

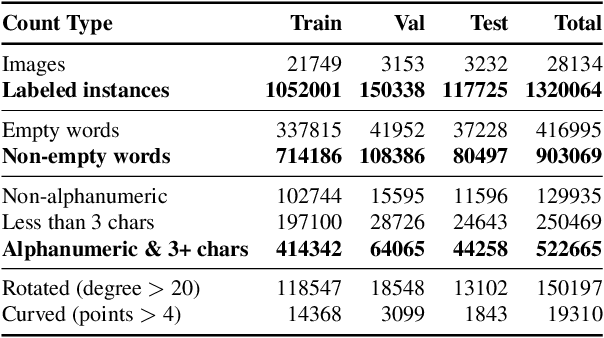
A crucial component for the scene text based reasoning required for TextVQA and TextCaps datasets involve detecting and recognizing text present in the images using an optical character recognition (OCR) system. The current systems are crippled by the unavailability of ground truth text annotations for these datasets as well as lack of scene text detection and recognition datasets on real images disallowing the progress in the field of OCR and evaluation of scene text based reasoning in isolation from OCR systems. In this work, we propose TextOCR, an arbitrary-shaped scene text detection and recognition with 900k annotated words collected on real images from TextVQA dataset. We show that current state-of-the-art text-recognition (OCR) models fail to perform well on TextOCR and that training on TextOCR helps achieve state-of-the-art performance on multiple other OCR datasets as well. We use a TextOCR trained OCR model to create PixelM4C model which can do scene text based reasoning on an image in an end-to-end fashion, allowing us to revisit several design choices to achieve new state-of-the-art performance on TextVQA dataset.
Glioblastoma Multiforme Patient Survival Prediction
Jan 26, 2021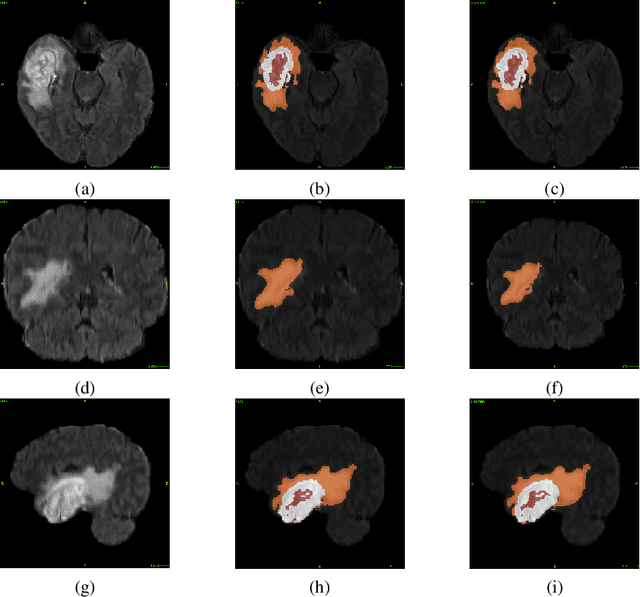
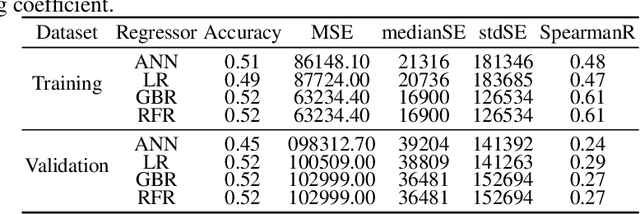

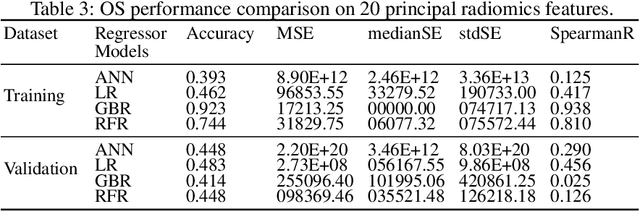
Glioblastoma Multiforme is a very aggressive type of brain tumor. Due to spatial and temporal intra-tissue inhomogeneity, location and the extent of the cancer tissue, it is difficult to detect and dissect the tumor regions. In this paper, we propose survival prognosis models using four regressors operating on handcrafted image-based and radiomics features. We hypothesize that the radiomics shape features have the highest correlation with survival prediction. The proposed approaches were assessed on the Brain Tumor Segmentation (BraTS-2020) challenge dataset. The highest accuracy of image features with random forest regressor approach was 51.5\% for the training and 51.7\% for the validation dataset. The gradient boosting regressor with shape features gave an accuracy of 91.5\% and 62.1\% on training and validation datasets respectively. It is better than the BraTS 2020 survival prediction challenge winners on the training and validation datasets. Our work shows that handcrafted features exhibit a strong correlation with survival prediction. The consensus based regressor with gradient boosting and radiomics shape features is the best combination for survival prediction.
* 10 pages, 9 figures
Normalized Avatar Synthesis Using StyleGAN and Perceptual Refinement
Jun 21, 2021


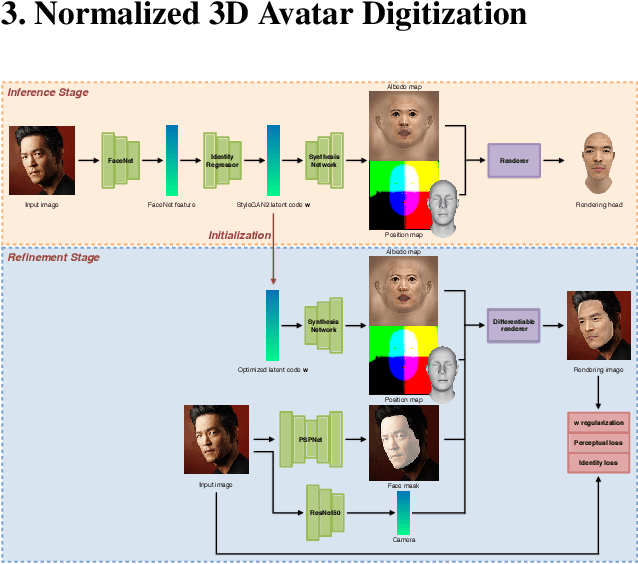
We introduce a highly robust GAN-based framework for digitizing a normalized 3D avatar of a person from a single unconstrained photo. While the input image can be of a smiling person or taken in extreme lighting conditions, our method can reliably produce a high-quality textured model of a person's face in neutral expression and skin textures under diffuse lighting condition. Cutting-edge 3D face reconstruction methods use non-linear morphable face models combined with GAN-based decoders to capture the likeness and details of a person but fail to produce neutral head models with unshaded albedo textures which is critical for creating relightable and animation-friendly avatars for integration in virtual environments. The key challenges for existing methods to work is the lack of training and ground truth data containing normalized 3D faces. We propose a two-stage approach to address this problem. First, we adopt a highly robust normalized 3D face generator by embedding a non-linear morphable face model into a StyleGAN2 network. This allows us to generate detailed but normalized facial assets. This inference is then followed by a perceptual refinement step that uses the generated assets as regularization to cope with the limited available training samples of normalized faces. We further introduce a Normalized Face Dataset, which consists of a combination photogrammetry scans, carefully selected photographs, and generated fake people with neutral expressions in diffuse lighting conditions. While our prepared dataset contains two orders of magnitude less subjects than cutting edge GAN-based 3D facial reconstruction methods, we show that it is possible to produce high-quality normalized face models for very challenging unconstrained input images, and demonstrate superior performance to the current state-of-the-art.