 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Slide-free MUSE Microscopy to H&E Histology Modality Conversion via Unpaired Image-to-Image Translation GAN Models
Aug 19, 2020
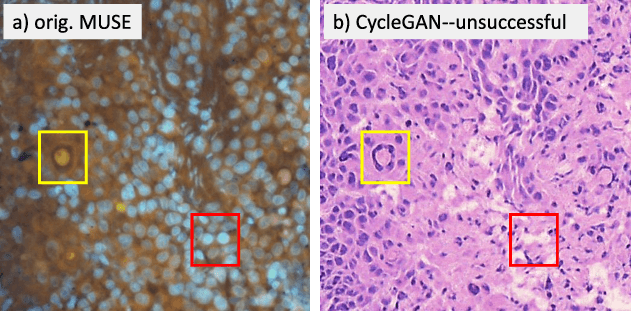
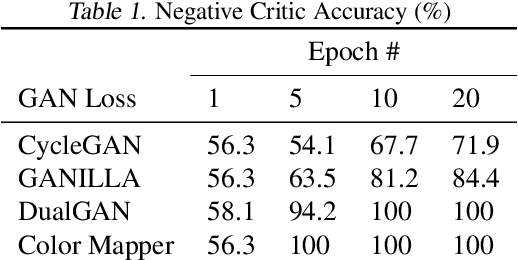
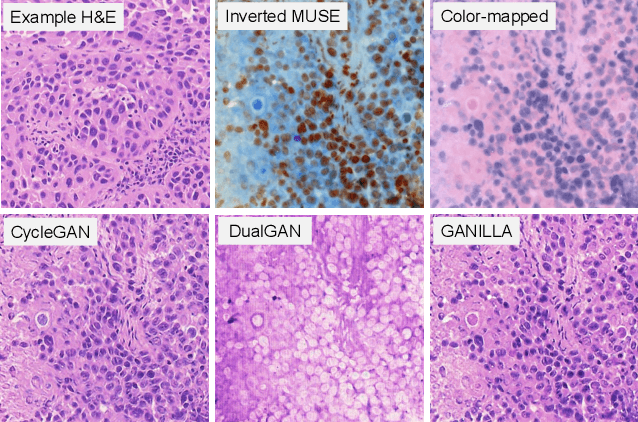
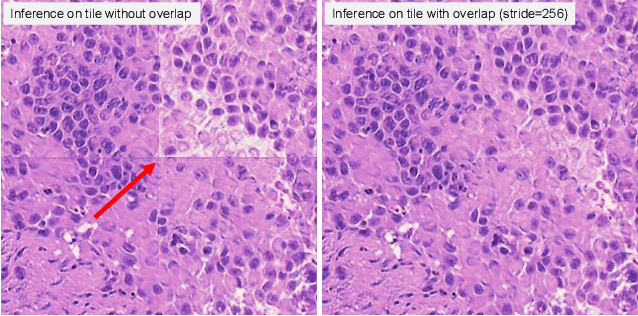
MUSE is a novel slide-free imaging technique for histological examination of tissues that can serve as an alternative to traditional histology. In order to bridge the gap between MUSE and traditional histology, we aim to convert MUSE images to resemble authentic hematoxylin- and eosin-stained (H&E) images. We evaluated four models: a non-machine-learning-based color-mapping unmixing-based tool, CycleGAN, DualGAN, and GANILLA. CycleGAN and GANILLA provided visually compelling results that appropriately transferred H&E style and preserved MUSE content. Based on training an automated critic on real and generated H&E images, we determined that CycleGAN demonstrated the best performance. We have also found that MUSE color inversion may be a necessary step for accurate modality conversion to H&E. We believe that our MUSE-to-H&E model can help improve adoption of novel slide-free methods by bridging a perceptual gap between MUSE imaging and traditional histology.
Progressive Pose Attention Transfer for Person Image Generation
Apr 09, 2019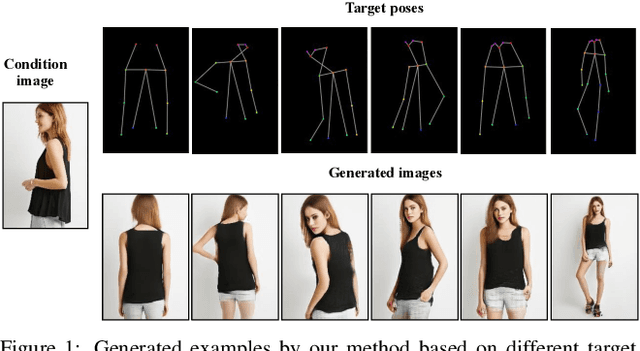
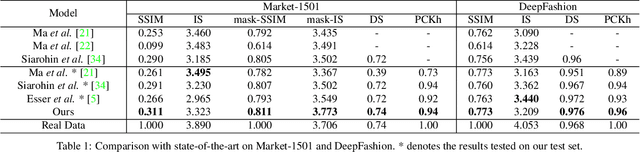
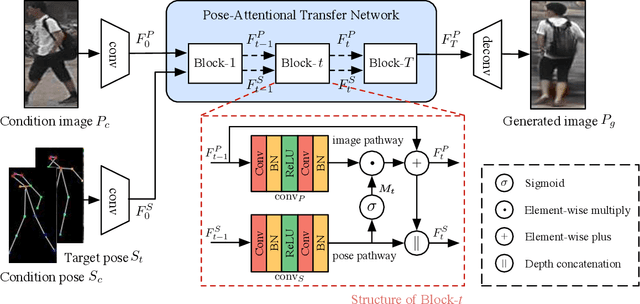
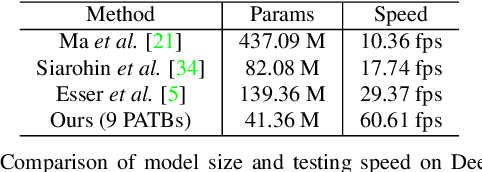
This paper proposes a new generative adversarial network for pose transfer, i.e., transferring the pose of a given person to a target pose. The generator of the network comprises a sequence of Pose-Attentional Transfer Blocks that each transfers certain regions it attends to, generating the person image progressively. Compared with those in previous works, our generated person images possess better appearance consistency and shape consistency with the input images, thus significantly more realistic-looking. The efficacy and efficiency of the proposed network are validated both qualitatively and quantitatively on Market-1501 and DeepFashion. Furthermore, the proposed architecture can generate training images for person re-identification, alleviating data insufficiency. Codes and models are available at: https://github.com/tengteng95/Pose-Transfer.git.
DumbleDR: Predicting User Preferences of Dimensionality Reduction Projection Quality
May 19, 2021
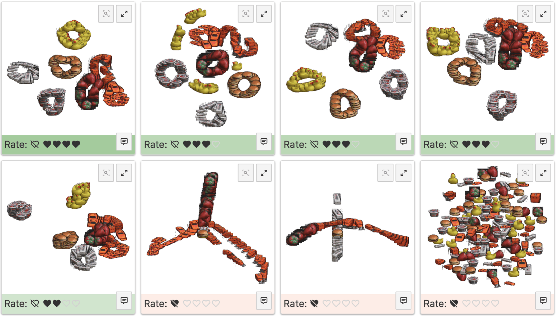
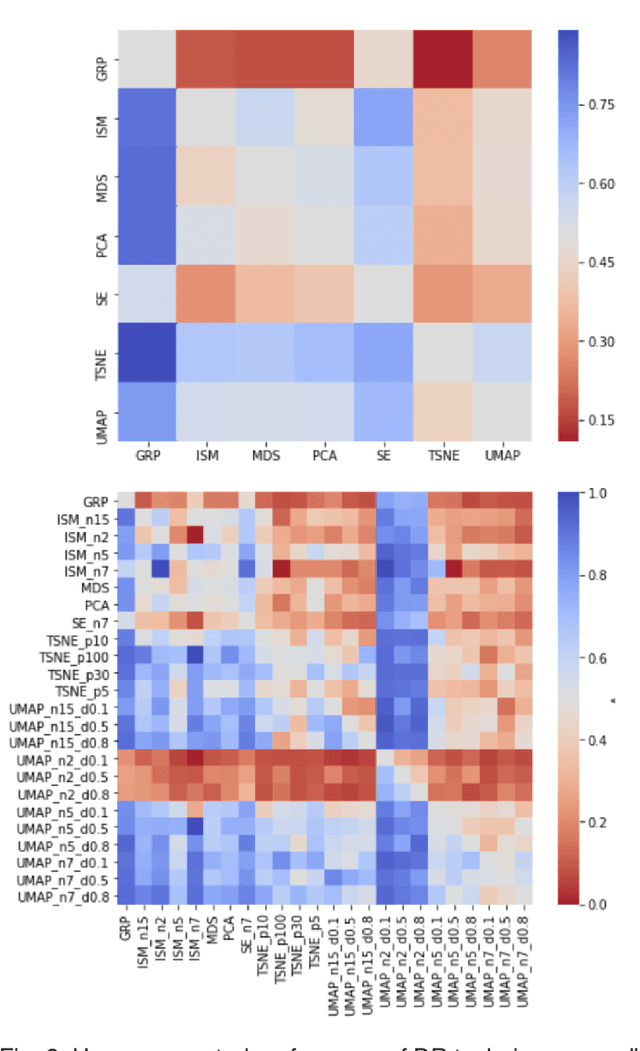
A plethora of dimensionality reduction techniques have emerged over the past decades, leaving researchers and analysts with a wide variety of choices for reducing their data, all the more so given some techniques come with additional parametrization (e.g. t-SNE, UMAP, etc.). Recent studies are showing that people often use dimensionality reduction as a black-box regardless of the specific properties the method itself preserves. Hence, evaluating and comparing 2D projections is usually qualitatively decided, by setting projections side-by-side and letting human judgment decide which projection is the best. In this work, we propose a quantitative way of evaluating projections, that nonetheless places human perception at the center. We run a comparative study, where we ask people to select 'good' and 'misleading' views between scatterplots of low-level projections of image datasets, simulating the way people usually select projections. We use the study data as labels for a set of quality metrics whose purpose is to discover and quantify what exactly people are looking for when deciding between projections. With this proxy for human judgments, we use it to rank projections on new datasets, explain why they are relevant, and quantify the degree of subjectivity in projections selected.
Adversarial Robustness Across Representation Spaces
Dec 01, 2020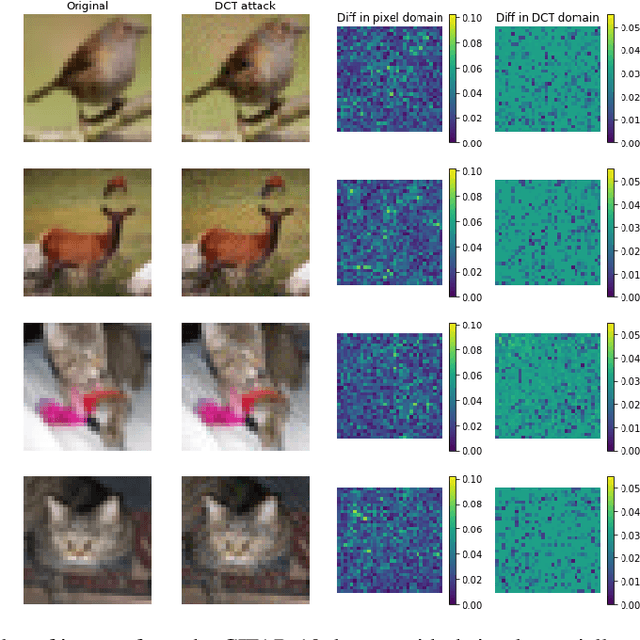
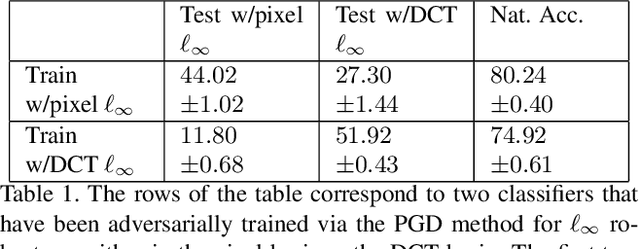

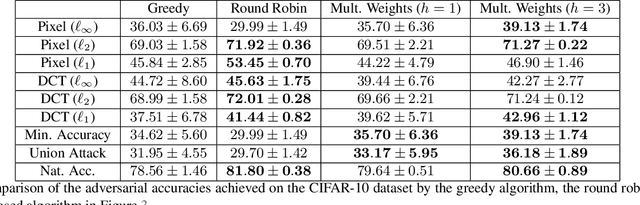
Adversarial robustness corresponds to the susceptibility of deep neural networks to imperceptible perturbations made at test time. In the context of image tasks, many algorithms have been proposed to make neural networks robust to adversarial perturbations made to the input pixels. These perturbations are typically measured in an $\ell_p$ norm. However, robustness often holds only for the specific attack used for training. In this work we extend the above setting to consider the problem of training of deep neural networks that can be made simultaneously robust to perturbations applied in multiple natural representation spaces. For the case of image data, examples include the standard pixel representation as well as the representation in the discrete cosine transform~(DCT) basis. We design a theoretically sound algorithm with formal guarantees for the above problem. Furthermore, our guarantees also hold when the goal is to require robustness with respect to multiple $\ell_p$ norm based attacks. We then derive an efficient practical implementation and demonstrate the effectiveness of our approach on standard datasets for image classification.
Controlling Length in Image Captioning
May 29, 2020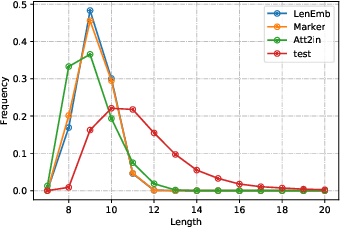

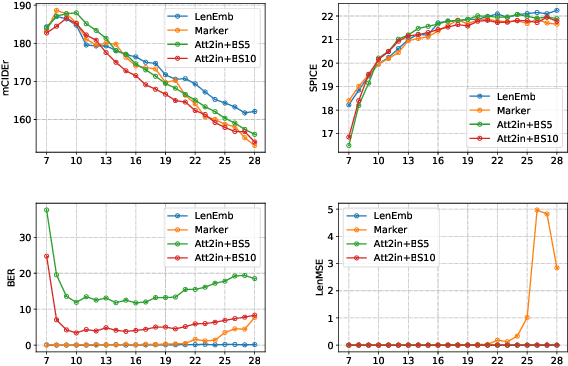

We develop and evaluate captioning models that allow control of caption length. Our models can leverage this control to generate captions of different style and descriptiveness.
Sandwich Batch Normalization
Feb 22, 2021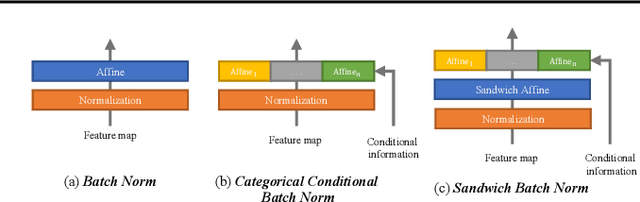

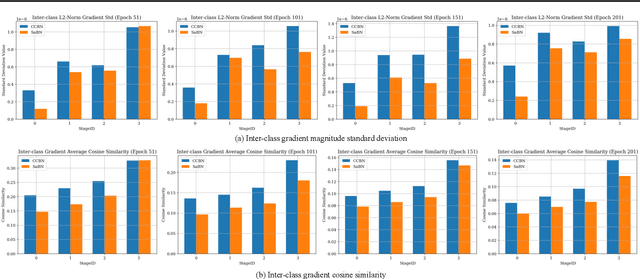

We present Sandwich Batch Normalization (SaBN), an embarrassingly easy improvement of Batch Normalization (BN) with only a few lines of code changes. SaBN is motivated by addressing the inherent feature distribution heterogeneity that one can be identified in many tasks, which can arise from data heterogeneity (multiple input domains) or model heterogeneity (dynamic architectures, model conditioning, etc.). Our SaBN factorizes the BN affine layer into one shared sandwich affine layer, cascaded by several parallel independent affine layers. Concrete analysis reveals that, during optimization, SaBN promotes balanced gradient norms while still preserving diverse gradient directions: a property that many application tasks seem to favor. We demonstrate the prevailing effectiveness of SaBN as a drop-in replacement in four tasks: $\textbf{conditional image generation}$, $\textbf{neural architecture search}$ (NAS), $\textbf{adversarial training}$, and $\textbf{arbitrary style transfer}$. Leveraging SaBN immediately achieves better Inception Score and FID on CIFAR-10 and ImageNet conditional image generation with three state-of-the-art GANs; boosts the performance of a state-of-the-art weight-sharing NAS algorithm significantly on NAS-Bench-201; substantially improves the robust and standard accuracies for adversarial defense; and produces superior arbitrary stylized results. We also provide visualizations and analysis to help understand why SaBN works. Codes are available at https://github.com/VITA-Group/Sandwich-Batch-Normalization.
Rank-smoothed Pairwise Learning In Perceptual Quality Assessment
Nov 21, 2020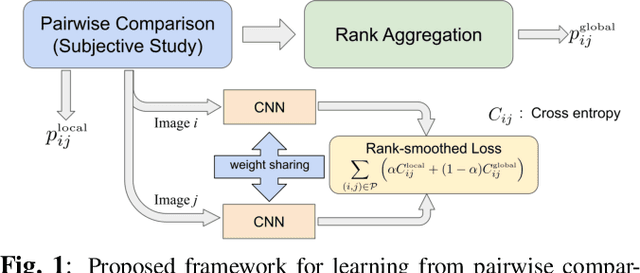
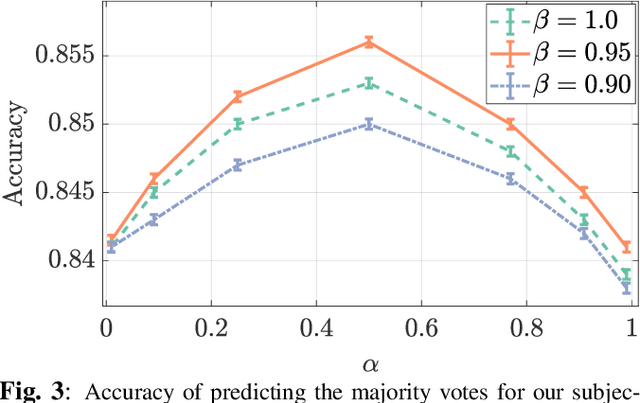

Conducting pairwise comparisons is a widely used approach in curating human perceptual preference data. Typically raters are instructed to make their choices according to a specific set of rules that address certain dimensions of image quality and aesthetics. The outcome of this process is a dataset of sampled image pairs with their associated empirical preference probabilities. Training a model on these pairwise preferences is a common deep learning approach. However, optimizing by gradient descent through mini-batch learning means that the "global" ranking of the images is not explicitly taken into account. In other words, each step of the gradient descent relies only on a limited number of pairwise comparisons. In this work, we demonstrate that regularizing the pairwise empirical probabilities with aggregated rankwise probabilities leads to a more reliable training loss. We show that training a deep image quality assessment model with our rank-smoothed loss consistently improves the accuracy of predicting human preferences.
Glioblastoma Multiforme Patient Survival Prediction
Jan 26, 2021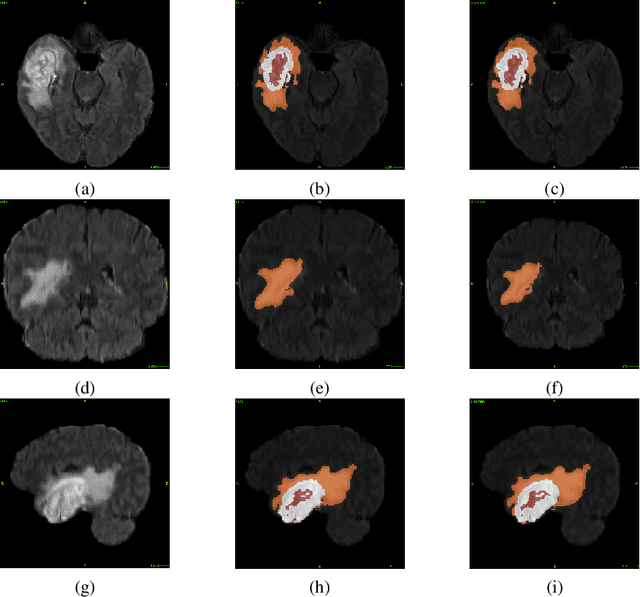
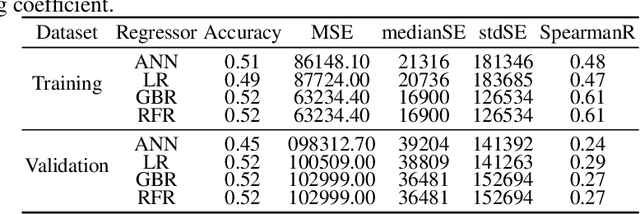

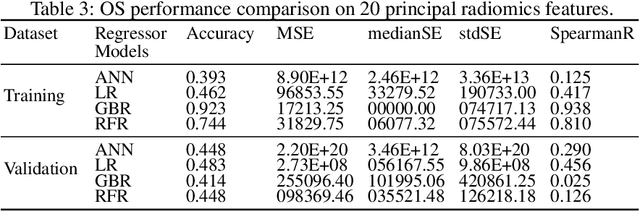
Glioblastoma Multiforme is a very aggressive type of brain tumor. Due to spatial and temporal intra-tissue inhomogeneity, location and the extent of the cancer tissue, it is difficult to detect and dissect the tumor regions. In this paper, we propose survival prognosis models using four regressors operating on handcrafted image-based and radiomics features. We hypothesize that the radiomics shape features have the highest correlation with survival prediction. The proposed approaches were assessed on the Brain Tumor Segmentation (BraTS-2020) challenge dataset. The highest accuracy of image features with random forest regressor approach was 51.5\% for the training and 51.7\% for the validation dataset. The gradient boosting regressor with shape features gave an accuracy of 91.5\% and 62.1\% on training and validation datasets respectively. It is better than the BraTS 2020 survival prediction challenge winners on the training and validation datasets. Our work shows that handcrafted features exhibit a strong correlation with survival prediction. The consensus based regressor with gradient boosting and radiomics shape features is the best combination for survival prediction.
* 10 pages, 9 figures
Learned Gradient Compression for Distributed Deep Learning
Mar 17, 2021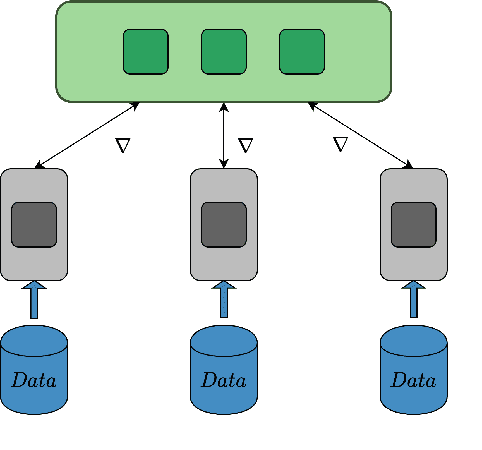
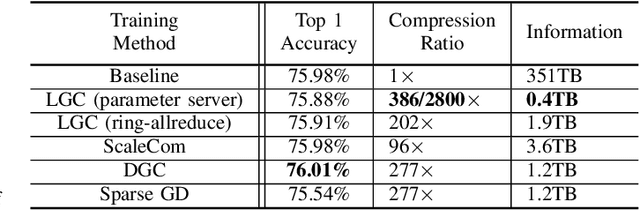
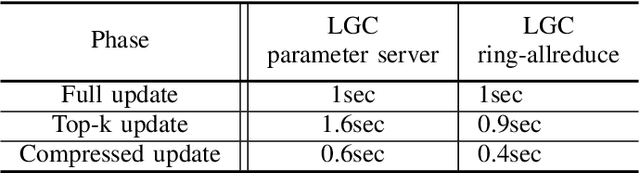
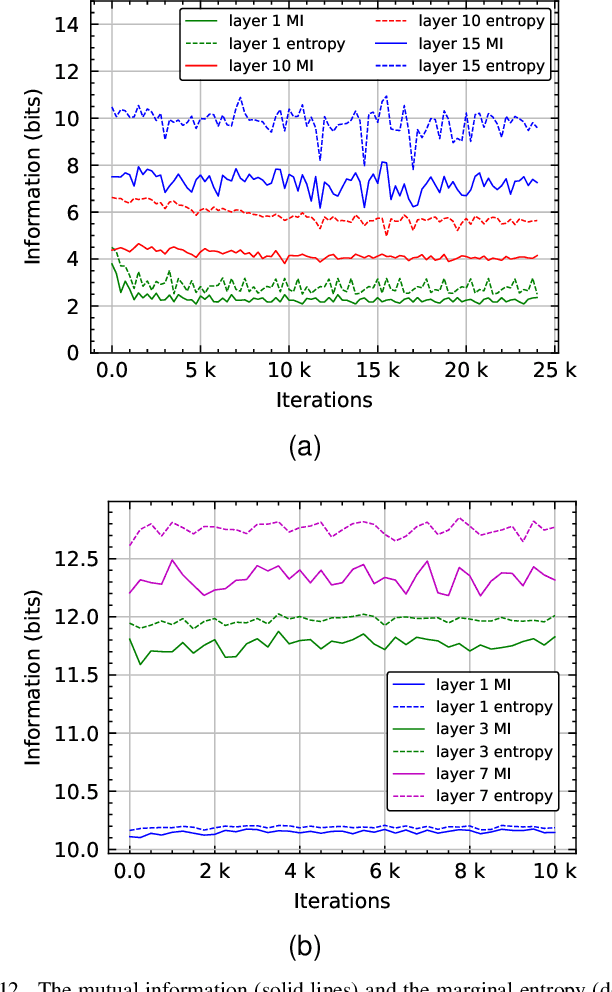
Training deep neural networks on large datasets containing high-dimensional data requires a large amount of computation. A solution to this problem is data-parallel distributed training, where a model is replicated into several computational nodes that have access to different chunks of the data. This approach, however, entails high communication rates and latency because of the computed gradients that need to be shared among nodes at every iteration. The problem becomes more pronounced in the case that there is wireless communication between the nodes (i.e. due to the limited network bandwidth). To address this problem, various compression methods have been proposed including sparsification, quantization, and entropy encoding of the gradients. Existing methods leverage the intra-node information redundancy, that is, they compress gradients at each node independently. In contrast, we advocate that the gradients across the nodes are correlated and propose methods to leverage this inter-node redundancy to improve compression efficiency. Depending on the node communication protocol (parameter server or ring-allreduce), we propose two instances of the LGC approach that we coin Learned Gradient Compression (LGC). Our methods exploit an autoencoder (i.e. trained during the first stages of the distributed training) to capture the common information that exists in the gradients of the distributed nodes. We have tested our LGC methods on the image classification and semantic segmentation tasks using different convolutional neural networks (ResNet50, ResNet101, PSPNet) and multiple datasets (ImageNet, Cifar10, CamVid). The ResNet101 model trained for image classification on Cifar10 achieved an accuracy of 93.57%, which is lower than the baseline distributed training with uncompressed gradients only by 0.18%.
Exploring modality-agnostic representations for music classification
Jun 02, 2021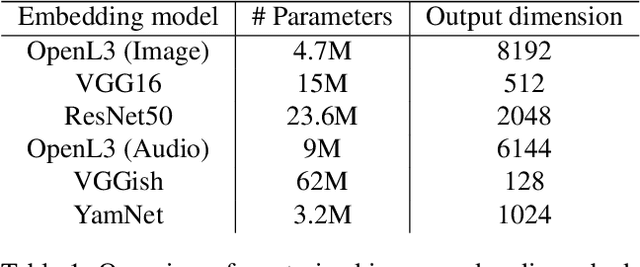
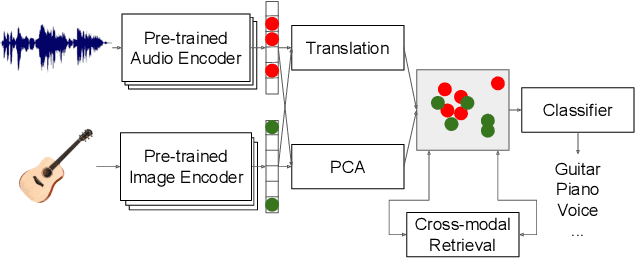
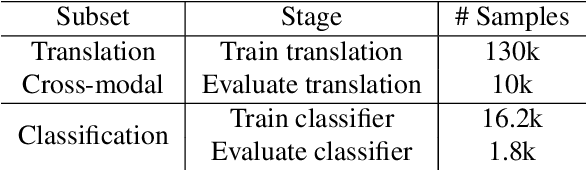
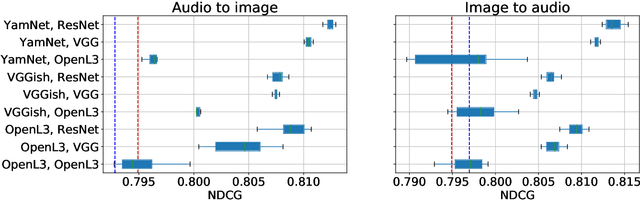
Music information is often conveyed or recorded across multiple data modalities including but not limited to audio, images, text and scores. However, music information retrieval research has almost exclusively focused on single modality recognition, requiring development of separate models for each modality. Some multi-modal works require multiple coexisting modalities given to the model as inputs, constraining the use of these models to the few cases where data from all modalities are available. To the best of our knowledge, no existing model has the ability to take inputs from varying modalities, e.g. images or sounds, and classify them into unified music categories. We explore the use of cross-modal retrieval as a pretext task to learn modality-agnostic representations, which can then be used as inputs to classifiers that are independent of modality. We select instrument classification as an example task for our study as both visual and audio components provide relevant semantic information. We train music instrument classifiers that can take both images or sounds as input, and perform comparably to sound-only or image-only classifiers. Furthermore, we explore the case when there is limited labeled data for a given modality, and the impact in performance by using labeled data from other modalities. We are able to achieve almost 70% of best performing system in a zero-shot setting. We provide a detailed analysis of experimental results to understand the potential and limitations of the approach, and discuss future steps towards modality-agnostic classifiers.