 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Multimodal Fusion with BERT and Attention Mechanism for Fake News Detection
Apr 23, 2021

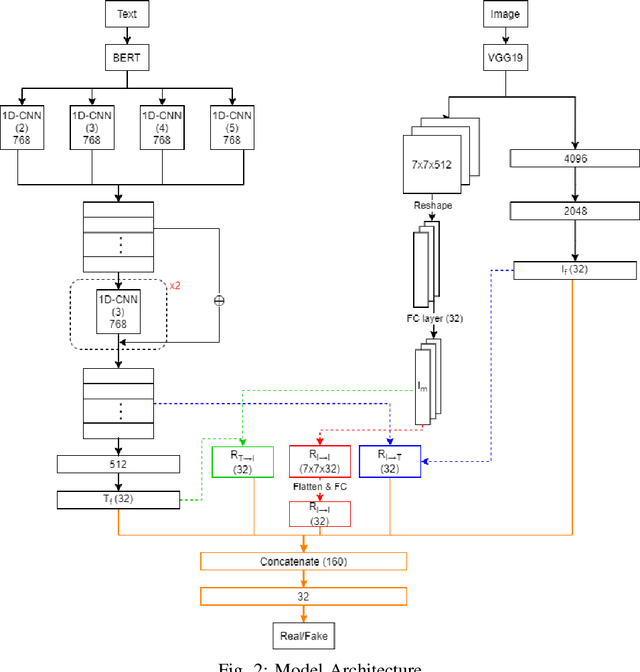
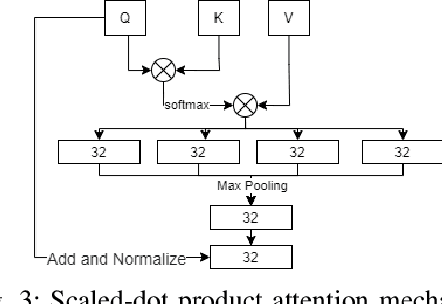

Fake news detection is an important task for increasing the credibility of information on the media since fake news is constantly spreading on social media every day and it is a very serious concern in our society. Fake news is usually created by manipulating images, texts, and videos. In this paper, we present a novel method for detecting fake news by fusing multimodal features derived from textual and visual data. Specifically, we used a pre-trained BERT model to learn text features and a VGG-19 model pre-trained on the ImageNet dataset to extract image features. We proposed a scale-dot product attention mechanism to capture the relationship between text features and visual features. Experimental results showed that our approach performs better than the current state-of-the-art method on a public Twitter dataset by 3.1% accuracy.
Deep Learning-based Prediction of Key Performance Indicators for Electrical Machine
Jan 23, 2021
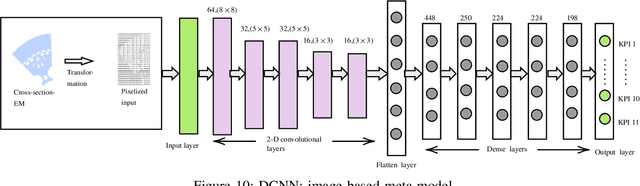
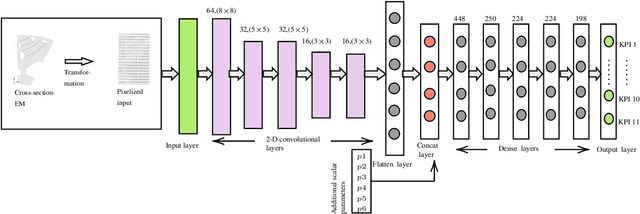
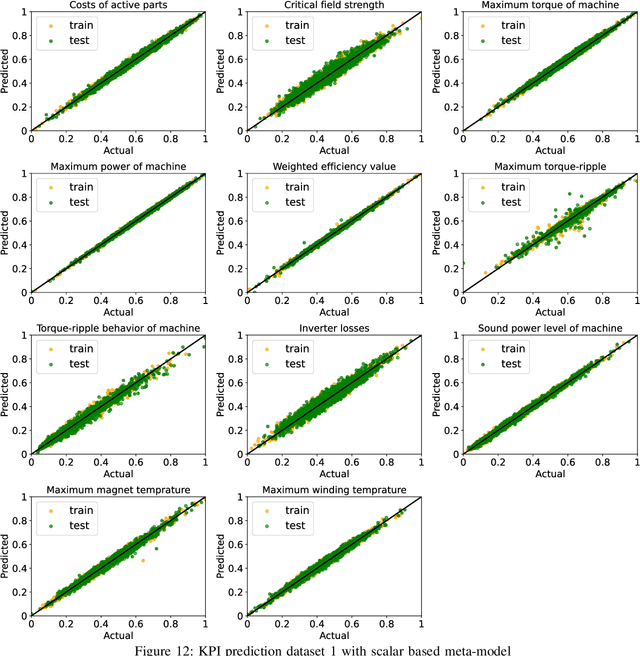
The design of an electrical machine can be quantified and evaluated by Key Performance Indicators (KPIs) such as maximum torque, critical field strength, costs of active parts, sound power, etc. Generally, cross-domain tool-chains are used to optimize all the KPIs from different domains (multi-objective optimization) by varying the given input parameters in the largest possible design space. This optimization process involves magneto-static finite element simulation to obtain these decisive KPIs. It makes the whole process a vehemently time-consuming computational task that counts on the availability of resources with the involvement of high computational cost. In this paper, a data-aided, deep learning-based meta-model is employed to predict the KPIs of an electrical machine quickly and with high accuracy to accelerate the full optimization process and reduce its computational costs. The focus is on analyzing various forms of input data that serve as a geometry representation of the machine. Namely, these are the cross-section image of the electrical machine that allows a very general description of the geometry relating to different topologies and the classical way with scalar parametrization of geometry. The impact of the resolution of the image is studied in detail. The results show a high prediction accuracy and proof that the validity of a deep learning-based meta-model to minimize the optimization time. The results also indicate that the prediction quality of an image-based approach can be made comparable to the classical way based on scalar parameters.
Memory-efficient GAN-based Domain Translation of High Resolution 3D Medical Images
Oct 06, 2020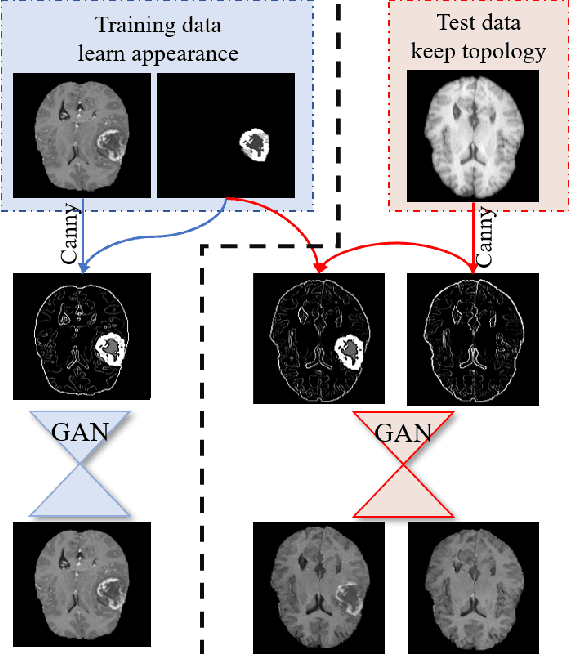

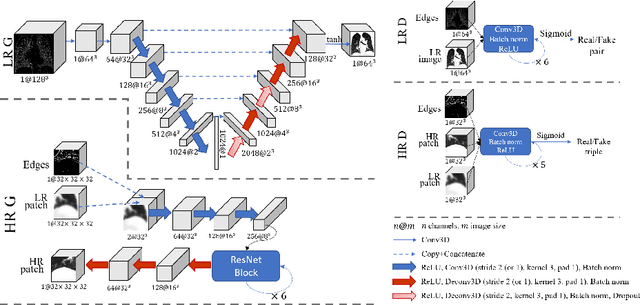
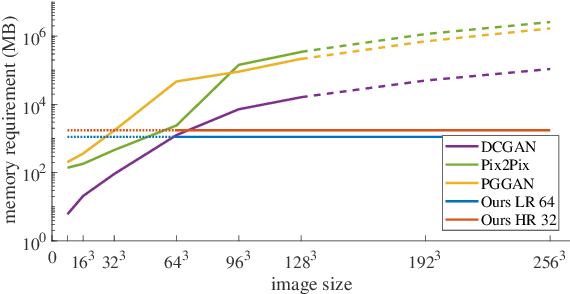
Generative adversarial networks (GANs) are currently rarely applied on 3D medical images of large size, due to their immense computational demand. The present work proposes a multi-scale patch-based GAN approach for establishing unpaired domain translation by generating 3D medical image volumes of high resolution in a memory-efficient way. The key idea to enable memory-efficient image generation is to first generate a low-resolution version of the image followed by the generation of patches of constant sizes but successively growing resolutions. To avoid patch artifacts and incorporate global information, the patch generation is conditioned on patches from previous resolution scales. Those multi-scale GANs are trained to generate realistically looking images from image sketches in order to perform an unpaired domain translation. This allows to preserve the topology of the test data and generate the appearance of the training domain data. The evaluation of the domain translation scenarios is performed on brain MRIs of size 155x240x240 and thorax CTs of size up to 512x512x512. Compared to common patch-based approaches, the multi-resolution scheme enables better image quality and prevents patch artifacts. Also, it ensures constant GPU memory demand independent from the image size, allowing for the generation of arbitrarily large images.
Attributes Aware Face Generation with Generative Adversarial Networks
Dec 03, 2020
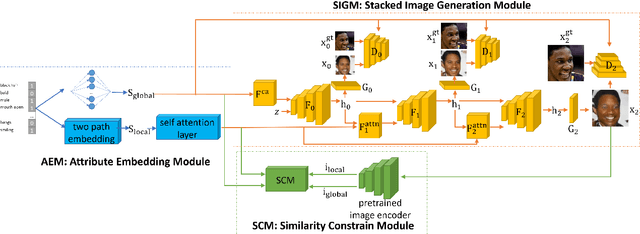
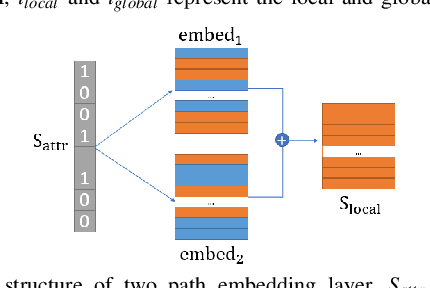

Recent studies have shown remarkable success in face image generations. However, most of the existing methods only generate face images from random noise, and cannot generate face images according to the specific attributes. In this paper, we focus on the problem of face synthesis from attributes, which aims at generating faces with specific characteristics corresponding to the given attributes. To this end, we propose a novel attributes aware face image generator method with generative adversarial networks called AFGAN. Specifically, we firstly propose a two-path embedding layer and self-attention mechanism to convert binary attribute vector to rich attribute features. Then three stacked generators generate $64 \times 64$, $128 \times 128$ and $256 \times 256$ resolution face images respectively by taking the attribute features as input. In addition, an image-attribute matching loss is proposed to enhance the correlation between the generated images and input attributes. Extensive experiments on CelebA demonstrate the superiority of our AFGAN in terms of both qualitative and quantitative evaluations.
Adaptive Test-Time Augmentation for Low-Power CPU
May 13, 2021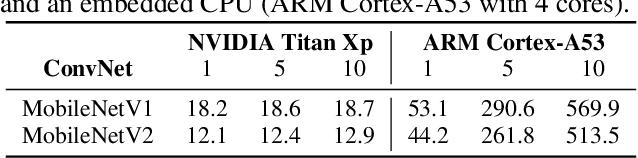
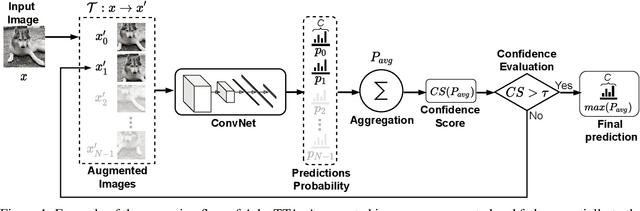
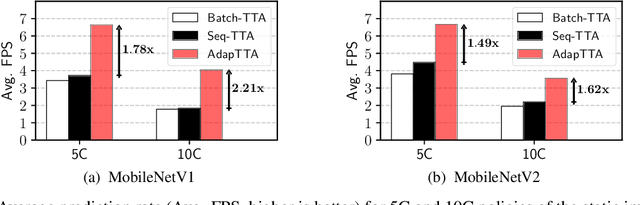
Convolutional Neural Networks (ConvNets) are trained offline using the few available data and may therefore suffer from substantial accuracy loss when ported on the field, where unseen input patterns received under unpredictable external conditions can mislead the model. Test-Time Augmentation (TTA) techniques aim to alleviate such common side effect at inference-time, first running multiple feed-forward passes on a set of altered versions of the same input sample, and then computing the main outcome through a consensus of the aggregated predictions. Unfortunately, the implementation of TTA on embedded CPUs introduces latency penalties that limit its adoption on edge applications. To tackle this issue, we propose AdapTTA, an adaptive implementation of TTA that controls the number of feed-forward passes dynamically, depending on the complexity of the input. Experimental results on state-of-the-art ConvNets for image classification deployed on a commercial ARM Cortex-A CPU demonstrate AdapTTA reaches remarkable latency savings, from 1.49X to 2.21X, and hence a higher frame rate compared to static TTA, still preserving the same accuracy gain.
Adaptive strategy for superpixel-based region-growing image segmentation
Mar 17, 2018This work presents a region-growing image segmentation approach based on superpixel decomposition. From an initial contour-constrained over-segmentation of the input image, the image segmentation is achieved by iteratively merging similar superpixels into regions. This approach raises two key issues: (1) how to compute the similarity between superpixels in order to perform accurate merging and (2) in which order those superpixels must be merged together. In this perspective, we firstly introduce a robust adaptive multi-scale superpixel similarity in which region comparisons are made both at content and common border level. Secondly, we propose a global merging strategy to efficiently guide the region merging process. Such strategy uses an adpative merging criterion to ensure that best region aggregations are given highest priorities. This allows to reach a final segmentation into consistent regions with strong boundary adherence. We perform experiments on the BSDS500 image dataset to highlight to which extent our method compares favorably against other well-known image segmentation algorithms. The obtained results demonstrate the promising potential of the proposed approach.
Image Captioning Based on a Hierarchical Attention Mechanism and Policy Gradient Optimization
Nov 13, 2018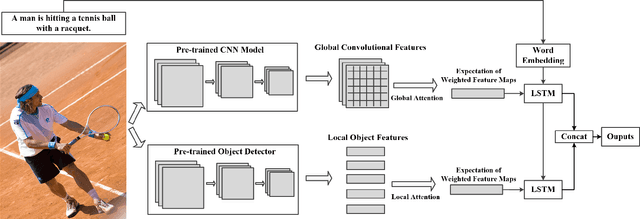
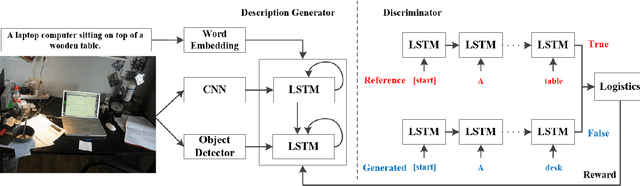
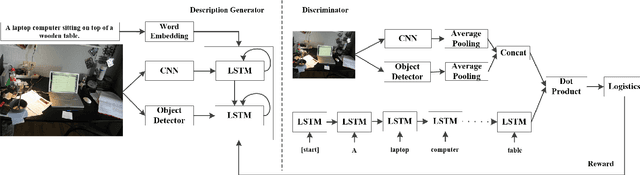
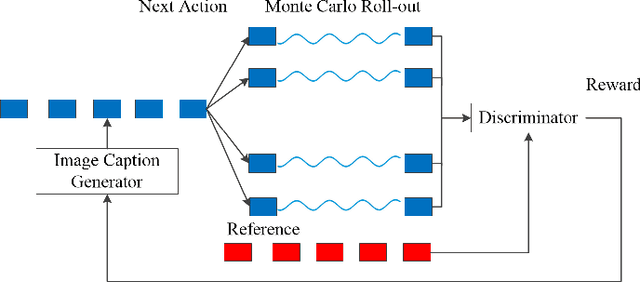
Automatically generating the descriptions of an image, i.e., image captioning, is an important and fundamental topic in artificial intelligence, which bridges the gap between computer vision and natural language processing. Based on the successful deep learning models, especially the CNN model and Long Short-Term Memories (LSTMs) with attention mechanism, we propose a hierarchical attention model by utilizing both of the global CNN features and the local object features for more effective feature representation and reasoning in image captioning. The generative adversarial network (GAN), together with a reinforcement learning (RL) algorithm, is applied to solve the exposure bias problem in RNN-based supervised training for language problems. In addition, through the automatic measurement of the consistency between the generated caption and the image content by the discriminator in the GAN framework and RL optimization, we make the finally generated sentences more accurate and natural. Comprehensive experiments show the improved performance of the hierarchical attention mechanism and the effectiveness of our RL-based optimization method. Our model achieves state-of-the-art results on several important metrics in the MSCOCO dataset, using only greedy inference.
Component SPD Matrices: A lower-dimensional discriminative data descriptor for image set classification
Jun 16, 2018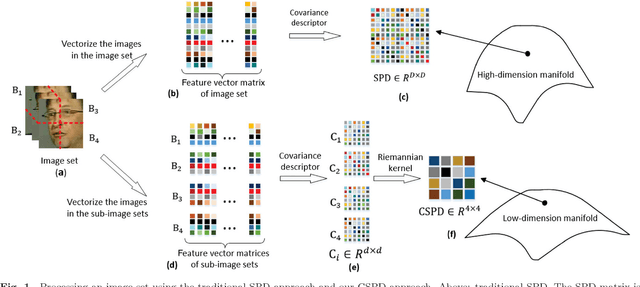
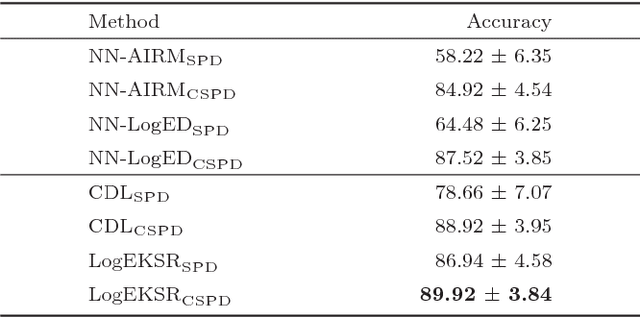
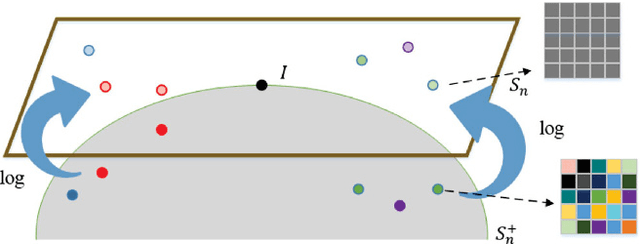
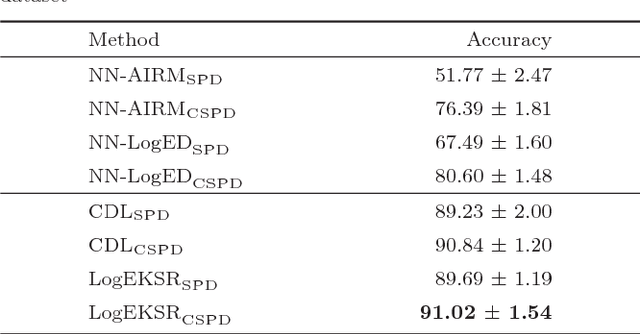
In the domain of pattern recognition, using the SPD (Symmetric Positive Definite) matrices to represent data and taking the metrics of resulting Riemannian manifold into account have been widely used for the task of image set classification. In this paper, we propose a new data representation framework for image sets named CSPD (Component Symmetric Positive Definite). Firstly, we obtain sub-image sets by dividing the image set into square blocks with the same size, and use traditional SPD model to describe them. Then, we use the results of the Riemannian kernel on SPD matrices as similarities of corresponding sub-image sets. Finally, the CSPD matrix appears in the form of the kernel matrix for all the sub-image sets, and CSPDi,j denotes the similarity between i-th sub-image set and j-th sub-image set. Here, the Riemannian kernel is shown to satisfy the Mercer's theorem, so our proposed CSPD matrix is symmetric and positive definite and also lies on a Riemannian manifold. On three benchmark datasets, experimental results show that CSPD is a lower-dimensional and more discriminative data descriptor for the task of image set classification.
SoundDet: Polyphonic Sound Event Detection and Localization from Raw Waveform
Jun 13, 2021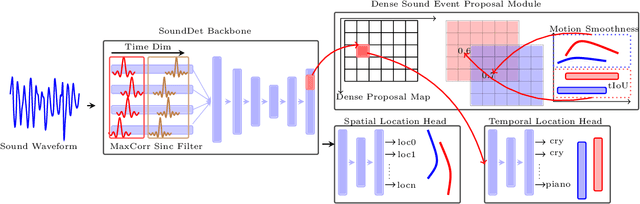
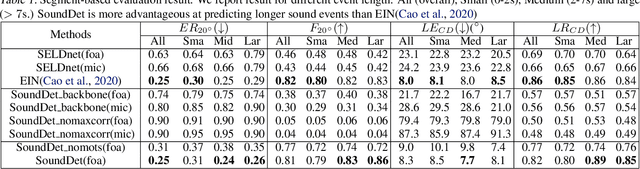
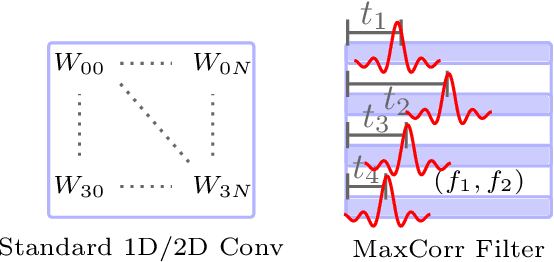
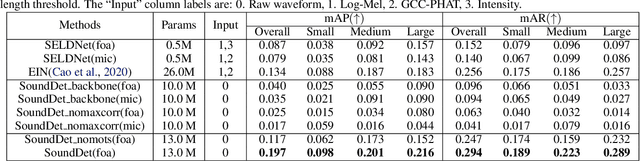
We present a new framework SoundDet, which is an end-to-end trainable and light-weight framework, for polyphonic moving sound event detection and localization. Prior methods typically approach this problem by preprocessing raw waveform into time-frequency representations, which is more amenable to process with well-established image processing pipelines. Prior methods also detect in segment-wise manner, leading to incomplete and partial detections. SoundDet takes a novel approach and directly consumes the raw, multichannel waveform and treats the spatio-temporal sound event as a complete ``sound-object" to be detected. Specifically, SoundDet consists of a backbone neural network and two parallel heads for temporal detection and spatial localization, respectively. Given the large sampling rate of raw waveform, the backbone network first learns a set of phase-sensitive and frequency-selective bank of filters to explicitly retain direction-of-arrival information, whilst being highly computationally and parametrically efficient than standard 1D/2D convolution. A dense sound event proposal map is then constructed to handle the challenges of predicting events with large varying temporal duration. Accompanying the dense proposal map are a temporal overlapness map and a motion smoothness map that measure a proposal's confidence to be an event from temporal detection accuracy and movement consistency perspective. Involving the two maps guarantees SoundDet to be trained in a spatio-temporally unified manner. Experimental results on the public DCASE dataset show the advantage of SoundDet on both segment-based and our newly proposed event-based evaluation system.
Web Table Classification based on Visual Features
Feb 25, 2021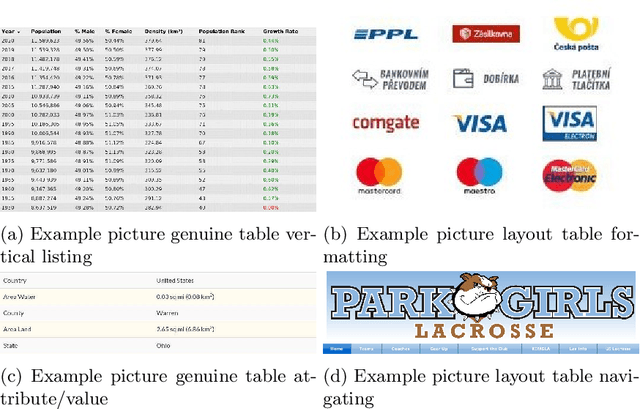
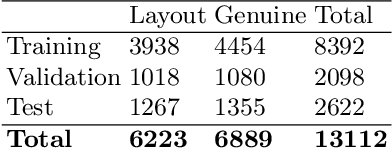
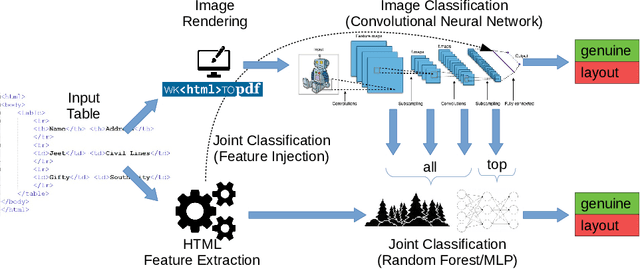
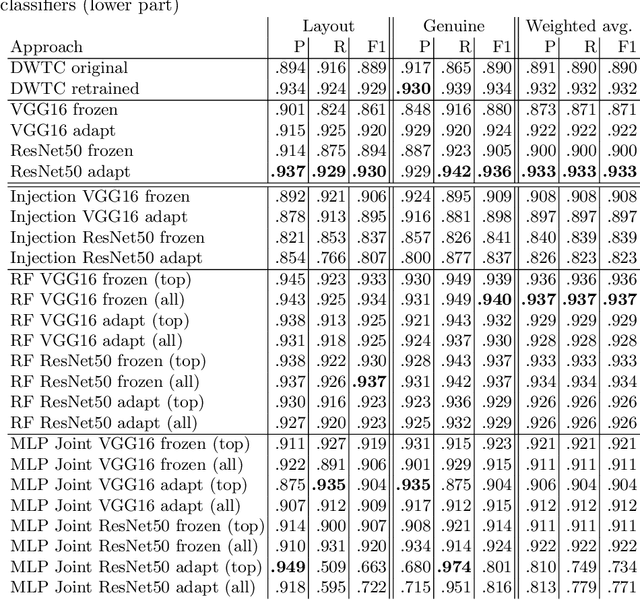
Tables on the web constitute a valuable data source for many applications, like factual search and knowledge base augmentation. However, as genuine tables containing relational knowledge only account for a small proportion of tables on the web, reliable genuine web table classification is a crucial first step of table extraction. Previous works usually rely on explicit feature construction from the HTML code. In contrast, we propose an approach for web table classification by exploiting the full visual appearance of a table, which works purely by applying a convolutional neural network on the rendered image of the web table. Since these visual features can be extracted automatically, our approach circumvents the need for explicit feature construction. A new hand labeled gold standard dataset containing HTML source code and images for 13,112 tables was generated for this task. Transfer learning techniques are applied to well known VGG16 and ResNet50 architectures. The evaluation of CNN image classification with fine tuned ResNet50 (F1 93.29%) shows that this approach achieves results comparable to previous solutions using explicitly defined HTML code based features. By combining visual and explicit features, an F-measure of 93.70% can be achieved by Random Forest classification, which beats current state of the art methods.