 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Maximal function pooling with applications
Mar 01, 2021
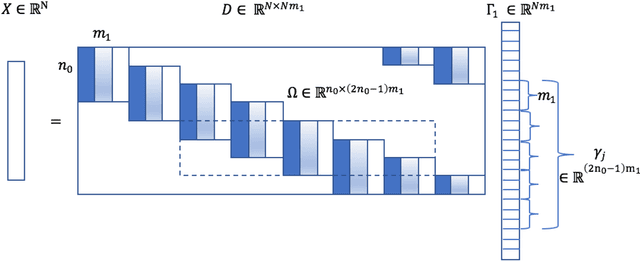

Inspired by the Hardy-Littlewood maximal function, we propose a novel pooling strategy which is called maxfun pooling. It is presented both as a viable alternative to some of the most popular pooling functions, such as max pooling and average pooling, and as a way of interpolating between these two algorithms. We demonstrate the features of maxfun pooling with two applications: first in the context of convolutional sparse coding, and then for image classification.
Sparse Adversarial Attack to Object Detection
Dec 26, 2020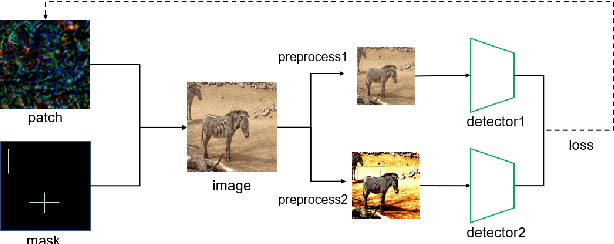


Adversarial examples have gained tons of attention in recent years. Many adversarial attacks have been proposed to attack image classifiers, but few work shift attention to object detectors. In this paper, we propose Sparse Adversarial Attack (SAA) which enables adversaries to perform effective evasion attack on detectors with bounded \emph{l$_{0}$} norm perturbation. We select the fragile position of the image and designed evasion loss function for the task. Experiment results on YOLOv4 and FasterRCNN reveal the effectiveness of our method. In addition, our SAA shows great transferability across different detectors in the black-box attack setting. Codes are available at \emph{https://github.com/THUrssq/Tianchi04}.
TransFG: A Transformer Architecture for Fine-grained Recognition
Mar 17, 2021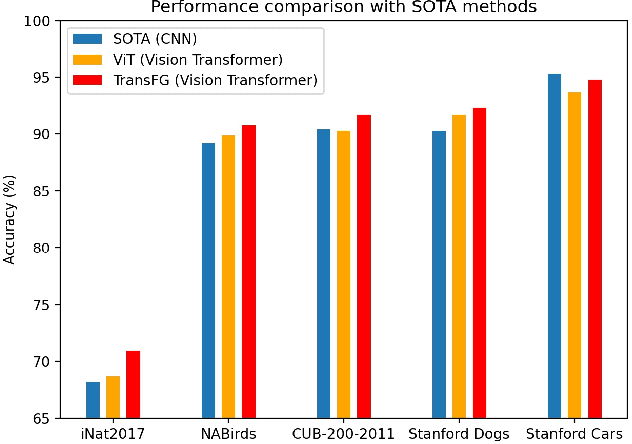
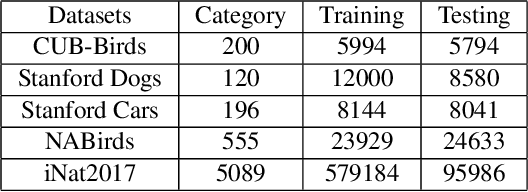
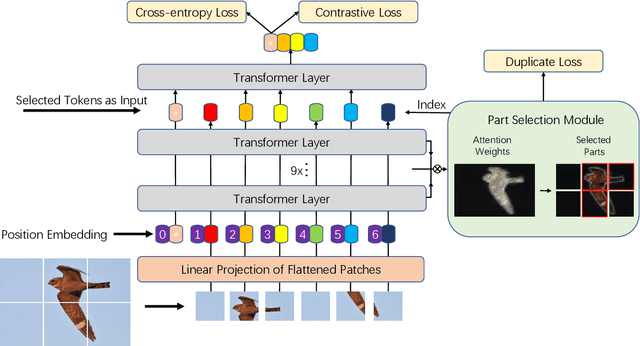
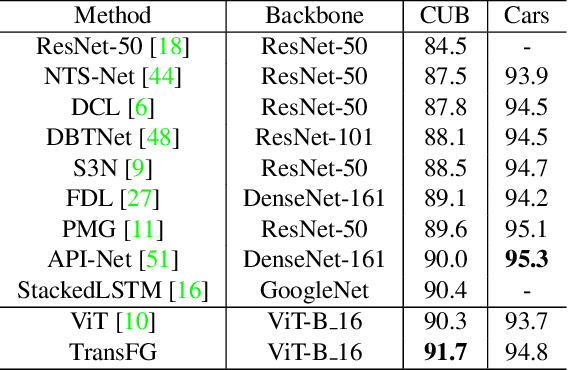
Fine-grained visual classification (FGVC) which aims at recognizing objects from subcategories is a very challenging task due to the inherently subtle inter-class differences. Recent works mainly tackle this problem by focusing on how to locate the most discriminative image regions and rely on them to improve the capability of networks to capture subtle variances. Most of these works achieve this by re-using the backbone network to extract features of selected regions. However, this strategy inevitably complicates the pipeline and pushes the proposed regions to contain most parts of the objects. Recently, vision transformer (ViT) shows its strong performance in the traditional classification task. The self-attention mechanism of the transformer links every patch token to the classification token. The strength of the attention link can be intuitively considered as an indicator of the importance of tokens. In this work, we propose a novel transformer-based framework TransFG where we integrate all raw attention weights of the transformer into an attention map for guiding the network to effectively and accurately select discriminative image patches and compute their relations. A contrastive loss is applied to further enlarge the distance between feature representations of similar sub-classes. We demonstrate the value of TransFG by conducting experiments on five popular fine-grained benchmarks: CUB-200-2011, Stanford Cars, Stanford Dogs, NABirds and iNat2017 where we achieve state-of-the-art performance. Qualitative results are presented for better understanding of our model.
High-Fidelity Generative Image Compression
Jun 17, 2020


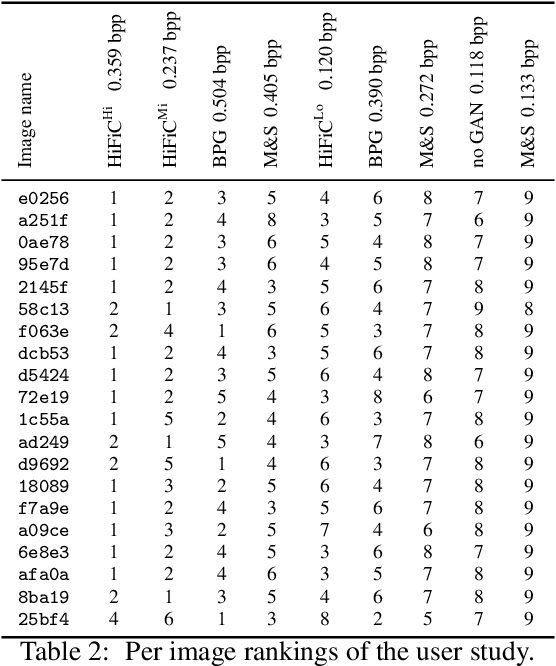
We extensively study how to combine Generative Adversarial Networks and learned compression to obtain a state-of-the-art generative lossy compression system. In particular, we investigate normalization layers, generator and discriminator architectures, training strategies, as well as perceptual losses. In contrast to previous work, i) we obtain visually pleasing reconstructions that are perceptually similar to the input, ii) we operate in a broad range of bitrates, and iii) our approach can be applied to high-resolution images. We bridge the gap between rate-distortion-perception theory and practice by evaluating our approach both quantitatively with various perceptual metrics and a user study. The study shows that our method is preferred to previous approaches even if they use more than 2x the bitrate.
OFEI: A Semi-black-box Android Adversarial Sample Attack Framework Against DLaaS
May 25, 2021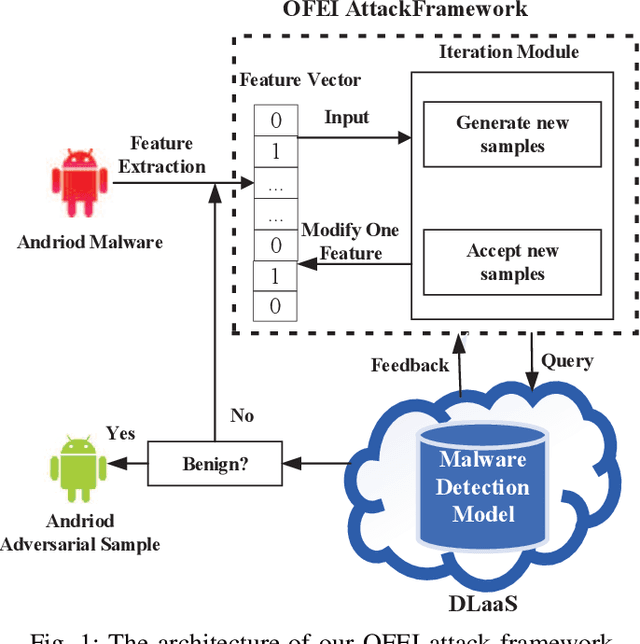
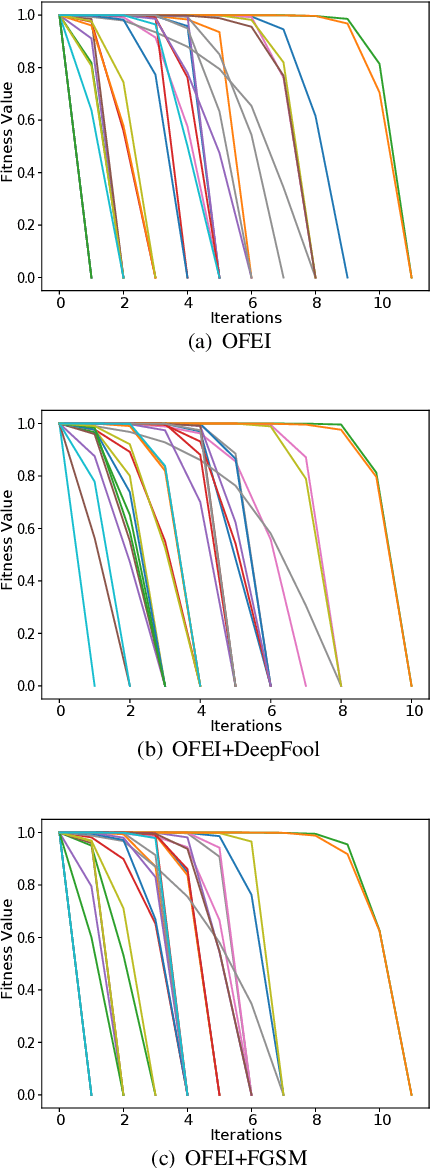
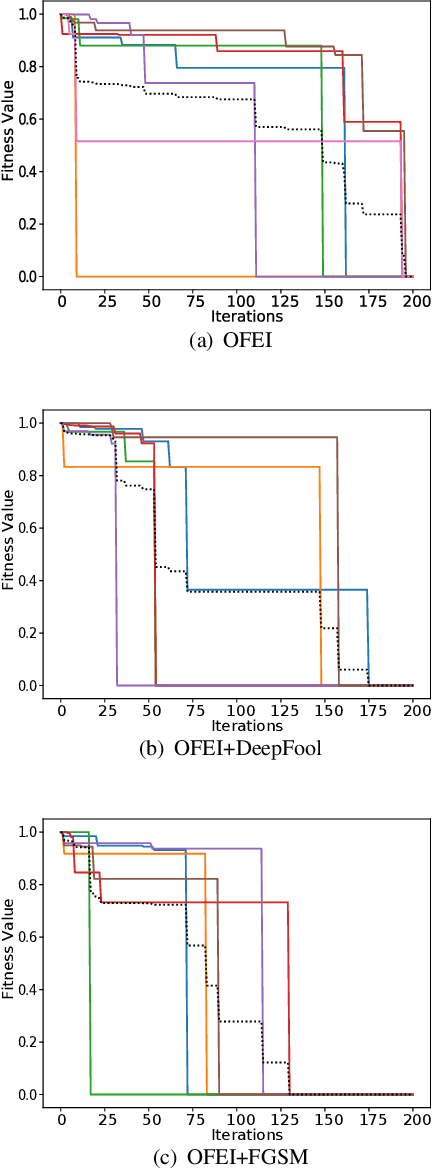
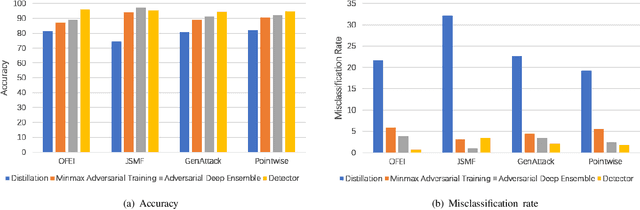
With the growing popularity of Android devices, Android malware is seriously threatening the safety of users. Although such threats can be detected by deep learning as a service (DLaaS), deep neural networks as the weakest part of DLaaS are often deceived by the adversarial samples elaborated by attackers. In this paper, we propose a new semi-black-box attack framework called one-feature-each-iteration (OFEI) to craft Android adversarial samples. This framework modifies as few features as possible and requires less classifier information to fool the classifier. We conduct a controlled experiment to evaluate our OFEI framework by comparing it with the benchmark methods JSMF, GenAttack and pointwise attack. The experimental results show that our OFEI has a higher misclassification rate of 98.25%. Furthermore, OFEI can extend the traditional white-box attack methods in the image field, such as fast gradient sign method (FGSM) and DeepFool, to craft adversarial samples for Android. Finally, to enhance the security of DLaaS, we use two uncertainties of the Bayesian neural network to construct the combined uncertainty, which is used to detect adversarial samples and achieves a high detection rate of 99.28%.
Beyond Visual Semantics: Exploring the Role of Scene Text in Image Understanding
May 25, 2019
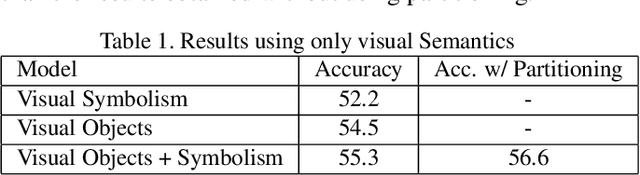
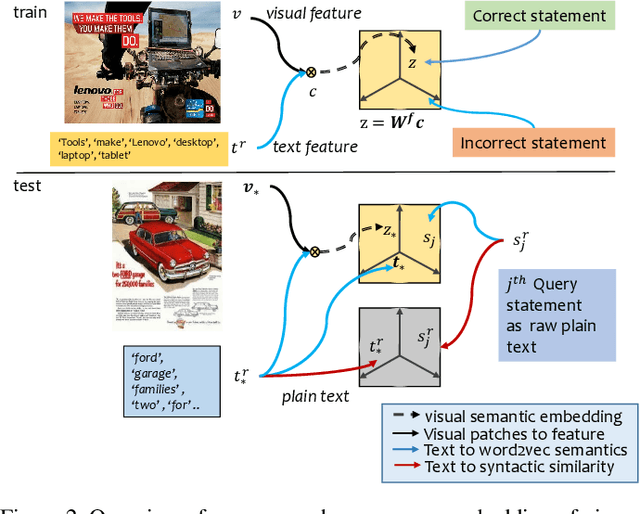

Images with visual and scene text content are ubiquitous in everyday life. However current image interpretation systems are mostly limited to using only the visual features, neglecting to leverage the scene text content. In this paper we propose to jointly use scene text and visual channels for robust semantic interpretation of images. We undertake the task of matching Advertisement images against their human generated statements that describe the action that the ad prompts and the rationale it provides for taking this action. We extract the scene text and generate semantic and lexical text representations, which are used in the interpretation of the Ad Image. To deal with irrelevant or erroneous detection of scene text, we use a text attention scheme. We also learn an embedding of the visual channel,\ie visual features based on detected symbolism and objects, into a semantic embedding space, leveraging text semantics obtained from scene text. We show how the multi channel approach, involving visual semantics and scene text, improves upon the current state of the art.
The Effectiveness of Instance Normalization: a Strong Baseline for Single Image Dehazing
May 08, 2018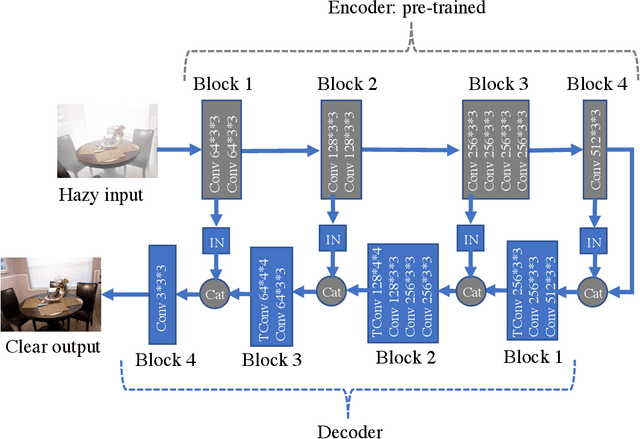
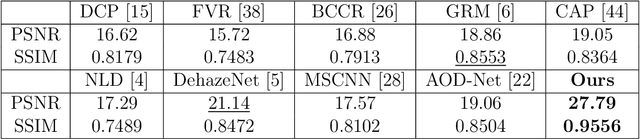
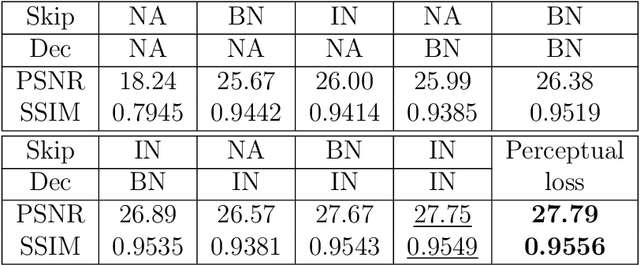

We propose a novel deep neural network architecture for the challenging problem of single image dehazing, which aims to recover the clear image from a degraded hazy image. Instead of relying on hand-crafted image priors or explicitly estimating the components of the widely used atmospheric scattering model, our end-to-end system directly generates the clear image from an input hazy image. The proposed network has an encoder-decoder architecture with skip connections and instance normalization. We adopt the convolutional layers of the pre-trained VGG network as encoder to exploit the representation power of deep features, and demonstrate the effectiveness of instance normalization for image dehazing. Our simple yet effective network outperforms the state-of-the-art methods by a large margin on the benchmark datasets.
A2J: Anchor-to-Joint Regression Network for 3D Articulated Pose Estimation from a Single Depth Image
Aug 27, 2019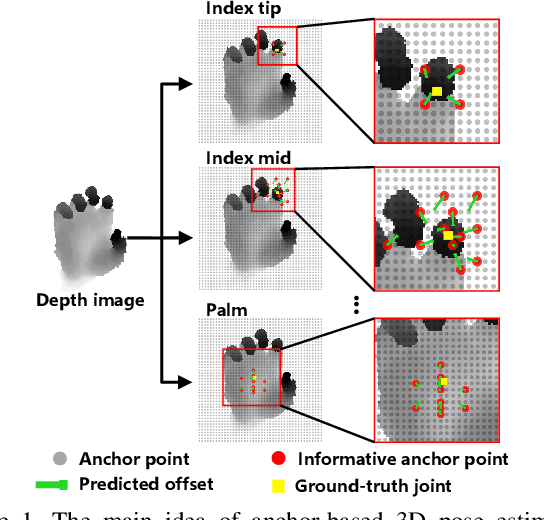

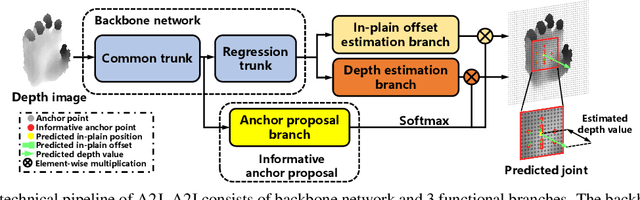
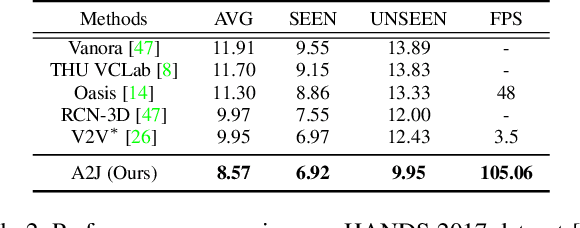
For 3D hand and body pose estimation task in depth image, a novel anchor-based approach termed Anchor-to-Joint regression network (A2J) with the end-to-end learning ability is proposed. Within A2J, anchor points able to capture global-local spatial context information are densely set on depth image as local regressors for the joints. They contribute to predict the positions of the joints in ensemble way to enhance generalization ability. The proposed 3D articulated pose estimation paradigm is different from the state-of-the-art encoder-decoder based FCN, 3D CNN and point-set based manners. To discover informative anchor points towards certain joint, anchor proposal procedure is also proposed for A2J. Meanwhile 2D CNN (i.e., ResNet-50) is used as backbone network to drive A2J, without using time-consuming 3D convolutional or deconvolutional layers. The experiments on 3 hand datasets and 2 body datasets verify A2J's superiority. Meanwhile, A2J is of high running speed around 100 FPS on single NVIDIA 1080Ti GPU.
Cognitive Visual Inspection Service for LCD Manufacturing Industry
Jan 11, 2021
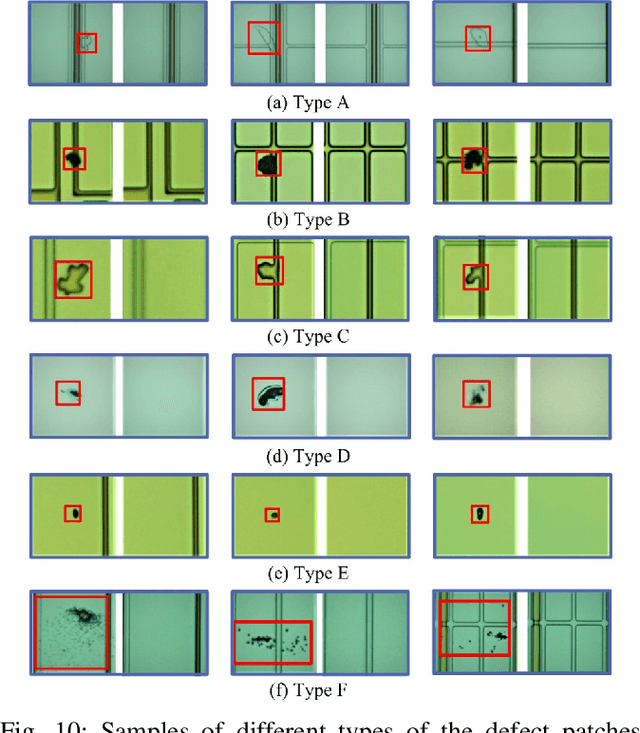
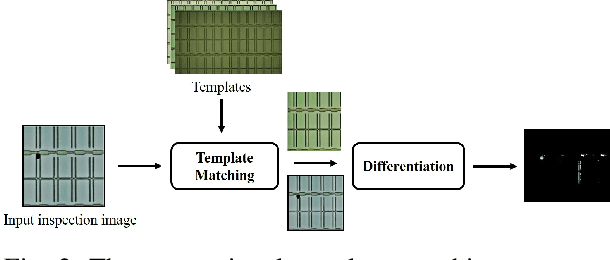
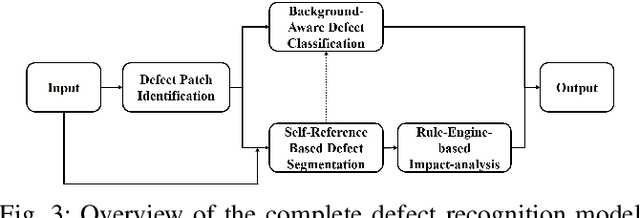
With the rapid growth of display devices, quality inspection via machine vision technology has become increasingly important for flat-panel displays (FPD) industry. This paper discloses a novel visual inspection system for liquid crystal display (LCD), which is currently a dominant type in the FPD industry. The system is based on two cornerstones: robust/high-performance defect recognition model and cognitive visual inspection service architecture. A hybrid application of conventional computer vision technique and the latest deep convolutional neural network (DCNN) leads to an integrated defect detection, classfication and impact evaluation model that can be economically trained with only image-level class annotations to achieve a high inspection accuracy. In addition, the properly trained model is robust to the variation of the image qulity, significantly alleviating the dependency between the model prediction performance and the image aquisition environment. This in turn justifies the decoupling of the defect recognition functions from the front-end device to the back-end serivce, motivating the design and realization of the cognitive visual inspection service architecture. Empirical case study is performed on a large-scale real-world LCD dataset from a manufacturing line with different layers and products, which shows the promising utility of our system, which has been deployed in a real-world LCD manufacturing line from a major player in the world.
Engaging Image Chat: Modeling Personality in Grounded Dialogue
Nov 02, 2018
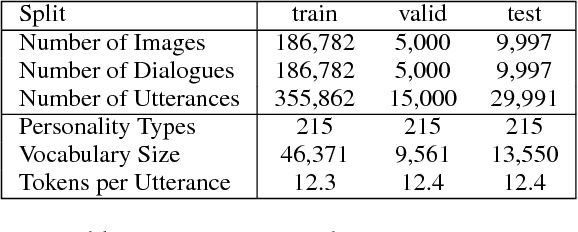
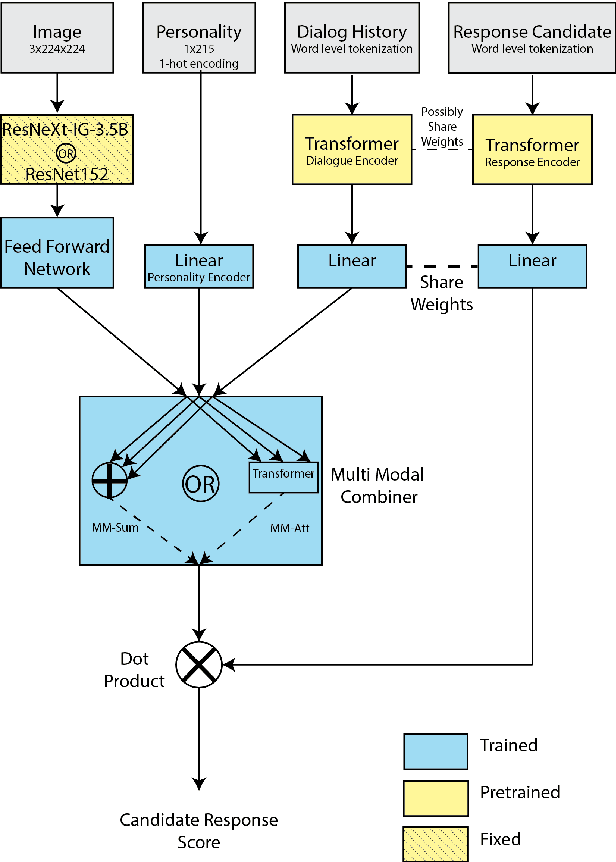

To achieve the long-term goal of machines being able to engage humans in conversation, our models should be engaging. We focus on communication grounded in images, whereby a dialogue is conducted based on a given photo, a setup that is naturally engaging to humans (Hu et al., 2014). We collect a large dataset of grounded human-human conversations, where humans are asked to play the role of a given personality, as the use of personality in conversation has also been shown to be engaging (Shuster et al., 2018). Our dataset, Image-Chat, consists of 202k dialogues and 401k utterances over 202k images using 215 possible personality traits. We then design a set of natural architectures using state-of-the-art image and text representations, considering various ways to fuse the components. Automatic metrics and human evaluations show the efficacy of approach, in particular where our best performing model is preferred over human conversationalists 47.7% of the time