 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Achieving Rotation Invariance in Convolution Operations: Shifting from Data-Driven to Mechanism-Assured
Apr 17, 2024
Achieving rotation invariance in deep neural networks without relying on data has always been a hot research topic. Intrinsic rotation invariance can enhance the model's feature representation capability, enabling better performance in tasks such as multi-orientation object recognition and detection. Based on various types of non-learnable operators, including gradient, sort, local binary pattern, maximum, etc., this paper designs a set of new convolution operations that are natually invariant to arbitrary rotations. Unlike most previous studies, these rotation-invariant convolutions (RIConvs) have the same number of learnable parameters and a similar computational process as conventional convolution operations, allowing them to be interchangeable. Using the MNIST-Rot dataset, we first verify the invariance of these RIConvs under various rotation angles and compare their performance with previous rotation-invariant convolutional neural networks (RI-CNNs). Two types of RIConvs based on gradient operators achieve state-of-the-art results. Subsequently, we combine RIConvs with different types and depths of classic CNN backbones. Using the OuTex_00012, MTARSI, and NWPU-RESISC-45 datasets, we test their performance on texture recognition, aircraft type recognition, and remote sensing image classification tasks. The results show that RIConvs significantly improve the accuracy of these CNN backbones, especially when the training data is limited. Furthermore, we find that even with data augmentation, RIConvs can further enhance model performance.
A CT Image Denoising Method with Residual Encoder-Decoder Network
Apr 02, 2024Utilizing a low-dose CT approach significantly reduces the radiation exposure for patients, yet it introduces challenges, such as increased noise and artifacts in the resultant images, which can hinder accurate medical diagnostics. Traditional methods for noise reduction struggle with preserving image textures due to the complexity of modeling statistical properties directly within the image domain. To address these limitations, this study introduces an enhanced noise-reduction technique centered around an advanced residual encoder-decoder network. By incorporating recursive processing into the foundational network, this method reduces computational complexity and enhances the effectiveness of noise reduction. Furthermore, the introduction of a root-mean-square error and perceptual loss functions aims to retain the integrity of the images' textural details. The enhanced technique also includes optimized tissue segmentation, improving artifact management post-improvement. Validation using the TCGA-COAD clinical dataset demonstrates superior performance in both noise reduction and image quality, as measured by post-denoising PSNR and SSIM, compared to the existing WGAN approach. This advancement in CT image processing offers a practical solution for clinical applications, achieving lower computational demands and faster processing times without compromising image quality.
Exploring Explainability in Video Action Recognition
Apr 13, 2024Image Classification and Video Action Recognition are perhaps the two most foundational tasks in computer vision. Consequently, explaining the inner workings of trained deep neural networks is of prime importance. While numerous efforts focus on explaining the decisions of trained deep neural networks in image classification, exploration in the domain of its temporal version, video action recognition, has been scant. In this work, we take a deeper look at this problem. We begin by revisiting Grad-CAM, one of the popular feature attribution methods for Image Classification, and its extension to Video Action Recognition tasks and examine the method's limitations. To address these, we introduce Video-TCAV, by building on TCAV for Image Classification tasks, which aims to quantify the importance of specific concepts in the decision-making process of Video Action Recognition models. As the scalable generation of concepts is still an open problem, we propose a machine-assisted approach to generate spatial and spatiotemporal concepts relevant to Video Action Recognition for testing Video-TCAV. We then establish the importance of temporally-varying concepts by demonstrating the superiority of dynamic spatiotemporal concepts over trivial spatial concepts. In conclusion, we introduce a framework for investigating hypotheses in action recognition and quantitatively testing them, thus advancing research in the explainability of deep neural networks used in video action recognition.
Rendering-Enhanced Automatic Image-to-Point Cloud Registration for Roadside Scenes
Apr 08, 2024Prior point cloud provides 3D environmental context, which enhances the capabilities of monocular camera in downstream vision tasks, such as 3D object detection, via data fusion. However, the absence of accurate and automated registration methods for estimating camera extrinsic parameters in roadside scene point clouds notably constrains the potential applications of roadside cameras. This paper proposes a novel approach for the automatic registration between prior point clouds and images from roadside scenes. The main idea involves rendering photorealistic grayscale views taken at specific perspectives from the prior point cloud with the help of their features like RGB or intensity values. These generated views can reduce the modality differences between images and prior point clouds, thereby improve the robustness and accuracy of the registration results. Particularly, we specify an efficient algorithm, named neighbor rendering, for the rendering process. Then we introduce a method for automatically estimating the initial guess using only rough guesses of camera's position. At last, we propose a procedure for iteratively refining the extrinsic parameters by minimizing the reprojection error for line features extracted from both generated and camera images using Segment Anything Model (SAM). We assess our method using a self-collected dataset, comprising eight cameras strategically positioned throughout the university campus. Experiments demonstrate our method's capability to automatically align prior point cloud with roadside camera image, achieving a rotation accuracy of 0.202 degrees and a translation precision of 0.079m. Furthermore, we validate our approach's effectiveness in visual applications by substantially improving monocular 3D object detection performance.
Evaluating Text-to-Image Synthesis: Survey and Taxonomy of Image Quality Metrics
Mar 29, 2024
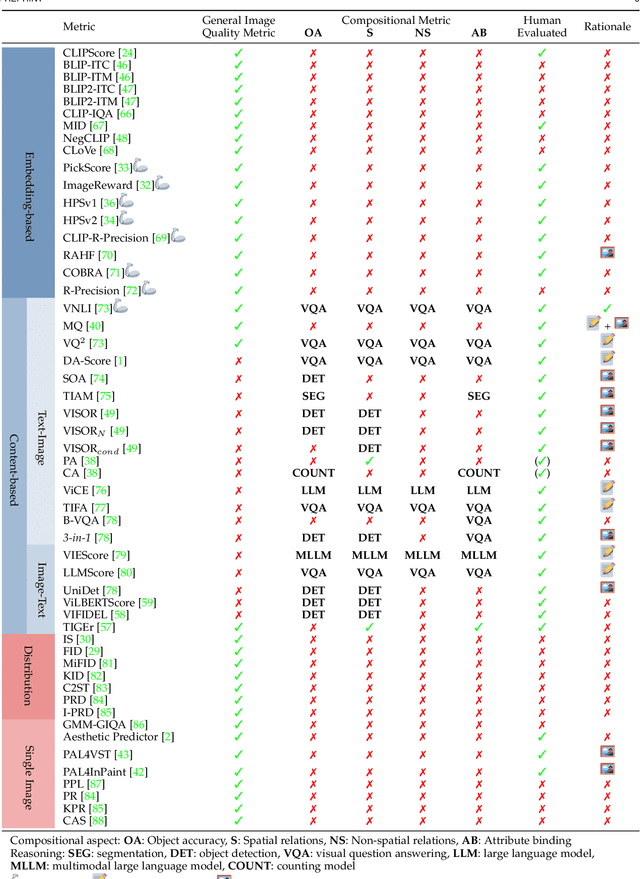
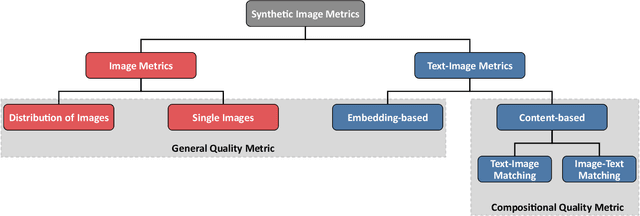
Recent advances in text-to-image synthesis enabled through a combination of language and vision foundation models have led to a proliferation of the tools available and an increased attention to the field. When conducting text-to-image synthesis, a central goal is to ensure that the content between text and image is aligned. As such, there exist numerous evaluation metrics that aim to mimic human judgement. However, it is often unclear which metric to use for evaluating text-to-image synthesis systems as their evaluation is highly nuanced. In this work, we provide a comprehensive overview of existing text-to-image evaluation metrics. Based on our findings, we propose a new taxonomy for categorizing these metrics. Our taxonomy is grounded in the assumption that there are two main quality criteria, namely compositionality and generality, which ideally map to human preferences. Ultimately, we derive guidelines for practitioners conducting text-to-image evaluation, discuss open challenges of evaluation mechanisms, and surface limitations of current metrics.
Gaussian Shading: Provable Performance-Lossless Image Watermarking for Diffusion Models
Apr 07, 2024Ethical concerns surrounding copyright protection and inappropriate content generation pose challenges for the practical implementation of diffusion models. One effective solution involves watermarking the generated images. However, existing methods often compromise the model performance or require additional training, which is undesirable for operators and users. To address this issue, we propose Gaussian Shading, a diffusion model watermarking technique that is both performance-lossless and training-free, while serving the dual purpose of copyright protection and tracing of offending content. Our watermark embedding is free of model parameter modifications and thus is plug-and-play. We map the watermark to latent representations following a standard Gaussian distribution, which is indistinguishable from latent representations obtained from the non-watermarked diffusion model. Therefore we can achieve watermark embedding with lossless performance, for which we also provide theoretical proof. Furthermore, since the watermark is intricately linked with image semantics, it exhibits resilience to lossy processing and erasure attempts. The watermark can be extracted by Denoising Diffusion Implicit Models (DDIM) inversion and inverse sampling. We evaluate Gaussian Shading on multiple versions of Stable Diffusion, and the results demonstrate that Gaussian Shading not only is performance-lossless but also outperforms existing methods in terms of robustness.
Lighter, Better, Faster Multi-Source Domain Adaptation with Gaussian Mixture Models and Optimal Transport
Apr 16, 2024In this paper, we tackle Multi-Source Domain Adaptation (MSDA), a task in transfer learning where one adapts multiple heterogeneous, labeled source probability measures towards a different, unlabeled target measure. We propose a novel framework for MSDA, based on Optimal Transport (OT) and Gaussian Mixture Models (GMMs). Our framework has two key advantages. First, OT between GMMs can be solved efficiently via linear programming. Second, it provides a convenient model for supervised learning, especially classification, as components in the GMM can be associated with existing classes. Based on the GMM-OT problem, we propose a novel technique for calculating barycenters of GMMs. Based on this novel algorithm, we propose two new strategies for MSDA: GMM-WBT and GMM-DaDiL. We empirically evaluate our proposed methods on four benchmarks in image classification and fault diagnosis, showing that we improve over the prior art while being faster and involving fewer parameters.
Comparative Analysis of Image Enhancement Techniques for Brain Tumor Segmentation: Contrast, Histogram, and Hybrid Approaches
Apr 08, 2024This study systematically investigates the impact of image enhancement techniques on Convolutional Neural Network (CNN)-based Brain Tumor Segmentation, focusing on Histogram Equalization (HE), Contrast Limited Adaptive Histogram Equalization (CLAHE), and their hybrid variations. Employing the U-Net architecture on a dataset of 3064 Brain MRI images, the research delves into preprocessing steps, including resizing and enhancement, to optimize segmentation accuracy. A detailed analysis of the CNN-based U-Net architecture, training, and validation processes is provided. The comparative analysis, utilizing metrics such as Accuracy, Loss, MSE, IoU, and DSC, reveals that the hybrid approach CLAHE-HE consistently outperforms others. Results highlight its superior accuracy (0.9982, 0.9939, 0.9936 for training, testing, and validation, respectively) and robust segmentation overlap, with Jaccard values of 0.9862, 0.9847, and 0.9864, and Dice values of 0.993, 0.9923, and 0.9932 for the same phases, emphasizing its potential in neuro-oncological applications. The study concludes with a call for refinement in segmentation methodologies to further enhance diagnostic precision and treatment planning in neuro-oncology.
* 9 Pages, & Figures, 2 Tables, International Conference on Computer Science Electronics and Information (ICCSEI 2023)
StreakNet-Arch: An Anti-scattering Network-based Architecture for Underwater Carrier LiDAR-Radar Imaging
Apr 14, 2024In this paper, we introduce StreakNet-Arch, a novel signal processing architecture designed for Underwater Carrier LiDAR-Radar (UCLR) imaging systems, to address the limitations in scatter suppression and real-time imaging. StreakNet-Arch formulates the signal processing as a real-time, end-to-end binary classification task, enabling real-time image acquisition. To achieve this, we leverage Self-Attention networks and propose a novel Double Branch Cross Attention (DBC-Attention) mechanism that surpasses the performance of traditional methods. Furthermore, we present a method for embedding streak-tube camera images into attention networks, effectively acting as a learned bandpass filter. To facilitate further research, we contribute a publicly available streak-tube camera image dataset. The dataset contains 2,695,168 real-world underwater 3D point cloud data. These advancements significantly improve UCLR capabilities, enhancing its performance and applicability in underwater imaging tasks. The source code and dataset can be found at https://github.com/BestAnHongjun/StreakNet .
CLIPtone: Unsupervised Learning for Text-based Image Tone Adjustment
Apr 01, 2024Recent image tone adjustment (or enhancement) approaches have predominantly adopted supervised learning for learning human-centric perceptual assessment. However, these approaches are constrained by intrinsic challenges of supervised learning. Primarily, the requirement for expertly-curated or retouched images escalates the data acquisition expenses. Moreover, their coverage of target style is confined to stylistic variants inferred from the training data. To surmount the above challenges, we propose an unsupervised learning-based approach for text-based image tone adjustment method, CLIPtone, that extends an existing image enhancement method to accommodate natural language descriptions. Specifically, we design a hyper-network to adaptively modulate the pretrained parameters of the backbone model based on text description. To assess whether the adjusted image aligns with the text description without ground truth image, we utilize CLIP, which is trained on a vast set of language-image pairs and thus encompasses knowledge of human perception. The major advantages of our approach are three fold: (i) minimal data collection expenses, (ii) support for a range of adjustments, and (iii) the ability to handle novel text descriptions unseen in training. Our approach's efficacy is demonstrated through comprehensive experiments, including a user study.