 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Ancient Painting to Natural Image: A New Solution for Painting Processing
Jan 02, 2019

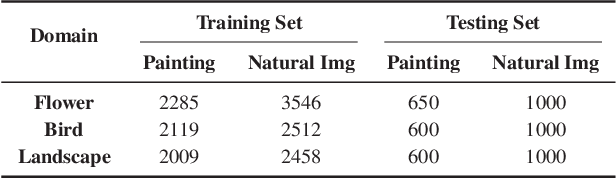

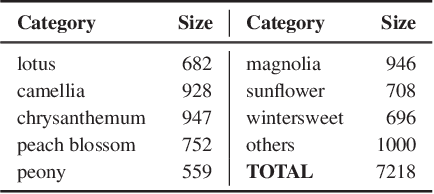
Collecting a large-scale and well-annotated dataset for image processing has become a common practice in computer vision. However, in the ancient painting area, this task is not practical as the number of paintings is limited and their style is greatly diverse. We, therefore, propose a novel solution for the problems that come with ancient painting processing. This is to use domain transfer to convert ancient paintings to photo-realistic natural images. By doing so, the ancient painting processing problems become natural image processing problems and models trained on natural images can be directly applied to the transferred paintings. Specifically, we focus on Chinese ancient flower, bird and landscape paintings in this work. A novel Domain Style Transfer Network (DSTN) is proposed to transfer ancient paintings to natural images which employ a compound loss to ensure that the transferred paintings still maintain the color composition and content of the input paintings. The experiment results show that the transferred paintings generated by the DSTN have a better performance in both the human perceptual test and other image processing tasks than other state-of-art methods, indicating the authenticity of the transferred paintings and the superiority of the proposed method.
Data Discovery Using Lossless Compression-Based Sparse Representation
Mar 17, 2021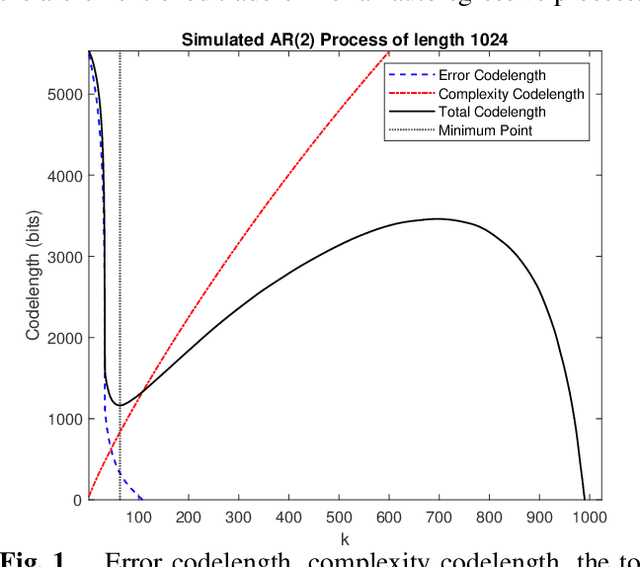
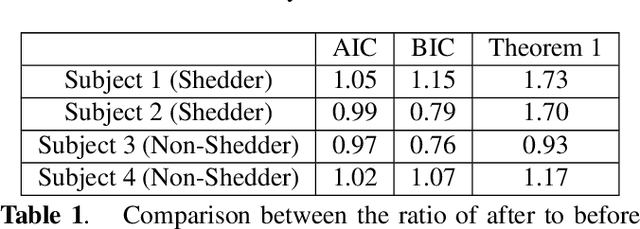
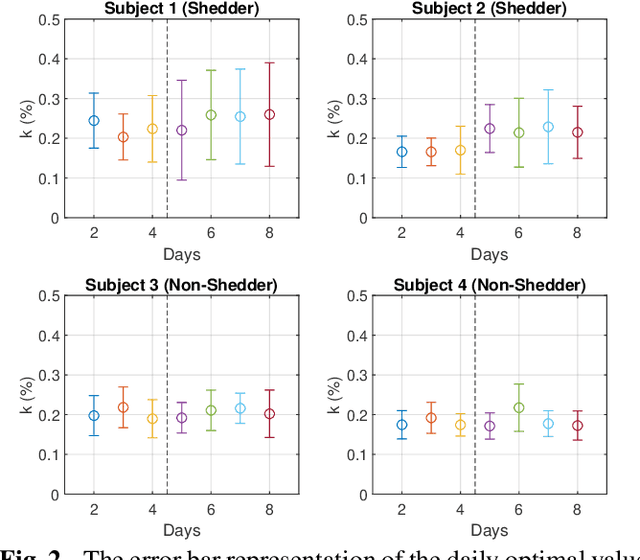
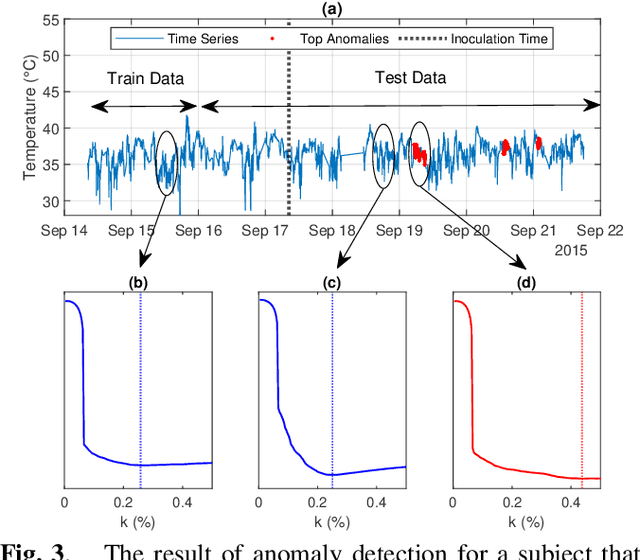
Sparse representation has been widely used in data compression, signal and image denoising, dimensionality reduction and computer vision. While overcomplete dictionaries are required for sparse representation of multidimensional data, orthogonal bases represent one-dimensional data well. In this paper, we propose a data-driven sparse representation using orthonormal bases under the lossless compression constraint. We show that imposing such constraint under the Minimum Description Length (MDL) principle leads to a unique and optimal sparse representation for one-dimensional data, which results in discriminative features useful for data discovery.
Towards Deep Learning-assisted Quantification of Inflammation in Spondyloarthritis: Intensity-based Lesion Segmentation
Jun 21, 2021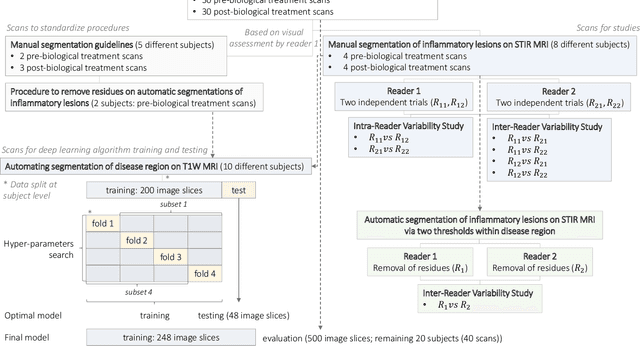
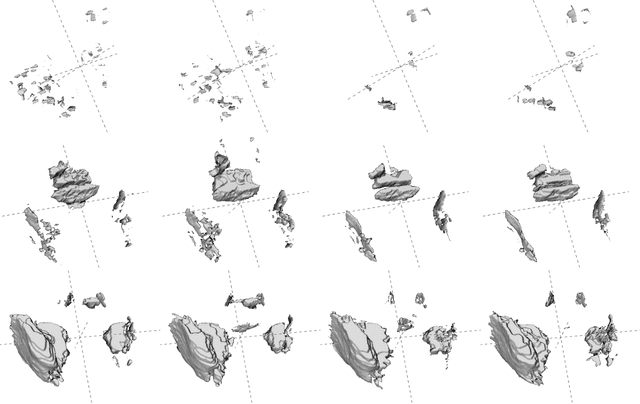
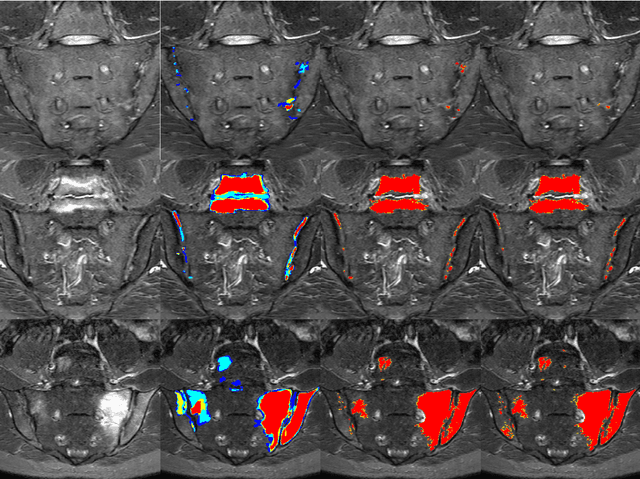
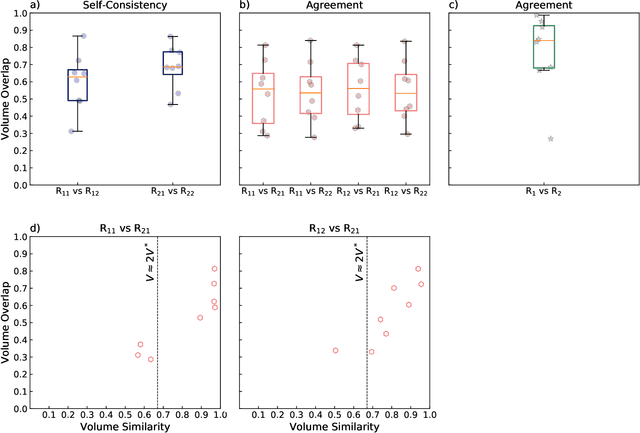
Purpose: To develop a semi-automated, AI-assisted workflow for segmentation of inflammatory lesions on STIR MRI of sacroiliac joints (SIJs) in adult patients with axial spondyloarthritis. Methods: Baseline human performance in manual segmentation of inflammatory lesions was first established in eight patients with axial spondyloarthritis recruited within a prospective study conducted between April 2018 and July 2019. To improve readers' consistency a semi-automated procedure was developed, comprising (1) manual segmentation of 'normal bone' and 'disease' regions (2) automatic segmentation of lesions, i.e., voxels in the disease region with outlying intensity with respect to the normal bone, and (3) human intervention to remove erroneously segmented areas. Segmentation of disease region (subchondral bone) was automated via supervised deep learning; 200 image slices (eight subjects) were used for algorithm training with cross validation, 48 (two subjects) - for testing and 500 (20 subjects) - for evaluation based on visual assessment. The data, code, and model are available at https://github.com/c-hepburn/Bone_MRI. Human and model performance were assessed in terms of Dice coefficient. Results: Intra-reader median Dice coefficients, evaluated from comparison of manual segmentation trials of inflammatory lesions, were 0.63 and 0.69 for the two readers, respectively. Inter-reader median Dice was in the range of 0.53 to 0.56 and increased to 0.84 using the semi-automated approach. Deep learning model ensemble showed average Dice of 0.94 in subchondral bone segmentation. Conclusions: We describe a semi-automated, AI-assisted workflow which improves the objectivity and consistency of radiological segmentation of inflammatory load in SIJs.
Dilated Deep Residual Network for Image Denoising
Sep 27, 2017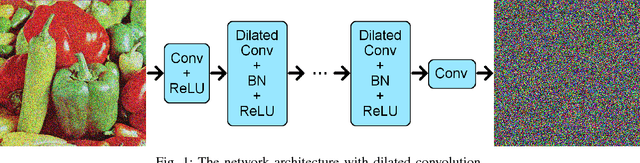
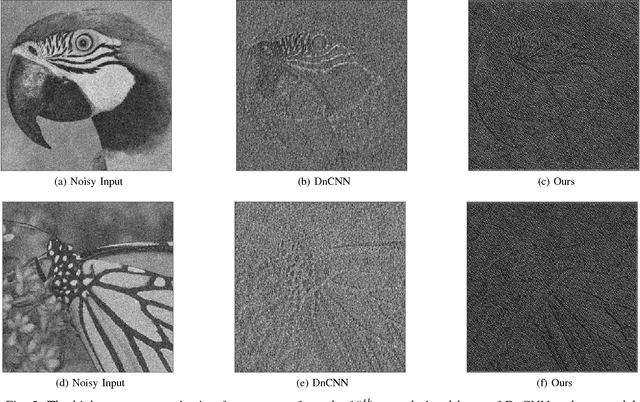


Variations of deep neural networks such as convolutional neural network (CNN) have been successfully applied to image denoising. The goal is to automatically learn a mapping from a noisy image to a clean image given training data consisting of pairs of noisy and clean images. Most existing CNN models for image denoising have many layers. In such cases, the models involve a large amount of parameters and are computationally expensive to train. In this paper, we develop a dilated residual CNN for Gaussian image denoising. Compared with the recently proposed residual denoiser, our method can achieve comparable performance with less computational cost. Specifically, we enlarge receptive field by adopting dilated convolution in residual network, and the dilation factor is set to a certain value. We utilize appropriate zero padding to make the dimension of the output the same as the input. It has been proven that the expansion of receptive field can boost the CNN performance in image classification, and we further demonstrate that it can also lead to competitive performance for denoising problem. Moreover, we present a formula to calculate receptive field size when dilated convolution is incorporated. Thus, the change of receptive field can be interpreted mathematically. To validate the efficacy of our approach, we conduct extensive experiments for both gray and color image denoising with specific or randomized noise levels. Both of the quantitative measurements and the visual results of denoising are promising comparing with state-of-the-art baselines.
Fully automated quantification of in vivo viscoelasticity of prostate zones using magnetic resonance elastography with Dense U-net segmentation
Jun 21, 2021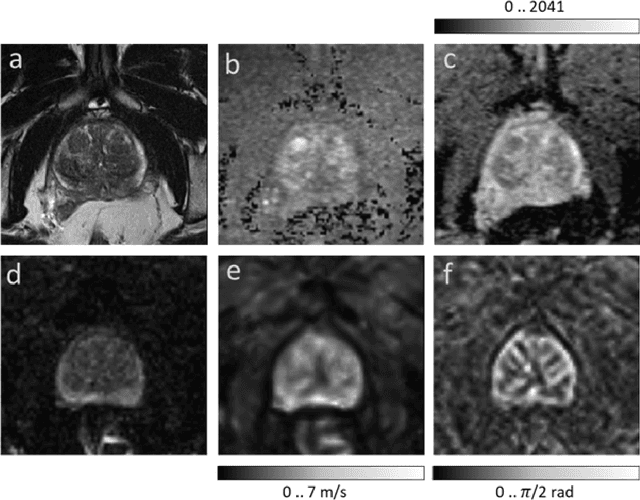

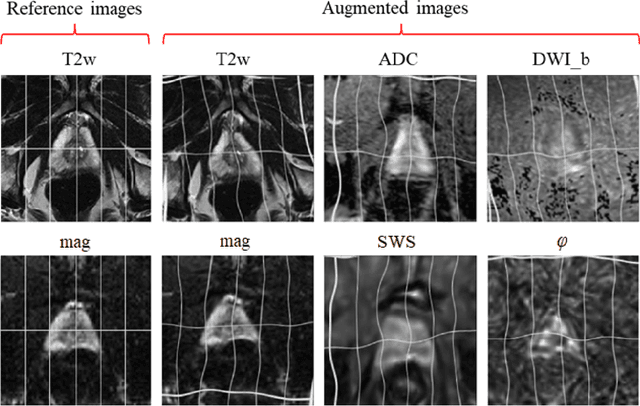
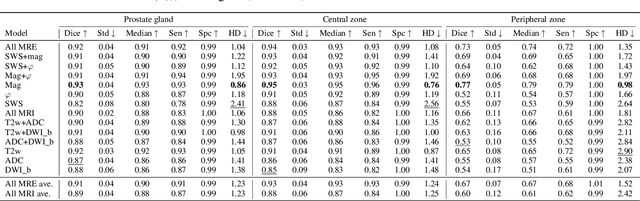
Magnetic resonance elastography (MRE) for measuring viscoelasticity heavily depends on proper tissue segmentation, especially in heterogeneous organs such as the prostate. Using trained network-based image segmentation, we investigated if MRE data suffice to extract anatomical and viscoelastic information for automatic tabulation of zonal mechanical properties of the prostate. Overall, 40 patients with benign prostatic hyperplasia (BPH) or prostate cancer (PCa) were examined with three magnetic resonance imaging (MRI) sequences: T2-weighted MRI (T2w), diffusion-weighted imaging (DWI), and MRE-based tomoelastography yielding six independent sets of imaging data per patient (T2w, DWI, apparent diffusion coefficient (ADC), MRE magnitude, shear wave speed, and loss angle maps). Combinations of these data were used to train Dense U-nets with manually segmented masks of the entire prostate gland (PG), central zone (CZ), and peripheral zone (PZ) in 30 patients and to validate them in 10 patients. Dice score (DS), sensitivity, specificity, and Hausdorff distance were determined. We found that segmentation based on MRE magnitude maps alone (DS, PG: 0.93$\pm$0.04, CZ: 0.95$\pm$0.03, PZ: 0.77$\pm$0.05) was more accurate than magnitude maps combined with T2w and DWI_b (DS, PG: 0.91$\pm$0.04, CZ: 0.91$\pm$0.06, PZ: 0.63$\pm$0.16) or T2w alone (DS, PG: 0.92$\pm$0.03, CZ: 0.91$\pm$0.04, PZ: 0.65$\pm$0.08). Automatically tabulated MRE values were not different from ground-truth values (P>0.05). In conclusion: MRE combined with Dense U-net segmentation allows tabulation of quantitative imaging markers without manual analysis and independent of other MRI sequences and can thus contribute to PCa detection and classification.
Weakly Supervised Complementary Parts Models for Fine-Grained Image Classification from the Bottom Up
Mar 07, 2019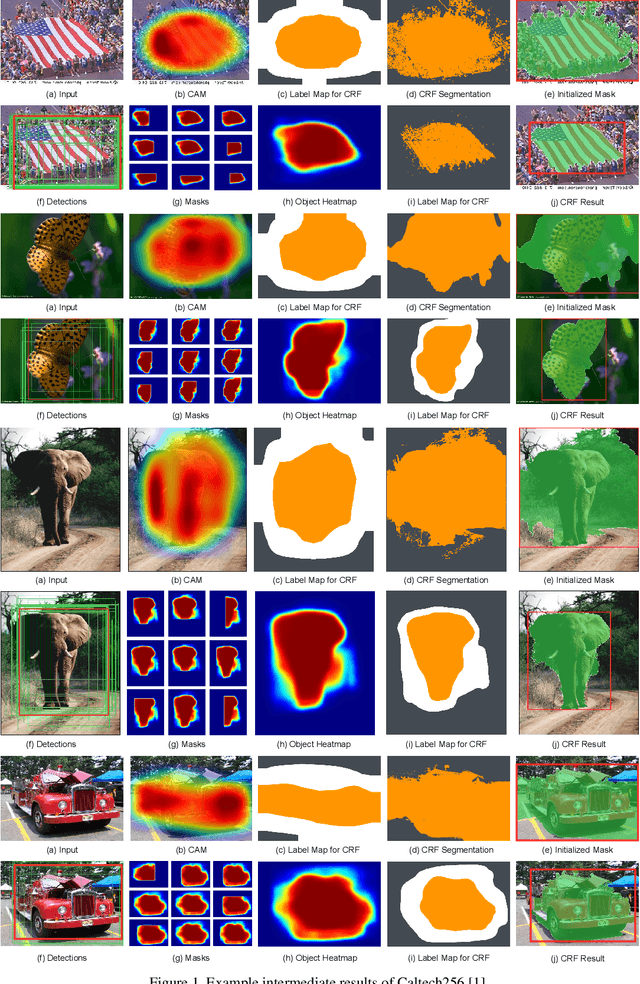

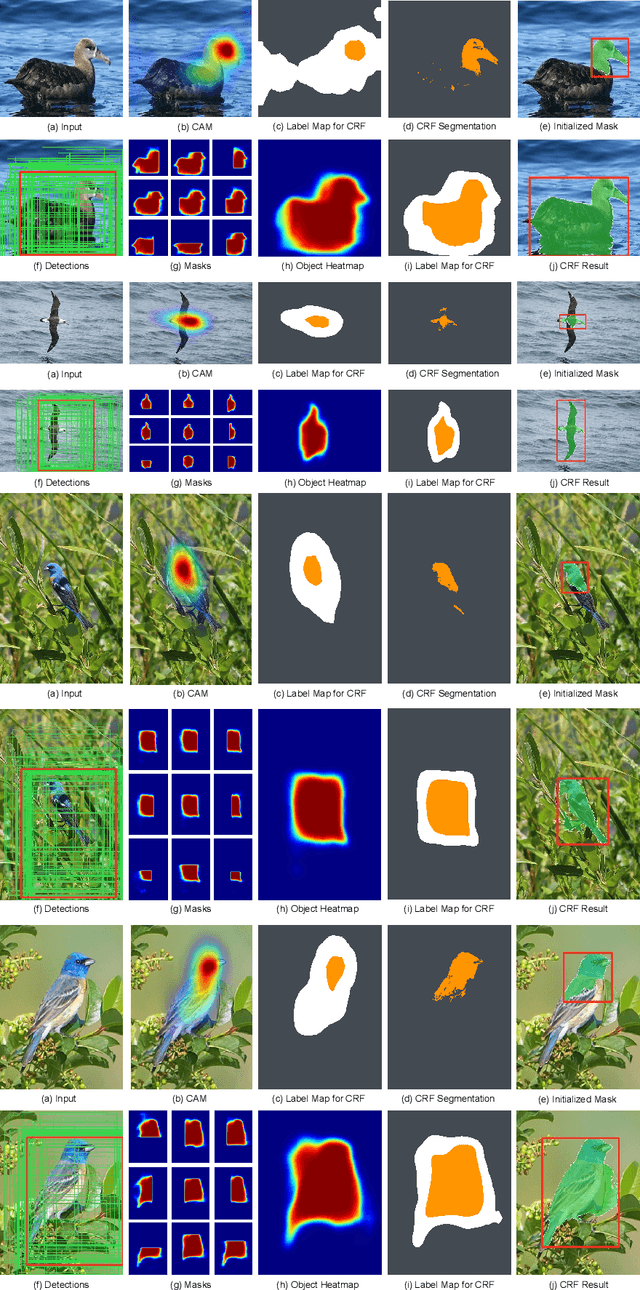
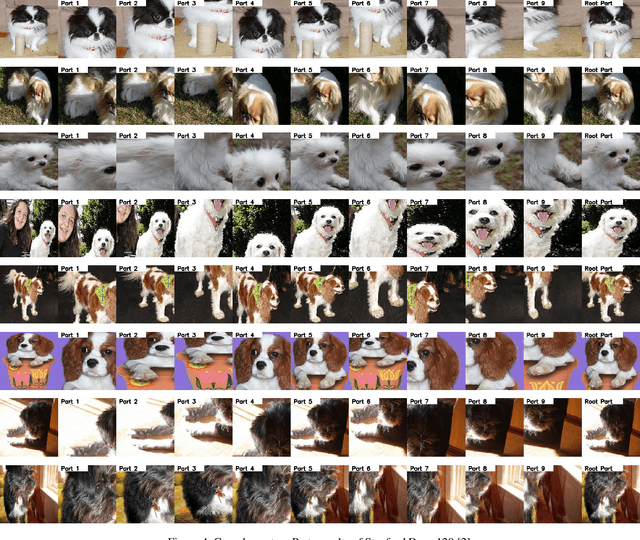
Given a training dataset composed of images and corresponding category labels, deep convolutional neural networks show a strong ability in mining discriminative parts for image classification. However, deep convolutional neural networks trained with image level labels only tend to focus on the most discriminative parts while missing other object parts, which could provide complementary information. In this paper, we approach this problem from a different perspective. We build complementary parts models in a weakly supervised manner to retrieve information suppressed by dominant object parts detected by convolutional neural networks. Given image level labels only, we first extract rough object instances by performing weakly supervised object detection and instance segmentation using Mask R-CNN and CRF-based segmentation. Then we estimate and search for the best parts model for each object instance under the principle of preserving as much diversity as possible. In the last stage, we build a bi-directional long short-term memory (LSTM) network to fuze and encode the partial information of these complementary parts into a comprehensive feature for image classification. Experimental results indicate that the proposed method not only achieves significant improvement over our baseline models, but also outperforms state-of-the-art algorithms by a large margin (6.7%, 2.8%, 5.2% respectively) on Stanford Dogs 120, Caltech-UCSD Birds 2011-200 and Caltech 256.
RadioNet: Transformer based Radio Map Prediction Model For Dense Urban Environments
May 15, 2021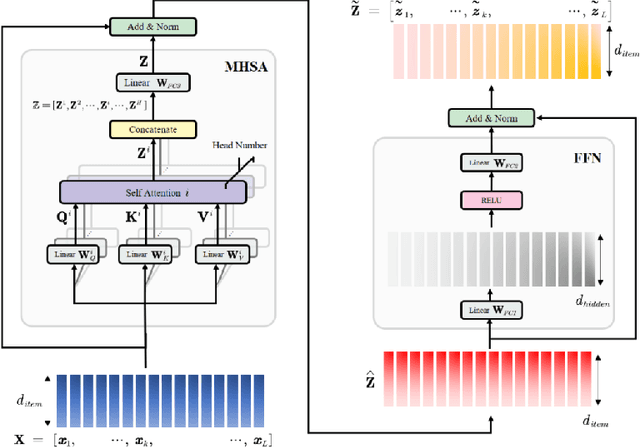
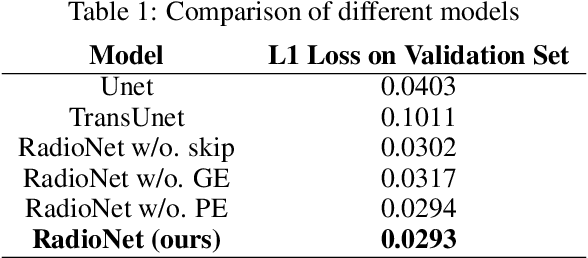
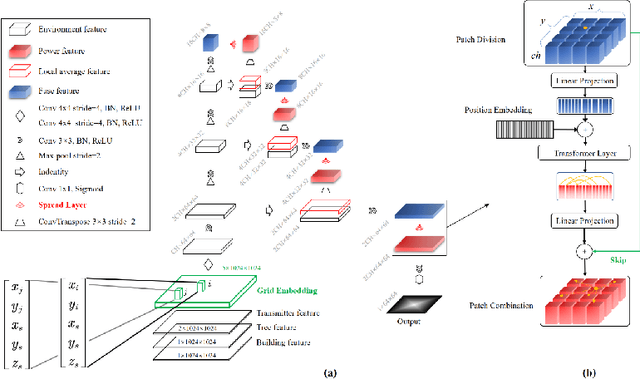

Radio Map Prediction (RMP), aiming at estimating coverage of radio wave, has been widely recognized as an enabling technology for improving radio spectrum efficiency. However, fast and reliable radio map prediction can be very challenging due to the complicated interaction between radio waves and the environment. In this paper, a novel Transformer based deep learning model termed as RadioNet is proposed for radio map prediction in urban scenarios. In addition, a novel Grid Embedding technique is proposed to substitute the original Position Embedding in Transformer to better anchor the relative position of the radiation source, destination and environment. The effectiveness of proposed method is verified on an urban radio wave propagation dataset. Compared with the SOTA model on RMP task, RadioNet reduces the validation loss by 27.3\%, improves the prediction reliability from 90.9\% to 98.9\%. The prediction speed is increased by 4 orders of magnitude, when compared with ray-tracing based method. We believe that the proposed method will be beneficial to high-efficiency wireless communication, real-time radio visualization, and even high-speed image rendering.
Demystifying Local Vision Transformer: Sparse Connectivity, Weight Sharing, and Dynamic Weight
Jun 08, 2021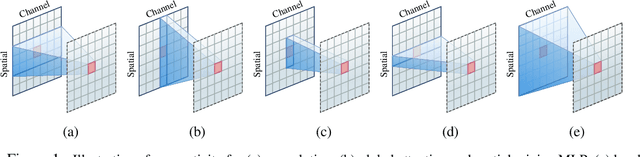
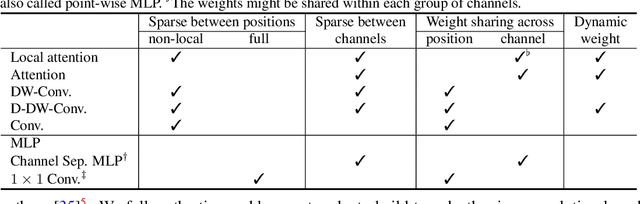
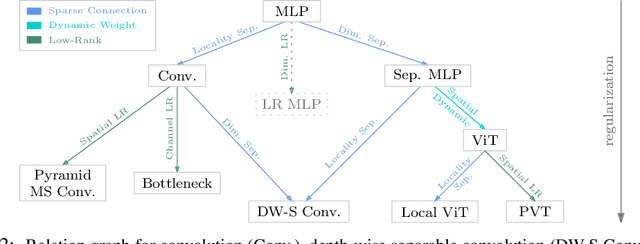
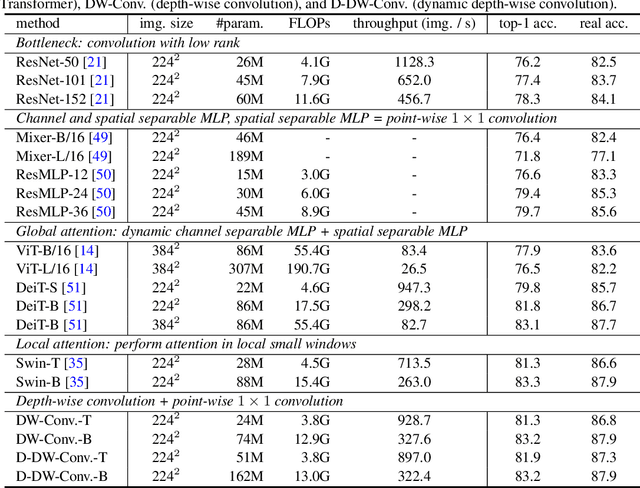
Vision Transformer (ViT) attains state-of-the-art performance in visual recognition, and the variant, Local Vision Transformer, makes further improvements. The major component in Local Vision Transformer, local attention, performs the attention separately over small local windows. We rephrase local attention as a channel-wise locally-connected layer and analyze it from two network regularization manners, sparse connectivity and weight sharing, as well as weight computation. Sparse connectivity: there is no connection across channels, and each position is connected to the positions within a small local window. Weight sharing: the connection weights for one position are shared across channels or within each group of channels. Dynamic weight: the connection weights are dynamically predicted according to each image instance. We point out that local attention resembles depth-wise convolution and its dynamic version in sparse connectivity. The main difference lies in weight sharing - depth-wise convolution shares connection weights (kernel weights) across spatial positions. We empirically observe that the models based on depth-wise convolution and the dynamic variant with lower computation complexity perform on-par with or sometimes slightly better than Swin Transformer, an instance of Local Vision Transformer, for ImageNet classification, COCO object detection and ADE semantic segmentation. These observations suggest that Local Vision Transformer takes advantage of two regularization forms and dynamic weight to increase the network capacity.
Specular reflections removal in colposcopic images based on neural networks: Supervised training with no ground truth previous knowledge
Jun 21, 2021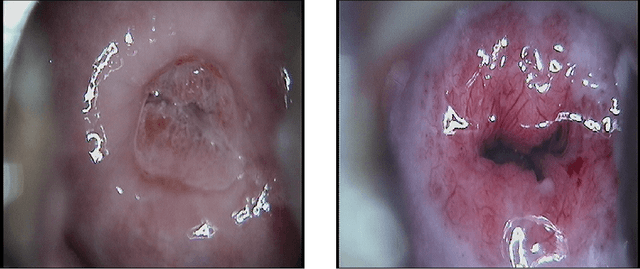
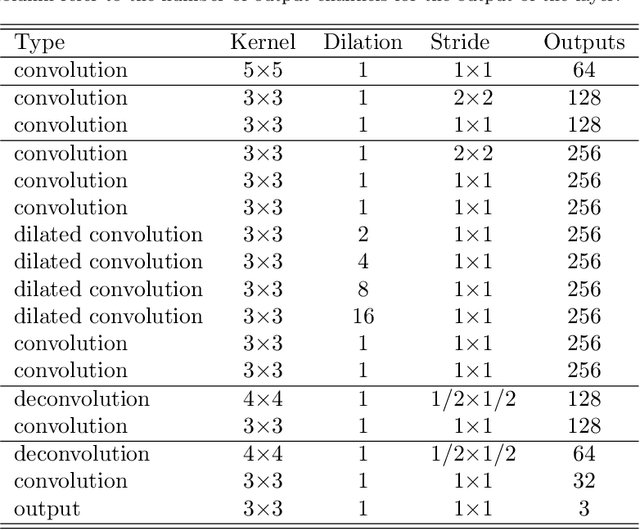
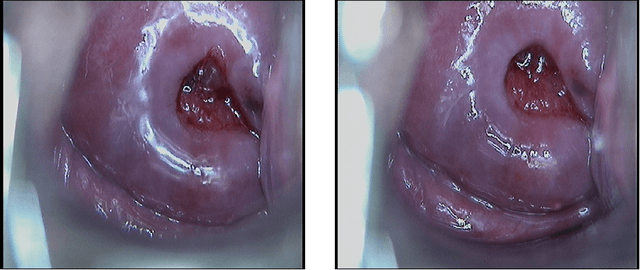
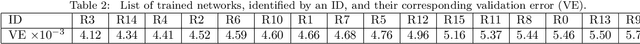
Cervical cancer is a malignant tumor that seriously threatens women's health, and is one of the most common that affects women worldwide. For its early detection, colposcopic images of the cervix are used for searching for possible injuries or abnormalities. An inherent characteristic of these images is the presence of specular reflections (brightness) that make it difficult to observe some regions, which might imply misdiagnosis. In this paper, a new strategy based on neural networks is introduced for eliminating specular reflections and estimating the unobserved anatomical cervix portion under the bright zones. For overcoming the fact that the ground truth corresponding to the specular reflection regions is always unknown, the new strategy proposes the supervised training of a neural network to learn how to restore any hidden regions of colposcopic images. Once the specular reflections are identified, they are removed from the image, and the previously trained network is used to fulfill these deleted areas. The quality of the processed images was evaluated quantitatively and qualitatively. In 21 of the 22 evaluated images, the detected specular reflections were eliminated, whereas, in the remaining one, these reflections were almost completely eliminated. The distribution of the colors and the content of the restored images are similar to those of the originals. The evaluation carried out by a specialist in Cervix Pathology concluded that, after eliminating the specular reflections, the anatomical and physiological elements of the cervix are observable in the restored images, which facilitates the medical diagnosis of cervical pathologies. Our method has the potential to improve the early detection of cervical cancer.
Transformer-based Methods for Recognizing Ultra Fine-grained Entities (RUFES)
Apr 13, 2021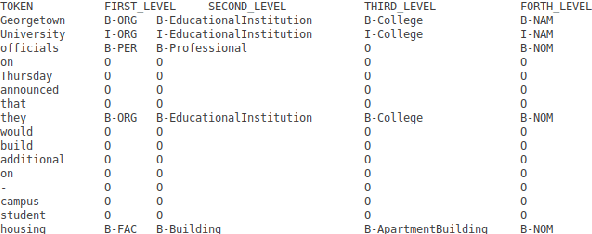
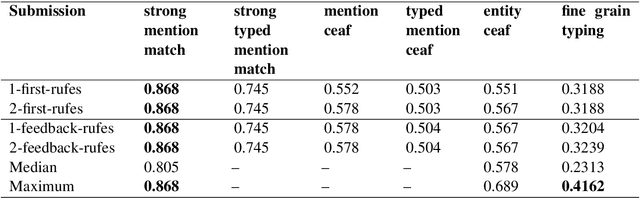
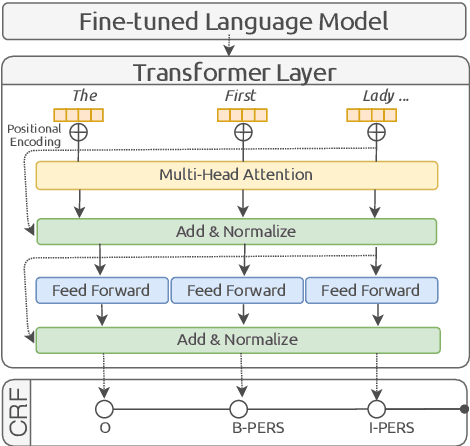
This paper summarizes the participation of the Laboratoire Informatique, Image et Interaction (L3i laboratory) of the University of La Rochelle in the Recognizing Ultra Fine-grained Entities (RUFES) track within the Text Analysis Conference (TAC) series of evaluation workshops. Our participation relies on two neural-based models, one based on a pre-trained and fine-tuned language model with a stack of Transformer layers for fine-grained entity extraction and one out-of-the-box model for within-document entity coreference. We observe that our approach has great potential in increasing the performance of fine-grained entity recognition. Thus, the future work envisioned is to enhance the ability of the models following additional experiments and a deeper analysis of the results.