 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Weakly Supervised Volumetric Segmentation via Self-taught Shape Denoising Model
May 06, 2021
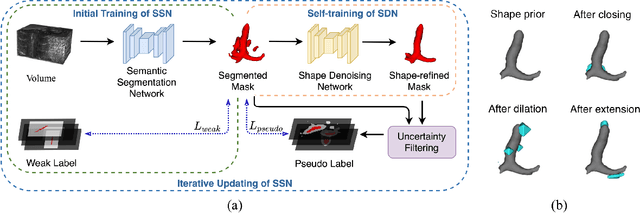
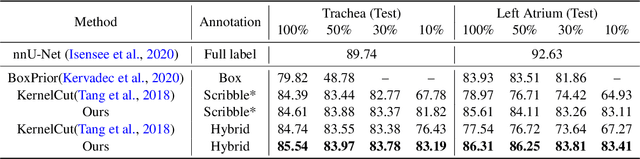


Weakly supervised segmentation is an important problem in medical image analysis due to the high cost of pixelwise annotation. Prior methods, while often focusing on weak labels of 2D images, exploit few structural cues of volumetric medical images. To address this, we propose a novel weakly-supervised segmentation strategy capable of better capturing 3D shape prior in both model prediction and learning. Our main idea is to extract a self-taught shape representation by leveraging weak labels, and then integrate this representation into segmentation prediction for shape refinement. To this end, we design a deep network consisting of a segmentation module and a shape denoising module, which are trained by an iterative learning strategy. Moreover, we introduce a weak annotation scheme with a hybrid label design for volumetric images, which improves model learning without increasing the overall annotation cost. The empirical experiments show that our approach outperforms existing SOTA strategies on three organ segmentation benchmarks with distinctive shape properties. Notably, we can achieve strong performance with even 10\% labeled slices, which is significantly superior to other methods.
CMUA-Watermark: A Cross-Model Universal Adversarial Watermark for Combating Deepfakes
May 23, 2021

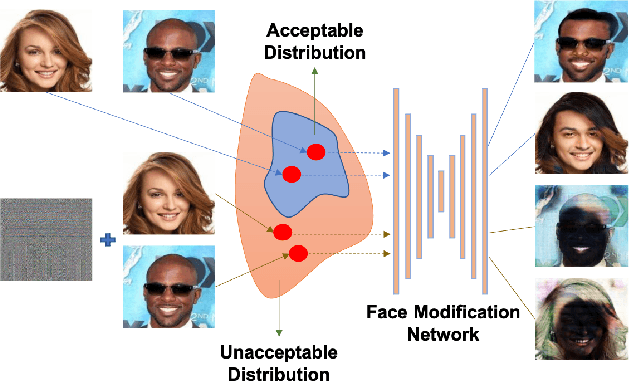

Malicious application of deepfakes (i.e., technologies can generate target faces or face attributes) has posed a huge threat to our society. The fake multimedia content generated by deepfake models can harm the reputation and even threaten the property of the person who has been impersonated. Fortunately, the adversarial watermark could be used for combating deepfake models, leading them to generate distorted images. The existing methods require an individual training process for every facial image, to generate the adversarial watermark against a specific deepfake model, which are extremely inefficient. To address this problem, we propose a universal adversarial attack method on deepfake models, to generate a Cross-Model Universal Adversarial Watermark (CMUA-Watermark) that can protect thousands of facial images from multiple deepfake models. Specifically, we first propose a cross-model universal attack pipeline by attacking multiple deepfake models and combining gradients from these models iteratively. Then we introduce a batch-based method to alleviate the conflict of adversarial watermarks generated by different facial images. Finally, we design a more reasonable and comprehensive evaluation method for evaluating the effectiveness of the adversarial watermark. Experimental results demonstrate that the proposed CMUA-Watermark can effectively distort the fake facial images generated by deepfake models and successfully protect facial images from deepfakes in real scenes.
Real-time Autonomous Robot for Object Tracking using Vision System
Apr 26, 2021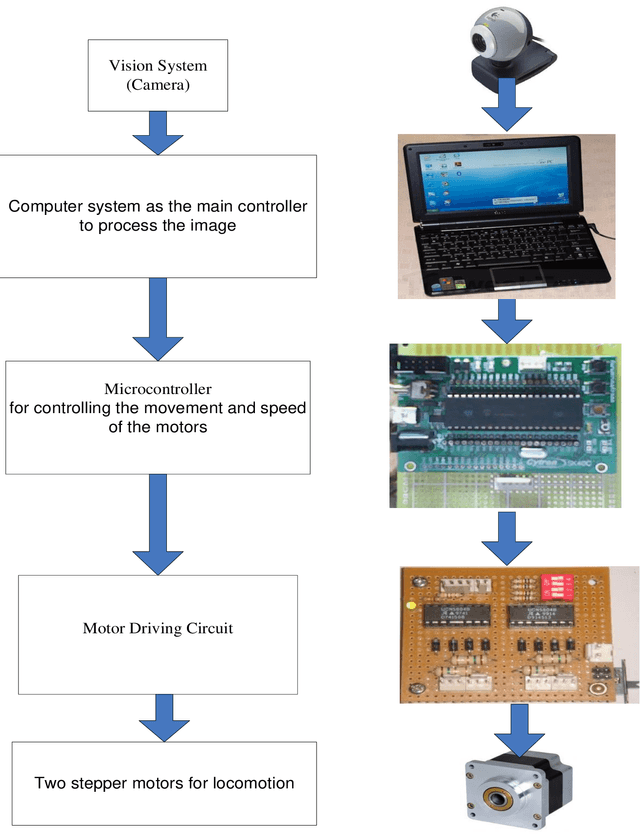


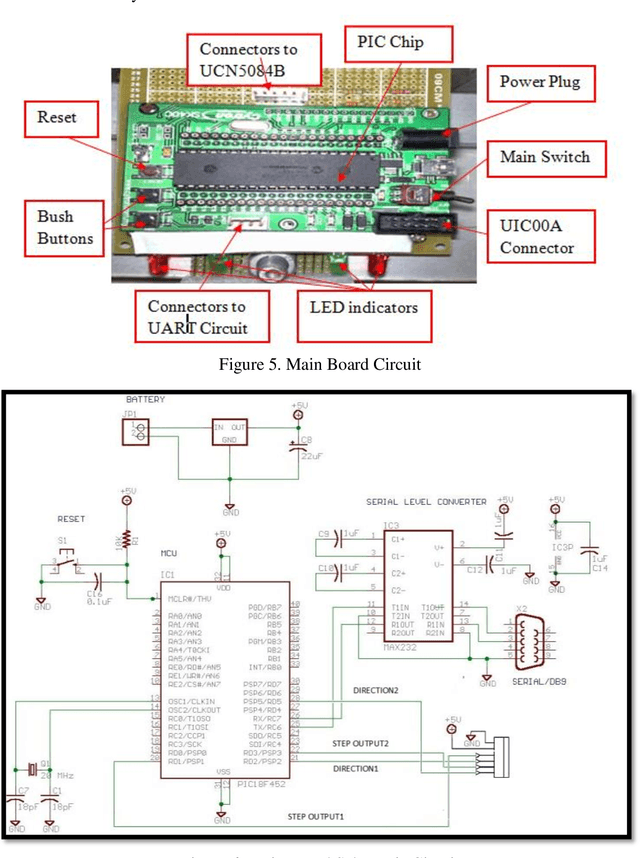
Researchers and robotic development groups have recently started paying special attention to autonomous mobile robot navigation in indoor environments using vision sensors. The required data is provided for robot navigation and object detection using a camera as a sensor. The aim of the project is to construct a mobile robot that has integrated vision system capability used by a webcam to locate, track and follow a moving object. To achieve this task, multiple image processing algorithms are implemented and processed in real-time. A mini-laptop was used for collecting the necessary data to be sent to a PIC microcontroller that turns the processes of data obtained to provide the robot's proper orientation. A vision system can be utilized in object recognition for robot control applications. The results demonstrate that the proposed mobile robot can be successfully operated through a webcam that detects the object and distinguishes a tennis ball based on its color and shape.
On training deep networks for satellite image super-resolution
Jun 16, 2019

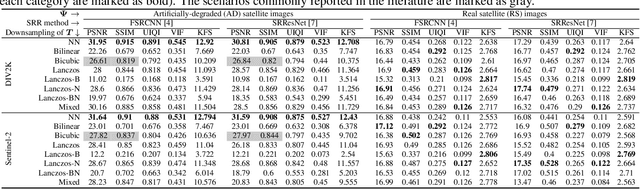
The capabilities of super-resolution reconstruction (SRR)---techniques for enhancing image spatial resolution---have been recently improved significantly by the use of deep convolutional neural networks. Commonly, such networks are learned using huge training sets composed of original images alongside their low-resolution counterparts, obtained with bicubic downsampling. In this paper, we investigate how the SRR performance is influenced by the way such low-resolution training data are obtained, which has not been explored up to date. Our extensive experimental study indicates that the training data characteristics have a large impact on the reconstruction accuracy, and the widely-adopted approach is not the most effective for dealing with satellite images. Overall, we argue that developing better training data preparation routines may be pivotal in making SRR suitable for real-world applications.
One Network to Segment Them All: A General, Lightweight System for Accurate 3D Medical Image Segmentation
Nov 05, 2019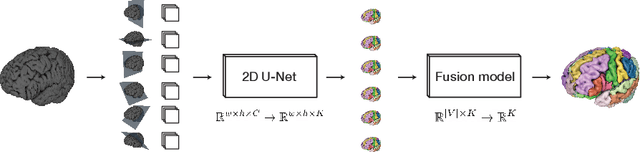

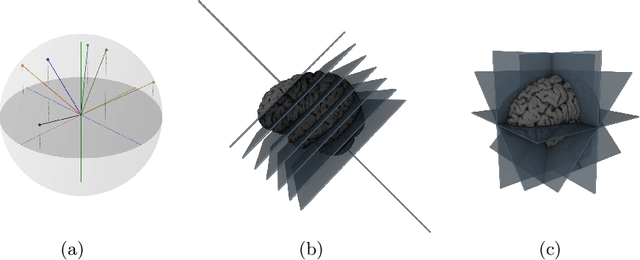
Many recent medical segmentation systems rely on powerful deep learning models to solve highly specific tasks. To maximize performance, it is standard practice to evaluate numerous pipelines with varying model topologies, optimization parameters, pre- & postprocessing steps, and even model cascades. It is often not clear how the resulting pipeline transfers to different tasks. We propose a simple and thoroughly evaluated deep learning framework for segmentation of arbitrary medical image volumes. The system requires no task-specific information, no human interaction and is based on a fixed model topology and a fixed hyperparameter set, eliminating the process of model selection and its inherent tendency to cause method-level over-fitting. The system is available in open source and does not require deep learning expertise to use. Without task-specific modifications, the system performed better than or similar to highly specialized deep learning methods across 3 separate segmentation tasks. In addition, it ranked 5-th and 6-th in the first and second round of the 2018 Medical Segmentation Decathlon comprising another 10 tasks. The system relies on multi-planar data augmentation which facilitates the application of a single 2D architecture based on the familiar U-Net. Multi-planar training combines the parameter efficiency of a 2D fully convolutional neural network with a systematic train- and test-time augmentation scheme, which allows the 2D model to learn a representation of the 3D image volume that fosters generalization.
"Weak AI" is Likely to Never Become "Strong AI", So What is its Greatest Value for us?
Mar 29, 2021AI has surpassed humans across a variety of tasks such as image classification, playing games (e.g., go, "Starcraft" and poker), and protein structure prediction. However, at the same time, AI is also bearing serious controversies. Many researchers argue that little substantial progress has been made for AI in recent decades. In this paper, the author (1) explains why controversies about AI exist; (2) discriminates two paradigms of AI research, termed "weak AI" and "strong AI" (a.k.a. artificial general intelligence); (3) clarifies how to judge which paradigm a research work should be classified into; (4) discusses what is the greatest value of "weak AI" if it has no chance to develop into "strong AI".
Global Weighted Average Pooling Bridges Pixel-level Localization and Image-level Classification
Sep 21, 2018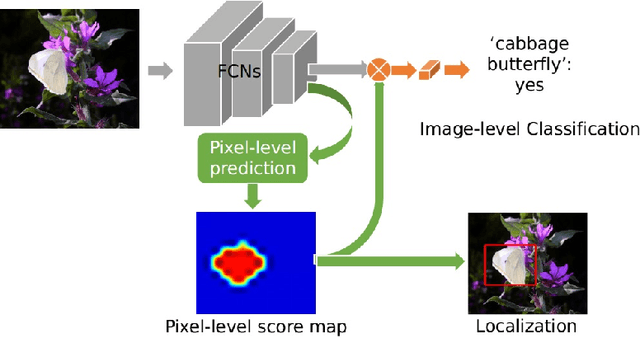
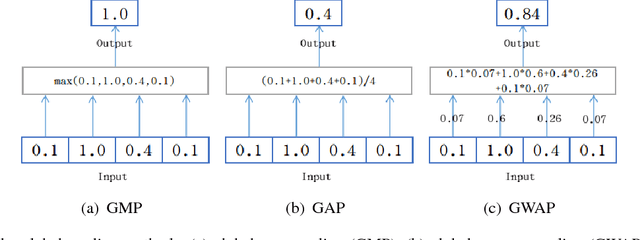
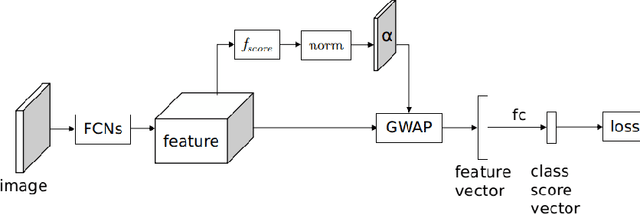

In this work, we first tackle the problem of simultaneous pixel-level localization and image-level classification with only image-level labels for fully convolutional network training. We investigate the global pooling method which plays a vital role in this task. Classical global max pooling and average pooling methods are hard to indicate the precise regions of objects. Therefore, we revisit the global weighted average pooling (GWAP) method for this task and propose the class-agnostic GWAP module and the class-specific GWAP module in this paper. We evaluate the classification and pixel-level localization ability on the ILSVRC benchmark dataset. Experimental results show that the proposed GWAP module can better capture the regions of the foreground objects. We further explore the knowledge transfer between the image classification task and the region-based object detection task. We propose a multi-task framework that combines our class-specific GWAP module with R-FCN. The framework is trained with few ground truth bounding boxes and large-scale image-level labels. We evaluate this framework on PASCAL VOC dataset. Experimental results show that this framework can use the data with only image-level labels to improve the generalization of the object detection model.
Joint Representation Learning and Novel Category Discovery on Single- and Multi-modal Data
Apr 26, 2021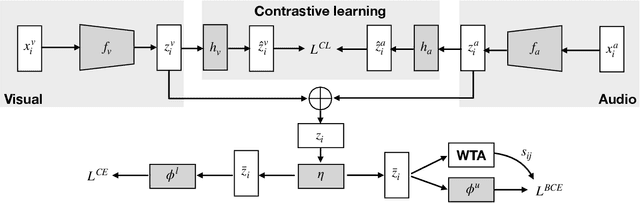
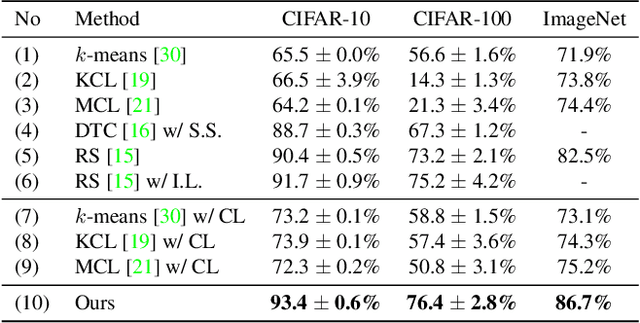
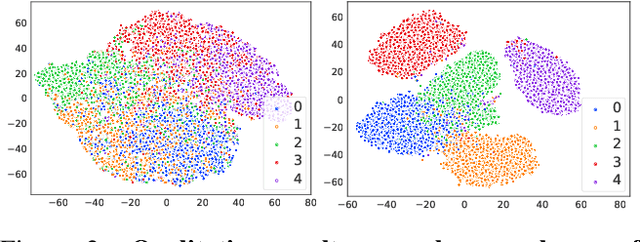
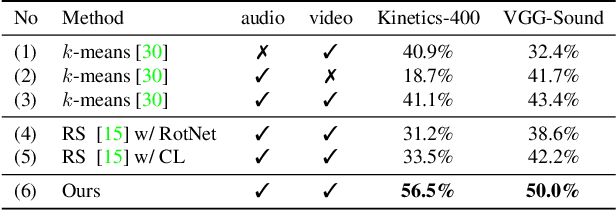
This paper studies the problem of novel category discovery on single- and multi-modal data with labels from different but relevant categories. We present a generic, end-to-end framework to jointly learn a reliable representation and assign clusters to unlabelled data. To avoid over-fitting the learnt embedding to labelled data, we take inspiration from self-supervised representation learning by noise-contrastive estimation and extend it to jointly handle labelled and unlabelled data. In particular, we propose using category discrimination on labelled data and cross-modal discrimination on multi-modal data to augment instance discrimination used in conventional contrastive learning approaches. We further employ Winner-Take-All (WTA) hashing algorithm on the shared representation space to generate pairwise pseudo labels for unlabelled data to better predict cluster assignments. We thoroughly evaluate our framework on large-scale multi-modal video benchmarks Kinetics-400 and VGG-Sound, and image benchmarks CIFAR10, CIFAR100 and ImageNet, obtaining state-of-the-art results.
Full Image Recover for Block-Based Compressive Sensing
Feb 01, 2018
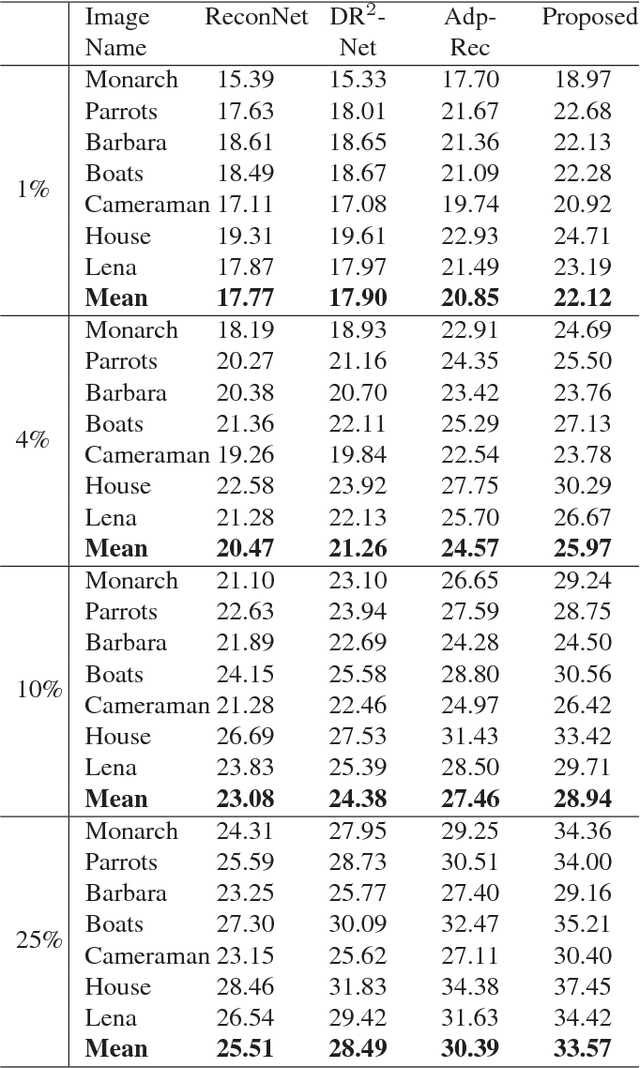
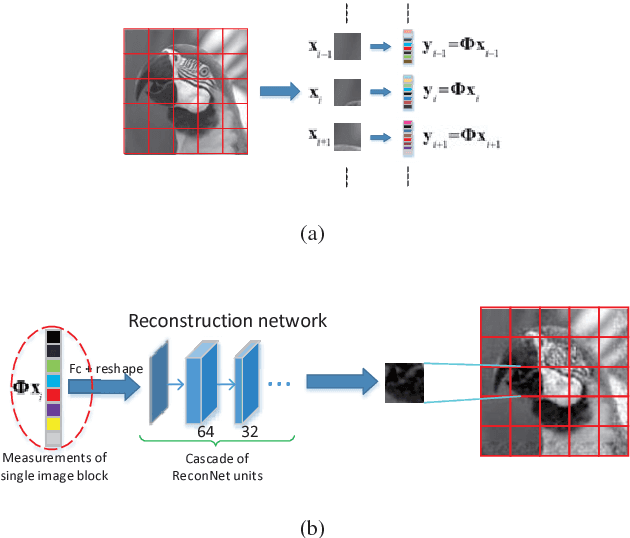
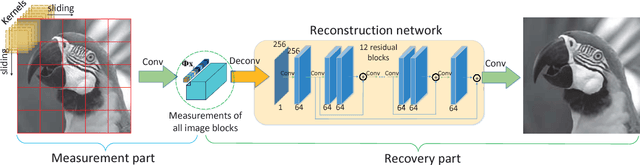
Recent years, compressive sensing (CS) has improved greatly for the application of deep learning technology. For convenience, the input image is usually measured and reconstructed block by block. This usually causes block effect in reconstructed images. In this paper, we present a novel CNN-based network to solve this problem. In measurement part, the input image is adaptively measured block by block to acquire a group of measurements. While in reconstruction part, all the measurements from one image are used to reconstruct the full image at the same time. Different from previous method recovering block by block, the structure information destroyed in measurement part is recovered in our framework. Block effect is removed accordingly. We train the proposed framework by mean square error (MSE) loss function. Experiments show that there is no block effect at all in the proposed method. And our results outperform 1.8 dB compared with existing methods.
Image Co-segmentation via Multi-scale Local Shape Transfer
May 15, 2018
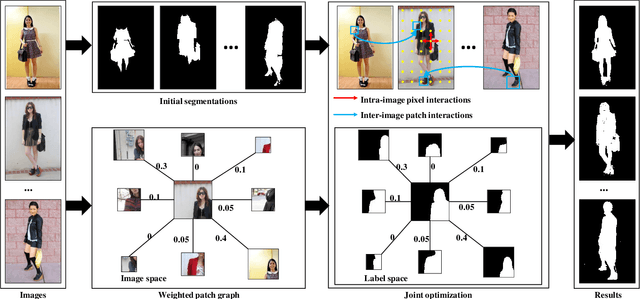


Image co-segmentation is a challenging task in computer vision that aims to segment all pixels of the objects from a predefined semantic category. In real-world cases, however, common foreground objects often vary greatly in appearance, making their global shapes highly inconsistent across images and difficult to be segmented. To address this problem, this paper proposes a novel co-segmentation approach that transfers patch-level local object shapes which appear more consistent across different images. In our framework, a multi-scale patch neighbourhood system is first generated using proposal flow on arbitrary image-pair, which is further refined by Locally Linear Embedding. Based on the patch relationships, we propose an efficient algorithm to jointly segment the objects in each image while transferring their local shapes across different images. Extensive experiments demonstrate that the proposed method can robustly and effectively segment common objects from an image set. On iCoseg, MSRC and Coseg-Rep dataset, the proposed approach performs comparable or better than the state-of-thearts, while on a more challenging benchmark Fashionista dataset, our method achieves significant improvements.