 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Near-lossless L-infinity constrained Multi-rate Image Decompression via Deep Neural Network
Oct 10, 2018
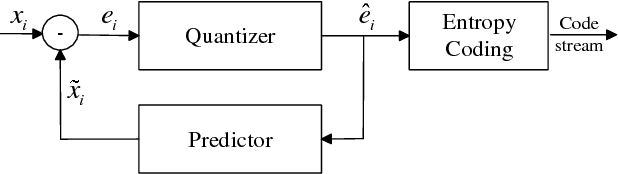
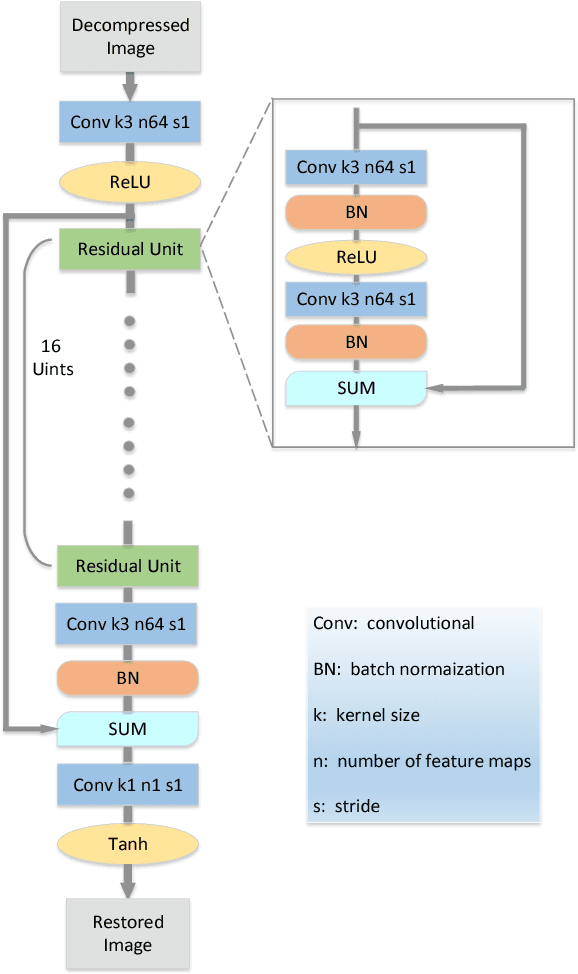
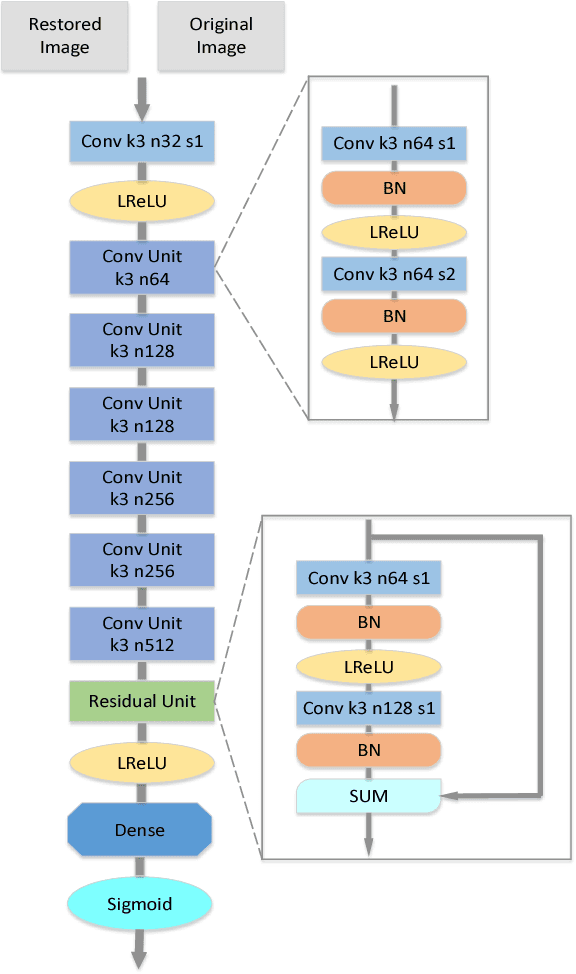
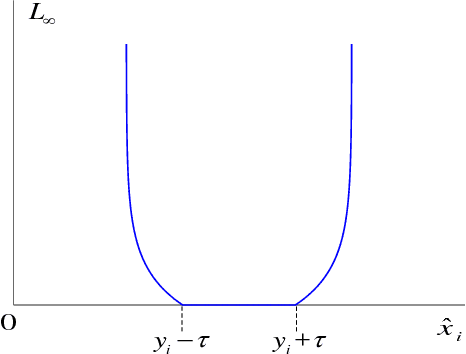
Recently a number of CNN-based techniques were proposed to remove image compression artifacts. As in other restoration applications, these techniques all learn a mapping from decompressed patches to the original counterparts under the ubiquitous L2 metric. However, this approach is incapable of restoring distinctive image details which may be statistical outliers but have high semantic importance (e.g., tiny lesions in medical images). To overcome this weakness, we propose to incorporate an L-infinity fidelity criterion in the design of neural network so that no small, distinctive structures of the original image can be dropped or distorted. Moreover, our anti-artifacts neural network is designed to work on a range of compression bit rates, rather than a fixed one as in the past. Experimental results demonstrate that the proposed method outperforms the state-of-the-art methods in L-infinity error metric and perceptual quality, while being competitive in L2 error metric as well. It can restore subtle image details that are otherwise destroyed or missed by other algorithms. Our research suggests a new machine learning paradigm of ultra high fidelity image compression that is ideally suited for applications in medicine, space, and sciences.
A new solution to the curved Ewald sphere problem for 3D image reconstruction in electron microscopy
Feb 07, 2021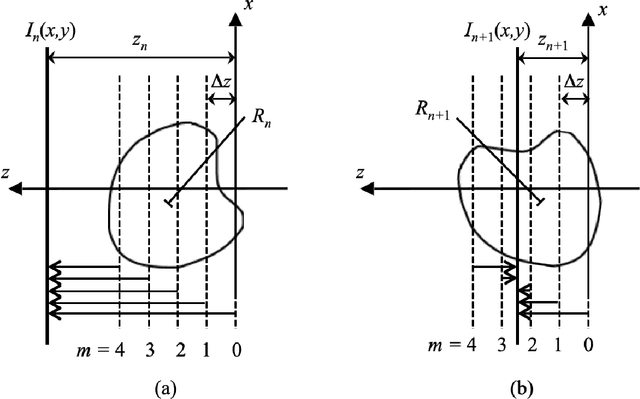
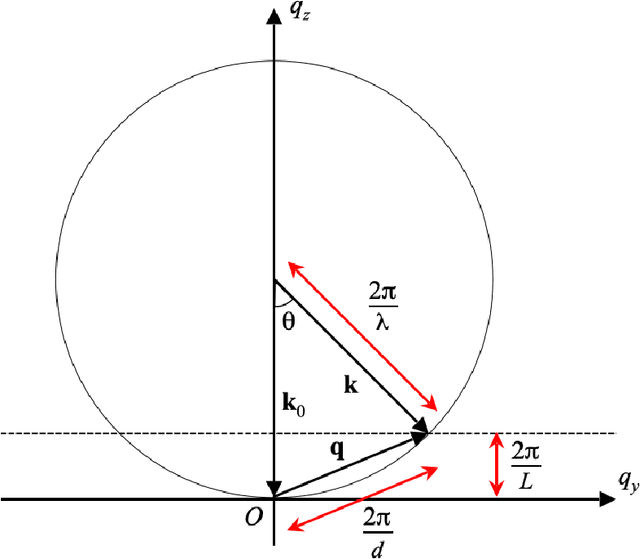
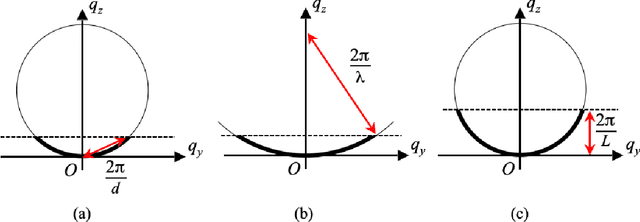
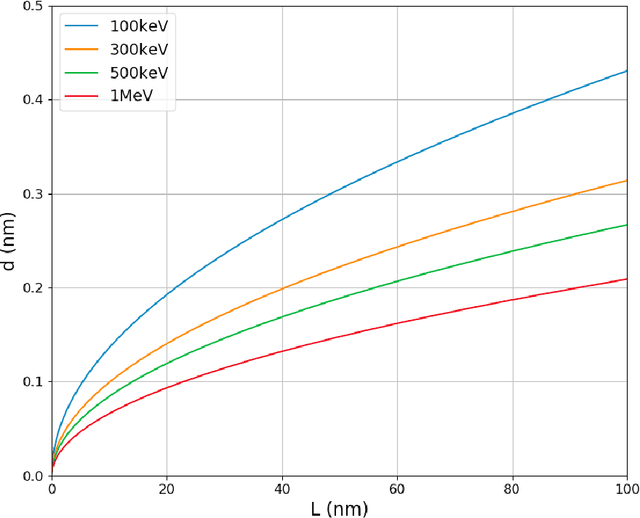
We develop an algorithm capable of imaging a three-dimensional object given a collection of two-dimensional images of that object that are significantly influenced by the curvature of the Ewald sphere. These two-dimensional images cannot be approximated as projections of the object. Such an algorithm is useful in cryo-electron microscopy where larger samples, higher resolution, or lower energy electron beams are desired, all of which contribute to the significance of Ewald curvature.
Multi Modal Adaptive Normalization for Audio to Video Generation
Dec 14, 2020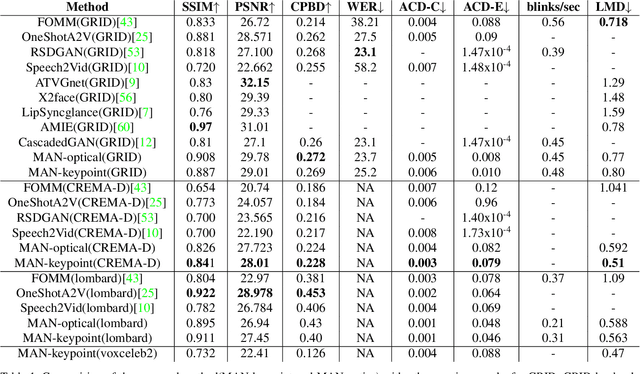

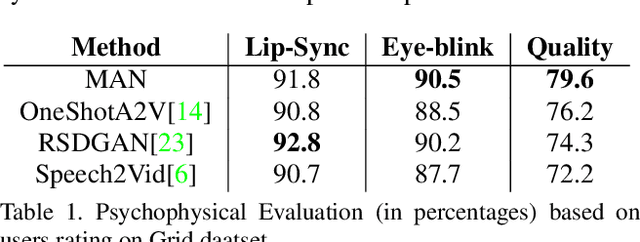
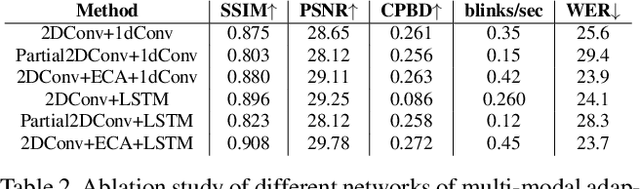
Speech-driven facial video generation has been a complex problem due to its multi-modal aspects namely audio and video domain. The audio comprises lots of underlying features such as expression, pitch, loudness, prosody(speaking style) and facial video has lots of variability in terms of head movement, eye blinks, lip synchronization and movements of various facial action units along with temporal smoothness. Synthesizing highly expressive facial videos from the audio input and static image is still a challenging task for generative adversarial networks. In this paper, we propose a multi-modal adaptive normalization(MAN) based architecture to synthesize a talking person video of arbitrary length using as input: an audio signal and a single image of a person. The architecture uses the multi-modal adaptive normalization, keypoint heatmap predictor, optical flow predictor and class activation map[58] based layers to learn movements of expressive facial components and hence generates a highly expressive talking-head video of the given person. The multi-modal adaptive normalization uses the various features of audio and video such as Mel spectrogram, pitch, energy from audio signals and predicted keypoint heatmap/optical flow and a single image to learn the respective affine parameters to generate highly expressive video. Experimental evaluation demonstrates superior performance of the proposed method as compared to Realistic Speech-Driven Facial Animation with GANs(RSDGAN) [53], Speech2Vid [10], and other approaches, on multiple quantitative metrics including: SSIM (structural similarity index), PSNR (peak signal to noise ratio), CPBD (image sharpness), WER(word error rate), blinks/sec and LMD(landmark distance). Further, qualitative evaluation and Online Turing tests demonstrate the efficacy of our approach.
Image Processing on IOPA Radiographs: A comprehensive case study on Apical Periodontitis
Dec 23, 2018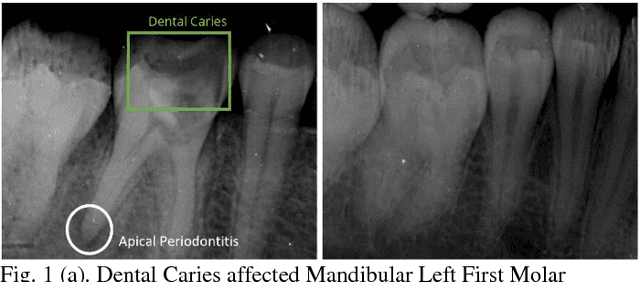
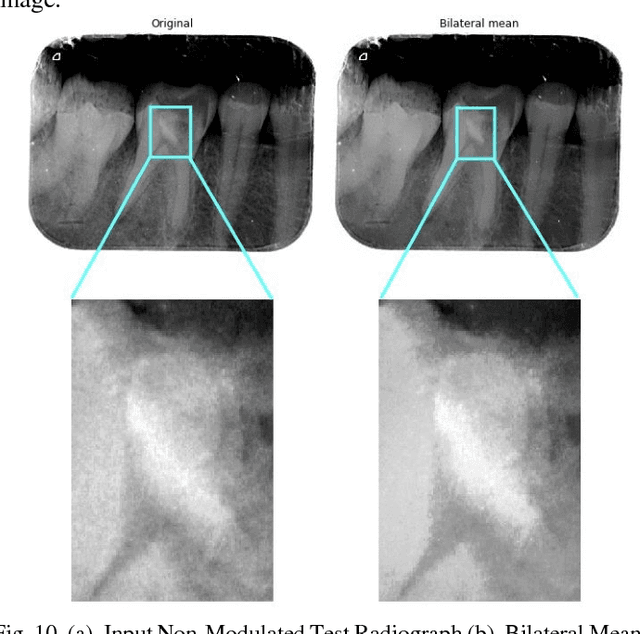
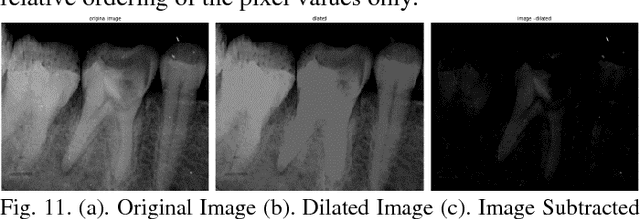
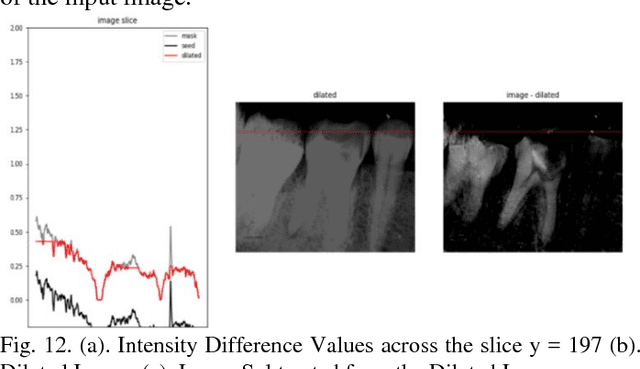
With the recent advancements in Image Processing Techniques and development of new robust computer vision algorithms, new areas of research within Medical Diagnosis and Biomedical Engineering are picking up pace. This paper provides a comprehensive in-depth case study of Image Processing, Feature Extraction and Analysis of Apical Periodontitis diagnostic cases in IOPA (Intra Oral Peri-Apical) Radiographs, a common case in oral diagnostic pipeline. This paper provides a detailed analytical approach towards improving the diagnostic procedure with improved and faster results with higher accuracy targeting to eliminate True Negative and False Positive cases.
Hierarchical Autoregressive Image Models with Auxiliary Decoders
Mar 06, 2019

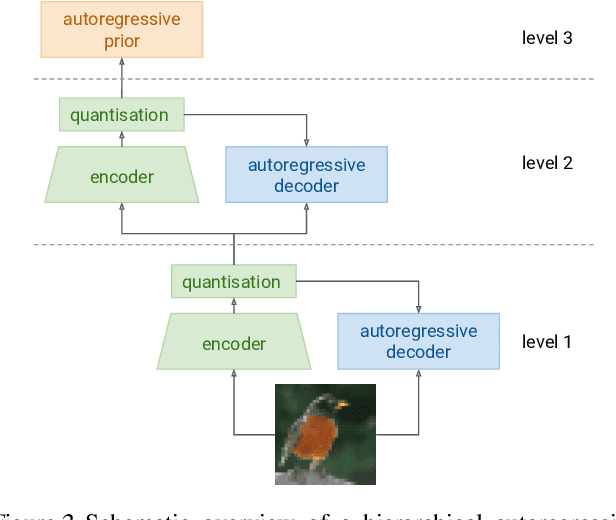
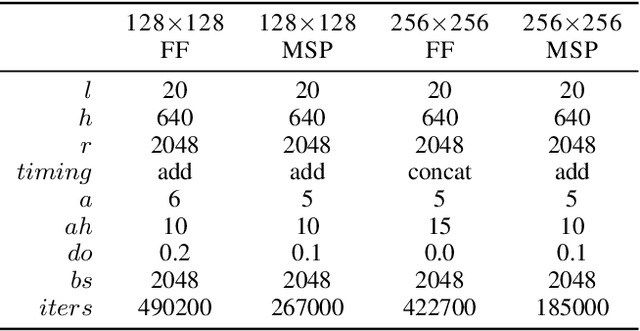
Autoregressive generative models of images tend to be biased towards capturing local structure, and as a result they often produce samples which are lacking in terms of large-scale coherence. To address this, we propose two methods to learn discrete representations of images which abstract away local detail. We show that autoregressive models conditioned on these representations can produce high-fidelity reconstructions of images, and that we can train autoregressive priors on these representations that produce samples with large-scale coherence. We can recursively apply the learning procedure, yielding a hierarchy of progressively more abstract image representations. We train hierarchical class-conditional autoregressive models on the ImageNet dataset and demonstrate that they are able to generate realistic images at resolutions of 128$\times$128 and 256$\times$256 pixels.
Label Embedded Dictionary Learning for Image Classification
Apr 17, 2019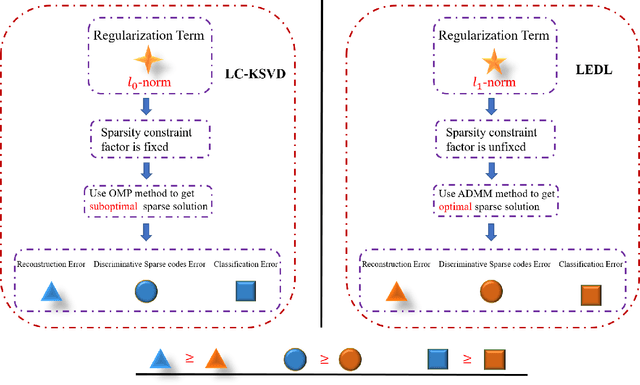


Recently, label consistent k-svd (LC-KSVD) algorithm has been successfully applied in image classification. The objective function of LC-KSVD is consisted of reconstruction error, classification error and discriminative sparse codes error with L0-norm sparse regularization term. The L0-norm, however, leads to NP-hard problem. Despite some methods such as orthogonal matching pursuit can help solve this problem to some extent, it is quite difficult to find the optimum sparse solution. To overcome this limitation, we propose a label embedded dictionary learning (LEDL) method to utilise the L1-norm as the sparse regularization term so that we can avoid the hard-to-optimize problem by solving the convex optimization problem. Alternating direction method of multipliers and blockwise coordinate descent algorithm are then exploited to optimize the corresponding objective function. Extensive experimental results on six benchmark datasets illustrate that the proposed algorithm has achieved superior performance compared to some conventional classification algorithms.
Resolution enhancement in the recovery of underdrawings via style transfer by generative adversarial deep neural networks
Jan 30, 2021



We apply generative adversarial convolutional neural networks to the problem of style transfer to underdrawings and ghost-images in x-rays of fine art paintings with a special focus on enhancing their spatial resolution. We build upon a neural architecture developed for the related problem of synthesizing high-resolution photo-realistic image from semantic label maps. Our neural architecture achieves high resolution through a hierarchy of generators and discriminator sub-networks, working throughout a range of spatial resolutions. This coarse-to-fine generator architecture can increase the effective resolution by a factor of eight in each spatial direction, or an overall increase in number of pixels by a factor of 64. We also show that even just a few examples of human-generated image segmentations can greatly improve -- qualitatively and quantitatively -- the generated images. We demonstrate our method on works such as Leonardo's Madonna of the carnation and the underdrawing in his Virgin of the rocks, which pose several special problems in style transfer, including the paucity of representative works from which to learn and transfer style information.
Accurate and fast matrix factorization for low-rank learning
Apr 21, 2021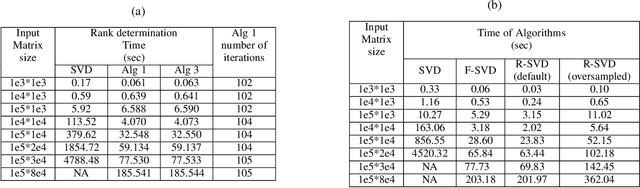
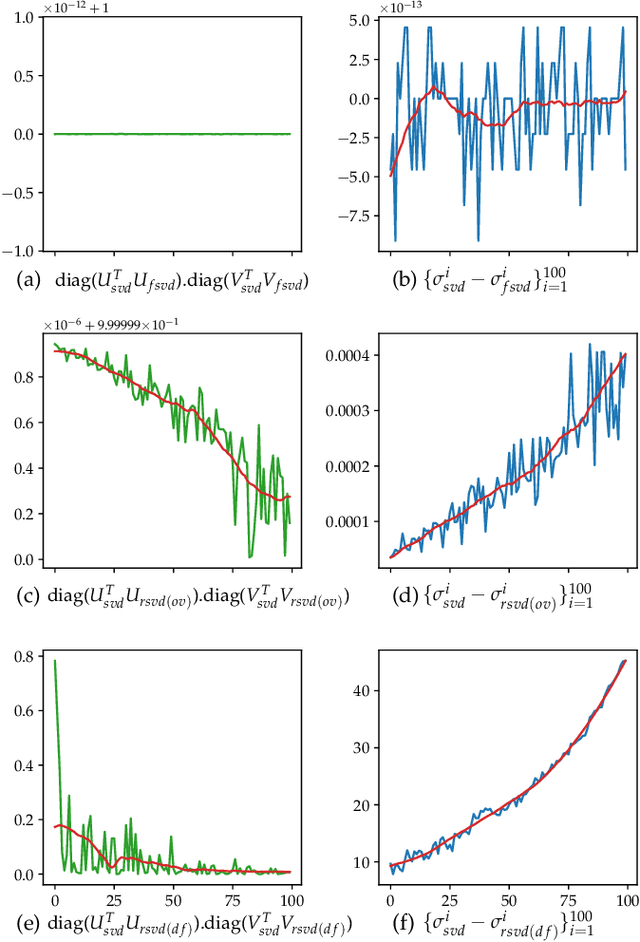
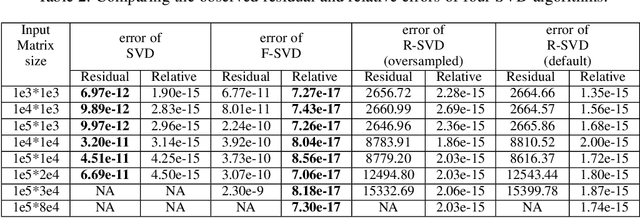
In this paper we tackle two important challenges related to the accurate partial singular value decomposition (SVD) and numerical rank estimation of a huge matrix to use in low-rank learning problems in a fast way. We use the concepts of Krylov subspaces such as the Golub-Kahan bidiagonalization process as well as Ritz vectors to achieve these goals. Our experiments identify various advantages of the proposed methods compared to traditional and randomized SVD (R-SVD) methods with respect to the accuracy of the singular values and corresponding singular vectors computed in a similar execution time. The proposed methods are appropriate for applications involving huge matrices where accuracy in all spectrum of the desired singular values, and also all of corresponding singular vectors is essential. We evaluate our method in the real application of Riemannian similarity learning (RSL) between two various image datasets of MNIST and USPS.
Learning Affective Correspondence between Music and Image
Apr 17, 2019


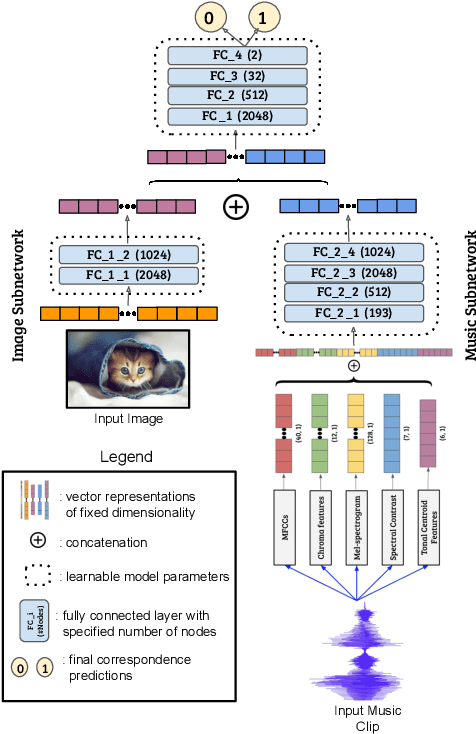
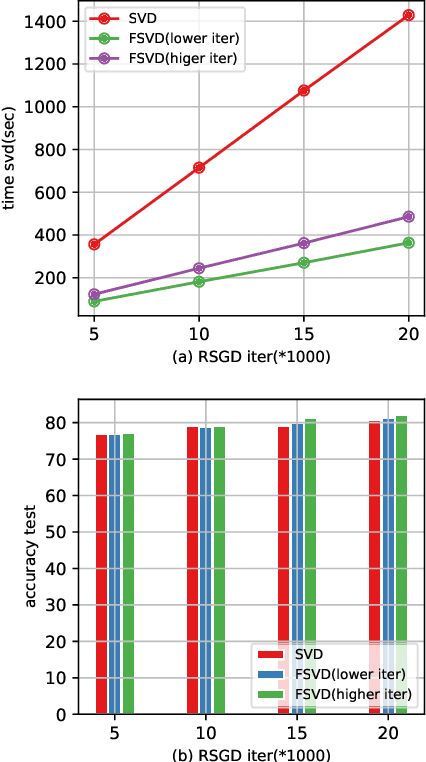
We introduce the problem of learning affective correspondence between audio (music) and visual data (images). For this task, a music clip and an image are considered similar (having true correspondence) if they have similar emotion content. In order to estimate this crossmodal, emotion-centric similarity, we propose a deep neural network architecture that learns to project the data from the two modalities to a common representation space, and performs a binary classification task of predicting the affective correspondence (true or false). To facilitate the current study, we construct a large scale database containing more than $3,500$ music clips and $85,000$ images with three emotion classes (positive, neutral, negative). The proposed approach achieves $61.67\%$ accuracy for the affective correspondence prediction task on this database, outperforming two relevant and competitive baselines. We also demonstrate that our network learns modality-specific representations of emotion (without explicitly being trained with emotion labels), which are useful for emotion recognition in individual modalities.
One-shot Representational Learning for Joint Biometric and Device Authentication
Jan 02, 2021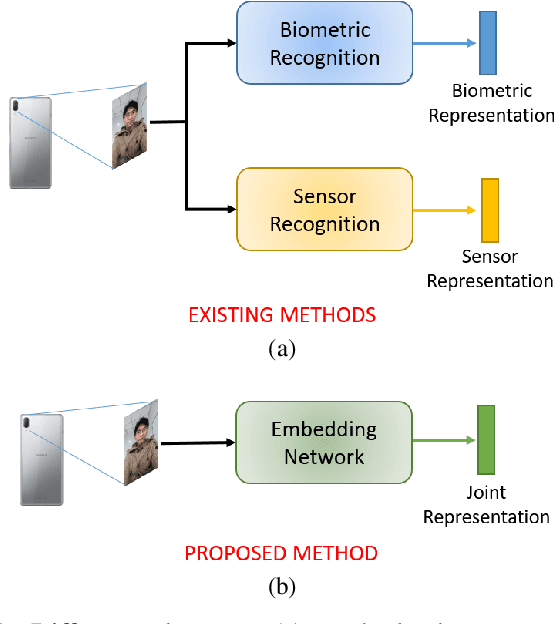
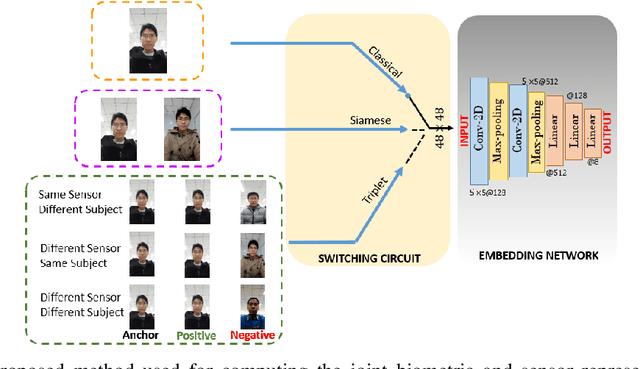
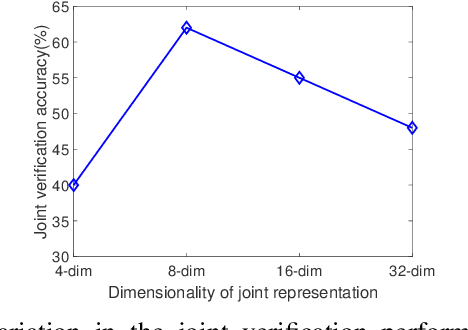
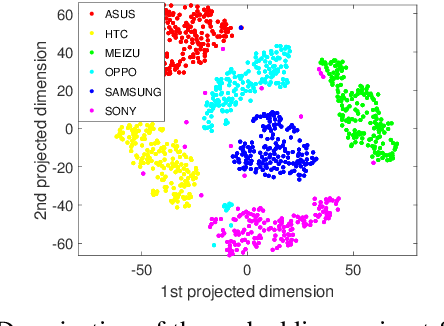
In this work, we propose a method to simultaneously perform (i) biometric recognition (i.e., identify the individual), and (ii) device recognition, (i.e., identify the device) from a single biometric image, say, a face image, using a one-shot schema. Such a joint recognition scheme can be useful in devices such as smartphones for enhancing security as well as privacy. We propose to automatically learn a joint representation that encapsulates both biometric-specific and sensor-specific features. We evaluate the proposed approach using iris, face and periocular images acquired using near-infrared iris sensors and smartphone cameras. Experiments conducted using 14,451 images from 15 sensors resulted in a rank-1 identification accuracy of upto 99.81% and a verification accuracy of upto 100% at a false match rate of 1%.