 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Deep Continuous Fusion for Multi-Sensor 3D Object Detection
Dec 20, 2020
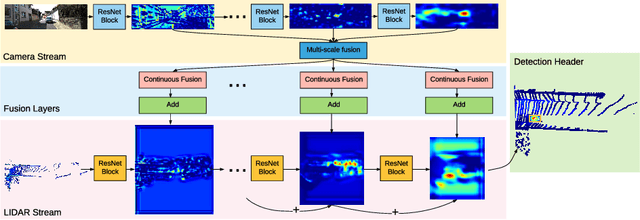
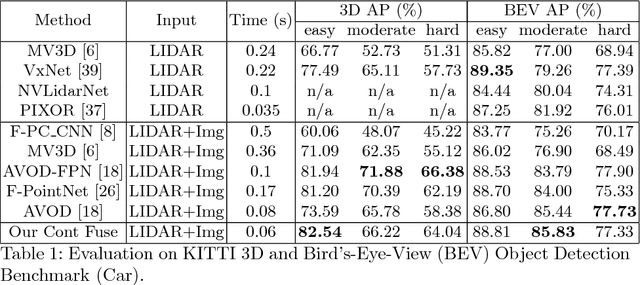
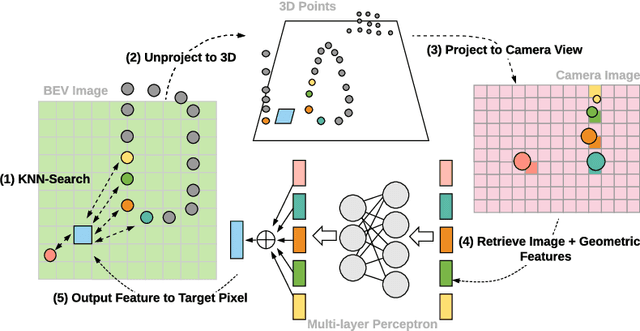
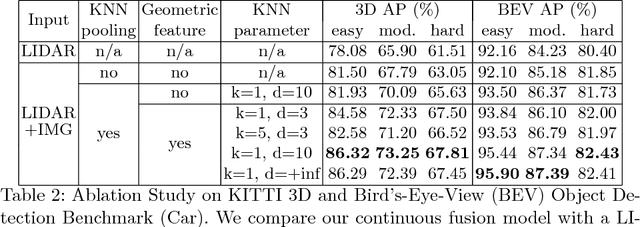
In this paper, we propose a novel 3D object detector that can exploit both LIDAR as well as cameras to perform very accurate localization. Towards this goal, we design an end-to-end learnable architecture that exploits continuous convolutions to fuse image and LIDAR feature maps at different levels of resolution. Our proposed continuous fusion layer encode both discrete-state image features as well as continuous geometric information. This enables us to design a novel, reliable and efficient end-to-end learnable 3D object detector based on multiple sensors. Our experimental evaluation on both KITTI as well as a large scale 3D object detection benchmark shows significant improvements over the state of the art.
CMUA-Watermark: A Cross-Model Universal Adversarial Watermark for Combating Deepfakes
May 23, 2021

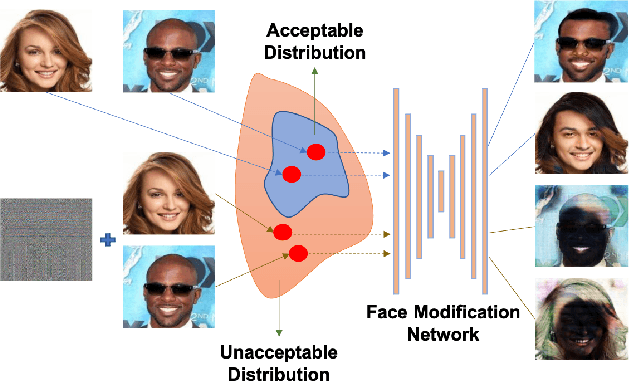

Malicious application of deepfakes (i.e., technologies can generate target faces or face attributes) has posed a huge threat to our society. The fake multimedia content generated by deepfake models can harm the reputation and even threaten the property of the person who has been impersonated. Fortunately, the adversarial watermark could be used for combating deepfake models, leading them to generate distorted images. The existing methods require an individual training process for every facial image, to generate the adversarial watermark against a specific deepfake model, which are extremely inefficient. To address this problem, we propose a universal adversarial attack method on deepfake models, to generate a Cross-Model Universal Adversarial Watermark (CMUA-Watermark) that can protect thousands of facial images from multiple deepfake models. Specifically, we first propose a cross-model universal attack pipeline by attacking multiple deepfake models and combining gradients from these models iteratively. Then we introduce a batch-based method to alleviate the conflict of adversarial watermarks generated by different facial images. Finally, we design a more reasonable and comprehensive evaluation method for evaluating the effectiveness of the adversarial watermark. Experimental results demonstrate that the proposed CMUA-Watermark can effectively distort the fake facial images generated by deepfake models and successfully protect facial images from deepfakes in real scenes.
Collage Inference: Achieving low tail latency during distributed image classification using coded redundancy models
Jun 05, 2019
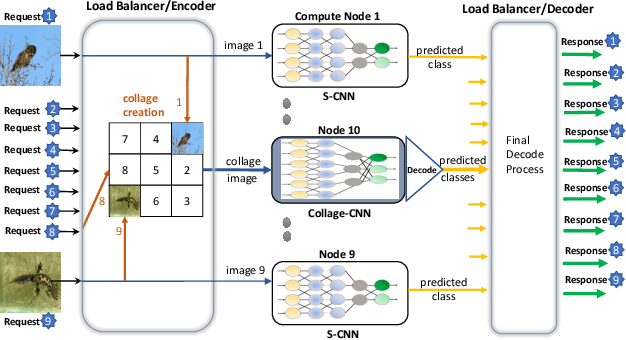
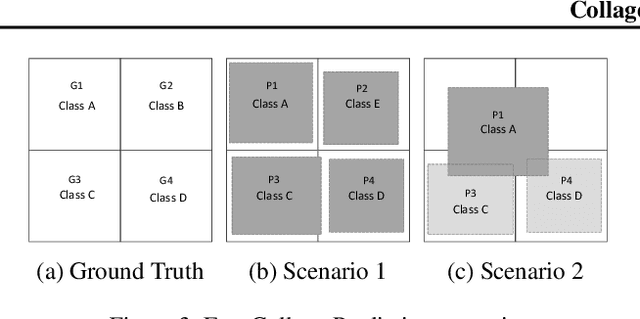
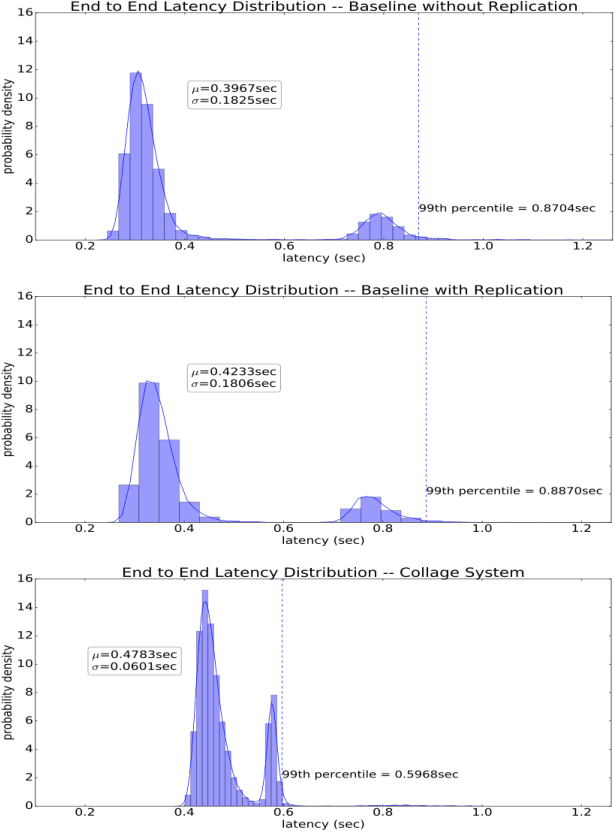
Reducing the latency variance in machine learning inference is a key requirement in many applications. Variance is harder to control in a cloud deployment in the presence of stragglers. In spite of this challenge, inference is increasingly being done in the cloud, due to the advent of affordable machine learning as a service (MLaaS) platforms. Existing approaches to reduce variance rely on replication which is expensive and partially negates the affordability of MLaaS. In this work, we argue that MLaaS platforms also provide unique opportunities to cut the cost of redundancy. In MLaaS platforms, multiple inference requests are concurrently received by a load balancer which can then create a more cost-efficient redundancy coding across a larger collection of images. We propose a novel convolutional neural network model, Collage-CNN, to provide a low-cost redundancy framework. A Collage-CNN model takes a collage formed by combining multiple images and performs multi-image classification in one shot, albeit at slightly lower accuracy. We then augment a collection of traditional single image classifiers with a single Collage-CNN classifier which acts as a low-cost redundant backup. Collage-CNN then provides backup classification results if a single image classification straggles. Deploying the Collage-CNN models in the cloud, we demonstrate that the 99th percentile tail latency of inference can be reduced by 1.47X compared to replication based approaches while providing high accuracy. Also, variation in inference latency can be reduced by 9X with a slight increase in average inference latency.
Boundary-induced and scene-aggregated network for monocular depth prediction
Feb 26, 2021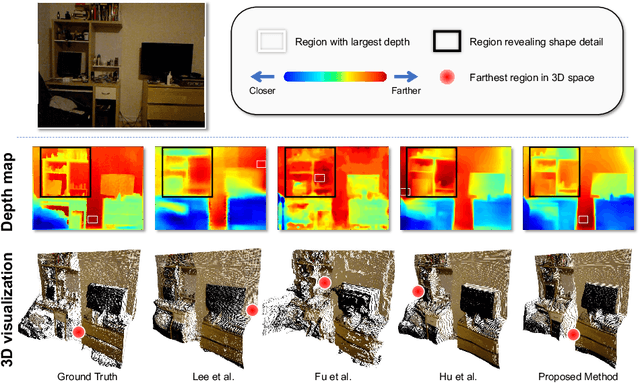
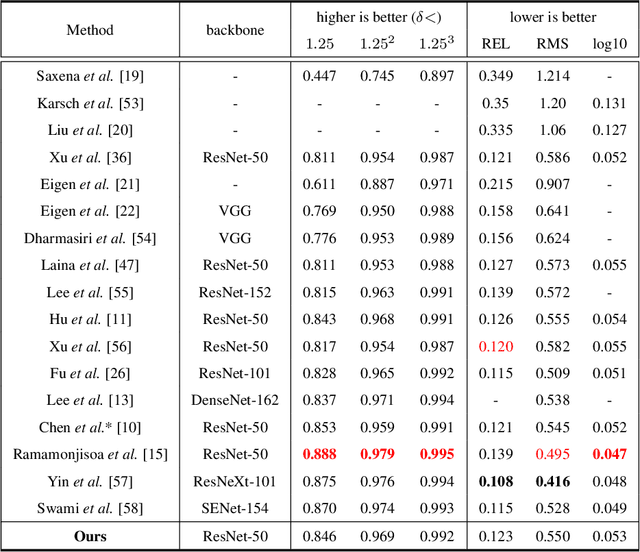
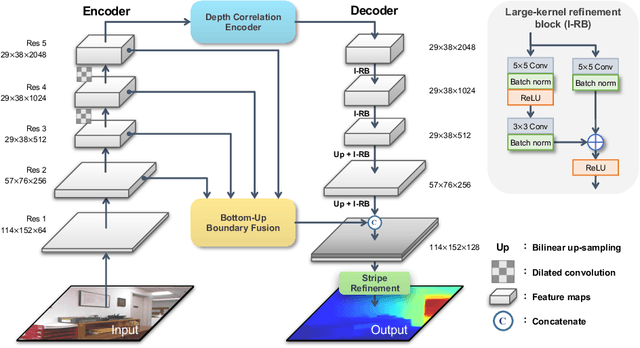
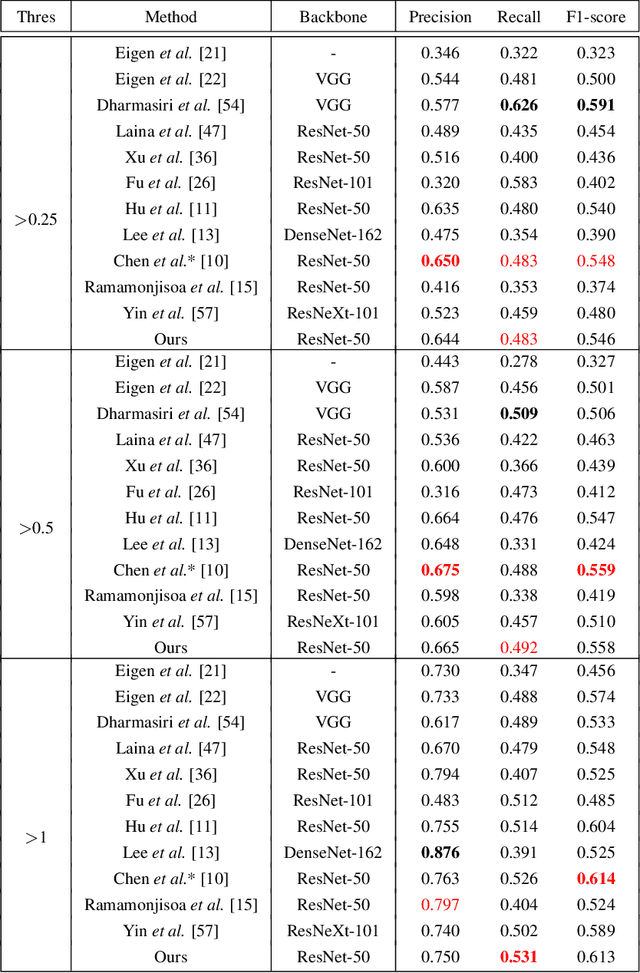
Monocular depth prediction is an important task in scene understanding. It aims to predict the dense depth of a single RGB image. With the development of deep learning, the performance of this task has made great improvements. However, two issues remain unresolved: (1) The deep feature encodes the wrong farthest region in a scene, which leads to a distorted 3D structure of the predicted depth; (2) The low-level features are insufficient utilized, which makes it even harder to estimate the depth near the edge with sudden depth change. To tackle these two issues, we propose the Boundary-induced and Scene-aggregated network (BS-Net). In this network, the Depth Correlation Encoder (DCE) is first designed to obtain the contextual correlations between the regions in an image, and perceive the farthest region by considering the correlations. Meanwhile, the Bottom-Up Boundary Fusion (BUBF) module is designed to extract accurate boundary that indicates depth change. Finally, the Stripe Refinement module (SRM) is designed to refine the dense depth induced by the boundary cue, which improves the boundary accuracy of the predicted depth. Several experimental results on the NYUD v2 dataset and \xff{the iBims-1 dataset} illustrate the state-of-the-art performance of the proposed approach. And the SUN-RGBD dataset is employed to evaluate the generalization of our method. Code is available at https://github.com/XuefengBUPT/BS-Net.
Brain MR Image Segmentation in Small Dataset with Adversarial Defense and Task Reorganization
Jun 25, 2019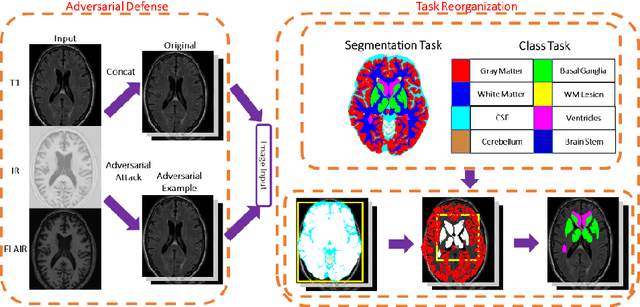
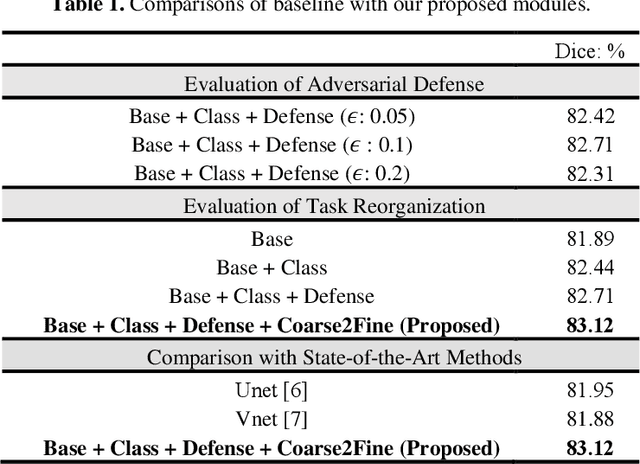
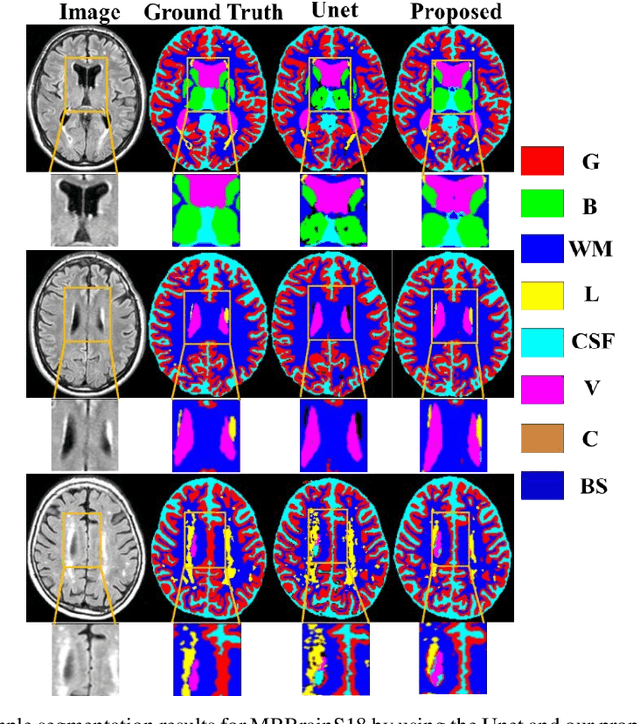
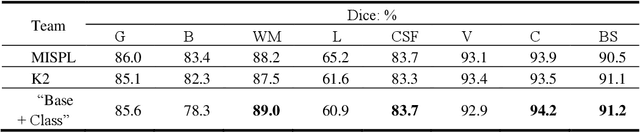
Medical image segmentation is challenging especially in dealing with small dataset of 3D MR images. Encoding the variation of brain anatomical struc-tures from individual subjects cannot be easily achieved, which is further chal-lenged by only a limited number of well labeled subjects for training. In this study, we aim to address the issue of brain MR image segmentation in small da-taset. First, concerning the limited number of training images, we adopt adver-sarial defense to augment the training data and therefore increase the robustness of the network. Second, inspired by the prior knowledge of neural anatomies, we reorganize the segmentation tasks of different regions into several groups in a hierarchical way. Third, the task reorganization extends to the semantic level, as we incorporate an additional object-level classification task to contribute high-order visual features toward the pixel-level segmentation task. In experiments we validate our method by segmenting gray matter, white matter, and several major regions on a challenge dataset. The proposed method with only seven subjects for training can achieve 84.46% of Dice score in the onsite test set.
The joint role of geometry and illumination on material recognition
Jan 07, 2021



Observing and recognizing materials is a fundamental part of our daily life. Under typical viewing conditions, we are capable of effortlessly identifying the objects that surround us and recognizing the materials they are made of. Nevertheless, understanding the underlying perceptual processes that take place to accurately discern the visual properties of an object is a long-standing problem. In this work, we perform a comprehensive and systematic analysis of how the interplay of geometry, illumination, and their spatial frequencies affects human performance on material recognition tasks. We carry out large-scale behavioral experiments where participants are asked to recognize different reference materials among a pool of candidate samples. In the different experiments, we carefully sample the information in the frequency domain of the stimuli. From our analysis, we find significant first-order interactions between the geometry and the illumination, of both the reference and the candidates. In addition, we observe that simple image statistics and higher-order image histograms do not correlate with human performance. Therefore, we perform a high-level comparison of highly non-linear statistics by training a deep neural network on material recognition tasks. Our results show that such models can accurately classify materials, which suggests that they are capable of defining a meaningful representation of material appearance from labeled proximal image data. Last, we find preliminary evidence that these highly non-linear models and humans may use similar high-level factors for material recognition tasks.
Spectrogram Inpainting for Interactive Generation of Instrument Sounds
Apr 15, 2021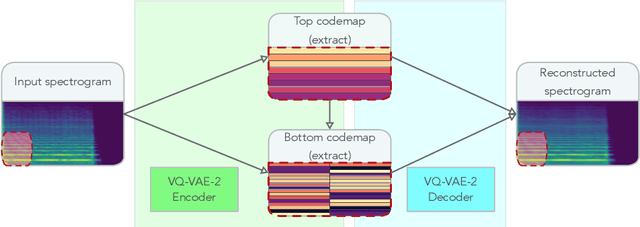
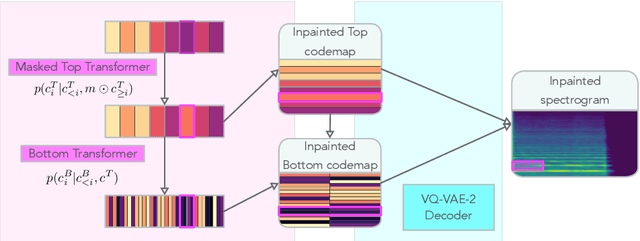
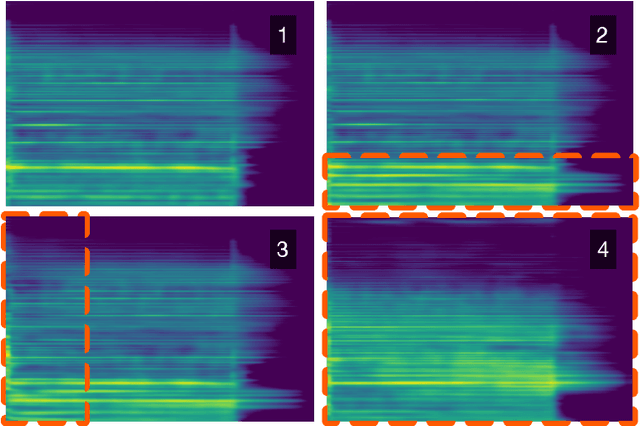
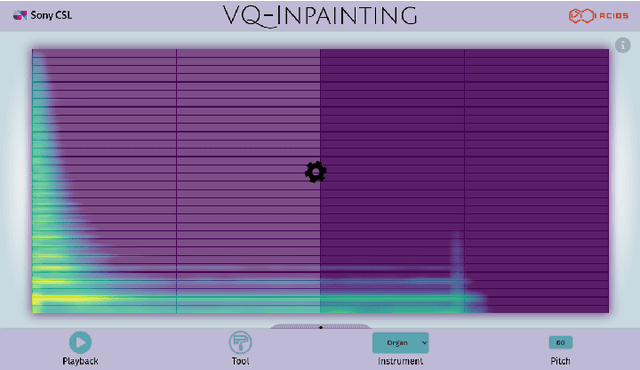
Modern approaches to sound synthesis using deep neural networks are hard to control, especially when fine-grained conditioning information is not available, hindering their adoption by musicians. In this paper, we cast the generation of individual instrumental notes as an inpainting-based task, introducing novel and unique ways to iteratively shape sounds. To this end, we propose a two-step approach: first, we adapt the VQ-VAE-2 image generation architecture to spectrograms in order to convert real-valued spectrograms into compact discrete codemaps, we then implement token-masked Transformers for the inpainting-based generation of these codemaps. We apply the proposed architecture on the NSynth dataset on masked resampling tasks. Most crucially, we open-source an interactive web interface to transform sounds by inpainting, for artists and practitioners alike, opening up to new, creative uses.
* 8 pages + references + appendices. 4 figures. Published as a conference paper at the The 2020 Joint Conference on AI Music Creativity, October 19-23, 2020, organized and hosted virtually by the Royal Institute of Technology (KTH), Stockholm, Sweden
Reservoir Computing based Neural Image Filters
Sep 07, 2018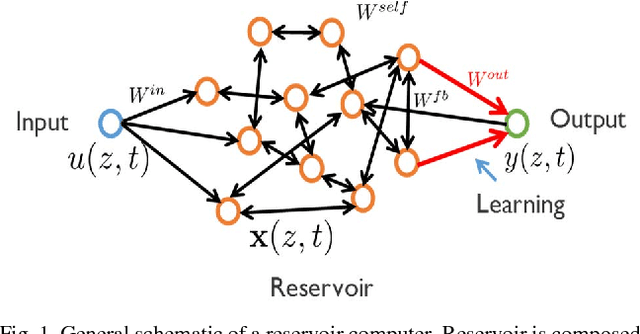
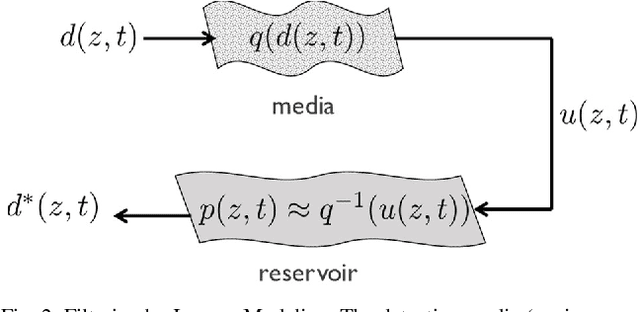

Clean images are an important requirement for machine vision systems to recognize visual features correctly. However, the environment, optics, electronics of the physical imaging systems can introduce extreme distortions and noise in the acquired images. In this work, we explore the use of reservoir computing, a dynamical neural network model inspired from biological systems, in creating dynamic image filtering systems that extracts signal from noise using inverse modeling. We discuss the possibility of implementing these networks in hardware close to the sensors.
RankSRGAN: Generative Adversarial Networks with Ranker for Image Super-Resolution
Aug 26, 2019
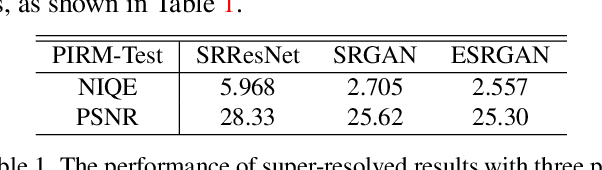
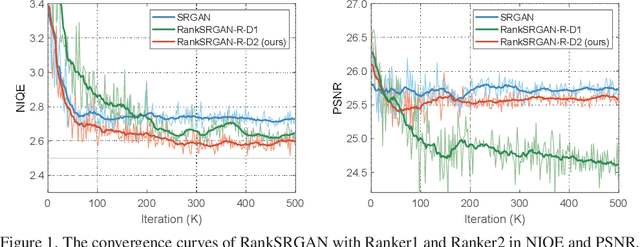
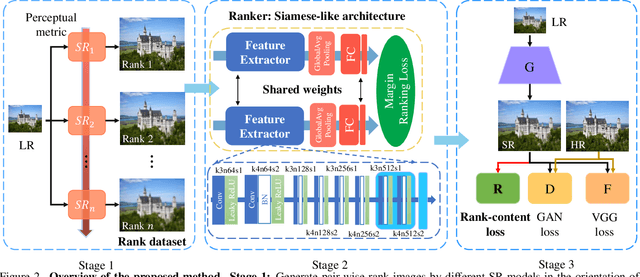
Generative Adversarial Networks (GAN) have demonstrated the potential to recover realistic details for single image super-resolution (SISR). To further improve the visual quality of super-resolved results, PIRM2018-SR Challenge employed perceptual metrics to assess the perceptual quality, such as PI, NIQE, and Ma. However, existing methods cannot directly optimize these indifferentiable perceptual metrics, which are shown to be highly correlated with human ratings. To address the problem, we propose Super-Resolution Generative Adversarial Networks with Ranker (RankSRGAN) to optimize generator in the direction of perceptual metrics. Specifically, we first train a Ranker which can learn the behavior of perceptual metrics and then introduce a novel rank-content loss to optimize the perceptual quality. The most appealing part is that the proposed method can combine the strengths of different SR methods to generate better results. Extensive experiments show that RankSRGAN achieves visually pleasing results and reaches state-of-the-art performance in perceptual metrics. Project page: https://wenlongzhang0724.github.io/Projects/RankSRGAN
LEAN: graph-based pruning for convolutional neural networks by extracting longest chains
Nov 13, 2020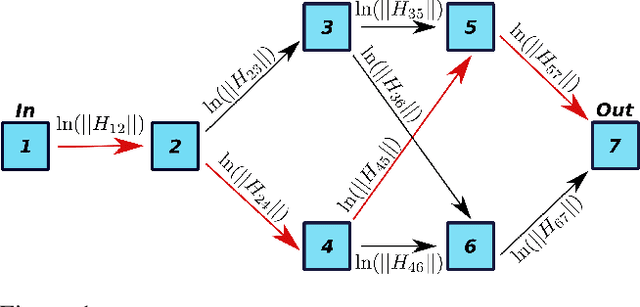
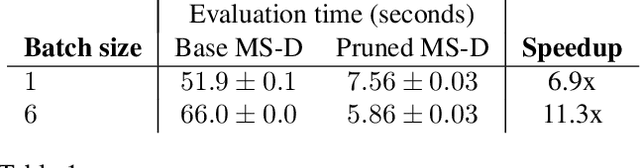
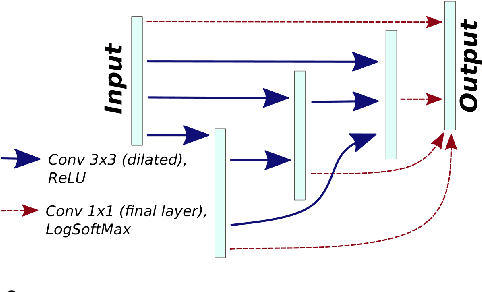
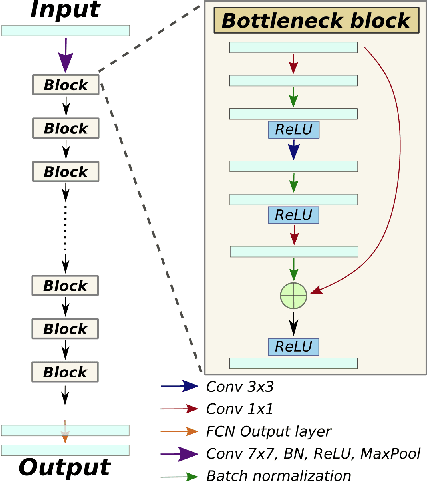
Convolutional neural networks (CNNs) have proven to be highly successful at a range of image-to-image tasks. CNNs can be computationally expensive, which can limit their applicability in practice. Model pruning can improve computational efficiency by sparsifying trained networks. Common methods for pruning CNNs determine what convolutional filters to remove by ranking filters on an individual basis. However, filters are not independent, as CNNs consist of chains of convolutions, which can result in sub-optimal filter selection. We propose a novel pruning method, LongEst-chAiN (LEAN) pruning, which takes the interdependency between the convolution operations into account. We propose to prune CNNs by using graph-based algorithms to select relevant chains of convolutions. A CNN is interpreted as a graph, with the operator norm of each convolution as distance metric for the edges. LEAN pruning iteratively extracts the highest value path from the graph to keep. In our experiments, we test LEAN pruning for several image-to-image tasks, including the well-known CamVid dataset. LEAN pruning enables us to keep just 0.5%-2% of the convolutions without significant loss of accuracy. When pruning CNNs with LEAN, we achieve a higher accuracy than pruning filters individually, and different pruned substructures emerge.