 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Weakly Supervised Complementary Parts Models for Fine-Grained Image Classification from the Bottom Up
Mar 07, 2019
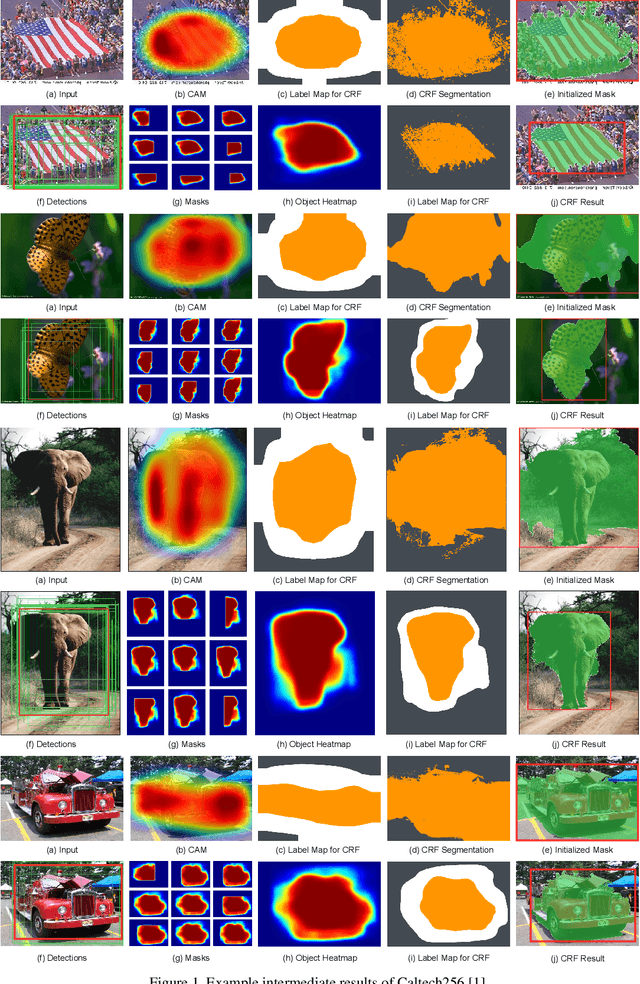

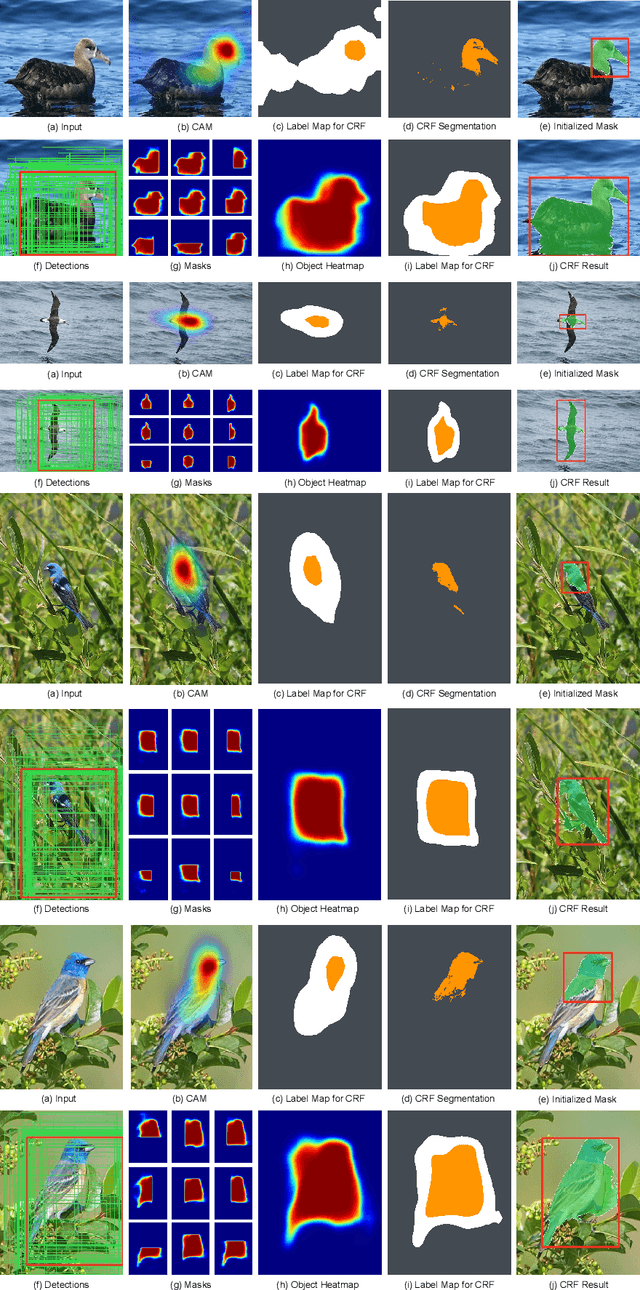
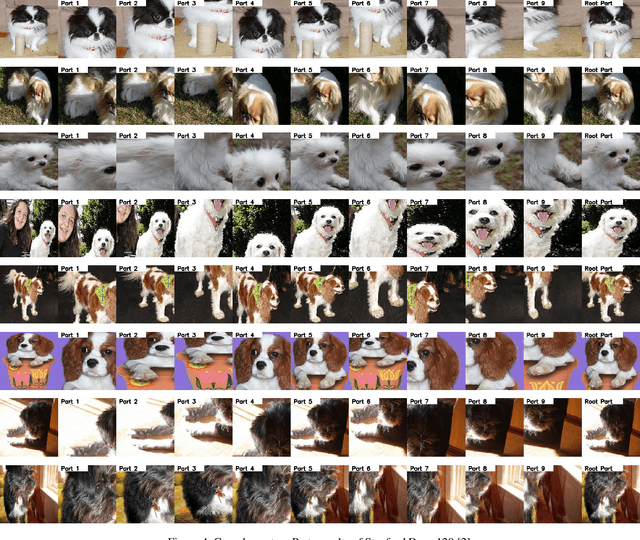
Given a training dataset composed of images and corresponding category labels, deep convolutional neural networks show a strong ability in mining discriminative parts for image classification. However, deep convolutional neural networks trained with image level labels only tend to focus on the most discriminative parts while missing other object parts, which could provide complementary information. In this paper, we approach this problem from a different perspective. We build complementary parts models in a weakly supervised manner to retrieve information suppressed by dominant object parts detected by convolutional neural networks. Given image level labels only, we first extract rough object instances by performing weakly supervised object detection and instance segmentation using Mask R-CNN and CRF-based segmentation. Then we estimate and search for the best parts model for each object instance under the principle of preserving as much diversity as possible. In the last stage, we build a bi-directional long short-term memory (LSTM) network to fuze and encode the partial information of these complementary parts into a comprehensive feature for image classification. Experimental results indicate that the proposed method not only achieves significant improvement over our baseline models, but also outperforms state-of-the-art algorithms by a large margin (6.7%, 2.8%, 5.2% respectively) on Stanford Dogs 120, Caltech-UCSD Birds 2011-200 and Caltech 256.
Dilated Deep Residual Network for Image Denoising
Sep 27, 2017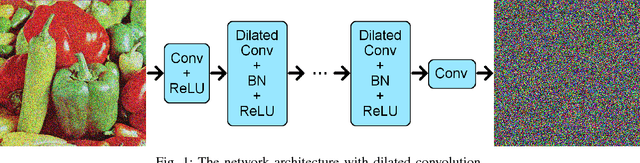
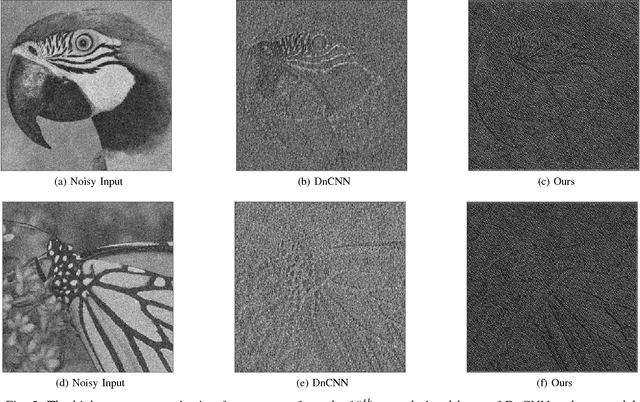


Variations of deep neural networks such as convolutional neural network (CNN) have been successfully applied to image denoising. The goal is to automatically learn a mapping from a noisy image to a clean image given training data consisting of pairs of noisy and clean images. Most existing CNN models for image denoising have many layers. In such cases, the models involve a large amount of parameters and are computationally expensive to train. In this paper, we develop a dilated residual CNN for Gaussian image denoising. Compared with the recently proposed residual denoiser, our method can achieve comparable performance with less computational cost. Specifically, we enlarge receptive field by adopting dilated convolution in residual network, and the dilation factor is set to a certain value. We utilize appropriate zero padding to make the dimension of the output the same as the input. It has been proven that the expansion of receptive field can boost the CNN performance in image classification, and we further demonstrate that it can also lead to competitive performance for denoising problem. Moreover, we present a formula to calculate receptive field size when dilated convolution is incorporated. Thus, the change of receptive field can be interpreted mathematically. To validate the efficacy of our approach, we conduct extensive experiments for both gray and color image denoising with specific or randomized noise levels. Both of the quantitative measurements and the visual results of denoising are promising comparing with state-of-the-art baselines.
Provable Guarantees for Self-Supervised Deep Learning with Spectral Contrastive Loss
Jun 08, 2021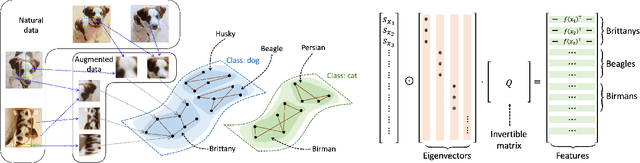
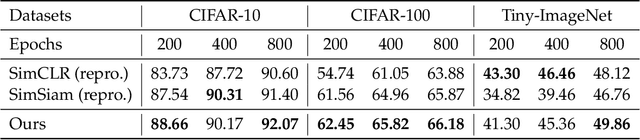
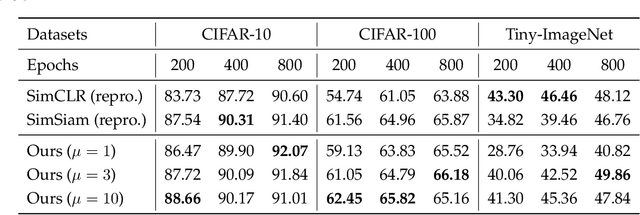
Recent works in self-supervised learning have advanced the state-of-the-art by relying on the contrastive learning paradigm, which learns representations by pushing positive pairs, or similar examples from the same class, closer together while keeping negative pairs far apart. Despite the empirical successes, theoretical foundations are limited -- prior analyses assume conditional independence of the positive pairs given the same class label, but recent empirical applications use heavily correlated positive pairs (i.e., data augmentations of the same image). Our work analyzes contrastive learning without assuming conditional independence of positive pairs using a novel concept of the augmentation graph on data. Edges in this graph connect augmentations of the same data, and ground-truth classes naturally form connected sub-graphs. We propose a loss that performs spectral decomposition on the population augmentation graph and can be succinctly written as a contrastive learning objective on neural net representations. Minimizing this objective leads to features with provable accuracy guarantees under linear probe evaluation. By standard generalization bounds, these accuracy guarantees also hold when minimizing the training contrastive loss. Empirically, the features learned by our objective can match or outperform several strong baselines on benchmark vision datasets. In all, this work provides the first provable analysis for contrastive learning where guarantees for linear probe evaluation can apply to realistic empirical settings.
Closer Look at the Uncertainty Estimation in Semantic Segmentation under Distributional Shift
May 31, 2021
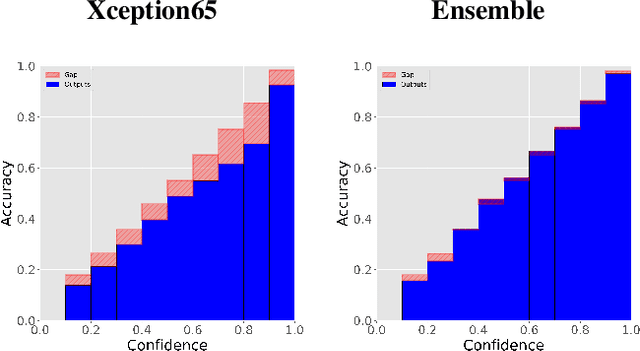
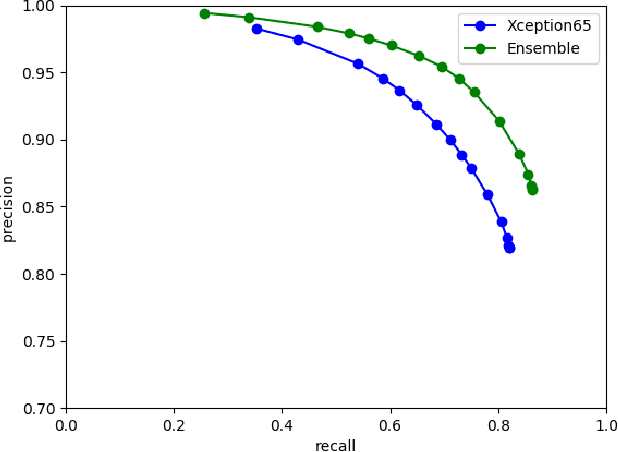

While recent computer vision algorithms achieve impressive performance on many benchmarks, they lack robustness - presented with an image from a different distribution, (e.g. weather or lighting conditions not considered during training), they may produce an erroneous prediction. Therefore, it is desired that such a model will be able to reliably predict its confidence measure. In this work, uncertainty estimation for the task of semantic segmentation is evaluated under a varying level of domain shift: in a cross-dataset setting and when adapting a model trained on data from the simulation. It was shown that simple color transformations already provide a strong baseline, comparable to using more sophisticated style-transfer data augmentation. Further, by constructing an ensemble consisting of models using different backbones and/or augmentation methods, it was possible to improve significantly model performance in terms of overall accuracy and uncertainty estimation under the domain shift setting. The Expected Calibration Error (ECE) on challenging GTA to Cityscapes adaptation was reduced from 4.05 to the competitive value of 1.1. Further, an ensemble of models was utilized in the self-training setting to improve the pseudo-labels generation, which resulted in a significant gain in the final model accuracy, compared to the standard fine-tuning (without ensemble).
Influence of Image Classification Accuracy on Saliency Map Estimation
Jul 27, 2018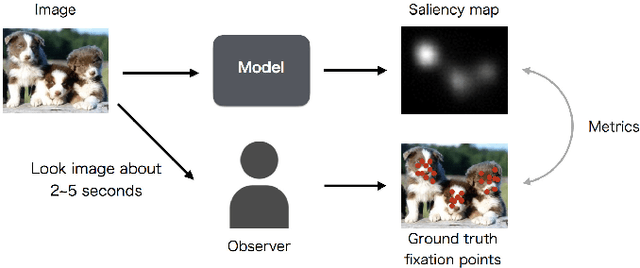
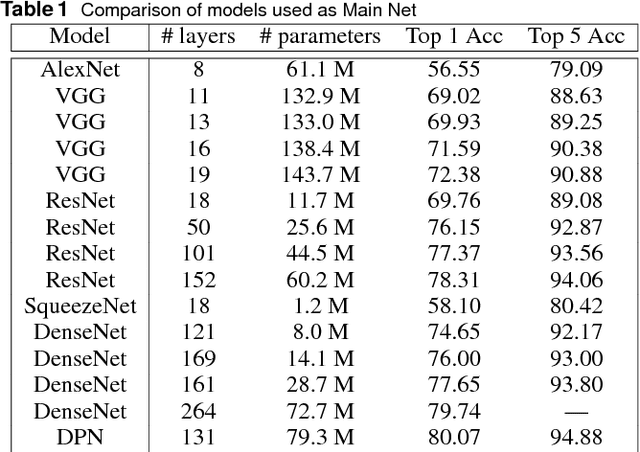
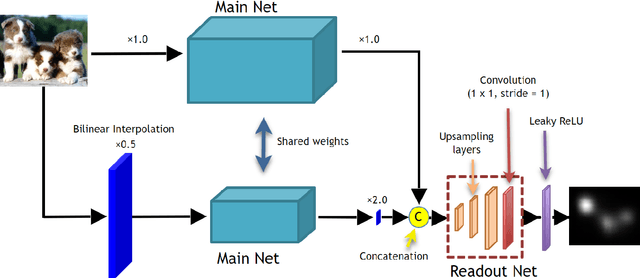
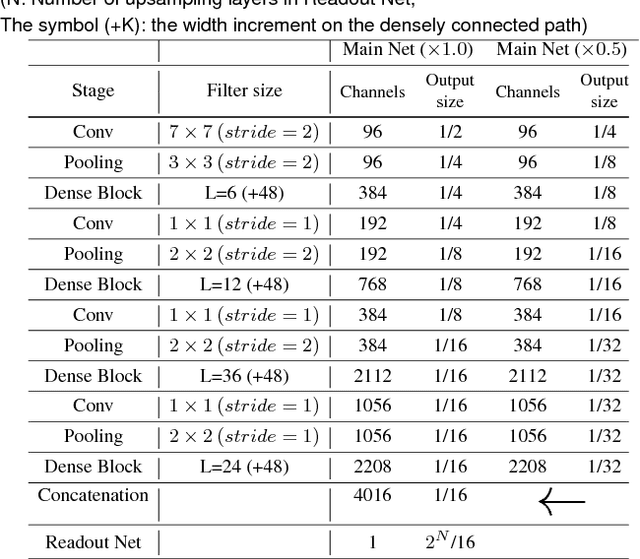
Saliency map estimation in computer vision aims to estimate the locations where people gaze in images. Since people tend to look at objects in images, the parameters of the model pretrained on ImageNet for image classification are useful for the saliency map estimation. However, there is no research on the relationship between the image classification accuracy and the performance of the saliency map estimation. In this paper, it is shown that there is a strong correlation between image classification accuracy and saliency map estimation accuracy. We also investigated the effective architecture based on multi scale images and the upsampling layers to refine the saliency-map resolution. Our model achieved the state-of-the-art accuracy on the PASCAL-S, OSIE, and MIT1003 datasets. In the MIT Saliency Benchmark, our model achieved the best performance in some metrics and competitive results in the other metrics.
Quantum Algorithms for Data Representation and Analysis
Apr 19, 2021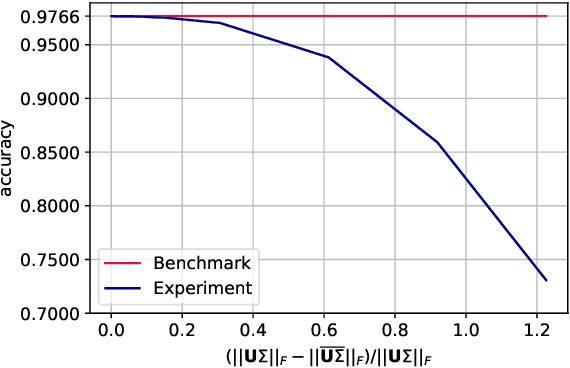
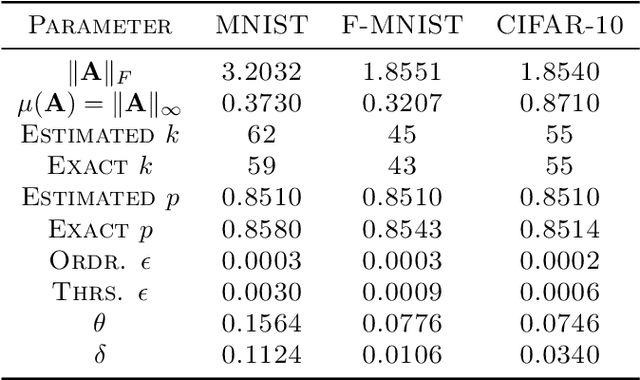
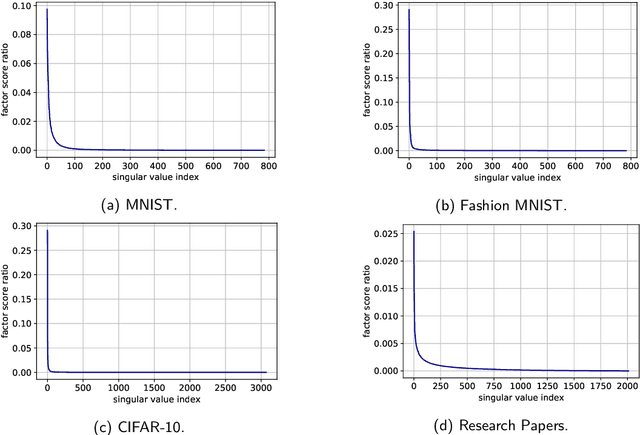
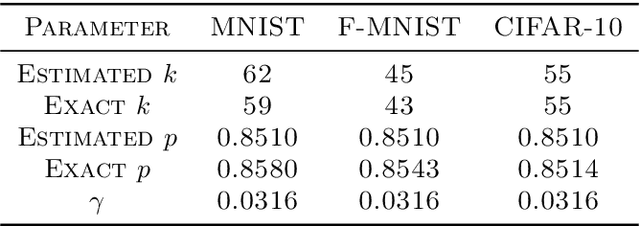
We narrow the gap between previous literature on quantum linear algebra and useful data analysis on a quantum computer, providing quantum procedures that speed-up the solution of eigenproblems for data representation in machine learning. The power and practical use of these subroutines is shown through new quantum algorithms, sublinear in the input matrix's size, for principal component analysis, correspondence analysis, and latent semantic analysis. We provide a theoretical analysis of the run-time and prove tight bounds on the randomized algorithms' error. We run experiments on multiple datasets, simulating PCA's dimensionality reduction for image classification with the novel routines. The results show that the run-time parameters that do not depend on the input's size are reasonable and that the error on the computed model is small, allowing for competitive classification performances.
MOS: Towards Scaling Out-of-distribution Detection for Large Semantic Space
May 05, 2021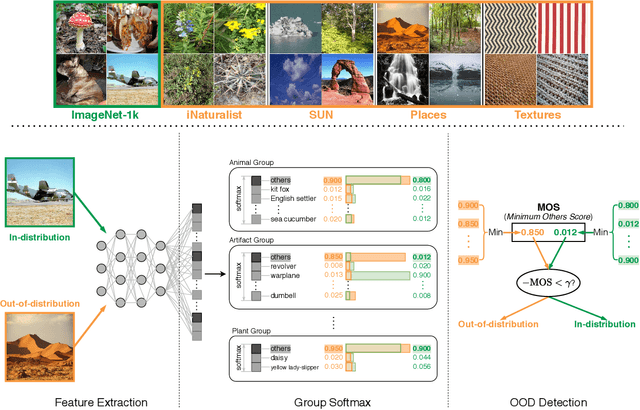
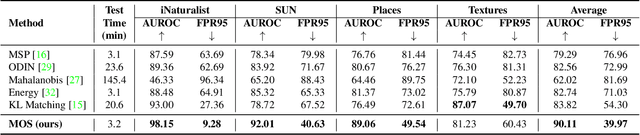
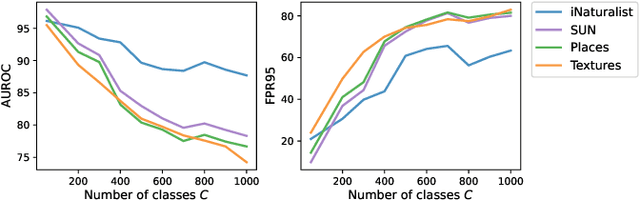
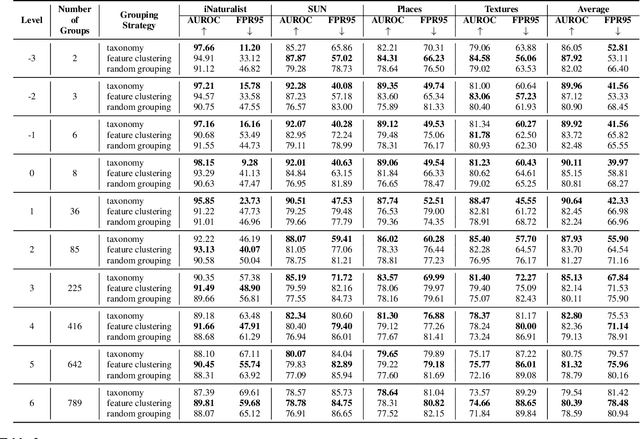
Detecting out-of-distribution (OOD) inputs is a central challenge for safely deploying machine learning models in the real world. Existing solutions are mainly driven by small datasets, with low resolution and very few class labels (e.g., CIFAR). As a result, OOD detection for large-scale image classification tasks remains largely unexplored. In this paper, we bridge this critical gap by proposing a group-based OOD detection framework, along with a novel OOD scoring function termed MOS. Our key idea is to decompose the large semantic space into smaller groups with similar concepts, which allows simplifying the decision boundaries between in- vs. out-of-distribution data for effective OOD detection. Our method scales substantially better for high-dimensional class space than previous approaches. We evaluate models trained on ImageNet against four carefully curated OOD datasets, spanning diverse semantics. MOS establishes state-of-the-art performance, reducing the average FPR95 by 14.33% while achieving 6x speedup in inference compared to the previous best method.
Image Dehazing using Bilinear Composition Loss Function
Oct 01, 2017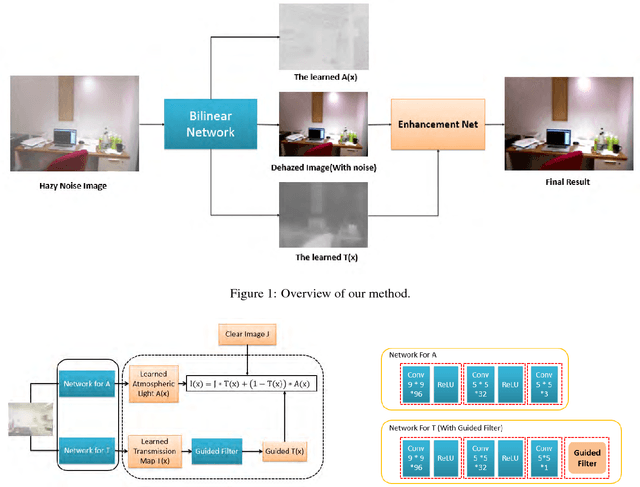



In this paper, we introduce a bilinear composition loss function to address the problem of image dehazing. Previous methods in image dehazing use a two-stage approach which first estimate the transmission map followed by clear image estimation. The drawback of a two-stage method is that it tends to boost local image artifacts such as noise, aliasing and blocking. This is especially the case for heavy haze images captured with a low quality device. Our method is based on convolutional neural networks. Unique in our method is the bilinear composition loss function which directly model the correlations between transmission map, clear image, and atmospheric light. This allows errors to be back-propagated to each sub-network concurrently, while maintaining the composition constraint to avoid overfitting of each sub-network. We evaluate the effectiveness of our proposed method using both synthetic and real world examples. Extensive experiments show that our method outperfoms state-of-the-art methods especially for haze images with severe noise level and compressions.
Scorpion detection and classification systems based on computer vision and deep learning for health security purposes
May 31, 2021
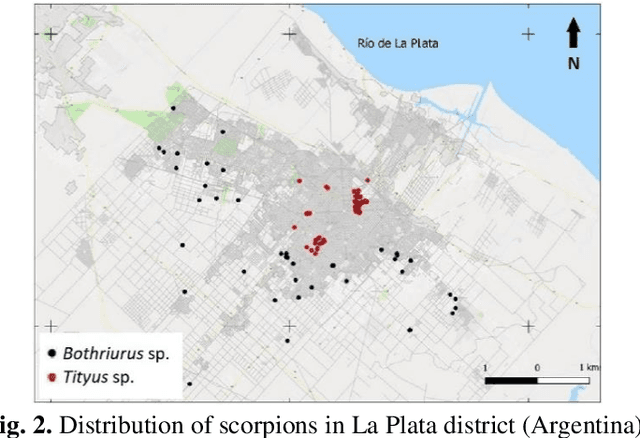
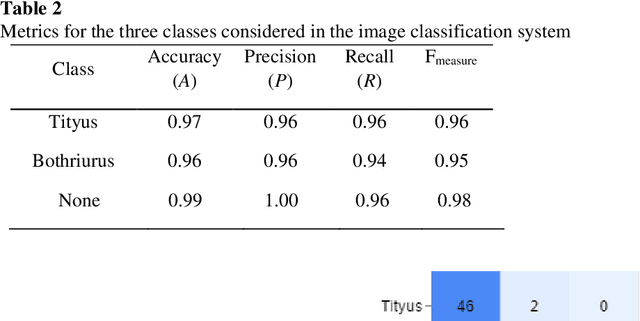
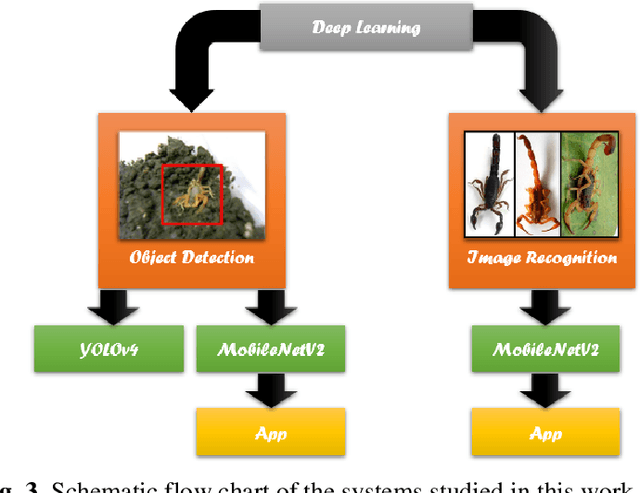
In this paper, two novel automatic and real-time systems for the detection and classification of two genera of scorpions found in La Plata city (Argentina) were developed using computer vision and deep learning techniques. The object detection technique was implemented with two different methods, YOLO (You Only Look Once) and MobileNet, based on the shape features of the scorpions. High accuracy values of 88% and 91%, and high recall values of 90% and 97%, have been achieved for both models, respectively, which guarantees that they can successfully detect scorpions. In addition, the MobileNet method has been shown to have excellent performance to detect scorpions within an uncontrolled environment and to perform multiple detections. The MobileNet model was also used for image classification in order to successfully distinguish between dangerous scorpion (Tityus) and non-dangerous scorpion (Bothriurus) with the purpose of providing a health security tool. Applications for smartphones were developed, with the advantage of the portability of the systems, which can be used as a help tool for emergency services, or for biological research purposes. The developed systems can be easily scalable to other genera and species of scorpions to extend the region where these applications can be used.
Learning Light Field Reconstruction from a Single Coded Image
Apr 26, 2018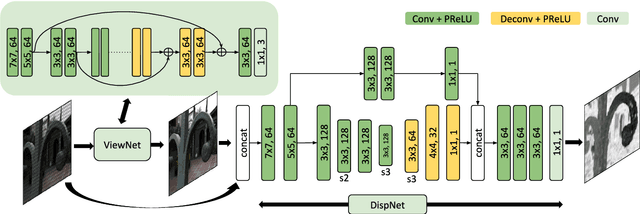



Light field imaging is a rich way of representing the 3D world around us. However, due to limited sensor resolution capturing light field data inherently poses spatio-angular resolution trade-off. In this paper, we propose a deep learning based solution to tackle the resolution trade-off. Specifically, we reconstruct full sensor resolution light field from a single coded image. We propose to do this in three stages 1) reconstruction of center view from the coded image 2) estimating disparity map from the coded image and center view 3) warping center view using the disparity to generate light field. We propose three neural networks for these stages. Our disparity estimation network is trained in an unsupervised manner alleviating the need for ground truth disparity. Our results demonstrate better recovery of parallax from the coded image. Also, we get better results than dictionary learning based approaches both qualitatively and quatitatively.