 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
A Simple and Effective Use of Object-Centric Images for Long-Tailed Object Detection
Feb 17, 2021
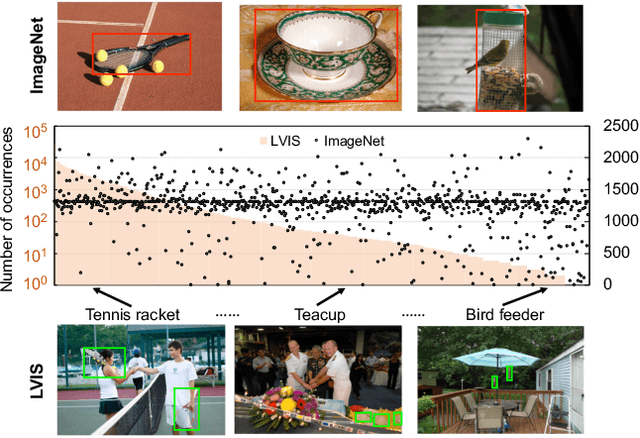
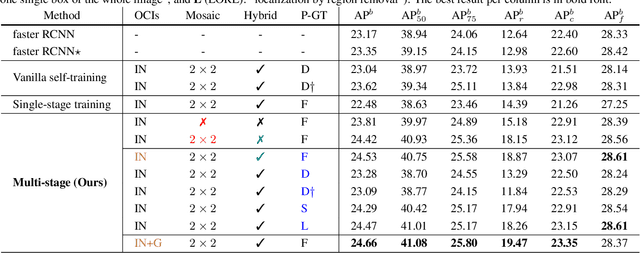

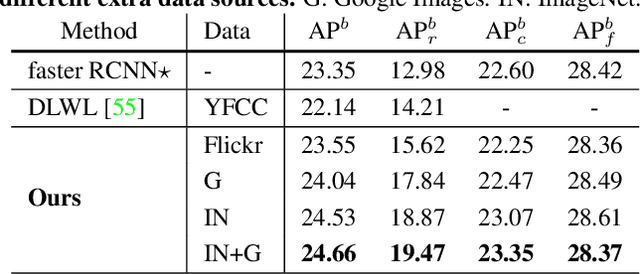
Object frequencies in daily scenes follow a long-tailed distribution. Many objects do not appear frequently enough in scene-centric images (e.g., sightseeing, street views) for us to train accurate object detectors. In contrast, these objects are captured at a higher frequency in object-centric images, which are intended to picture the objects of interest. Motivated by this phenomenon, we propose to take advantage of the object-centric images to improve object detection in scene-centric images. We present a simple yet surprisingly effective framework to do so. On the one hand, our approach turns an object-centric image into a useful training example for object detection in scene-centric images by mitigating the domain gap between the two image sources in both the input and label space. On the other hand, our approach employs a multi-stage procedure to train the object detector, such that the detector learns the diverse object appearances from object-centric images while being tied to the application domain of scene-centric images. On the LVIS dataset, our approach can improve the object detection (and instance segmentation) accuracy of rare objects by 50% (and 33%) relatively, without sacrificing the performance of other classes.
PlenoptiCam v1.0: A light-field imaging framework
Oct 14, 2020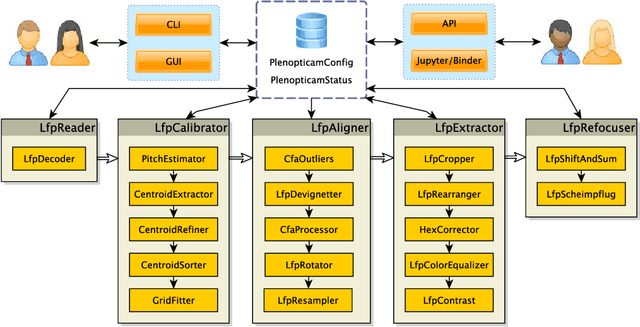
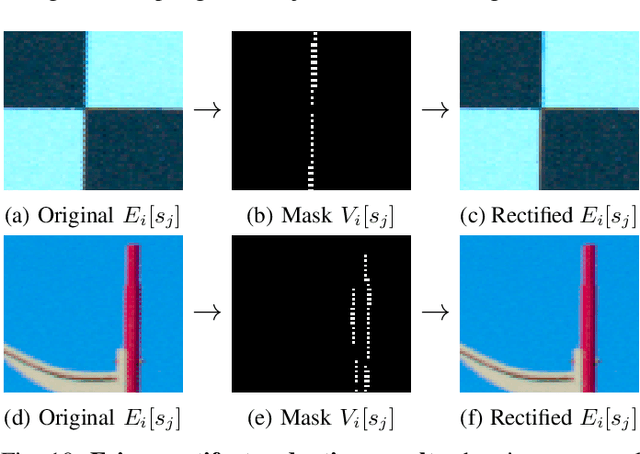


Light-field cameras play a vital role for rich 3-D information retrieval in narrow range depth sensing applications. The key obstacle in composing light-fields from exposures taken by a plenoptic camera is to computationally calibrate, re-align and rearrange four-dimensional image data. Several attempts have been proposed to enhance the overall image quality by tailoring pipelines dedicated to particular plenoptic cameras and improving the color consistency across viewpoints at the expense of high computational loads. The framework presented herein advances prior outcomes thanks to its cost-effective color equalization from parallax-invariant probability distribution transfers and a novel micro image scale-space analysis for generic camera calibration independent of the lens specifications. Our framework compensates for hot-pixels, resampling artifacts, micro image grid rotations just as vignetting in an innovative way to enable superior quality in sub-aperture image extraction, computational refocusing and Scheimpflug rendering with sub-sampling capabilities. Benchmark comparisons using established image metrics suggest that our proposed pipeline outperforms state-of-the-art tool chains in the majority of cases. The software described in this paper is released under an open-source license offering cross-platform compatibility, few dependencies and a lean graphical user interface to make the reproduction of results and the experimentation with plenoptic camera technology convenient for peer researchers, developers, photographers, data scientists and everyone else working in this field.
Using RGB Image as Visual Input for Mapless Robot Navigation
Apr 16, 2019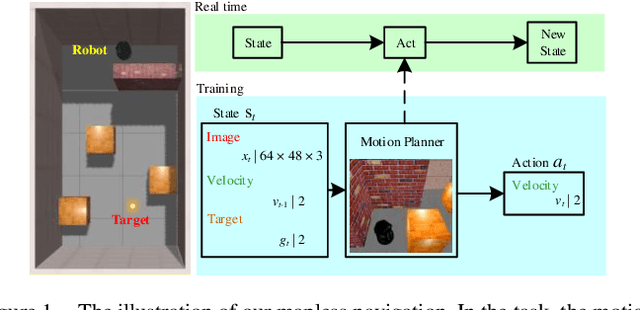
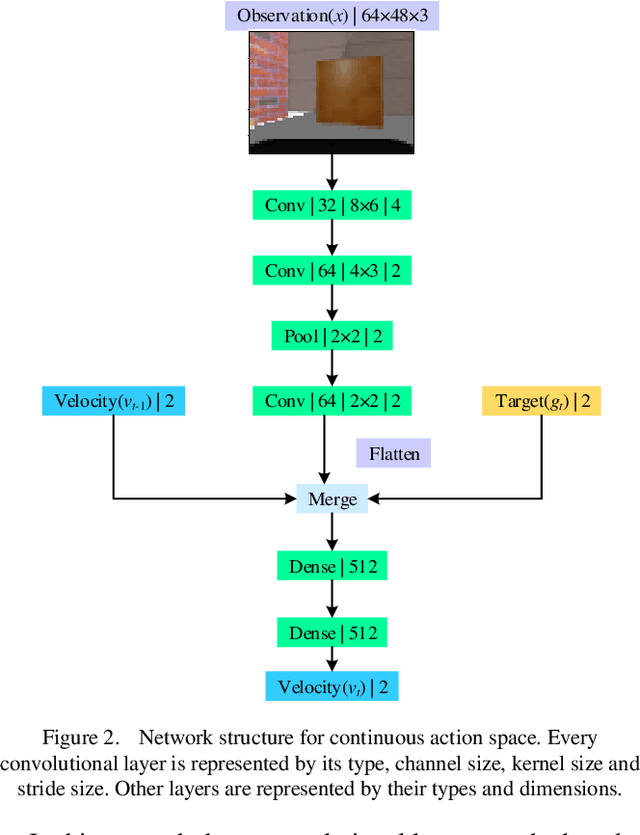
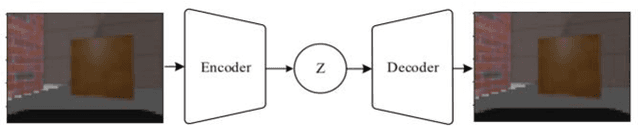
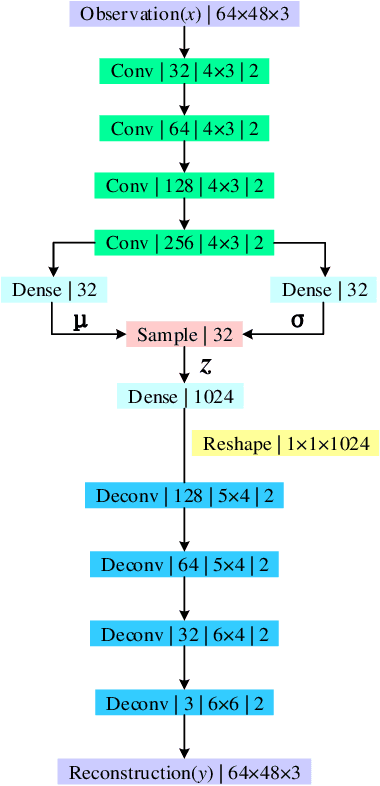
Robot navigation in mapless environment is one of the essential problems and challenges in mobile robots. Deep reinforcement learning is a promising technique to tackle the task of mapless navigation. Since reinforcement learning requires a lot of explorations, it is usually necessary to train the agent in the simulator and then migrate to the real environment. The big reality gap makes RGB image, the most common visual sensor, rarely used. In this paper we present a learning-based mapless motion planner by taking RGB images as visual inputs. Many parameters in end-to-end navigation network taking RGB images as visual input are used to extract visual features. Therefore, we decouple visual features extracted module from the reinforcement learning network to reduce the need of interactions between agent and environment. We use Variational Autoencoder (VAE) to encode the image, and input the obtained latent vector as low-dimensional visual features into the network together with the target and motion information, so that the sampling efficiency of the agent is greatly improved. We built simulation environment as robot navigation environment for algorithm comparison. In the test environment, the proposed method was compared with the end-to-end network, which proved its effectiveness and efficiency. The source code is available: https://github.com/marooncn/navbot.
Learning to Sample the Most Useful Training Patches from Images
Nov 24, 2020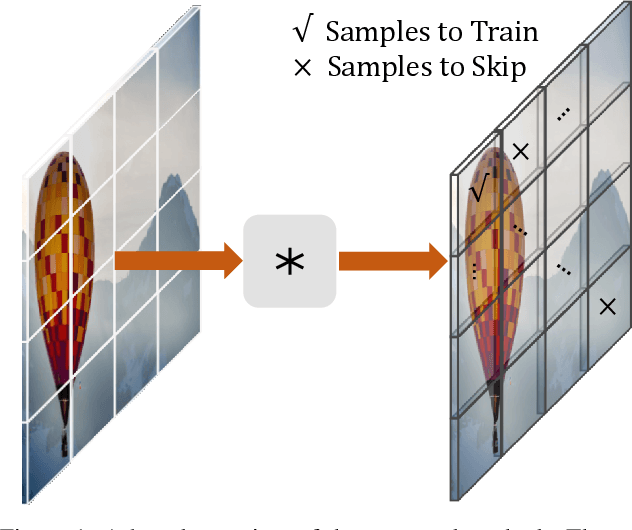


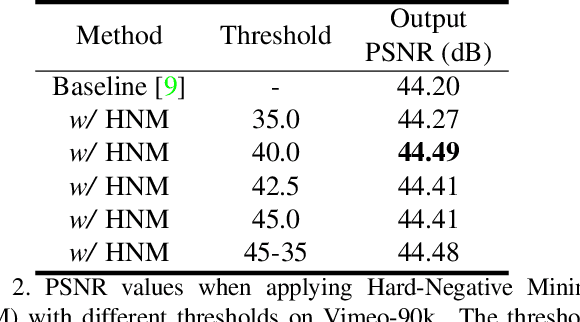
Some image restoration tasks like demosaicing require difficult training samples to learn effective models. Existing methods attempt to address this data training problem by manually collecting a new training dataset that contains adequate hard samples, however, there are still hard and simple areas even within one single image. In this paper, we present a data-driven approach called PatchNet that learns to select the most useful patches from an image to construct a new training set instead of manual or random selection. We show that our simple idea automatically selects informative samples out from a large-scale dataset, leading to a surprising 2.35dB generalisation gain in terms of PSNR. In addition to its remarkable effectiveness, PatchNet is also resource-friendly as it is applied only during training and therefore does not require any additional computational cost during inference.
Convolutional Neural Network Denoising in Fluorescence Lifetime Imaging Microscopy (FLIM)
Mar 07, 2021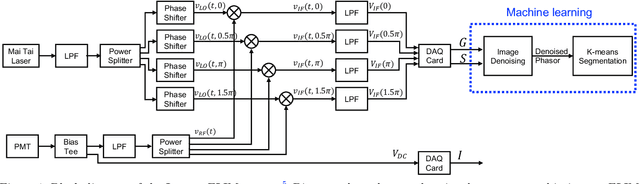


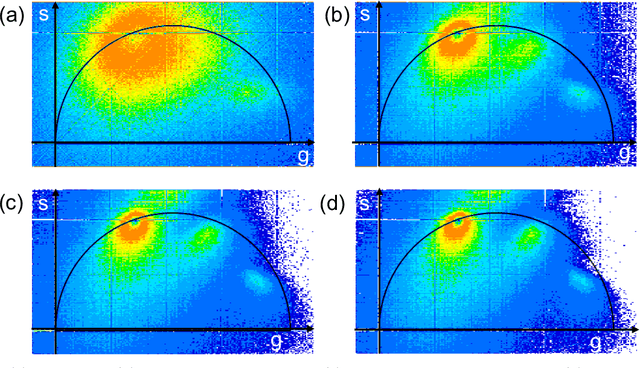
Fluorescence lifetime imaging microscopy (FLIM) systems are limited by their slow processing speed, low signal-to-noise ratio (SNR), and expensive and challenging hardware setups. In this work, we demonstrate applying a denoising convolutional network to improve FLIM SNR. The network will be integrated with an instant FLIM system with fast data acquisition based on analog signal processing, high SNR using high-efficiency pulse-modulation, and cost-effective implementation utilizing off-the-shelf radio-frequency components. Our instant FLIM system simultaneously provides the intensity, lifetime, and phasor plots \textit{in vivo} and \textit{ex vivo}. By integrating image denoising using the trained deep learning model on the FLIM data, provide accurate FLIM phasor measurements are obtained. The enhanced phasor is then passed through the K-means clustering segmentation method, an unbiased and unsupervised machine learning technique to separate different fluorophores accurately. Our experimental \textit{in vivo} mouse kidney results indicate that introducing the deep learning image denoising model before the segmentation effectively removes the noise in the phasor compared to existing methods and provides clearer segments. Hence, the proposed deep learning-based workflow provides fast and accurate automatic segmentation of fluorescence images using instant FLIM. The denoising operation is effective for the segmentation if the FLIM measurements are noisy. The clustering can effectively enhance the detection of biological structures of interest in biomedical imaging applications.
Dual-stream Network for Visual Recognition
May 31, 2021
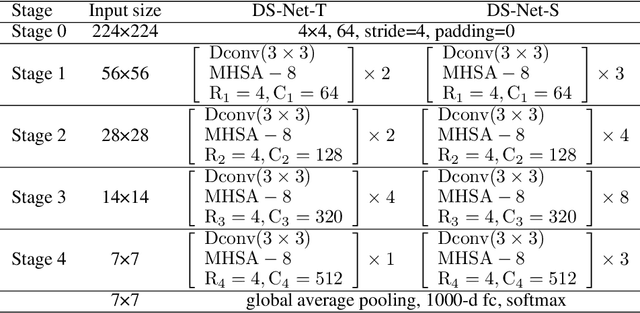
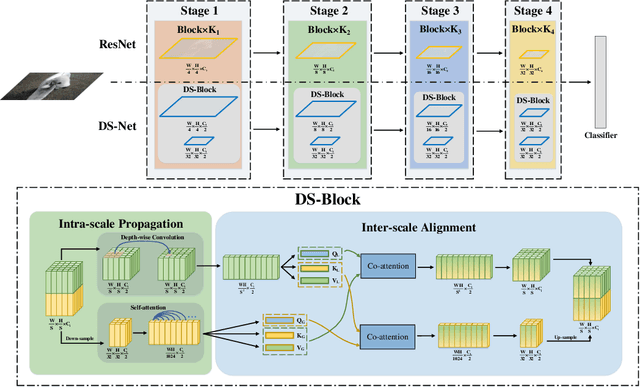
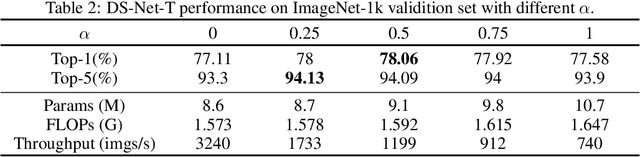
Transformers with remarkable global representation capacities achieve competitive results for visual tasks, but fail to consider high-level local pattern information in input images. In this paper, we present a generic Dual-stream Network (DS-Net) to fully explore the representation capacity of local and global pattern features for image classification. Our DS-Net can simultaneously calculate fine-grained and integrated features and efficiently fuse them. Specifically, we propose an Intra-scale Propagation module to process two different resolutions in each block and an Inter-Scale Alignment module to perform information interaction across features at dual scales. Besides, we also design a Dual-stream FPN (DS-FPN) to further enhance contextual information for downstream dense predictions. Without bells and whistles, the propsed DS-Net outperforms Deit-Small by 2.4% in terms of top-1 accuracy on ImageNet-1k and achieves state-of-the-art performance over other Vision Transformers and ResNets. For object detection and instance segmentation, DS-Net-Small respectively outperforms ResNet-50 by 6.4% and 5.5 % in terms of mAP on MSCOCO 2017, and surpasses the previous state-of-the-art scheme, which significantly demonstrates its potential to be a general backbone in vision tasks. The code will be released soon.
Texture Synthesis Guided Deep Hashing for Texture Image Retrieval
Nov 04, 2018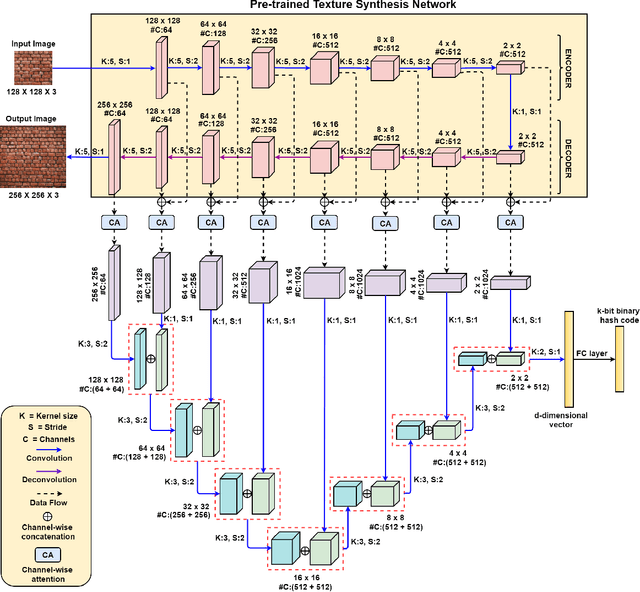
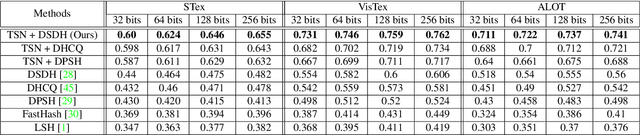

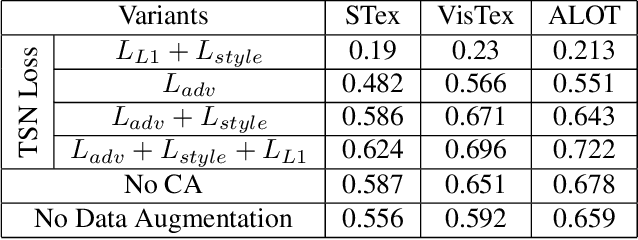
With the large-scale explosion of images and videos over the internet, efficient hashing methods have been developed to facilitate memory and time efficient retrieval of similar images. However, none of the existing works uses hashing to address texture image retrieval mostly because of the lack of sufficiently large texture image databases. Our work addresses this problem by developing a novel deep learning architecture that generates binary hash codes for input texture images. For this, we first pre-train a Texture Synthesis Network (TSN) which takes a texture patch as input and outputs an enlarged view of the texture by injecting newer texture content. Thus it signifies that the TSN encodes the learnt texture specific information in its intermediate layers. In the next stage, a second network gathers the multi-scale feature representations from the TSN's intermediate layers using channel-wise attention, combines them in a progressive manner to a dense continuous representation which is finally converted into a binary hash code with the help of individual and pairwise label information. The new enlarged texture patches also help in data augmentation to alleviate the problem of insufficient texture data and are used to train the second stage of the network. Experiments on three public texture image retrieval datasets indicate the superiority of our texture synthesis guided hashing approach over current state-of-the-art methods.
Semantic Layout Manipulation with High-Resolution Sparse Attention
Dec 14, 2020
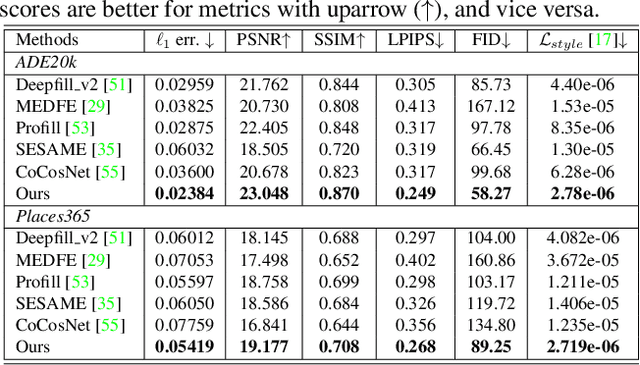
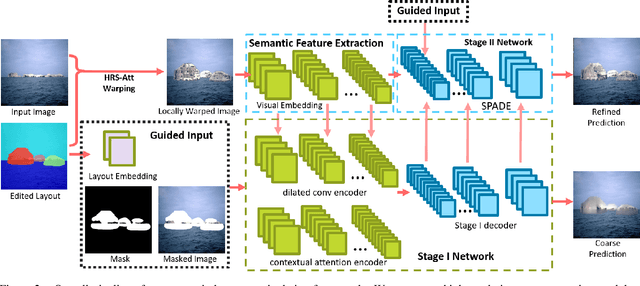
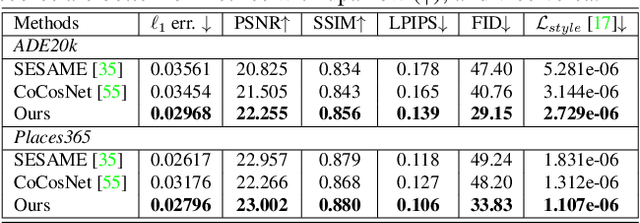
We tackle the problem of semantic image layout manipulation, which aims to manipulate an input image by editing its semantic label map. A core problem of this task is how to transfer visual details from the input images to the new semantic layout while making the resulting image visually realistic. Recent work on learning cross-domain correspondence has shown promising results for global layout transfer with dense attention-based warping. However, this method tends to lose texture details due to the lack of smoothness and resolution in the correspondence and warped images. To adapt this paradigm for the layout manipulation task, we propose a high-resolution sparse attention module that effectively transfers visual details to new layouts at a resolution up to 512x512. To further improve visual quality, we introduce a novel generator architecture consisting of a semantic encoder and a two-stage decoder for coarse-to-fine synthesis. Experiments on the ADE20k and Places365 datasets demonstrate that our proposed approach achieves substantial improvements over the existing inpainting and layout manipulation methods.
Constructing a Visual Relationship Authenticity Dataset
Oct 11, 2020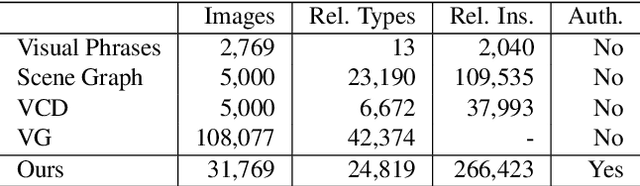

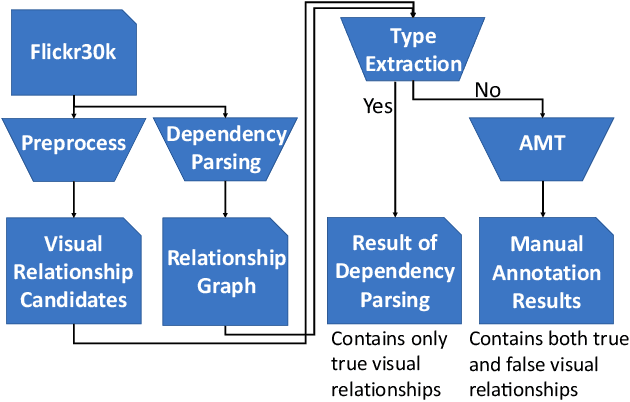
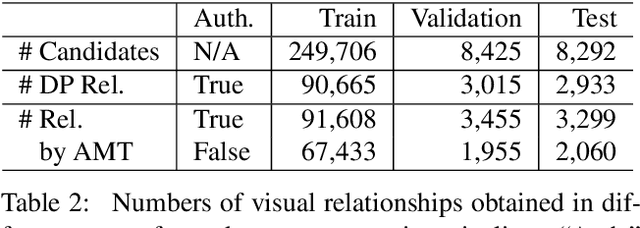
A visual relationship denotes a relationship between two objects in an image, which can be represented as a triplet of (subject; predicate; object). Visual relationship detection is crucial for scene understanding in images. Existing visual relationship detection datasets only contain true relationships that correctly describe the content in an image. However, distinguishing false visual relationships from true ones is also crucial for image understanding and grounded natural language processing. In this paper, we construct a visual relationship authenticity dataset, where both true and false relationships among all objects appeared in the captions in the Flickr30k entities image caption dataset are annotated. The dataset is available at https://github.com/codecreator2053/VR_ClassifiedDataset. We hope that this dataset can promote the study on both vision and language understanding.
Is segmentation uncertainty useful?
Mar 30, 2021
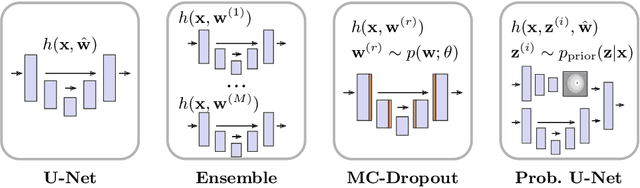
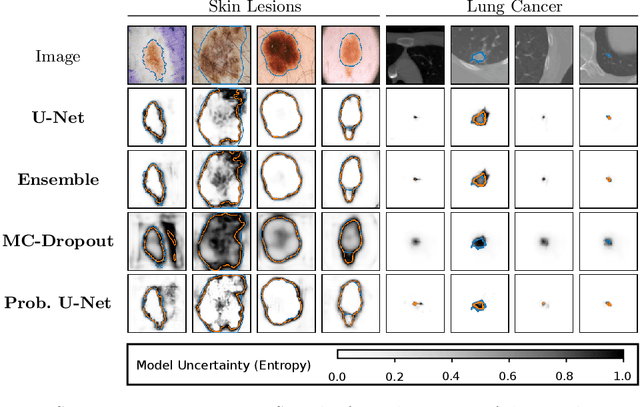
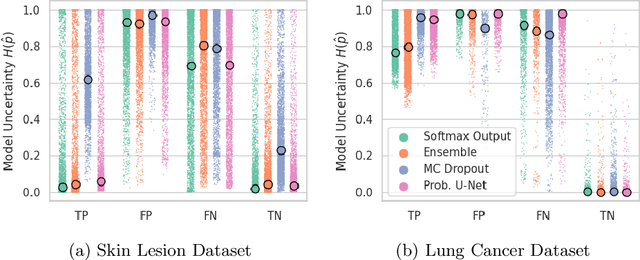
Probabilistic image segmentation encodes varying prediction confidence and inherent ambiguity in the segmentation problem. While different probabilistic segmentation models are designed to capture different aspects of segmentation uncertainty and ambiguity, these modelling differences are rarely discussed in the context of applications of uncertainty. We consider two common use cases of segmentation uncertainty, namely assessment of segmentation quality and active learning. We consider four established strategies for probabilistic segmentation, discuss their modelling capabilities, and investigate their performance in these two tasks. We find that for all models and both tasks, returned uncertainty correlates positively with segmentation error, but does not prove to be useful for active learning.