 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Quantum Algorithms for Data Representation and Analysis
Apr 19, 2021
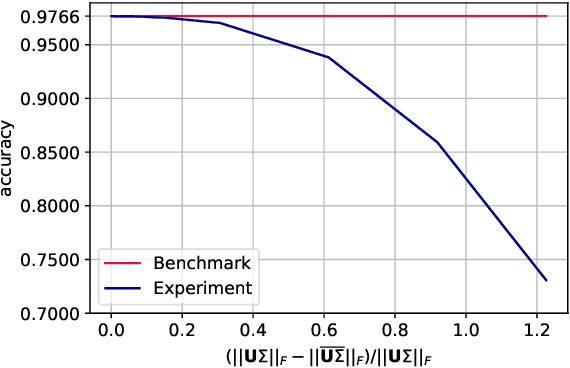
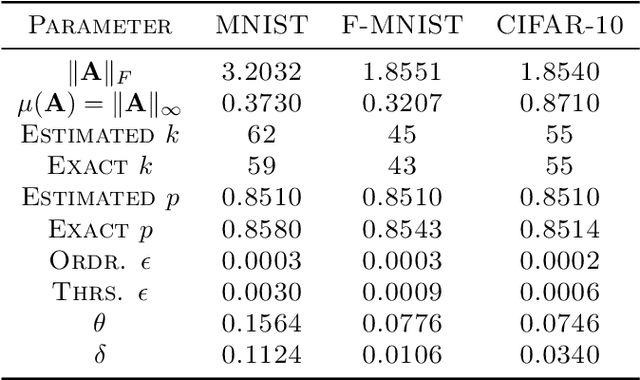
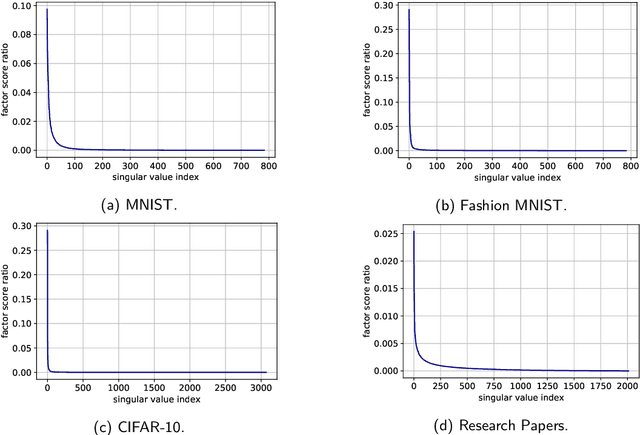
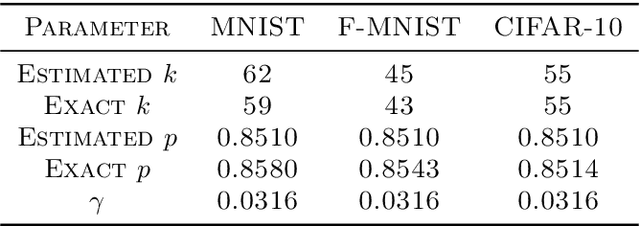
We narrow the gap between previous literature on quantum linear algebra and useful data analysis on a quantum computer, providing quantum procedures that speed-up the solution of eigenproblems for data representation in machine learning. The power and practical use of these subroutines is shown through new quantum algorithms, sublinear in the input matrix's size, for principal component analysis, correspondence analysis, and latent semantic analysis. We provide a theoretical analysis of the run-time and prove tight bounds on the randomized algorithms' error. We run experiments on multiple datasets, simulating PCA's dimensionality reduction for image classification with the novel routines. The results show that the run-time parameters that do not depend on the input's size are reasonable and that the error on the computed model is small, allowing for competitive classification performances.
An Effective Single-Image Super-Resolution Model Using Squeeze-and-Excitation Networks
Oct 03, 2018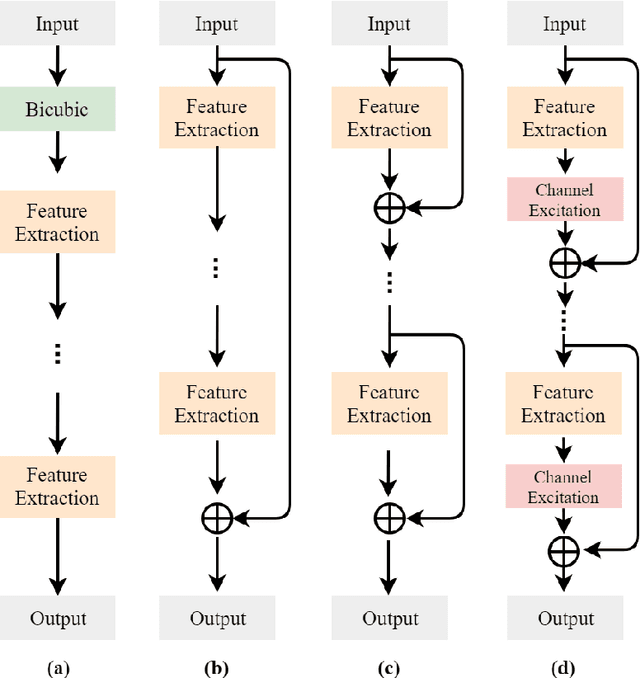
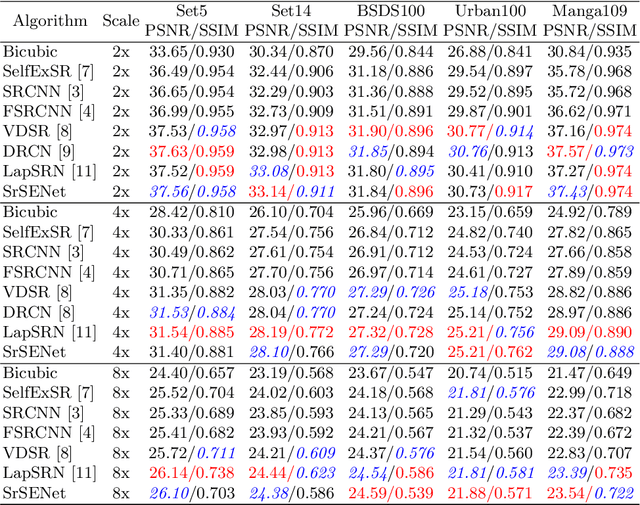
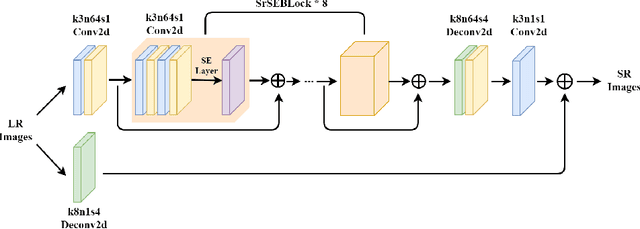

Recent works on single-image super-resolution are concentrated on improving performance through enhancing spatial encoding between convolutional layers. In this paper, we focus on modeling the correlations between channels of convolutional features. We present an effective deep residual network based on squeeze-and-excitation blocks (SEBlock) to reconstruct high-resolution (HR) image from low-resolution (LR) image. SEBlock is used to adaptively recalibrate channel-wise feature mappings. Further, short connections between each SEBlock are used to remedy information loss. Extensive experiments show that our model can achieve the state-of-the-art performance and get finer texture details.
MOS: Towards Scaling Out-of-distribution Detection for Large Semantic Space
May 05, 2021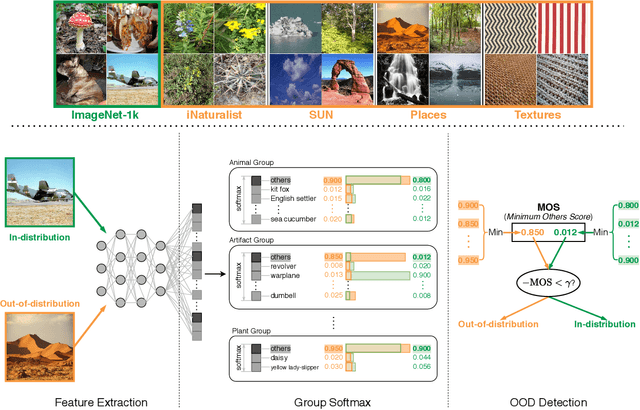
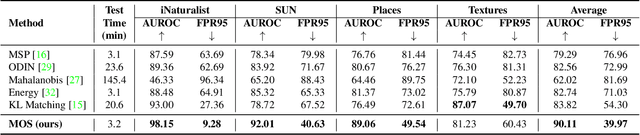
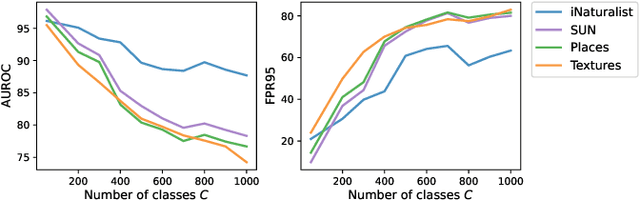
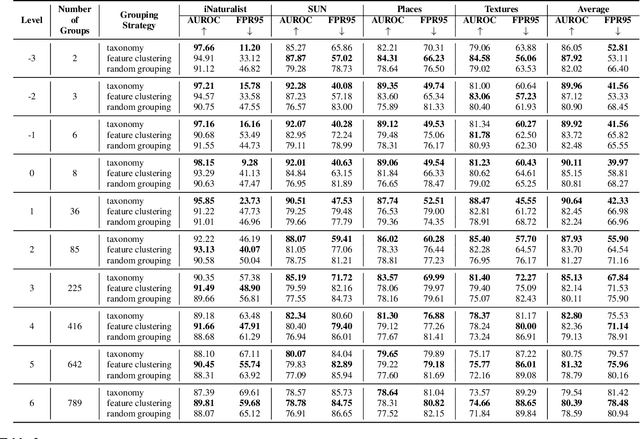
Detecting out-of-distribution (OOD) inputs is a central challenge for safely deploying machine learning models in the real world. Existing solutions are mainly driven by small datasets, with low resolution and very few class labels (e.g., CIFAR). As a result, OOD detection for large-scale image classification tasks remains largely unexplored. In this paper, we bridge this critical gap by proposing a group-based OOD detection framework, along with a novel OOD scoring function termed MOS. Our key idea is to decompose the large semantic space into smaller groups with similar concepts, which allows simplifying the decision boundaries between in- vs. out-of-distribution data for effective OOD detection. Our method scales substantially better for high-dimensional class space than previous approaches. We evaluate models trained on ImageNet against four carefully curated OOD datasets, spanning diverse semantics. MOS establishes state-of-the-art performance, reducing the average FPR95 by 14.33% while achieving 6x speedup in inference compared to the previous best method.
Using RGB Image as Visual Input for Mapless Robot Navigation
Apr 16, 2019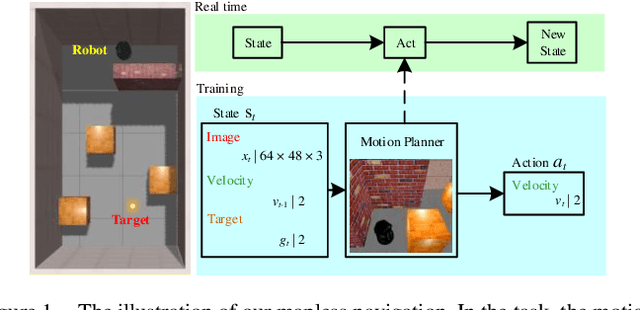
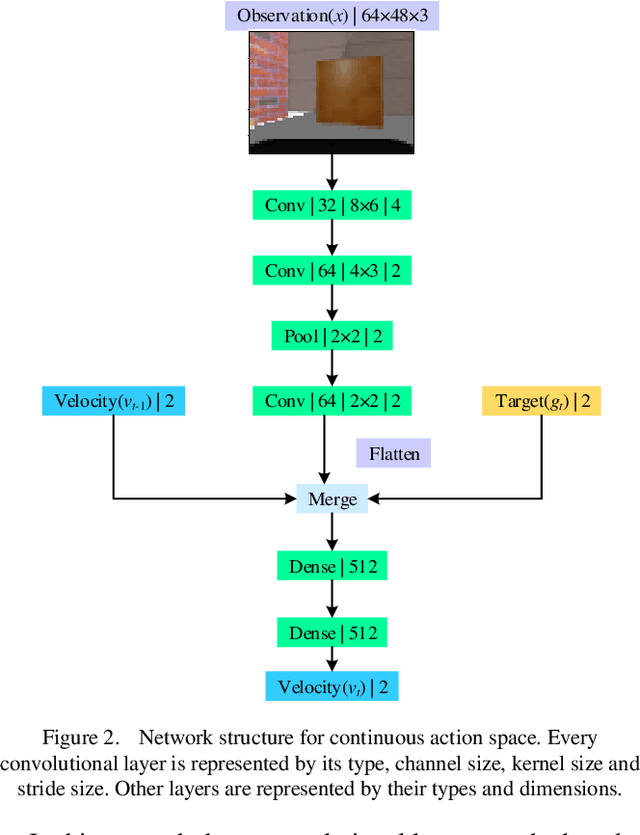
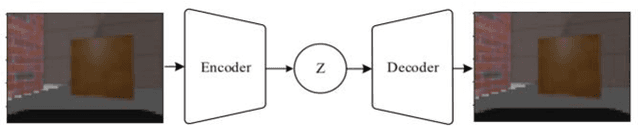
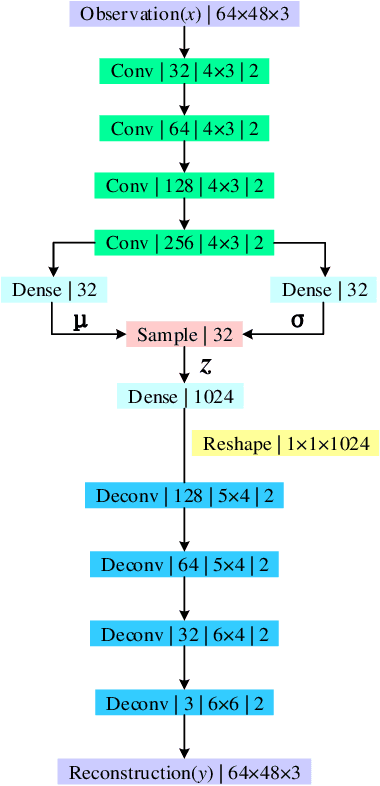
Robot navigation in mapless environment is one of the essential problems and challenges in mobile robots. Deep reinforcement learning is a promising technique to tackle the task of mapless navigation. Since reinforcement learning requires a lot of explorations, it is usually necessary to train the agent in the simulator and then migrate to the real environment. The big reality gap makes RGB image, the most common visual sensor, rarely used. In this paper we present a learning-based mapless motion planner by taking RGB images as visual inputs. Many parameters in end-to-end navigation network taking RGB images as visual input are used to extract visual features. Therefore, we decouple visual features extracted module from the reinforcement learning network to reduce the need of interactions between agent and environment. We use Variational Autoencoder (VAE) to encode the image, and input the obtained latent vector as low-dimensional visual features into the network together with the target and motion information, so that the sampling efficiency of the agent is greatly improved. We built simulation environment as robot navigation environment for algorithm comparison. In the test environment, the proposed method was compared with the end-to-end network, which proved its effectiveness and efficiency. The source code is available: https://github.com/marooncn/navbot.
Scorpion detection and classification systems based on computer vision and deep learning for health security purposes
May 31, 2021
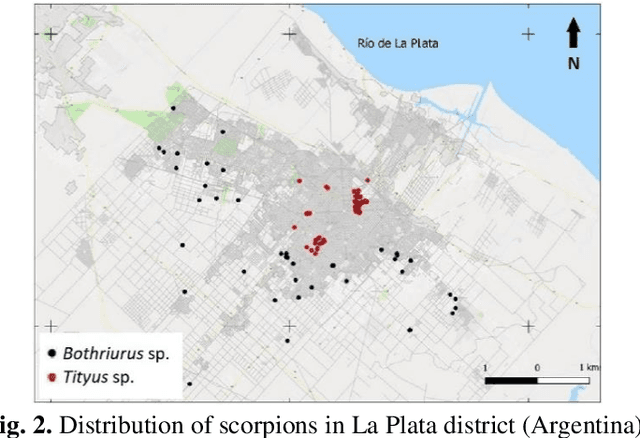
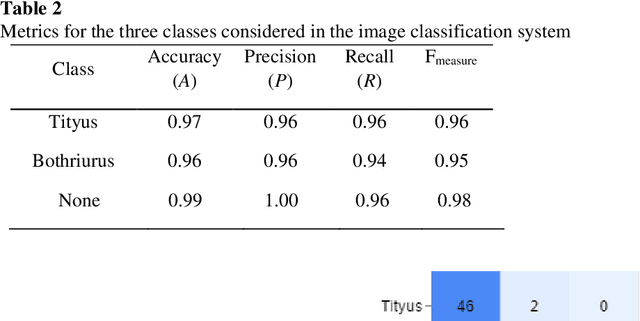
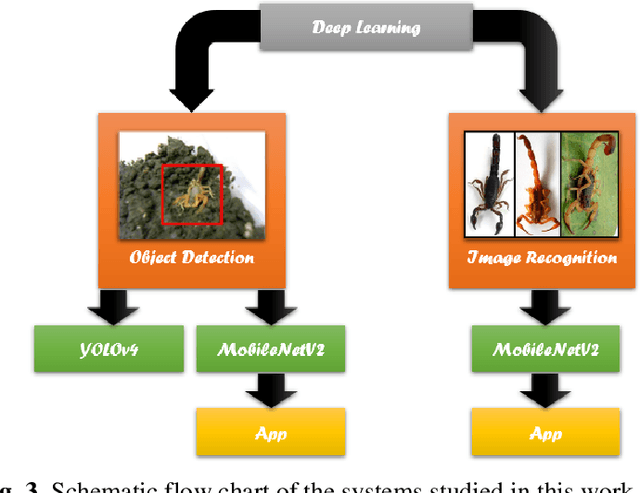
In this paper, two novel automatic and real-time systems for the detection and classification of two genera of scorpions found in La Plata city (Argentina) were developed using computer vision and deep learning techniques. The object detection technique was implemented with two different methods, YOLO (You Only Look Once) and MobileNet, based on the shape features of the scorpions. High accuracy values of 88% and 91%, and high recall values of 90% and 97%, have been achieved for both models, respectively, which guarantees that they can successfully detect scorpions. In addition, the MobileNet method has been shown to have excellent performance to detect scorpions within an uncontrolled environment and to perform multiple detections. The MobileNet model was also used for image classification in order to successfully distinguish between dangerous scorpion (Tityus) and non-dangerous scorpion (Bothriurus) with the purpose of providing a health security tool. Applications for smartphones were developed, with the advantage of the portability of the systems, which can be used as a help tool for emergency services, or for biological research purposes. The developed systems can be easily scalable to other genera and species of scorpions to extend the region where these applications can be used.
Texture Synthesis Guided Deep Hashing for Texture Image Retrieval
Nov 04, 2018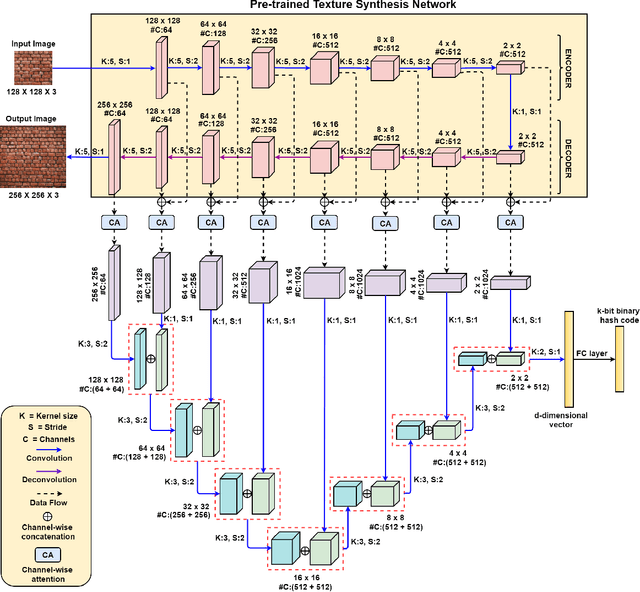
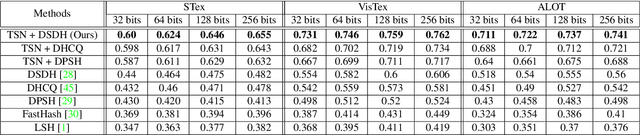

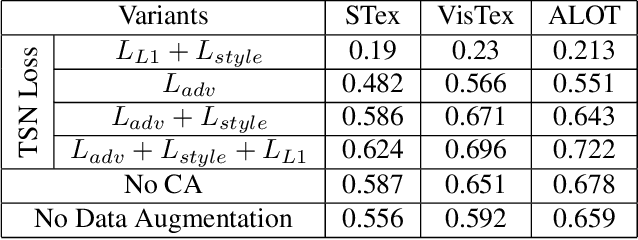
With the large-scale explosion of images and videos over the internet, efficient hashing methods have been developed to facilitate memory and time efficient retrieval of similar images. However, none of the existing works uses hashing to address texture image retrieval mostly because of the lack of sufficiently large texture image databases. Our work addresses this problem by developing a novel deep learning architecture that generates binary hash codes for input texture images. For this, we first pre-train a Texture Synthesis Network (TSN) which takes a texture patch as input and outputs an enlarged view of the texture by injecting newer texture content. Thus it signifies that the TSN encodes the learnt texture specific information in its intermediate layers. In the next stage, a second network gathers the multi-scale feature representations from the TSN's intermediate layers using channel-wise attention, combines them in a progressive manner to a dense continuous representation which is finally converted into a binary hash code with the help of individual and pairwise label information. The new enlarged texture patches also help in data augmentation to alleviate the problem of insufficient texture data and are used to train the second stage of the network. Experiments on three public texture image retrieval datasets indicate the superiority of our texture synthesis guided hashing approach over current state-of-the-art methods.
Image Pivoting for Learning Multilingual Multimodal Representations
Jul 24, 2017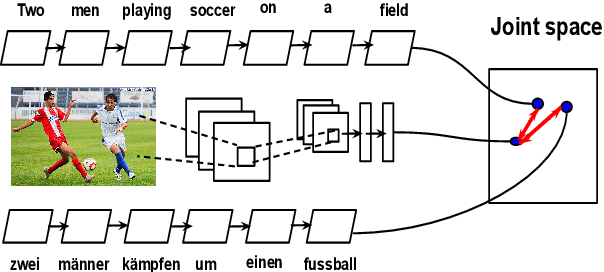
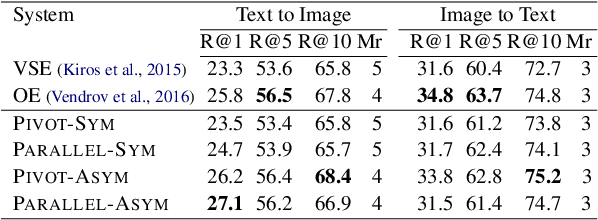
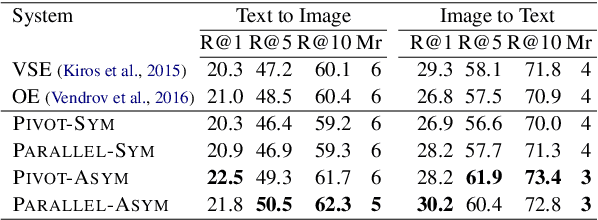

In this paper we propose a model to learn multimodal multilingual representations for matching images and sentences in different languages, with the aim of advancing multilingual versions of image search and image understanding. Our model learns a common representation for images and their descriptions in two different languages (which need not be parallel) by considering the image as a pivot between two languages. We introduce a new pairwise ranking loss function which can handle both symmetric and asymmetric similarity between the two modalities. We evaluate our models on image-description ranking for German and English, and on semantic textual similarity of image descriptions in English. In both cases we achieve state-of-the-art performance.
3DCaricShop: A Dataset and A Baseline Method for Single-view 3D Caricature Face Reconstruction
Mar 15, 2021
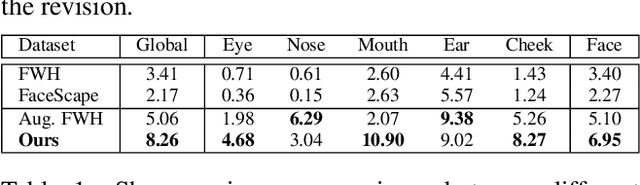

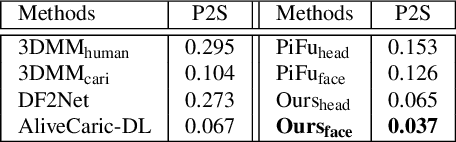
Caricature is an artistic representation that deliberately exaggerates the distinctive features of a human face to convey humor or sarcasm. However, reconstructing a 3D caricature from a 2D caricature image remains a challenging task, mostly due to the lack of data. We propose to fill this gap by introducing 3DCaricShop, the first large-scale 3D caricature dataset that contains 2000 high-quality diversified 3D caricatures manually crafted by professional artists. 3DCaricShop also provides rich annotations including a paired 2D caricature image, camera parameters and 3D facial landmarks. To demonstrate the advantage of 3DCaricShop, we present a novel baseline approach for single-view 3D caricature reconstruction. To ensure a faithful reconstruction with plausible face deformations, we propose to connect the good ends of the detailrich implicit functions and the parametric mesh representations. In particular, we first register a template mesh to the output of the implicit generator and iteratively project the registration result onto a pre-trained PCA space to resolve artifacts and self-intersections. To deal with the large deformation during non-rigid registration, we propose a novel view-collaborative graph convolution network (VCGCN) to extract key points from the implicit mesh for accurate alignment. Our method is able to generate highfidelity 3D caricature in a pre-defined mesh topology that is animation-ready. Extensive experiments have been conducted on 3DCaricShop to verify the significance of the database and the effectiveness of the proposed method.
The effectiveness of feature attribution methods and its correlation with automatic evaluation scores
May 31, 2021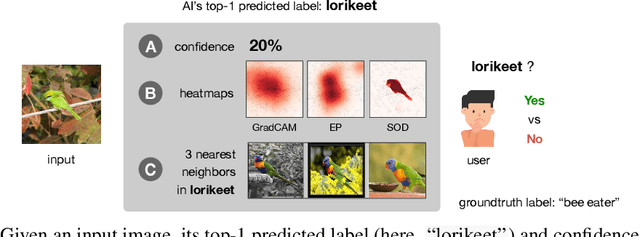

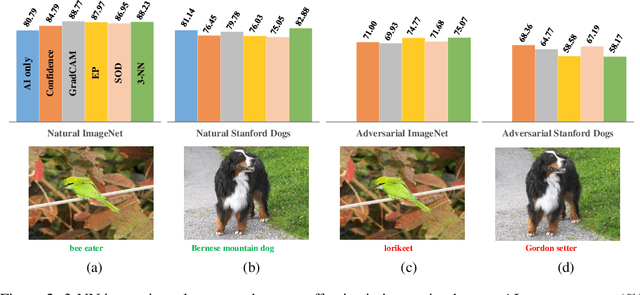

Explaining the decisions of an Artificial Intelligence (AI) model is increasingly critical in many real-world, high-stake applications. Hundreds of papers have either proposed new feature attribution methods, discussed or harnessed these tools in their work. However, despite humans being the target end-users, most attribution methods were only evaluated on proxy automatic-evaluation metrics. In this paper, we conduct the first, large-scale user study on 320 lay and 11 expert users to shed light on the effectiveness of state-of-the-art attribution methods in assisting humans in ImageNet classification, Stanford Dogs fine-grained classification, and these two tasks but when the input image contains adversarial perturbations. We found that, in overall, feature attribution is surprisingly not more effective than showing humans nearest training-set examples. On a hard task of fine-grained dog categorization, presenting attribution maps to humans does not help, but instead hurts the performance of human-AI teams compared to AI alone. Importantly, we found automatic attribution-map evaluation measures to correlate poorly with the actual human-AI team performance. Our findings encourage the community to rigorously test their methods on the downstream human-in-the-loop applications and to rethink the existing evaluation metrics.
Automated and Autonomous Experiment in Electron and Scanning Probe Microscopy
Mar 22, 2021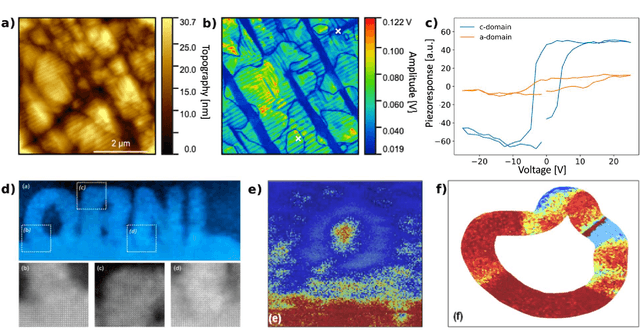
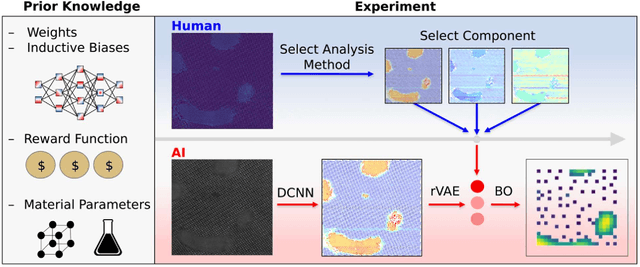
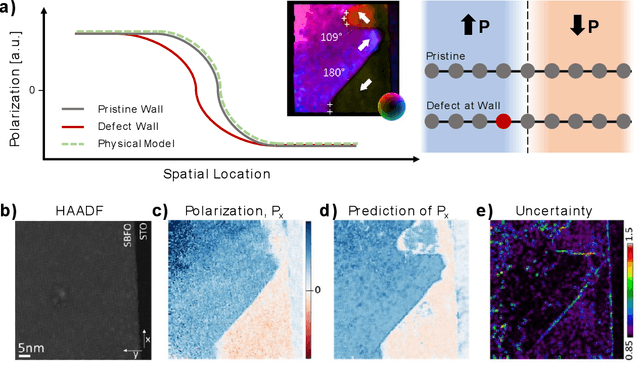
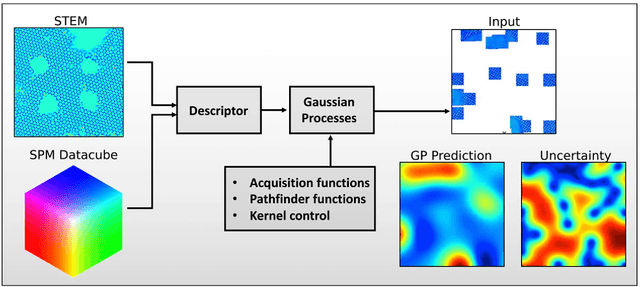
Machine learning and artificial intelligence (ML/AI) are rapidly becoming an indispensable part of physics research, with domain applications ranging from theory and materials prediction to high-throughput data analysis. In parallel, the recent successes in applying ML/AI methods for autonomous systems from robotics through self-driving cars to organic and inorganic synthesis are generating enthusiasm for the potential of these techniques to enable automated and autonomous experiment (AE) in imaging. Here, we aim to analyze the major pathways towards AE in imaging methods with sequential image formation mechanisms, focusing on scanning probe microscopy (SPM) and (scanning) transmission electron microscopy ((S)TEM). We argue that automated experiments should necessarily be discussed in a broader context of the general domain knowledge that both informs the experiment and is increased as the result of the experiment. As such, this analysis should explore the human and ML/AI roles prior to and during the experiment, and consider the latencies, biases, and knowledge priors of the decision-making process. Similarly, such discussion should include the limitations of the existing imaging systems, including intrinsic latencies, non-idealities and drifts comprising both correctable and stochastic components. We further pose that the role of the AE in microscopy is not the exclusion of human operators (as is the case for autonomous driving), but rather automation of routine operations such as microscope tuning, etc., prior to the experiment, and conversion of low latency decision making processes on the time scale spanning from image acquisition to human-level high-order experiment planning.